SEARCH
Advanced Search
ABOUT
Site Map
CP RSS Channel
Contact Us
Sponsoring CP
About Our Sponsors
NEWS
Cover Stories
Articles & Papers
Press Releases
CORE STANDARDS
XML
SGML
Schemas
XSL/XSLT/XPath
XLink
XML Query
CSS
SVG
TECHNOLOGY REPORTS
XML Applications
General Apps
Government Apps
Academic Apps
EVENTS
LIBRARY
Introductions
FAQs
Bibliography
Technology and Society
Semantics
Tech Topics
Software
Related Standards
Historic
|
This document is designed to provide a reference list on "schemas" in the context of XML, RDF, SGML, EXPRESS, etc. [Note: Content and organization are provisional; need to clean up references in part 3 especially.]
Expected WG Deliverables
"The Schema Working group plans to deliver Requirements, Working Drafts, and Proposed Recommendations on data typing and schema language in 1999."
WG Description
"While XML 1.0 supplies a mechanism, the Document Type
Definition (DTD) for declaring constraints on the use of markup,
automated processing of XML documents requires more rigorous
and comprehensive facilities in this area. Requirements are for
constraints on how the component parts of an application fit
together, the document structure, attributes, data-typing, and so
on. The XML Schema Working Group is
addressing means for defining the structure, content and
semantics of XML documents." See XML Schema Requirements Comments mailing list: [email protected] and archive.
XML Schema Developers List: The [email protected] discussion list is publicly archived on the W3C server. Henry Thompson announced this public list on April 07, 2000 with a message "'XML Schema Developers List Launched': To accompany the XML Schema Last Call drafts, the W3C is pleased to announce the opening of a public mailing list for XML Schema implementation developers, [email protected]. To subscribe, send mail to [email protected] with 'subscribe' as the subject."
See also "XML Schema: Tools - Usage - Development".
WG Published Deliverables
XML Schema Requirements
"XML Schema Requirements." W3C Note 15 February 1999. Edited by Ashok Malhotra (IBM) and Murray Maloney (Veo Systems Inc.). The document 'specifies the purpose, basic usage scenarios, design principles, and base requirements for an XML schema language.[local archive copy]
XML Schema Formalization
[March 21, 2001] W3C Publishes XML Schema Formalization. A communiqué from Matthew Fuchs (Commerce One) highlights the technical significance of W3C's recent XML Schema formalization, published in a W3C Working Draft as XML Schema: Formal Description. The document supplies formal a description of XML types and validity as specified by the recently-issued Proposed Recommendation XML Schema Part 1: Structures. From the Introduction: "This formalization is a formal, declarative system for describing and naming XML Schema information, specifying XML instance type information, and validating instances against schemas. The goals of the formalization are to: (1) Provide a semantic framework for software systems that use the W3C XML Schema specification, such as the W3C XML Query Algebra; (2) Specify names for all components of an XML Schema, so that they can be uniquely identified by URIs. Such unique identifiers may be useful to XML Query, RDF, and topic maps, among others; (3) Formally define validation at a declarative level; (4) Define the mapping from the current XML Schema syntax onto the structures described here, as well as the mapping between the XML Schema component mode and our component model. Many potential applications of XML Schema may benefit from the definition of a formal model. We have focused on the material in Part I (Structures), as this is the most complex; a basic understanding of first-order predicate logic, which is part of most computer science curricula, is adequate to understand this document." [Full context]
[May 03, 2001] W3C XML Schema Published as a W3C Recommendation. The World Wide Web Consortium (W3C) has announced the publication of the W3C XML Schema specification as a W3C Recommendation. A W3C 'Recommendation' "indicates that a specification is stable, contributes to Web interoperability, and has been reviewed by the W3C Membership, who are in favor of supporting its adoption by academic, industry, and research communities. XML Schemas define shared markup vocabularies, the structure of XML documents which use those vocabularies, and provide hooks to associate semantics with them. With over two years of development and testing through implementation, XML Schema provides an essential piece for XML to reach its full potential. The XML Schema specification consists of three parts. One part defines a set of simple datatypes, which can be associated with XML element types and attributes; this allows XML software to do a better job of managing dates, numbers, and other special forms of information. The second part of the specification proposes methods for describing the structure and constraining the contents of XML documents, and defines the rules governing schema-validation of documents. The third part is a primer, which explains what schemas are, how they differ from DTDs, and how someone builds a schema. XML Schema introduces new levels of flexibility that may accelerate the adoption of XML for significant industrial use. For example, a schema author can build a schema that borrows from a previous schema, but overrides it where new unique features are needed. XML Schema allows the author to determine which parts of a document may be validated, or identify parts of a document where a schema may apply. XML Schema also provides a way for users of ecommerce systems to choose which XML Schema they use to validate elements in a given namespace, thus providing better assurance in ecommerce transactions and greater security against unauthorized changes to validation rules. Further, as XML Schema are XML documents themselves, they may be managed by XML authoring tools, or through XSLT." [Full context In connection with the release of the Schema Recommendation, W3C has also provided for the creation of a W3C XML Schema Test Collection, announced by Henry S. Thompson (University of Edinburgh and W3C; Oriol Carbo, University of Edinburgh and W3C). "Goals and Objectives: The W3C XML Schema Test Collection work aims at coordinating test suites for W3C XML Schema processors created by different developers." The main objectives as announced 2001-05-02 are: (1) to integrate existing tests for W3C XML Schema processors in a common environment so they can be accessed publicly and shared among developers; (2) to establish a standard approach to test material IPR which meets the needs of both contributors and users; (3) to collect and develop tools to automate the execution and presentation of the test suites; (4) to offer a standard description of tests related to W3C XML Schema processors: [...]; (5) [to provide test descriptions] understandable by a developer without the need to actually view the test file(s) themselves); (6) to offer a standard presentation of test results; (7) to design additional tests and add/regularise descriptions of the existing tests; (8) in due course, to provide an XSLT-based approach to comparing XML representations of the post schema-validation infoset as produced by different processors; we will shortly announce the availability of XML Schemas for both the ordinary Infoset and the PSVInfoset. "The W3C expects to author only a small part of the collection -- we are counting on Member organisations and others to contribute the majority. To offer materials for the collection, please send e-mail to [email protected]." Note from Henry Thompson: "...the [email protected] mailing address is not a mailing list; it's for potential contributors to use to initiate discussions about contributions. For discussions of testing, I don't think we need a new mailing list; I'd expect [email protected] to be used for discussing W3C XML Schema testing..." - Announcement: "World Wide Web Consortium Issues XML Schema as a W3C Recommendation. Two Years of Development Produces Comprehensive Solution for XML Vocabularies."
- Testimonials for XML Schema Recommendation - From Altova, Inc., Commerce One, IBM, IPR Systems, Lotus Development Corporation, Microsoft Corporation, Oracle Corporation, Reuters, Inc., SAP AG, webMethods, and University of Edinburgh.
- XML Schema Part 1: Structures. W3C Recommendation 02-May-2001. [Default] namespace: http://www.w3.org/2001/XMLSchema. Latest version URL: http://www.w3.org/TR/xmlschema-1/. Edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle Corporation), Murray Maloney (for Commerce One), and Noah Mendelsohn (Lotus Development Corporation). Available in XML format (with XML DTD and XSL stylesheet); see also the separate XML Schema and XML DTD for Part 1. [cache .ZIP, local copy]
- XML Schema Part 2: Datatypes. W3C Recommendation 02-May-2001. Latest version URL: http://www.w3.org/TR/xmlschema-2/. Edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (Microsoft, formerly of IBM). Available in XML; also with a schema for built-in datatypes only. [cache]
- XML Schema Part 0: Primer. W3C Recommendation 02-May-2001. Latest version URL: http://www.w3.org/TR/xmlschema-0/. Edited by David C. Fallside (IBM). Appendices include: A. Acknowledgements; B. Simple Types & Their Facets; C. Using Entities D. Regular Expressions E. Index. [cache]
- Namespaces. [Default] namespace: http://www.w3.org/2001/XMLSchema. Also: "To facilitate usage in specifications other than the XML Schema definition language, such as those that do not want to know anything about aspects of the XML Schema definition language other than the datatypes, each 'built-in' datatype is also defined in the namespace whose URI is: http://www.w3.org/2001/XMLSchema-datatypes. This applies to both 'built-in primitive' and 'built-in derived' datatypes."
- Mail Archives for W3C XML Schema development '[email protected]'. Send subscription requests to [email protected].
- Mail Archives for 'www-xml-schema-comments'
- XML Schema type library - Sample. See the Primer (Part 0) for reference/description. [cache]
- Errata for W3C XML Schema Rec
- Translations of W3C XML Schema Rec
[March 31, 2001] XML Schema. W3C Proposed Recommendation 30-March-2001. "This version of this Proposed Recommendation replaces that published on 16-March-2001. The only change from that draft is that the type there called 'number' is here renamed 'decimal'. This type was called 'decimal' up until the draft of 16 March 2001, so this change simply restores the original name of this type." The deadline for review of this document is Monday 16 April 2001. XML Schema Part 0: Primer; XML Schema Part 1: Structures; XML Schema Part 2: Datatypes.
[March 16, 2001] W3C Publishes XML Schema as a Proposed Recommendation. The W3C XML Schema specification has advanced to the 'Proposed Recommendation' stage, indicating that "the specification is stable and that implementation experience has been gathered, showing that each feature of the specification can be implemented." The three-part document has been produced as part of the W3C XML Activity. This PR version replaces the Candidate Recommendation of October 24, 2000. The deadline for review of the PR specification is Monday April 16, 2001. Review comments may be sent to the publicly archived 'xmlschema-dev' mailing list. As with the Candidate Recommendation, "The XML Schema specification consists of three parts. One part defines a set of simple datatypes, which can be associated with XML element types and attributes; this allows XML software to do a better job of managing dates, numbers, and other special forms of information. The second part of the specification proposes methods for describing the structure and constraining the contents of XML documents, and defines the rules governing schema-validation of documents. The third part is a primer, which explains what schemas are, how they differ from DTDs, and how someone builds a schema." [Full context]
See also:
- DTD changes in XML Schema from CR to PR. Provided by Robin LaFontaine, based on DeltaXML schema comparison software. See DeltaXML XML Schema [comparison] software. [source]
- [March 31, 2001] Revised Online Validator for XML Schema (XSV) and XML Schema Update Tool (XSU). Henry S. Thompson (HCRC Language Technology Group, University of Edinburgh) has announced a revised 'beta test' release of his XSV 'Validator for XML Schema' service and corresponding XSU update tool for XML Schema CR -> PR. This version of XSV supports checking XML schema documents with the namespace URI http://www.w3.org/2001/XMLSchema, corresponding to the W3C Proposed Recommendation for XML Schema. XSV is an open source "GPLed work-in-progress attempt at a conformant schema-aware processor." The online XSV interface provides two forms for W3C XML schema checking: "(1) one for checking a schema which is accessible via the Web, and/or schema-validating an instance with a schema of your own; (2) another form for use if you are behind a firewall or have a schema to check which is not accessible via the Web." In addition to source code distributions (Python), the latest version of XSV is available in a self-installing package for Win32 platforms. The XSU transformation tool provides for automated update of XML Schema documents from the XML Schema 20000922 version to the Proposed Recommendation (20010316) version. It is a service in 'beta test' which "attempts to convert valid XML schema documents with the namespace URI http://www.w3.org/2000/10/XMLSchema to valid schema documents with the namespace URI http://www.w3.org/2001/XMLSchema" using a transform sheet. In this connection, the XSU developers request sample XML schemas to provide a testing pool: they ask that users grant permission to W3C to retain input of tested XML schemas (just tick the checkbox). [Full context]
[October 24, 2000] Testimonials for XML Schema Candidate Recommendation. [cache] [October 24, 2000] Announcement (in part): A W3C press release announces the publication of XML Schema as a W3C Candidate Recommendation. "The World Wide Web Consortium (W3C) has issued XML Schema as a W3C Candidate Recommendation. Advancement of the document to Candidate Recommendation is an invitation to the Web development community at large to make implementations of XML Schema and provide technical feedback. Simply defined, XML Schemas define shared markup vocabularies and allow machines to carry out rules made by people. They provide a means for defining the structure, content and semantics of XML documents. 'Databases, ERP and EDI systems all know the difference between a date and a string of text, but before today, there was no standard way to teach your XML systems the difference. Now there is,' declared Dave Hollander, co-chair of the W3C XML Schema Working Group and CTO of Contivo, Inc. 'W3C XML Schemas bring to XML the rich data descriptions that are common to other business systems but were missing from XML. Now, developers of XML ecommerce systems can test XML Schema's ability to define XML applications that are far more sophisticated in how they describe, create, manage and validate the information that fuels B2B ecommerce.' By bringing datatypes to XML, XML Schema increases XML's power and utility to the developers of electronic commerce systems, database authors and anyone interested in using and manipulating large volumes of data on the Web. By providing better integration with XML Namespaces, it makes it easier than it has ever been to define the elements and attributes in a namespace, and to validate documents which use multiple namespaces defined by different schemas. XML Schema introduces new levels of flexibility that may accelerate the adoption of XML for significant industrial use. For example, a schema author can build a schema that borrows from a previous schema, but overrides it where new unique features are needed. his principle, called inheritance, is similar to the behavior of Cascading Style Sheets, and allows the user to develop XML Schemas that best suit their needs, without building an entirely new vocabulary from scratch. XML Schema allows the author to determine which parts of a document may be validated, or identify parts of a document where a schema may apply. XML Schema also provides a way for users of ecommerce systems to choose which XML Schema they use to validate elements in a given namespace, thus providing better assurance in ecommerce transactions and greater security against unauthorized changes to validation rules. Further, as XML Schema are XML documents themselves, they may be managed by XML authoring tools, or through XSLT. . . Candidate Recommendation is W3C's public call for implementation, an explicit invitation for W3C members and the developer community at large to review the XML Schema specification and build their own XML Schemas. This period of implementations and reporting allows the editors to learn how developers outside of the Working Group might use them, and where there may be ambiguities for implementors. Public testing and implementation contribute to a more robust XML Schema, and to more widespread use." See the full text of the announcement: "World Wide Web Consortium Issues XML Schema as a Candidate Recommendation. Implementation testing the key to Interoperability." [cache] [October 24, 2000] XML Schema Part 1: Structures. W3C Candidate Recommendation 24-October-2000, edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle Corp.), Murray Maloney (for Commerce One), and Noah Mendelsohn (Lotus Development Corporation). Part 1 defines the XML Schema definition language, "which offers facilities for describing the structure and constraining the contents of XML 1.0 documents, including those which exploit the XML Namespace facility. The schema language, which is itself represented in XML 1.0 and uses namespaces, substantially reconstructs and considerably extends the capabilities found in XML 1.0 document type definitions (DTDs). This specification depends on XML Schema Part 2: Datatypes. Appendix A supplies a normative "Schema for Schemas"; Appendix F contains a non-normative "DTD for Schemas"; Appendix J gives brief summaries of the substantive changes to this specification since the public working draft of 7 April 2000. XSD for XML Schema, [cache] DTD for XML Schema, [cache] [October 24, 2000] XML Schema Part 2: Datatypes. W3C Candidate Recommendation 24-October-2000, exited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). Part 2 of the specification for the XML Schema language "defines facilities for defining datatypes to be used specifications. The datatype language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs) for specifying datatypes on elements and attributes." Appendix A provides the normative "Schema for Datatype Definitions" and Appendix B gives the non-normative "DTD for Datatype Definitions." [October 24, 2000] XML Schema Part 0: Primer. W3C Candidate Recommendation 24-October-2000, edited by David C. Fallside (IBM). "XML Schema Part 0: Primer is a non-normative document intended to provide an easily readable description of the XML Schema facilities and is oriented towards quickly understanding how to create schemas using the XML Schema language. XML Schema Part 1: Structures and XML Schema Part 2: Datatypes provide the complete normative description of the XML Schema language -- this primer describes the language features through numerous examples which are complemented by extensive references to the normative texts." [October 24, 2000] Commentary. See the longer memo from Henry S. Thompson (Janet Daly) with an explanation of why (I18N) WG dissented from the specification's treatment of dates and times, and the CR exit criteria. Also, in connection with this CR publication, Henry Thompson announced the availablility of a self-installing version of XSV, the W3C/University of Edinburgh XML Schema validator; 'WIN32 for now, UN*X coming soon'.
[September 22, 2000] XML Schema Part 1: Structures. Reference: W3C Working Draft 22-September-2000, edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle Corp.), Murray Maloney (for Commerce One), and Noah Mendelsohn (Lotus Development Corporation). The most important changes for the 07-September-2000 release are found in this Structures document. The non-normative 'Appendix H' in the Structures document supplies a "Description of changes" to the working draft since the previous public version of 07-April-2000. Some eighteen (18) changes are identified here. For example: [H1] "'Equivalence classes' have been renamed 'substitution groups', to reflect the fact that their semantics is not symmetrical; [H2] "The content model of the complexType element has been significantly changed, allowing for tighter content models and a better fit between the abstract component and its XML Representation"; [H3] "Empty content models are now signalled by an explicit empty content particle, mixed content by specifying the value true for the mixed attribute on complexType or complexContent; [H6] "A new form of schema composition operation, similar to that provided by include but allowing constrained redefinition of the included components has been added, using a redefine element"; [H8] "The defaulting for the minOccurs and maxOccurs attributes of element has been simplified: it is now 1 in both cases, with no interdependencies"; [H9] "The content model for the group element when it occurs at the top level has been tightened, to allow only a single all, choice, group, or sequence child"; [H13] "Abstract types in element declarations are now allowed." See the main news entry and editorial notes provided in Henry Thompson's announcement 'New Pre-CR Public Working Drafts of XML Schema Released'. [cache] [September 22, 2000] XML Schema Part 2: Datatypes. Reference: W3C Working Draft 22-September-2000, edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). "XML Schema: Datatypes is part 2 of a two-part draft of the specification for the XML Schema definition language. "This document proposes facilities for defining datatypes to be used in XML Schemas as well as other XML specifications. The datatype language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs) for specifying datatypes on elements and attributes." [cache] [September 22, 2000] XML Schema Part 0: Primer. Reference: W3C Working Draft, 22-September-2000, edited by David C. Fallside (IBM). "XML Schema Part 0: Primer is a non-normative document intended to provide an easily readable description of the XML Schema facilities and is oriented towards quickly understanding how to create schemas using the XML Schema language." [cache]
[February 26, 2000] XML Schema Part 0: Primer. Reference: W3C Working Draft, 25-February-2000, edited by David C. Fallside (IBM). The primer has been issued in conjunction with a new working draft [25 February 2000] of the normative tomes on XML Schema Structures and XML Schema Datatypes. Abstract: XML Schema Part 0: Primer is a non-normative document intended to provide an easily readable description of the XML Schema facilities and is oriented towards quickly understanding how to create schemas using the XML Schema language. XML Schema Part 1: Structures and XML Schema Part 2: Datatypes provide the complete normative description of the XML Schema definition language, and the primer describes the language features through numerous examples which are complemented by extensive references to the normative texts. This 'Second Torah' commentary is officially a part of the W3C XML Activity. Discrepancies between the sacred text and its commentary are noted in the Primer. Description: "This document, XML Schema Part 0: Primer, provides an easily approachable description of the XML Schema definition language, and should be used alongside the formal descriptions of the language contained in Parts 1 and 2 of the XML Schema specification. The intended audience of this document includes application developers whose programs read and write schema documents, and schema authors who need to know about the features of the language, especially features that provide functionality above and beyond what is provided by DTDs. The text assumes that you have a basic understanding of XML 1.0 and XML-Namespaces. Each major section of the primer introduces new features of the language, and describes the features in the context of concrete examples. Section 2 covers the basic mechanisms of XML Schema. It describes how to declare the elements and attributes that appear in XML documents, the distinctions between simple and complex types, defining complex types, the use of simple types for element and attribute values, schema annotation, a simple mechanism for re-using element and attribute definitions, and null values. Section 3 covers some of XML Schema's advanced features, and in particular, it describes mechanisms for deriving types from existing types, and for controlling these derivations. The section also describes mechanisms for merging together fragments of a schema from multiple sources, and for element substitution. Section 4 covers more advanced features, including a powerful mechanism for specifying uniqueness among attributes and elements, a mechanism for using types across namespaces, a mechanism for extending types based on namespaces, and a description of how documents are checked for conformance. In addition to the sections just described, the primer has a number of appendices that contain detailed reference information on simple types and an associated regular expression language. The primer is a non-normative document, which means that it does not provide a definitive (from the W3C's point of view) specification of the XML Schema language." [February 26, 2000] XML Schema Part 1: Structures. Reference: W3C Working Draft 25-February-2000; edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle Corp.), Murray Maloney (Commerce One), and Noah Mendelsohn (Lotus Development Corporation). The specification itself is available in XML as well as HTML format. The release includes a formal description of schema 'structures' facilities in schema and in XML DTD notation. "Following a period of review and polishing, it is the WG's intent to issue a Last Call for Review by other W3C working groups sometime during March, 2000, and to submit this specification thereafter for publication as a Candidate Recommendation." Document abstract: "XML Schema: Structures specifies the XML Schema definition language, which offers facilities for describing the structure and constraining the contents of XML 1.0 documents. The schema language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs). This specification depends on XML Schema Part 2: Datatypes." Description: "The purpose of XML Schema: Structures is to define the nature of XML schemas and their component parts, provide an inventory of XML markup constructs with which to represent schemas, and define the application of schemas to XML documents. The purpose of an XML Schema: Structures schema is to define and describe a class of XML documents by using schema components to constrain and document the meaning, usage and relationships of their constituent parts: datatypes, elements and their content and attributes and their values. Schemas may also provide for the specification of additional document information, such as default values for attributes and elements. Schemas have facilities for self-documentation. Thus, XML Schema: Structures can be used to define, describe and catalogue XML vocabularies for classes of XML documents. Any application that consumes well-formed XML can use the XML Schema: Structures formalism to express syntactic, structural and value constraints applicable to its document instances. The XML Schema: Structures formalism allows a useful level of constraint checking to be described and validated for a wide spectrum of XML applications. However, the language defined by this specification does not attempt to provide all the facilities that might be needed by any application. Some applications may require constraint capabilities not expressible in this language, and so may need to perform their own additional validations." [February 26, 2000] XML Schema Part 2: Datatypes. Reference: W3C Working Draft 25-February-2000; edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). The release includes separate documents containing the corresponding formal schema notation, an XML DTD, and schema for built-in datatypes only; there is an XML version as well. XML Schema: Datatypes is part 2 of a two-part draft of the specification for the XML Schema definition language. This document proposes facilities for defining datatypes to be used in XML Schemas and other XML specifications. The datatype language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs) for specifying datatypes on elements and attributes. Rationale for Part 2: "... validity constraints exist on the content of [XML document] instances that are not expressible in XML DTDs. The limited datatyping facilities in XML have prevented validating XML processors from supplying the rigorous type checking required in these situations. The result has been that individual applications writers have had to implement type checking in an ad hoc manner. This specification addresses the need of both document authors and applications writers for a robust, extensible datatype system for XML which could be incorporated into XML processors. As discussed below, these datatypes could be used in other XML-related standards as well." The concrete requirements to be fulfilled by this specification are articulated in the XML Schema Requirements document; it states that the XML Schema Language must: (1) provide for primitive data typing, including byte, date, integer, sequence, SQL & Java primitive data types, etc.; (2) define a type system that is adequate for import/export from database systems (e.g., relational, object, OLAP); (3) distinguish requirements relating to lexical data representation vs. those governing an underlying information set; (4) allow creation of user-defined datatypes, such as datatypes that are derived from existing datatypes and which may constrain certain of its properties (e.g., range, precision, length, format). "Although the Working Group does not anticipate further substantial changes to the functionality described here, this is still a working draft, subject to change based on experience and on comment by the public and other W3C working groups. Following a period of review and polishing, it is the WG's intent to issue a Last Call for Review by other W3C working groups sometime during March, 2000, and to submit this specification thereafter for publication as a Candidate Recommendation."
[December 17, 1999] XML Schema Part 1: Structures (W3C Working Draft 17-December-1999). Edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle Corp.), Murray Maloney (Commerce One), and Noah Mendelsohn (Lotus Development Corporation). XML Schema: Structures represents "part 1 of a two-part draft of the specification for the XML Schema definition language. This document proposes facilities for describing the structure and constraining the contents of XML 1.0 documents. The schema language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs)." The purpose of a Structures schema document is to "define and describe a class of XML documents by using these constructs to constrain and document the meaning, usage and relationships of their constituent parts: datatypes, elements and their content, attributes and their values. Schema constructs may also provide for the specification of additional information such as default values. Schemas are intended to document their own meaning, usage, and function through a common documentation vocabulary. Thus, XML Schema: Structures can be used to define, describe and catalogue XML vocabularies for classes of XML documents." [local archive copy] XML schema - 'Schema for Schemas'; [local archive copy] XML DTD - 'DTD for Schemas'; [local archive copy] XML Schema: Structures in XML format [December 20, 1999] Henry S. Thompson has made available the slides and some additional documentation from an intensive (full-day) tutorial session on the XML Schema Definition Language, presented at XML '99 in Philadelphia. The materials have been updated to match the 1999-12-17 versions of the Schema WD documents. (1) presentation slides in HTML, and (2) additional materials in HTML. Original/canonical formats: Powerpoint slides [local archive copy] and additional notes (.doc) [local archive copy]. Announced on XML-DEV 20-Dec-1999. dtddiff of 1999-12-17 schema proposal vis-à-vis 1999-11 WD. "Below is the result of running Earl Hood's dtddiff script to compare the DTD's from appendix B of the November and December drafts of the W3C Schema Proposal." From Bob DuCharme XML Schema Part 2: Datatypes (W3C Working Draft 17-December-1999) has been edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). XML Schema: Datatypes presents part 2 of a two-part draft of the specification for the XML Schema definition language. This document proposes facilities for defining datatypes to be used in XML Schemas and other XML specifications. The datatype language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs) for specifying datatypes on elements and attributes." It is well known that "validity constraints exist on the content of [XML document] instances that are not expressible in XML DTDs. The limited datatyping facilities in XML have prevented validating XML processors from supplying the rigorous type checking required in these situations. The result has been that individual applications writers have had to implement type checking in an ad hoc manner. This [Datatypes] specification addresses the need of both document authors and applications writers for a robust, extensible datatype system for XML which could be incorporated into XML processors." At the moment, these datatypes can be specified only "for element content that would be specified as #PCDATA and attribute values of various types in a DTD." [local archive copy] XML schema - Schema for datatypes; [local archive copy] XML DTD - DTD for datatypes; [local archive copy] XML Schema: Datatypes in XML Format
XML Schema Definition Language - Second Working Draft
XML Schema Part 1: Structures. Reference: W3C Working Draft 24-September-1999, edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle),
Murray Maloney (Commerce One), and Noah Mendelsohn (Lotus).
Part 1 "proposes facilities for describing the structure and constraining the contents of XML
1.0 documents. The schema language, which is itself represented in XML 1.0, provides a superset of the
capabilities found in XML 1.0 document type definitions (DTDs). . .
The purpose of the Structures specification is to provide an
inventory of XML markup constructs with which to write schemas." Such
a schema is used "to define and describe a class of XML documents by
using these constructs to constrain and document the meaning, usage and relationships of their constituent
parts: datatypes, elements and their content, attributes and their values, entities and their contents and notations.
Schema constructs may also provide for the specification of additional information such as default values.
Schemas are intended to document their own meaning, usage, and function through a common documentation
vocabulary. Thus, the Structures specification can be used to define, describe and catalogue XML vocabularies for
classes of XML documents. Any application that consumes well-formed XML can use the XML Schema: Structures formalism to express
syntactic, structural and value constraints applicable to its document instances. The Structures
formalism will allow a useful level of constraint checking to be described and validated for a wide spectrum of
XML applications. However, the language defined by this specification does not attempt to provide all the
facilities that might be needed by any application. Some applications may require constraint capabilities not
expressible in this language, and so may need to perform their own additional validations."
- Structures - HTML Version, [local archive copy]
- XML format, [local archive copy]
- XML schema, [local archive copy]
- XML DTD, [local archive copy]
- Comments to:[email protected]
- Comments public archive.
- XML Schema Part 1: Structures - Proposed Updates from Simplification Task Force. 13-August-1999. Based on W3C Working Draft 19-July-1999. Taskforce members: D. Beech, P. Biron, A. Brown, P. Chen, D. Fallside (ed), M. Fuchs, M. Murata, J. Robie. "The updates proposed in this document take the form of new text to replace text currently existing in sections 2, 3 and Appendix B of the 19 July XML Schema: Structures working draft. Within sections 2 and 3 of this proposal, subsections indicated by only headings are assumed to contain the text of the July 19 draft, although note that the heading itself of section 2.4 is updated." [local archive copy]
- Proposal by the "Simple Syntax" Taskforce. August 13, 1999. Taskforce members: D. Beech, P. Biron, A. Brown, P. Chen, D. Fallside (ed), M. Fuchs, M. Murata, J. Robie. "This paper describes the recommendation of the "Simple Syntax" Taskforce for simplifying the syntax of element definitions, type definitions, and element usage within content models. It provides a syntax description, examples, in addition to a summary of alternatives explored. A companion document XML Schema Part 1: Structures - Proposed Updates from Simplification Taskforce proposes new text for the Structures working draft." [local archive copy]
- Note on the 2nd WD, by Henry S. Thompson
- dtddiff of XSDL 5/99 and 9/99 - Provided by Bob DuCharme, XML-DEV.
-
XML Schema Part 2: Datatypes. Reference: W3C Working Draft 24-September-1999, edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). The Datatypes document "specifies a language for defining datatypes to be used in XML Schemas and possibly elsewhere." As explained in the W3C's XML Schema Requirements document, the Datatypes design is motivated by the recognition that "document authors, including authors of traditional documents and those transporting data in XML, often require a high degree of type checking to ensure robustness in document understanding and data interchange." In many cases, "validity constraints exist on the content of the [XML] instances that are not expressible in XML DTDs. The limited datatyping facilities in XML have prevented validating XML processors from supplying the rigorous type checking required in these situations. The result has been that individual applications writers have had to implement type checking in an ad hoc manner. This [Datatypes] specification addresses the need of both document authors and applications writers for a robust, extensible datatype system for XML which could be incorporated into XML processors." The facilities in the Datatypes WD have been designed in light of the formal requirements, which stipulate that the XML Schema Language must: (1) provide for primitive data typing, including byte, date, integer, sequence, SQL & Java primitive data types, etc.; (2) define a type system that is adequate for import/export from database systems (e.g., relational, object, OLAP); (3) distinguish requirements relating to lexical data representation vs. those governing an underlying information set; and (4) allow creation of user-defined datatypes, such as datatypes that are derived from existing datatypes and which may constrain certain of its properties (e.g., range, precision, length, format)."
XML Schema Definition Language - First Working Draft
XML Schema Part 1: Structures. W3C Working Draft 6-May-1999. Edited by David Beech (Oracle), Scott Lawrence (Agranat Systems), Murray Maloney (Commerce One), Noah Mendelsohn (Lotus), and Henry S. Thompson (University of Edinburgh). Part 1 'proposes facilities for associating datatypes with XML element types and attributes; this will allow XML software to do a better job of managing dates, numbers, and other special forms of information.'
XML Schema Part 2: Datatypes. World Wide Web Consortium Working Draft 06-May-1999. Edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). Part 2 of the specification 'proposes methods for describing the structure and constraining the contents of XML documents.'
XML-Data. W3C Note 05-Jan-1998. "This paper describes an XML vocabulary for schemas, that is, for defining and documenting object classes. It can be used for classes which as strictly syntactic (for example, XML) or those which indicate concepts and relations among concepts (as used in relational databases, KR graphs and RDF). The former are called 'syntactic schemas;' the latter 'conceptual schemas'." XML-Data Reduced. Draft Version 3-July-1998, version 0.21. By Charles Frankston (Microsoft) and Henry S. Thompson (University of Edinburgh). "The XML-Data submission contained many new ideas that an XML schema language could support. This document refines and subsets those ideas down to a more manageable size in order to allow faster progress toward adopting a new schema language for XML. Some of the inconsistencies in the XML-Data submission are cleaned up, and some changes have been made based on comments received since the XML-Data submission was posted. This note is a refinement of the January 1998 XML-Data submission http://www.w3.org/TR/1998/NOTE-XML-data-0105/." [local archive copy] "[Microsoft] XML Schema Developer's Guide" Andrew Layman [XML-DEV 18-May-1999]: "'XML-Data Reduced' (XDR) refers to a trimmed and improved version of the XML-Data schema syntax. The original XML-Data submission can be found at http://www.w3.org/TR/1998/NOTE-XML-data/. Information on XML-Data Reduced is at http://msdn.microsoft.com/xml/XMLGuide/schema-overview.asp'." Note: 'XDR' in this context not to be confused with XDR: External Data Representation Standard (Network Working Group, Request for Comments: 1832, August 1995). [February 09, 2001] Microsoft XDR-XSD Converter. An XDR-XSD Converter is available for download from Microsoft's [XML] MSDN Online Development Center. The transformation tool is made available in its current beta state for experimentation purposes only. "This XSLT stylesheet transforms XML Data Reduced (XDR) Schemas as supported in MSXML to XML Schemas -- conformant to the W3C XML Schema Candidate Recommendation of October 25, 2000. MSXML 3.0 itself does not support the W3C XML Schema format. Notes on XDR-XSD Converter: XDR schemas using open content models allow more attribute extensions than the XML Schema resulting from this style sheet. Specifically, under XDR, when model="open" attributes from the target namespace may be added to an element, as long as they conform to the validity constraints for that attribute. Attributes from other namespaces may be added to an element, whether or not there are validity constraints for those attributes. It is not possible in XSD to treat attribute validation differently for attributes from the target namespace (<xsd:anyAttribute namespace="##targetNamespace" processContents="lax"/>) than for attributes from other namespaces (<xsd:anyAttribute namespace="##other" processContents="strict"/>). This is represented in the XML Schema DTD as only allowing one <xsd:anyAttribute/> element. The transformed XSD schema will not allow attributes from the target namespace. You may want to adjust the resulting schema to accommodate for this, by either not requiring attributes from the target namespace to be validated, or by adding the allowed attributes explicitly to the content model." The developers welcome feedback on problems encountered or other suggestions that would help them improve the transformation tool.
DCD. NOTE-dcd-19980731, Submission to the World Wide Web Consortium 31-July-1998. "This document proposes a structural schema facility, Document Content Description (DCD), for specifying rules covering the structure and content of XML documents. The DCD proposal incorporates a subset of the XML-Data Submission and expresses it in a way which is consistent with the ongoing W3C RDF (Resource Description Framework) effort; in particular, DCD is an RDF vocabulary. DCD is intended to define document constraints in an XML syntax; these constraints may be used in the same fashion as traditional XML DTDs. DCD also provides additional properties, such as basic datatypes."
SOX. Schema for Object-oriented XML. NOTE-SOX-19980930, Submitted to W3C 19980915. "This document proposes a schema facility, Schema for Object-oriented XML (SOX), for defining the structure, content and semantics of XML documents to enable XML validation and higher levels of automated content checking. The SOX proposal is informed by the XML 1.0 [XML] specification as well as the XML-Data submission (XML-Data), the Document Content Description submission (DCD) and the EXPRESS language reference manual (ISO-10303-11). SOX provides an alternative to XML DTDs for modeling markup relationships to enable more efficient software development processes for distributed applications." "SOX was created by Commerce One in anticipation of the coming W3C standard XML Schema Language. SOX leverages the object-relationships between data structures to allow for the easy management of a component library, and the use of type relationships within schema-based e-commerce applications. It also provides strong datatyping capabilities, like other XML Schema languages..." References:
DDML. Document Definition Markup Language (DDML) Specification, Version 1.0. NOTE-ddml-19990119, W3C Note, 19-Jan-1999. "This document proposes Document Definition Markup Language (DDML), a schema language for XML documents. DDML [previously 'XSchema'] encodes the logical (as opposed to physical) content of DTDs in an XML document. This allows schema information to be explored and used with widely available XML tools. DDML is deliberately simple, providing an initial base for implementations. While introducing as few complicating factors as possible, DDML has been designed with future extensions, such as data typing and schema reuse, in mind."
[January 13, 2000] The W3C has acknowledged a submission request from Extensibility, Inc for publication of a NOTE: Datatypes for DTDs (DT4DTD) 1.0. Reference: W3C Note 13-January-2000, by Lee Buck (Extensibility), Charles F. Goldfarb (The XML Handbook), and Paul Prescod (ISOGEN International). The document abstract: "The presented specification allows legacy systems that may presently be unable to convert their DTD markup declarations to XML Schema, to utilize XML Schema conformant datatypes. With it, DTD creators can specify datatypes for attribute values and data content, thereby providing the foundation for a smoother future transition path. NOTE: Free open-source code that supports this specification for both SAX and DOM is available at www.extensibility.com/dt4dtd." [And:] "XML 1.0, using DTDs, provides a strong foundation for validating the syntax of a document and ensuring that all the necessary pieces of information are present (i.e. necessary elements are included, inappropriate ones are not, attributes are supplied when required, etc.). DTDs do not, however, offer much help in constraining the value of a particular attribute or element: a.k.a. datatypes to those with programming backgrounds. DT4DTD brings this important capability to XML. Specifically it: (1) Provides compatibility with XML Schema data types; (2) Provides compatibility with XML-Data data types; (3) Provides programmatic extensions for DOM and SAX; (4) Provides an extensible architecture for custom datatypes; (5) Provides runtime support for data typed schemas created in XML Authority... The techniques specified in DT4DTD are already in commercial use in several places, including the Financial Products Markup Language from JPMorgan and PriceWaterhouseCoopers, and versions of the Common Business Library from Commerce One, among others. Design-time support for DT4DTD is also available in leading commercial schema design tools such as XML Authority, which is produced by this submitting member organization." See also the W3C staff comment from Dan Connolly, which reads (in part): "W3C is pleased to receive the DT4DTD submission from Extensibility. During this transitional period of the W3C XML Activity while the XML Schema Working Group develops and deploys their work, this submission provides a valuable mechanism for addressing the lack of data types such as integer, date, etc. in XML 1.0 DTD syntax in a way that is compatible with legacy systems. However, it relies on a global convention for the interpretation of the unqualified names e-dtype and a-dtype, while use of XML Namespaces would make this unnecessary..." Local archive copy: NOTE, W3C comment, acknowledgement. [December 01, 1999] Datatypes for DTDs. A draft specification residing on the Extensibility Web site (and looking suspiciously like a W3C 'NOTE') proposes a mechanism that allows the declaration of datatypes for XML content (PCDATA) and attributes. To wit: Datatypes for DTDs (DT4DTD) Version 1.0 (November 1999) is a 'Public Specification' edited by Lee Buck (Extensibility), Charles F. Goldfarb, and Paul Prescod (ISOGEN International). Initially posted as a public document: '10/31/99'. "Abstract: The presented specification allows legacy systems that may presently be unable to convert their DTD markup declarations to XML Schema, to utilize XML Schema conformant datatypes. With it, DTD creators can specify datatypes for attribute values and data content, thereby providing the foundation for a smoother future transition path... Free open-source code that supports this specification for both SAX and DOM is available at www.extensibility.com/dt4dtd." According to one of the authors, the specification represents just "a little convention for getting around the limitations of notations as applied to attributes and contents for datatyping." The markup facility uses NOTATIONs, and relies upon two 'fixed' attributes, e-dtype and a-dtype. Declaring a datatype for an element is permitted only if associated element type's content allows data but no sub-elements. The background: "XML 1.0, using DTDs, provides a strong foundation for validating the syntax of a document and ensuring that all the necessary pieces of information are present (i.e., necessary elements are included, inappropriate ones are not, attributes are supplied when required, etc.). DTDs do not, however, offer much help in constraining the value of a particular attribute or element: a.k.a. datatypes to those with programming backgrounds. DT4DTD brings this important capability to XML. Specifically it: (1) Provides compatibility with XML Schema data types; (2) Provides compatibility with XML-Data data types; (3) Provides programmatic extensions for DOM and SAX; (4) Provides an extensible architecture for custom datatypes; (5) Provides runtime support for data typed schemas created in XML Authority. The DT4DTD [package] consists of a two major parts: a) The draft specification, and b) The SDK [in Java]." Note:(?) similar datatype declaration mechanisms (appropriate for 'architecture-engine' and 'notation-engine' processing aka 'handwaving') are available in SGML, and particularly in Web SGML, where the added 'data specification declared value' allows arguments to be passed to notation processors. DT4DTD Draft Specification, October/November 1999 (local archive copy)
[February 24, 2000] A recent communiqué from Anders Møller reports on a new release of the Document Structure Description (DSD) specification in which free source code and Win32 executables are available for download. The Document Structure Description (DSD) is an "XML schema language developed by AT&T Labs Research and BRICS, University of Aarhus. DSDs require no specialized XML/SGML insights. The technology is based on simple, general, and familiar concepts that allow much stronger document descriptions than possible with DTDs or the current XML Schema proposal. DSD provides an alternative to XML DTDs and other XML schema languages. It adds expressive power, increases readability, and contains support for default attributes and contents. Furthermore, it guarantees linear time processing in the size of the application document. The relationship between DSDs and XML Schema is briefly described in a FAQ document." [November 19, 1999] Document Structure Description (DSD): An XML Schema Language. A communiqué from Nils Klarlund forwards an announcement for Document Structure Description (DSD) as "a new and very effective way of describing XML documents." According to the text of the announcement, "This new DSD schema language is result of a research collaboration between AT&T Labs, NJ and BRICS at the University of Aarhus, Denmark. The DSD 1.0 language has been designed by Nils Klarlund, Anders Møller, and Michael I. Schwartzbach. A prototype DSD processor has been implemented. It is freely available for experimentation and further development. The DSD language has arisen out of a need to describe XML documents to Web programmers with an elementary background in computer science. DSDs have also been expressively designed to further W3C sponsored XML technologies such as Cascading Style Sheets (CSS) and XSL Transformations (XSLT). CSS is an essential part of modern HTML, but has so far not been formulated as a general style sheet mechanism for XML that works with any semantic domain. DSDs provide both a generalized semantics for a CSS-like style sheet mechanism and document processing instructions that provide the abstraction benefits of CSS in any XML document. XSLT 1.0 is a programming notation that allows transformations of classes of XML documents into semantic domains like HTML. XSLT programs are easy to write, especially if assumptions can be made about the input documents. The expressive power of DSDs allow declarative and readable specifications of XML documents that are to be subjected to XSLT processing. DSDs require no specialized XML/SGML insights. The technology is based on general and familiar concepts that allow much stronger document descriptions than possible with DTDs or the current XML Schema proposal." The Web site references the DSD 1.0 specification, an overview article, and a DSD description of DSDs.
RELAX Core and TREX (Tree Regular Expressions for XML) are to be unified, since the two are very similar as structure-validation languages. The unified TREX/RELAX language is called RELAX NG [for "Relax Next Generation," pronounced "relaxing"]. This design work is now being conducted within the OASIS TREX Technical Committee, where a (first) specification is expected by July 1, 2001. The OASIS TC has also been renamed 'RELAX NG' [mailing list: '[email protected]'] to reflect the new name of the unified TREX/RELAX language. The RELAX NG development team plans to submit the OASIS specification to ISO, given the importance of ISO standards in Europe. See Minutes for RELAX NG TC 2001-05-17 and RELAX Core as ISO TR.
The Examplotron specification edited by Eric van der Vlist (Dyomedea) uses instance documents "as a lightweight schema language -- eventually adding the information needed to guide a validator in the sample documents. Examplotron may be used either as a validation language by itself, or to improve the generation of schemas expressed using other XML schema languages by providing more information to the schema translators. An XSLT transformation [in compile.xsl] transforms examplotron documents into XSLT sheets that validate 'similar' documents."
