SEARCH
Advanced Search
ABOUT
Site Map
CP RSS Channel
Contact Us
Sponsoring CP
About Our Sponsors
NEWS
Cover Stories
Articles & Papers
Press Releases
CORE STANDARDS
XML
SGML
Schemas
XSL/XSLT/XPath
XLink
XML Query
CSS
SVG
TECHNOLOGY REPORTS
XML Applications
General Apps
Government Apps
Academic Apps
EVENTS
LIBRARY
Introductions
FAQs
Bibliography
Technology and Society
Semantics
Tech Topics
Software
Related Standards
Historic
|
| SGML and XML News. Q3 July - September 2000 |
Related News: [XML Industry News] - [XML Articles] - Current SGML/XML News - [News 2000 Q2] - [News 2000 Q1] - [SGML/XML News 1999 Q4] - [SGML/XML News 1999 Q3] - [SGML/XML News 1999 Q2] - [SGML/XML News 1999 Q1] - [SGML/XML News for 1998] - [SGML/XML News for 1997] - [SGML/XML News for 1996] - [SGML News for 1995]
Site Search: [VMS Indexed Search]
[September 30, 2000] Microsoft's September 2000 MSXML Beta Release. Microsoft has published an article in the MSDN Web Workshop which outlines new features in the September 2000 MSXML Beta Release. "The September 2000 Microsoft XML Parser (MSXML) Beta Release is an update to the July 2000 MSXML Beta Release. This latest release of MSXML [9/29/2000] represents a step beyond the July 2000 release, providing: (1) Server-safe HTTP access; (2) Complete implementation of XSLT/Xpath; (3) Changes to the SAX2 implementation, including new SAX2 helper classes; (4) A number of bug fixes and performance improvements; (5) Even higher conformance than the July release with the World Wide Web Consortium (W3C) standards and the Organization for the Advancement of Structural Information Standards (OASIS) Test Suite. [XSLT/XPath Support]: This release supports every existing XSLT/XPath feature included in the current standards. Most notably that means this release includes the following new XSLT and XPath features: (a) The <xsl:decimal-format> element, (b) The unparsed-entity-uri() and format-number() functions, (c) The namespace axis. [Server-Safe HTTP]: The September 2000 MSXML Beta Release provides server-safe ServerXMLHTTP implementation. This provides similar functionality to the XMLHTTP object, except in a server-safe way. To utilize server-safe HTTP, use the XMLDOMDocument2 setProperty method or SAXXMLReader setFeature method. Alternatively, you can use this new object on its own as a generic server-side HTTP access component. [SAX2 Implementation]: Also, in the September 2000 MSXML Beta Release, there are no longer two separate SAX readers for Microsoft C++ and Microsoft Visual Basic; the same coclass, SAXXMLReader, now implements both sets of interfaces. This means that Visual Basic programs should create SAXXMLReader, not a VBSAXXMLReader class. Another important [SAX2] change is that the parser passes strings to handlers by reference, not by name. This improves performance and avoids extra string copying. It also affects function headers in existing handler implementations. The September release also includes a helper implementation of the XML writer and SAX attributes. The XMLWriter coclass allows you to generate XML documents from a SAX events stream. The SAXAttributes coclass simplifies creation of an Attribute object, if you need one for SAX-based XML processing. [Namespace Support]: The IXMLDOMNode functions, selectNodes() and selectSingleNode(), can now use qualified names. The prefixes used for those names should be set by XMLDOMDocument2.setProperty("SelectionNamespaces", ...). The September release installs the MSXML 3.0 parser (msxml3.dll) in side-by-side mode, which means that installing MSXML 3.0 will not cause any previously installed version of MXSML to be replaced. Both the new parser and the old one will reside 'side-by-side' on your computer. However, Microsoft Internet Explorer, Microsoft Windows 95, Windows 98, Microsoft Windows NT, and Windows 2000 will continue to use only the older version of the parser until you use the xmlinst.exe installer tool to manually replace the older parser with the newer one. Previous versions of MSXML 3.0 automatically installed xmlinst.exe with the parser as part of the installation process. However, this September release provides the xmlinst.exe utility as a download instead." The September 2000 MSXML Beta Release and the September 2000 MSXML SDK Beta Release are now available for download. See "What's New in the September 2000 Microsoft XML Parser Beta Release." [September 29, 2000] Web Services Description Language (WSDL). Ariba, IBM, and Microsoft have jointly issued a specification for a 'Web Services Description Language (WSDL)' which defines an XML grammar "for describing network services as collections of communication endpoints capable of exchanging messages." Authors include Erik Christensen (Microsoft), Francisco Curbera (IBM), Greg Meredith (Microsoft), and Sanjiva Weerawarana (IBM). This published WSDL specification "represents the current thinking with regard to descriptions of services within Ariba, IBM and Microsoft, and consolidates concepts found in NASSL, SCL, and SDL (earlier proposals)." Document abstract: "WSDL is an XML format for describing network services as a set of endpoints operating on messages containing either document-oriented or procedure-oriented information. The operations and messages are described abstractly, and then bound to a concrete network protocol and message format to define an endpoint. Related concrete endpoints are combined into abstract endpoints (services). WSDL is extensible to allow description of endpoints and their messages regardless of what message formats or network protocols are used to communicate, however, the only bindings described in this document describe how to use WSDL in conjunction with SOAP 1.1, HTTP GET/POST, and MIME. This version of the WSDL language is a first step that does not include a framework for describing the composition and orchestration of endpoints. A complete framework for describing such contracts will include means for composing services and means for expressing the behavior of services, i.e., the sequencing rules for sending and receiving messages. Composition of services must be type safe but also allow for reference passing with service references being exchanged and bound at runtime. The latter being key for negotiating contracts at runtime and capturing the behavior of referral and brokering services. The authors of the WSDL specification intend to publish revised versions of WSDL and/or additional documents in a timely fashion which will include a (1) framework for composing services and a (2) framework for describing the behavior of services." The WSDL specification is available for review on the IBM and Microsoft web sites. See also "Web Services Description Language (WSDL)." [September 29, 2000] Harvesting RDF Statements from XLinks. A new W3C Note on XLink and RDF bears the title Harvesting RDF Statements from XLinks. Reference: W3C Note 29-September-2000, edited by Ron Daniel Jr. (Metacode Technologies Inc.). This Note is not a formal product of the W3C XML Linking Working Group, but "is made available by the W3C XML Linking Working Group for the consideration of the XLink and RDF communities in the hopes that it may prove useful." Abstract: "Both XLink and RDF provide a way of asserting relations between resources. RDF is primarily for describing resources and their relations, while XLink is primarily for specifying and traversing hyperlinks. However, the overlap between the two is sufficient that a mapping from XLink links to statements in an RDF model can be defined. Such a mapping allows XLink elements to be harvested as a source of RDF statements. XLink links (hereafter, 'links') thus provide an alternate syntax for RDF information that may be useful in some situations. This Note specifies such a mapping, so that links can be harvested and RDF statements generated. The purpose of this harvesting is to create RDF models that, in some sense, represent the intent of the XML document. The purpose is not to represent the XLink structure in enough detail that a set of links could be round-tripped through an RDF model." [Principles:] "Simple RDF statements are comprised of a subject, a predicate, and an object. The subject and predicate are identified by URI references, and the object may be a URI reference or a literal string. To map an XLink link into an RDF statement, we need to be able to determine the URI references of the subject and predicate. We must also be able to determine the object, be it a URI reference or a literal. The general principle behind the mapping specified here is that each arc in a link gives rise to one RDF statement. The starting resource of the arc is mapped to the subject of the RDF statement. The ending resource of the arc is mapped to the object of the RDF statement. The arc role is mapped to the predicate of the RDF statement. However, a number of corner cases arise, described in [Section] 3, 'Mapping Specification'. RDF statements are typically collected together into 'models.' The details of how models are structured are implementation dependent. This Note assumes that harvested statements are added to 'the current model,' which is the model being constructed when the statement was harvested. But this Note, like RDFSchema, does not specify exactly how models must be structured." See also (1) "XML Linking Language", (2) "Resource Description Framework (RDF)", and (3) "XML and 'The Semantic Web'." [September 29, 2000] New Release of Redland - An RDF Application Framework. Dave Beckett (Institute for Learning and Research Technology, University of Bristol) announced the release of Redland version 0.9.4 with a new Perl interface and added support for Linux RPM binaries. Redland (An RDF Application Framework) "is a library that provides a high-level interface for RDF allowing the model to be stored, queried and manipulated. Redland implements each of the RDF model concepts in its own class so provides an object based API for them. Some of the classes providing the parsers, storage mechanisms and other elements are built as modules that can be added or