References:
Hook: A One-Element Language for Validation of XML Documents based on Partial Order. By Rick Jelliffe, Academia Sinica Computing Centre. "The Hook validation language is a thought experiment in minimalism in XML schema languages. The purpose of such a minimal language would be to provide useful but ultra-terse success/fail validation for basic incoming QA, especially of datagrams. It is like a checksum for a schema. The validation it performs can be characterized as "Does this element have a feasible name, ancestry, previous-siblings and contents?", there being some tradeoff between the how fully the later criteria are tested..." [cache]
[These references need reorganization - soon, I hope. -rcc]
[August 2005] "How Schema-Validity is Different from Being Married." By C. M. Sperberg-McQueen. Presented at Extreme Markup Languages 2005 (August 1 - 5, 2005, Best Western Europa-Downtown, Montréal, Québec, Canada). "Validation with some schema languages (e.g. XML 1.0 and SGML DTDs) is a black-or-white question: either the document is (wholly) valid or it's not valid (at all). There are no gray areas: a document cannot be 'mostly valid' any more than one can be 'a little bit married'. The theoretical information content of a validation result in these systems is thus exactly one bit: yes/valid or no/invalid. In practice good validators try to provide a little more information about errors, but quality of error diagnostics varies and error handling is not standardized. In other languages (e.g., XML Schema), validity assessment is designed to provide more than one binary digit of useful information. XML Schema allows various forms of partial validation: Validation can start at an element other than the root. Wildcards can specify that elements they match should not be validated but skipped (aka 'black-box processing' — the data must be well-formed XML, but don't look inside). And wildcards can specify 'lax' validation (matching elements must be well-formed XML, and if the schema has declarations for them, they'll be validated, but the absence of declarations doesn't make the container invalid). In XML Schema, schema-validity is captured by three properties: The first is [validation attempted]: Did we try to validate this item? Its values are full, none, partial. The second is [validity]: Is the element valid? It takes the values valid, invalid, notKnown. The third is [schema error code]: If the item is not valid, then a list of error codes (references to XML Schema validation rules) explaining why. This paper will talk about why it can be dangerous and unhelpful to reduce validity to a single bit of information, and how it can be helpful to take a richer view of validity as a property with several values, a property not just of the document as a whole but of each element and attribute in the document..." [September 07, 2005] "Change to the public schema document for the XML namespace (xml.xsd)." Posted by Henry S. Thompson to the 'public-xml-core-wg' list onbehalf of the W3C XML Core Working Group. The schema document at http://www.w3.org/2001/xml.xsd has changed, in order to (belatedly) track the change to xml:lang in XML 3rd edition, which now allows the empty string as well as a language code. Per the standard change policy, the old version is still available [at http://www.w3.org/2004/10/xml.xsd] and will not be changed. A copy of the new version which will never change is also available [at http://www.w3.org/2005/08/xml.xsd]. Send comments to [email protected]. [May 24, 2005] W3C Workshop to Address Improved Interoperability of Schema-Aware Software. W3C has issued a Call for Participation in connection with the June 21-22, 2005 "Workshop on XML Schema 1.0 User Experiences," to be held at the Oracle Conference Center in Redwood Shores, California. The deadline for submission of a user experience report has been extended through May 27, 2005. The purpose of this W3C Workshop is to "gather concrete reports of user experience with XML Schema 1.0, and examine the full range of usability, implementation, and interoperability problems around the specification and its test suite. Topics of discussion include, but are not limited to, the use of XML Schema in vocabulary design, Web Services description and toolkits, XHTML, XML Query, and XML Schema editors." The W3C XML Schema specification was released in a Second Edition Recommendation on October 28, 2004. This Second Edition incorporated the changes dictated by the corrections to errors found in the first edition, published as a W3C Recommendation on May 2, 2001. Since its approval as a W3C Recommendation, XML Schema 1.0 "has been widely adopted by vendors and as a foundation for other specifications in the Web Services area, in XML query systems, and elsewhere." The W3C Workshop on XML Schema 1.0 User Experiences will provide an opportunity for users to identify usability problems, to document the most serious interoperability problems users have experienced with schema-aware software, to design improvements to the XML Schema test suite, and to discuss future work to improve interoperability of schema-aware software. As with other W3C Workshops, this "Workshop on XML Schema 1.0 User Experiences" is open to the public, but will be limited to 60 attendees. Participants are required to submit a user experience report (by May 27, 2005); these papers will be included in the published proceedings of the Workshop. See the Workshop Program. [April 24, 2005] "WS-I Submission for the W3C Workshop on XML Schema 1.0 Specification User Experiences." By Erik Johnson (Epicor) for the Web Services Interoperability Organization (WS-I). Version: 1.0. "The Web Services Interoperability Organization (WS-I) herein offers a submission to the W3C Workshop on XML Schema 1.0 User Experiences. The WS-I appreciates this opportunity to contribute to the Workshop and looks forward to working with the W3C in fostering broad adoption of the XML Schema 1.0 Specification. Unlike other specifications relevant to web services, the WS-I had initially felt that there were no clear ambiguities or feature pathways of the W3C XML Schema 1.0 Specification 2nd Edition itself that merited development of a WS-I XML Schema profile. In fact, the WS-I Basic Profile 1.0 expressly allows the use of all W3C XML Schema 1.0 Specification constructs and types. In 2003 however, the WS-I commissioned a Working Group to study interoperability issues with XML Schema raised by WS-I Community members, specifically end-user organizations. The XML Schema Work Plan Working Group (WS-I SWPWG) was then chartered to produce a recommendation for possible further action to the WS-I Board. The WS-I SWPWG began work in November of 2004 to study the issue claims and define how the WS-I might in fact take action. This submission summarizes portions of the conversation and consensus from the work of the WS-I XML Schema Work Plan Working Group... It defeats the purpose of XML web services if developers creating or consuming services have to understand the toolkit and platform assumptions of their counterparts. So, toolkit support of XML Schema needs to be measured in the context of suitability to purpose. But there are many permutations of platform stacks, programming languages, and toolkits in use and the idea of suitability is clearly subjective. WS-I members have discussed these issues from two viewpoints: The first is the need for guidance and clarification of the W3C XML Schema 1.0 Specification, especially around best practices for extensibility, versioning, and type composition (modularity). The second is the need for a testing capability that covers XML Schema constructs found in real-world schemas (good, bad, and ugly) rather than academic coverage of XML Schema features..." For details on the workshop, see the news story "W3C Workshop to Address Improved Interoperability of Schema-Aware Software." [cache] [January 23, 2004] IBM and X-Hive Present XML Schema API as a W3C Member Submission. W3C has acknowledged receipt of a member submission entitled XML Schema API. The technology was submitted by from IBM Corporation and X-Hive Corporation B.V. and provides API access to properties of the XML Information Set. Specifically, the document "defines an XML Schema API, a platform- and language-neutral interface that allows programs and scripts to dynamically access and query the post-schema-validation infoset (PSVI) defined in the Normative Appendix C (Outcome Tabulations) of the W3C Recommendation XML Schema Part 1: Structures, "C.2 Contributions to the post-schema-validation infoset." The specification is implemented in Apache Xerces2 Java Parser; there is also a C++ binding and implementation for this specification in Apache Xerces C++ Parser." Section 1.2 defines interfaces which allow developers to access the XML Schema components which follow as a consequence of validation and/or assessment; Section 1.3 defines a set of interfaces for accessing the PSVI from an instance document; Section 1.4 defines a set of interfaces for loading XML Schema documents. The W3C Staff comment on the XML Schema API notes that the proposal "provides a substantial and useful addition to the DOM API, or to other existing event/pull parsing APIs such SAX/XNI. However, the XML Query and XSL Working Groups have been working on extending the work of XML Schema and adding more properties, and are working on a new version of XML Schema 1.1; therefore, while the proposal addresses today's needs, it should be noted that future extensions will still be needed to follow additions to the XML Architecture." [December 2003] "Using Finite State Automata to Implement W3C XML Schema Content Model Validation and Restriction Checking." By Henry S. Thompson and Richard Tobin (University of Edinburgh Division of Informatics Scotland). Presented at XML Europe 2003. "Implementing validation and restriction checking for W3C XML Schema content models is harder than for DTDs. This paper gives complete details on how to convert W3C XML Schema content models to Finite State Automata, including handling of numeric exponents and wildcards. Enforcing the Unique Particle Attribution constraint and implementing restriction checking in polynomial time using these FSAs is also described..." See also XSV (XML Schema Validator). [December 23, 2003] "XML and Information Integration: Conceptual Modeling of XML Schemas." By Bernadette Farias Lóscio, Ana Carolina Salgado, and Luciano do Rêgo Galvão (Centro de Informática, Universidade Federal de Pernambuco, Brasil). In Proceedings of the Fifth International Workshop on Web Information and Data Management (WIDM 2003) (November 7-8, 2003). "XML has become the standard format for representing structured and semi-structured data on the Web. To describe the structure and content of XML data, several XML schema languages have been proposed. Although being very useful for validating XML documents, an XML schema is not suitable for tasks requiring knowledge about the semantics of the represented data. For such tasks it is better to use a conceptual schema. This paper presents an extension of the Entity Relationship (ER) model, called X-Entity, for conceptual modeling of XML schemas. We also present the process of converting a schema, defined in the XML Schema language, to an X-Entity schema. The conversion process is based on a set of rules that consider element declarations and type definitions and generates the corresponding conceptual elements. Such representation provides a cleaner description for XML schemas by focusing only on semantically relevant concepts. The X-Entity model has been used in the context of a Web data integration system with the goal of providing a concise and semantic description for local schemas defined in XML Schema... The X-Entity representation provides a cleaner description for XML schemas hiding implementation details and focusing on semantically relevant concepts. The X-Entity model extends the ER model so that one can explicitly represent important features of XML schemas, including: element and subelement relationships, occurrence constraints of elements and attributes and choice groups. Due to space limitations, some X-Entity features were not presented in this paper. Other issues were not considered in our approach, including: hierarchy of elements and attributes, cardinality of group of elements, elements with mixed content and order of elements imposed by a sequence compositor. However, our model can be easily extended with additional features and new rules can be developed for the conversion process. We already implemented a prototype to generate XEntity schemas from XML Schemas..." [November 24, 2003] "An Introduction to Schematron." By Eddie Robertsson. From XML.com (November 12, 2003). "The Schematron schema language differs from most other XML schema languages in that it is a rule-based language that uses path expressions instead of grammars. This means that instead of creating a grammar for an XML document, a Schematron schema makes assertions applied to a specific context within the document. If the assertion fails, a diagnostic message that is supplied by the author of the schema can be displayed. One advantages of a rule-based approach is that in many cases modifying the wanted constraint written in plain English can easily create the Schematron rules. In order to implement the path expressions used in the rules in Schematron, XPath is used with various extensions provided by XSLT. Since the path expressions are built on top of XPath and XSLT, it is also trivial to implement Schematron using XSLT, which is shown later in the section Schematron processing. Schematron makes various assertions based on a specific context in a document. Both the assertions and the context make up two of the four layers in Schematron's fixed four-layer hierarchy: phases (top-level), patterns, rules (defines the context), and assertions... This introduction covers only three of these layers (patterns, rules and assertions); these are most important for using embedded Schematron rules in RELAX NG... Version 1.5 of Schematron was released in early 2001 and the next version is currently being developed as an ISO standard. The new version, ISO Schematron, will also be used as one of the validation engines in the DSDL (Document Schema Definition Languages) initiative..." See: "Schematron: XML Structure Validation Language Using Patterns in Trees." [August 05, 2003] "WDSL Tales From the Trenches, Part 3." By Johan Peeters. From O'Reilly WebServices.xml.com (August 05, 2003). ['Continuing the focus on sound design, we have the third and final installment of Johan Peeters' "WSDL Tales from the Trenches." Peeters concentrates on the importance of modeling the data elements involved in web services, and explains the best strategies for using W3C XML Schema to model this data.'] "I examine the type definitions and element declarations in the types element of a WSDL document. Such types and elements are for use in the abstract messages, the message elements in a WSD. WSDL does not constrain data definitions to W3C XML Schema (WXS). However, alternatives to WXS are not covered in this article: the goal of the series is to provide help and guidance with current real-world problems, and I have not seen any of the alternatives to WXS being used for web services on a significant scale to date. This may change in the future: while only the WXS implementation is discussed in the WSDL 1.1 spec, it was always the intention of the WSDL designers to provide several options. The WSDL 1.2 draft's appendix on Relax NG brings this closer to realization. Data modeling with WXS is not for the faint-hearted. It presents a lot of pitfalls. This article will point some of these out and helps you avoid them..." On WSDL 1.2, see the announcement "W3C Releases Three Web Services Description Language (WSDL) 1.2 Working Drafts." The non-normative Appendex E ('Examples of Specifications of Extension Elements for Alternative Schema Language Support') in the WSDL Part 1: Core WD includes a section on RELAX NG: "A RELAX NG schema may be used as the schema language for WSDL. It may be embedded or imported; import is preferred. A namespace must be specified; if an imported schema specifies one, then the [actual value] of the namespace attribute information item in the import element information item must match the specified namespace. RELAX NG provides both type and element definitions which appear in the {type definitions} and {element declarations} properties of [Section 2.1.1] 'Definitions Component' respectively..." [July 16, 2003] "Logic Grammars and XML Schema." By C. M. Sperberg-McQueen (World Wide Web Consortium / MIT Laboratory for Computer Science, Cambridge MA). Draft version of paper prepared for Extreme Markup Languages 2003, Montréal. "This document describes some possible applications of logic grammars to schema processing as described in the XML Schema specification. The term logic grammar is used to denote grammars written in logic-programming systems; the best known logic grammars are probably definite-clause grammars (DCGs), which are a built-in part of most Prolog systems. This paper works with definite-clause translation grammars (DCTGs), which employ a similar formalism but which more closely resemble attribute grammars as described by [D. Knuth, 'Semantics of Context-Free Languages,' 1968] and later writers; it is a bit easier to handle complex specifications with DCTGs than with DCGs. Both DCGs and DCTGs can be regarded as syntactic sugar for straight Prolog; before execution, both notations are translated into Prolog clauses in the usual notation... Any schema defines a set of trees, and can thus be modeled more or less plausibly by a grammar. Schemas defined using XML Schema 1.0 impose some constraints which are not conveniently represented by pure context-free grammars, and the process of schema-validity-assessment defined by the XML Schema 1.0 specification requires implementations to produce information that goes well beyond a yes/no answer to the question 'is this tree a member of the set?' For both of these reasons, it is convenient to use a form of attribute grammar to model a schema; logic grammars are a convenient choice. In [this] paper, I introduce some basic ideas for using logic grammars as a way of animating the XML Schema specification / modeling XML Schema... The paper attempts to make plausible the claim that a similar approach can be used with the XML Schema specification, in order to provide a runnable XML Schema processor with a very close tie to the wording of the XML Schema specification. Separate papers will report on an attempt to make good on the claim by building an XML Schema processor using this approach; this paper will focus on the rationale and basic ideas, omitting many details..." See also the abstract for the Extreme Markup paper [Tuesday, August 5, 2003]: "The XML Schema specification is dense and sometimes hard to follow; some have suggested it would be better to write specifications in formal, executable languages, so that questions could be answered just by running the spec. But programs are themselves often even harder to understand. Representing schemas as logic grammars offers a better approach: logic grammars can mirror the wording of the XML Schema specification, and at the same time provide a runnable implementation of it. Logic grammars are formal grammars written in logic-programming systems; in the implementation described here, logic grammars capture both the general rules of XML Schema and the specific rules of a particular schema." Note: the paper is described as an abbreviated version of "Notes on Logic Grammars and XML Schema: A Working Paper Prepared for the W3C XML Schema Working Group"; this latter document (work in progress 2003-07) provides "an introduction to definite-clause grammars and definite-clause translation grammars and to their use as a representation for schemas." [June 21, 2003] "Mobile Subset of XML Schema Part 2." ISO Document for information and review. Produced by SC34 Japan for ISO/IEC JTC 1/SC34/WG1: Information Technology -- Document Description and Processing Languages -- Information Presentation. Project 19757-5 (Project Editor, Martin Bryan). ISO Reference: ISO/IEC JTC 1/SC34 N 0410. April 22, 2003. Excerpts: "We propose to create a compact and reliable subset of W3C XML Schema Part 2 and publish it as an ISO standard. The main target of this subset is mobile devices (such as cellular phones). Mobile devices are expected to use XML in the near future. Small XML parsers have been developed already. Validators for schema languages are expected to follow, and a prototypical validator for RELAX NG on mobile phones has been developed. Such parsers and validators will hopefully be used for implementing XForms and Web Service on mobile devices. Part 2 of W3C XML Schema provides a set of datatypes and facets. Although it might not be perfect, it is likely to be widely used by many XML applications including mobile applications. We just cannot believe that an incompatible set of general-purpose datatype (e.g., int) libraries will be accepted by the market. However, datatypes and facets of W3C XML Schema Part 2 are too complicated for mobile devices. Some specifications such as XForms have already created their own subsets of W3C XML Schema Part 2. However, if different specifications introduce different subsets, incomparability will be significantly spoiled. It would be much nicer if one subset is internationally standardized... [In the] choice of datatypes we omit: (1) datatypes requiring infinite precision; (2) datatypes that do not have obvious mapping to J2ME; (3) archaic datatypes such as IDREFS, ENTITY, ENTITIES, and NOTATION; (4) unsolid datatypes -- dateTime and so forth; (5) datatypes such that validity depends on namespace declarations... [In the] choice of facets we omit: [1] the pattern facet, which requires the property list of Unicode characters; [2] whitespace, which does not affect validity but controls PSVI; [3] totalDigits and fractionDigits. Implementation considerations: We have studied the source code of Jing implementation by James Clark. We believe that if the above restrictions are accepted, an implementation of the remaining datatypes and facets will require less than 20KB as the size of a JAR file." See details for the proposed list of datatypes and factes in 'Table 1: The list of datatypes' and 'Table 2: The list of facets'. [cache] [June 19, 2003] Namespace Routing Language (NRL) Supports Multiple Independent Namespaces. James Clark has announced the publication of a Namespace Routing Language (NRL) specification. NRL is "an XML language for combining schemas for multiple namespaces; it allow the schemas that it combines to use arbitrary schema languages." The release includes a tutorial and specification document and a sample implementation in the Jing (RELAX NG Validator in Java) distribution. NRL "is the successor to Clark's Modular Namespaces (MNS) language and is intended to be another step on the path towards Document Schema Definition Languages (DSDL) Part 4." The W3C XML Namespaces Recommendation itself "allows an XML document to be composed of elements and attributes from multiple independent namespaces: each of these namespaces may have its own schema and the schemas for different namespaces may be in different schema languages. The problem then arises of how the schemas can be composed in order to allow validation of the complete document." The Namespace Routing Language attempts to solve this problem. Among the features and benefits of NRL: it supports schema language coexistence, allows extension of schemas not designed to be extended, makes authoring of extensible schemas easier supports 'transparent' namespaces, allows contextual control of extension, and allows concurrent validation. "For RELAX NG, it can be used to provide some of the namespace-based modularity features that are built-in to XSD. NRL is designed to allow an implementation to stream, and the sample implementation does so. The sample implementation has a SAX-based plug-in architecture that allows new schema languages to be added dynamically. It comes with support for RELAX NG (both XML and compact syntax), W3C XML Schema (via a wrapper around Xerces-J), Schematron, and (recursively) NRL; it can also use any schema language with an implementation that supports the JARV interface." [June 10, 2003] "Introducing Examplotron: The Fastest Road to Schema." By Uche Ogbuji (Principal Consultant, Fourthought, Inc). From IBM developerWorks, XML zone. June 10, 2003. ['A zoo of XML schema languages is out there, and although some of the beasts are bigger than others none is as friendly as Examplotron. With Examplotron, your example XML document is your schema, for the most part. It requires you to learn very little new syntax, and most of the core features of XML can be specified by providing representative examples in the source. In this article, Uche Ogbuji introduces Examplotron, providing plenty of examples.'] "At first XML had the Document Type Definition (DTD). XML 1.0 came bundled with the schema technology inherited from SGML. However, numerous XML users complained about DTDs including the fact that they use a different syntax from XML itself. The W3C developed a successor technology to DTD, W3C XML Schema, but some complained that it was too complex, and that it showed every sign of design-by-committee. Separate groups developed schema technologies that became RELAX NG and Schematron. These technologies all have their strengths and weaknesses, and their attendant factions. But for the developer with deadlines to mind, crafting schemata is often too much of an additional burden. Without a doubt, it is always a good idea to develop a schema. If for no other reason, it provides documentation of the format. But in the real world, the most common course for harassed developers is to develop a sample of the XML format to serve all purposes of a proper schema. But what if the example itself could provide the benefits of a formal schema? In particular, what if the example could be used to validate documents? Eric van der Vlist set out to develop a system that allows example documents to serve as formal schemata, and his invention is Examplotron. In this article, I introduce Examplotron. This system is simple to use, so I encourage you to follow along by downloading Examplotron 0.7 (compile.xsl) and use your favorite XSLT and RELAX NG processors... On a recent project, a client who had many XML formats hired me, through my company Fourthought, to develop schemata for documentation and validation for these XML formats. All they had to start with were sample XML documents for each format. Using Examplotron to generate the production RELAX NG schemata from these sample documents saved me perhaps over a hundred hours of effort, and thus saved them tens of thousands of dollars. I did have to augment Examplotron with document generation and other refinement code; I hope to cover the non-proprietary aspects of this refinement code in a future article. Examplotron produces RELAX NG schemata, but if you must produce W3C XML Schema, all is still well: You can use James Clark's excellent Trang tool to convert RELAX NG to WXS. I know from my overall consulting experience that sample documents are the most common form of schema in the real world, so I expect that Examplotron will be of great help to a lot of folks right away." See Examplotron above. [April 30, 2003] "Clean Up Your Schema for SOAP. Updating XML Schemas to be SOAP-Friendly." By Shane Curcuru (Advisory Software Engineer, IBM Research). From IBM developerWorks, Web services. April 29, 2003. ['More and more projects are using XML schemas to define the structure of their data. As your repository of schemas grows, you need tools to manipulate and manage your schemas. The Eclipse XSD Schema Infoset Model has powerful querying and editing capabilities. In this article, Shane Curcuru will show how you can update a schema for use with SOAP by automatically converting attribute uses into element declarations.'] "If you've built a library of schemas, you might want to reuse them for new applications. If you already have a data model for an internal purchase order, as you move towards Web services you may need to update it for use with SOAP. SOAP allows you to transport an xml message across a network; the xml body can also be constrained with a schema. However a SOAP message typically uses element data for its xml body, not attribute data. You'll explore a program that can automatically update an existing schema document to convert any attribute declaration into roughly 'equivalent' element declarations... Given the complexity of XML schemas, you certainly don't want to use Notepad to edit the .xsd files. A good XML editor is not much of a step up -- while it may organize your elements and attributes nicely, it can't show the many abstract Infoset relationships that are defined in the Schema specification. That's where the Schema Infoset Model comes in; it expresses both the concrete DOM representation of a set of schema documents, and the full abstract Infoset model of a schema. Both of these representations are shown through the programmatic API of the Model as well as in the Model's built-in sample editor for schemas... If you've installed the XSD Schema Infoset Model and Eclipse Modeling Framework (EMF) plugins into Eclipse, you can see the sample editor at work in your Workbench... performing a conceptually simple editing operation on schema documents (turning attributes into elements) can entail a fair amount of work. However the power of the Schema Infoset Model's representation of both the abstract Infoset of a schema and its concrete representation of the schema documents makes this a manageable task. The Model also includes simple tools for loading and saving schema documents to a variety of sources, making it a complete solution for managing your schema repository programmatically. Some users might ask, 'Why not use XSLT or another XML-aware application to edit schema documents?' While XSLT can easily process the concrete model of a set of schema documents, it can't easily see any of the abstract relationships within the overall schema that they represent. For example, suppose that you need to update any enumerated simpleTypes to include a new UNK enumeration value meaning unknown. Of course, you only want to update enumerations that fit this format of using strings of length of three; you would not want to update numeric or other enumerations... This article presupposes an understanding of schemas in XML and how SOAP works. The sample code included in the zip file works standalone or in an Eclipse workbench..." [March 24, 2003] Schema Unit Test (SUT) Framework for Testing XML Schema. Gavin Kingsley (Invensys Energy Systems Limited) announced the availability of a SourceForge project Schema Unit Test (SUT) which introduces a framework for testing XML Schema. SUT incorporates the Schematron reference implementation developed by Rick Jelliffe of the Academia Sinica Computing Centre. Problem statement: "W3C Schema can quickly become complex and difficult to determine if they are validating the correct vocabulary. The addition of embedded Schematron schema only makes this problem worse... The SUT framework has two parts. The first is a namespace and vocabulary for embedding test cases into sample XML documents, designed to highlight what is legal and what is not legal in the vocabulary defined in the schema under test. This aspect is independent of what schema language is used and can in theory be applied to any schema language with automatic validation tools. The second part is a Java implementation using JUnit for testing a W3C Schema with embedded Schematron schema. This implementation reads SUT test suite descriptions written in XML with embedded test cases and then creates a JUnit test suite that can be executed inside JUnit in the usual way. Although SUT is written to use JUnit, no specialise Java or JUnit knowledge is required to run SUT test suites. An example is provided based on the purchase order schema from the W3C primer... A SUT Test Suite is a well-formed XML file containing an example of a file to be validated. Test cases are identified by additional elements in the SUT namespace, http://www.powerware.com/nz/XMLSchemaUnitTest. The case element identifies test cases created by adding or removing elements. The attribute element identifies test cases created by adding, removing or changing attributes; detailed descriptions of these elements are available (case; attribute)." SUT has free, open source code. [February 21, 2003] "Mapping Between UML and XSD." By David Carlson (Ontogenics Corp). From XMLmodeling News Volume One, Issue Two (January 28, 2003). "One of the principal advantages of using UML when designing XML vocabularies is that the model can serve as a specification which is independent of a particular schema language implementation. W3C XML Schema is the most common choice right now, but we hope that business vocabularies (and other non-business technical markup languages) have a long life and will be implemented using alternative new schema languages. To achieve this goal, we need to define a complete and flexible mapping between UML and each implementation language. Given that UML was originally intended for object-oriented analysis and design, the mapping is most straightforward for languages that have an object-oriented flavor... A bi-directional mapping between UML and schemas is specified in the form of a UML Profile. The purpose of a UML profile for this or any other use is to extend the UML modeling language with constructs unique to an implementation language, analysis method, or application domain. The profile extension mechanism is part of the UML standard; it was expanded in the recent UML version 1.4 and will be further expanded when UML 2.0 is adopted this year. A UML profile (pre version 2.0) is composed of three constructs: stereotypes, tagged value properties, and constraints. A stereotype defines a specialized kind of UML element; for example, the XSDcomplexType stereotype defines a specialized kind of UML Class, and XSDschema defines a specialized kind of UML package. Tagged values define properties of these stereotyped elements. So the XSDschema stereotype includes a targetNamespace property. By assigning this stereotype to a UML package and setting a value for this property, we have augmented the UML modeling language with information used to generate a complete XML Schema document from an abstract vocabulary model. Similar stereotypes and properties are defined for all XML Schema constructs. A profile constraint specifies rules about how and where stereotypes and their tagged values can be used in a model. These rules should include what are often called co-constraints: how the value of one property constrains the values of other properties..." [January 23, 2003] Trang Multi-Format Schema Converter Supports DTD to W3C XML Schema Conversion. A posting from James Clark to the XML-DEV List announces a new release of Trang, Clark's Multi-Format Schema Converter based on RELAX NG. The conversion tool supports several schema languages for XML, including RELAX NG (XML syntax), RELAX NG compact syntax, XML 1.0 DTDs, W3C XML Schema. With one exception, Trang will convert between any of these formats (W3C XML Schema is supported for output only, not for input). "Trang is written in Java, and available under a BSD-style license. In this release, [Clark has] added an input module for DTDs based on his DTDinst program; this implies that Trang can now convert directly from DTDs to W3C XML Schema (XSD)." Clark identifies three unique features of Trang: "(1) it can reliably turn parameter entities into the higher-level semantic constructs available in XSD (simple types, groups, attribute groups) -- even in the presence of arbitrarily deep nesting of parameter entity references within parameter entity declarations; (2) it supports namespaces, including DTDs that mix multiple namespaces; (3) it can create good-quality, idiomatic XSD, which takes advantage of features such as substitution groups." [January 22, 2003] "Altova Simplifies XML Development Through Enhanced Support for Microsoft .NET, Oracle XML DB, Web Services and Document Publishing in XMLSPY 5 Release. New features further demonstrate XMLSPY 5 is the most comprehensive XML development environment for any XML-enabled software project." - "Altova Inc., producer of XMLSPY, the world's leading XML development tool with over a million registered users, today announced the availability of XMLSPY 5 Release 3. Presently, XML technologies today are being applied to solve a wide spectrum of enterprise computing challenges, including electronic commerce, document publishing, database integration, and web services applications. To maximize software developer productivity in implementing any XML-enabled solution, Altova has added enhanced developer support for various widely used enterprise technologies, thereby accelerating and simplifying XML development. The new version of XMLSPY is available immediately for free trial download. To meet the needs of enterprise developers, XMLSPY 5 builds on the success of previous award winning versions through the addition of several key new features: (1) Improved Support for building Microsoft .NET applications: The XMLSPY 5 Code Generator now supports Microsoft C# code generation to accelerate application development on the Microsoft .NET platform. Use XMLSPY to Model data elements in XML Schema, then XMLSPY can auto-generate C# class (data bindings) corresponding to elements defined in the data model. The generated code uses System.XML, the new Microsoft .NET Application Program Interface (API) for programmatically accessing XML documents. (2) Enhanced support for Oracle XML DB. XMLSPY's new features enable developers to easily perform common operations on data managed by XML DB including: List XML Schemas, Load a Schema from a list, Save New or Delete XML Schema to Oracle XML DB, Register an XML Schema with Oracle XML DB, Execute Query using Oracle9i's DBURI, Browse, Open, Edit and Save XML documents stored in Oracle XML DB via WebDAV. (3) Additional Web Services Support: A new Web Service Description Language (WSDL) Documentation generation utility makes it easier for a Web service developer to document and publish a Web service's interface to business partners, other developers, or to the public. (4) PDF support for Document Publishing: XMLSPY's stylesheet designer now supports visual editing and generation of eXtensible Stylesheet Language Formatting Object (XSL:FO) code, which enables XML content to be rendered into a PDF file. Now, with a single stylesheet design, developers can preview the output of a stylesheet transformation in either PDF or HTML. (5) Usability Enhancements for Stylesheet Designer: Improved drag/drop functionality in Stylesheet Designer. (6) New Java Integration Support: A new Java API enables easier customization and integration of the XMLSPY development environment for system integrators or Java-based product companies wanting to extend the functionality of XMLSPY. Now, programmers can control and use XMLSPY functionality from their Java-based programs. XMLSPY already supports integration via a COM based interface..." [January 21, 2003] "Requirements for XML Schema 1.1." Edited by Charles Campbell, Ashok Malhotra (Microsoft), and Priscilla Walmsley. W3C Working Draft 21-January-2003. Version URL: http://www.w3.org/TR/2003/WD-xmlschema-11-req-20030121/. Latest version URL: http://www.w3.org/TR/xmlschema-11-req/. "This document contains a list of requirements and desiderata for version 1.1 of XML Schema... Since the XML Schema Recommendation (Part 0: Primer, Part 1: Structures, and Part 2: Datatypes) was first published in May, 2001, it has gained acceptance as the primary technology for specifying and constraining the structure of XML documents. Users have employed XML Schema for a wide variety of purposes in many, many different situations. In doing so, they have uncovered some errors and requested some clarifications. They have also requested additional functionality. Most of the errors and clarifications are addressed in the published errata and will be integrated into XML Schema 1.0 Second Edition, to be published shortly. Additional functionality and any remaining errors and clarifications will be addressed in XML Schema 1.1 and XML Schema 2.0. This document discusses the requirements for version 1.1 of XML Schema. These issues have been collected from e-mail lists and minutes of telcons and meetings, as well as from the various issues lists that the XML Schema Working Group has created during its lifetime. Links are provided for further information. The items in this document are divided into three categories: (1) A requirement must be met in XML Schema 1.1; (2) A desideratum should be met in XML Schema 1.1; (3) An opportunistic desideratum may be met in XML Schema 1.1..." [January 17, 2003] "From Model to Markup: XML Representation of Product Data." By Joshua Lubell (US National Institute of Standards and Technology, Manufacturing Systems Integration Division). Paper presented December 2002 at the XML 2002 Conference, Baltimore, MD, USA. With Appendix (Complete PDM Example with EXPRESS Schema, RELAX NG Schema [Compact Syntax], RELAX NG Schema [XML Syntax], W3C XML Schema, Flat XML Data, Hierarchical XML Data). "Business-to-consumer and business-to-business applications based on the Extensible Markup Language (XML) tend to lack a rigorous description of product data, the information generated about a product during its design, manufacture, use, maintenance, and disposal. ISO 10303 defines a robust and time-tested methodology for describing product data throughout the lifecycle of the product. I discuss some of the issues that arise in designing an XML exchange mechanism for product data and compare different XML implementation methods currently being developed for STEP... ISO 10303, also informally known as the Standard for the Exchange of Product model data (STEP), is a family of standards defining a robust and time-tested methodology for describing product data throughout the lifecycle of the product. STEP is widely used in Computer Aided Design (CAD) and Product Data Management (PDM) systems. Major aerospace and automotive companies have proven the value of STEP through production implementations. But STEP is not an XML vocabulary. Product data models in STEP are specified in EXPRESS (ISO 10303-11), a modeling language combining ideas from the entity-attribute-relationship family of modeling languages with object modeling concepts. To take advantage of XML's popularity and flexibility, and to accelerate STEP's adoption and deployment, the ISO group responsible for STEP is developing methods for mapping EXPRESS schemas and data to XML. The rest of this paper discusses some of the issues that arise in designing an XML exchange mechanism for product data. It also compares two implementation approaches: a direct mapping from EXPRESS to XML syntax rules, and an indirect mapping by way of the Unified Modeling Language (UML)... Observations: Developers of mappings from product data models to XML have learned some valuable lessons. The most important lesson is that, although XML makes for an excellent data exchange syntax, XML is not well suited for information modeling. After all, if XML were a good modeling language, it would be much easier to develop a robust mapping from EXPRESS to XML. UML, on the other hand, is a good modeling language and, therefore, it should be easier to map EXPRESS to UML than to XML. Although mapping EXPRESS to UML does not make the difficulties of representing product models in XML go away, it offloads a significant part of the effort from the small and resource-strapped STEP developer community to the much larger and resource-rich UML developer community. Another lesson learned is that the choice of XML schema language used in the mapping is not very important, as long as the schema language supports context-sensitive element types and provides a library of simple data types for items such as real numbers, integers, Booleans, enumeration types, and so on. Therefore, both the W3C XML Schema definition language and RELAX NG are good XML schema language choices. The DTD is a poor schema language choice for the reasons discussed earlier..." See Lubell's RELAX NG List Note of 2003-01-17: "Although David Carlson's "Modeling XML Applications with UML" (Addison Wesley) mentions WXS but not RELAX NG, his hyperModel tool can generate both WXS and RELAX NG schemas from XMI. Carlson used to have a web-accessible form where you could upload an XMI file and process it using hyperModel, but the website wasn't working the last time I tried to use it. He has also implemented hyperModel as a plug-in to Eclipse and is selling this as a commercial product. I haven't come across any documentation for Carlson's UML-to-RELAX NG mapping. The RELAX NG in my XML 2002 paper "From Model to Markup" was created using the web-accessible hyperModel tool, although I had to tweak the output in order to handle bidirectional UML associations and to use interleave properly..." See: "Conceptual Modeling and Markup Languages." [January 17, 2003] "Transforming XML Schemas." By Eric Gropp. From XML.com. January 15, 2003. ['Eric Gropp shows how XSLT can be used to transform W3C XML Schemas to create, among other things, HTML input forms, generate query interfaces, and documentation of data structures and interfaces.'] A W3C XML Schema (WXS) document contains valuable information that can be used throughout a system or application, but the complexity that WXS allows can make this difficult in practice. XSLT, however, can concisely and efficiently manipulate WXS documents in order to perform a number of tasks, including creating HTML input forms, generating query interfaces, documenting data structures and interfaces, and controlling a variety of user interface elements. As an example, this article describes an XSLT document which creates an XHTML form based on the WXS definition of a complex element. For brevity and clarity, the article omits several WXS and XHTML form aspects, including attribute definitions, keys, imported/included schemas, and qualified name issues. How these additional features are implemented can depend greatly on your use of WXS and on your application. However, building a stylesheet that handles every possible WXS feature can be quite an effort and may often be unnecessary. Much of the information -- occurrence constraints, data types, special restrictions, and enumerations -- needed to build an XHTML form is already contained in a WXS document. Missing bits such as label text and write restrictions can be added into WXS's <annotation> element. The stylesheet will perform four distinct tasks: (1) Find the definition of the target complex element that we want; (2) Build a form element for the target element; (3) Find the definitions of the target element's valid children; (4) Build an input element for each of the simple child elements. In order to do this, the stylesheet will apply different template rules to similar WXS elements depending on the task at hand. To make this possible, the stylesheet will use a separate mode for each task... This article will preface the description of a set of template rules with a model that is based on UML Activity Diagrams. In these diagrams template rules are shown as states; modes are shown as composite states... Using WXS as the common resource for data typing in your application can have big payoffs. By allowing components and interfaces to automatically reflect changes to an application's data model, you can greatly increase the reusability and flexibility of a system. XSLT is a useful, largely platform-independent, and highly portable tool for making this possible." See also XML Schema: The W3C's Object-Oriented Descriptions for XML, by Eric van der Vlist. [January 10, 2003] W3C Working Draft Specification for XML Schema Component Designators. The W3C XML Schema Working Group has released an initial working draft for XML Schema: Component Designators. The specification defines a system for designating XML Schema components. The document addresses a range of problematic issues in the use of a QName to designate schema components as defined in the W3C XML Schema Recommendation. "The schema-as-a-whole schema component may represent the amalgamation of several distinct schema documents, or none at all. It may be associated with any number of target namespaces, including none at all. It may have been obtained for a particular schema assessment episode by deferencing URIs given in schemaLocation attributes, or by an association with the target namespace or by some other application-specific means. In short, there are substantial technical challenges to defining a reliable designator for the schema-as-a-whole, particularly if that designator is expected to serve as a starting point for the other components encompassed by that schema. The editors propose to divide the problem of constructing schema component designators into two parts: defining a designator for an assembled schema, and defining a designator for a schema component, understood relative to a designated schema." [December 26, 2002] "A Data Model for Strongly Typed XML." By Dare Obasanjo. From XML.com. December 18, 2002. ['Dare Obasanjo has been searching for an appropriate data model for typed XML. In his article he examines the Post Schema-Validation Infoset, but settles on the XPath/XQuery data model as the best candidate for applications that want to use a strongly typed data model for XML.'] "In many XML applications, the producers and consumers of XML documents are aware of the datatypes within those documents. Such applications can benefit from manipulating XML via a data model that presents a strongly typed view of the document. Although a number of abstractions exist for manipulating XML -- the XML DOM, XML infoset, and XPath data model -- none of these views of XML take into account usage scenarios involving strongly typed XML. Many developers utilize XML in situations where type information is known at design or compile time, including interacting with relational databases and strongly typed programming languages like Java and C#. Thus, there is a significant proportion of the XML developer community which would benefit from a data model that encouraged looking at XML as typed data. This article is about my search for and discovery of this data model. The W3C XML Information Set recommendation describes an abstract representation of an XML document. The XML Infoset is primarily meant to act as a set of definitions used by XML technologies to formally describe what parts of an XML document they operate on. Several W3C XML technologies are described in terms of the XML Infoset, including SOAP 1.2, XML Schema, and XQuery. An XML document's information set consists of a number of information items. An information item is an abstract representation of a component of an XML document: such as an element, attribute or processing instruction. Each information item has a set of associated named properties. Each property is either a collection of related information items or data about the information item; the [children] property of an element information item is an example of the former, while the [base URI] of a document information item is an example of the latter. An XML document's information set must contain a document information item from which all other information items belonging to the document can be accessed. The XML Infoset is a tree-based hierarchical representation of an XML document... The XQuery and XPath 2.0 Data Model is still a working draft; some of its details may change before it becomes a W3C recommendation. However, the core ideas behind the data model which this article explores are unlikely to change. This article is based on the November 15th draft of the working draft. The XQuery and XPath 2.0 data model presents itself as a viable data model for processing XML in strongly typed usage scenarios. The loose coupling to the W3C XML Schema type system is especially beneficial because it both provides an interoperable set of types, yet does not limit one to solely those types. The XQuery and XPath 2.0 data model stands out as the most credible data model for dealing with XML in strongly typed scenarios. Given that the XQuery and XPath 2.0 data is based on the XML Infoset, and also builds upon the past experience with XPath 1.0, it's the best candidate for the Data Model for XML..." [December 12, 2002] "Datatypes for XML Topic Maps (XTM): Using XML Schema Datatypes." By Murray Altheim (Knowledge Media Institute, The Open University, Milton Keynes, Bucks, UK). Draft version 1.4 2002/12/12. Topic map available in XML format, also zipped. Reference posted to the OASIS Topic Maps Published Subjects Technical Committee list. Abstract: "The W3C Recommendation XML Schema Part 2: Datatypes ('XSD') provides a specification of datatypes and their facets, and forms the semantic basis of this document, which establishes Published Subject Indicators (PSIs) for each XML Schema datatype and facet. A PSI is a (relatively) stable URL used as a canonical identifier for a subject, particularly within an XML Topic Map (XTM) document, though application of PSIs is not limited to XTM. This document does not alter any XML Schema datatype definition; for definitions of each datatype..." Author's note: "I'm pleased to announce a first draft of something that's been in the works for over a year... The ability to constrain or 'type' topic characteristics is something necessary within the topic map community. Constraints on topic map structures may be provided by various forms of schema facilities, such as TMCL, but a simple datatyping feature is still something sorely missing. There are some examples provided in the document... I welcome comments or suggestions towards establishing 'best practices' for use of these PSIs, as well as comments on the structures within the provided topic map. I am willing to add visualizations of various parts of the topic map if that is considered helpful." The purpose of the Topic Maps Published Subjects Technical Committee is "to promote the use of Published Subjects by specifying requirements, recommendations, and best practices, for their definition, management and use. Public Subject was defined by ISO 13250 Topic Maps standard and further refined as Published Subject in the XML Topic Maps (XTM) 1.0 Specification." See: "(XML) Topic Maps." [November 30, 2002] "Modeling Biz Docs in XML." By Jon Udell. In InfoWorld (November 29, 2002). ['Unlocking Office 11's XML features means coming to grips with its data definition language, XML Schema. That won't be easy, but the sooner we start, the better. The future of Web services depends on our ability to model business documents in XML. Yes, XML Schema is complex, but some of the issues are more general. Even experts disagree on the best practices for object-oriented data modeling. Office 11 creates an environment in which we can start to codify those best practices as they apply to ordinary business documents.'] "The good news is that Office 11 supports XML Schema. The bad news is that XML Schema has been described even by XML experts as 'confusing,' 'impenetrable,' 'fuzzy,' and 'as user-friendly as a stick in the eye.' A successor to the SGML/XML DTD (Standard Generalized Markup Language/XML document type definition), XML Schema is a language for writing rules that constrain the kinds of elements that can appear in documents and the ways in which they can be sequenced, grouped, and nested. XML Schema is still a relatively new specification. The W3C Recommendation for XML Schema was published in May 2001. XML parsers that support XML Schema haven't done so for very long, and there is not yet much experience using it. Most people who are adept at defining document structure learned how to do so by writing DTDs. Some of the allergic reaction to XML Schema can, therefore, be chalked up to normal reluctance to learn new skills... Upgrading the word processors and spreadsheets on those government computers to versions that not only can read and write XML, but, more crucially, can enforce rules about datatypes and structures, is part of the solution. Assuming, of course, that such rules can be written, deployed, and unobtrusively applied and maintained over time. 'Therein,' observes Windley, 'lies the rub.' There is very little extant knowledge about how to model unstructured and semistructured data in XML. Unlike SGML, the XML DTD was always optional, because the framers of XML knew there was enormous value in documents that were merely well-formed, even if not valid with respect to a DTD. RSS (Rich Site Summary), for example, the wildly popular XML format for content syndication, has no DTD or schema... One possibility is to infer schemas from example documents. Tools can do this, but so far, not with much sophistication. Microsoft, for example, offers a .Net namespace (Microsoft.XsdInference) that will infer a schema from an XML document, and even refine that schema based on further examples. The results make a useful starting point, and inferencing is a promising technology that can and should evolve, but the fact is that modeling XML data is a complex subject that even the best human experts have yet to codify. XML Schema delivers a much richer set of modeling tools than were available to DTD authors. Learning to use them well is going to be a challenge..." See also "Microsoft Office 11 and XDocs." [November 26, 2002] "XML Spy Tops as XML Editor." By Timothy Dyck. In eWEEK (November 25, 2002). "Altova GMBH's XML Spy has long been a strong player in the XML space, and Version 5 of the XML editor raises the bar even higher. Of all the XML editors eWEEK Labs has seen -- and we've seen a lot -- the $990 XML Spy 5.0 Enterprise Edition provides the best overall combination of editing power and usability, along with wide database and programming language integration support. This earns the product an eWEEK Labs Analyst's Choice award. XML Spy's user interface -- particularly its graphical schema editing tools and grid-based XML data editor -- keeps impressing us with its versatility, intuitiveness and power. For quick, ad hoc XML transformations, such as converting a series of attributes into elements, XML Spy is a perfect tool. The Enterprise Edition of XML Spy is new to the product line. It includes cutting-edge HTML-to-XML conversion capabilities; Java and C++ code generation; and Web services features, including a Simple Object Access Protocol debugger and a graphical WSDL (Web Services Description Language) file editor. The $399 Professional Edition of XML Spy does not have these features but does include the XML and XML Schema editing features, database import and export capabilities, and the XSLT (Extensible Stylesheet Language Transformations) debugger found in 5.0... The XSLT debugger in the new XML Spy line is important not only because it will be highly useful to developers, but also because it was one feature the competition had that XML Spy didn't. Excelon Corp.'s Stylus Studio 4.5, for example, has a very effective XSLT debugger... Also significant in XML Spy 5.0 is a new feature that helps automate the conversion of an HTML-based site to one that is based on XML technologies. XML Spy accomplishes this by transforming XML source data through Extensible Stylesheet Language into HTML... Plus: HTML-to-XML conversion capabilities; XSLT processor and debugger; graphical WSDL editor; Java and C++ code generators for XML data structures; Web services debugger; powerful XML editing features. Minus: Lacks support for DB2 and Sybase Adaptive Server Enterprise XML database extensions." [November 22, 2002] "W3C XML Schema Design Patterns: Avoiding Complexity." By Dare Obasanjo. From XML.com. November 20, 2002. ['A year or so ago XML.com published an article called "W3C XML Schema Made Simple," which suggested, somewhat controversially, that you should avoid areas of the W3C XML Schema specification in order to keep things manageable. This week our main feature is both a companion piece and counterpoint to the "Made Simple" article. In "W3C XML Schema Design Patterns: Avoiding Complexity" Dare Obasanjo suggests that most of W3C XML Schema is indeed useful, but highlights areas the schema author should handle with care.'] "Over the course of the past year, during which I've worked closely with W3C XML Schema (WXS), I've observed many schema authors struggle with various aspects of the language. Given the size and relative complexity of the WXS [W3C XML Schema] recommendation, it seems that many schema authors would be best served by understanding and utilizing an effective subset instead of attempting to comprehend all of its esoterica. There have been a few public attempts to define an effective subset of W3C XML Schema for general usage, most notable have been W3C XML Schema Made Simple by Kohsuke Kawaguchi and the X12 Reference Model for XML Design by the Accredited Standards Committee (ASC) X12. However, both documents are extremely conservative and advise against useful features of WXS without adequately describing the cost of doing so. This article is primarily a counterpoint to Kohsuke's and considers each of his original guidelines; the goal is to provide a set of solid guidelines about what you should do and shouldn't do when working with WXS... The Guidelines: I've altered some of Kohsuke's original guidelines [...] I propose some additional guidelines as well: Do favor key/keyref/unique over ID/IDREF for identity constraints; Do not use default or fixed values especially for types of xs:QName; Do not use type or group redefinition; Do use restriction and extension of simple types; Do use extension of complex types; Do carefully use restriction of complex types; Do carefully use abstract types; Do use elementFormDefault set to qualified and attributeFormDefault set to unqualified; Do use wildcards to provide well defined points of extensibility... The WXS recommendation is a complex specification because it attempts to solve complex problems. One can reduce its burdens by utilizing its simpler aspects. Schema authors should ensure that their schemas validate in multiple schema processors. Schemas are an important facilitator of interoperability. It's foolish to depend on the nuances of a specific implementation and inadvertently give up this interoperability..." [November 15, 2002] "Normalizing XML, Part 1." By Will Provost. From XML.com. November 13, 2002. ['Will Provost's Schema Clinic series on XML.com has so far taken an object-oriented view of W3C XML Schema design. This month, Will has written the first of a two-part series that examines the relational aspects of schema design. The series examines guidelines that achieve the goal of normalization -- the principles guiding database design -- using the mechanisms provided by W3C XML Schema.'] "The goal is to see what relational concepts we can usefully apply to XML. Can the normal forms that guide database design be applied meaningfully to XML document design? Note that we're not talking about mapping relational data to XML. Instead, we assume that XML is the native language for data expression, and attempt to apply the concepts of normalization to schema design. The discussion is organized loosely around the progression of normal forms, first to fifth. As we'll see, these forms won't apply precisely to XML, but we can adhere to the law's spirit, if not its letter. It's possible to develop guidelines for designing W3C XML Schema (WXS) that achieve the goals of normalization: (1) Eliminate ambiguity in data expression; (2) Minimize redundancy -- some would say, 'eliminate all redundancy'; (3) Facilitate preservation of data consistency; (4) Allow for rational maintenance of data. In this first of two parts, we'll consider the first through third normal forms, and observe that while there are important differences between the XML and relational models, much of the thinking that commonly goes into RDB design can be applied to WXS design as well. ... the key concept of reducing redundancy through key association is alive and well in W3C XML Schema design. While I'd love to finish on this bright note, I must report that there are devils inhabiting the details. In part two of this article, I'll point them out and discuss the implications for WXS design, as well as addressing the subtler fourth and fifth normal forms..." [November 14, 2002] "Web Services Development: Jean Paoli on XML in Office 11." By Jon Udell. In InfoWorld (November 14, 2002). ['Next week's issue of InfoWorld includes an article on the new XML capabilities of Office 11. While researching the story, I interviewed the architect of XML in Office 11, Microsoft's Jean Paoli, one of the primary co-creators of XML. Here are some of his remarks == excerpts from Paoli'] "... The goal is to unleash the Excel functionality on generic schema, on customer-defined schema. Who knows how to create a data model better than the financial or health care company who uses the data? Until now, it was very difficult to find a tool which lets you pour the data belonging to any arbitrary schema, and then, for example, chart that data... All our tools are XML editors now: Word, Excel, XDocs. But we shouldn't think about XML editors, we should think about the task at hand. If I want to create documents with a lot of text, that's Word. With XDocs, the task is to gather information in structured form. And with Excel, it's to analyze information. We have this great toolbox which enables you to analyze data. We can do pie charts, pivot tables, I don't know how many years of development of functionality for analyzing data. So we said, now we are going to feed Excel all the XML files that you can find in nature... To create the schema for your spreadsheet, first look at the information which is captured in that spreadsheet. Give names to the data. The data is about the user's name and e-mail address, for example. I don't want to call it cell 1, cell 2, or F1 or F11. The whole thing about XML is to give names to things which are in general not named... The goal is to unleash the Excel functionality on generic schema, on customer-defined schema. Who knows how to create a data model better than the financial or health care company who uses the data? Until now, it was very difficult to find a tool which lets you pour the data belonging to any arbitrary schema, and then, for example, chart that data..." Udell says: "Modeling XML data using DTD (Document Type Description) or, more recently, XML Schema, has been a fairly arcane discipline. Practitioners have included publishers seeking to repurpose content and Web services developers writing WSDL files for which XML Schema serves as the type definition language. But enterprise data managers have not, in general, seen much reason to model lots of data using XML Schema. With Office 11, Microsoft aims to rewrite the rules in a dramatic way. If every enterprise desktop can consume, process, and emit schema-valid XML data, the modeling of that data becomes a huge strategic opportunity. And the people who can do that modeling effectively become very valuable..." See "Microsoft 'XDocs' Office Product Supports Custom-Defined XML Schemas." [November 12, 2002] "Place XML Message Design Ahead of Schema Planning to Improve Web Service Interoperability." By Yasser Shohoud. In MSDN Magazine Volume 17, Number 12 (December 2002). ['Web Services are all about exchanging data in the form of XML messages. If you were about to design a database schema, you probably wouldn't let your tool do it for you. You'd hand-tool it yourself to ensure maximum efficiency. In this article, the author maintains that designing a Web Service should be no different. You should know what kind of data will be returned by Web Service requests and use the structure of that data to design the most efficient message format. Here you'll learn how to make that determination and how to build your Web Service around the message structure.'] "When you build a data-centric application, how do you create the database schema? Do you begin by creating classes and then let your IDE or tools create the database schema for you, or do you design the database schema yourself, taking into account normalization, referential integrity, and performance optimizations? Chances are you design and create the database schema yourself. Even if you use a visual schema designer rather than data definition language (DDL) statements, you are still taking control of the database schema design. Web Services are all about supplying the right data at the right time. When a client calls a Web Service, an XML data message is sent over the wire and a response is returned to the client. When you program the Web Service and its clients, you are really programming against these messages. The data in these messages is ultimately what the application cares about. So why would you create a Web Service beginning with the classes and methods and let the tools create the message schemas for you? You should design the data (message) schema and implement the Web Service to fit this design, like you would when designing a database schema... Web Services are all about applications exchanging data over the Web in the form of XML messages, so building a Web Service requires careful design of these messages using XML Schema and WSDL. When you begin with message design rather than method design the kind of data your Web Service expects to receive and return is made clear. By designing messages using XSD and WSDL, you create a formal interface definition that Web Service developers can implement and client developers can program against simultaneously. Next time you begin a Web Service project, begin by designing the messages format using the Visual Studio XML Schema designer..." [November 08, 2002] SchemaViewer 1.0. Francis Kilkelly has announced the availability of a SchemaViewer 1.0 tool which "virtually eliminates tedious browsing of XML Schema documents by representing them as a easily navigatable hierarchical tree. The application is a Swing-based GUI. Features: (1) The tool allows you to quickly and easily browse the contents of any W3C-compliant XML Schema. (2) It displays any XML Schema as a hierarchical tree comprising of elements encountered within the schema/s. (3) If an element has 'type', 'ref' or 'base' attributes then the referenced element will appear as a child of the current element in the tree. (4) If the XML Schema has any import or include statements this tool will include the contents of the corresponding XML Schema. (5) This tool also allows you to view XML Schemas embedded within WSDL (Web Services Definition Language) documents." Requires Java Run-Time Environment 1.3.1 or higher. See related resources in W3C list of XML Schema tools. [November 04, 2002] Architag XML Editor XRay Supports W3C XML Schema. A posting from Mae Ozkan [2002-11-01] reports that Architag's XML Editor XRay now supports XML Schema (XSD) with XRay version 2.0. "Full W3C XML Schema (also called XSD) support is built into version 2 of XRay. XSD schemas are automatically parsed according to the W3C specification to assure compliance. Then, a schema is available, using XML Namespaces, to validate other XML documents within XRay. The XRay editing engine offers a real-time validator. Parsing errors are shown in real time as you type your XML tags and content. The real-time editing functionality helps new users learn XML quickly because they get instant feedback. Web Services Description Language (WSDL) is fully supported in XRay 2.0. This includes all parts of WSDL documents, including intelligent parsing of schemas within the WSDL file. XRay has built-in XSLT processing that, like the XML engine, provides real-time transformation of XML structures, including HTML. There is also a built-in HTML viewer for quick development of XML-based Web pages..." See the screen shots. XRay 2.0 is available for free download from http://architag.com/xray. [October 31, 2002] "Analyze Schemas with the XML Schema Infoset Model." By Shane Curcuru. From DevX XML Zone. October 2002. ['IBM's new XML Schema Infoset Model provides a complete modeling of schemas themselves, including the concrete representations as well as the abstract relationships within a schema or a set of schemas. Learn how to use this powerful library to perform complex queries on your own schemas.'] "As the use of schemas grows, so does the need for tools to manipulate those schemas. IBM's new XML Schema Infoset Model provides a complete modeling of schemas themselves, including the concrete representations as well as the abstract relationships within a schema or set of schemas. This library easily queries the model of a schema for detailed information. You can also use it to update the schema to fix any problems found and write the schema back out. Although there are a number of parsers and tools that use schemas to validate or analyze XML documents, tools that allow querying and advanced manipulation of schema documents themselves are still being built. The XML Schema Infoset Model (AKA the Java packages org.eclipse.xsd.*, or just 'the library') provides a rich API library that models schemas -- both their concrete representations (perhaps in a schema.xsd file) and the abstract concepts in a schema as defined by the specification. As anyone who has read the schema specs knows, they are quite detailed. The XML Schema Infoset Model strives to expose all the Infoset details within any schema. This allows you to efficiently manage your schema collection, and empower higher-level schema tools such as schema-aware parsers and transformers... The XML Schema Infoset Model also includes the UML diagrams used in building the library interfaces themselves; these diagrams show the relationships between the library objects, which very closely mimic the concepts in the schema specifications..." Note: The IBM XML Schema Infoset Model "is a reference library for use with any code that examines, creates, or modifies XML Schemas (standalone or as part of other artifacts, such as XForms or WSDL documents." On October 23, 2002 IBM released a downloadable Version 1.0.1 stable build (20021023_1900TL); see the Developer FAQ and complete documentation. The earlier news item: "IBM Publishes XML Schema Infoset API Requirements and Development Code." [October 31, 2002] "Create Flexible and Extensible XML Schemas. Building XML Schemas in an Object-Oriented Framework." By Ayesha Malik (Senior Consultant, Object Machines). From IBM developerWorks, XML zone. October 2002. ['XML schemas offer a powerful set of tools for constraining and formalizing the vocabulary and grammar of XML documents. With XML rapidly emerging as the data transport format of the future, it is clear that the structure of the XML, as outlined by schemas, must be created and stored in an organized manner. Developers experienced in object-oriented design know that a flexible architecture ensures consistency throughout the system and helps to accommodate growth and change. This instructional article uses an object-oriented framework to show you how to design XML schemas that are extensible, flexible, and modular.'] "When leveraging established patterns of object-oriented programming in constructing XML schemas, I use the three main principles of object-oriented design: encapsulation, inheritance, and polymorphism. To help discuss object-oriented frameworks in this context, I use an example of a fictitious company, Bond Publishing... Design patterns for decoupling: Recently, some design patterns have emerged that address decoupling and cohesiveness in XML schemas. We have already discussed how to create reusable components. Now, you'll learn how to vary the granularity of datatypes. This is similar to trying to answer the question 'How can I refactor my code and how much refactoring is appropriate for a given situation?' There are currently three design patterns that represent three levels of granularity when creating components... Object-oriented programming places a great deal of emphasis on packaging classes according to their services. The package structure organizes the code and facilitates modularity and maintenance. You can achieve similar benefits by organizing your XML schemas according to their functions... If your system is going to use XML to transport data information, either internally or externally, then you should seriously consider how to properly design your XML schemas. In this article, you have seen how to create schemas that use inheritance, encapsulation and polymorphism, and even had a glimpse of emerging design patterns in XML schema design. Leveraging these object-oriented frameworks helps you design XML schemas that are modular and extensible, maintain data integrity, and can be easily integrated with other XML protocols..." [October 24, 2002] Microsoft XSD Inference Tool Creates Schemas from XML Instances. A posting from Dare Obasanjo announces the availability of a Microsoft XSD Inference utility. The Beta 1 XSD Inference Tool "is used to create an XML Schema definition language (XSD) schema from an XML instance document. The input must be a well-formed XML instance document, and not an XML fragment. The output is an XML schema that can validate the instance document. When provided with well-formed XML file, the utility generates an XSD that can be used to validate that XML file. You can also refine the XSD generated by providing the tool more well-formed XML files." An interface to the tool is available online, and a binaries may be downloaded for use with Microsoft .Net Frameworks. For the online version, the total size of the file must not exceed 1 MB. Related utilities from the Microsoft 'GotDotNet' XML Tools Team include the Microsoft XML Diff and Patch tool and an XSD Schema Validator. [Full context] [October 04, 2002] A posting from Henry S. Thompson announces a "Major New Release of XSV" which reorganizes the code to make it PPC (Python Polically Correct) and adds new functionality. XSV (XML Schema Validator) is an open source GPLed work-in-progress attempt at a conformant schema-aware processor, as defined by XML Schema Part 1: Structures, May 2, 2001 (REC) version. Henry says: "New functionality includes command-line settable optional invocation control of top-level element name and/or type, partial support for the 'pattern' facet. The status page provides more details, including information on the Win32 installer and running the sources -- made easier now, because there are RPMs for the underlying PyLTXML stuff... Since this is a major re-org, there's obviously a bigger chance than usual of bugs lurking, despite moderately careful regression testing -- please let me know ASAP of anything that stops working..." [October 03, 2002] "Working with a Metaschema." By Will Provost. From XML.com (October 02, 2002). ['Document schemas can be useful for a lot more than their primary purpose of validating document instances. For some time now, it has been popular to use a schema to construct parts of a processing application. Our main feature this week, the latest in Will Provost's XML Schema Clinic series, focuses on how schemas can be used in application construction. In particular, Will looks at how the schema for W3C XML Schemas themselves can be adapted to produce "metaschemas," allowing your applications to either restrict or extend the functionality of W3C XML Schema.'] "W3C XML Schema [here: WXS] provides a structural template that describes in detail each type and relationship: just the information an application would need, say, to build a new instance document from a data stream or to create an intuitive GUI for data entry. Given the tremendous complexity of WXS, however, applications which consume schemas face a daunting processing challenge. Often the full power of the language is neither needed nor wanted, as modeling requirements may be relatively simple, and developers don't want to be responsible for every possible wrinkle in a schema. If only we could constrain a candidate schema to use just a subset of the full WXS vocabulary... Oh, wait, we can. 'WXS vocabulary' is the tip-off: a schema is just an XML document, after all, and it can be validated like any other. What we need, in other words, is a schema for our schema. In this article we'll investigate the uses of metaschemas and the techniques for creating them. This will bring us in close contact with the existing WXS metamodel, an interesting study in and of itself. We'll consider several strategies for bending this metamodel to our application's purposes, and we'll see which strategies best suit which requirements. To tip the hand a bit, the prize will go to the WXS redefine component as a way of redefining parts of the WXS metamodel itself... This system isn't perfect. There are many ways in which I'd like to leverage the WXS metamodel that are either closed to me or just too complicated to be worth the trouble. This isn't a shortcoming in WXS, as I see it; if the type model were as pliable as I'd like it to be, it just wouldn't be W3C XML Schema and wouldn't have the tremendous descriptive power and precision that I also want. Where they are feasible, redefinitions of schema components offer an elegant way to tailor the WXS model to the needs of an application. XPath/XSLT validation can provide another option, but it's important to see past logistics and remember that the WXS metamodel is as stiff as it is for a reason. If you find yourself demanding features in your application's candidate schema that make them malformed under WXS proper, or changing so many things that the metamodel is unrecognizable, you should probably be building your metamodel from scratch or working from a different starting point." See also XML Schema: The W3C's Object-Oriented Descriptions for XML, by Eric van der Vlist. [October 01, 2002] "Guide to the XML Schema Specifications." Techquila's Topicmap-powered browser for the W3C XML Schema Specifications. By Kal Ahmed (Techquila). October 01, 2002. "The W3C XML Schema standards are often accused of being over-complex and difficult to read. In an attempt to assist those trying to find their way around the W3C specifications, I have created a multi-modal topic map of the specifications. In this topic map you will find indexes of the terms used by the specifications and the main concepts of XML Schema. The topic maps are primarily created automatically using MDF to process the XML Schema specifications and the schema for XML Schema. The topic maps are then integrated by merging them with a hand-crafted topic map created using TMTab. A static HTML site has been created from the topic maps and can be browsed [online]. The application that produces this HTML output is based on TM4J and Jakarta Velocity. For more information about the creation and publication of topic maps using open-source and free software; or to get the topic map files themselves, please contact Kal Ahmed directly..." [From the posting: "I've spent a little time creating topic maps from the XML Schema family of specifications. The HTML-ized result is now [online]... This is a first stab at trying to topicmap the specs so comments on both presentation and content would be very welcome. For the topic map nerds, the XTM files are available; send me an email if you would like them. My thanks to Jeni Tennison who provided some really helpful hints in getting me started on this project (though all the mistakes are mine!)."] [September 30, 2002] "Data Interchange Standards Association Develops New Software Tool to Ease XML Schema Documentation." - "The Data Interchange Standards Association (DISA) released a report on the Componetizer, a new software tool built by DISA that automatically identifies and documents data items in the electronic rules for XML documents, called XML Schemas. The eXtensible Markup Language (XML) is a high-powered standard format, developed by the World Wide Web Consortium or W3C, for exchanging business messages and other structured data over the Internet. The Componetizer dramatically reduces the time and effort needed to document XML Schemas, an often-laborious process in the development of standard business messages written in XML. While XML Schemas can be powerful, they are written in XML syntax, which is machine-readable but sometimes difficult to understand by humans. The Componetizer scans XML Schemas, identifies the individual data items in those schemas, and then arrays the Schema components in easy-to-read tables viewable with any Web browser... The Componetizer works with XML Schemas meeting the requirements of the W3C's XML Schema 1.0 Recommendation of May 2, 2001. DISA has used the Componetizer to generate documentation for some of its current industry affiliates, and plans to expand the outputs to other visual display and database formats..." See "Componetizer: A Tool for Extracting and Documenting XML Schema Components," by Marcel Jemio and Alan Kotok. [September 16, 2002] Altova Introduces New XML Product Line for Design and Development. Altova Inc. has released a new XML product line consisting of three easy-to-use software tools designed to facilitate and advance the adoption of XML technologies. The XMLSPY 5 tool "builds on the previous XMLSPY version by adding XSLT debugging, WSDL editing, Java/C++ code generation, HTML Importing, and Tamino Integration. Altova's AUTHENTIC 5 is a standards-based browser enabled document editor; it allows business users to seamlessly capture thoughts and ideas directly in XML content for storage in any content management system, database, or XML repository, for later retrieval or transformation, unlocking corporate knowledge. The STYLEVISION 5 XML tool supports web developers by providing powerful conversion utilities for painless migration of traditional HTML websites to true XML-based sites; it consists of XSLT stylesheets, XML Schema/DTD, and XML content." Each of the tools is available from the Altova website for free trial download and evaluation. [Full context] [September 05, 2002] IBM alphaWorks Updates XML Schema Quality Checker. A posting from Achille Fokoué (XML/XSL Transformational Systems, IBM T.J. Watson Research Center) announces the release of the IBM XML Schema Quality Checker version 2.1.1 from IBM Alphaworks. XML Schema Quality Checker (SQC) "is a program which takes as input documents containing XML Schemas written in the W3C XML schema language and diagnoses improper uses of the schema language. Where the appropriate action to correct the schema is not obvious, the diagnostic message may include a suggestion about how to make the fix. For Schemas which are composed of numerous schema documents connected via <include>, <import> or <redefine> element information items, a full schema-wide checking is performed. The tool can also be run in batch mode to quality check multiple XML schemas in a single run. SQC may be installed as an Eclipse or WSAD Plugin." Changes in version 2.1.1 include: (1) improved error detection; (2) implementation of fixes based upon the W3C 'XML Schema 1.0 Specification Errata' document; (3) SchemaQualityChecker is now using Apache's XERCES-J version 2.1; (4) Additional command line options; (5) Eclipse progress meter. [Full context] [August 30, 2002] "Validation by Instance." By Michael Fitzgerald. From XML.com. (August 28, 2002). ['Michael Fitzgerald shows a convenient way to write schemas for validating XML documents. Rather than modeling the schema from scratch, Michael shows how to derive schemas (DTDs, RELAX NG, and W3C XML Schema) from instance documents.'] "Most people these days develop XML documents and schema with a visual editor of some sort, perhaps Altova's XML Spy, Tibco's TurboXML, xmlHack from SysOnyx, or Oxygen. Some even use several editors on a single project, depending on the strengths of the software. Others prefer to work closer to the bone. I usually develop my schema and instances by hand, using the vi editor, along with other Unix utilities (actually, I use Cygwin on a Windows 2000 box). I don't want to make more work for myself, but I prefer to use free, open source tools that allow me to make low-level changes that suit my needs. If you prefer to work this way, you should enjoy this piece. In this article, I will explore how you can translate an XML document into a Document Type Definition (DTD), a RELAX NG schema, and then into an W3C XML Schema (WXS) schema, in that order. I'll do this with the aid of several open source tools, and I'll also cover a way to validate the original XML instance against the various schemas. [1] Translating the DTD to RELAX NG: James Clark's DTDinst is a Java tool that translates a DTD either into its own XML vocabulary or into a schema in RELAX NG's XML syntax. After downloading and installing dtdinst.jar, you can issue the following command to translate a DTD into RELAX NG: [2] Translating an XML Document into a DTD: To translate the XML document into a DTD, I'll use Michael Kay's DTDGenerator. Originally, DTDGenerator was part of the Saxon XSLT processor, but now it is separate. At just 17kb, it's a pretty small download. DTDGenerator does a fair amount of work for you, but it doesn't produce parameter entities, notation declarations, or entity declarations. It's also not namespace-aware, but DTDs aren't inherently aware of namespaces or qualified names anyway. [3] Translating RELAX NG to XML Schema: Trang is a another tool written by James Clark. It can take as input a schema written in RELAX NG XML and compact syntax; it can produce RELAX NG XML, RELAX NG compact syntax, DTD, and WXS as output. After downloading Trang (which includes a JAR file for Jing, a RELAX NG validator), unzipping and installing it, you can convert the RELAX NG schema back to a DTD new-event.dtd ... If you work on the Windows platform, I have also written a set of batch files that will perform all the translations (from instance, to DTD, to RELAX NG, and finally to W3C XML Schema) and then validate against them in one simple step... Using the tools I've described here, you can perform the conversions and validate against the resulting schemas in a matter of seconds. You may still prefer to use a visual editor, but I believe that learning and using these tools can save you time and money..." [August 08, 2002] "UML For W3C XML Schema Design." By Will Provost. From XML.com. August 07, 2002. ['Will Provost offers a UML profile for W3C XML Schema'] "Even with the clear advantages it offers over the fast-receding DTD grammar, W3C XML Schema (WXS) cannot be praised for its concision. Indeed, in discussions of XML vocabulary design, the DTD notation is often thrown up on a whiteboard solely for its ability to quickly and completely communicate an idea; the corresponding WXS notation would be laughably awkward, even when WXS will be the implementation language. Thus, UML, a graphical design notation, is all the more attractive for WXS design. UML is meant for greater things than simple description of data structures. Still the UML metamodel can support Schema design quite well, for wire-serializable types, persistence schema, and many other XML applications. UML and XML are likely to come in frequent professional contact; it would be nice if they could get along. The highest possible degree of integration of code-design and XML-design processes should be sought. Application of UML to just about any type model requires an extension profile. There are many possible profiles and mappings between UML and XML, not all of which address the same goals. The XML Metadata Interchange and XMI Production for W3C XML Schema specifications, from the OMG, offer a standard mapping from UML/MOF to WXS for the purpose of exchanging models between UML tools. The model in question may not even be intended for XML production. WXS simply serves as a reliable XML expression of metadata for consumption in some other tool or locale. My purpose here is to discuss issues in mapping between these two metamodels and to advance a UML profile that will support complete expression of an WXS information set... The major distinction is that XMI puts UML first, so to speak, in some cases settling for a mapping that fails to capture some useful WXS construct, so long as the UML model is well expressed. My aim is to put WXS first and to develop a UML profile for use specifically in WXS design: (1) The profile should capture every detail of an XML vocabulary that an WXS could express. (2) It should support two-way generation of WXS documents. I suggest a few stereotypes and tags, many of which dovetail with the XMI-Schema mapping. I discuss specific notation issues as the story unfolds, and highlight the necessary stereotypes and tags... David Carlson [Modeling XML Applications with UML: Practical e-Business Applications] has also done some excellent work in this area, and has proposed an extension profile for this purpose. I disagree with him on at least one major point of modeling and one minor point of notation, but much of what is developed here lines up well with Carlson's profile..." See references in: (1) "Conceptual Modeling and Markup Languages"; (2) "XML and 'The Semantic Web'." [August 05, 2002] "Not My Type: Sizing Up W3C XML Schema Primitives." By Amelia Lewis. From XML.com. July 31, 2002. ['Continuing our occasional series of opinion pieces from members of the XML community, Amy Lewis takes a hard look at W3C XML Schema datatypes.'] "Since the application of XML to data representation first gained public visibility, there has been a movement to enhance its type system beyond that originally provided by DTD. Several attempts were made (SOX, XML Data and XML Data Reduced, Datatypes for DTDs, and others) before the W3C handed the problem to the XML Schema Working Group. What is the goal of data type definitions for XML? For one thing, it establishes "strong typing" in XML in a fashion that corresponds with strong typing in programming languages. Various commercial interests have been vocal supporters of strong typing in XML because they see typed generic data representation as their best hope for interoperability and increased automation. With typing in schemas extended into the textual content of simple types, and not just the structural content of complex types, businesses can enforce contracts for data exchange. In other words, strong typing enables electronic commerce. To phrase it a little differently, the data types defined in DTDs were considered inadequate to support the requirements of electronic commerce or, more generally, of commercially reliable electronic information exchange. The publication of W3C XML Schema (or WXS), in which one half of the specification was devoted to the definition of a type library (part two), seemed to resolve the problem. Certainly, with forty-four built-in data types, nineteen of them primitive, it seemed at first glance to cover the field. The increasing visibility of WXS and the efforts to layer additional specifications on top of it -- XML Query, the PSVI, data types in XPath 2.0, typing in web services -- have begun to raise serious questions about WXS part two, even among proponents of strong types, including the author of this article. There are two fundamental problems with WXS datatyping. The first is its design: it's not a type system -- there is no system -- and not even a type collection. Rather, it's a collection of collections of types with no coherent or consistent set of interrelations. The second problem is a single sentence in the specification: 'Primitive datatypes can only be added by revisions to this specification'. This sentence exists because of the design problem; lacking a concept for what a primitive data type is, the only way to define new types is by appeal to authority. The data type library is wholly inextensible, internally inconsistent, bloated in and incomplete for most application domains..." 'Related Reading' from O'Reilly includes XML Schema: The W3C's Object-Oriented Descriptions for XML, by Eric van der Vlist. [August 03, 2002] "XML to Relational Conversion using Theory of Regular Tree Grammars." By Murali Mani and Dongwon Lee. In Proceedings of the VLDB Workshop on Efficiency and Effectiveness of XML Tools, and Techniques (EEXTT), Hong Kong, China, August 2002. 12 pages, with 17 references. "In this paper, we study the different steps of translation from XML to relational models, while maintaining semantic constraints. Our work is based on the theory of regular tree grammars, which provides a useful formal framework for understanding various aspects of XML schema languages. We first study two normal form representations for regular tree grammars. The first normal form representation, called NF1, is used in the two scenarios: (a) Several document validation algorithms use the NF1 representation as the first step in the validation process for efficiency reasons, and (b) NF1 representation can be used to check whether a given schema satisfies the structural constraints imposed by the schema language. The second normal form representation, called NF2, forms the basis for conversion of a set of type definitions in a schema language L1 that supports union types (e.g., XML-Schema), to a schema language L2 that does not support union types (e.g., SQL), and is used as the first step in our XML to relational conversion algorithm..." General references: "XML Schemas." [cache] [August 03, 2002] "NeT and CoT: Translating Relational Schemas to XML Schemas Using Semantic Constraints." By Dongwon Lee, Murali Mani, Frank Chiu, and Wesley. W. Chu. Paper prepared for VLDB 2002 (28th International Conference on Very Large Data Bases). "The paper introduces two algorithms, called NeT and CoT, to translate relational schemas to XML schemas using various semantic constraints are presented. The XML schema representation we use is a language-independent formalism named XSchema, that is both precise and concise. A given XSchema can be mapped to a schema in any of the existing XML schema language proposals. Our proposed algorithms have the following characteristics: (1) NeT derives a nested structure from a flat relational model by repeatedly applying the nest operator on each table so that the resulting XML schema becomes hierarchical, and (2) CoT considers not only the structure of relational schemas, but also semantic constraints such as inclusion dependencies during the translation - it takes as input a relational schema where multiple tables are interconnected through inclusion dependencies and converts it into a 'good' XSchema. To validate our proposals, we present experimental results using both real schemas from the UCI repository and synthetic schemas from TPC-H." See similarly "NeT and CoT: Inferring XML Schemas from the Relational World", by Dongwon Lee, Murali Mani, Frank Chiu, and Wesley. W. Chu; in Proceedings of ICDE 2002, San Jose, California, February 2002. General references: "XML Schemas." [source] [July 27, 2002] "Data Modeling using XML Schemas." By Murali Mani (Computer Science Dept, UCLA). Presentation to be given Wednesday, August 7, 2002 as a Nocturne at the Extreme Markup Languages Conference 2002. "XML appears to have the potential to make significant impact on database applications, and XML is already being used in several database applications. One of the main reasons for this is the 'superiority' of XML schemas for data modeling - recursion and union types are easily specified using XML schemas. In order to do data modeling effectively, we should be study it systematically. A data model has three constituents to it - structural specification, constraint specification, and operators for manipulating and retrieving the data. Regular tree grammar theory has established itself as the basis for structural specification for XML schemas. Constraint specification is still being studied, and we have approaches such as 'path-based constraint specification' and 'type-based constraint specification', with strong indications of type-based constraint specification as a very suitable candidate. Operators are available as part of XPath, XSLT, XQuery etc. In this talk, we would like to mention about the two ways of specifying contraints - path-based and type-based. Then we would like to describe how we can specify entities and relationships using regular tree grammar theory, and with type-based constraint specification. Furthermore, we would like to talk about an issue which is attracting attention of late -- subtyping required for XML processing. There are two techniques for subtyping in XML Schemas -- explicit as in W3C XML Schema or implicit as in XDuce. The main results here are: (a) The two subtyping schemes are incompatible with each other, and (b) There are open and interesting issues in doing implicit subtyping..." Extreme 2002 Conference will be held August 4 - 9, 2002 in Montréal. [July 23, 2002] A posting from James Clark announces an update for RELAX NG resources, availble from the Thai Open Source Software Center. From the posting: "I've updated jing, trang and dtdinst. Trang now has experimental support for generating W3C XML Schema. DTDinst has a new option -i for inlining attribute list declarations; this makes its generated output work better as input for generating W3C XML Schema. Jing has a couple of minor bug fixes... There are still lots of things I want to add to the trang XSD output module. Feedback on what improvements are most needed is welcome... The XML Schema support (provisional) has several limitations..." See "RELAX NG." [July 20, 2002] "The Essence of XML." By Jérôme Siméon (Bell Laboratories) and Philip Wadler (Avaya Labs). Invited paper prepared for presentation at the Sixth International Symposium on Functional and Logic Programming (FLOPS 2002), University of Aizu, Aizu, Japan, September 15-17, 2002. 14 pages, with 22 references. Referenced on Philip Wadler's XML page. "The World-Wide Web Consortium (W3C) promotes XML and related standards, including XML Schema, XQuery, and XPath. This paper describes a formalization XML Schema. A formal semantics based on these ideas is part of the official XQuery and XPath specification, one of the first uses of formal methods by a standards body. XML Schema features both named and structural types, with structure based on tree grammars. While structural types and matching have been studied in other work (notably XDuce, Relax NG, and a previous formalization of XML Schema), this is the first work to study the relation between named types and structural types, and the relation between matching and validation. The dichotomy between names and structures is not quite so stark as at first it might appear. Many languages use combinations of named and structural typing. For instance, in ML record types are purely structural, but two types declared with 'datatype' are distinct, even if they have the same structure. Further, relations between names always imply corresponding relations between structures. For instance, in Java if one class is declared to extend another then the first class always has a structure that extends the second. Conversely, structural relations depend upon names. For instance, names are used to identify the fields of a record... Our aim is to model XML and Schema as they exist -- we do not claim that these are the best possible designs. Indeed, we would argue that XML and Schema have several shortcomings. First, we would argue that a data representation should explicitly distinguish, say, integers from strings, rather than to infer which is which by validation against a Schema. (This is one of the many ways in which Lisp S-expressions are superior to XML.) Second, while derivation by extension in Schema superficially resembles subclassing in object-oriented programming, in fact there are profound differences. In languages such as Java, one can typecheck code for a class without knowing all subclasses of that class (this supports separate compilation). But in XML Schema, one cannot validate against a type without knowing all types that derive by extension from that type (and hence separate compilation is problematic). Nonetheless, XML and Schema are widely used standards, and there is value in modeling these standards. In particular, such models may: (i) improve our understanding of exactly what is mandated by the standard, (ii) help implementors create conforming implementations, and (iii) suggest how to improve the standards..." See also the previous/preliminary version. [cache] [July 05, 2002] "W3C XML Schema Design Patterns: Dealing With Change." By Dare Obasanjo. From XML.com. July 03, 2002. ['One of the key challenges in XML systems is how to cope with change in documents. Business requirements and interactions change, and your documents need to change with them while retaining backwards compatibility. Our feature article this week, the first in a series from Dare Obasanjo, covers design patterns for W3C XML Schema that support the evolution of your XML documents over time.'] "W3C XML Schema is one to specify the structure of and constraints on XML documents. As usage of W3C XML Schema has grown, certain usage patterns have become common and this article, the first in a series, will tackle various aspects of the creation and usage of W3C XML Schema. This article will focus on techniques for building schemas which are flexible and which allow for change in underlying data, the schema, or both in a modular manner. Designing schemas that support data evolution is beneficial in situations where the structure of XML instances may change but still must be validated against the original schema. For example, several entities may share XML documents, the format of which changes over time, but some entities may not receive updated schemas. Or when you must ensure that older versions of an XML document can be validated by newer versions of the schema. Or, perhaps, multiple entities share XML documents that have a similar structure but in which significant domain specific differences. The address.xsd example in the W3C XML Schema Primer describes a situation in which a generic address format exists that can be extended to encompass localized address formats..." [June 26, 2002] "DSDL Examined." By Leigh Dodds. From XML.com. June 26, 2002. ['In his final column Leigh looks at DSDL, the ISO activity to standardise XML document validation.'] "The core of DSDL will be the Interoperability Framework (Part 1): the glue that binds together the other modules. This week Eric van der Vlist, who is the appointed editor of this section, and Rick Jelliffe have separately produced proposals that aim to explore these kind of framework structures in more detail. The two proposals, neither of which have any formal standing, take very different approaches to the same problem. Van der Vlist's XML Validation Interoperability Framework (XVIF) takes the approach of embedding validation and transformation pipelines within another vocabulary. The specification and online demonstrator both show how this could be achieved by embedding the pipelines within a schema language, but in principle the XVIF is language-neutral so could be embedded within an XSLT transformation for example. XVIF elements just rely on their container to provide the context node on which they will interact. The embedded pipelines may generate other nodes or a simple boolean validation flag. Van der Vlist has produced a prototype that supports using pipelines containing XPath expressions, XSLT transformations, and manipulating content with simple regular expressions, or using Regular Fragmentations. In contrast, Rick Jelliffe's proposal, 'Schemachine' is closer to other pipeline frameworks such as XPipe and Cocoon in that the pipelines are defined by a separate vocabulary. In fact Jelliffe notes that the proposal borrows a lot from XPipe and Schematron in that it has a number of similar elements and structures, e.g., phases. Schemachine divides pipeline elements up into particular roles such as Selectors (e.g., XPath expressions), Tokenizers (e.g., Regular Fragmentations) and Validators (e.g., RELAX NG, Schematron). Jelliffe differentiated XVIF and Schemachine as 'innies and outies'. Technology aside, the important aspect of these proposals is the intent: publicly exploring strawman proposals and implementations to gather feedback before considering standardization. That's a path which seems not only likely to produce viable results, but may actually deliver useful tools that others benefit from in the shorter term..." [June 26, 2002] "Enforcing Association Cardinality." By Will Provost. From XML.com. June 26, 2002. ['Our main feature this week is the first in a new, ongoing, series focusing on W3C XML Schema, called "XML Schema Clinic." Will Provost will be examining issues in schema design and XML data modeling. In this first installment, Will discusses using W3C XML Schema to control the cardinality of associations between elements in a document type.'] "If you're like me, XML document design brings out your darker side. We like a schema whose heart is stone -- a schema that's just itching to call a candidate document on the carpet for the slightest nonconformity. None of this any-element-will-do namespace validation for us. We enjoy the dirty work: schemas, we think, are best built to be aggressive in ferreting out the little mistakes in the information set that could later confuse the more sheltered and constructive-minded XML application. In this article, we'll practice a bit of that merciless science. Specifically, we'll look at ways to control the cardinality of associations between XML elements. The basic implementation, which we'll review momentarily, of an association between two types is simple enough but is only sufficient for many-to-one relationships. What if multiple references, or zero references, to an item are unacceptable? What if a referenced item may or may not be present? These variations will require other techniques, and these are essential for the truly draconian schema author. This article will use a simple UML notation to illustrate patterns and examples. Knowledge of both XML Schema 1.0 (Part 1 in particular) and UML is assumed, although in developing our notation we'll have a chance to review a little of both... The Unified Modeling Language (UML) provides a basis for a simple notation which will serve our needs in identifying rudimentary design patterns and in illustrating specific examples. Note that many UML-to-Schema mappings are possible; see the 'XMI Production for XML Schema' specification from the OMG for one much more formal option..." [June 24, 2002] IBM Clio Tool Supports Mapping Between Relational Data and XML Schemas. Clio is a Computer Science Research project at IBM's Almaden Research Lab. Its developers are designing methods to specify the transformation of legacy data to make it fit for new uses. Clio addresses the challenge of "merging and coalescing data from multiple and diverse sources into different data formats. In particular, it addresses schema matching (the process of matching elements of a source schema with elements of a target schema) and schema mapping (the process of creating a query that maps between two disparate schemas), which lie at the heart of data integration systems. Clio is a tool for generating mappings (queries) between relational and XML Schemas. The user is presented with the structure and constraints of two schemas and is asked to draw correspondences between the parts of the schemas that represent the same real world entity. Correspondences can also be inferred by Clio and verified by the user. Given the two schemas and the set of correspondences between them, clio can generates the (SQL, XSLT, or XQueries) queries that drive the translation of data conforming to the first (source) schema to data conforming to the the second (target) schema." [Full context] [June 21, 2002] "Can XML Be The Same After W3C XML Schema?" By Eric van der Vlist. From XML.com. June 19, 2002. ['Eric van der Vlist has just finished writing a book on W3C XML Schemas for O'Reilly, an experience that has given him a unique perspective on schema languages and W3C XML Schema in particular. Here Eric reflects on the nature of W3C XML Schema and how it could affect XML as a whole'] "The first question to ask is why is W3C XML Schema different? Why am I asking this question about W3C XML Schema and not about DTDs, Schematron, or RELAX NG? The short answer is datatypes and object orientation. These two aspects of W3C XML Schema are tightly coupled. Datatypes are to W3C XML Schema what classes are to object oriented programming languages. Both promote a categorization of information into classes and subclasses, analogous to the taxonomies biologists use to classify species. Although this process of classification or derivation seems natural, it is not universal and is much less visible in other schema languages. To reuse the metaphor of species, a rule based language such as Schematron does not attempt to put a sticker on a species, but rather set of rules defining if an animal belongs to a set of 'valid' animals ('the set of animals having four legs and able to run at least 50 km/h'). Grammar based languages, including RELAX NG and DTD, describe the patterns used to build the animal ('an animal made of a body, a neck, a head, a tail, and four legs')... My reward for digging into the W3C XML Schema Recommendation has been to discover an unexpected pearl far away from the limelight: W3C XML Schema is exceedingly good at associating metadata with elements or attributes...Schematron is about rules, and RELAX NG is about patterns; neither of them describes elements or attributes as such. Schematron can define rules to be checked in the context of an element, and RELAX NG can describe a pattern containing a single element, but W3C XML Schema is the only one which can describe elements and attributes. As long as validation is your primary concern, this may not make much difference, but for attaching metadata to elements and attributes, a language which describes elements and attributes seems to be a better fit..." [June 17, 2002] "XInterfaces: A New Schema Language for XML." Final thesis by Oliver Nölle. Programming Languages Group, Institute for Computer Science, University of Freiburg, Germany. June 12, 2002. Thesis supervisor, Prof. Dr. Peter Thiemann. 106 pages, with 45 references. Abstract: "A new schema language for XML is proposed to enhance the interoperability of applications sharing a common dataset. An XML document is considered as a semi-structured database, which evolves over time and is used by different applications. An XInterface defines a view of an XML document by imposing constraints on structure and type of selected parts. These constraints are not grammar-based but specify an open-content model, allowing additional elements and attributes to be present anywhere in the document. This enables each application to define and validate its own view on the document, with data being shared between applications or specifically added by one application. XInterfaces feature an explicit type hierarchy, enabling easy extension of existing schemas and documents while guaranteeing conformance of the extended documents to the existing views. This allows data evolution without breaking compatibility of existing applications. Because different applications share one document, access mechanisms are described that guarantee the validity of the document for all applications after modifications. As a proof of concept, a tool was implemented that maps XInterfaces to a class framework in Java, allowing convenient access to those parts of an XML document that are described by XInterfaces." Notes from Oliver Nölle in a posting dated June 16, 2002: "As a final thesis project I created a new schema language named 'XInterfaces'. It is a very simple language, similar to XML Schema in syntax and similar to Schematron in semantics, featuring an explicit type hierarchy which allows multiple inheritance. Although it is a very simple concept, I think it is a very useful one. I'm announcing it here as this language has some features that XML Schema currently does not have, but which I found very useful in certain scenarios (in particular, multiple inheritance and open content model). Maybe later versions of XML Schema are moving towards implementing these features and XInterfaces can be an inspiration. If you are interested, you can find my thesis, a sample validator implementation and related material on the XInterfaces home page..." See also: (1) A sample XInterface type definition which could be applied to this instance document; (2) XInterface type definition for XInterface type definitions; (3) XML Schema schema that defines the syntax of XInterface type definitions; (4) sample implementation of an XInterface schema validator. [cache] [June 04, 2002] "Stylesheet for Extracting Schematron Information from a RELAX-NG Schema." A posting from Eddie Robertsson references a new XSLT stylesheet: "... As long as your application isn't highly time critical you can always embedd Schematron rules within a RELAX-NG schema. Sun's MSV [Multi-Schema XML Validator] will support Schematron like rules in RELAX-NG schemas and I've just finished an XSLT stylesheet 'RNG2Schtrn.xsl' that will extract Schematron rules from a RELAX-NG schema and create a Schematron schema that can be used for validation. It works similar to the XSD2Schtrn.xsl stylesheet that extracts Schematron rules from a W3C XML Schema with one difference: Schematron rules in a RELAX-NG schema can appear anywhere between elements in the RELAX-NG namespace (in W3C XML Schema they have to be declared inside the xs:appinfo element) Like the XSD2Schtrn.xsl stylesheet the RNG2Schtrn.xsl stylesheet will also extract Schematron rules that are included in RELAX-NG modules from the main RNG schema by either <include> or <externalRef>. I'm currently modifying my previous article on how to embedd Schematron rules in W3C XML Schema to add a new section on how this is done in RELAX-NG and it will be available shortly. If you're interested in embedding Schematron rules in a RELAX-NG schema you can still have a look at the original article ['Combining the power of W3C XML Schema and Schematron'] because the technique used for both W3C XML Schema and RELAX-NG is exactly the same..." [June 04, 2002] "Guidelines for the Use of XML within IETF Protocols." Updates the draft "Guidelines For The Use of XML in IETF Protocols" ['draft-hollenbeck-ietf-xml-guidelines-00.txt', April 5, 2002]. By Scott Hollenbeck (VeriSign, Inc.), Marshall T. Rose (Dover Beach Consulting, Inc.), and Larry Masinter (Adobe Systems Incorporated; WWW). Reference: 'draft-hollenbeck-ietf-xml-guidelines-04.txt'. June 4, 2002, expires: December 3, 2002. 