removed as required. Redland provides: (1) A modular, object based library written in C; (2) C and Perl APIs for manipulating the RDF Model and parts -- Statements, Resources and Literals; (3) Parsers for importing the model from RDF/XML syntax [both parsers external at present]; (4) Storage for models in memory and on disk via Berkeley DB [SleepyCat]; (5) Query APIs for the model by Statement (triples) or by Nodes and Arcs; (6) Statement Streams for construction, parsing, de/serialisation of models." Beckett has created an eGroups list for the software at http://www.egroups.com/group/redland/ and invites interested parties to join the mailing list and development effort. At present Redland has no built in RDF/XML parser, so if you want to parse RDF/XML, you will have to download an external parser, either the W3C libwww C or the Java API RDF Parser (based on SiRPAC), as described in the installation document. A Python interface for Redland is now being designed, and work has begun on an internal RDF parser. The sources are available for download from main web site or from SourceForge. The code library is free software / open source software released under the LGPL or MPL licenses. See other references in "Resource Description Framework (RDF)." [September 28, 2000] W3C Releases DOM Level 2 Specification as Proposed Recommendation. Members of the W3C have released an announcement for the promotion of DOM Level 2 specifications to PR (Proposed Recommendation) status. The announcement for DOM Level2 PR has three parts: (1) The DOM Level 2 Proposed Recommendation URIs; (2) A content summary of DOM Level 2; (3) Results of the DOM Level 2 Candidate Recommendation Phase. The DOM Level 2 specification has been published as six (6) separate modules: (1) Document Object Model Level 2 Core; (2) Document Object Model Level 2 Views; (3) Document Object Model Level 2 HTML; (4) Document Object Model Level 2 Style; (5) Document Object Model Level 2 Events; (6) Document Object Model Level 2 Traversal and Range. During the Candidate Recommendation phase, "implementations have been made of every part of the specification, but the interoperability between different implementations has not been as exhaustively tested. However, what interoperability testing has been done has yielded only positive results. A significant number of different implementations from different sources were involved. As other specifications depend on DOM Level 2 (SMIL, SVG, MathML), and as the experience to date has been successful, the Director has approved DOM Level 2 to be presented to the AC for consideration as a Recommendation." The Document Object Model (DOM) "is an application programming interface (API) for valid HTML and well-formed XML documents. It defines the logical structure of documents and the way a document is accessed and manipulated. In the DOM specification, the term 'document' is used in the broad sense -- increasingly, XML is being used as a way of representing many different kinds of information that may be stored in diverse systems, and much of this would traditionally be seen as data rather than as documents. Nevertheless, XML presents this data as documents, and the DOM may be used to manage this data. With the Document Object Model, programmers can build documents, navigate their structure, and add, modify, or delete elements and content. Anything found in an HTML or XML document can be accessed, changed, deleted, or added using the Document Object Model, with a few exceptions - in particular, the DOM interfaces for the XML internal and external subsets have not yet been specified. As a W3C specification, one important objective for the Document Object Model is to provide a standard programming interface that can be used in a wide variety of environments and applications. The DOM is designed to be used with any programming language. In order to provide a precise, language-independent specification of the DOM interfaces, we have chosen to define the specifications in Object Management Group (OMG) IDL, as defined in the CORBA 2.3.1 specification. In addition to the OMG IDL specification, we provide language bindings for Java and ECMAScript (an industry-standard scripting language based on JavaScript and JScript)." See further (1) W3C Document Object Model (DOM) page, (2) the DOM Activity, and (3) "W3C Document Object Model (DOM)." [W3C announcement] [September 28, 2000] Revised W3C Note on Describing and Retrieving Photos Using RDF and HTTP. An updated version of the W3C Note Describing and Retrieving Photos Using RDF and HTTP has been posted. Reference: W3C Note, 28-September-2000; by Yves Lafon and Bert Bos (W3C). "This note describes a project for describing and retrieving (digitized) photos with (RDF) metadata. It describes the RDF schemas, a data-entry program for quickly entering metadata for large numbers of photos, a way to serve the photos and the metadata over HTTP, and some suggestions for search methods to retrieve photos based on their descriptions. The data-entry program has been implemented in Java, a specific Jigsaw frame has been done to retrieve the RDF from the image through HTTP. The RDF schema uses the Dublin Core schema as well as additional schemas for technical data. We already have a demo site, and, in a few weeks, we have sample source code available for download. The online demo: A sample server has been set up, and some pictures are available. Any request to text version of those pictures will give you the RDF description of the picture. I.e., an HTTP request for MIME type image/jpeg or image/* returns the photo, a request for text/rdf or text/* returns the metadata. Or you can just view the metadata by adding ';textFrdf' at the end of the pictures URI. Note that the index page has been created by a script using the RDF embedded in the pictures for the captions and alt text. The system can be useful for collections of holiday snapshots as well as for more ambitious photo collections. The Jigsaw extension and the JPEG related classes are a available in the Jigsaw 2.0.4 distribution, the metadata editor rdfpic is available from the Jigsaw demo site. Appendix A of the Note supplies three schemas (Dublin Core, technical and content) in the syntax proposed by the RDF schemas draft." See (1) "Resource Description Framework (RDF)" and compare (2) "DIG35: Metadata Standard for Digital Images." [September 28, 2000] Java XP Package Updated. A communiqué from Tom Harding announces the release of a new version of an 'XP' Java package that implements Extensible Protocol. Extensible Protocol (XP) is "a bidirectional protocol on which XML documents are exchanged between two endpoints. It is similar to BXXP but simpler: the document length is not required, it doesn't define multiplexing, and it uses the XML document encoding instead of MIME. XP will work best for applications that use relatively long-lasting, contextual conversations. XP is extremely simple and lets you build outward from the wire, rather than inward from a complex software interface. XP's only dictate is that everything that crosses the wire is XML. There is no distinction of the representation of control information from that of data. The new version of the com.thinlink.xp package implements XP draft 00 using stream sockets and the Apache Crimson processor. You use an event-listener interface and the Document Object Model to build, send and receive XML documents. XP requires some subtle behavior from the underlying processor; namely, the ability to identify and parse multiple documents from the input stream. Apache Crimson was relatively easy to adapt to this task because it relies mostly on built-in Java I/O." Documentation for XP is available online, and the package may be downloaded. [September 28, 2000] Web Resource Application Framework. Jonas Liljegren recently announced the first alpha release of (Perl) RDF::Service from the Wraf (SourceForge) project. Wraf (Web Resource Application Framework) implements a RDF API. The purpose is to enable the construction of applications that fully uses the RDF data model in order to realize the Semantic Web. (1) All data is described in RDF (2) The User Interface is defined in RDF. Data presentation will be dependent on the user profile, situation context, and just what information can be found from trusted sources. (3) All functions and program code are named, described and handled as RDF Literals. Running an application can result in method calls to services on other internet servers. New functions could by reference transparently be downladed and executed from trusted sources. The actual code is Perl but the system could be extended to recognize other languages. (4) The development of applications is done in the same system used to run the application. Wraf will be extended and developed from within iteself. Wraf uses interfaces to other sources in order to integrate all data in one enviroment, regardless of storage format. You can read and update information from configuration files, databases, XML files, LDAP, etc. The system will use intelligent caching and optimizations in order to gain in speed without sacrifice any flexibility. A persistant backend service deamon will take requests from clients in mod_perl. Other non-browser interfaces could also use the service. Wraf will be idealy suited for complex, interconnected systems there the addition of new data often breakes the previous format and the exceptions is the rule. It can be used for personalized content generation, topic communities, intranets and more." See: (1) "Resource Description Framework (RDF)" and (2) "XML and 'The Semantic Web'." [September 27, 2000] Description Logics Markup Language (DLML). An XML language "Description Logic Markup Language (DLML)" is presented in the web site overview thus: "DLML is not a language but rather a system of DTDs that allows to encode many (if not all) description logics in the same framework. So far, it is restricted to TBox encoding. One important motivation to build DTDs for description languages is to be able to embed formal knowledge (in DL) in documents; see the pages of the ESCRIRE action for more information. Another motivation is to experiment with simple representation language transformations for which description logics are well-suited. The DLML structures can be used for storing and communicating terminologies to other systems. But they can also be transformed in the process. [See the XML document manipulations presented on the web site which are achieved easily with XML Stylesheet Language Tranformations (XSLT); 'moreover the transformations are described in a modular way which follows the modular description of the logics themselves.'] . . . The goal of DLML is to encode description logics expressions into XML. For instance, the sentence 'All CSmaster students are bachelor students whose advisor is computer scientist' is phrased in description logics by the expression: CSMasterStudents < (and Bachelor Student (all advisor ComputerScientist)). In this example, CSMasterStudent, Bachelor and Student are called concepts and advisor is called a role. The sentence above is a concept introduction for the concept CSMasterStudents. It is primitive because introduced by the < symbol. This means that if all the CSmaster students are bachelor students whose advisor is computer scientist, the reverse is not supposed to hold. The symbols and and all are called (concept) constructors and used for building complex concept descriptions. The DLML takes advantage of the modularity of description logics in which each operator and introducer can be described independently and a logic assemble these operators. The resources available here are: (1) The encoding of many operators, (2) The definition of logics, and (3) The illustration of many transformations, including some taking advantage of the semantics of the logic. Some current development work: (1) The full semantics description of the logics provided by DLML (this can be used, for instance, in order to check that a particular transformation is valid). (2) A stylesheet for transfoming a logic specification (by providuing its constructors and introducers) into complete DTD and DSD for that logic..." See the project web site for examples and other references. Generally on semantics in XML, see "XML and 'The Semantic Web'." [September 27, 2000] ParlML Project Update. Peter Pappamikail (Head of Information Resources Management European Parliament) recently posted an announcement updating the EC's ParlML project and its funding. 'ParlML' is a proposed XML-based 'Common Vocabulary for Parliamentary Language'. In the original call for participation, a preliminary study was outlined "to be taken by the interested partners to explore the whole range of XML standards (XML schema, DOM, XML and RDF in particular) with a view to developing a formal language definition." The report reads: "As announced at the ECPRD's ITC working party seminar last week in Paris, I met last night with representatives of the Secretariat General of the European Commission and the IDA Programme (European Commission funded programme promoting the interchange of data between administrations). I am pleased to announce that there is now an agreement in principle to finance the ParlML project and - timing and procedures permitting - to do so over the 2000 and 2001 IDA programme budgets. The project would fund work carried out under contract: (1) to agree a project methodology and terms of reference; (2) to scope the project and assess the level of work under way in this specific field, in particular work that may be aimed at seeking approval for XML tagsets with national standards bodies; (3) to create two XML meta-vocabularies: ParlML, for the markup of parliamentary texts and work; and LexML, for the markup of legislative texts. together with an 'ontology' defining the relationship between semantic elements (entity/element relationships, processes, etc.) and recommendations regarding the standards to use [ISO Topic Maps, RDF, UML, etc.]; (4) agree approval and updating mechanisms for the vocabularies and ontology. It is suggested that a 'governing body' of some description should be established to guide and validate the contractor's work, and approve the standard. Advice on different possibilities and approaches will be sought over the coming weeks. My service (with as much help as I can muster) must now prepare terms of reference and technical requirements for approval by the IDA programme management board, by mid November at the latest. I will be examining in the coming days, together with the rest of Parliament's IT directorate, other EU institutions and bodies, and national parliaments, the best way of proceeding. Whatever approach is agreed, speed is now of the essence if we are to benefit from funding also under the 2000 budget. If your parliament is interested in: being part of the body that would be set up to approve the standard and guide the project work; taking responsibility for one or other aspect of the work; carrying out, directly or indirectly, some aspect of the work (thus freeing project funding for other areas); providing information, support, studies or other work already undertaken in the field of XML tagset definitions; being kept informed of progress in order to be able to use the ParlML/LexML tagsets once approved.... please reply to this message and give full contact details. Such a reply is 'non binding': our concern is to assess which IT services are interested in which aspects of the project. If you have other information, comments, warnings, criticisms, praise, plase feel free to reply also." See (1) "ParlML: A Common Vocabulary for Parliamentary Language" and (2) "Legal XML Working Group." [September 27, 2000] Update for IBM's XML Parser for Java. IBM alphaWorks Labs recently announced that the XML Parser for Java Version 3.1.0 Release (XML4J-3_1_0) is now publicly available. "This release contains public and stable support of the DOM Level 1, and SAX Level 1 specifications. It also contains implementations of the DOM Level 2, SAX Level 2 implementations, and partial April 7 W3C Schema implementations but these are considered experimental, as the specifications themselves are still subject to change." XML Parser for Java "is a validating XML parser written in 100% pure Java. The package (com.ibm.xml.parser) contains classes and methods for parsing, generating, manipulating, and validating XML documents. XML Parser for Java is believed to be the most robust XML processor currently available and conforms most closely to the XML 1.0 Recommendation. IBM is major contributor to Apache's Xerces-J code base, which is the basis for XML4J version 3." [September 25, 2000] Release of Unicorn XSLT Processor, Professional Edition. Alexey Gokhberg has announced the availability of Unicorn XSLT Processor, Professional Edition. "As all products of Unicorn XSLT Processor family, the Unicorn XSLT Processor Professional Edition is implemented in C++ and is fast, compact, easy to install and to use. The final W3C XSLT Recommendation is supported. The product design is focused on achieving the interoperability between XSLT and other information processing technologies, in order to dramatically extend the scope of applications which can be efficiently addressed using the XSLT approach. The powerful Unicorn ECMAScript Interpreter (UESI) engine is now an integral part of the product. It implements the vendor-independent object-oriented programming language ECMAScript, as well as the rich set of language extensions specially designed to facilitate XML data processing. The poineer object-based XSLT extension technology (http://www.unicorn-enterprises.com/xslobj.htm) is employed to support integration between XSLT and ECMAScript. The unique set of database access XSLT extensions (http://www.unicorn-enterprises.com/xslsql.htm) is supported as well. With these extensions, XSLT technology can be used to handle a wide range of XML transformation algorithms that involve data stored in the traditional relational databases. Several other facilities that extend XSLT are also available. Report generation extensions (http://www.unicorn-enterprises.com/xslrpt.htm) allow dynamic split/group processing. Text input extensions (http://www.unicorn-enterprises.com/xsltxt.htm) are designed to process source data represented in a text format. The Unicorn XSLT Processor software is free, and runs on Windows NT 4.0 and Windows 95. Note that Unicorn Formatting Objects (UFO) was also released recently. "UFO implements the substantial subset of the Extensible Stylesheet Language (XSL) Version 1.0 specification (W3C Working Draft 27-March-2000). This product is optimized for composition of business-style documents (e.g., catalogs, orders, invoices, banking statements, etc). The extensive support is provided for various features (for instance, collapsing border model in tables), which are not yet supported by few existing XSL implementations." The Unicorn XML Processor is also available: this is "a stand-alone ECMAScript interpreter that supports a rich set of built-in extension objects. These objects implement various XML-related features: (1) representation of XML documents using DOM (Document Object Model) (2) non-validating XML parser (3) XML writer supporting XML, HTML and text output methods." For related tools, see "XSL/XSLT Software Support." [September 25, 2000] XML-DBMS for Perl Released. Ronald Bourret recently announced the release of XML-DBMS. "XML-DBMS (Perl) is a port of the Java version of XML-DBMS. XML-DBMS is middleware for transferring data between XML documents and relational databases. It views the XML document as a tree of data-specific objects in which element types are generally viewed as classes and attributes and PCDATA as properties of those classes. It then uses an object-relational mapping to map these objects to the database. An XML-based mapping language is used to define the view and map it to the database." XML-DBMS (Perl) has been developed by Nick Semenov and Ronald Bourret; it is issued under GPL license. For references on XML