33 pages. "The Extensible Markup Language (XML) is a framework for structuring data. While it evolved from SGML -- a markup language primarily focused on structuring documents -- XML has evolved to be a widely- used mechanism for representing structured data. There are a wide variety of Internet protocols being developed; many have need for a representation for structured data relevant to their application. There has been much interest in the use of XML as a representation method. This document describes basic XML concepts, analyzes various alternatives in the use of XML, and provides guidelines for the use of XML within IETF standards-track protocols... It is the goal of the authors that this draft (when completed and then approved by the IESG) be published as a Best Current Practice (BCP)..." Document also available in XML and plain text formats. See also the archives of the 'ietf-xml-use' mailing list, which supports a general discussion on how and when to use XML in IETF protocols. A related posting by James Clark "RELAX NG and W3C XML Schema" in response to section 4.6 of the draft ("... XML Schema should be used as the formalism in the absence of clearly stated reasons to choose another...") led to an XML-DEV thread "XML Schema considered harmful?" See comments from James Clark and Rick Jelliffe. [cache, text] [June 04, 2002] "Analyzing XML Schemas With the Schema Infoset Model. Easily Perform Complex Queries on Your Schemas With This Model." By Shane Curcuru (Advisory Software Engineer, IBM). From IBM developerWorks, XML Zone. June 2002. ['As the use of schemas grows, the need for tools to manipulate schemas grows. The new Schema Infoset Model provides a complete modeling of schemas themselves, including the concrete representations as well as the abstract relationships within a schema or a set of schemas. This article will show some of the power of this library to easily query the model of a schema for detailed information about it; we could also update the schema to fix any problems found and write the schema back out.'] "Although there are a number of parsers and tools that use schemas to validate or analyze XML documents, tools that allow querying and advanced manipulation of schema documents themselves are still being built. The Schema Infoset Model (AKA the IBM Java Library for Schema Components) provides a rich API library that models schemas -- both their concrete representations (perhaps in a schema.xsd file) and the abstract concepts in a schema as defined by the specification. As anyone who has read the schema specs knows, they're quite detailed, and this model strives to expose all the details within any schema. This will then allow you to efficiently manage your schema collection, and empower higher level schema tools -- perhaps schema-aware parsers and transformers... While you can use XSLT or XPath to query a schema's concrete representation in an .xsd file or inside some other .xml content, it is much more difficult to discover the type derivations and interrelationships that schema components actually have. Since the Schema Infoset Model library models both the concrete representation and the abstract concept of the schema, it can easily be used to collect details about its components, even when the schema may have deep type hierarchies or be defined in multiple schema files... Although this is a contrived example, it does show how the library's detailed representation of a schema makes it easy to find exactly the parts of a schema you need. The library provides setter methods for the properties of schema components, so it is easy to update your sample to automatically fix any found types by adding any missing facets. And since the library models the concrete representation of the schema as well, you can write your updated schema back out to an .xsd file..." See "IBM Publishes XML Schema Infoset API Requirements and Development Code" and the announcement. [May 24, 2002] IBM Publishes XML Schema Infoset API Requirements and Development Code. A posting from Bob Schloss describes the public availability of a requirements document for an XML Schema Infoset API and code being written to produce a reference implementation for the schema components API. The requirements document outlines "the design principles, scope, and requirements for a XML Schema Infoset and API; it includes requirements as they relate to development time and runtime software which: (1) constructs, examines or modifies schema components; (2) examines the Post Schema Validation Infoset; (3) makes use of schema components in conjunction with components that represent the infoset of other namespaces (such as WSDL or XForms). It includes requirements concerning the data model, external requirements, and coordination. The API could be used by programs such as: editors of XML instance documents which provide guidance based on a schema; tools that examine pairs of schemas; mapping tools that support non-XML data sources at one end and schema-described XML at the other; tools to visualize, create, modify and extend XML Schemas." The IBM development team is building a reference implementation for the API which is expected to be "very complete -- not simply read-only, but able to handle any XML Schema, no matter how complex." This work, including source code, UML, example usage code, and documentation is available online. [Full context] [May 17, 2002] "XML Schema Languages." By Eric van der Vlist. May 2002. Prepared for the XML Europe 2002 Tutorials. The tutorial follows the classification of XML schema languages proposed by the ISO DSDL Working Group at http://dsdl.org. (1) Introduction; (2) Rule based languages [XSLT and Schematron[; (3) Grammar based languages [RELAX NG]; (4) Object Oriented languages [W3C XML Schema]. See source from the DSDL web site. [May 17, 2002] "Eric van der Vlist on W3C XML Schema." By [O'Reilly Staff]. From XML.com. May 15, 2002. ['An interview with the author of O'Reilly's "XML Schema" book.'] "Eric van der Vlist, a regular contributor to XML.com, has just completed writing XML Schema: The W3C's Object-Oriented Descriptions for XMLfor O'Reilly, to be published in June 2002. In this interview he explains the importance of XML schema languages, and his motivations for writing the book. "[I have chosen this subject] "because I think that the XML schema languages in general, and W3C XML Schema in particular, are the hot topics of the moment: being at the same time essential and potentially dangerous for XML. I thought that an objective book needed to be written, which would be a kind of map to W3C XML Schema, showing clearly not only the features and goodies but also the pitfalls of this specification... the lack of XML schema languages is simply not economically acceptable! An application must expect that the XML documents used as input follow some kind of structure, in order to be able to understand them. Formalizing this structure as 'XML schemas' enables all kind of productivity, quality and performance improvements by automating tasks such as validation, code generation, data binding, documentation and query optimization... The XML DTD was specified in the XML 1.0 recommendation, published before Namespaces in XML 1.0. The XML DTD ignores the notion of namespace and lacks the flexibility necessary to support them in a simple way. The XML DTD is also a descendant of the SGML DTD, which had been designed for document-oriented applications, and lacks a complete type system -- a requirement for data oriented applications. The W3C had the choice between updating the specification of the DTD or creating a new specification; it chose to start anew. I guess that the interoperability issues linked with any modification of the XML 1.0 recommendation have influenced this decision: it is often easier to create a new standard than to update an existing one, especially when it's a successful one! [...] DSDL proposes a classification of schema languages in three categories: (1) Rule based languages (such as Schematron), defining the rules to be followed by a class of XML documents. (2) Grammar based languages (such as RELAX NG), defining the structure of a class of XML documents as a grammar or a set of patterns. (3) Object oriented languages (disclaimer: I am the editor of this section of the DSDL work), describing a class of XML documents as object oriented structures facilitating the mapping between XML documents and object oriented applications. This classification shows that the XML schema languages are very different and could be considered more complementary than competing. If we had to define these schema languages from scratch today, with the experience we have acquired and putting aside any political considerations, I think that we could even define them as layers: a rule based language would be the foundation of a grammar based language, on top of which an object oriented language could be defined..." Note: Eric van der Vlist's book "explains XML Schema foundations, a variety of different styles for writing schemas, simple and complex types, datatypes and facets, keys, extensibility, documentation, design choices, best practices, and limitations; complete with references, a glossary, and examples throughout." [April 17, 2002] "Schema Centric XML Canonicalization." By Selim Aissi (Intel), Bob Atkinson (Microsoft), and Maryann Hondo (IBM). Published by UDDI.org. "Copyright (c) 2000-2002 by Accenture, Ariba, Inc., Commerce One, Inc., Compaq Computer Corporation, Fujitsu Limited, Hewlett-Packard Company, i2 Technologies, Inc., Intel Corporation, International Business Machines Corporation, Oracle Corporation, SAP AG, Sun Microsystems, Inc., VeriSign, Inc., and / or Microsoft Corporation." Version 1.0. Working Draft 13-February-2002. An editors' working draft copy circulated for general review, comment, and feedback. Version URL: http://www.uddi.org/pubs/SchemaCentricCanonicalization-20020213.htm. Latest version URL: http://www.uddi.org/pubs/SchemaCentricCanonicalization.htm. "Existing XML canonicalization algorithms such as Canonical XML and Exclusive XML Canonicalization suffer from several limitations and design artifacts (enumerated herein) which significantly limit their utility in many XML applications, particularly those which validate and process XML data according to the rules of and flexibilities afforded by XML Schema. The Schema Centric Canonicalization algorithm addresses these concerns... The Schema Centric Canonicalization algorithm is intended to be complementary in a hand-in-glove manner to the processing of XML documents as carried out by the assessment of schema validity by XML Schema, canonicalizing its input XML instance with respect to all those representational liberties which are permitted thereunder. Moreover, the specification of Schema Centric Canonicalization heavily exploits the details and specification of the XML Schema validity-assessment algorithm itself. In XML Schema, the analysis of an XML instance document requires that the document be modeled at the abstract level of an information set as defined in the XML Information Set recommendation. Briefly, an XML document's information set consists of a number of information items connected in a graph. An information item is an abstract description of some part of an XML document: each information item has a set of associated named properties... Properties on each of these items, for example the [children] property of element information items, connect together items of different types in an intuitive and straightforward way. The representation of an XML document as an infoset lies in contrast to its representation as a node-set as defined in XPath. The two notions are conceptually quite similar, but they are not isomorphic. For a given node-set it is possible to construct a semantically equivalent infoset without loss of information; however, the converse is not generally possible. It is the infoset abstraction which is the foundation of XML Schema, and it is therefore the infoset abstraction we use here as the foundation on which to construct Schema Centric Canonicalization algorithm. The Schema Centric Canonicalization algorithm consists of a series of steps: creation of the input as an infoset, character model normalization, processing by XML-Schema assessment, additional infoset transformation, and serialization..." [cache] [April 12, 2002] "Beyond W3C XML Schema." By Will Provost. From XML.com. April 10, 2002. ['XSLT has proven to be a very successful technology, and has moved beyond the relatively narrow scope that drove its design. Even James Clark, XSLT's primary designer, never imagined the many uses XSLT would find. In "Beyond W3C XML Schema" Will Provost demonstrates that there are some aspects of document validation beyond the capabilities of W3C XML Schema. He describes the use of XPath with XSLT for reaching into documents and checking those constraints that can't be enforced with a schema.'] "The XML developer who needs to validate documents as part of application flow may choose to begin by writing W3C XML Schema for those documents. This is natural enough, but W3C XML Schema is only one part of the validation story. In this article, we will discover a multiple-stage validation process that begins with schema validation, but also uses XPath and XSLT to assert constraints on document content that are too complex or otherwise inappropriate for W3C XML Schema. We can think of a schema as both expressive and prescriptive: it describes the intended structure and interpretation of a type of document, and in the same breath it spells out constraints on legal content. There is a bias toward the expressive, though: W3C XML Schema emphasizes "content models", which are good at defining document structure but insufficient to describe many constraint patterns. This is where XPath and XSLT come in: we'll see that a transformation-based approach will let us assert many useful constraints and is in many ways a better fit to the validation problem. (In fact, one might define schema validation as no more than a special kind of transformation; see the paper of van der Vlist.) We'll begin by looking at some common constraint patterns that W3C XML Schema does not support very well and then develop a transformation-based approach to solving them... XPath and XSLT can form a second line of defense against invalid data. The value of this second stage in the validation architecture will be judged by what it can do that W3C XML Schema cannot. Here's a short list of constraint patterns XPath can express well. (1) Structural analysis of the tree as a whole; (2) Weakly-typed designs; (3) Finer control over use of subtypes -- say base types A and B are associated but subtype A2 should only see instances of B2, not B1 or B3, etc.; (4) Single values based on numeric or string calculation -- a number that must be a multiple of three, a string that must list values in a certain order; (5) Relationships between legal single values -- a checksum over a long list of values, or a rule limiting the total number of occurrences of a common token; (6) Constraints that span multiple documents -- for instance a dynamic enumeration where the legal values are listed in a second document, and so cannot be hardcoded into a schema... We've discovered a multi-stage validation architecture based entirely on W3C-standardized technology. Out in the world, another popular transformation-based approach is Schematron, an open source tool which specifies constraint definitions in its own language. Its vocabulary simplifies the XSLT structure shown in the previous section and relies on XPath for its constraint expressions. It also allows for both 'positive' and 'negative' assertions. The big difference is that a Schematron schema must be pre-compiled, or 'pre-transformed' if you will, into a validating stylesheet, which once created is the true counterpart to the pure-XSLT transformations used here..." [March 29, 2002] "W3C XML Schema Needs You." By Leigh Dodds. From XML.com. March 27, 2002. ['One of the consequences of complexity in an open specification is a decreased likelihood of interoperability in implementation. XML developers have been bumping into this problem with the W3C XML Schema language recently. Leigh Dodds covers these problems, and a call for developers to aid the progress of greater interoperability.] "The W3C XML Schema (XSD) specifications have drawn fire again recently, with a number of concerns being aired about an apparent lack of interoperability between implementations. Jonathan Robie, a member of the Schema Working Group, has issued a rallying cry for developers to unite and help push for interoperability... There was a resurgence of the 'XML Schema is too complex' debate on XML-DEV last week. While this is an oft debated topic, the issues have had a slightly different slant this time around with claims that XSD is so complex that it's proving extremely difficult to implement... A few constructive suggestions were circulated during the discussion, some more radical than others. Rob Griffin suggested producing a list of standard error messages for validators, which ought to help achieve some level of consistency across implementations, as well as clarifying the circumstances in which each error should arise. Andrew Watt recommended the addition of a use case document that would provide an additional means of tackling the specifications. Watt pointed to the XML Query documents as a good exemplar. Rick Jelliffe's suggestion to modularize XML Schema was the most radical. Jelliffe suggested that instead of a rewrite the schema specifications should be split into eight small sections which '...would allow greater modularity, let readers and implementers concentrate and advertise conformance on different parts, and fit in with ISO DSDL, for users who, say, want to use RELAX NG with XML Schemas primitive datatypes'. Jelliffe also commented that rather than criticizing XML Schema, the important first question should be to consider which schema language or combination of languages is most suited to a particular application domain. Jelliffe offered a prediction that document oriented systems will likely settle on DSDL, while database oriented applications will find XML Schemas most suitable..." [March 18, 2002] "Mastering XML Schemas." By Elliotte Rusty Harold. Presented at "XML & Web Services 2002 Conference" (Queen Elizabeth II Conference Centre, London, March 2002). [Tuesday 12 March, 2002.] [February 19, 2002] "XML Schema and RELAX NG Element Comparison." By Michael Fitzgerald. Reference posted to the RELAX NG TC list. "This document briefly compares XML Schema's 42 elements with RELAX NG's 28 elements. In the table that follows, the first column lists all the XML Schema elements while the second column lists any RELAX NG elements that have a one-to-one relationship, a comparable purpose, or only a roughly similar purpose to XML Schema elements. Elements unique to each language are also listed in separate tables below..." ['I have made an attempt to briefly compare the purpose of XML Schema's elements with RELAX NG's elements. The comparison appears in three tables totaling about 2 and 1/2 pages printed. I would appreciate any comments you have about this document...'] Note also the relax ng links on the Wy'east Communications web site. [February 14, 2002] Clark Updates Jing - A RELAX NG Validator in Java. James Clark has announced a new version of Jing with significant changes and revised documentation. Jing version '2002-02-13' implements the final RELAX NG 1.0 Specification and also implements parts of RELAX NG DTD Compatibility, specifically checking of ID/IDREF/IDREFS. James has "almost completely rewritten the validator using an improved algorithm. In the old algorithm, the state of the validation was represented by a stack of sets of patterns; in the new algorithm, the state is represented by a single pattern... The new release includes a documented API for Jing; in fact there are two APIs, a native API and JARV. James has rewritten the description of derivative-based validation to correspond to what's been implemented and to incorporate feedback received on the previous version from Murata-san and Kawaguchi-san... The Jing implementation is available for download as a JAR file and as a Win32 executable for use with the Microsoft Java VM. [Full context] [February 14, 2002] IBM Releases XML Schema Quality Checker Version 2.0. IBM alphaWorks labs has released an enhanced version of its XML Schema Quality Checker (SQC). SQC is "a program which takes as input documents containing XML Schemas written in the W3C XML schema language and diagnoses improper uses of the schema language. Where the appropriate action to correct the schema is not obvious, the diagnostic message may include a suggestion about how to make the fix. The updated version now provides direct validation of embedded schemas like those which may appear in WSDL documents or XForms. It includes bug fixes and now uses Xerces version 2.0.0. For Eclipse or WSAD users, the IBM XML Schema Quality Checker can now be installed as an Eclipse or WSAD plugin; it can also still be run as a standalone command line program." [Full context] [February 12, 2002] dtd2xs version 1.54. Announcement posted by Joerg Rieger. "We are pleased to announce a new release of 'DTD to XML Schema translator' [dtd2xs]. One may use it to translate a Document Type Definition (XML 1.0 DTD) into an XML schema (REC-xmlschema-1-20010502). The translator can map meaningful DTD entities onto named and therefore reusable XML Schema constructs such as <simpleType>, <attributeGroup> and <group>. The translator can map DTD comments onto XML Schema <documentation> elements. Freely available as a Java class, as a Web tool, and as Java application..." [February 11, 2002] "Combining the Power of W3C XML Schema and Schematron." By Eddie Robertsson. "This article shows how to combine W3C XML Schema and Schematron by inserting Schematron rules in the <xs:appinfo> element of the W3C XML Schema... After the W3C ratified W3C XML Schema as a full recommendation on May 2nd 2001 it has become clear that this is the most popular XML Schema language for developers. Many believed that W3C XML Schema would solve all the problems that existed with validation of XML documents but this was never the goal of W3C XML Schema... When W3C XML Schema is not powerful enough there are other options for developers. One option is to find a different XML Schema language that can express all the needed constraints. Another option is to add extra code to your application to check the things not expressible in the W3C XML Schema language. A third option, made available through one of W3C XML Schema's extension mechanisms, is to combine W3C XML Schema with another XML Schema language. This article will provide an explanation and several examples of how Schematron rules can easily be embedded within W3C XML Schemas. Schematron has its strengths where W3C XML Schema has its weaknesses (co-occurrence constraints) and its weaknesses where W3C XML Schema has its strengths (structure and data types). In the examples provided W3C XML Schema is used as far as possible and then the embedded Schematron rules are used to express what cannot be done with W3C XML Schema alone. The following four areas, which W3C XML Schema does not fully address, will be covered: dependant attributes, interleaving of elements, co-occurrence constraints and relationships between different XML documents. A short introduction to Schematron is provided but the reader will need a basic understanding of W3C XML Schema to benefit from the article..." [Posted note on '[email protected]': "I'm currently working on a paper that will explain the details of embedding Schematron rules in the <xs:appinfo> element in a W3C XML Schema. I've put up a draft which contains some background, introduction to Schematron, examples of embedded Schematron rules and how the validation process works. The draft also contains a link to a zip file with all the examples used so you can try it out yourself. All comments are welcome..." [January 24, 2002] "Relax NG, Compared." By Eric van der Vlist. From XML.com. January 23, 2002. ['The RELAX NG schema language explained and compared to W3C XML Schemas.] "This article is a companion to two different works already published on XML.com: my introduction to W3C XML Schema is a tutorial introducing the language's main features, with a progression which I hope is intuitive; and my comparison between the main schema languages, an attempt to provide an objective and practical feature-by-feature comparison between XML schema languages. In this new article, I have taken the same approach as the one used in the W3C XML Schema tutorial but this time I've implemented the schemas using RELAX NG... it provides a good starting point for those of us who know W3C XML Schema and want to quickly point out the differences with RELAX NG. Links are provided throughout to the corresponding sections of the W3C XML Schema tutorial, and you are encouraged to follow both simultaneously... Throughout this comparison, we have seen that one of the main differences between the two languages is a matter of style: while RELAX NG focuses on generic 'patterns', W3C XML Schema has differentiated these patterns into a set of distinct components (elements, attributes, groups, complex and simple types). The result is on one side a language which is lightweight and flexible (RELAX NG) and on the other side a language which gives more 'meaning' or 'semantic' to the components that it manipulates (W3C XML Schema). The question of whether the added features are worth the price in terms of complexity and rigidity is open, and the answer probably depends on the applications. Independently of this first difference between the two, the different positions regarding 'non-determinism' between RELAX NG, which accepts most of the constructs a designer can imagine, and W3C XML Schema, which is very strict, mean that a number of vocabularies which can be described by RELAX NG cannot be described by W3C XML Schema. A way to summarize this is to notice that an implementation such as MSV (the 'Multi Schema Validator' developed by Kohsuke Kawaguchi for Sun Microsystems) uses a RELAX NG internal representation as a basis to represent the grammar described in W3C XML Schema and DTD schemas. This seems to indicate that RELAX NG can be used as the base on which object oriented features such as those of W3C XML Schema can be implemented. The value of an XML-specific object-oriented layer is still to be determined, though, since generic object-oriented tools should be able to generate RELAX NG schemas directly..." See W3C XML Schema and "RELAX NG." [January 09, 2002] "XML and WebSphere Studio Application Developer. Part 1: Developing XML Schema." By Christina Lau (Senior Technical Staff Member, IBM Toronto Lab). In IBM WebSphere Developer Technical Journal (December 30, 2001). "IBM's WebSphere Studio Application Developer is a new application development product that supports the building of a large spectrum of applications using different technologies such as JSP, servlets, HTML, XML, Web services, databases, and EJBs. This is the first of a series of articles that will focus on the XML tools provided with Application Developer. This article covers the XML Schema Editor. It provides a birds-eye view of the XML Schema Editor that is included in WebSphere Studio Application Developer. In future articles, we will cover more advanced topics such as: (1) Creating schemas from multiple documents; (2) Identity constraints; (3) Generating Java beans from XML Schema; (4) Generating XML documents from XML Schema; (5) How the wildcard works. The XML Schema Editor is a visual tool that supports the building of XML Schema that conforms to the XML Schema Recommendation Specification (May 2001)..." [December 20, 2001] "XML Schema tome 0: Introduction." Recommandation du W3C du 2 Mai 2001. From W3C XML Schema Recommendation Part 0. Translated by Jean-Jacques Thomasson. Referenced by Eric van der Vlist: "It's my pleasure to announce the publication of an excellent translation of XML Schema part 0 by Jean-Jacques Thomasson on XMLfr...". Note: "Ce document est une traduction de la recommandation XML Schema du W3C, datée du 2 mai 2001. Cette version traduite peut contenir des erreurs absentes de l'original, introduites par la traduction elle-même." See the W3C web site for XML Schema. [December 13, 2001] "Comparing XML Schema Languages." By Eric van der Vlist. From XML.com. December 12, 2001. ['DTDs, W3C XML Schema, RELAX NG: what's the difference? And which is the best tool for the job? There is a healthy ecology in XML schema technologies: ranging from DTDs, through the W3C's XML Schema Definition Language to newer entrants such as RELAX NG and Schematron. In his article, Eric gives us a timeline of XML schema languages, and compares the strengths of each of these technologies. Eric's talk in Orlando "XML Schema Languages" was standing-room only.'] "This article explains what an XML schema language is and which features the different schema languages possess. It also documents the development of the major schema language families -- DTDs, W3C XML Schema, and RELAX NG -- and compares the features of DTDs, W3C XML Schema, RELAX NG, Schematron, and Examplotron... The English language definition of schema does not really apply to XML schema languages. Most of the schema languages are too complex to 'present to the mind' or to a program the instance documents that they describe, and, more importantly and less subjectively, they often focus on defining validation rules more than on modeling a class of documents. All XML schema languages define transformations to apply to a class of instance documents. XML schemas should be thought of as transformations. These transformations take instance documents as input and produce a validation report, which includes at least a return code reporting whether the document is valid and an optional Post Schema Validation Infoset (PSVI), updating the original document's infoset (the information obtained from the XML document by the parser) with additional information (default values, datatypes, etc.) One important consequence of realizing that XML schemas define transformations is that one should consider general purpose transformation languages and APIs as alternatives when choosing a schema language... One of the key strengths of XML, sometimes called 'late binding,' is the decoupling of the writer and the reader of an XML document: this gives the reader the ability to have its own interpretation and understanding of the document. By being more prescriptive about the way to interpret a document, XML schema languages reduce the possibility of erroneous interpretation but also create the possibility of unexpectedly adding 'value' to the document by creating interpretations not apparent from an examination of the document itself. Furthermore, modeling an XML tree is very complex, and the schema languages often make a judgment on 'good' and 'bad' practices in order to limit their complexity and consequent validation processing times. Such limitations also reduce the set of possibilities offered to XML designers. Reducing the set of possibilities offered by a still relatively young technology, that is, premature optimization, is a risk, since these 'good' or 'bad' practices are still ill-defined and rapidly evolving. The many advantages of using and widely distributing XML schemas must be balanced against the risk of narrowing the flexibility and extensibility of XML.There are currently no perfect XML Schema languages. Fortunately, there are a number of good choices, each with strengths and weaknesses, and these choices can be combined. Your job may be as simple as picking the right combination for your application." "Schema Languages Comparison." Thursday, December 13, 2001. XML 2001 Conference. 7:30 PM - 9:00 PM. Town Hall Meeting. Moderator: Lauren Wood. Analysts: John Cowan, Norman Walsh. DTD Team: Tommie Usdin (lead), Debbie Lapeyre, Steve de Rose. RELAX NG: James Clark, Murata Makoto. Schematron: Rick Jelliffe, Eddie Robertsson, Francis Norton. W3C Schemas: Henry Thompson (lead), Martin Gudgin, Priscilla Walmsley. An opportunity to find out more about the strengths and weaknesses of currently available schema languages This Town Hall will give you more information about when to use W3C Schemas, Schematron, RELAX NG or DTDs. This session bring together experts in four different schema languages, so that you can learn the strengths and weaknesses, and when each schema language is likely to be most useful. Schema language experts in four languages were asked to participate and they formed four teams, one each for W3C Schemas, Schematron, RELAX NG and DTDs. Each team created schemas for a set of document types (also created by the teams). At the Town Hall meeting, two analysts will report on the schemas, and then the open discussion will begin. Attendees will be able to ask questions of the team members and the analysts. Note that not all team members from all teams are able to attend the session, although all participated in the design of the schemas..." [December 11, 2001] SoftQuad's Enhanced XMetaL 3 Supports W3C XML Schema and Collaborative Authoring. An announcement from SoftQuad Software describes the January 2002 release of XMetaL 3, Softquad's flagship XML content creation software. The new version of XMetaL "features innovative ease-of-use and collaboration capabilities for content authors and provides developers with a rich XML development environment. XMetaL 3 is the first customizable XML editor with a rich development environment to support XML Schema, an essential standard developed by the W3C to define common languages for specific business applications. XML Schema enables companies to exchange information seamlessly with partners, customers, and suppliers. XMetaL 3 is a validating XML editor within an open and scriptable development environment that allows developers to use common Web development and programming skills to create integrated XML content applications. With an extensive COM and JAVA API comprising over 300 interfaces, support for DOM, CSS, XSL and standard scripting languages, XMetaL gives developers the power to control exactly how XML is displayed and entered by end users. New XMetaL features for end users include support for revision marking, preview in HTML and PDF, enhanced integration with Microsoft Office, workgroup document sharing, and enterprise document sharing." W3C XML Schema Support: "(1) XMetaL will load a W3C Schema and validate documents using features that are common to both W3C Schema and DTDs as well as important features unique to W3C Schema; (2) Supports the structural validation features in demand by industry XML standards organizations such as RIXML; (3) Supports locally-scoped element declarations, occurrence indicators, and substitution group elements, and more." [Full context] [December 11, 2001] "What's a Schema Anyway?" By Dave Peterson. In XML Files: The XML Magazine Issue 32 (December 2001). Edited by Dianne Kennedy. "... [DTD syntax is] a concise language, special purpose for DTDs. It was designed that way, because back in the '80s there were no authoring tools already existing; DTDs had to be read and written entirely by hand. The SGML designers considered writing DTDs using SGML 'tag' markup, but found it too hard to read. On the other hand, now there are tools for authoring XML (and SGML). And there is in the XML culture a desire to do everything with tags when possible. So the Schema designers chose to describe a Schema using an XML document -- that is, using 'tag' syntax. This makes written Schemas (properly called Schema Documents) somewhat 'wordier' -- more difficult to read -- than DTDs, in the raw, but also makes it easier to find tools to help deal with them. The standard that describes schemas makes an explicit distinction between the abstract set of information (the Schema) and the written description thereof (one or more Schema Documents). Not only does this make it easier to understand, it also makes it easier to consider alternate description languages..." [December 07, 2001] Xerces-C++ XML Parser Version 1.6.0 Provides Full Support for W3C XML Schema Recommendation. A communiqué from Tinny Ng (XML Parsers Development, IBM Toronto Laboratory) announces the release of the Apache Xerces-C++ XML parser version 1.6.0, including full support for the W3C XML Schema Recommendation. Xerces-C++ is "a validating XML parser written in a portable subset of C++; Xerces-C++ makes it easy to give your application the ability to read and write XML data. A shared library is provided for parsing, generating, manipulating, and validating XML documents. The parser features: (1) Conformance to the XML Specification 1.0; (2) Tracking of latest DOM [Level 1.0], DOM [Level 2.0], SAX/SAX2, Namespace, and XML Schema specifications; (3) Source code, samples, and documentation; (4) Programmatic generation and validation of XML; (5) Pluggable catalogs, validators and encodings; (6) High performance; (7) Customizable error handling." The latest version of Xerces-C++ includes a port to FreeBSD and support for specifying a schema location through a method call. Source code and binaries are available for several platforms. [Full context] [November 29, 2001] Schema Toolkit. "XML-Schema Toolkit is an innovative XML parsing, data-binding and schema validation tool. XML-Schema Toolkit can help turn XML standards into implementations. Using the Schema Coder GUI application, an XML schema is transformed into C++ code, enabling the rapid creation of XML schema-valid vocabularies. It also provides a framework to use these vocabularies, once they have been implemented. Version 0.12 contains SchemaCoder, which can convert XML schemas to C++ code. The web site now has better documentation, explaining the aims of the toolkit. The toolkit is currently free to use, but not to redistribute. It works for Windows 98, NT and upwards, and the code integrates with Microsoft's Visual C++ 6..." See also the description. [November 21, 2001] "GXS Releases XML Schema Plug-in. Saves Time Converting Between XML and Other Formats." In eai Journal (November 13, 2001). ['Mapping transactions from proprietary data formats, such as those for enterprise ERP or legacy systems, into XML is a time-consuming process. GXS XML Schema Plug-in saves time in this mapping process by allowing the use of XML schemas to help define the structure, content, and semantics of XML documents.'] "GE Global eXchange Services (GXS) has released XML Schema Plug-in, e-business software that will allow companies to more quickly integrate XML transactions into back office systems. The new software can help companies save time and reduce costs associated with exchanging XML documents with suppliers, customers, and other trading partners. The Plug-in works in conjunction with the GXS data transformation engine, allowing customers to import XML schemas into the mapping tool, and then validate XML messages against the schemas. Platforms supported by the Plug-in include Windows and Unix. Said Jim Rogers [GXS general manager of integration solutions]: 'Clients who are implementing their e-buy process using XML will find that this capability can save them a great deal of time and effort in integrating XML B2B transactions with their ERP or legacy business applications'..." [November 12, 2001] XSV (XML Schema Validator) Version 1.4. This version introduces a 'derivation-by-restriction experiment'. "The web interface, the self-installer, and the sources for XSV, our W3C XML Schema validator, have all been updated with a new version. Version 1.4 introduces a cheap-but-effective approximation to enforcement of the constraints on derivation by restriction for complex type definitions. This works by enforcing the subset invariant, and rejects any content model for a type definition derived by restriction which allows anything not allowed by the base type definition's content model. This is slightly weaker than the REC: i.e., everything it rules out is ruled out by the REC, but a few things ruled out by the REC will not be caught. Note this is not what the REC envisages, but it will go a lot further towards enforcing interoperability between XSV and other processors which do enforce the REC as intended. Nothing is as good as full conformance, but I hope this step, which only took about three hours to implement, will be of use never-the-less..." From Henry S. Thompson 2001-11-12. [November 01, 2001] "Extending Schemas." Edited by Paul Kiel (HR-XML). Contributors: Members of the HR-XML Technical Steering Committee. Working Draft 2001-09-11, Version 1.0. "HR-XML Consortium specifications are meant to model specific business practices. Recognizing that it cannot satisfy the needs of all implementers all the time, the need for a standard way to extend schemas becomes clear. This document is aimed to provide guidance regarding the extension of XML Schemas so that trading partners can exchange information in the real world as well as experiment with new data that could be incorporated into a future specification... Given that extension is a reality, how can we accommodate extensions without undermining the principle of open standards? This document is meant to provide guidance on the best practice for extending schemas. Its goal is to show: (1) Official endorsement of different methods for implementation; (2) Conventions for creating extensions to encourage consistency... This document focuses on XML Schema extension methods. Where possible, references to DTD equivalent issues are included. Addressing all possible extension methods for DTDs (i.e., internal subsets) is not in scope... As discussed here, 'extending' is meant to 'add additional elements and attributes to an existing schema'. This is not to be confused with how Roger Costello uses it in the XML Schemas: Best Practices discussion; he refers to 'extending' meaning adding functionality to schema that does not currently exist... The Technical Steering Committee has approved two methods that enable extension of HR-XML schemas without undermining an open standards mission. The 'wrapper' and 'ANY' techniques are explained herein. Additionally, a 'Namespace' extension method was examined and rejected, details in Appendix C..." [Comment from Chuck Allen: "Like every other organization developing XML schemas, HR-XML is wrestling with 'standard' approaches to extending 'standards'. The editors welcome comments on the extension document; send email to Chuck Allen or Paul Kiel. See: (1) "HR-XML Consortium"; (2) Elists for lists.hr-xml.org. [source .DOC] [November 01, 2001] "[XML Schema] Enumeration Extension." By Paul Kiel (HR-XML). 2001-10-29. 5 pages. "HR-XML Consortium work groups are increasingly grappling with a common problem regarding the use of enumerations in schemas. The traditional use of enumerations consists of a fixed number of provided values, which are determined at the time of the schema design. The problem arises when a business process is modeled with a schema that includes enumerated lists that do not cover 100% of the foreseen cases. The main question arises: how can a work group standardize enumerated values when less than 100% of the foreseeable values are known at design time? The objective of this text is to endorse a method for standardizing enumerated values without preventing extensions to cover unknown or trading partner specific values... The two most debated approaches to standardizing incomplete enumeration lists are a union of values with a string, essentially a convention, and a union of values with a string pattern, known as pattern extension... The Technical Steering Committee has determined that while the principle of separating data from metadata has significant merit, in this case, making the best use of the parser can be more important. Consequently, it endorses the Pattern Extension method of standardization of incomplete enumeration lists when most of the values are known. When only a few values are know, the Convention Method is acceptable as well as using an atomic data type such as a simple string..." Comment from Chuck Allen: "We regard this document on handling enumerations as a schema design technique with some use in certain circumstances. We're also interested in the notion of 'interfaces to taxonomies' -- being able to reference or (carry along) taxonomies that would provide data values. One of our use cases is posting job openings to job boards; each job board has a different classification system (these usually translate to drop-down lists in a web user interface). We definitely will not take on the task of try to develop standard skill and job taxonomies, but we want to be able to plug-in those in use by major job boards and by government agencies (US Dept of Labor and many other national labor boards have developed skill/job taxonomies). While our use case is specific to HR, the basic problem of referencing and using external taxonomies is not unique to our problem domain..." See: (1) "HR-XML Consortium"; (2) Elists for lists.hr-xml.org. [source .DOC] [October 30, 2001] New Implementation of the W3C/LTG Validator for XML Schema (XSV). A posting from Henry S. Thompson (HCRC Language Technology Group, University of Edinburgh) announces the availability of XSV Version 1.3. XSV (Validator for XML Schema) is an open source (GPLed) work-in-progress attempt at a conformant schema-aware processor, as defined by the W3C Recommendation for XML Schema. A significant change has been introduced in version 1.3, which "switches from using DTD to pre-validate schema documents to using schema-for-schemas. Hitherto, XSV has pre-validated all schema documents involved in a schema-validation episode with the DTD for schemas. This was both not quite right, in that it meant certain constraints were not enforced, because not expressed in the DTD, and messy, in that if a schema document included an internal subset, it was tricky to preserve it. With the advent of version 1.3, all schema documents are now pre-validated with a pre-compiled version of the schema for schemas itself. Even if a DOCTYPE is present, XML 1.0 validation will not be performed, although processing will reflect attribute defaults and general entity bindings, as required by XML 1.0." The authors have done their best with regression testing to ensure that the new XSV release is working properly, but there is potential for introduction of new vulnerabilities and backwards incompatibilities; feedback from the public is solicited. Both the online web version and the standalone/download implementation of XSV have been upgraded to XSV version 1.3. The XSV Schema validator has been developed by Henry S. Thompson and Richard Tobin, with contributions (Web interface) by Dan Connolly. [Full context] [October 26, 2001] Apache XML Project Releases Xerces-C++ Parser Version 1.5.2 with Enhanced Schema Support. A posting from Tinny Ng (XML Parsers Development, IBM Toronto Laboratory) announces the release of the Xerces C++ 1.5.2 XML parser from the Apache XML Project. The Xerces C++ Parser Version 1.5.2 provides additional support for W3C XML Schema. Highlights of the new release include: (1) More Schema Subset support (see http://xml.apache.org/xerces-c/schema.html for details and restriction) (2) XMLPlatformUtils::Initialize/Terminate() pair of routines can now be called more than once within a process; (3) Progressive parse support in SAX2XMLReader; (4) Project files for BCB 5; (5) runConfigure script to accept multiple compiler and linker options; (6) more bug fixes, and performance improvement." The distribution includes source code as well as binaries for AIX, HP11, Linux, Solaris, and Windows. [Full context] [October 19, 2001] "Modeling XML Vocabularies with UML: Part III." By Dave Carlson. From XML.com. October 10, 2001. ['The third and final part of Dave Carlson's series on modeling XML vocabularies covers a specific profile of UML for use with XML Schema, and describes how UML can contribute to the analysis and design of XML applications.' See previously Part I and Part II.] "This article is the third installment in a series on using UML to model XML vocabularies. The examples are based on a simple purchase order schema included in the W3C XML Schema Primer, and we've followed an incremental development approach to define and refine this vocabulary model with UML class diagrams. The first objective of this third article is to complete the process of refining the PO model so that the resulting schema is functionally equivalent to the one contained in the XSD Primer. The second objective is to broaden our perspective for understanding how UML can contribute to the analysis and design of XML applications... The following list summarizes several goals that guide our work. (1) Create a valid XML schema from any UML class structure model, as described in the first two parts of this series. (2) Refine the conceptual model to a design model specialized for XML schema by adding stereotypes and properties that are based on a customization profile for UML. (3) Support a bi-directional mapping between UML and XSD, including reverse engineering existing XML schemas into UML models. (4) Design and deploy XML vocabularies by assembling reusable modules. Integrate XML and non-XML information models in UML; to represent, for example, both XML schemas and relational database schemas in a larger system... Even this relatively narrow scope covers a broad terrain. The following introduction to a UML profile for XML adds a critical step toward all of these goals. These extensions to UML allow schema designers to satisfy specific architectural and deployment requirements, analogous to physical database design in a RDBMS. And these same extensions are necessary when reverse engineering existing schemas into UML because we must map arbitrary schema structures into an object-oriented model... One of the benefits gained by using UML as part of our XML development process is that it enables a thoughtful approach to modular, maintainable, reusable application components. In the first two parts of this series, the PurchaseOrder and Address elements were specified in two separate diagrams, implying reusable submodels. UML includes package and namespace structures for making these modules explicit and also specifying dependencies between them... A package, shown as a file folder in a diagram, defines a separate namespace for all model elements within it, including additional subpackages. These UML packages are a very natural counterpart to XML namespaces. A dashed line arrow between two packages indicates that one is dependent on the other. When used in a schema definition, each package produces a separate schema file. The implementation of dependencies varies among alternative schema languages. For DTDs they might become external entity references. For the W3C XML Schema, these package dependencies create either <include> or <import> elements, based on whether or not the target namespaces of related packages are equal. A dependency is shown from the PO package to the XSD_Datatypes package, but an import element is not created because this datatype library is inherently available as part of the XML Schema language. This object-oriented approach to XML schema design facilitates modular reuse, just as one would do when using languages such as Java or C++..." [October 17, 2001] Sun Microsystems Releases Generalized Schema-Related Tools for Validation and Conversion. A posting from Kohsuke KAWAGUCHI (Sun Microsystems) announces the availability of an updated version of Sun's Multi-Schema XML Validator (MSV), along with three new schema-related tools. The new Sun XML Instance Generator "is a Java technology tool to generate various XML instances from several kinds of schemas; it supports DTD, RELAX Namespace, RELAX Core, TREX, and a subset of XML Schema Part 1. The RELAX NG Converter is a tool to convert schemas written in various schema languages to their equivalent in RELAX NG. The new Multi-Schema XML Validator Schematron add-on is a Java tool to validate XML documents against RELAX NG schemas annotated with Schematron schemas. By using this tool, you can embed Schematron constraints into RELAX NG schemas, making it easy to write many constraints that are difficult to achieve by RELAX NG alone." [Full context] [October 06, 2001] "Possible Extensions to RELAX NG. DSDL Use Cases." By Martin Bryan (The SGML Centre). BSI IST/41. Posted to the RELAX-NG mailing list. "In talking to James Clark earlier today about the relationship between RELAX NG and the proposed new ISO Document Structure Definition Language (DSDL) James asked if I could provide some use cases that would justify the initial set of requirements that the DSDL proposal contained. The attached document starts by listing the requirements identified as being essential for DSDL, and then provides a set of use case statements that seeks to justify each requirement. It also contains brief use cases for supporting three optional features of SGML that are not supported by XML, and not listed as being requirements for DSDL, but for which cases can be made within data streams being used by businesses..." See "Document Schema Definition Language (DSDL) Proposed as ISO New Work Item." (June 12, 2001). [October 02, 2001] Zvon XML Schema Reference. [Another cool tool] Prepared by Jiri Jirat and Miloslav Nic. The Schema reference is based on the W3C XML Schema Recommendations [updated from CR specifications]. The reference tool consists of two parts: (1) A Schema browser, based on the analysis of normative XML Schema; (2) A DTD browser, based on the analysis of non-normative DTD. The reference features hyperlinked clickable indexes and schemas: clicking on 'Annotation Source' or 'Go to standard' leads you to the relevant part of the specification. [September 24, 2001] "XML Schema Quick Reference Cards." Prepared by Danny Vint. See: (1) XML Schema - Structures Quick Reference Card, and (2) XML Schema - Data Types Quick Reference Card. XML-DEV posting: "I've just uploaded 2 quick reference cards that I built for the XML Schema Data types and Structures specifications. These cards are available in PDF format. If you download and print them realize that they are setup for 8.5 x 14 paper. If when you print these files, just set the 'Fit to page' and Landscape mode to get a properly scaled copy of these documents. I'm also in the process of moving my 'XML Family EBNF Productions Help' to this new site as well as updating the content. This isn't completed; I'm currently showing the older version that I have previously published..." [September 21, 2001] "Modeling XML Vocabularies with UML: Part II." By Dave Carlson. From XML.com. September 19, 2001. "Mapping UML Models to XML Schema: This is where the rubber meets the road when using UML in the development of XML schemas. A primary goal guiding the specification of this mapping is to allow sufficient flexibility to encompass most schema design requirements, while retaining a smooth transition from the conceptual vocabulary model to its detailed design and generation. A related goal is to allow a valid XML schema to be automatically generated from any UML class diagram, even if the modeller has no familiarity with the XML schema syntax. Having this ability enables a rapid development process and supports reuse of the model vocabularies in several different deployment languages or environments because the core model is not overly specialized to XML... The default mapping rules described in this article can be used to generate a complete XML schema from any UML class diagram. This might be a pre-existing application model that now must be deployed within an XML web services architecture, or it might be a new XML vocabulary model intended as a B2B data interchange standard. In either case, the default schema provides a usable first iteration that can be immediately used in an initial application deployment, although it may require refinement to meet other architectural and design requirements. The first article in this series presented a process flow for schema design that emphasized the distinction between designing for data-oriented applications versus text-oriented applications. The default mapping rules are often sufficient for data-oriented applications. In fact, these defaults are aligned with the OMG's XML Metadata Interchange (XMI) version 2.0 specification for using XML as a model interchange format. This approach is also well aligned with the OMG's new initiative for Model Driven Architecture (MDA). Text-oriented schemas, and any other schema that might be authored by humans and used as content for HTML portals, often must be