databases, see "XML and Databases." [September 23, 2000] Petri Net Markup Language (PNML). A research team at Humboldt-Universität zu Berlin has developed a proposal for an interchange format 'Petri Net Markup Language' in support of software tool interoperability. This research represents one part of a larger collaborative effort by scientists in several countries to create an XML-based standardized interchange format for Petri nets. Following a meeting in June 2000 ("Meeting on XML/SGML based Interchange Formats for Petri Nets" - 21st International Conference on Application and Theory of Petri Nets Aarhus, Denmark, June 26-30, 2000), a mailing list was formed to manage the discussion. Resulting from the ICATPN 2000 meeting, seven "position papers" (some with accompanying slides) and four "detailed proposals" for descriptive markup encoding are now available online. It is hoped that a standardization effort for XML notation will be approved by October 2000, and that a preliminary interchange format can be drafted by the end of 2000; the format should be compatible with ISO/IEC 15909. The Petri Net Markup Language (PNML) is "a preliminary proposal of an XML-based interchange format for Petri nets. Originally, the PNML was intended to serve as a file format for the Java version of the Petri Net Kernel. It turned out that currently several other groups are developing an XML-based interchange format too. So, the PNML is only one contribution to the ongoing discussion and to the standardization efforts of an XML-based format. The specific feature of the PNML is its openness: It distinguishes between general features of all types of Petri nets and specific features of a specific Petri net type. The specific features are defined in a separate Petri Net Type Definition (PNTD) for each Petri net type. In its current version, the PNML demonstrates that an XML-based interchange format can be defined in a generic way. What features are considered to be so general such that they must be included in the PNML, and what features are considered to be specific to a particular net type is subject to further discussion..." The project web site supplies description of PNML, an XML schema, several PNTD for different Petri net types, and some examples. See further description and references in "Petri Net Markup Language (PNML)." In this connection, note also the "Exchangeable Routing Language (XRL)", which uses XML-based Petri net representation for workflows. On XML and Petri Nets in general: "XML and Petri Nets." [September 22, 2000] W3C XML Schema Working Group Releases Updated XML Schema Working Drafts. The W3C XML Schema Working Group has published an updated version of the XML Schema specification. The most important set of changes is found in the Part 1: Structures document. Editorial notes are provided in Henry Thompson's announcement 'New Pre-CR Public Working Drafts of XML Schema Released'. (1) XML Schema Part 1: Structures. Reference: W3C Working Draft 22-September-2000, edited by Henry S. Thompson (University of Edinburgh), David Beech (Oracle Corp.), Murray Maloney (for Commerce One), and Noah Mendelsohn (Lotus Development Corporation). "XML Schema: Structures specifies the XML Schema definition language, which offers facilities for describing the structure and constraining the contents of XML 1.0 documents. The schema language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs). This specification depends on XML Schema Part 2: Datatypes. Status of Structures: "This working draft incorporates most Working Group decisions through 2000-09-19. It has been reviewed by the XML Schema Working Group, and the Working Group has agreed to its publication as a working draft, which includes our proposed resolution of most issues raised during Last Call. The Working Group intends to submit this specification for publication as a Candidate Recommendation very soon, but is issuing this interim public draft as it sets out a number of changes to the XML Representation of XML Schemas, and we wished to make these available as quickly as possible. Readers may find Description of changes (non-normative) in Appendix H helpful in identifying the major changes since the last Public Working Draft. Note that this revision incorporates several backwards-incompatible changes to the XML representation of schemas. Accordingly, the XML Schema namespace URI has changed to http://www.w3.org/2000/10/XMLSchema." Henry Thompson's note indicates that "the XML Schema WG will shortly release an XSLT stylesheet to forward-convert XML Schema documents which conformed to the older syntax to the new syntax." The non-normative 'Appendix H' in the Structures document supplies a "Description of changes" to the working draft since the previous public version of 07-April-2000. Some eighteen (18) changes are identified here. For example: [H1] "'Equivalence classes' have been renamed 'substitution groups', to reflect the fact that their semantics is not symmetrical; [H2] "The content model of the complexType element has been significantly changed, allowing for tighter content models and a better fit between the abstract component and its XML Representation"; [H3] "Empty content models are now signalled by an explicit empty content particle, mixed content by specifying the value true for the mixed attribute on complexType or complexContent; [H6] "A new form of schema composition operation, similar to that provided by include but allowing constrained redefinition of the included components has been added, using a redefine element"; [H8] "The defaulting for the minOccurs and maxOccurs attributes of element has been simplified: it is now 1 in both cases, with no interdependencies"; [H9] "The content model for the group element when it occurs at the top level has been tightened, to allow only a single all, choice, group, or sequence child"; [H13] "Abstract types in element declarations are now allowed." Etc. (2) XML Schema Part 2: Datatypes. Reference: W3C Working Draft 22-September-2000, edited by Paul V. Biron (Kaiser Permanente, for Health Level Seven) and Ashok Malhotra (IBM). "XML Schema: Datatypes is part 2 of a two-part draft of the specification for the XML Schema definition language. This document proposes facilities for defining datatypes to be used in XML Schemas as well as other XML specifications. The datatype language, which is itself represented in XML 1.0, provides a superset of the capabilities found in XML 1.0 document type definitions (DTDs) for specifying datatypes on elements and attributes." (3) XML Schema Part 0: Primer. Reference: W3C Working Draft, 22-September-2000, edited by David C. Fallside (IBM). XML Schema Part 0: Primer is a non-normative document intended to provide an easily readable description of the XML Schema facilities and is oriented towards quickly understanding how to create schemas using the XML Schema language. XML Schema Part 1: Structures and XML Schema Part 2: Datatypes provide the complete normative description of the XML Schema definition language, and the primer describes the language features through numerous examples which are complemented by extensive references to the normative texts." For XML Schema background and references, see: (1) the W3C XML Schema page; (2) mailing lists for comments on the W3C specifications and for public discussion; (3) XSV Validator for XML Schema; (4) comprehensive references in "XML Schemas." [September 22, 2000] FRODO RDFSViz RDF Schema Visualization Tool. Michael Sintek announced the release of an RDF Schema visualization tool named 'FRODO RDFSViz'. The FRODO RDFSViz tool "provides a visualization service for ontologies represented in RDF Schema. It uses the Java RDF API implementation (from Sergey Melnik) and the Graphviz graph drawing program (from AT&T and Lucent Bell Labs). The tool creates simple class diagrams where classes become vertices and rdfs:subClassOf relations become edges. Optionally, properties with rdfs:Class-valued domains and ranges are also visualized as (labeled) edges. Future extensions are planned, e.g., to show properties with range rdfs:Literal or to support the strawman syntax. If you want to visualize general RDF models, you may use the RDF graph visualization tool Rudolf RDFViz (from Dan Brickley). The FRODO RDFSViz tool was implemented in the FRODO project (A Framework for Distributed Organizational Memories) at DFKI Kaiserslautern (German Research Center for Artificial Intelligence)." An online demo (which uses a Java servlet) and the download distribution (binary and source, command line and servlet versions) are available via the project web site. Online examples of tool output include: (1) The newspaper ontology from the Protégé-2000 tool which has experimental support for editing RDF schemas and instance data; (2) Searchable Internet services example from the RDF Schema specification. The developers (Michael Sintek and Andreas Lauer) welcome user comments, bug reports, and ideas for improvements. On RDF, see "Resource Description Framework (RDF)." [September 22, 2000] Global Uniform Interoperable Data Exchange (GUIDE Business Transaction Markup). GUIDE (Global Uniform Interoperable Data Exchange), recently announced by David RR Webber, is "an open interoperable XML markup specification for business information exchanges. The intention is to develop a vendor neutral, non-proprietary and open public set of XML markup methods within the context of ebXML, the XML/edi Group and the W3C XML syntax specifications work. Businesses and industries are adopting XML based information exchanges today and require a robust interoperable system for using XML syntax interoperably. Having DTD and Schema definitions is not enough by itself. Consistent software methods for the payload formats and the supporting repository definitions of the semantic rule definitions in those payloads and associated business processes are essential. GUIDE provides these mechanisms by leveraging simple XML syntax today, and also allowing the phased adoption of more advanced schema technologies as they mature in the future. GUIDE is specifically designed to be easy to understand, use and implement. GUIDE works with your existing XML parsers today so builds on your product base investment. The GUIDE specification has been formally submitted to the ebXML initiative and as such is open and public within the auspicies of ebXML. . . GUIDE is a XML format for describing business information interchanges between a set of endpoints exchanging transactions. GUIDE has a layered approach, so that each aspect of the GUIDE syntax is expressed as a separate markup layer. Separation into layers is a fundamental requirement in order to meet the ability to deploy the semantic web as opposed to the content-based web of today. The objective of GUIDE is to provide a simple open business interchange system for the consistent exchange of transactions." The current [2000-09-22] GUIDE draft specification "represents the blending of current practical work in a variety of areas with XML, including the latest W3C Schema and Datatyping drafts, MSL typing markup, SOAP based interchanges, ISO11179, tpaML and ebXML related work. It is not the intention that GUIDE replace all these other initiatives, but rather that GUIDE provide a consistent way to harmonize these more complex syntaxes into a format that ordinary businesses can use reliably and consistently for basic day-to-day information interchanges. This will also allow developers to create base implementations of XML parsers and tools that are simply GUIDE compatible, that can later be extended to also support more complex syntaxes as business needs dictate." The project is supported by a GUIDE implementors' mailing list; the technical specification is available in PDF and HTML formats, together with sample GUIDE Schema formats. See also: "Global Uniform Interoperable Data Exchange (GUIDE)." [September 22, 2000] Synchronized Multimedia Integration Language (SMIL 2.0) Specification in Last Call Review. As part of the W3C Synchronized Multimedia Activity, the W3C SYMM Working Group has published a last-call public working draft of the Synchronized Multimedia Integration Language (SMIL 2.0) Specification. Reference: W3C Working Draft 21-September-2000, edited by Jeff Ayars, Dick Bulterman, Aaron Cohen, et al. The last-call review period ends 20-October-2000, after which the Working Group 'intends to submit this specification for publication as a Candidate Recommendation.' The new WD updates Synchronized Multimedia Integration Language (SMIL) Boston Specification [W3C Working Draft 22-June-2000]; accordingly, 'SMIL-Boston' (code name) is now renamed SMIL20. The WD document "specifies the second version of the Synchronized Multimedia Integration Language (SMIL, pronounced 'smile'). SMIL 2.0 has the following two design goals: (1) Define an XML-based language that allows authors to write interactive multimedia presentations. Using SMIL 2.0, an author can describe the temporal behavior of a multimedia presentation, associate hyperlinks with media objects and describe the layout of the presentation on a screen. (2) Allow reusing of SMIL syntax and semantics in other XML-based languages, in particular those who need to represent timing and synchronization. For example, SMIL 2.0 components are used for integrating timing into XHTML and into SVG. SMIL 2.0 is defined as a set of markup modules, which define the semantics and an XML syntax for certain areas of SMIL functionality. Appendix A of the working draft contains the SMIL 2.0 XML DTDs [cache]. See also the SMIL mailing list archives and the public working draft of HTML+SMIL Language Profile (modules supporting animation, content control, linking, media objects, timing an synchronization, and transition effects; not currently ready for last-call review). In order to help evaluate the SMIL 2.0 Last Call specification, Oratrix is making versions of its GRiNS for SMIL-2.0 player available for general testing and evaluation. For earlier references, see: "Synchronized Multimedia Integration Language (SMIL)." [September 21, 2000] Jabber XML Protocol Gains Popularity. A recent announcement from Jabber.org notes that the Jabber extensible instant messaging platform has "surpassed 10,000 server downloads with more than 1,000 of these servers now actively deployed on the Internet, marking a 100-percent increase in the number of downloaded servers in the last two months and an increase of more than ten times the number of servers in active deployment in the same period." Jabber, specified in the Jabber XML Protocol, is characterized as an "open source, XML-based instant messaging platform. . . key features of Jabber include: Distributed Server Architecture; ISP-level service, similar to most other Internet services; XML based messaging transport protocol; Simplistic in function, allowing simple and pervasive clients; Embeddable and Extensible in every way' Back-end compatibility with all other IM systems -- you can communicate with AIM and ICQ users, as well as users of future IM systems." The IETF Internet Draft specification formalizes the Jabber data types in a Jabber Protocol DTD and an XML Streams DTD. Description: "At the core, Jabber is an API to provide instant messaging and presence functionality independent of data exchanged between entities. The primary use of Jabber is to give existing applications instant connectivity through messaging and presence features, contact list capabilities, and back-end services that transparently enrich the available functionality. Essentially, Jabber defines an abstraction layer utilizing XML to encode the common essential data types. This abstraction layer is managed by an intelligent server which routes data between the client APIs and the backend services that translate data from remote networks or protocols. By using this compatible abstraction layer, Jabber can provide many aspects of an Instant Messaging (IM) and/or Presence service in a simplified and uniform way. XML is used in Jabber to define the common basic data types: message and presence. Essentially, XML is the core enabling technology within the abstraction layer, providing a common language with which everything can communicate. XML allows for painless growth and expansion of the basic data types and almost infinite customization and extensibility anywhere within the data. Many solutions already exist for handling and parsing XML, and the XML Industry has invested significant time in understanding the technology and ensuring full internationalization. XML Namespaces are used within all Jabber XML to create strict boundaries of data ownership. The basic function of namespaces is to separate different vocabularies of XML elements that are structurally mixed together. By ensuring that Jabber's XML is namespace-aware, it allows any XML defined by anyone to be structurally mixed with any data element within the protocol. This feature is relied upon frequently within the protocol to separate the XML that is processed by different components." See other references in "Jabber XML Protocol." [September 21, 2000] Extracting and Reifying RDF Statements from XML. Jonathan Borden (of The Open Healthcare Group) posted an announcement for an XSLT-based RDF extractor for XML. "In my investigations of simplfied XML syntax for RDF, and extracting RDF from arbitrary or colloqial XML, I have now come to the conclusion that the essence of TimBL's strawman, in which rdf:parseTyle='Resource' is the default, provides the best option for extracting RDF statements from XML. I have incorporated Jason Diamond's rdf.xsl into a new implementation of an XSLT based RDF extractor for XML. This extractor outputs rdf:Statements. Interestingly, when the result of a transform is itself transformed, the statements are reified, hence I call this rdfExtractify.xsl. A brief list of its features: (1) It implements XLink2RDF, now for extended XLinks as well; (2) It extracts RDF statements from plain 'ole XML; (3) It extracts RDF statements from RDF with defaultParseType='Resource' -- this is a param; (4) It handles collections, aboutEach and bagID; the syntax for collections is loosened so that any child element can be a member (need not only be <rdf:li>) (5) It implements QNameToURI -- see http://www.openhealth.org/RDF/QNameToURI.htm -- which converts namespace qualified names to URIs; (6) It implements nodeIdentifier which produces an XPointer fragment identifier e.g., #xpointer(/foo[1]) or ChildSeq identifier e.g., #/1/2 (see the XPointer spec), the type of XPointer produced is set in the explicitPathIndices = 'ChildSeq' (default) param. See now the updated: Extracting and reifying RDF from XML with the sources and online forms-based 'extractifier'. On RDF, see "Resource Description Framework (RDF)." [September 21, 2000] First MathML Conference at UIUC: 'MathML and Math on the Web'. Apropos of XML and mathematics: an announcement "Wolfram Research To Host First MathML Conference" says in part: "Wolfram Research, Inc. is the host of the first MathML and Math on the Web conference, to be held October 20-21, 2000, on the campus of the University of Illinois at Urbana-Champaign. This conference brings together those interested or involved in the future of math on the web. The conference is sponsored by Wolfram Research, the AMS (American Mathematical Society), Compaq, IBM, Netscape, the University of Illinois Grainger Engineering Library, Waterloo Maple, and the W3C (World Wide Web Consortium). This conference provides a forum for presenting and discussing current research and applications involving MathML, an XML application for describing mathematical notation and capturing both its structure and its content. MathML is the W3C-endorsed standard for displaying math on the web. The conference embraces all areas of MathML technologies, including rendering, authoring, converting, and archiving. Scheduled events include an opening video address by Tim Berners-Lee, creator of the World Wide Web and director of the W3C, as well as keynote addresses by Robert Sutor, IBM Program Director for XML Technology ["XML: From Math to SOAP"], and Stephen Wolfram, founder of Wolfram Research and creator of Mathematica ["Mathematical Notation: Past and Future"]. More information about the conference, including the schedule of events and presentation abstracts, is available on the MathML conference web site at http://www.mathmlconference.org." See also the W3C MathML web site and "Mathematical Markup Language (MathML)." [September 21, 2000] IPTC Releases NITF Version 2.5 for XML-Based News. A recent announcement from the International Press Telecommunications Council (IPTC) describes the availability of the Version 2.5 release of the NITF XML DTD. "NITF is an XML-based DTD designed for the markup and delivery of news content in a variety of ways, including print, wireless devices and the Web. It was developed by the International Press Telecommunications Council, an international consortium of news providers, and the Newspaper Association of America, Reston, Va. The standards groups first released NITF in spring 1999, and an NITF Maintenance Committee has made a number of improvements since then. Both the NITF and the NewsML wrapper can be stand alone but may also be used in a complimentary manner as NITF objects can be moved within and managed by NewsML in a multimedia environment. NewsML Version final is expected to be released next month. 