refined to simplify the XML document structure. For example, many schema designers eliminate the wrapper elements corresponding to an association role name (but this also prevents use of the XSD <all> model group). This refinement and many others can be specified in a vocabulary model by setting a new default parameter for one UML package, which then applies to all of its contained classes..." See: (1) Part I of Carlson's article; (2) "Conceptual Modeling and Markup Languages." [September 13, 2001] Altova Releases Comprehensive Tool Suite for Advanced XML Application Development. A posting from Alexander Falk announces the final production release of the XML Spy 4.0 Suite, "a comprehensive product-line of easy-to-use software tools, facilitating all aspects of XML application development. The XML Spy 4.0 Suite consists of the XML Spy 4.0 Integrated Development Environment (IDE), the XML Spy 4.0 XSLT Designer, and the XML Spy 4.0 Document Editor, a comprehensive tool-set for all XML application development. The XML Spy 4.0 Integrated Development Environment is a solution for developing XML-based applications, making it easy to create and manage XML documents, stylesheets, and schemas. The XSLT Designer is an innovative new approach to automate writing of complex XSLT Stylesheets using an intuitive, drag-and-drop user interface. The XML Spy 4.0 Document Editor is available as a browser plug-in or a stand-alone application; it offers a word-processor style free-flow WYSISYG editor for XML documents, empowering non-technical users to create and edit XML documents." A 30-day evaluation version is available for download. [Full context] [September 07, 2001] W3C Presents a First Public Release of the XML Schema Test Collection. A posting from Henry S. Thompson announces a "first public release of the W3C XML Schema Test Collection, made possible by a substantial contribution of tests from Microsoft. Both positive and negative expected outcomes are tested with respect to a range of core XML Schema features. [The tests are presented] in a standard form which tabulates (without ratifying) the test materials, together with a brief description, and the outcomes for each one expected by the contributor. The document also includes the first of what the W3C team hopes will be many outcome tabulations for a publically available XML Schema processor... the column labelled 'Expected' means the outcome expected by the contributor [not necessarily what's expected by the W3C WG]. For the test file(s) present which has/have extension .xsd, its/their conformance to the XML Schema REC's definition of valid XML representations of XML Schemas is what is at issue. When a test file with extension .xml is present as well, its schema-validity is at issue as well." Thompson reports that the W3C team already has in hand an additional contribution of tests from NIST; these will be added soon to augment the 100+ tests from Microsoft. The test materials are available for download from the W3C web site as a single package, distributed under the W3C Document License. [Full context] [cache] [September 04, 2001] DTDinst Tool Converts XML DTDs into XML Instance Format. A posting from James Clark announces the availability of a DTD converter 'DTDinst' which converts XML DTDs into XML instance format. "The XML instance can be in either a format specific to DTDinst or can be in RELAX NG format." DTDinst-specific output format is documented in RELAX NG non-XML syntax and in RELAX NG format. The key feature of DTDinst "is its handling of parameter entities: it is able to reliably turn parameter entity declarations and references into a variety of higher-level semantic constructs. It can do this even in the presence of arbitrarily deep nesting of parameter entity references within parameter entity declarations. At the same time, it accurately follows XML 1.0 rules on parameter entity expansion, so that any valid XML 1.0 DTD can be handled. If a parameter entity is used in a way that does not correspond to any of the higher-level semantics constructs supported by DTDinst, then references to that parameter entity will be expanded in the DTDinst output. DTDinst is available as a precompiled JAR file; the source is also available." Clark provides an XSLT stylesheet that "converts DTDinst format to RELAX NG; it has many more limitations than the converter builtin to DTDinst, but it may be useful as a basis for XSLT-based processing of DTDinst format." James writes: "Feedback is welcome, especially on any DTDs it doesn't handle well and on additional features that you would like to see..." [Full context] [August 24, 2001] "Semantic Data Modeling Using XML Schemas." By Murali Mani, Dongwon Lee, and Richard R. Muntz (Department of Computer Science, University of California, Los Angeles, CA). [To be published] in Proceedings of the 20th International Conference on Conceptual Modeling (ER 2001), Yokohama, Japan, November, 2001. "Most research on XML has so far largely neglected the data modeling aspects of XML schemas. In this paper, we attempt to make a systematic approach to data modeling capabilities of XML schemas. We first formalize a core set of features among a dozen competing XML schema language proposals and introduce a new notion of XGrammar. The benefits of such formal description is that it is both concise and precise. We then compare the features of XGrammar with those of the Entity-Relationship (ER) model. We especially focus on three data mod- eling capabilities of XGrammar: (a) the ability to represent ordered binary relationships, (b) the ability to represent a set of semantically equivalent but structurally different types as 'one' type using the closure properties, and (c) the ability to represent recursive relationships... Ordered relationships exist commonly in practice such as the list of authors of a book. XML schemas, on the other hand, can specify such ordered relationships. Semantic data modeling using XML schemas has been studied in the recent past. ERX extends ER model so that one can represent astyle sheet and a collection of documents conforming to one DTD in ERX model. But order is represented in ERX model by an additional order attribute. Other related work include a mapping from XML schema to an extended UML, and a mapping from Object-Role Modeling (ORM) to XML schema . Our approach is different from these approaches: we focus on the new features provided by an XML Schema -- element-subelement relationships, new datatypes such as ID or IDREF(S), recursive type definitions, and the property that XGrammar is closed under union, and how they are useful to data modeling... The paper is organized as follows. In Section 2, we describe XGrammar that we propose as a formalization of XML schemas. In Section 3, we describe in detail the main features of XGrammar for data modeling. In Section 4, we show how to convert an XGrammar to EER model, and vice versa. In Section 5, an application scenario using the proposed XGrammar and EER model is given. Finally, some concluding remarks are followed in Section 6. ... [Conclusions:] In this paper, we examined several new features provided by XML schemas for data description. In particular, we examined how ordered binary relationships 1:n (through parent-child relationships and IDREFS attribute) as well as n:m (through IDREFS attribute) can be represented using an XML schema. We also examined the other features provided by XML grammars -- representing recursive relationships using recursive type definitions and union types. The EER model, conceptualized in the logical design phase, can be mapped on to XGrammar (or its equivalent) and, in turn, mapped into other final data models, such as relational data model, or in some cases, the XML data model itself (i.e., data might be stored as XML documents themselves). We believe that work presented in this paper forms a useful contribution to such scenarios." Also available in Postscript format. [cache PDF, Postscript] [August 23, 2001] "Understanding W3C Schema Complex Types." By Donald Smith. From XML.com. August 22, 2001. "Are W3C XML Schema complex types so difficult to understand that you shouldn't even bother trying? Kohsuke Kawaguchi thinks so; or so he claimed in his recent XML.com article, in which he offered assurances that you can write complex types without understanding them. My response to that assertion is to ask why would you want to write complex types without understanding them, especially when they are easily understandable? There are four things you need to know in order to understand complex types in W3C Schemas... One of the most important, but least emphasized, aspects of W3C schemas is the type hierarchy. The importance of the type hierarchy can hardly be overstated. Why? Because the syntax for expressing types in schemas follows precisely from the type hierarchy. Schema types form a hierarchy because they all derive, directly or indirectly, from the root type. The root type is anyType. (You can actually use anyType in an element declaration; it allows any content whatsoever.) The type hierarchy first branches into two groups: simple types and complex types. Here we encounter the first two of the four things you need to know in order to understand complex types: first, derivation is the basis of connection between types in the type hierarchy; and, second, the initial branching of the hierarchy is into simple and complex types. It's no wonder that people get confused about complex types. They generally don't realize that all complex types are divisible into two kinds: those with simple content and those with complex content. The reason why people don't generally realize this is because they normally learn the abbreviated syntax first. But, as we've seen, if you learn the full syntax and the logic behind it first, then the abbreviated syntax, and complex types in general, cease to be a befuddingly conundrum. If all of this is now as clear to you as it is to me, you don't have to trust anyone's assurances that you should use complex types without understanding them. You can now use and understand them..." [August 2001] "W3C XML Schema: DOs and DON'Ts." By Kohsuke Kawaguchi (Sun Microsystems). "It's easy to learn and use W3C XML Schemas once you know how to avoid the pitfalls. Here are some DOs. You should at least learn the following things. (1) DO use element declarations, attribute groups, model groups and simple types. (2) DO use XML namespaces as much as possible. Learn the correct way to use them. Here are some DON'Ts: [3] DO NOT try to be a master of XML Schema; it would take months. [4] DO NOT use complex types, (global) attribute declarations, and notations. [5] DO NOT use local declarations. [6] DO NOT use substitution groups. [7] DO NOT use schema without the targetNamespace attribute — AKA chameleon schema..." [August 18, 2001] XSD documentation generator. Preliminary version. By Christopher R. Maden. ['... I need a stylesheet that when applied will report the metadata for a .xsd stylesheet (similar to the one that Microsoft has posted to their website for .xdr reporting...'] Chris replies: "I have one that handles simple features of XSD (basically, as much as I needed for a specific project) and reports the documentation and structure of the schema. It's rather crude right now; if you want to tweak the layout or add features, please feel free. (I would appreciate any mods being shared.) The documentation generator is at http://crism.maden.org/consulting/pub/xsl/xsd2html.xsl. There's a correspondingly-featured DTD generator at http://crism.maden.org/consulting/pub/xsl/xsd2dtd.xsl... Neither has any documentation right now; more as it is..." [cache] [August 16, 2001] Wrox Press Publishes Major Reference Tool for XML Schemas. Wrox Press has published a full-length volume on XML Schemas in its 'Programmer to Programmer' Series. Professional XML Schemas has been authored by Kurt Cagle, Jon Duckett, Oliver Griffin, Stephen Mohr, Francis Norton, Nikola Ozu, Ian Stokes-Rees, Jeni Tennison, and Kevin Williams. Professional XML Schemas "exhaustively details the W3C XML Schema language, and teaches the new syntax in an intuitive and logical way. [It documents] how to declare elements and attributes, how to create complex content models, how to work with multiple namespaces, and how to use XML Schemas in real-world situations. A number of practical case studies illustrate the design and creation of schemas in the diverse worlds of relational databases, document management, and e-commerce applications." The book covers all major aspects of schema application, including: "(1) A complete guide to XML Schema Syntax; (2) Using XML Schema built-in types, and deriving new types; (3) Working with XML Schemas and XML Namespaces; (4) Creating identity and uniqueness constraints; (5) Good schema design, illustrated in a number of different areas; (6) Working with schemas and XSLT; (7) Writing XML Schemas for working with SOAP; (8) Integrating Schematron and XML Schemas." Reference tools in appendices include Schema Element and Attribute Reference, Schema Datatypes Reference, UML Reference, Tools and Parsers, and Bibliography and Further Reading. [Full context] [August 11, 2001] "Information Supply Chain: XML Schemas Get the Nod." By Solomon H. Simon. In Intelligent Enterprise (July 23, 2001). ['Now that XML Schemas have reached final recommendation status, they are more attractive than DTDs.'] "In spite of the kick-start that B2B e-commerce provided for XML, many companies held back because of their perception that XML lacked standards. But now that XML Schemas have been given final recommendation status by the World Wide Web Consortium (W3C), that resistance can start to subside. This status is tantamount to making XML Schemas a metadata standard and a valid alternative to Document Type Definitions (DTDs). With the general acceptance and use of schemas, companies will be ready to kick their XML communications and data interchange efforts into high gear. XML Schemas greatly simplify the use of XML in business applications because they follow XML format, enable data reuse, are compatible with extensible stylesheet language transformations, and are simpler compared to DTDs... A schema is the XML construct used to represent the data elements, attributes, and their relationships as defined in the data model. By definition, a DTD and a schema are very similar. However, DTDs usually define simple, abstract text relationships, while schemas define more complex and concrete data and application relationships. A DTD doesn't use a hierarchical formation, while a schema uses a hierarchical structure to indicate relationships. The XML Schema standard uses the XML syntax exclusively, rather than borrowing from SGML, and it will augment, then later supplant, DTDs... Schemas give the developer richer control over the data type declarations than is possible in DTDs. Second, schemas allow greater reuse of metadata by permitting the developer to include more external schemas than allowable with DTDs. The main reason to use schemas is to improve compatibility and consistency within an XML document or application. In isolation, it doesn't matter significantly if an XML document uses a DTD or a schema. However, the moment that a developer or user wants to modify the document, share the document, or combine multiple documents, the differences become more apparent. Because schemas follow the XML format, it is easier to design tools, such as extensible stylesheet language transformation scripts, that will modify them. A real concern about XML documents is that developers will use different vocabularies, which will minimize interoperability. To leverage the capabilities of XML, developers must be able to bend the syntax rules of a specific document without breaking the vocabulary. Although there are still obstacles to overcome, such as vocabulary, the W3C's recommendation of XML Schemas is a major step toward better data interchange between companies and, eventually, more sophisticated, widely used B2B e-commerce." [August 01, 2001] Glosses on 'PSVI' (Post Schema Validation Infoset). XML-DEV posts. (1) "The Post-Schema Validation Infoset is an XML infoset as modified by a schema processor. Validating a document against a DTD requires that the DTD be read first, and then the document evaluated with respect to the DTD, because that's how SGML works. But since a schema is just another XML document, there's no order requirement. You can parse an XML document as well-formed and build an infoset from that. Then you take your schema and evaluate the document's infoset with respect to it. You augment the infoset with type information, default attributes or values, and validity status (yes, no, not checked) - that's your PSVI." [Christopher R. Maden] (2) "Post Schema Validation Infoset. A goal of Schema was to leave the infoset unchanged after doing schema processing, unlike DTDs. So, there needed to be a place to stick all the aditional information a Schema provides an instance, hence the creation of the PSVI. A processor or application that doesn't care about the PSVI can still validate a document against a schema and not have to worry about it." [David E. Cleary] [August 01, 2001] Sun Microsystems Releases Java 'Multi-Schema XML Validator'. A posting from Kohsuke KAWAGUCHI (Sun Microsystems) announces the availability of a 'Sun Multi-Schema XML Validator.' The Sun Multi-Schema XML Validator (MSV) is "a Java technology tool to validate XML documents against XML schemata. MSV supports RELAX NG, RELAX Namespace, RELAX Core, TREX, XML DTDs, and a subset of W3C XML Schema Part 1. The validator can be used as a command-line tool (to validate XML documents against a schema or DTD) or as a library (to validate documents or to manipulate schemas from inside a Java application). The distribution includes binaries, sample source code, and detailed documentation." [Full context] [July 23, 2001] "Xerces, XML4J, and XML4C add XML Schema support. Summer 2001 updates to Apache and IBM parser." By Natalie Walker Whitlock (Writer/Owner, Casaflora Communications) . From IBM developerWorks. July 2001. ['New versions of the Apache XML Project's Xerces parsers released in June support the W3C XML Schema Recommendation. The new Xerces for Java supports essentially all of the XML Schema spec; Xerces for C++ implements a more limited subset of XML Schema, an incremental step toward complete support of the newly anointed specification that will in many cases take the place of DTDs in XML development. IBM also released updates to the alphaWorks parsers -- XML4C and XML4J -- that correspond to the Xerces parsers. A table outlines the XML Schema features supported in this release of the parsers.'] "The two popular Xerces parsers from the Apache Software Foundation, Xerces Java (aka Xerces-J) and Xerces C++ (aka Xerces-C) made a great leap forward in June to support XML Schema. Xerces-J 1.4.1 boasts essentially complete support for the entire W3C XML Schema Recommendation. Xerces-C 1.5 supports a more limited subset of XML Schema. The alphaWorks parsers based on them, XML4J and XML4C, have also been updated with corresponding XML Schema support. The Xerces-C update is characterized as an important incremental step toward full W3C XML Schema support. In its announcement to its mailing list, the Apache XML Project promises to continue to update its open-source C++ parsers steadily, with the goal of implementing all of the features of the current XML Schema Recommendation before the end of the year... Other parsers, such as those from Oracle, XSV, XmlSpy, MSParser, and Extensibility, all claim some support for XML Schema. According to the companies' technical specifications, however, currently these parsers merely edit and validate XML schemas; they cannot read or interpret XML Schema instances. Additionally, at this writing the MSXML parser supports only Microsoft's version of the schema language, XML-data. According to my review of the online literature (Web sites, newsgroups, and mailing lists), the Xerces parsers (and their alphaWorks relatives) are the first to truly support advanced W3C XML Schema functionality..." [July 21, 2001] Microsoft Releases MSXML Parser 4.0 Beta 2. Microsoft has announced the release of a technology preview 'Beta 2' version of MSXML Parser 4.0, offering "a faster SAX and XSLT, complete XSD," and other enhancements. "The July 2001 release of the Microsoft XML Parser (MSXML) 4.0 Technology Preview is a preliminary release of MSXML 4.0. This technology preview has a number of improvements compared to the April release: (1) XSD validation with SAX; (2) XSD validation with DOM, using the schemaLocation attribute; (3) Schema Object Model (SOM) to access schema information in DOM and SAX; (4) Substantially faster XSLT engine -- tests show about x4, and for some scenarios x8, acceleration, except the known serious performance bug for xsl:keys; (5) New and substantially faster SAX parser, which is also available in DOM with the NewParser property... [See discussion.] [July 18, 2001] "XML for Data: Styling With Schemas. Using XML Schema Archetypes and XSLT Style Sheets to Simplify Your Code." By Kevin Williams (Chief XML architect, Equient - a division of Veridian). From IBM developerWorks. July 2001. ['This column by developer and author Kevin Williams demonstrates how to use XML Schema archetyping (and style sheets) to control styling of data for various presentation modes. Ten code samples in XML, XML Schema, and XSLT show how the techniques work to reduce code bulk and simplify maintenance.'] "In my previous column, I described how simple and complex archetypes may be used to simplify and streamline your XML schema designs. This column takes a look at one practical application of XML Schema archetypes: using style sheets to provide a consistent rendering of archetypes in the presentation layer... What are 'archetypes'? Archetypes are common definitions that can be shared across different elements in your XML schemas. In early versions of the XML Schema specification, archetypes had their own declarations; in the released version, however, archetypes are implemented using the simpleType and complexType elements... This column outlines the way you can use archetypes to streamline your coding experience. This discussion really only scratches the surface. In a large system that must support many presentation targets (HTML, wireless, other machine consumers) and many different source-document types (for bandwidth reduction or security reasons), using archetypes properly makes it very easy to keep your style sheet output consistent and correct." See previously: "XML for Data: Using XML Schema Archetypes. Adding Archetypal Forms to Your XML Schemas." [July 17, 2001] "RELAX NG: Unification of RELAX Core and TREX." By MURATA Makoto (International University of Japan, currently visiting IBM Tokyo Research Lab.) Paper [to be] presented at Extreme Markup Languages 2001, August 12-17, 2001, Montréal, Canada. "RELAX Core and TREX are schema languages for XML. RELAX Core was designed in Japan and has recently been approved as an ISO Technical Report (ISO TR 22250-1); TREX was designed by James Clark. RELAX Core and TREX are similar: they are based on tree automata and do not change information sets. On the other hand, there are some significant differences: attributes, unordered content models, namespaces, wild cards, the syntax, and the underlying implementation techniques. At OASIS, it was decided to unify these two languages and the new language is called RELAX NG. This talk shows how differences between RELAX Core and TREX are resolved in RELAX NG." See: "RELAX NG." [July 16, 2001] XML Schema for ISBN. By Roger L. Costello and Roger Sperberg. Description: "Roger Sperberg and I have collaborated to create an ISBN simpleType definition. It defines the legal ISBN values for every country in the world... The ISBN schema was not able to check all the constraints on an ISBN number. One of the constraints on ISBNs is that the last digit must match a certain sum of the previous digits modulo 11. (This is all documented in the ISBN schema.) Clearly, this constraint is not expressable with XML Schemas. Consequently we needed to supplement the ISBN schema simpleType definition with something else. We choose to express the additional constraints using XSLT... this allows anyone in publishing who is working with XML Schema to incorporate ISBN validation in their applications without having to create it from scratch. The agencies for the 126 group codes (which mostly represent countries, but also geographical regions and language groupings) do not all follow the recommendations of the international ISBN agency, so pending further research, the validation for some groups is not full. (It is complete, however, for the English-speaking ISBNs)..." -- Postings from Roger L. Costello and Roger Sperberg. [cache, with examples, XSLT script] [July 16, 2001] "Taxonomy of XML Schema Languages Using Formal Language Theory." By MURATA Makoto (International University of Japan, currently visiting IBM Tokyo Research Lab.) Dongwon Lee, and Murali Mani (University of California at Los Angeles/Computer Science Department). Paper to be presented at Extreme Markup Languages 2001, August 12-17, 2001, Montréal, Canada. PDF (print) version: 25 pages. "Most people are familiar with regular expressions, which define sets of strings of characters (regular languages). An extension of the idea of regular languages (as sets of strings) yields the idea of regular tree languages, which are sets of trees. From the ideas of regular tree languages, a mathematical framework for the description and comparison of XML Schema languages can be constructed. In this framework, four subclasses of regular tree languages and distinguished: local tree languages, single-type tree languages, restrained-competition tree languages, and regular tree languages. With these subclasses one can classify a few XML schema proposals and type systems: DTDs, the W3C XML Schema language, DSD, XDuce, RELAX, and TREX. Different grammar subclasses have different properties under the operations of XML document validation and type assignment..." Also available in HTML format. See the XPress project publications listing for related papers. [cache] [July 16, 2001] "A Standards-Based Framework for Comparing XML Schema Implementations." By Henry S. Thompson (HCRC Language Technology Group and World Wide Web Consortium) and Richard Tobin (HCRC Language Technology Group). Paper to be presented at Extreme Markup Languages 2001, August 12-17, 2001, Montréal, Canada. "XML Schema processing may be described as a mapping from an input information set to an output post-schema-validation information set (PSVI). Information sets are not defined as concrete data structures, APIs, or data streams; they are abstractions. But if they realize the PSVI in different ways, how can one compare two implementations of XML Schema to check their consistency with each other? One simple standards-based approach is to reflect the PSVI as an XML document. One can then use standard tools to compare the output of the two processors. XSLT stylesheets can be used to display the reflected PSVI and to highlight differences between results produced by different processors or by the same processor from different inputs..." [July 16, 2001] ZedX XML Studio, under development 2001-07-13 by Zheng Min. See the announcement. The editing tool supports "structure based and rule based XML Schema (also supporting other formats) editor that allows a user to define schemas without knowing the syntax of the schemas... [Supports] content-sensitive element/attribute listing and auto-completion. When inserting an element, a pull-down list shows only the valid elements at the point of insertion (not like some editors that show all the elements available in the document). Once an element is selected, the editor automatically creates the element and any sub-elements required by its DTD/Schema. This feature is available for both wellformed and validated document editing..." [July 12, 2001] IBM's XML Parser for Java (XML4J) Supports W3C XML Schema Recommendation. IBM alphaWorks has released an updated version of the XML Parser for Java (XML4J) which supports the W3C XML Schema specification and includes other enhancements. XML4J version 3.2.0 is distributed as source code and as a binary; it is covered by the standard Apache 1.1 license. XML4J now incorporates the following: "(1) W3C XML Schema Recommendation 1.0 support; (2) SAX 1.0 and SAX 2.0 support; (3) Support for DOM Level 1, DOM Level 2, and for some features of DOM Level 3 Core Working Draft; (4) JAXP 1.1 support." The IBM XML applications development team has also released an improved version of the 'XML Schema Quality Checker' tool. Version 1.85 of the XML Schema Quality Checker fixes 15 bugs present in the previous version, and improves usability under Solaris 2.7 and Windows 98. IBM's XML Schema Quality Checker "is a program which takes as input an XML Schema written in the W3C XML schema language and diagnoses improper uses of the schema language; where the appropriate action to correct the schema is not obvious, the diagnostic message may include a suggestion about how to make the fix." [Full context] [July 09, 2001] "From DTDs to XML Schemas. [EXPLORING XML.]" By Michael Classen. From Webreference.com. July 2001. ['Describing XML documents using XML Schemas offers a number of advantages over DTDs. In today's Tools Treasure Hunt, XML explorer Michael Classen introduces you to a utility that will help you convert your existing DTDs to XML Schemas.'] "The XML Schema standard was conceived to improve on DTD limitations and create a method to specify XML documents in XML, including standard pre-defined and user-specific data types. Defining an element specifies its name and content model, meaning attributes and nested elements. In XML Schemas, the content model of elements is defined by their type. An XML document adhering to a schema can then only have elements that match the defined types. One distinguishes simple and complex types. A number of simple types are predefined in the specification, such as string, integer and decimal. A simple type cannot contain elements or attributes in its value, whereas complex types can specify nesting of elements and associations of attributes with an element. User-defined elements can be formed from the predefined ones using the object-oriented concepts of aggregation and inheritance. Aggregation groups a set of existing elements into a new one. Inheritance extends an already defined element so that it could stand in for the original. The DTD to XML Schema Conversion Tool takes a DTD and translates it into its equivalent XML schema definition..." [July 06, 2001] New Release of XML Schema Validator (XSV). A posting from Henry S. Thompson (HCRC Language Technology Group, University of Edinburgh) announces an update of the W3C/LTG XML Schema Validator tool. The Validator for XML Schema REC (20010502) version is "an open source work-in-progress attempt at a conformant schema-aware processor, as defined by XML Schema Part 1: Structures, May 2, 2001 (REC) version. XSV has been developed by Henry S. Thompson and Richard Tobin of at the Language Technology Group of the Human Communication Research Centre in the Division of Informatics at the University of Edinburgh." The new release [XSV 1.197/1.99 of 2001/07/06 10:02:16] is available interactively online from the W3C web site. The '2001/07/06' release provides bug fixes and better handling of attribute defaults. Source code and Win32 binaries have also been updated. The online version of the tool provides two HTML forms: (1) one for checking a schema which is accessible via the Web, and/or schema-validating an instance with a schema of your own, (2) another for file upload if you are behind a firewall or have a schema to check which is not accessible via the Web. Four styles of output may be selected (verbose/concise; styled for different generations of HTML browsers). [Full context] [July 05, 2001] Updated IBM XML for C++ parser (XML4C). XML4C version 3.5.0 [released 06/27/2001] is based on the Apache Xerces XML C++ Parser v1.5.0. It includes experimental support for a subset of the W3C Schema language, bug fixes and performance improvements. The download now includes the iSeries (AS400) binaries... [it is] a validating XML parser written in a portable subset of C++. XML4C integrates the Xerces-C parser with IBM's International Components for Unicode (ICU) and extends the number of encodings supported to over 150. It consists of three shared libraries (2 code and 1 data) which provide classes for parsing, generating, manipulating, and validating XML documents. Source code, samples and API documentation are provided with the parser. Version 3.5.0 update contains: (1) Support of SAX 1.0 and SAX 2.0 specifications (2) Support of DOM 1.0 and DOM 2.0 specifiactions (3) Experimental support of a subset of the W3C Schema language (4) Support for ICU 1.8.1 (5) Bug fixes and performance improvemenents (6) Documentation in PDF format (7) Experimental IDOM - a new design of the C++ DOM API. (8) Lexical Handler of SAX2-ext (9) DOM implementation optimization." [July 05, 2001] "Schema to Java Compiler." [Pre-Alpha, 2001-07-05.] Overview: "Java code, outlined in the packages allows the processing of XML documents described by specific schema. Usually, the incoming XML document gets unmarshalled into the instances of the classes generated from the schema, processed, and, finally, gets marshalled back into XML form..." See the announcement: "Creative Science Systems Announces Release of Schema to Java Compiler." - Schema2Java Compiler Tool is the first publicly available tool to generate run time Java code from arbitrary XML Schema that supports the implementation guidelines of the World Wide Web Consortium (W3C) XML Schema Technical Recommendation. W3C is the world-renowned standards body for developing interoperable Web Technologies..." [June 29, 2001] "XML for Data: Using XML Schema Archetypes. Adding Archetypal Forms to Your XML Schemas." By Kevin Williams (Chief XML architect, Equient - a division of Veridian). From IBM developerWorks. June 2001. ['In the first installment of his new column, Kevin Williams describes the benefits of using archetypes in XML Schema designs for data and provides some concrete examples. He discusses both simple and complex types, and some advantages of using each. Code samples in XML Schema are provided.'] "In my turn on the Soapbox, I mentioned in passing how archetypes can be used in XML Schema designs for data to significantly minimize the coding and maintenance effort required for a project, and to reduce the likelihood of cut-and-paste errors. In this column, I'm going to give you some examples of the use of archetypes in XML schemas for data, and show just where the benefits lie. What are archetypes? Archetypes are common definitions that can be shared across different elements in your XML schemas. In earlier versions of the XML Schema specification, archetypes had their own declarations; in the released version, however, 'archetypes' are implemented using the simpleType and complexType elements. Let's take a look at some examples of each. Simple archetypes are created by extending the built-in datatypes provided by XML Schema. The allowable values for the type may be constrained by so-called facets, a fancy term for the different parameters that may be set for each built-in datatype. It's also possible to create a simple type by defining a union of two other datatypes or by creating a list of values that correspond to some other datatype. For our purposes, however, the restrictive declaration of simple types is the most interesting. Let's take a look at some examples... This installment has taken a look at the use of archetypes in the design of XML schemas. You've seen that judicious use of archetypes, together with smart naming conventions, can make schemas shorter and easier to maintain. There's an additional benefit to using archetypes -- a little trick to ensure consistent styling of your information..." Note the reference to the author's book Professional XML Schemas [ISBN: 1861005474], from Wrox Press; released now/soon. [June 29, 2001] Professional XML Schemas. By [Wrox Team] Kurt Cagle, Jon Duckett, Oliver Griffin, Stephen Mohr, Francis Norton, Nik Ozu, Ian Stokes-Rees, Kevin Williams. Wrox Press. ISBN: 1861005474. 'July 2001'. [Provisional] Book Description from the publisher: "XML Schemas will take over from DTDs as the primary method of defining XML data. Some of the most powerful reasons for using XML Schemas are their ability to: Validate much more powerfully with extended constraint mechanisms The ability to create your own datatypes Dynamically bind instance documents to schemas at run time Be used with existing xml tools as they are written in XML syntax Support namespaces Merge schemas into one Professional XML Schemas demystifies the complex W3C specification, showing how to create XML Schemas using the new syntax, and how to create schemas for documents, data transfer/storage, and object state. Data Modelling is strongly linked to learning about schemas. This book will discuss strategies for creating your own markup languages, and look at different models that authors should consider. The book will also introduce tools, practical examples of schemas developed for real world uses, and how they are used in the real world. This book is for all professional XML programmers who need to use XML Schemas to define data and need a practical guide to this new standard..." [June 22, 2001] IBM alphaWorks 'Regex for Java. "Updated 06/22/2001 to conform to the W3C Recommendation of XML Schema Datatypes. Also, new option to report non-matching position; some bug fixes. Regex for Java is a powerful, high-performance regular expression library for Java. You can search for a string matching to a regular expression pattern in your application with Regex for Java. Regex for Java supports almost all features of Perl5's regular expression. It also supports the syntax of XML Schema's regular expression." See XML Schema Part 2: Datatypes, W3C Recommendation 02-May-2001, Appendix F (Regular Expressions). [June 22, 2001] Regular Expression Generator for ranges. From Roger L. Costello, XML-DEV post. "I have created a simple tool which, given a range, will generate the corresponding regular expression. Example: for the range: 451 - 789, here is the regular expression which is generated: 45[1-9]|4[6-9][0-9]|[5-6][0-9][0-9]|7[0-7][0-9]|78[0-9]." download. [June 22, 2001] "DTD to XML Schema Translator." dtd2xs version 1.0. [Use the 'dtd2xs' tool to] "translate a Document Type Definition (DTD) into a XML Schema (REC-xmlschema-1-20010502). The translator can map meaningful DTD entities onto XML Schema constructs (simpleType, attributeGroup, group), i.e. the XML document model is not anonymized. In addition, the translator can map DTD comments onto XML Schema documentation nodes in various ways. By default, DTD comments are ignored; with a flag, DTD comments may be preserved with default parameters. Freely available for download as Java class and as standalone Java application." [Posting from Joerg Rieger 2001-06-19 to '[email protected]'; cache] [June 22, 2001] "Soapbox: Why XML Schema beats DTDs hands-down for data. A look at some data features of XML Schema" By Kevin Williams (Chief XML Architect, Equient - a division of Veridian). From IBM developerWorks. June 2001. ['In his turn on the Soapbox, info-management developer and author Kevin Williams tells why he's sold on XML Schema for the structural definition of XML documents for data. He looks at four features of XML Schema that are particularly suited to data representation, and he shows some examples of each. Code samples include XSD schemas and schema fragments.'] "As you're no doubt aware, the W3C recently promoted the XML Schema specification to Recommendation status, making that spec the XML structural definition language of choice. While most people find the specifications a little hard to read, the jargon conceals a very strong set of features, especially for those of us who are designing XML structures for data. I'd like to take a look at a few of those features. Strong typing is probably the biggest advantage XML Schema has over DTDs, and it is the aspect of XML Schema you've heard the most about. In a DTD, you don't have a whole lot of choices for constraining the allowable content of your elements and attributes... [Conclusion:] I've taken a brief look at some aspects of XML Schema that make schemas much better than DTDs for the definition of XML structures for data. While DTDs are likely to be around for a while yet (there are plenty of legacy documents that still rely on them for their structural definition), support for XML Schema is quickly being implemented for all the major XML software offerings. In the following months, I'll take a look at some of the ideas I've laid out here in greater depth in my forthcoming column." Article also in PDF format. [June 18, 2001] Xerces-C++ Parser Provides Support for W3C XML Schema Recommendation. A posting from Tinny Ng (IBM Toronto Laboratory) announces the release of Xerces-C 1.5.0 with partial support for the W3C XML Schema Recommendation. The developers intend to update this package until it implements all the functionality of the current XML Schema Recommendation. Apache Xerces-C is a "validating XML parser written in a portable subset of C++. Xerces-C makes it easy to give your application the ability to read and write XML data. A shared library is provided for parsing, generating, manipulating, and validating XML documents. Xerces-C is faithful to the XML 1.0 recommendation and associated standards (DOM 1.0, DOM 2.0. SAX 1.0, SAX 2.0, Namespaces). The parser provides high performance, modularity, and scalability. Source code, samples and API documentation are provided with the parser. For portability, care has been taken to make minimal use of templates, no RTTI, no C++ namespaces and minimal use of #ifdefs. In addition to the implementation of XML Schema subset, Xerces-C 1.5.0 offers: (1) Mac OS X command line configuration and build support; (2) Enabled libWWW NetAccessor support under UNIX; (3) Enabled COMPAQ Tru64 UNIX machines to build xerces-c with gcc; (4) Updated support for SCO UnixWare 7 [gcc]; (5) Experimental IDOM; (6) Support for ICU 1.8; (6) Documentation in PDF format; (7) Bug fixes and performance improvement." Xerces-C 1.5.0 source code and binaries are available for AIX, HP11, Linux, Solaris, Windows. [Full context] [June 14, 2001] Altova's XML Spy 4.0 Beta Supports W3C XML Schema Recommendation. Altova has announced a limited beta testing phase for the XML Spy 4.0 product line, including the XML Spy 4.0 Integrated Development Environment (IDE) and the XML Spy 4.0 Document Framework, released to customers and invited industry experts. The XML Spy 4.0 Integrated Development Environment (IDE) "builds on the success of the award-winning XML Spy 3.5 product in the developer market and adds expanded ODBC database access functionality, enhanced user interface customization, as well as support for the final XML Schema Recommendation for both graphical XML Schema editing and validation of XML instance documents based upon XML Schema. The XML Spy 4.0 Document Framework is based on a combination of XML Schema and XSLT Stylesheets. This provides the customer with a highly user-friendly interface -- very much like a typical word processor -- that allows for true XML content editing and creation. The framework consists of two applications: (1) The XML Spy 4.0 Document Editor supports free-flow WYSIWYG text editing, form-based data input, graphical elements, presentation and editing of arbitrary repeating XML elements as tables, real-time validation, and consistency checking using XML Schema and is deployed on the end-users desk. (2) The XML Spy 4.0 Document Administrator application includes a graphical XSLT Generator that enables the customization of the document editor by defining an XSLT Stylesheet and additional editing-specific options based upon the underlying DTD or XML Schema for use during the content creation or editing process." [Full context] [June 09, 2001] "[W3C] XML Schema Tutorial." By Roger L. Costello (of xFront.com XML Technologies). The main tutorial is a PPT slide set with some 276 slides. The slides reference 36 worked examples and 14 lab exercises. From the June 9, 2001 update note: "The tutorial is now updated to the Recommendation specification (i.e., the latest W3C specification). It includes a complete set of labs with answers. All examples and lab answers are complete and have been validated using Henry Thompson's schema validator, xsv [self-installing Win32 .exe], which is bundled in with the tutorial (thanks Henry!). It also includes a Javascript program, written by Martin Gudgin, that enables you to use MSXML4.0 (thanks Martin!)... I have provided a number of DOS batch files (i.e., validate.bat, run-examples.bat, run-lab-answers.bat) to make it easy for you to schema validate your XML files. I am continually adding new material to this tutorial. Please check back periodically for updates..." [June 09, 2001] "New Breeze XML Studio Release 2.5 Available. Beta Release Adds W3C XML Schema Support to Leading Data Binding Solution." - "The Breeze Factor, a company focused on providing solutions that simplify e-business using XML, today announced the latest release of its XML to Java data binding product: Breeze XML Studio Release 2.5. The release adds direct support for XML Schema, which was recently issued as a standard recommendation by the World Wide Web Consortium. Breeze XML Studio 2.5 is a substantial upgrade over previous releases and now can import structure in four formats: XML Schema (XSD), XML DTD, XML document (schema by example), and relational DBMS structure via JDBC/ODBC. With Breeze XML Studio 2.5, developers can take an XML schema and convert it directly to a set of Java classes that model the schema and encapsulate the parsing and validating of XML files conformant with that schema... While Breeze XML Studio can be used to design simple structures in its internal IDE, many customers will utilize a tool such as Tibco Extensibility's XML Authority for design and editing of complex structures. 'XSD is ideally suited to expressing business semantics. With its early support of XSD, The Breeze Factor is enabling users to bring that power to the application layer,' Lee Buck, VP, chief scientist XML Technologies, Tibco Extensibility. In addition to XML Schema support, the newest release includes improvements to the generated code when the schema has complex content models. 'It is one thing to parse an XML structure and understand the relationships between structure elements,' said Gregory Messner, CTO at The Breeze Factor. 'It is quite another to generate clean, readable and programmer-friendly component interfaces which make instances of that structure easy to use. The 2.5 release includes enhanced interfaces which make working with complex content very straightforward.' Breeze is licensed on a developer seat and OEM deployment basis. Developer seat licenses are sold for $495 with discounts for volume purchases. The Breeze Factor simplifies e-business using XML. The company accelerates e-business efforts by generating frameworks for XML and XML-based protocols making it easier for developers to work with and extend the newest language of the Internet. The company's products include Breeze XML Studio, a visual development environment that binds XML data to Java classes and provides an alternative to the DOM for working with XML for application programming. The Breeze Factor has offices in Encinitas, Calif. and Park City, Utah." [June 09, 2001] TIBCO Software Releases 'XML Validate' with Support for W3C XML Schema Recommendation. An announcement from TIBCO Software Inc. describes the release of a new streaming XML validator with full support for W3C XML Schema. Details: Tibco has "announced the commercial release of XML Validate, a member of the TIBCO Extensibility product family. XML Validate is an enterprise-grade solution for validating streaming XML documents or messages against an XML Schema or DTD. The Simple API for XML (SAX)-based implementation for run-time validation provides organizations with the core component in developing high bandwidth, XML-based processing. This release of XML Validate is also the first commercially available validator to fully support the World Wide Web Consortium (W3C) XML Schema Recommendation. The XML Schema Recommendation was released [2001-05-02] by the W3C... this XML Schema validation support will facilitate the creation of XML driven ecosystems based on open-standards. Additionally, XML Validate supports the validation of DTDs to allow connectivity with organizations not currently using XML Schema. XML Validate is a core building block for creating an e-commerce processing engine for XML documents and messages. As organizations conduct e-commerce with a growing and global audience, the processing capabilities of XML Validate can scale to the demand. XML Validate has the potential of handling millions of transactions per day per server. XML Validate can easily be inserted into an existing XML parsing scenario, enabling validation to occur the instant it is received by the parser. Because SAX is an event-based API, XML Validate is the ideal solution in a streaming run-time environment, creating an enterprise-grade XML processing engine." [Full context] [June 05, 2001] "Translating XML Schema." By Timothy Dyck. In eWEEK (May 28, 2001). "Earlier this month at the Tenth International World Wide Web Conference in Hong Kong, XML took its biggest step forward since the document format was first standardized in February 1998. At the conference, the World Wide Web Consortium released XML Schema as a W3C Recommendation, finalizing efforts that started in 1998 to define a standard way of describing Extensible Markup Language document structures and adding data types to XML data fields. Now that it is finally out, the long-delayed XML Schema standard will catalyze the next big step in XML -- allowing cross-organizational XML document exchange and verification. Just as discovery of the Rosetta stone in 1799 provided a way to fix the meaning of Egyptian hieroglyphs so they could be understood across the gulf of two millennia, XML Schema provides a way for organizations to fix the meaning of XML documents so they can be understood across the gulf of organizational boundaries and otherwise incompatible IT architectures. As a result, XML Schema will be a cornerstone in the new e-commerce architecture that we are collectively building and will be a vital component for making business exchanges and other loose associations of trading partners possible. The arrival of XML Schema, more than three years after XML itself, has left many chafing at the bit (and others, such as Microsoft Corp., running off in their own direction implementing and shipping products based on prestandard efforts), and the market is now more than ready for this standard to take hold. However, XML Schema's long development cycle gave vendors time to understand the specification and start writing compliant software, and we are now seeing the rapid release of XML Schema-compliant (or soon-to-be-compliant) authoring tools and servers... That long, committee-driven development cycle also resulted in a specification that has a bit of everything in it, and fully compliant XML Schema parsers will have to be complex pieces of software to support all the options the specification allows. Fortunately, XML Schema documents have to reference only the functionality they need, and the more complex options in XML Schema, such as null elements and explicit types, may just fade away through disuse. The W3C recently published a recommendation on how to group Extensible HTML, the consortium's replacement for HTML, into well- defined subgroups so XHTML browsers (such as those in cellular phones) can clearly define which parts of the language they support and which they don't. Something similar is a possibility for XML Schema if the full specification proves too difficult to implement for some vendors (although large players such as IBM, Microsoft and Oracle Corp. are moving ahead full speed with plans to support the full specification as published). Over the next few years, eWeek Labs predicts XML Schema will become integral to the way that many companies exchange information..." [June 05, 2001] "[W3C XML Schema] Speedy Adoption Expected." By Jim Rapoza. In eWEEK (May 28, 2001). "When XML was introduced, although there were early adopters, it still took about a year before Extensible Markup Language began to be regularly used in enterprise- level applications and deployments. Now that XML Schema is a standard, the waiting period for its adoption should be much shorter. Part of this can be attributed to how long businesses have been waiting for this schema. Many have been working on tools and compatibility issues while the standard was under development. However, it is also due in part to the complexity of the schema. Whereas the initial XML standard could be easily built and managed by anyone with an editor, many vendors plan to provide new tools to help shield users from the size and complexity of XSD (XML Schema Definition). Given the importance of XML Schema for handling data-driven communications among businesses, eWeek Labs recommends that developers begin evaluating tools that will help them move to XSD. In addition, companies should find out what their enterprise software vendors' plans are for supporting and integrating with XML Schema. As is true of most standards, many of the initial sets of XML Schema tools are essentially validators that help developers stay within the standard. Several are from individual World Wide Web Consortium members and universities, but some are also available from vendors such as IBM, and Java-based validators are available from Sun Microsystems Inc... Another important set of tools for businesses moving to XML Schema are conversion tools, which will help develop-ers convert content to the new standard. Probably the most important will be tools for converting standard XML DTDs (Document Type Definitions) to XSD, although some of those currently available have not been updated to the final standard. There are also tools for converting files from other schema languages, including a tool from Microsoft Corp. for converting files from XML Data Reduced to XSD...Microsoft recently released betas of MSXML and SQLXML that support the schema and has said that most of its products will support XSD in their next versions. Sun has released a new XML data types library that supports the final XML Schema standard, and Tibco Software Inc. includes tools for validating documents using XSD... [June 05, 2001] "Using Schema and Serialization to Leverage Business Logic." By Eric Schmidt. From Microsoft MSDN Online. 