'This Version 2.5 of NITF incorporates several changes sought by news organizations that have been putting the standard to work,' said Tony Rentschler, senior software engineer at Associated Press in New York, and chairman of the Maintenance Committee. 'It's a cleaner, more workable DTD both for news providers and their customers.' Among the changes in version 2.5: (1) Clarification of language and time elements (2) Deprecation or removal of several unneeded HTML elements (3) Addition of an alternate code element (<alt-code>), for reference to an internal or external controlled vocabulary as a way of identifying a company, organization or person, among other things. Alan Karben, vice president of product development at ScreamingMedia Inc. in New York, is editor of the DTD and maintains a list of suggested changes from those who are implementing NITF. The new NITF website contains extensive material on the revised DTD, including a tutorial, dynamic documentation, links to discussion forums and of course the DTD itself (with or without documentation). Also posted is a link to the IPTC Subject Reference System for identifying the content of news material in any media." See other description and references in "News Industry Text Format (NITF)." [September 21, 2000] W3C Sponsors XML-Encryption Workshop. Joseph Reagle Jr. (W3C Policy Analyst, IETF/W3C XML-Signature Co-Chair) issued an announcement for a W3C XML-Encryption Workshop. The workshop is hosted by XCert and will be held Thursday, November 2, 2000 in Lafayette/San Francisco, CA. Workshop participants need not belong to W3C member organizations. Rationale: "If XML is to become the language of trusted Web applications (e.g., electronic commerce) it needs standard mechanisms for digitally signing and encrypting XML entities. Furthermore, this mechanism must be fully functional in environments where only XML tools are available. While the joint IETF-W3C Working Group is completing a XML Digital Signatures specification, its charter expressly precludes work on encryption. Consequently, this Workshop will focus on (1) the requirements for XML encryption, (2) the proposals being discussed on the public XML Encryption list as potential starting points for a specification and (3) the structure of a possible W3C activity to advance such a specification to Recommendation." Topics appropriate for the workshop include: "(1) Scope of encryption: should the scope apply to elements only, or any Information Set Item? How should the scope of encryption be described/identified: should the data model be based on on a simple ad-hoc representation or the complete Information Set? (2) Should the data model be represented via URIs or an XML instance using RDF Schema or XSet? (3) KeyInfo: Given that encryption keys might encrypt content or other keys, in what way must the Signature KeyInfo be extended to handle the common Encryption applications? (4) Digital Signature 'awareness' and syntax alignment: to what degree can XML-Encryption use use similar syntax and algorithm identifiers? (5) Schema design: how will encryption portions of an XML instances affect that instances XML schema validity? (6) Algorithm, modes, and formats: which algorithms and formats MUST be supported? (7) Parser impact: will parser have to either post-process or be 'callback equipped' to avoid re-parsing of an entire document after a portion has been decrypted? (8) What rat holes can be identified as out of scope?..." See further the draft agenda and "XML and Encryption." [September 21, 2000] Energy Trading Standards Group (ETSG). Caminus Corporation and HoustonStreet Exchange have led a group of energy exchanges and trading partners in the formation of a new consortium, the Energy Trading Standards Group (ETSG). According to a recent announcement: "The energy trading industry's leading exchanges and technology companies have announced the formation of the Energy Trading Standards Group (ETSG), an open consortium that will develop standards to automate the sale of wholesale energy and improve information sharing between energy trading companies. Consortium members to date include ABB Energy Information Systems, Automated Power Exchange (APX), Caminus Corporation, HoustonStreet Exchange, Open Link Energy, RedMeteor.com, Inc., Triple Point Technology Inc., GFInet, and Sapient. The consortium, initiated by Caminus and HoustonStreet, is open to all interested industry participants. ETSG will develop open standards based upon XML (Extensible Markup Language) technology, the lingua franca of business-to-business Internet commerce. The companies will initially create standards for exchanging data between online trading platforms and transaction/risk management systems used by wholesale electricity and natural gas trading companies. 'XML is rapidly becoming the key data interchange standard for time-critical, high-volume information sharing on the Web, and is a step towards improving operational efficiency in trading systems,' said Amin Rawji, vice president, TransCanada Energy, a company active in the energy markets. 'The ETSG consortium is to be commended for taking the initiative in effectively administering the XML standard for Internet-based B-to-B transactions and applications interoperability in the energy trading industry.' The ETSG consortium will streamline the deal capture process by creating open standards to automate the internal data exchange between frontline traders and their company's mid- and back-office transaction management systems. This automation will save energy trading companies time and expense by eliminating the errors associated with trade ticket generation and data entry, providing real-time access to trade data and eliminating the cost of building and managing proprietary systems and connectors. The consortium intends to develop standards to improve the often-fragmented external exchange of transaction and related data among energy trading partners. Open information exchange standards will allow wholesale energy buyers and sellers to benefit from nearly instantaneous electronic trade confirmations and 'down-stream' scheduling. The ETSG consortium will freely publish the standards so that energy companies can apply them to their own business processes. The consortium will develop XML-enabled connectors to allow energy trading companies to easily integrate their systems with service providers adopting these standards..." See also "Energy Trading Standards Group (ETSG)." [September 21, 2000] W3C/IETF Working Draft for XML-Signature Syntax and Processing. A last-call working draft for XML-Signature Syntax and Processing has been issued by the joint W3C/IETF XML Signature Working Group. Reference: W3C Working Draft 18-September-2000, edited by Donald Eastlake, Joseph Reagle, and David Solo. Also published as 'draft-ietf-xmldsig-core-09.txt'. This second last call WD ends on November 5, 2000; "barring substantive comment, the WG will request Candidate recommendation status as soon as possible, following the Canonical XML request." The WD document "specifies XML digital signature processing rules and syntax. XML Signatures provide integrity, message authentication, and/or signer authentication services for data of any type, whether located within the XML that includes the signature or elsewhere. . . XML Signatures can be applied to any digital content (data object), including XML. An XML Signature may be applied to the content of one or more resources. Enveloped or enveloping signatures are over data within the same XML document as the signature; detached signatures are over data external to the signature element. More specifically, this specification defines an XML signature element type and an XML signature application; conformance requirements for each are specified by way of schema definitions and prose respectively. This specification also includes other useful types that identify methods for referencing collections of resources, algorithms, and keying and management information. The XML Signature is a method of associating a key with referenced data (octets); it does not normatively specify how keys are associated with persons or institutions, nor the meaning of the data being referenced and signed. Consequently, while this specification is an important component of secure XML applications, it itself is not sufficient to address all application security/trust concerns, particularly with respect to using signed XML (or other data formats) as a basis of human-to-human communication and agreement. Such an application must specify additional key, algorithm, processing and rendering requirements." Formal models are provided by the XML schema and XML DTD; see also RDF Data Model. See further information in (1) the