'Extreme XML' Column. May 17, 2001. ['New columnist Eric Schmidt addresses how you can use schemas and serialization technology to leverage XML in your applications and services.'] "In this issue of Extreme XML, we are going to examine the importance of schema usage and the use of serialization technology to leverage XML in your applications and services. The majority of development tasks today revolve around developers taking existing infrastructure (business components, databases, queues, and so on) and morphing them into the next version of their product... The surge of XML usage over the past several years has not led to a complimentary increase in defined data models for XML documents. For this section, I am referring to a data model for XML to be the structure, content, and semantics for XML documents. The one main reason for this slow growth in XML data models is the lack of, until now, a robust XML schema standard. Document Type Definitions (DTDs) have out grown their usefulness in the enterprise space because of their focus on XML from a document perspective and not viewing XML document instances from a data and type perspective. Typed data items like addresses, line items, employees, orders, and so on have complex models and are the basis for most applications. Applications look at data from strongly typed perspective. For example, a Line Item is an inherited member of an order and contains typed information like product price, which is of type currency. The majority of this type of modeling cannot be accomplished with DTDs. Due to the simple structuring and typing mechanisms in DTDs, numerous XML validation, structuring, and typing systems have been created, including Document Content Description (DCD), SOX, Schematron, RELAX and XML-Data Reduced (XDR). The later, XDR, has gained much momentum in the Windows and B2B based communities due to its usage in products like SQL Server, BizTalk Server, and MSXML. In addition, most independent software vendors (ISVs) and B2B integrators support XDR because of its data typing support, namespace support, and its XML-based language. However, XDR's usefulness stills falls short of providing a truly extensible modeling and typing system for complex data structures. This was a known issue at the time of XDR's creation. Building on the lessons learned from previous schema implementations, the W3C XML Schema working group set out to create a specification (XML Schema) for defining the structure, content, and semantics of XML documents. Ultimately, this specification should provide an extensible environment so that it could be applied to any type of business or processing logic. During the development of this article, I was pleased to see that the W3C released XML Schema as a recommendation. This is a tremendous step in solidifying and stabilizing XML-based implementations that need to employ schema services. Next, we're going to look at the importance and power behind XML Schema... I have distilled five core items you need to know about XML Schema so you can get up and running: (1) XML Schema is represented in XML 1.0 syntax; this makes parsing XML Schema available to any XML 1.0-compliant parser, and thus can be used within a higher-level API like the DOM. (2) Data typing of simple content: XML Schema provides a specification for primitive data types (string, float, double, and so on) found in most common programming languages. (3) Typing of complex content: XML Schema provides the ability to define content models as types. (4) Distinction between the type definition and instance of that type: unlike XDR, XML Schema type definitions are independent of instance declarations; this makes it possible to reuse type definitions in different contexts to describe distinct nodes within the instance document. (5) W3C support and industry implementation... creating specific and lucid schema should be your first task when creating XML- and Web Service-enabled applications. If your partners need other schema definitions than XML Schema, for example DTD, start with an XML Schema approach and then port the implementation. You'll come out ahead in the long run." See also the sample code for the article. [June 05, 2001] "XSD for Visual Basic Developers." By Yasser Shohoud. From the DevXpert Web Services Depot [for VB Developers]. May 2001. "The W3C's XML Schema is sometimes referred to as XML Schema Definition language or XSD for short. XSD is an XML-based grammar for describing the structure of XML documents. A schema-aware validating parser, like MSXML 4.0, can validate an XML document against an XSD schema and report any discrepancies. To solve the [invalid invoice document] problem outlined above, you'd create an XSD schema that describes the invoice document. You'd then make this schema available to the UI tier developers. The schema is now part of the 'interface contract' between the middle tier and the UI. While the application is in development, the UI tier can validate the invoice documents that they send against that schema to ensure they are valid. Similarly, the SaveInvoice function can validate the input invoice document against the schema before attempting to process it. Now if you change the invoice document to support a new feature, you must change the schema accordingly. Now the UI team tries to validate the invoice documents they're sending and this validation fails so they immediately realize that the schema has changed and that they must change the invoice documents they are sending. This can also help catch version mismatch problems where you have an older client trying to talk to a newer middle tier or vice versa.... In this brief introduction to XSD, you've seen how you can make a Visual Basic class to an XSD schema and how to use that schema with MSXML 4.0 to validate documents. You also learned the relation between XSD and XML namespaces and how namespaces can be used to combine elements from different schemas in one XML document. This tutorial barely scratches the surface of what you can do with XSD schemas. There are many more features and details you might be interested in (or might not care about). Once you are comfortable with the concepts explained in this tutorial, check out the XML Schema Primer (part of the XSD specification) which goes into a lot more details about XSD with many examples..." [May 22, 2001] IBM XML Schema Quality Checker Supports the W3C XML Schema Recommendation. A communiqué from Bob Schloss (IBM Research) reports on the availability of an updated IBM XML Schema Quality Checker tool from IBM alphaWorks. The new version of this downloadable tool (Version 1.0.17, 05/21/2001) assists users who are creating XML Schemas conforming to the May 2, 2001 W3C Recommendation. The updated release "contains fixes bugs, adds a checker to verify that identity constraint definitions (Key, KeyRef and Unique) are consistent with the type of the element declaration where they appear, and updates the default stylesheet used to view the error reports. The XML Schema Quality Checker is a program which takes as input an XML Schema written in the W3C XML schema language and diagnoses improper uses of the schema language. Where the appropriate action to correct the schema is not obvious, the diagnostic message may include a suggestion about how to make the fix. For XML Schemas which are composed of numerous schema documents connected via <include>, <import>, or <redefine> element information items, a full schema-wide checking is performed. The tool can also be run in batch mode to quality-check multiple XML schemas in a single run." Schloss reports that the team is continuing to work on more complete checking of the consistency of identity-constraint definitions and on additional improvements; they welcome feedback and suggestions. The tool has been produced by the IBM Application Development team, including Achille Fokoué, Bob Schloss, Tom Gallivan, and Roberto Galnares. [Full context] [May 14, 2001] "XML Schema becomes W3C Recommendation: What This Means. With the approval of the W3C and its 500+ members, XML is ready for the next big step to worldwide deployment." By Natalie Walker Whitlock (Casaflora Communications). From IBM developerWorks. May 2001. ['After more than two years of review and revision, the World Wide Web Consortium (W3C) announced on May 1 that it has embraced the XML Schema with a formal Recommendation. W3C Recommendation status is the final step in the consortium's standards approval process, indicating that the schema is a fully mature, stable standard backed by the 510 W3C member organizations.'] "Speaking at the 10th International World Wide Web Conference in Hong Kong, Web pioneer and W3C Director Tim Berners-Lee said that XML Schema (parts 0, 1 and 2) should now be considered as one of the foundations of XML, together with XML 1.0 and Namespaces in XML. He also stated that the specification provides 'an XML language for defining XML all languages.' The finalized Schema brings rich data descriptions to XML. Schema will solve the primary problem of B2B communication and interoperability that has held XML back from its full potential. The standardized Schema is expected to integrate data exchange across business, and ultimately realize the full promise of XML to facilitate and accelerate electronic business... Schema increases XML's power and utility to the developer by providing better integration with XML Namespaces. By introducing datatypes to XML, Schema makes it easier than ever to define the elements and attributes in a namespace, and to validate documents that use multiple namespaces defined by different schemas. XML Schema also introduces new levels of flexibility intended to speed its adoption for business use. According to [IBM's Noah] Mendelsohn, who also helped write the spec, XML Schema addresses a number of new issues and therefore has features for demanding apps. Yet, he says, developers can learn how to use XML Schema to do what they've been doing in XML with DTDs in 'about an hour or two.'... Berners-Lee added that XML Schema would need to be clarified and simplified after the many implementations and unexpected interpretations of the specification. Indeed, the cry of simplification has been one of the loudest heard from critics. The current complexity has been blamed for driving others to create alternative, lighter weight schemas, such as TREX and RELAX. Some have even said XML Schema is so complex that even some W3C insiders are calling for future versions to be incompatible with this first release so they do not repeat what critics say are the flaws of the first version... Despite the controversies, most groups have publicly stated that they will support and incorporate the W3C's XML Schema. These groups include IBM, Microsoft, Sun Microsystems, Commerce One, and Oracle. In a public statement, Oracle said its Oracle9i will be the first production database to implement the new Schema. In addition, both Microsoft's .Net initiative and Sun's SunOne Web services effort will take advantage of XML Schema..." XSDSchema mailing list. Yahoo mailing list 'XSDSchema' "is for the purpose of open discussion and mutual help in relation to the W3C XML Schema specification which reached full Recommendation status at W3C on 2nd May 2001..." [May 03, 2001] Sun XML Datatypes Library Supports W3C XML Schema. A communiqué from Eduardo Gutentag reports on the availability of the 'Sun XML Datatypes Library'. Developed by Kohsuke Kawaguchi, the datatypes library is Sun's implementation of W3C's XML Schema Part 2 intended for use with applications that incorporate XML Schema Part 2. The preview version 1 of 'April 2001' implements the proposed recommendation version of the W3C XML Schema Part 2 Datatypes. The distribution of the XML Datatypes Library includes a sample class file src/com/sun/tranquilo/datatype/CommandLineTester.java provided "as a guide for implementing your own Java classes with the Datatypes Library." Documented examples include validating a string with an integer datatype, deriving a new type from an existing DataType object, and diagnosing errors. The library distribution includes software developed by the Apache Software Foundation; its use requires JDK 1.3. [Full context] [April 24, 2001] "XML Schema Catches Heat." By Roberta Holland. In eWEEK (April 23, 2001). "After more than two years of development, the World Wide Web Consortium could be only weeks away from releasing its long-awaited XML Schema specification. But despite its release, the specification, which is designed to automate data exchange between companies, is coming under fire. Now in the final review phase by W3C Director Tim Berners-Lee, the specification, according to critics, is far too complex -- so complex that it has driven several XML experts to create alternative and lighter-weight schemas. Furthermore, some W3C insiders are even calling for future versions to be incompatible with this first release so as not to repeat what they say are the flaws of the first version. 'There has been controversy,' said Tim Bray, co-author of the W3C's Extensible Markup Language specification, in Vancouver, British Columbia. 'XML Schema is a very large project. The working group is a very large body that has been very visible. All the major vendors are on it. As a result, the [specification] tends to have a lot of compromises in it.' XML Schema has been one of the most watched standards efforts of late. The schema expresses shared vocabularies and defines the structure and content of XML documents. XML Schema is expected to make data exchange among businesses cheaper and easier than what is possible using Document Type Definitions. The comment period for XML Schema ended last week. The spec now lies with Berners-Lee, who will determine if any technical issues raised should prevent its release. W3C officials expect a decision within weeks.... Trex, which Clark submitted to the Organization for the Advancement of Structured Information Standards, is simpler and more modular, as it focuses just on the validation of XML documents. A similar effort, Relax, was started late last year by schema working group member Makoto Murata. Murata, who works with the International University of Japan Research Institute and IBM in Tokyo, also dissatisfied with the W3C's direction, said the schema group was focused more on benefits to vendors than on the technology, unlike the original XML working group. Clark and Murata recently merged their efforts under OASIS, in Billerica, Mass. Clark hopes they can produce a first draft in two to three months. Another alternative, called Schematron, was started in October 1999 by working group member Rick Jelliffe, who represented Academia Sinica Computing Centre, in Taipei, Taiwan, until this month. The most positive change 'is a widespread realization that XML Schema will not be the universal and terminal schema language,' said Jelliffe, now CTO of Topologi Pty. Ltd., in Sydney, Australia. 'I think if we can hose down people's expectations and mindshare-grabbing marketing, XML Schema will be successful.' [...] Despite the controversies, many are supporting XML Schema, including Microsoft, IBM and Oracle Corp. Micro soft last week announced a technical preview of its XML parser supporting schema. The Redmond, Wash., company also will include XML Schema in the second beta version of Visual Studio.Net, which will be given to attendees at Microsoft's TechEd conference in June." [April 20, 2001] "Taxonomy of XML Schema Languages Using Formal Language Theory." By Murata Makoto (IBM Tokyo Research Labs), Dongwon Lee (UCLA / CSD), and Murali Mani (UCLA / CSD). 24 pages. April, 2001. "On the basis of regular tree languages we present a mathematical framework for XML schema languages. This framework helps to formally describe, compare, and implement such XML schema languages. Our main results are as follows: (1) Four subclasses of regular tree languages: local tree languages, single-type tree languages, restrained competition tree languages, and regular tree languages. (2) A classification and comparison of a few XML schema proposals and type systems:DTD, XML-Schema, DSD, XDuce, RELAX, and TREX (3) Properties of the grammar classes under two common operations: XML document validation and type assignment... As the popularity of XML increases substantially, the importance of XML schema language to describe the structure and semantics of XML documents also increases. Although there have been about a dozen XML schema language proposals made recently, no comprehensive mathematical analysis of such schema proposals has been available. We believe that providing a framework in abstract mathematical terms is important to understand various aspects of XML schema languages and to facilitate their efficient implementations. Towards this goal, in this paper, we propose to use formal language theory, especially tree grammar theory, as such a framework. Given an XML document and its schema, suppose one wants to check whether the document is valid against the schema and further find out the types (or non-terminals) associated with each element in the document. We are interested in algorithms for such document validation and type assignment operations, and the time complexity of such algorithms. Furthermore, we would like to know if such algorithms can be implemented on top of SAX or rather require DOM. Such issues are closely related with the efficient implementation of XML schema language proposals, and are directly addressed by our mathematical framework... [Conclusion:] A mathematical framework using formal language theory to compare various XML schema languages is presented. This framework enables us to define various subclasses of regular tree languages, and study the closure properties and expressive power of these languages. Also, algorithms for document validation and type assignment for the different grammar classes are described. Finally, various schema language proposals are compared using our framework, and the implementations available are discussed. Our framework brings forward a very important question: Do we need to migrate from deterministic content models of XML 1.0 in favor of schema languages such as RELAX and TREX that allow non-deterministic content models? Our work in this paper as well as other work, with regard to document processing and XML query, makes us believe that we should allow non-deterministic content models in XML schema languages. We have multiple directions for future research which we are pursuing presently. We are examining ambiguity in regular tree grammars and languages, and studying how to determine whether a given regular tree grammar is ambiguous or not. We are also examining integrity constraints necessary for a schema language as studied widely in the area of database systems, and examining efficient implementations of these constraints for XML applications." [Note the comment posted: "I hope that this paper (submitted to Extreme) helps to understand validation algorithms for schema languages such as RELAX and TREX. You might have seen earlier versions of this paper, but this is away more readable... In my understanding, Algorithm 4.1 shown in this paper is similar to the algorithms of PyTREX, VBRELAX, and XDuce. The algorithm of RELAX Verifier for Java is based on Algorithm 5, but is more advanced. The algorithm of JTREX is more advanced than Algorithm 5 in that it constructs tree automata lazily. In the final version, I will try to add more information about JTREX."] References for related papers are given on Murali Mani's web site. [cache] [April 02, 2001] W3C XML Schema Specifications Developed in the 'OSS Through Java Initiative'. A communiqué from Ben Eng (Nortel) reports on "a significant XML Schema effort that has been underway in the 'OSS Through Java Initiative' for the past year. The first three API specifications being developed are for Service Activation, Trouble Ticketing, and Quality of Service; extending across all OSS through Java specifications is a common J2EE Design Guidelines document. All three API specifications are currently in Community Review ending April 16, 2001, at which time they will be promoted to Public Review status. We specify APIs in three styles: EJB session interfaces with Java Value Types, EJB session interfaces with XML Value Types, and XML messaging (transportable by JMS, ebXML/SOAP, or whatever). There is functional equivalence between the styles. Each OSS API will specify all three styles of APIs; specifying one automatically generates the other two. The latter two styles of interfaces are specified in XML Schema." [Full context] [March 29, 2001] "XML-Deviant: Schemas by Example." By Leigh Dodds. From XML.com. March 28, 2001. ['There has been a lot of activity in the area of XML schema languages recently: with several key W3C publications and another community proposed schema language. Another alternative schema language has emerged from the XML community, relying entirely on example instance documents.'] (1) "W3C XML Schema: The finish line is now in sight for the members of the W3C XML Schemas Working Group. The XML Schema specifications are an important step closer to completion with their promotion to Proposed Recommendation status. All that remains now is for Tim Berners-Lee, as Director of the W3C, to approve the specifications before they become full Recommendations. The road has been long and hard, and it's had a number of difficult sections along the way." (2) Examplotron: "Eric van der Vlist has been helping to realize Rick Jelliffe's vision of a plurality of schema languages by publishing Examplotron, a schema language without any elements. Examplotron's innovation lies in its '"schema by example' approach to schema generation. Rather than define a dedicated schema language with which a document can be described, Examplotron uses sample instance documents, annotated with several attributes that carry schema specific information such as occurrence of elements, and assertions about element and attribute content. Like Schematron before it, Examplotron is implemented using XSLT. An Examplotron instance document can be converted into a validating stylesheet by applying a simple transformation..." For schema description and references, see "XML Schemas." [March 23, 2001] Examplotron 0.1." By Eric van der Vlist (Dyomedea). "The purpose of examplotron is to use instance documents as a lightweight schema language -- eventually adding the information needed to guide a validator in the sample documents. 'Classical' XML validation languages such as DTDs, W3C XML Schema, Relax, Trex or Schematron rely on a modeling of either the structure (and eventually the datatypes) that a document must follow to be considered as valid or on the rules that needs to be checked. This modeling relies on specific XML serialization syntaxes that need to be understood before one can validate a document and is very different from the instance documents and the creation of a new XML vocabulary involves both creating a new syntax and mastering a syntax for the schema. Many tools (including popular XML editors) are able to generate various flavors of XML schemas from instance documents, but these schemas do not find enough information in the documents to be directly useable leaving the need for human tweaking and the need to fully understand the schema language. Examplotron may then be used either as a validation language by itself, or to improve the generation of schemas expressed using other XML schema languages by providing more information to the schema translators..." From the XML-DEV posting: "Beating Hook, Rick Jelliffe's single element schema language has been quite a challenge, but I am happy to announce examplotron a schema language without any element. Although examplotron does include an attribute, this attribute is optional and you can build quite a number of schemas without using it and I think it fair to say that examplotron is the most natural and easy to learn XML schema language defined up to know ;=) ... The idea beyond examplotron -and the reason why it's so simple to use- is to define schemas giving sample documents. Although examplotron can be used as a standalone tool, it can also be used to generate schemas for more classical -and powerful- languages and I don't think it will compete with them but rather complement them. Thanks for your comments..." See also: (1) the XML-DEV posting, and (2) "XML Schema Element and Attribute Validator." [March 16, 2001] "XML Schemas: Best Practice. [Homepage.]" By Roger L. Costello (Mitre). March 13, 2001. Table of Contents: Motivation and Introduction to Best Practices; Default Namespace - targetNamespace or XMLSchema?; Hide (Localize) Versus Expose Namespaces; Global versus Local; Element versus Type; Zero, One, or Many Namespaces; Variable Content Containers; Creating Extensible Content Models; Extending XML Schemas. Roger says: "I have created a homepage containing all of our work. Also, based upon our recent discussions (especially on Default Namespace) I have updated all the online material and examples. In so doing I fixed a lot of typos, clarified things, etc. [You can] download Online Material Plus Schemas: I have zipped up all the online discussions, along with the schemas and instance documents that are referenced in the online material. Now you can download all this material and run all the examples. Also download Best Practice Book: I have put the Best Practice material into book form. You can download this book and print it out... In a few days I would like to start up again our discussions on Creating Extensible Schemas..." [March 12, 2001] Tibco Releases Commercial Version of XML Canon/Developer. An announcement from TIBCO Software Inc. describes the availability of XML Canon/Developer (XCD) which "enables organizations to build an XML infrastructure that accesses, stores, and integrates the vocabulary from schemas or DTDs in any XML-based application. XCD supports a 'logical schema analysis' approach for creating XML vocabularies and grammars which can then be re-purposed with new semantic meaning." XCD features include support for design-time repository for XML assets (document-level and component-level object control from a centralized repository) and distributed Web-based access to an organization's XML assets repository. The Web-based interface also leverages the Internet for collaboration with suppliers, customers, trading partners and industry groups. XCD "enables the analysis of schemas and DTDs at the component-level by creating a data dictionary or vocabulary of an Enterprise's XML assets; this Enterprise vocabulary can then be browsed, searched, and re-constructed to create an infinite set of new semantically different schemas." [Full context] [March 09, 2001] White Paper Demonstrates 'Modeling XHTML with UML' and XML Schema Generation. A communiqué from Dave Carlson (Ontogenics Corp., Boulder, Colorado) reports on creation of an XML Schema that covers all of XHTML Basic (this may be the first complete XML Schema for XHTML Basic). Details are given in the white paper Modeling XHTML with UML. Carlson writes: "There are a 3-4 situations where it is a bit lenient in accepting markup that it shouldn't, but overall it seems to work quite well. This model makes very heavy use of inheritance to capture the XHTML concept of content groups, such as Flow, Block, Inline, etc. I have generated two different schemas: one uses extension of complexType definitions, the other employs a copy-down strategy to avoid extension. Both schemas work with the XSV validator... What's interesting about this is that the schema was automatically generated from a UML model. The white paper includes all the UML class diagrams for the XHTML Basic modules. I've written a schema generator that produces schemas from any UML tool that can export an XMI 1.0 document representing the model. This model of XHTML was created using Rational Rose... the generated schema also provides a good stress test case for validation tools." [Full context] [March 07, 2001] Schema For Representing Infosets Explicitly in XML. From Richard Tobin (HCRC, University of Edinburgh). 2001-03-07 or later. "This is a schema for representing infosets explicitly in XML. There are two main versions: one for the basic infoset, and one for the post-schema-validation (PSV) infoset. One reason for producing this schema was to allow comparison of the infosets generated by different processors (including parsers and schema validators). It has also proved useful for finding flaws in the infoset and schema specifications themselves..." In the '20010216' version, "the basic schema matches the Infoset Last Call draft; the PSV schema has not yet been updated to match." See also earlier versions online. Contents: (1) XMLInfoset.xsd; (2) XMLSchema-infoset.xsd; (3) infoset-basic-items.xsd; (4) infoset-basic-properties.xsd; (5) infoset-basic-types.xsd; (6) infoset-schema-components.xsd; (7) infoset-schema-facets.xsd. [cache 2001-03 for '20010216' version'] [March 07, 2001] "Mapping W3C Schemas to Object Schemas to Relational Schemas." By Ronald Bourret (The Open Healthcare Group). March 2001. "This paper summarizes two different mappings. The first, part of the process generally known as XML data binding, maps the W3C's XML Schemas to object schemas. The second, known as object-relational mapping, maps object schemas to relational database schemas. The two mappings can be joined (and the intermediate object schema eliminated) to create a mapping from XML Schemas to database schemas. This is not shown, but left as an exercise to the reader. Note that because individual XML Schema structures can often be mapped to multiple object structures, and because individual object structures can often be mapped to multiple database structures, there are usually multiple possible mappings from XML Schemas to database schemas. The mapping is described in terms of the data model presented in XML Schemas Part 1: Structures, rather than the XML syntax used to describe schemas. Although I might eventually add a section describing the mapping based on the XML syntax, this is currently left as a (non-trivial) exercise for the reader...The purpose of this paper is to help people write code that can automatically generate object and database schemas from XML Schemas, as well as transferring data between XML documents, objects, and databases according to mappings between them. Because the set of possible mappings from XML Schemas to object schemas is fairly large, I do not expect any software to support all possible mappings any time soon, if ever. A more reasonable strategy is for the software to pick a subset of mappings that make sense for its uses and implement those." [Introduction on XML-DEV: 'I've posted a paper mapping a (very slight) variant of the data model in W3C schemas to object schemas, and then mapping object schemas to relational schemas. The first part of the paper -- mapping XML schemas to object schemas -- is likely to be of most interest to people. It is undoubtedly similar to Sun's XML data binding (JSR-31) and Veo Systems work with SOX. In fact, I wrote it because neither of those specifications seems to be publicly available. The work also appears to be a superset of the mappings in Bill La Forge's Quick and Enhydra's Zeus project. Please note that the paper is rather terse and assumes you understand the general ideas behind the mapping from XML schemas / DTDs to object schemas. If not, see the presentation "Mapping DTDs to Databases", available from: http://www.rpbourret.com/xml.'] [cache] [March 06, 2001] "Extending XML Schemas." By Roger L. Costello (et al.). XML-DEV post March 06, 2001. Topic: 'What is Best Practice of checking instance documents for constraints that are not expressible by XML Schemas?' "XML Schemas - Strive to be All Powerful? As XML Schemas completes version 1 and begins work on version 2, the question comes to mind: 'should XML Schemas strive in the next version to be all powerful?' Programming languages seem to have that goal - to enable a programmer to express any problem using the language. Perhaps the goal of version 2 of XML Schemas should be to provide enough flexibility that any constraint may be expressed. Alternatively, perhaps XML Schemas should just provide a core set of constraint expressing mechanisms (as it does today), and let the marketplace create a technology (technologies?) to supplement XML Schemas. Then version 2 of XML Schemas would have few changes from version 1..." [March 05, 2001] "Comparing W3C XML Schemas and Document Type Definitions (DTDs). [XML Matters #7.]" By David Mertz, Ph.D. (Idempotentate, Gnosis Software, Inc.). From IBM developerWorks, XML Library. March 2001. ['Many developers expect that XML schemas will soon supplant DTDs for specifying XML document types. David Mertz is skeptical that schemas will replace DTDs, though he believes that XML schemas are an invaluable tool in a developer's arsenal. This installment of the "XML Matters" column steps up to the challenge of comparing schemas and DTDs and clarifying just what is going on in the XML schema world.'] "While there are a number of instances where W3C XML Schemas excel, there remain, nonetheless, a number of areas where DTDs are better. Developers are continually left with tough choices... Much of the point of using XML as a data representation format is the possibility of specifying structural requirements for documents: rules for exactly what types of content and subelements may occur within elements (and in what order, cardinality, etc.). In traditional SGML circles, the representation of document rules has been as DTDs -- and indeed the formal specification of the W3C XML 1.0 Recommendation explicitly provides for DTDs. However, there are some things that DTDs cannot accomplish that are fairly common constraints; the main limitation of DTDs is the poverty in their expression of data types (you can specify that an element must contain PCDATA, but not that it must contain, for example, a nonNegativeInteger). As a side matter, DTDs do not make the specification of subelement cardinality easy (you can compactly specify 'one or more' of a subelement, but specifying 'between seven and twelve' is, while possible, excessively verbose, or even outright contorted). In answer to various limitations of DTDs, some XML users have called for alternative ways of specifying document rules. It has always been possible to programmatically examine conditions in XML documents, but the ability to impose the more rigid standard that, 'a document not meeting a set of formal rules is invalid,' essentially, is often preferable. W3C XML Schemas are one major answer to these calls, but not the only schema option out there... At least two fundamental and conceptual wrinkles remain for any 'schemas everywhere' goal. The first issue is that the W3C XML Schema Candidate Recommendation, which just ended its review period on December 15, 2000, does not include any provision for entities; by extension, this includes parametric entities. The second issue is that despite their enhanced expressiveness, there are still many document rules that you cannot express in XML schemas (some proposals offer to utilize XSLT to enhance validation expressiveness, but other means are also possible and in use). In other words, schemas cannot quite do everything DTDs have long been able to, while on the other hand, schemas also cannot express a whole set of further rules one might wish to impose on documents. At a more pragmatic level, tools for working with XML schemas are less mature than those for working with DTDs... W3C XML Schemas let XML programmers express a new set of declarative constraints on documents for which DTDs are insufficient. For many programmers, the use of XML instance syntax in schemas also brings a greater measure of consistency to different parts of XML work; others disagree, of course. Schemas are certainly destined to grow in significance and scope as they become more familiar, and as developers enhance more tools to work with them. One way to get a jump start on schema work is to automate the conversion of existing DTDs to XML schema format. Obviously, automated conversions cannot add the new expressive capabilities of XML schemas themselves; but automation can create good templates from which to specify the specific typing constraints one wishes to impose." Also in PDF format, cache. [February 17, 2001] Abbreviated Tag Names / ASN.1 / binary encodings for XML Schema data types. From Charles Reitzel, XML-DEV. "Surely, ASN.1 is preferable to inventing a new set of binary encodings for XML Schema data types. Besides being available now, ASN.1 has the advantage of interoperability with LDAP. I'm sure there are many uses for representing LDAP data as XML and vice-versa: lookup web service deployment descriptors, directory data export/import, UDDI registry implementation, ... LDAP already defines "Syntaxes" for many primitive data types (date, string, integer, ...). LDAP has the ability to use different names for the same OID, which might be helpful in supporting multiple XML views of shared LDAP data. Conceivably, these attribute types could be used independently of directories, per se. However, done with care and restraint, it shouldn't be to hard find a usable overlap between LDAP schemas and XML Schema. Both support basic "struct" data types as well as attribute and element/entry type inheritance. Complications: 1) Because LDAP attributes are multi-valued, however, they don't always map to XML attributes. So some additional meta-data is needed here. 2) It is difficult to separate LDAP object classes from directories. An XML data type is probably needed to represent an LDAP distinguished name as a URI ("urn:ldap:cn=joebob,l=texas")? However, LDAP relative distinguished names (RDNs) can probably be represented with a properly scoped XML Schema key definition." [February 14, 2001] MSL - A model for W3C XML Schema. Conversations by Dan Connolly, Andrea Asperti, and Philip Wadler on the the public W3C '[email protected]' mailing list [forum for discussion of W3C Spec Production Issues] have (incidentally) referenced MSL (Model Schema Language), which represents "an attempt to formalize some of the core idea in XML Schema." MSL, as with Hypertextual Electronic Library of Mathematics (HEML) and the online The COQ proof assistant, may be of interest to XML developers having expertise in mathematics and formal logic. A presentation entitled "MSL: A model for W3C XML Schema" will be given in an XML Foundations session at the Tenth International World Wide Web Conference (WWW10). The same WWW10 session, chaired by Carl Lagoze of Cornell University, will feature also "A Unified Constraint Model for XML" (Wenfei Fan, Gabriel M. Kuper, Jerome Simeon) and "Keys for XML" (Peter Buneman, Susan Davidson, Wenfei Fan,Carmem Hara, Wang-Chiew Tan). An online draft paper indicates that "MSL has already proved helpful in work on the design of XML Query; we expect that similar techniques can be used to extend MSL to include most or all of XML Schema." According to one online authority, MSL (Model Schema Language) is "an initiative by members of the W3C's XML Schema Working Group, to provide a formal model for the XML Schema language." Cf. the Software AG Glossary, which notes also a 'New MSL DraftFull context]
[February 09, 2001] "The Hook: A Minimal Validation Language of One Element Based on Partial Ordering." By Rick Jelliffe. 2001/02/07. "The Hook validation language is a thought experiment in minimalism in XML schema languages. The purpose of such a minimal language would be to provide useful but ultra-terse success/fail validation for basic incoming QA, especially of datagrams. It is like a checksum for a schema. The validation it performs can be characterized as "Does this element have a feasible name, ancestry, previous-siblings and contents?", there being some tradeoff between the how fully the later criteria are tested. Let us start with the following technical criteria: (1) Smaller than DTD: if it is downloaded from a server as a separate file, it should be downloadable in the first packet group, so less than 512 (the minimum MTU) -100 (for MIME header) =412 bytes; (2) Implementable by a streaming processor; (3) No forward references; (4) No pathological schemas as far as blowouts; (5) An efficient implementation should be possible; (6) Suitable for coarse validation of document for some significant issues; (7) The schema should be namespace-aware; (8) The minimal schema should only require 1 element or perhaps fit in a PI; (9) The datatype should be expressible using XML Schemas regular expressions or simple space-separated tokens; (10) The schema paradigm is the (partial) ordering of elements against the information kept during stream processing... A Hook schema is an element containing a list of element names, some of which may be grouped by square brackets. This list represents a certain ordering of the names and validation consists of checking conformity to this ordering. The DTD for the language is [7 lines]... Hook seems to suit languages that have large flat bottoms, languages specific requirements early on in each content model, languages with specific elements that do not re-occur in different contexts with different priorities, languages with attributes that are not vital or will be checked by other mechanisms. Hook would seem useful as a coarse-grained but ultra-terse validation language. If we say that validation is to catch errors that are most likely to happen, the most likely errors are spelling errors, children in the wrong order, and required parents: Hook gets or catches most. How much would this help an interactive editor? It would know which elements can start, but for new documents it would present to many choices: however if editing existing documents it would cull the available list pretty well, because it would know what the current level was. It would know empty elements... Joe English has posted interesting material regarding formalisms for Hook, algorithm for implementing and other material..." [February 09, 2001] "The Politics of Schemas: Part 2." By Kendall Grant Clark. From XML.com. February 07, 2001. ['Having established in the first half of this essay that schemas are essentially political, this second installment examines the relevance of this to the XML community, and avenues for further consideration.'] "You may find yourself agreeing that schemas are political but wondering, nevertheless, what it has to do with XML practitioners or with XML itself. XML is, however, a universal data format. If we take the universal claims made about XML seriously, professional schema-makers must ask whether some interests and views of contested concepts might be excluded, perhaps systematically, from schema-making and from schemas; whether such exclusion is socially beneficial or harmful; and, if harmful, what should be done about it. From the early days of XML's development there's been talk about vendor neutrality, interoperability, and universality. Such talk was part of SGML's appeal since the mid-70s and rightly so. Today that talk fails regularly to take account of politics. XML advocacy often ignores the fact that schemas may be vendor neutral but cannot be interest neutral; that schemas may be universally accessible but formalize a strongly contested understanding of a vital part of the world; or that schemas may distort or impede some people's interactions with the world in ways they find inequitable or inappropriate. XML schemas are often placed in the public domain and available for anyone's royalty-free use (subject obviously to uncommon levels of knowledge and expertise) -- a state of affairs clearly preferable to proprietary alternatives. But is it enough? What good does it do that one can use, even modify a de facto standard schema, royalty free, when the schema reflects interests inimical to one's own, formalizes an understanding of the world one strongly contests, and is used in a widely deployed, vital Semantic Web application that has no serious competitor? What good does it do to modify the schema to reflect one's own interests and understandings if doing so renders it unusable? [...] Political schemas may limit what we notice, what we can say or think about what we notice, and to whom we can say it, especially inasmuch as we use machines to mediate parts of the world to us. The Semantic Web vision means, if anything at all, creating software systems that mediate the world to some of us in useful and, one hopes, fair, just, and good ways. What XML technologists say and think and do about the politics of schemas, the Semantic Web, and the social benefits of the technology they create will go a long way to determining the Web's future, and maybe something of society's future too. I hope I at least have said enough to encourage the wide-ranging and free conversation it is the responsibility of XML technologists, along with others, to have." [February 09, 2001] "XML-Deviant: Schemarama." By Leigh Dodds. From XML.com. February 07, 2001. ['For the past two weeks XML-DEV has seen fascinating exchanges between three inventors of alternative XML schema proposals.'] "During the last week, XML-DEV has been the scene of a series of interesting and innovative discussions concerning schemas in general and also specific schema languages. The XML-Deviant provides a round-up. Grammars Versus Rules: Most schema languages rely on regular grammars for specifying schema constraints, a fundamental paradigm in the design of these languages. The one exception is Schematron, produced by Rick Jelliffe. Schematron throws out the regular grammar approach, replacing it with a rule-based system that uses XPath expressions to define assertions that are applied to documents... A unique feature of Schematron is its user-centric approach, allowing useful feedback messages to be associated with each assertion. This allows individual patterns in a schema to be documented, giving very direct feedback to users. Indeed a recent comparison of six schema languages highlights how far Schematron differs in its design. At times the discussion strayed into comparisons of several schema languages. Rick Jelliffe provided his interpretation of the different approaches behind TREX, RELAX, XML Schemas and Schematron: 'Underlying Murata-san's RELAX seems to be that we should start from desirable properties that web documents need: lightweightedness, functioning even if the schema goes offline (hence no PSVI) and modularity. I think underneath James Clark's TREX is that we can support plurality if we have a powerful-enough low-level schema language into which others can be well translated. I think underlying W3C XML Schemas is that a certain level of features and monolithicity is appropriate (though perhaps regrettable) because of the need to support a comprehensive set of tasks and to make sure that there are no subset processors (validity should always mean validity); however the processors are monolithic but the schemas are fragmented by namespace. Underlying Schematron is that we need to model the strong (cohesive) directed relationships in a dataset and ignore the weak ones, that constraints vary through a document's life cycle, and that lists of natural language propositions can be clearer than grammars.' [...] James Clark's summary of the advantages of TREX over W3C XML Schemas is also worth reading in its entirety. TREX, like Schematron, is a very simple yet powerful schema language..." Data Sheet for the Hackerlab Rx XML Regular Expression Matcher. "Hackerlab Rx-XML is a regular expression pattern matcher for Schema-capable validating XML processors. It is also a general purpose Unicode regular expression matcher. Key Features: Rx-XML is fast and accurate; Supports the regular expression language specified in the W3C document 'XML Schema Part 2'; Supports alternative regular expression syntaxes; Clean and simple 'classic C' interface; Patterns may use UTF-8 or UTF-16; Strings compared to compiled patterns may use UTF-8 or UTF-16; Provides protection against encoding-based illegal data attacks: Ill-formed encoding sequences (e.g., non-shortest form UTF-8) are detected and rejected during regular expression compilation and matching; Configurable space/time trade-offs; Ready for Unicode 3.1: Designed for a character set with 2^21 code points; Validation tests are included; Postscript and HTML documentation is included. Hackerlab Rx-XML is part of the Hackerlab C Library which is distributed under the terms of the GNU General Public License, Version 2, as published by the Free Software Foundation..." See also the An Introduction to XML Regular Expressions [sw]. [February 05, 2001] "XML Schema Slowly Matures. XML Schema can't fix everything by itself, but it fills a gaping hole in the XML group of technologies and specifications." By Don Kiely (Third Sector Technologies). In XML Magazine Volume 2, Number 1 (February/March 2001). ['XML's Document Type Definition provides a means of defining XML structure. DTDs are well supported in the software industry, but they come with a substantial set of problems, too. Can this marriage be saved? Find out how XML Schema may save structured XML.'] "Now that the XML Schema specification is a W3C candidate recommendation, it is entering a period of its life when the standards committee thinks that all the basic parts are there and working. There are still a few kinks to work out, but people are encouraged to start building proof-of-concept tools and applications. With any luck, it will hit full maturity sometime later this year, and we'll have full benefit of all its features. But what's the big deal about those features? The XML 1.0 recommendation has a means of defining XML structure built into it, the Document Type Definition, or DTD. DTDs are well supported in the software industry because of their origins with SGML, and XML is a derivative language of SGML. There are lots of DTDs out there doing lots of good work, and lots of people understand them well. There is a wealth of books, journal articles, and Web resources that provide plenty of information about them. The problems with DTDs are several. DTDs are a decidedly non-XML syntax that is hard to learn, they have no sense of data types and only the loosest limits on some structural constraints, they have a closed architecture, they lack support for namespaces, and generally they do not adhere even to the most trivial of the goals built into the design of XML. Probably the biggest issue driving the XML Schema specification is the lack of data types in DTDs. Even if you ship me an XML document that declares itself to be strictly compliant with a DTD, the XML data can have almost random data as element content and attribute values, even if the element name clearly suggests an integer or floating point number, for example. Very messy, and very unlike XML... The listings and code that accompany this article use sample XML data from the XML Schema Part 0: Primer candidate recommendation document for purchase order data... In general, you'll want to validate XML data that is shared between different applications, particularly if you don't have control over both applications. This way the application that is consuming the XML data doesn't need to have extensive data-checking code to make sure that the data is usable and in the structure it expects. Depending on the validation structure you use, you still may need to do some programmatic error checking. For example, when using a DTD for validation, you'll still need to check that content and attribute values can be converted from their string representation to the type of data you are expecting, such as currency or date values. On the other hand, if you have control over both ends of the data sharing, such as two applications you wrote or between two components in a single application, you may be able to forego validation and save the processing cycles. It really boils down to yet another of many design and architecture decisions necessary for software development. XML Schema, unlike XML itself, is unlikely to cure the world of all its ills. But it fills a gaping hole in the XML group of technologies and specifications and can achieve full status as a W3C recommendation none too soon." [February 02, 2001] "The Status of Schemas." By Steve Gillmor and Sean Gallagher. In XML Magazine (February/March 2001). ['The XML Schemas specification, now one step closer to finalization, will enhance XML document exchange on the Web'] "The W3C XML Schema specification has advanced to candidate recommendation status after several years of effort. Editorial director Sean Gallagher and editor in chief Steve Gillmor talked with IBM E-Business Standards & Technology Lead David Fallside, IBM representative to the W3C Schema Working Group and the W3C Advisory Committee and chair of the XML Protocol Group, and Lotus Distinguished Engineer Noah Mendelsohn, IBM and Lotus representative to the W3C Schemas Working Group and the W3C Advisory Committee. Mendelsohn: [an overview of the significance of the XML Schema specification as it reaches CR] 'XML provides a standard means of interchanging data and documents, especially on the World Wide Web. XML Schemas is a standard way of interchanging descriptions of those documents, and that's important not only because it gives you a way to validate that the document you receive is in some sense correct -- that it meets at least the minimum standards for format and content -- but Schema descriptions will be extremely important in supporting a variety of tools. There will be Schema-aware editing systems that use the Schema to help create a better editing experience. There will be tools for mapping XML into various database systems that will use the information in the Schema to find out what needs to be mapped, or will produce Schemas to expose to the world the kind of information that they're making available. Schemas will be key for building XML queries -- before you know what you're querying, you have to know what it looks like. Schemas as a whole are a core foundation technology that moves XML forward for all of these applications.' Fallside: 'Candidate Recommendation [CR] is the stage where the W3C solicits implementation experience from other W3C members and the world at large on the XML Schema specification. Achieving candidate recommendation status is a way for the W3C to say that we believe that this is a stable draft of the specification; it's stable to the extent that people should be comfortable building implementations using this specification, and we would like your feedback based on those implementations.'..." [January 31, 2001] XML Schema FAQ. By Francis Norton. 