IETF/W3C XML Digital Signature Working Group mailing list archives and (2) in "XML Digital Signature (Signed XML - IETF/W3C)." [September 20, 2000] Object Management Group Publishes CORBA/SOAP Interworking Request For Proposal. An announcement from the Object Management Group summarizes a recent OMG Technical Meeting in which the Platform Technology Committee (PTC) "initiated work on a standard that will integrate the new protocol SOAP with OMG's CORBA architecture. SOAP (Simple Object Access Protocol) transmits business data expressed in the Extensible Markup Language (XML) over the widely-used web protocol HTTP. In order to take full advantage of this new protocol, enterprises need to integrate it with their existing computing infrastructure. When complete less than a year from now, the new standard will enable this integration by allowing SOAP clients to invoke CORBA servers, and CORBA clients and servers to interoperate using SOAP. Also in the infrastructure arena, the PTC initiated efforts to standardize methods to transmit CORBA network packets through firewalls, and to adapt Real-Time Object Request Brokers to emit alternative protocols needed for, e.g., telecommunications or other Real-Time applications. The PTC also initiated efforts to standardize a mapping from OMG IDL (Interface Definition Language) to WMLscript, a scripting language based on the Wireless Markup Language, and to standardize an activation framework for persistent CORBA servers." The new RFP is published as CORBA/SOAP Interworking Request For Proposal. Reference: OMG Document 'orbos/00-09-07'; submissions due February 5, 2001. "The RFP solicits proposals for (1) support of CORBA semantics over SOAP (2) enabling native SOAP clients to access CORBA services." Description and scope: "CORBA is a widely deployed distributed systems infrastructure that is currently used as an enabling technology for web integration (intranet, internet, and extranet). SOAP (Simple Object Access Protocol) is an evolving specification being developed under the auspices of the W3C. It is anticipated that SOAP will be widely deployed in the future for use in B2B interactions. It is important that there be a seamless integration between the CORBA and SOAP infrastructures which would enable CORBA invocations to be carried using SOAP. The scope of proposals shall be limited to defining a protocol (marshaling format and message exchange state machine) and the limited object model mappings implicit in the mandatory requirements. Mappings between object models, the definition of a 'service description language', and mappings between SOAP infrastructure services and CORBA services, such as Naming, are out of scope of this RFP. Proposals are expected to track and take into account ongoing work within the W3C, e.g., the proposed XML-PC Working Group. [Specifically:] proposals shall: (a) support the full set of IDL types defined in CORBA 2.4; (b) support the semantics of CORBA invocations, including service contexts; (c) use the SOAP extensibility framework (without changing the SOAP protocol) and track ongoing W3C work; (d) define an IOR profile for SOAP; (e) provide an interoperability solution that permits native SOAP clients to make invocations that are processed by CORBA servers; that is, present a SOAP view, (as defined in CORBA 2.4 section 17.2.3) of a CORBA service to a CORBA unaware SOAP client..." See also in connection with this new RFP: (1) the paper Proposed CORBA SOAP RFP, by Jeff Mischkinsky (Persistence Software), and (2) A Discussion Paper: Simple CORBA Object Access Protocol (SCOAP) (with slides). By BEA Systems, Inc., Financial Toolsmiths AB, Hewlett Packard Company, International Business Machines Corporation, Iona Technologies, Inc., Object Oriented Concepts, Inc., Persistence Software, Inc., Rogue Wave Software, Inc., and Sun Microsystems, Inc. Reference: OMG TC Document 'orbos/00-09-03'. 78 pages. Chapter 3, 'IDL-to-XMLSchema Mapping' describes the XML Schema that is used to describe IDL types; Chapter 8, 'Mapping XML Schema Types to IDL' describes how to.map certain XML Schema datatypes to IDL. "This work was undertaken as a 'proof of concept' (to ourselves and others) that there exists at least one reasonable and viable way to integrate CORBA and SOAP. In addition, its purpose is to spark discussions and debate about this and other approaches to the problem space..." For related resources, see "XML and CORBA" and "Simple Object Access Protocol (SOAP)." [September 20, 2000] Java Interface for RDF Database 'rdfDB'. Eric van der Vlist (Dyomedea) recently announced the availability of a Java interface for rdfDB (a RDF open source database) which can be used within an XT/XSLT transformation. The Java interface, as described on the 4xt.org web site, allows one to "get the results back in plain Java and/or from a a XT/XSLT transformation. RdfDB is a simple, scalable, open-source database for RDF developed by R.V. Guha. rdfDB uses a high level SQLish query language. The data is modelled as a directed labelled graph (RDF), where nodes in graph can be resources, integers, or strings. The new Java interface allows querying the database using its query language and to get the results back row by row and column by column in plain Java and/or as a result tree fragment in a XT/XSLT transformation. It is currently used on the web site XMLfr, where a full site summary has been loaded into rdfDB as three RSS 1.0 channels using the DC and taxonomy modules. . . One of the examples provided in the download section (2rss) shows how specific RSS channels for a topic can easily be generated using the interface, allowing to close the loop: the rdfDB fed by RSS channels can generate RSS channels." See "Resource Description Framework (RDF)." [September 19, 2000] ComDais.com Announces cdXML Standard and cdXML.org for B2B Applications. A recent announcement from ComDais.com (ComDais) describes the formation of cdXML.org as an independent users group to govern the future direction of a proposed 'cdXML' standard specifying an API for building advanced market place applications. According to the announcement: "cdXML allows software developers to interact with a single interface for both buy-side and sell-side functionality across multiple commerce platforms, rather than using a blend of standards and various proprietary interfaces used today to gain the full set of operations required to build today's advanced B2B market places. cdXML is an API industry standard, like cXML but is focused on the buyer/market maker side. cdXML combined with cXML gives the market place application developer a comprehensive independent API set on which to base their projects. This enables market makers to avoid costly and time consuming reengineering with each upgrade of their platform. cXML is the basis for supplier interfaces to the Ariba Supplier network. cdXML extends the ease of XML based standards to market place platforms. The combination of these specifications provides the full spectrum of functionality required by market place administrators and application developers. ComDais provides a complete portable implementation of both these standards. The product is called e.InterfaceNow. e.InterfaceNow supports the full cXML 1.1 and cdXML 1.0 specifications and is available today for the Ariba Marketplace platform. e.InterfaceNow provides both the buyer and supplier functionality that allows software development teams to access the full power of the underlying platforms. This includes: User session management Enhanced product search Punchout and Punchin capability User administration and workflow Requisition management Product and catalog management Purchase order management Shipping and product delivery management. ComDais is making this standard available for free to the industry, like Ariba has done with cXML. Jess Jessop (ComDais.com CEO and CTO) said: 'We are building high-end production market place applications, right now; today and could not wait for a stable XML based API which would eliminate the necessity for our partners to constantly rework their applications with every update to the platform. So we created the cdXML specification and implemented it and cXML over Ariba's Marketplace platform, addressing the real-life needs for developers who have to get market places up and running today'." For other details, see (1) the draft XML DTDs and (2) the text of the announcement, "ComDais.com Gives cdXML to The Industry. cdXML a Complete Buyer / Market Maker XML API for Building Advanced Market Place Applications." [September 16, 2000] Ontology Interchange Language (OIL). OIL (Ontology Interchange Language) proposes a "a joint standard for integrating ontologies with exisiting and arising web standards. OIL is a Web-based representation and inference layer for ontologies, which combines the widely used modelling primitives from frame-based languages with the formal semantics and reasoning services provided by description logics. Furthermore, OIL is the first ontology representation language that is properly grounded in W3C standards such as RDF/RDF-Schema and XML/XML-Schema. OIL is based on existing proposals such as OKBC, XOL and RDF and enrich them with necessary features for expressing rich ontologies. XML can be used as a serial syntax for OIL. Such a syntax is very useful because it puts OIL in the mainstream of tools that are currently being developed for supporting XML-based documents. Validation and rendering techniques developed for XML can directly be used for ontologies specified in OIL. Therefore, the appendix of this paper provides the definition of a DTD that defines constraints on valid documents in OIL. . . The relationship between OIL and RDF/RDFS is much closer than that between OIL and XML Schemas. This is not surprising, since XML-schema was meant to generalize the way of defining the structure of valid XML-documents and RDF/RDFS was meant to capture meaning in the manner of semantic nets. In the same way as RDF-Schema is used to define itself it can also be used to define other ontology languages. We