2001-01-31. See the supporting documents on the www.SchemaValid.com web site. The source for the FAQ document is XML conforming to a FAQ Schema; it has been formatted into HTML with FAQ Stylesheet. "[XML] DTDs have several limitations, one of which is the fact that they are not written in standard XML data syntax. This means, for instance, that while it is quite possible to write an XSLT transform to document an XML Schema, there are far fewer tools to process DTDs. XML Schema also offers several features which are urgently required for data processing applications, such as a sophisticated set of basic data types including dates, numbers and strings with facets that can be superimposed - inlcuding regular expressions and minimum and maximum ranges and lengths..." [cache from new URL] [January 19, 2001] "XML Schema Extension Mechanisms." By David E. Cleary. December 2000. "This presentation documents the two methods for extending XML Schema with application specific information. It includes examples of real world uses of these extensions today." Examples: "(1) XMLSchema-hasFacetAndProperty.xml - This is the schema for the facet and property appinfo extension. This interesting thing to note is that the human readable documentation in the schema specifies how an application should use this extension. For instance, it specifies how you determine what facets and properties user defined datatypes supports via walking the basetype chain. (2) enum2.xml - This is an annotated version of TextNumbers that includes localized enumerations. Applications that support this extension can use these localized enumerations for their UI instead of relying on the English version. (3) appinfo.xml - This is the XML Schema definition for the appinfo element taken directly out of the Schema for Schemas. It shows it allows an attribute called source that is of type uriReference. It also supports mixed content (i.e., both character data as well as child elements) and uses the "any" wildcard to specify it can have any content. Make note of the processContents attribute that is set to lax, which sets validation rules. (4) string.xml - A fragment of the XML Schema datatypes schema. This schema uses an appinfo extension that specifies what property and facets a datatype supports. This extension is also used in generating the datatypes specification." [cache] [January 19, 2001] "4th Generation XML Application Development." By David E. Cleary. December 2000. "This presentation discusses an application development methodology that relies on molding XML instance data to your application as opposed to writing your application based on the XML vocabulary used. It details how Progress Software uses schema annotation to map XML data to business logic and includes a example of using this methodology to map XML instance data to existing Java classes... The SchemaMapper application requires the Xerces-J Parser from Apache to be in your classpath. If you are using Microsoft's JVM, you can do this by adding an entry for xerces.jar in the registry. To use the SchemaMapper, you just give it a qualified filename of an XML instance document. The instance document must conforn to a schema located in the Schemas directory." See the announcement. [cache] [January 16, 2001] "The W3C XML Schema Specification in Context." By Rick Jelliffe. From XML.com. January 10, 2001. ['This article compares the W3C XML Schema Definition Language with XML document instances and DTDs, SGML DTDs, Perl regular expressions, and alternative schema technologies such as RELAX and Schematron.'] "This article gives simple comparisons between the W3C XML Schemas and [related formalisms:] W3C XML instances, W3C XML DTDs, ISO SGML DTDs, ISO SGML meta-DTDs, Perl regular expressions. And some technologies that have arisen as a response to it: JIS RELAX, Schematron, DSD. It does not provide an exhaustive list of all W3C XML Schemas features. The information was prepared with the October Candidate Recommendation versions in mind. W3C XML Schemas does not operate on marked-up instances per se, but on the information set of a document after it has been parsed, after any entity expansion and attribute value defaulting has occurred. Think of it as if it were a process looking at the W3C DOM API. The result of schema-validating a document is a set of outcomes giving, in particular, any violations of constraints -- there is currently no standard API for this; however the W3C XML Schemas specification gives a complete list of the constraint violations; an enhanced information set, the post-schema-validation information set, which can include various details about type and facets -- there is currently no standard API for this either; however, the W3C XML Schemas specification gives a complete list of the additional information...W3C XML Markup Declarations (DTDs) are geared to provide simple datatyping on attributes sufficent to support graph-structures in the document only. W3C XML Schemas are intended to provide a systematic datatyping capability. W3C XML DTDs provide a basic macro facility, parameter entities, with which many good effects can be achieved. W3C XML Schemas reconstructs the most common of these in various high-level features..." [January 13, 2001] Updated DTD to XML Schema Conversion Tool. Mary Holstege posted an announcement for the release of an updated version of a DTD to XML Schema tool. I am attaching an updated version of the Perl script ['dtd2xsd.pl'] that is available on the W3C site. This new version makes the following changes: (1) Use the CR syntax instead of the April [XML Schema] draft syntax; (2) Add support for an external mapping file for type aliases, simple types, model, attribute, and substitution groups; (3) Map ANY correctly to wildcard rather than element 'ANY'; (4) Support for treating lead PCDATA as string or other aliased simple type instead of as mixed content (may be more appropriate for data-oriented DTDs) e.g., <!ELEMENT title (#PCDATA)> => <element name="title" type="string"/>; (5) Support subsitution groups (simplistically). For the record: this update has no official standing... It is worth pointing out that this tool does not produce terribly high quality schemas, but it is a decent starting point if you have existing DTDs." See Mary Holstege's web site for samples and documentation on this version of the application. [January 13, 2001] Zvon XML Schema Reference. By Miloslav Nic. January 09, 2001. "This reference is based on W3C Candidate Recommendations for XML Schema Part 1: Structures and XML Schema Part 2: Datatypes. This reference will be upgraded when the standard is finalized. This reference consists of two parts: (1) Schema browser - based on the analysis of normative XML Schema; (2) DTD browser - based on the analysis of non-normative DTD. Main features of the XML Schema reference include: (1) Clickable indexes and schemas. (2) Click on 'Annotation Source' leads to the relevant part of the specification." The Zvon web site provides tutorials for a wide range of XML-related technologies (DOM, XSLT, CSS, XML DTDs, XHTML, XLink, XPointer, SVG, etc.). [October 12, 2000] (Beta) XSDs for XMLSpec, XLink, and Namespaces documents. Note of 12 Oct 2000: "As my initial foray into non-toy XML Schemas, I took a stab at creating an XML Schema for the XML Specification doctype. My goal was to write an XML Schema that was configurable in the same general way that Maler/Andaloussi-methodology DTDs are, and that would validate the same set of documents (modulo additional constraints that DTDs can't express). I'm sure I've overlooked things, possibly large things, but the schema at http://dev.w3.org/cvsweb/spec-prod/schema/ now validates the XML 2e Recommendation with XSV 1.166/1.77 of 2000/09/28 15:54:50." - Norm Walsh. See "XML Specification DTD." [February 26, 2000] Comparison of XML/SGML DTDs and the W3C XML Schema Specification. Rick Jelliffe (Academia Sinica Computing Centre) announced the availability of a learning document which compares SGML/XML DTDs with the new W3C XML Schema specification. The document will be useful alongside the W3C's new XML Schema Part 0: Primer as an aid to understanding the specification. "This note gives simple comparisons between XML Schemas and the technologies that have influenced it. The XML Schema Specification in Context does not provide an exhaustive list of all XML Schemas features. [...] As an aid to the bewildered, I have started making a little note comparing XML Schemas from the new [2000-02-25 W3C] draft and: (1) XML DTD; (2) SGML DTD, and (3) SGML meta-DTD (architectures). A draft is at http://www.ascc.net/~ricko/XMLSchemaInContext.html. This draft is not suitable/stable/correct enough for linking or reference, but I hope some people may find it useful. Any improvements are welcome. Sections on Murata-san's RELAX or Nils' DSD or other schema languages would be nice too; I may put in something about Schematron too; I hope we can avoid juvenile acrimony and have friendly discussions on the features and niches that the various Schema languages will lend themselves to." Note, in this connection, a recent request from C. Michael Sperberg-McQueen and Dave Hollander (Co-chairs, W3C XML Schema Working Group) that the new three-part XML Schema specification be read in preparation for the upcoming XML Schema discussion at XTech 2000: "Those interested in XML Schema may want to take a look at the new draft before the town-meeting on XML Schema Tuesday night at XTech." The URLs are: (1) Primer, (2) Structures, and (3) Datatypes. [March 31, 2001] XSV and XSU: see PR 2001-0-316 version of XSV and XSU. [June 22, 2000] [See previous entry.] New UNICODE Version of W3C/LTG XML Schema Validator Released. Henry S. Thompson (W3C XML Schema Structures Co-Editor; HCRC Language Technology Group, University of Edinburgh) recently announced an updated release of the online W3C/LTG 'XML Schema Validator, XML Output Version'. "The original 8-bit-only, text output version of XSV has been retired, as signalled last week. The full UNICODE version, with text/xml output, is now the main line public version, and it's at a new address, [was: http://www.w3.org/2000/06/webdata/xsv]. The usage of XSV is up -- running at roughly 100 validations a day, with a high of nearly 200 last Friday. Thanks to those who tick the 'Contribute' box -- I'm about to harvest recent contributions and expand the regression test suite to reflect the increase in breadth of usage. The latest version has a number of bug fixes and improved compliance in the area of enforcing content-model determinism. Of the not-yet-implemented-by-XSV aspects of XML Schema, I would welcome feedback on what users are most keen to see covered first, [from among]: (1) Simple type conformance, other than enumerations and max/min for numeric types; (2) Detailed enforcement of derivation by restriction; (3) Full XPath expressions for identity constraints; and (4) Post-schema-validation infoset contributions." Readers are invited to note, in this connection, activity on the [email protected] discussion list, which is publicly archived on the W3C server. Henry Thompson announced this public list on April 07, 2000 with a message "'XML Schema Developers List Launched': To accompany the XML Schema Last Call drafts, the W3C is pleased to announce the opening of a public mailing list for XML Schema implementation developers, [email protected]. To subscribe, send mail to [email protected] with 'subscribe' as the subject." [April 27, 2000] [See previous entry.] XSV: W3C/HCRC Language Technology Group XML Schema Validator. The W3C Web site now hosts an 'XML Schema Validator', referenced from a document entitled 'W3C/HCRC Language Technology Group Schema Validator'. [was: http://cgi.w3.org/cgi-bin/xmlschema-check] The XML Schema validator has been provided by Henry S. Thompson and Richard Tobin (Language Technology Group of the Human Communication Research Centre in the Division of Informatics, University of Edinburgh); the Web interface is from Dan Connolly. XSV (XML Schema Validator) is an open source (GPLed) work-in-progress attempt at a conformant schema-aware processor, as defined by XML Schema Part 1: Structures. Documentation on the current status of XSV is provided on the LTG Web site. The easiest way to use the Schema Validator is to enter one or more URL in the forms interface. The form provides a check-box to check if you want to attempt schema-validation even if the schema(s) have errors. Additionally, one may download the (Python) sources from the W3C public CVS repository. Note: also now the announcement of 2000-05-05 posted to XML-DEV: "You are invited to experiment with the open source Edinburgh/W3C schema validator XSV, via a webpage interface. It will schema-validate instances using schemas, and as an obvious special case, check schemas against the schema for schemas. This is an alpha release, which is undoubtedly buggy, and known not to check everything it should, but please do use it, and if you are willing, tick the box which lets us copy your schemas to build up a regression test suite." See also the reference page for XML 'DTD' and well-formedness validation. [XSV noted by Don Box as "Henry Thompson's most excellent schema validator" 2000-04-27] Note 2000-05-28 - new test version with XML output options. [August 10, 2000] 'XML serialization of a XML document'. "We have been developing a schema for representing the infoset of a document, with the intention of using it to compare the output of XML Schema implementations. See the directory www.cogsci.ed.ac.uk/~richard/infoset/0718/. infoset-basic-subset.xsd is a schema allowing any subset of the infoset. infoset-psv-subset.xsd is the same for the post-schema-validation infoset. From Richard Tobin, posting to XML-DEV, 2000-08-10. [cache] [December 01, 2000] "Tutorials: Using XML Schemas. Part 1." By Eric van der Vlist. From XML.com (November 29, 2000). ['In the first half of this introduction to XML Schemas, a W3C XML language for describing and constraining the content of XML documents, we cover the basics of creating structured, readable schemas.'] "This is the first of a two-part introduction to the W3C's XML Schema technology. XML Schemas are an XML language for describing and constraining the content of XML documents. XML Schemas are currently in the Candidate Recommendation phase of the W3C development process... The second part of this tutorial will cover mixed-content types, identity constraints, building reusable schemas, using namespaces, and referencing schemas from instance documents." See also Part 2. [December 22, 2000] "Using W3C XML Schema. Part 2." By Eric van der Vlist. From XML.com. December 15, 2000. ['The second half of a comprehensive introduction to the W3C's XML Schema Definition Language, including coverage of namespaces, object-oriented features and instance documents.'] "In the first part of this series we examined the default content type behavior, modeled after data-oriented documents, where complex type elements are element and attribute only, and simple type elements are character data without attributes. The W3C XML Schema Definition Language also supports the definition of empty content elements, and simple content elements (those that contain only character data) with attributes..." [December 22, 2000] "W3C XML Schema Tools Guide." ['A run-down of editors, validators and code libraries with support for XML Schema.'] By Eric van der Vlist. From XML.com. December 15, 2000. "The list of tools supporting XML Schema is still short, reflecting the fact that the specification is not yet a W3C Recommendation. When using a tool, check that it supports the version of XML Schema you are expecting: we've listed the support available at the time of writing. The most recent version of XML Schema is the Candidate Recommendation, dated 2000/10/24." [December 01, 2000] "Reference: W3C XML Schema Structures Reference." By Eric van der Vlist. From XML.com (November 29, 2000). ['A complete quick reference to the elements of the W3C XML Schemas Structures specification, including content models and links to the original definitions.'] "The quick reference below has been created using material from the W3C XML Schema Candidate Recommendation, 24-October-2000. Links to the original document are provided for each element (labeled as 'ref' after each element name)..." [December 01, 2000] "Reference: W3C XML Schema Datatypes Reference." By Rick Jelliffe. From XML.com (November 29, 2000). ['A brief primer on the essential aspects of the W3C XML Schema Datatypes, including a diagrammatic reference to the XML Schemas Datatypes specification.'] "This quick reference helps you easily locate the definition of datatypes in the XML Schema specification. A 'What You Need To Know' section gives a brief introduction to the way datatypes work... W3C XML Schema specification defines many different built-in datatypes. These datatypes can be used to constrain the values of attributes or elements which contain only simple content. These datatypes are not available for constraining data in mixed content. All simple datatypes are derived from their base type by restricting the values allowed in their lexical spaces or their value spaces. Every datatype has a set of facets that characterize the properties of the datatype. For example, the length of a string or the encoding of a binary type (i.e., whether hex encoding or base64). By restricting some of the many facets, a new datatype can be derived. There are three varieties of datatypes that you can use when deriving your own datatypes: as well as atomic datatypes, where the data contains a single value, you can derive a list, where the data is treated as a whitespace-separated list of tokens, and a union type, where the lexical value of the data determines which of the base types is used... There is no [current] provision for (1) overriding facets in the instance document, (2) creating quantity/unit pairs, (3) declaring n>1 dimensional arrays of tokens, (4) specifying inheritance effects, (5) declaring complex constraints where the value of some other information item in the instance (e.g., an attribute) has an effect on the current datatype." [December 08, 2000] "Talks: XML 2000 Focuses on Schemas." By Eric van der Vlist. From XML.com. December 06, 2000. ['Reports from the first afternoon of the "XML Leading Edge" track from XML 2000, which was dedicated to the W3C XML Schema Definition Language.'] "XML 2000 dedicated the first afternoon of its 'XML Leading Edge' track to W3C XML Schema. The sessions highlighted XML Schema's application for validating documents, showed its extensibility, and presented applications that separate logic and presentation from the structure of the document. The first presentation was a rapid overview of the specification, currently a Candidate Recommendation, by Michael C. Sperberg-McQueen, co-chair of the W3C XML Schema Working Group. Sperberg-McQueen began with an introduction in which he explained that error detection, even at a purely syntactic level, may be very beneficial by showing flaws in the expression of what a programmer writes... Matthew Fuchs, from Commerce One, in his presentation entitled 'The Role of an Extensible, Polymorphic Schema Language for Electronic Commerce Communities', talked about the possibilities created by the object-oriented features of W3C XML Schema for defining the extensible vocabularies needed in global marketplaces... Lee Buck, from TIBCO, presented the Schema Adjunct Framework, an initiative to define a common vocabulary to extend W3C XML Schema for different purposes, such as database mappings or business rules validation... Matthew Gertner, from Schemantix, went further down the extensibility path by showing how schema-based development might be 'A New Paradigm for Web Applications'. He begain by saying that rich data types and inheritance are the features that categorize modern computing, going so far as to present W3C XML Schema and its extensions as a 'Universal Data Model' that can be used to define database mappings and to generate the classes of an application." [October 16, 2000] XML Schema: A W3C Recommendation?" By Michael Classen. From Webreference.com. October 16, 2000. Now that the XML Schema specification is one step away from becoming a W3C Recommendation, it is a good time to take a closer look at the new improved way to declare document type definitions. As mentioned in [XML] column10, DTDs have a number of limitations: (1) The syntax of a DTD is different from XML, requiring the document writer to learn yet another notation, and the software to have yet another parser; (2) There is no way to specify datatypes and data formats that could be used to automatically map from and to programming languages; (3) There is not a set of well-known basic elements to choose from. DTDs were inherited by XML from its predecessor SGML, and were a good way to get XML started off quickly and give SGML people something familiar to work with. Nevertheless it became soon apparent that a more expressive solution that itself uses XML was needed... XML Schema offers a rich and flexible mechanism for defining XML vocabularies. It promises the next level of interoperability by describing meta-information about XML in XML. Various tools for validating and editing schemas are available from the Apache Project and IBM alphaworks." [December 05, 2000] "TIBCO Software Launches First Infrastructure Software Product for Managing XML Assets. XML Canon/Developer Delivers First Collaborative, Internet-Enabled, XML Schema And DTD Repository." - "TIBCO Software Inc., a leading provider of real-time infrastructure software for e-business, today announced XML Canon/Developer (XCD). XCD, the first member of the XML Canon family, is a comprehensive development platform that enables the life cycle management of XML-based business rules in a Web-accessible repository. XCD allows businesses to dynamically create and adapt XML-based standards that facilitate collaboration for e-business internally and with trading partners, customers and industry groups. The XML Canon product line supports the diverse requirements and various stages of XML development organizations are implementing. First to be launched is XCD for organizations developing and deploying XML infrastructure assets (e.g,. XML schemas, DTDs, instance documents, stylesheets, or adjuncts.) Features: (1) Managing Business Rules and Taxonomies: Access and manage the inter-relationships of an organization's e-business rules or XML schemas at a granular level. (2) Web-enabled Collaboration: internal and external exchange and collaboration of e-business rules based on customizable access control. (3) Life Cycle Management: configurable staging for all XML infrastructure assets, including DTDs, XML schemas, adjuncts, instance documents or stylesheets. (4) Extensible Architecture: extend and integrate with existing applications without having to re-architect them through the processing technology of XCD. (5) Full integration: across TIBCO Extensibility product family: Turbo XML, XML Authority, XML Instance, and XML Console. XML Canon/Developer will run on Windows 2000, NT 4, SP6 with support for SQL 7.0 SP1 or Oracle 8i. Microsoft IE 5.0 or 5.5 is also required. TIBCO's Extensibility client interface Turbo XML is also required." [December 04, 2000] IBM Regex for Java. "Regex for Java is a powerful, high-performance regular expression library. Regex for Java supports almost all features of Perl5's regular expression. It also supports the syntax of XML Schema's regular expression. Runs on all Java platforms, JDK/JRE 1.1, or later." [June 15, 2000] Extensibility has announced the release of XML Instance, a 'Breakthrough Schema Driven Data Editor. XML Instance is a schema-driven XML business document editor which provides real-time validation and editing facilities against an XML schema or DTD. XML Instance is the ideal platform for the creation of XML business documents, messages, and configuration files for use in XML-based applications. Organizations can embed their XML-based business rules in an XML Instance document so that internal, trading partner, and industry standards are achieved. XML business documents can be generated and edited conforming to DTDs or schemas in major and emerging XML schema dialects including, XDR, SOX v.2 and a sub-set of XSDL (April 7) processors, bridging diverse e-business environments. . . When opening an existing document with a schema reference, XML Instance automatically locates and loads the schema, producing a template which facilitates fast and accurate document editing. When creating a new document, a schema can be set to create a fresh template. XML Instance supports all major and emerging schema dialects. The support of these dialects creates flexibility when exchanging or receiving XML business documents. XML Instance provides thorough document-building guidance based upon the rules of the schema. Real-time validation facilities ensure accurate data representation and promote seamless and accurate data interchange with your trading partners and industry groups. XML Instance is now available for download. [December 08, 2000] "Schemantix (formerly Praxis) to Launch Schemantix Development Platform (SxDP) at XML 2000. Innovative New-Generation Web Platform Makes Its Debut At Premier XML Conference." - "Schemantix today [2000-11-29] announced that it will be launching Schemantix Development Platform (SxDP), the world's first XML schema-driven web development platform, at XML 2000 in Washington, DC. SxDP takes advantage of the innate power of XML to provide a next-generation platform for developing and deploying powerful applications on the Web. Traditional template-based Web development languages (such as PHP, Allaire ColdFusion and Microsoft ASP) have reached their limits, and developers are actively seeking more flexible and robust solutions. Companies using existing systems are particularly frustrated by the overwhelming task of maintaining large-scale applications using hundreds or even thousands of templates. Moreover, since these systems mix application logic and presentation together in each template, it is extremely difficult to reuse business logic in new applications that do not share the same visual design. In contrast, SxDP uses XML schemas to model application data structures, and XSLT stylesheets to produce the desired application look-and-feel. In this way, modifications to the application can be made centrally by adapting the XML schemas appropriately. Pages using the schemas are updated automatically, significantly reducing the effort needed to maintain large applications. In addition, application logic is cleanly separated from appearance and can be associated with a different presentation simply by changing the stylesheet used to produce the final formatting. Preliminary versions of SxDP have already met with favorable response from industry-leading technology companies. 'Commerce One has performed a detailed technical evaluation of Schemantix Development Platform (SxDP). We are impressed by both the vision behind the platform and its excellent technical implementation.' says Mudita Jain, SxDP is being made available as Open Source software with BSD-style license similar to that used by the Apache Software Foundation, a leading Open Source group. Schemantix plans to develop commercial products on top of the platform, with the first product slated for release in Q3 2001." [August 08, 2000] Envision XML. "Widely known as the manufacturer and vendor of System Architect 2001 the enterprise modeling tool, Popkin Software is poised to launch its attack on the e-business tools market with envision XML, a graphical based XML schema generator and reverser. envision XML will allow users to more easily implement and manage the XML schema, critical for successful implementation of B2B applications and other Web based information technologies including the second generation Web. At the core of envision XML is a data dictionary that stores the definitions used in the schema and allows reuse of these items across the organization. Above the dictionary is the graphical editor providing drag-and-drop facilities to immensely improve productivity, accuracy and standardization of schema development. The reverse engineering facility will let users easily incorporate existing schema into the dictionary to create their own schema management environment." See the announcement of 2000-08-04 [cache]. [September 12, 2000] Matthew Gertner (CTO, Praxis) posted an announcement for Schemantix version 0.3. "Schemantix is our contribution to the frequently recurring discussion about where XML, and XML schemas in particular, are actually useful. In essence, it is a Open Source system for developing web application using XML schemas as the core representation of application data structures. This provides a single point of maintenance for these applications and thus solves many of the problems associated with large-scale web applications written in template-based languages like ASP, JSP, PHP and ColdFusion. For much more on Schemantix, see www.schemantix.com. The current version is an alpha release that includes the functionality for generating HTML forms from XML schemas. The only schema language we currently support is SOX, but we will have preliminary XSDL and DTD support integrated over the next couple of weeks, as well as support for generating reports as well as forms. I'll make a followup announcement as new features become available. The entire system is available in full source code compliant with the J2EE platform. We'd be most interested in any feedback you might have, both with regard to the overall philosophy of the system and the specific implementation. This is an Open Source project, so if anyone would like to find out more about contributing, please contact me directly." Background: "As browser-hosted applications become increasingly complex and sophisticated, popular approaches to web development such as Microsoft Active Server Pages (ASP) and its open-source competitor PHP are reaching their limits. When underlying data structures are changed, each individual template must be checked and modified accordingly -- a maintenance nightmare for larger applications. Schemantix addresses these issues by moving application logic from the individual templates and back-end data sources into a single central location: XML schemas. XML schemas add powerful new facilities supporting object-oriented features such as inheritance, polymorphism and rich datatyping. As such, they represent an ideal repository for storing business and presentation logic that can be reused across an entire web application, from the browser-hosted user interface to the backend data storage engine." [September 23, 2000] "XML Schemas: Best Practices." By Roger L. Costello et al. (1) Hiding (Localizing) Namespace Complexities within the Schema (2) Namespaces: Expose them or Not? Purpose: collectively come up with a set of 'best practices' in designing XML Schemas. The specifics of designing a schema are dependent upon the task at hand. The goal of this effort is to come up with a set of schema design guidelines that hold true irrespective of the specific task. Below are some of the things that must be considered in designing a schema. It is by no means an exhaustive list. For example, it doesn't address when to block a type from derivation, when to create a schema without a namespace, when to make an element or a type abstract, etc. Nonetheless, it is a start to some hopefully useful discussions. First, a quick list of the issues: (1) Element versus Type Reuse; (2) Local versus Global; (3) elementFormDefault - to qualify or not to qualify; (4) Evolvability/versioning; (5) One namespace versus many namespaces (import verus include); (6) Capturing semantics of elements and types ... [June 29, 2000] XML Schema and XML DTDs - will XML Schemas replace XML DTDs? [Opinion by] Rick Jelliffe as of 2000-06-29. XML-DEV post. "For back-end data interchange, especially from a DBMS, you can expect XML Schemas to replace DTDs. They provide better datatyping and they are designed to fit in conveniently with RDBMS and OO languages such as Java. For data that is closer to human users or file-systems, XML Schemas cannot entirely replace DTDs yet. . ." [September 29, 2000] "The Beginning of the Endgame. A Look at the Changes in the Pre-CR W3C XML Schemas Draft." By Rick Jelliffe. From XML.com. September 27, 2000. ['The W3C's XML Schemas technology, vital to the use of XML in e-business, is finally nearing completion. This article catalogs the most significant changes from the recent draft specs,and highlights areas where priority feedback is required from implementors and users.'] "This article looks at those changes in the recent Pre-CR draft of W3C XML Schemas that will most effect developers and users. Requirements for data interchange with database systems have been important during W3C XML Schema's development. The recent changes also support markup languages and schema construction better. The Candidate Recommendation (CR) drafts are slated to appear hot on the heels of the current drafts. The XML Schema Working Group was aware that authors, implementers, schema writers, and technical evaluators needed to know the most recent changes, especially since they include some syntax changes that will affect schemas using type derivation." [August 30, 2000] "The basics of using XML Schema to define elements. Get started using XML Schema instead of DTDs for defining the structure of XML documents." By Ashvin Radiya and Vibha Dixit (AvantSoft, Inc.). From IBM DeveloperWorks. August 2000. ['The new XML Schema system, now nearing acceptance as a W3C recommendation, aims to provide a rich grammatical structure for XML documents that overcomes the limitations of the DTD. This article demonstrates the flexibility of schemas and shows how to define the most fundamental building block of XML documents -- the element -- in the XML Schema system.'] " We have covered the most fundamental concepts needed to define elements in XML Schema, giving you a flavor of its power through simple examples. Many more powerful mechanisms are available: (1) XML Schema includes extensive support for type inheritance, enabling the reuse of previously defined structures. Using what are called facets, you can derive new types that represent a smaller subset of values of some other types, for example, to define a subset by enumeration, range, or pattern matching. In the example for this article, ProductCode type was defined using pattern facet. A subtype can also add more element and attribute declarations to the base type. (2) Several mechanisms can control whether a subtype can be defined at all or whether a subtype can be substituted in a specific document. For example, it is possible to express that InvoiceType (type of Invoice number) cannot be subtyped, that is, no one can define a new version of InvoiceType. You can also express that, in a particular context, no subtype of ProductCode type can be substituted. (3) Besides subtyping, it is possible to define equivalence types such that the value of one type can be replaced by another type. (4) By declaring an element or type to be abstract, XML Schema provides a mechanism to force substitution for it. (5) For convenience, groups of attributes and elements can be defined and named. That makes reuse possible by subsequently referring to the groups. (6) XML Schema provides three elements -- appInfo, documentation, and annotation -- for annotating schemas for both human readers (documentation) and applications (appInfo). (7) You can express uniqueness constraints based on certain attributes of child elements. . ." Also available in PDF format; [cache] [July 21, 2000] XML Schema Conformance at XMLConf. "XML Schema, a W3C work-in-progress, is a very complex specification. The development of test suites and harnesses in this project is intended to help identify underspecified behavior in the spec and to advance the development of conformant processors. Since the specification is subject to change, the test cases in the suite may need to be modified for each release. The initial development thrusts are the development of test cases for specific constraints on schemas and the enhancement of the Java XML conformance harness for use in testing of Java parsers. The suite may be downloaded either as part of the nightly CVS snapshot or by checking out the schema module from the CVS. The development of a designed conformance suite should complement the sample schemas collected by the XML Schema Validation Service (XSV). The SourceForge XMLConf project hosts XML related testing efforts, focusing initially on conformance testing. Notice that all of this software is under the GPL. The first testing effort hosted here addresses XML conformance. It includes test harnesses for Java (with SAX/SAX2) and for JavaScript (with DOM/COM). The second such effort is currently in its early stages, and addresses XML Schema conformance. Other projects discussed include DOM testing, performance measurement, XSLT conformance ... the whole gamut. Basically, if it's an XML related technology and there's enough of a standard API that an automated harness could usefully compare different implementations, it could fit in here. The intention here is provide a home for open, public, collaborative development of harnesses and test cases for testing XML (and related) processors. It complements the corresponding efforts of W3C, NIST, OASIS, and many others..." [October 12, 2000] Noted: An OASIS mailing list 'xmlschema-conf' and corresponding XML Schema Conformance Committee. For related references, see "XML Conformance". [September 14, 2000] "Beyond Schemas." By Scott Vorthmann (Extensibility, Inc.) and Jonathan Robie (Software AG). Paper presented at the Extreme Markup Languages 2000 Conference (August 13 - 18, 2000, Montréal, Canada). Published as pages 249-255 (with 3 references) in Conference Proceedings: Extreme Markup Languages 2000. 'The Expanding XML/SGML Universe', edited by Steven R. Newcomb, B. Tommie Usdin, Deborah A. Lapeyre, and C. M. Sperberg-McQueen. "The Schema Adjunct Framework is an XML-based language used to associate task-specific metadata with schemas and their instances, effectively extending the power of existing XML schema languages such as DTDs or XML Schema. This is useful because in many environments additional information which is typically not available in the schema itself is needed to process XML documents. Such information includes mappings to relational databases, indexing parameters for native XML databases, business rules for additional validation, internationalization and localization parameters, or parameters used for presentation and input forms. Some of this information is used for domain-specific validation, some to provide information for domain-specific processing. No schema language provides support for all the information that might be provided at this level, nor should it -- instead, we suggest a way to associate such information with a schema without affecting the underlying schema language." See the Schema Adjunct Framework overview in the "Schema Adjunct Framework Developer's Guide" and specification document from Extensibility. See also the article in MLTP 2/3. [August 28, 2000] "Comparative Analysis of Six XML Schema Languages." By Dongwon Lee and Wesley W. Chu (Department of Computer Science University of California, Los Angeles Los Angeles, CA 90095, USA Email: {dongwon,wwc}@cs.ucla.edu). UCLA CS-TR 200008 (Technical Report). Also published in ACM SIGMOD Record Volume 29, Number 3 (September, 2000). " Abstract: As XML is emerging as the data format of the internet era, there is an substantial increase of the amount of data in XML format. To better describe such XML data structures and constraints, several XML schema languages have been proposed. In this paper, we present a comparative analysis of the six noteworthy XML schema languages. As of June 2000, there are about a dozen of XML schema languages that have been proposed. Among those, in this paper, we choose six schema languages (XML DTD, XML Schema, XDR, SOX, Schematron, DSD) as representatives. Our rationale in choosing the representatives is as follows: (1) they are backed by substantial organizations so that their chances of survival is high (e.g., XML DTD and XML Schema by W3C, XDR by Microsoft, DSD by AT&T), (2) there are publically known usages or applications (e.g., XML DTD in XML, XDR in BizTalk, SOX in xCBL), (3) the language has a unique approach distinct from XML DTD (e.g., SOX, Schematron, DSD)..." The document is also available in Postscript and HTML formats. [cache] [August 11, 2000] "XML Schema Languages: Beyond DTD." By Demetrios Ioannides (Michigan State University, East Lansing, MI). In Library Hi Tech Volume 18, Number 1 (2000), pages 9-14 (with 6 tables, 14 references). [ISSN: 0737-8831.] Abstract: "The flexibility and extensibility of XML have largely contributed to its wide acceptance beyond the traditional realm of SGML. Yet, there is still one more obstacle to be overcome before XML is able to become the evangelized universal data/document format. The obstacle is posed by the limitations of the legacy standard for constraining the contents of an XML document. The traditionally used DTD (document type definition) format does not lend itself to be used in the wide variety of applications XML is capable of handling. The World Wide Web Consortium (W3C) has charged the XML schema working group with the task of developing a schema language to replace DTD. This XML schema language is evolving based on early drafts of XML schema languages. Each one of these early efforts adopted a slightly different approach, but all of them were moving in the same direction. . . The XML new schema is not only an attempt to simplify existing schemas. It is an effort to create a language capable of defining the set of constraints of any possible data resource. Table VI XML schema goals simply illustrates the XML schema goals. The importance of having a fully fledged and universally accepted schema language is paramount. Without it, no serious migration from legacy data structures to XML will be possible. Databases with unwieldy data structures such as MARC will greatly benefit from such a migration. We will no longer depend on data structures that were predefined years ago to meet different needs. The extensible nature of these schema languages will allow the easy creation of any data structure, thus providing the flexibility mandated by the mutability of today's information needs. Bringing a wealth of metadata into an extensible format and allowing it to take full advantage of the dynamic nature of networking is an extremely exciting prospect for information professionals. The first step, premature as it may be, yet very symbolic, is the CORC Project's creation of a DTD for MARC. In the future, intelligent schemas will allow for blending of existing metadata with full-text, multimedia, and much more. The possibilities are endless..." "Using Regular Expressions - XML Schema Style." [June 29, 2000] "In the Grand Schema of XML." By Yasser Shohoud (devxpert Corporation). In XML Magazine Volume 1, Number 3 (Summer 2000), pages 38-43. ['If you are designing an Internet, intranet, or client-server application, you should be thinking about XML schemas. XML Schema Language is a powerful feature that can be used to validate data in myriad ways and save you time in the process. Yasser Shohoud shows you how.'] "XML Schema Language is likely to become a standard in the near future. Although at the time of this writing, no validating parsers support the current version of the schema language, at least one parser, XML Authority from Extensibility, supports an earlier version of the language. XML Authority version 1.2 is planned for release soon and should support a more current version of the XML Schema Language specification. Also, the MSXML parser supports Microsoft's version of the schema language known as XML-data. Microsoft has plans to support the XML Schema Language when the W3C finalizes it. XML documents can be thought of as containers for data; they are similar to tables in a relational database and objects in an object-oriented language. In relational databases, the Data Definition Language is used to define new data types and create tables using those types, while specifying rules and constraints on columns in those tables. You can then insert data into the tables, and the database will ensure that your rules and constraints are enforced. Object-oriented programming languages let you define classes that have properties whose type may be one of the intrinsic data types or another class. You can then instantiate objects from those classes and set the values of their properties. The run-time type checking system will ensure that property values are of the correct type according to the class definition. An XML document contains one or more elements containing attributes, other elements, and text. As with database tables and object-oriented classes, you need to define rules about the structure, permissible data types, and constraints that apply to each element within the document. These rules would be equivalent to a class definition in Java. An XML document can then be considered an instance of this class definition and therefore be validated against the definition at runtime. Using the XML Schema Language, document authors can define the structure and permissible data types within their documents. Validating parsers can then be used to check conformance of documents claiming to be instances of a given schema. Going back to our database analogy, XML Schema Language is like a DDL for databases, a specific XML schema is like a specific table definition in a database, and an XML instance document is like a record in a database table. The object-oriented language analogy may be obvious by now: XML Schema Language is like the language you use to define a class (for example, Java or C++); a specific XML schema is like a class with properties, and the XML instance document is like an object instance of that class. The object-oriented analogy applies only to class properties, since XML elements are data containers with no methods of their own. . ." [June 22, 2000] "Composite datatypes - XML Schema datatype for date+time." By Rick Jelliffe. "There are [currently, 2000-06-29] no composite datatypes in XML Schemas..." [July 14, 2000] "The results of my W3C XML Schema Questionnaire are now available at http://metalab.unc.edu/xql/tally.html." From Jonathan Robie, Fri, 14 Jul 2000 16:29:35 -0500 [June 22, 2000] Extensible Types (eTypes) - From IBM alphaWorks. 'A Java component library which enables users to specify properties and determine whether objects satisfy these properties.' "Extensible Types (eTypes) is a Java component library that enables users to specify constraints and determine whether objects satisfy these particular constraints. With our first preview release we provide a library built on eTypes that can validate many of the datatypes defined by W3C XML Schema April 7th, 2000 working draft as well as several well know ISO datatypes. An important application of eTypes is the so-called automatic inference of datatypes from XML document instances. Indeed, the eType distribution includes a command line tool for deducing XML Schema text-only types from a set of XML documents or sets of example strings. With eTypes, XML developers will get a head start in writing XML Schemas that constrain the data allowed 'in between' XML tags and attributes..." [January 13, 2001] XML Spy 3.5. An announcement for the evaluation version of XML Spy 3.5 describes the most recent added features of the XML Spy editing tool. "XML Spy is centered around a professional validating XML editor that provides four advanced views on your documents: an Enhanced Grid View for structured editing, a Database/Table view that shows repeated elements in a tabular fashion, a Text View with syntax-coloring for low-level work, and an integrated Browser View that supports both CSS and XSL style-sheets." From the announcement: "Version 3.5 Beta 4 is the last public beta release for our upcoming XML Spy 3.5 product, and includes several new features. Specifically this beta release contains/supports: (1) validation of XML Schemas with integrated error highlighting directly within the Schema design view; (2) improved validation of XML instance documents based on XML Schemas -- it consumes less memory and is much faster; (3) access and manipulate files in any respository that is accessible through an ftp:, http:, or https: URL; (4) browse and manipulate folders directly from the Open/Save URL dialog on any FTP or WebDAV server... [etc.] We are now also offering a quick introduction to the new XML Schema Design View online. If you are interested in working with XML Schema, please visit this URL, which explains the new XML Schema related features in detail: http://www.xmlspy.com/features_schema35.html... XML Spy 3.5 includes a new schema design menu that is available whenever an XML Schema document is opened and displayed in the XML Schema Design View. When you open an XML Schema document, XML Spy displays all globally defined particles (i.e., elements, complexTypes, attributeGroups, etc.) in the XML Schema as a list in the XML Schema Design View. If an element, complexType, or attributeGroup is selected, the corresponding attributes are automatically shown in the list underneath the globals. For each particle that has the little tree symbol next to it, you can click on that symbol to open the content model for that particle in the advanced tree view of XML Spy. To edit the content model, simply use drag&drop to rearrange elements or use the right mouse button for other manipulations. To return to the global view, please use the menu command 'Display All Globals'. To navigate to related elements or types, you can also double-click on the name of any complexType (shown as a rectangle with yellow background) or Ctrl-double-click on any element in the tree view. In addition, the following floating XML Schema Navigator window is always visible and lets you switch to different particles by simply double-clicking them in the list. At the same time, elements can be easily added to the content model, by dragging them from the XML Schema Navigator window onto the desired position in the content model. While most parameters of an element node (such as its name, type, and major facets) can be edited directly in the tree view, the full details of the selected node are always visible (and can be edited) in the detail views in separate floating windows. In addition to offering these flexible editing capabilities, the advanced Schema Design View of XML Spy is also highly configurable and lets the user choose what parameters should be displayed and how the display should be formatted..." [May 02, 2000] XML Spy 3.0 Beta 3 Supports XML Schema. Alexander Falk (Icon Information-Systems) recently announced the availability of XML Spy 3.0 for Windows, including new support for XML Schema/DTD editing and validation. "It is my pleasure to announce the last scheduled beta release of XML Spy 3.0 for Windows, which is no longer only an XML editor, but has matured into a true Integrated Development Environment (IDE) for XML that includes: (1) XML editing and validation, (2) Schema/DTD editing and validation, (3) XSL editing and transformation. XML Spy 3.0b3 contains our new incremental validating parser which fully supports Document Type Definitions (DTD), Document Content Description (DCD), XML-Data Reduced (XDR), BizTalk, and already contains support for most of the new April 7 W3C XML Schemas, which makes XML Spy the first editor that supports the new XML Schema draft from editing through schema validation to intelligent editing of XML instance documents based on the schema. The XML Schema support includes: (1) simpleType & complexType; (2) element & attribute; (3) group, sequence, choice, any; (4) all datatype facets, including user-defined patterns; (5) notation, annotation, documentation, include. [...] The editing tool provides four advanced views on your documents: an Enhanced Grid View for strucutred editing, a Database/Table view that shows repeated elements in a tabular fashion, a Text View with syntax-coloring for low-level work, and an integrated Browser View that supports both CSS and XSL style-sheets." See the web site for a detailed description of new features in XML Spy 3.0. The editor is available for download and 30-day evaluation. [June 10, 2000] "Use XML Even As It Changes. Here's how you can tackle application-to-application integration needs while building a migration path to XML Schema." By James Bean. In Enterprise Development. February, 2000. "The current XML specification uses Document Type Definitions (DTDs) to describe the content and structure of an XML document. However, there's an innovation waiting in the wings: XML Schema. Schema will most likely present the best solution for describing metadata with XML. But current implementations are often based on DTDs. Schema should be adopted rather rapidly, but a number of industry-based XML vocabularies and numerous custom-developed XML DTDs will require a reasonable period of migration. This article will show you how to address your short-term A2A integration needs with XML DTDs and how to build in a handy migration path to Schema, then preview how Schema will most likely work..." [May 03, 2000] "The Schema Adjunct Framework." By Scott Vorthmann and Lee Buck (Extensibility, Inc.). Draft Specification 24-February-2000. ['Introducing Extensibility's Schema Adjunct Framework, an open standard for describing and utilizingschema-level information within processing environments.'] "Software applications that process XML often need to associate additional information with documents beyond the structures and properties that can be expressed in a schema language. For example, they may need to specify how XML structures are mapped into object-based or relational systems, provide business logic associated with structures, state how structures should be formatted, or state additional constraints not expressible in the schema language. If most applications needed the same set of relatively simple extensions, these extensions should be integrated into the schema language itself. In practice, the extensions needed by various systems differ widely, and they may need to be specified in many different ways, including XML data, procedural program code, or query statements. Any schema language that attempted to support the whole range of possible extensions would quickly become unwieldy. A more tractable approach is to provide a general framework that allows users to specify additional information about the structures or properties that the schema defines. For instance, an application that generates HTML forms from XML schemas must associate labels and controls with various elements specified in the schema. Naturally, no schema language supports such HTML-specific statements. To fill such needs, the Schema Adjunct Framework introduces the concept of a schema adjunct, an XML document that contains additional, application-specific data relative to a particular schema. The additional data may be stated in any language that can be placed in an XML document, including query languages, Java, JavaScript, XML-based languages, or prose. A schema adjunct provides the information that enables the use of a schema (and its instances) within a particular application. This means that a given schema can be enabled in a family of interoperating applications by an equal number of adjuncts. Conversely, a given application can be applied to a variety of schemas by supplying an adjunct for each schema." See also the Executive Summary, the Developer's Guide, and the SDK in Java. [April 19, 2000] Curt Arnold has announced the publication of an "HTMLHelp file for the 7-April-2000 XML Schema Working Draft, available at the AEA Technology Web site. This help file has been generated from the 'schema for schemas' appearing in the 7-April-2000 XML Schema W3C Working Draft. There is minimal narration in this help file; however it should be useful for a quick reference and a roadmap to the concrete schema language. The help file does not attempt to document the context-specific variants of elements (for example, the element may not have a name attribute when it is not an immediate child of a element). If you like excessive narration, still available is the help file to an alternative December 17th working [XML Schema] draft where I tried to discuss some of the issues that I had with that draft. Some of the issues have been reflected in later drafts, others have been deferred to later, however some still seem like pressing issues to me, specifically complexType derivation by restriction. Please send any comments on this help file to [email protected]." [April 21, 2000] XML Schema Compiler. Curt Arnold recently announced a 'schema compiler' effort, supported by a developers' mailing list. The XML Schema compiler project has been created to build reference implementations of schema evaluation and simplification in XSLT. The public is "invited to join a project to an open-source XSLT-based compiler for XML Schema. The XML Schema "compiler" project intends to provide reference implementations (and potentially other) of schema processing to: (1) produce analysis of errors in the source schema; (2) produce a compiled form of the schema that contains the expansion of inclusions, imports, complexType derivations, etc, in a form that closely related to the information set necessary for a parser to validate a conforming document. The compiled form should help reduce the potential for hacking by attacking resources used in the schema definition. (3) support transliteration (as much as possible) of XML schema constraints to other validation mechanisms such as Schematron or RELAX; (4) support generation of documentation for schemas; (5) provide a forum to discuss schema related issues; (6) provide feedback to the W3C XML Schema working group; and (7) assist the development of schema-aware (and/or compiled schema-aware) parsers." Project XSDComp is accessible on SourceForge. Note: "I've packaged up my current work as the 0.0.1 version of XML Schema compiler and made it available on the project home page at http://sourceforge.net/project/?group_id=4826; it is definitely a work in progress and has known flaws in addition to unimplemented features. However, it is useful as a validator for XML Schema and a general indication of where the project is going..." [2000-05-01] And Curt Arnold wrote 25-August-2000: ["The XML Schema 'compiler' project intends to provide a reference implementations of schema evaluation and simplification in XSLT."] You might want to check out my XML Schema Compilation project at SourceForge (http://sourceforge.net/projects/XSDComp) which uses XSLT to convert XML Schema to a consise, fully evaluated form (all includes/imports brought into one file, all references converted to ID/IDREF pairs, etc). I've definitely advanced my working copy beyond what I've put in the CVS. If you are interested after taking a look around, I can update it." See the download, [cache] [March 17, 2000] "XSDL - A Next Generation Schema Language to replace DTDs. [XSDL Presentation.]" By Dr. Matthew Fuchs, CommerceOne. Presented at XML SIG (The Center for Information, Connection, and Education). February 24, 2000. "XSDL, A Whirlwind Tour" is available as a set of PowerPoint slides. "For over a year, the W3C's XML Schema Working Group has been developing XSDL, a next-generation schema language to replace DTDs. The goal has been a language to support the requirements of a whole range of applications beyond documents; active participants have included Oracle, Microsoft, HP, Sun, and CommerceOne, among others. The draft Schema language has several features that propel it far beyond DTDs as a means of describing information. It includes both object-oriented extensions for element types and strong datatyping for attribute values and string content. It has strong integration with namespace and a powerful composition mechanism to allow definitions from multiple schemas to work together. This talk will describe the important features of this language, due to become a W3C Candidate Recommendation in March (we will also describe what a "Candidate Recommendation" is), and describe potential applications, such as improved XML/Java integration. While XSDL implementations are not yet available, almost all the significant features are already available in CommerceOne's SOX (Schema for Object-oriented XML), which was one of the inputs to the XSDL process. Participants who are interested in a preview of the future of XML schema languages can download and use our publicly-available SOX parser http://www.marketsite.net/xml/xdk." [From Earl Bingham: "I just heard a presentation last night from Mathew Fuchs from CommerceOne who is on the W3 board for XML Schemas. He gave a great presentation on XSDL and how it is evolving. If anyone is interested I can send out the powerpoint slides and Ialso made a video of the presentation that I can make copies for anyone who wantsit. It also has a great demo of XML Authority software and how this can be used with some of the latest standards." "UML for XML Schema Mapping Specification." By Grady Booch (Rational Software Corp.), Magnus Christerson (Rational Software Corp.), Matthew Fuchs (CommerceOne Inc.), and Jari Koistinen (CommerceOne Inc.). 12/08/99. "This paper describes a graphical notation in UML for designing XML Schemas. UML (Unified Modeling Language) is a standard object-oriented design language that has gained virtually global acceptance among both tool vendors as well as software developers. UML has been standardized by the Object Management Group (OMG). XML Schema is an emerging standard from W3C. XML Schema is a language for defining the structure of XML document instances that belong to a specific document type. XML Schema can be seen as replacing the XML DTD syntax. XML Schema provides strong data typing, modularization and reuse mechanisms not available in XML DTDs. There is currently no W3C recommendation for XML Schema, although several have been proposed and W3C is actively working on producing a recommendation. This paper describes the relationship between UML and the SOX schema used by CommerceOne. Our intention is, however, to adapt the mapping to the W3C recommendation when that becomes available. W3C discussions up to this point indicate the notation described here will be upward compatible with the eventual recommendation." [February 26, 2000] XML Schema for RDF. "For anyone interested, appended is a stab at an XML Schema for RDF. It shows how abstract elements and equivClass is useful for constructing frameworks..." From Rick Jelliffe. [August 04, 2000] XSD for RDF by Dan Connolly. Revision of an XSD sketched by Rick Jelliffe. v 1.17 2000/08/04. [cache] [April 21, 2000] "The Meanings of XML: DTDs, DCDs and Schemas." By Michael Classen. In Internet.com WebReference (April 16, 2000). XPLORING XML - Column 10. ['Don't be scared by the schema. The syntax and semantics of XML are the sources of its strength. Join our Xpert as he reveals the secrets of XML data and structure definitions.'] "So far in this column we ignored the more formal aspects of XML, such as defining the correct syntax and semantics of specific documents. While we examined the set of rules common to all documents (remember well-formed vs. valid documents?), I have so far neglected the mechanisms for specifying your own families of documents..." [September 07, 2000] "Schema Round-up." By Leigh Dodds. From XML.com (September 06, 2000). "Noting an increasing interest in XML Schemas on several mailing lists, this week the XML Deviant takes a look at some of the resources available to the aspiring schema developer." [March 18, 2000] Mark Scardina (Oracle 'Group Product Manager and XML Evangelist') recently announced the availability of Oracle's 'XML Schema Parser', which supports the use of simple and complex datatypes in XML. "Version 0.9.0.0 of the XML Schema Processor for Java is now available on the Oracle Technology Network at http://technet.oracle.com/tech/xml/. This first release of the XML Schema Processor is a companion component to the XML Parser for Java that allows support to simple and complex datatypes into XML applications with Oracle8i. Since these components are implemented in Java, they can run 'out of the box' in the Oracle8i JServer Java VM or in any standalone Java 1.1 or greater VM. The tool supports XML documents in the following encodings: UTF-8, UTF-16, ISO-10646-UCS-2, ISO-10646-UCS-4, US-ASCII, EBCDIC-CP-*, ISO-8859-1to -9, Shift_JIS, BIG, GB2312, EUC-JP, EUC-KR, KOI8-R, ISO-2022-JP, and ISO-2022-KR. The tool incorporates new APIs in XMLParser to invoke XML Schema validation, and new APIs to build a XMLSchema object. The following features are not implemented in this release: (1) unique, key and keyref constrains, (2) derivation by restriction from complexType, (3) pattern facet in string, datetime datatypes, (4) builtin types derived from integer [unsigned] long, short, int, byte), (5) comparison of datetime datatypes. The distribution includes sample XML applications to show how to use the Oracle XML parser with the XMLSchema processor. The Schema Processor supports much of the [2000-02-25] XML Schema Working Draft, with the goal being that it be 100% fully conformant when XML Schema becomes a W3C Recommendation. The XML Schema Processor makes writing custom applications that process XML documents straightforward in the Oracle8i environment, and means that a standards-compliant XML Schema Processor is part of the Oracle8i platform on every operating system where Oracle8i is ported." [December 03, 1999] XML Schema Tutorials at the XML '99 / Markup '99 Conferences.
- Henry S. Thompson wrote on XML-DEV, 29 Nov 1999 [Subject: XML Schema One-day intensive tutorial]: "It's not too late to sign up for the tutorial I'm giving at Markup '99/XML '99 on Sunday: a full day introduction to the up-to-the minute state of XML Schema. We'll be working from a pre-publication version of the next public working draft, due out 16 December, currently anticipated to be the last draft before the WG submits a version to Last Call. Don't miss this chance to pester one of the editors with your personal opinions about what is and isn't right about this important impending W3C recommendation." The blurb: Full-Day Tutorials. 9:00 am - 5:30 pm. XML Schema Languages: A Technical Introduction Instructor: Henry Thompson, University of Edinburgh. "Prerequisite skills: Technical knowledge of XML, XML DTDs, and computer grammars. XML Schema definition language proposes facilities for describing the structure and constraining the contents of XML 1.0 documents. The schema language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs.) This tutorial provides a technically detailed examination of the most recent XML Schema by one of its editors. In addition, the tutorial presents an introduction to schema constraints, types, composition and symbol spaces along with terminology used throughout the specification. Part two of the tutorial discusses specifying a language for defining datatypes to be used in XML Schema."
- Sunday, December 5, 1999. Morning Half-Day Tutorial. 9:00 am - 12:30 pm. A Non-Technical Introduction to XML Schemas Instructor: Murray Maloney, Muzmo Communications Inc. "An XML schema is a formal expression of the structure of an XML document and of constraints on text contained therein. XML's existing Document Type Definition can be used for this purpose. But there is a growing recognition that a DTD is inadequate or inappropriate for expressing what many of the current and anticipated applications of XML require. This tutorial focuses on the requirement for an XML schema language and highlights the concepts of an XML schema definition. It also discusses the ways a schema language will facilitate the use of XML on the Web."
- Also: (1) Monday December 06, 4:45 PM : "Modeling an XML Schema," by Lee Buck, Extensibility, Inc. (2) Wednesday, December 08, 9:00 AM: "XML Schema and Datatypes," by Michael Sperberg-McQueen. 'An XML schema is a mechanism somewhat analogous to DTDs for constraining document structure (order, occurrence of elements, attributes). In addition, specific goals beyond DTD functionality, such as the specification of datatypes have been identified within the scope of XML Schema. This informative session focuses on the emerging XML schema language and the proposed mechanism for specifying datatypes.'
[January 06, 2000] XML Schema Tutorial. Updated September 05, 2000 [or later]. Roger L. Costello (Mitre) recently posted an announcement for a tutorial on the current W3C working draft specification for XML Schema. The document is presented as a set of 91 PowerPoint slides. Roger says: "With a lot of help from this list community and many hours studying the spec, I have created a tutorial on the latest draft (12-17-99) of the XML Schema specification. It is freely available at http://www.xfront.com/xml-schema.html. I personally learn best with examples, so the tutorial contains quite a few examples to demonstrate various features." [cache, 2000-09-06] [May 15, 2001] Mary Holstege's "Conversion Tool (XML DTDs to W3C XML Schema)" based upon Perl. With contributions by Yuichi Koike, Dan Connolly, and Bert Bos. See dtd2xsd.pl from www.mathling.com, May 15, 2001 or later. [cache] [April 20, 2000] See previous entry. DTD to XML Schema Conversion Tool. Based on Perl: perl dtd2xsd.pl [-alias] [-prefix p] [-ns n] [file]. By Bert Bos, Dan Connolly, Yuichi Koike. Said to be 'open source'. [cache] [November 09, 1999] "Family Tree of Schema Languages for Markup Languages" referenced from Rick Jelliffe's Schemas & XML document. [local archive copy] "Resource Description Framework (RDF) Schema Specification." W3C Working Draft 30-October-1998, WD-rdf-schema-19981030. [October 08, 1999] W3C Publishes The Cambridge Communiqué on Web Data Models. The W3C has released a NOTE on Web data models under the title The Cambridge Communiqué. Reference: W3C NOTE 7-October-1999, edited by Ralph R. Swick and Henry S. Thompson. The note constitutes "a report of the results of a meeting of a group of W3C Members involved in XML and RDF to advance the general understanding of a unified approach to the expression of Web data models. This document is one response to the Web data architecture discussed in "Web Architecture: Describing and Exchanging Data". In detail: a group "consisting of W3C Member representatives and W3C staff involved in the XML and RDF activities met on August 26 and 27 [1999] to discuss the architectural relationship between the schema work being undertaken within these two activities. The goals of this meeting were to articulate a vision of this relationship for the Web community, to feed input into the XML Schema Working Group and other W3C activities in support of this vision, and to resolve issues raised in the Member review of the RDF Schema Proposed Recommendation concerning overlap with XML work." The document presents nine (provisional) 'Observations and Recommendations', the first of which states: "The XML data model is the XML Information Set being specified by the XML Information Set Working Group. Other data models exist, both generic and application-specific. RDF is an example of one such generic data model. The XML Schema and RDF Schema languages are separate languages based on different data models and do not need to be merged into a single comprehensive language..." [July 05, 1999] "Understanding XML Schemas. [Schemas for XML.]" By Norman Walsh. From XML.com. July 01, 1999. "In May, the [W3C] XML Schema Working Group (WG) published its first Working Draft (WD). Schemas will have a broad impact on the future of XML for two reasons: first because they will define what it means for an XML document to be valid and second because they are a radical departure from Document Type Definitions (DTDs), the existing schema mechanism inherited from SGML. In this article, I'll explore what schemas are, what validity means, how schemas differ from DTDs, and what new functionality will be gained from adopting them. I'll be using the XML Schemas WD from 6 May 1999 to frame the discussion and as the source for concrete examples. . . Looking at the scope and functionality that schemas will provide, they seem like a great improvement over DTDs. Certain kinds of applications, exchanging information between databases, for example, and ecommerce are clearly going to be made simpler and more interoperable by XML Schema. As I see it, the primary virtue of DTDs today is that they are well understood and they do offer a good way to describe the structure of an document for interchange. It will take some time before XML Schema are as well understood. Until then, we'll be 'flying without a net' to a certain extent, waiting for the final standard and practical, documented methodologies for schema creation to follow." See 'XML Schemas' from the W3C: XML Schema Part 1: Structures and XML Schema Part 2: Datatypes. [December 20, 1999] "Writing a data type-checking XML parser with Xerces." By Bob DuCharme. In IBM Developer Library. December 1999. "While most XML parser developers are waiting for the W3C Schema Working Group's proposal to become a Recommendation before they support it, the Xerces parser donated by IBM to the Apache XML project already supports much of the Working Group's September 1999 Working Draft. In particular, it supports basic data-type checking, one of the most eagerly awaited W3C Schema features. In this article, see how your XML Java applications can take advantage of data-type checking when using the Xerces parser... The first parser I know of that provided any support for the W3C Schema Working Group's XML Schema Definition Language (XSDL) was alphaWorks' xml4j-ea1, a special version of the xml4j XML Parser for Java Early Access release (see Resources). It included support for a subset of XSDL that was backward-compatible with XML 1.0 DTDs. In other words, if you rewrote an XML 1.0 DTD as an XSDL schema that didn't take advantage of any of XSDL's new features, an application using the xml4j-ea1 parser could validate a document against that schema. With xml4j-ea2 and the Xerces parser that IBM donated to the Apache project, the IBM XML Technology Group developers added the feature that developers were clamoring the loudest for: type checking. Because the Working Group still has some issues to work out in Part 2 ("Datatypes") of the XSDL Proposal, the Xerces parser doesn't yet support all the data types mentioned in the proposal. But real numbers, integers, booleans, and of course strings are supported, and your applications can take advantage of this support now." [September 17, 1999] "UML as a Schema Language for XML based Data Interchange." By David Skogan (Department of Informatics, University of Oslo, P.O. Box 1080 Blindern, N-0316 OSLO, NORWAY). WWW. Paper submitted to UML'99. With 26 references. 1999-05-14. Abstract: "The Unified Modeling Language (UML) is here used as a schema language to define data interchange formats based on the Extensible Markup Language (XML). UML is a powerful and flexible modeling language and XML is expected to be the next generation data interchange format for the Web. UML's declarative expressiveness and intuitive visual form overcome XML's current declarative powers. The use of UML as a schema language combined with XML as a data representation language addresses both semantic and syntactic interoperability. A mapping from UML to XML is defined and two prototype implementations are presented. The mapping is inspired by Object Management Group's (OMG) XML Metadata Interchange specification (XMI). It is developed as a part of the ongoing standardization work creating an international standard for geographic information (ISO 15046). It is generic and may easily be adapted to other application domains." Cited in connection with a docment on the document Geographic Information BROWSER 1.0.2.1" - 'A prototype XML import/export facility and browser. Encode, decode, navigate, and edit Geographical Information.' "The GI Browser has been developed in the DISGIS project and is based on ISO CD 15046-18 Geographic Information - Encoding, a standard currently being developed by ISO/TC 211." [local archive copy] [December 03, 1999] "Serializing Graphs of Data in XML." By Adam Bosworth, Andrew Layman, and Michael Rys (Microsoft). From the BizTalk Web site. '1999.' "XML is evolving as the standard format of exchanging data among heterogeneous, distributed computer systems and as such is used to represent data of various origins in a common format. Often, this data possesses rich structure and represents relationship among various entities. These relationships form graphs, where the relations are directed from one entity to another (and may have inverses) and where there may be multiple paths to an entity. Thus, an important goal of the encoding of this data is to preserve the exact graph structure in the serialization to XML. The aim of this paper is to describe a specific way to use XML to serialize graphs of data (such as database tables and relations or nodes and edges from directed labeled graphs) in such a way that the graph structure is preserved and can be reconstructed. A graph of data serialized according to the described rules is said to be in canonical form. Other representations of the same data can be mapped into and out of the canonical form as long as they do not lose or add information. Therefore, the canonical form provides a common basis that can be exploited for information integration across multiple sources and it can be used as a common abstraction for data interchange. This paper does not change the fact that every validatable XML document conforms to a specific grammar. Rather, it proposes a way to mechanically generate, from a database's or graph's schema, a particular grammar that can be used to serialize data from the database or graph, and into which any other serialization of that data can be mapped. The proposal here is not appropriate for every usage of XML (such as documents), but it is appropriate for those usages that are encodings of directed, labeled graphs..." [local archive copy] XOL - XML-Based Ontology Exchange Language. XOL is a language for ontology exchange. It is "designed to provide a format for exchanging ontology definitions among a set of interested parties. The ontology definitions that XOL is designed to encode include both schema information (meta-data), such as class definitions from object databases -- as well as non-schema information (ground facts) , such as object definitions from object databases. XOL is similar to other past ontology-exchange languages; its development was inspired by Ontolingua and OML. XOL differs from Ontolingua in having an XML-based syntax rather than a Lisp-based syntax; the semantics of OKBC-Lite are extremely similar to the semantics of Ontolingua. XOL differs from OML in that the semantics of OML are based on Conceptual Graphs, which have a number of differences from OKBC-Lite." Business Rules Markup Language (BRML). BRML is an 'XML Rule Interlingua for Agent Communication, based on Courteous/Ordinary Logic Programs.' It is used in connection with 'CommonRules' from IBM, and was developed in connection with IBM's Business Rules for E-Commerce Project. A related proposal is given in the 'Agent Communication Markup Language,' a new XML version of FIPA standards-draft Agent Communication Language.' Ontology and Conceptual Knowledge Markup Languages. A communique from Robert E. Kent summarizes new directions for the Ontology and Conceptual Knowledge Markup Languages. Documentation for the Ontology Markup Language (OML) accessible at http://wave.eecs.wsu.edu/CKRMI/OML.html. OML was originally intended to be subservient to the more inclusive CKML (Conceptual Knowledge Markup Language) and to Conceptual Knowledge Processing (CKP). The earlier versions of OML were basically a translation to XML of the SHOE formalism (http://www.cs.umd.edu/projects/plus/SHOE/), with suitable changes and improvements. [The new design] is highly RDF/Schemas compatible, although it has its own solution to the namespace problem; but more importantly, we have incorporated our own version of the elements and expressiveness of conceptual graphs. In fact, the current version of OML may be the first time a framework using XML and equivalent to predicate logic has been placed on the Internet. For these reasons, at least four versions of OML are being considered, each designed for a different purpose: the full Standard OML is regarded as the most expressive and natural; Abbreviated OML is for interoperability with the conceptual graphs standard CGIF (http://concept.cs.uah.edu/CG/Standard.html); Simple OML is for interoperability with RDF with schemas; and Core OML is for logical simplicity." [July 05, 1999] "XML Authority Ends Waiting Game for Schema Developers." By Dale Dougherty. From XML.com. July 01, 1999. [From Extensibility,] "XML Authority is a visual editing environment for creating and testing schemas. It is also good for viewing existing DTDs or other schema examples in a consistent way. For many of us, the syntax of DTDs can be confusing and awkward, and while a visual interface doesn't necessarily spare you from knowing the underlying syntax, it allows you a higher level, interpreted view of the structure you are creating. . . XML Authority regards DTDs and each of the different schema proposals as essentially the same from the developer's point of view. They use different syntax and there are some differences in features but there is a lot in common. Developers can use XML Authority as a consistent interface for building schemas, regardless of whether you want the result saved as a DTD, or in any of the prevalent schema proposals. This allows the developer to be a standards pragmatist and start getting some useful work done today." "Meta Content Framework Using XML", NOTE-MCF-XML. Submitted to W3C 6 June 97. Edited by R. V. Guha and Tim Bray. "MGML - an SGML Application for Describing Document Markup Languages." By Tim Bray (and others, see details). [local archive copy] "Why I Demand Schemata: Element Type Hierarchies for Transparent Document Structure Definition." By Henry S. Thompson (Language Technology Group, University of Edinburgh). Draft date: October 15, 1997. [local archive copy] ISO 11179 - Specification and Standardization of Data Elements. According to Frank Olken (Lawrence Berkeley National Laboratory) in a seminar description 'XML-Data/RDF for ISO/IEC 11179', "the W3C XML-Schema Working Group is currently working on several issues which could have an impact on metadata registries in general, and ISO/IEC 11179 in particular." XML-Data Schemas Guide. By Andrew Layman. May/July, 1999. "This paper describes the features in the XML-Data schema language implemented by Microsoft's Internet Explorer 5.0 MSXML parser. XML-Data is an XML vocabulary for describing classes of XML documents and components, that is, for defining XML element types, attribute types and declaring rules for their combination into documents (or portions of documents). This paper is a tutorial guide to the features; they are defined more exactly at http://msdn.microsoft.com/xml/XMLGuide/schema-overview.asp, and you should look there for definitive specifications. XML-Data Schemas Guide (First Draft, May 25 1999) ISO 11179 with X3.285. DTD Element Index. DTD work from ISO 11179 and X3.285 by Terry Allen (Veo Systems); HTML presentation of ISO 11179 with X3.285 facilitated by Norm Walsh's DTDParse. NB: this is a transient URL for the ISO 11179 DTD, so please do not create public bookmarks to it. [May 13, 1999] "XML Notation Schemas." By Rick Jelliffe. May 12, 1999. "This note is for discussion purposes by the W3C Schema Working Group. It provides an alternative characterization of the schema problem. This provides a fromwork for addressing many issues not handled in the first working draft of the XML Schema specification." [local archive copy] [December 01, 1999] "Describing your Data: DTDs and XML Schemas." By Simon St. Laurent. From XML.com (December 01, 1999). ['Are you confused about which XML schema syntax to use? Concerned that your XML applications remain interoperable with future XML schema standards? Simon St. Laurent guides us through the maze of XML schema languages, focusing on DTDs and XML Schemas.'] "If you've been developing with XML for even a short period of time, you are likely to have reached the point of wanting to describe your XML data structures. Document Type Definitions (DTDs) and XML Schemas are key technologies in this area. Although neither are strictly required for XML development, both DTDs and XML Schemas are important parts of the XML toolbox. DTDs have been around for over twenty years as a part of SGML, while XML Schemas are relative newcomers. Though they use very different syntax and take different approaches to the task of describing document structures, both mechanisms definitely occupy the same turf. The W3C seems to be grooming XML Schemas as a replacement for DTDs, but it isn't yet clear that how quickly the transition will be made. DTDs are here-and-now, while XML Schemas, in large part, are for the future..." [May 12, 1999] "Alternatives to XML DTDs: Four Proposals." By Bob DuCharme. In <TAG> Volume 13, Number 4 (April 1999), pages 5-7. "In a follow-up to his analysis last month of XML's Document Type Definition (DTD) declaration syntax, Bob DuCharme focuses on the status of four alternative DTD schemas proposed by the W3C: XML-Data, XML Document Content Description (DCD), Schema for Object-oriented XML (SOX), and Document Definition Markup Language (DDML). In particular, DuCharme outlines the history and priorities behind each schema, and considers the functionality each affords to applications that manipulate metadata structured in XML. The article discusses some features that the W3C Schema Working Group members could add to the schema proposal that they'll draft after studying the four existing proposals." [See now also "World Wide Web Consortium Releases First Working Drafts of XML Schema Specification. W3C Members Collaborate to Improve and Standardize Needed Technology."] [March 30, 1999] "If Not DTDs, Then What?" By Bob DuCharme. In <TAG> Volume 13, Number 3 (March 1999), pages 1-3. "On an XML discussion mailing list, someone once claimed that no one would use DTDs if they were optional. Why bother, he asked, with something that just restricts your freedom when creating documents? XML Specification coeditor Tim Bray replied that the opposite effect had happened: people complained that DTDs did not allow enough restrictions. This article corrects most peoples' misconceptions that the current work on schemas in the W3C don't constitute alternatives to the DTD, but different ways of representing the DTD. [. . .] None of the four [current schema] proposals will ever 'win' as the accepted alternative to traditional DTD syntax. Instead, the W3C has assembled an XML Schema Working Group to evaluate the proposals and then construct a new proposal combining their best features, and probably adding some new ones as well. The Working Group's membership includes at least two authors, editors, or contributors involved in the creation of each of the original four proposals." Knowledge Interchange Format (KIF) A Discussion of the Relationship Between RDF-Schema and UML." NOTE-rdf-uml-19980804. By: Walter W. Chang (Advanced Technology Group, Adobe Systems). "This note summarizes the relationship between RDF-Schema and UML, the generic industry standard object-oriented modeling framework for information systems modeling. This note will briefly describe these systems then relate them to each other." W3C XML Schema Working Group. Co-chaired by Dave Hollander of Hewlett-Packard and C. M. Sperberg-McQueen of the University of Illinois at Chicago. "Document Definition Markup Language (DDML) Specification, Version 1.0." NOTE-ddml-19990119. 19-Jan-1999. [local archive copy] DCD - Document Content Description for XML SOX - Schema for Object-oriented XML "Universal Commerce Language and Protocol (UCLP)" XML-Data Resource Description Framework (RDF) Schema Specification WD-rdf-schema-19981030, W3C Working Draft 30 October 1998. ". . . this document defines a schema specification language. More succinctly, the RDF Schema mechanism provides a basic type system for use in RDF models. It defines resources and properties such as Class and subClassOf that are used in specifying application-specific schemas." See also the W3C Resource Description Framework (RDF) XML Authority - "a graphical design tool accelerating the creation and enhancing the management of schemas for XML. With support for data typing, solutions for data interchange and document oriented applications converge. XML Authority includes a toolset to help convert existing application and document structures to schemas, defining the basis for well formed XML documents and enabling valid XML. Beta, 1999-03-25. See XML & Schemas. [January 15, 1999] "XML Schema Languages." By Ronald Bourret. January, 1999. Presentation slides. Summary: "I recently gave a presentation on XML schema languages. Due to the recent questions about these on XML-Dev, I've annotated my slides and made them available on the Web. A majority of my audience didn't know XML, so the presentation starts with a brief description of XML. It then discusses why you might want XML schema languages, their basic syntax, and what the major differences between the four existing languages (XSchema, DCD, SOX, and XML-Data) are. It ends with a summary of what I think a schema language should have today and what languages I think you should use for what purpose. . . This presentation briefly reviews the current (January 1999) state of XML schema languages -- why we have them, how to use them, and what each language offers. Disclaimer 1: I am one of the co-authors of XSchema. Because of this, there is likely to be some bias, especially in the 'Existing XML Schema Languages' and 'Summary' sections. If you have complaints, comments, or suggestions, please send me email. Disclaimer 2: Because I know XSchema, it is used as the sample language for illustrating most schema language concepts. DCD, SOX, or XML-Data could have been used equally well." Also available in Powerpoint format. Note: The W3C has recently chartered an XML Schema Working Group, co-chaired by Dave Hollander of Hewlett-Packard and C. M. Sperberg-McQueen of the University of Illinois at Chicago. Object Management Group (OMG) and XML Metadata Interchange Format (XMI) [October 28, 1999] First Working Draft of ISO/WD 10303-28: XML Representation of EXPRESS Driven Data. A first working draft of ISO 10303-28 has been developed by Eurostep and Monsell EDM for BSI. This is: ISO/WD 10303-28:1999(E). Product data representation and exchange: Implementation methods: XML representation of EXPRESS-driven data. Reference: ISO TC184/SC4/WG10 N285 and ISO TC184/SC4/WG11 N090, Date: 1999-10-24. This "first rough draft of part 28" specifies "the way in which XML can be used to encode both EXPRESS schemas and corresponding data." An accompanying document explaining the use of Use of Architectural Forms is also available: "Use of Architectural Forms for Early to Late Bound Mapping WG11 N91. These two documents have been sent to SOLIS as WG11/N90 and N91, and are intended to form the basis for discussion at an upcoming meeting in New Orleans. The goal of the project in this new work item is explained in the introduction to the proposed standard: "ISO 10303 is an International Standard for the computer-interpretable representation of product information and for the exchange of product data. The objective is to provide a neutral mechanism capable of describing products throughout their life cycle. This mechanism is suitable not only for neutral file exchange, but also as a basis for implementing and sharing product databases, and as a basis for archiving. This part of ISO 10303 specifies means by which data and schemas specified using the EXPRESS language (ISO 10303-11) can be encoded using XML. XML provides a basic syntax that can be used in many different ways to encode information. In this part of ISO 10303, the following uses of XML are specified: a) A late bound XML architectural Document Type Declaration (DTD) that enables any EXPRESS schema to be encoded; b) An extension to the late bound DTD to enable data corresponding to any EXPRESS schema to be encoded as XML; c) A canonical form for the late bound DTD that is derived from the architectural DTD; d) The use of SGML architectures to enable early binding XML forms to be defined that are compatible with the late binding. The use of architectures allows for different early bindings to be defined that are compatible with each other and can be processed using the architectural DTD." The Architectural Forms document (by Robin La Fontaine) "explains the basics of SGML Architectures as needed to represent the relationship between the early-bound and late-bound XML formats for Express-driven data... Given a document in XML which corresponds with a particular DTD, architectural forms provide a standard mechanism for viewing it as if it were consistent with another DTD (the meta-DTD or base architecture). This is being used within STEP to allow one or more early-bound data sets to be viewed as if they were defined in terms of the standard late-bound DTD. Thus software written against the late-bound DTD can, without modification, process data that complies with any compliant early-bound DTD. 'Compliant' here means that the early-bound DTD has the late-bound DTD as its base architecture. This gives some flexibility in defining early-bound DTDs which can be optimised for different purposes, e.g., for display, for data exchange, for compactness." Persons interested in the activity of this ISO group may contact the Nigel Shaw (Project Leader, Eurostep Limited) or Robin La Fontaine (Project Editor, Monsell EDM). For background on this proposed new work item, see "SGML/XML and STEP"; see also (tangentially) "Product Data Markup Language (PDML)." [March 30, 2000] "XML Schemas: Setting Rules for XML Documents." By Simon St.Laurent. March 2000. Slideset presentation (24 slides). "Why schemas? (1) Common Vocabularies: Establishing common vocabularies makes it easy to build software that processes information according to a clearly defined set of rules. The larger the audience using the same vocabulary, the larger the audience. (2) Formal Sets of Rules: Because machines (computers) will be doing most of the XML processing, expressing those vocabularies in a form that computers can understand is important. The formal description must be regular, unambiguous, and relatively easy to process. (3) Building Contracts: On the human side of the information interchange equation, formal descriptions of vocabularies can provide a core set of rules for all participants in a series of transactions. Schemas can make it clear which kinds of information are required or optional for which kinds of transactions. ...it only covers what I could say in 90 minutes." [January 12, 1999] The ISO TC 184/SC4 [Industrial data] Secretariat has issued an ISO New Work Item Ballot for "XML representation for EXPRESS-driven data." The NWI 'specifies the representation according to the syntax of Extensible Markup Language (XML) of data defined using ISO 10303-11 (the EXPRESS language) and/or for EXPRESS schemas. The mappings from the EXPRESS language to the syntax of the representation are specified. Any EXPRESS schema or schemas and the data they describe can be represented.' The current proposal 'arises out of the preliminary work item on SGML and Industrial Data (commonly refered to as 'STEP/SGML Harmonisation') and is seen as an important part of that initiative. The use of XML will enable increased flexibility with respect to future changes to EXPRESS schemas. The result of the NWI will enable the generalized use of XML and SGML tools and web browser technology with EXPRESS-driven data and schemas.' The facility would 'enable the use of the recommended syntax for data exchange on the World Wide Web to be applied to instances of EXPRESS-driven data, enable the use of the recommended syntax for data exchange on the World Wide Web to be applied to EXPRESS schemas, and enable EXPRESS schemas to be exchanged together with data instances they describe.' ISO/IEC 11404 INTERNATIONAL STANDARD. Information technology -- Programming languages, their environments and system software interfaces -- Language-independent datatypes. First edition 1996-12-15. "This International Standard provides the specification for the Language-Independent Datatypes. It defines a set of datatypes, independent of any particular programming language specification or implementation, that is rich enough so that any common datatype in a standard programming language or service package can be mapped to some datatype in the set." [local archive copy] "Beyond the SGML DTD." By François Chahuneau. Posting submitted to the W3C WG discussion forum. Extensible Type Specifications for RDF and XML Schemas." By Frank Olken. Lawrence Berkeley National Laboratory. September 11, 1998. DRAFT 1.0. "This document addresses issues of extensible type specifications for use in XML and RDF schemas, i.e., schemas which describe information encoded as either XML or RDF documents. XML documents are described by XML schemas such as XML-Data and DCD (Document Content Definitions). RDF documents are described by W3C RDF schemas. We are particulary concerned with two issues: 1) decomposing the descriptation of basic types; 2) extensibility of type specifications." [local archive copy] "Adding Strong Data Typing to SGML and XML", by Tim Bray. May [21,] 1997. archive copy, May 21, 1997; or: previous archive copy, May 15, 1997]. Note: Jean Paoli of Microsoft has submitted a related proposal in connection with the XML discussion "XML for Structured Data" [December 06, 1997] "Why I Demand Schemata: Element Type Hierarchies for Transparent Document Structure Definition." By Henry S. Thompson (Language Technology Group, University of Edinburgh). Draft date: October 15, 1997. Overview: "In this paper I describe the XML-Data schemata proposal, concentrating on the motivation for and nature of the provision of an element-type hierarchy, in which element types can inherit attribute declarations and positions in content models from ancestors in the hierarchy. I argue that this represents a major improvement over the use of parameter entities to structure and maintain DTDs." [local archive copy] [September 03] "Tips and Techniques." By [<TAG> Online Staff]. In <TAG> Volume 13, Number 7 (July, 1999), pages 8-10. "This month's article shows you how to create an XML schema in accordance with the current draft spec from the W3C XML Schema Working Group. 1. Create XML schema, 2. Create document according to schema, 3. Point to schema using namespaces. Remember that this article is based on a working draft of the XML schema specification. The final recommendation might look slightly or completely different from this, but the concepts will remain the same. . . The example shows the structure of our Joke Markup Language. The root element is 'Joke', which contains three elements (Setup, PunchLine, and OneLiner) and two attributes (Type and FirstUsed)." [See http://architag.com/newsletter/joke.xsd.] "MGML - an SGML Application for Describing Document Markup Languages." SGML '96 (?) [local archive copy] "Meta Content Framework Using XML", NOTE-MCF-XML. Submitted to W3C 6 June 97. Edited by R. V. Guha and Tim Bray. "This document provides the specification for a data model for describing information organization structures (metadata) for collections of networked information. It also provides a syntax for the representation of instances of this data model using XML, the Extensible Markup Language."
[CR: 19980217]
Chahuneau, François. "SGML and Meta-information: From SGML DTDs to XML-DATA." Pages 337-340 in SGML/XML '97 Conference Proceedings. SGML/XML '97. "SGML is Alive, Growing, Evolving!" The Washington Sheraton Hotel, Washington, D.C., USA. December 7 - 12, 1997. Sponsored by the Graphic Communications Association (GCA) and Co-sponsored by SGML Open. Conference Chairs: Tommie Usdin (Chair, Mulberry Technologies), Debbie Lapeyre (Co-Chair, Mulberry Technologies); Michael Sperberg-McQueen (Co-Chair, University of Illinois). Alexandria, VA: Graphic Communications Association (GCA), 1997. Extent: 691 pages, CDROM; print volume contains author and title indexes, keyword and acronym lists. Author's affiliation: [François Chahuneau]: AIS (Advanced Information Systems) S.A., 17 Rue Remy Dumoncel, Paris, France F-75014; Email: [email protected]; WWW: http://www.ais.berger-levrault.fr/.
Abstract: "This paper studies, from an historical perspective, the relationship between SGML and data modeling concerns. SGML did not the invent the concept of structural document models, or 'schemata'. Nevertheless, through the notion of DTDs, it made this powerful concept available and understandable to a large number of people with little or no data modeling experience.
"With the evolutionary trend towards 'content oriented' DTDs, the emergence of well-described methodologies to design them and the appearance of specialized 'case' tools to manipulate them, the potential of SGML as a data modeling methodology became clear, and some SGML enthusiasts suggested to use it as a general purpose tool.
"However, because an SGML DTD intimately mixes the notion of a 'grammar' and that of a 'schema', these two concepts remained partly confused, at least in the 'orthodox' SGML approach. This original characteristic caused some misunderstandings and raised many suspicions from the 'traditional' data modeling world. This largely precluded, so far, the use of SGML as a general data modeling tool outside the restricted arena of structured documents.
"By introducing a simplified syntax with a fixed grammar, XML isolated the role of DTDs as 'pure schemata', and also made them unnecessary for pure recognition of the 'de facto' document structure.
Finally, recent proposals such as MCF and XML-data suggest to use the XML syntax itself to encode document schemata, therefore making 'traditional' DTDs obsolete. At the same time, they propose several extensions to the SGML data modeling semantics, by incorporating object-oriented concepts. Will such an evolution allow XML to become the official, well-accepted and ubiquitous way to exchange structured data and associated models, and bring SGML power much beyond its original application niche?"
[Extract from the section "The Dual Nature of DTDs"]: "With the benefit of hindsight, after ten years of practice, the design of SGML appears as an unlikely and unique mixture of many brilliant ideas and a few mistakes, and strikes [one] by its total lack of references to data modeling or language design theories which had already emerged in computer science at the time it was designed. A major point of originality is the central SGML DTD concept itself: a DTD is both a generative grammar for the markup language which will be used to tag corresponding instances, and a schema which characterizes a document class: it assigns names to things and defines rules stating what structural patterns shall or shall not be not possible/required in an SGML document (modeled as a tree of typed nodes with attributes) which belongs to the class. In the same set of statements, one is instructed that 'the end tag for AUTHOR can be omitted' and that 'the document must have a title and a single one', although these two pieces of information admittedly belong to totally different areas of concern. This dual nature of DTD should not necessarily lead to confusing the two notions. Unfortunately, this is largely what happened in the SGML community..."
|








 | Receive daily news updates from Managing Editor, Robin Cover.

 |
|


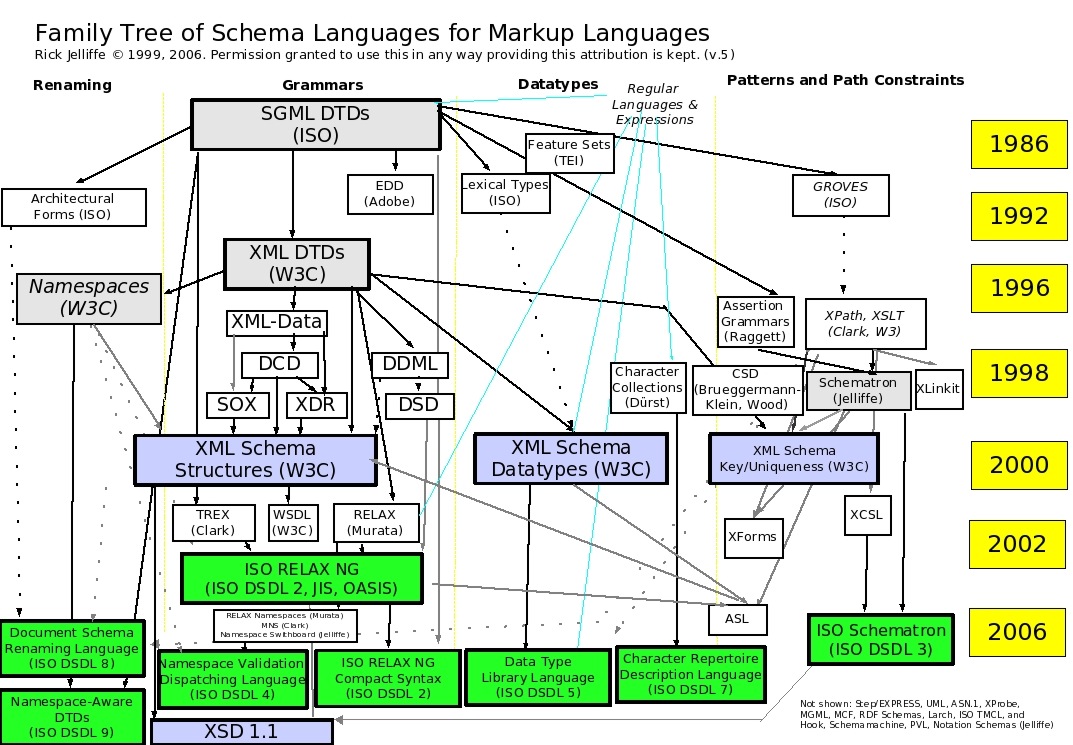{kind=link}