have therefore defined a syntax for OIL by giving an RDF-schema for the core of OIL, and proposing related RDF-schemas that could complement this core by covering further aspects. To ensure maximal compatibility with existing RDF/RDFS-applications and vocabularies, the integration of OIL with the resources defined in RDF-schema has been a main focus in designing the RDF-model for OIL." As described in the white paper: "OIL unifies three important aspects: Formal semantics and efficient reasoning support as provided by Description Logics, epistemological rich modeling primitives as provided by Frame languages, and a standard proposal for syntactical exchange notations as provided by the Web community. (1) Description Logics describe knowledge in terms of concepts and role restrictions that are used to automatically derive classification taxonomies. They provide theories and systems for expressing structured knowledge, for accessing it and reason-ing with it in a principled way. (2) Frame-based systems provide as central modeling primitive classes (i.e., frames) with certain properties called attributes. These attributes do not have a global scope but are only applicable to the classes they are defined for. A frame provides a certain context for modeling one aspect of a domain. (3) Web standards: XML and RDF. Given the current dominance and importance of the WWW, a syntax of an ontology language must be formulated using existing web standards for information representation. The XML schema syntax of OIL was mainly defined as an extension of XOL. OIL is also defined on top of the Resource Description Framework RDF and RDF schema." OIL's machine readable syntax is defined as an XML DTD, an XML Schema definition, and an RDF Schema definition. The formal definition of this human-readable syntax can be found at http://www.ontoknowledge.org/oil/syntax. The development of OIL is governed by a Steering Commitee and an Advisory Board; the project is sponsored by the European Community via the IST projects Ibrow and On-to-knowledge. For related work on ontologies and semantic models for the 'Semantic Web', see (1) SemanticWeb.org - 'Towards a Web Of Meaning...', maintained by Stefan Decker (Stanford University). SemanticWeb.org is operated by three research groups: The Onto-Agents and Scalable Knowledge Composition (SKC) Research Group at Stanford University, The Ontobroker-Group at the University of Karlsruhe, and The Protégé Research Group at Stanford University. (2) the list of 'semantic web' initiatives referenced on the OIL web site. For other OIL description and references, see (1) the project web site and (2) "Ontology Interchange Language (OIL)." Generally: see "XML and 'The Semantic Web'." [September 16, 2000] Schematron Open Source Project on SourceForge. Rick Jelliffe (Academia Sinica Computing Center, Taipei) recently announced the creation of a open source Schematron project on the SourceForge website. SourceForge is 'a free service to Open Source developers offering easy access to the best in CVS, mailing lists, bug tracking, message boards/forums, task management, site hosting, permanent file archival, full backups, and total web-based administration.' Rick writes: "I am happy to announce the start of a project on the Source Forge website for Schematron. The two main facilities we are making use of are: (1) a mail list for anyone interested in Schematron, alternative schema languages and automated, external inference of assertions about structured data; I don't think it will be a high volume site, but I hope it will be interesting; (2) a central public site for adding implementations and schemas. To register for the mail-list, go to webpage http://lists.sourceforge.com/mailman/listinfo/schematron-love-in; to see the project (which will be loaded over the next few weeks), go to the project page." The Schematron is 'An XML Structure Validation Language using Patterns in Trees'. It is an assertion language for XML based on matching combinations of XPath expressions. It can be used both as a schema language and for automatically generating external markup (such as RDF, XLinks and Topic Maps) to annotate XML documents. "The Schematron differs in basic concept from other schema languages in that it not based on grammars but on finding tree patterns in the parsed document. This approach allows many kinds of structures to be represented which are inconvenient and difficult in grammar-based schema languages. If you know XPath or the XSLT expression language, you can start to use The Schematron immediately. The Schematron can be useful in conjunction with many grammar-based structure-validation languages: DTDs, XML Schemas, DCD, SOX, XDR. The Schematron allows you to develop and mix two kinds of schemas: (1) Report elements allow you to diagnose which variant of a language you are dealing with. Many languages have these kind of variants: HTML 2, 3.2., Strict HTML 4, Transitional HTML 4, Frameset HTML 4, ISO HTML, etc. (2) Assert elements allow you to confirm that the document conforms to a particular schema. The Schematron is based on a simple action: First, find a context nodes in the document (typically an element) based on XPath path criteria; Then, check to see if some other XPath expressions are true, for each of those nodes." For an overview of the Schematron, see (1) "Introducing the Schematron. A fresh approach to XML validation and reporting," by Uche Ogbuji and (2) the Zvon Schematron tutorial by Nic Miloslav. For XML schemas in general, see "XML Schemas." [September 16, 2000] Outline Processor Markup Language (OPML). Dave Winer (UserLand Software) posted an announcement for a new XML-based format "Outline Processor Markup Language", or OPML, 1.0. "The purpose of this OPML format is to provide a way to exchange information between outliners and Internet services that can be browsed or controlled through an outliner. An 'outline' [in this case] is a tree, where each node contains a set of named attributes with string values. The OPML design goal is to have a transparently simple, self-documenting, extensible and human readable format that's capable of representing a wide variety of data that's easily browsed and edited. As the format evolves this goal will be preserved. It should be possible for a reasonably technical person to fully understand the format with a quick read of a single Web page. OPML 1.0 is the native file format of Radio UserLand, a product in development at UserLand. The specification may be tweaked in response to comments or questions." Background and rationale: "Outlines have been a popular way to organize information on computers for a long time. While the history of outlining software is unclear, a rough timeline is possible. Probably the first outliner was developed by Doug Engelbart, as part of the Augment system in the 1960s. Living Videotext, 1981-87, developed several popular outliners for personal computers. They are archived on a UserLand website, outliners.com. Frontier, first shipped in 1992, is built around outlining. The text, menu and script editors in Frontier are outliners, as is the object database browser. XML 1.0, the format that OPML is based on, is a recommendation of the W3C. Radio UserLand, first shipped in 2000, is an outliner whose native file format is OPML. Outlines can be used for specifications, legal briefs, product plans, presentations, screenplays, directories, diaries, discussion groups, chat systems and stories. Outliners are programs that allow you to read, edit and reorganize outlines. [Online] examples of OPML documents: play list, specification, presentation." See: "Outline Processor Markup Language (OPML)." [September 15, 2000] dbXML Source Code Release for Open Source Native XML Database Application Server. Kimbro Staken (Chief Technology Officer, dbXML Group L.L.C) recently posted an announcement for the dbXML Group's version 0.2 release of the dbXML Core Edition. "dbXML is the industry's first Open Source Native XML Database Application Server. It has been designed from the ground up as a complete solution to enterprise-wide XML integration and application provisioning. The dbXML Core Edition is a data management system designed specifically for collections of XML documents. It is easily embedded into existing applications, highly configurable, and openly extensible. Between Versions 0.1 and 0.2, we have completely rewritten dbXML in Java. Because of the rewrite, we essentially started over from scratch about a month and a half ago. We've made incredible progress in that short amount of time, but there's still a bit left to do. Don't be fooled though, there's more than enough to digest, and the product is in a sufficient state that real-world applications can be developed with it. I didn't say production applications, just real-world. Production quality will come later. There are a few major system modules that need to be written. These include a simple Query Mechanism for XPath expressions, a Query Engine that understands an industry-standard DDL and DML (which has yet to be identified), an Access Control system, and the dbXML Traversable, Compressed DOM. So, as you can see, there's a bit left to do, but in the past 1.5 months, the four of us have performed a minor miracle in getting dbXML into the shape that it's in. The dbXML Core Edition is being released under the terms of the GNU Lesser General Public License (LGPL). If you'd like to download the source code, you are welcome to visit the Core project's web page. If you'd like to contribute to the project, we invite you to visit our SourceForge project page at http://www.sourceforge.net/projects/dbxml-core. . . The dbXML Group focuses on next-generation web application development tools and services specifically in the realm of XML-related technologies. The dbXML Group started operating in August of 1999 in order to produce an enterprise-scale XML Database Application Server." [September 15, 2000] Preliminary Technical Release of XLink Generator 'xlinkit.com' ['consistencycheck.com']. A communiqué from Anthony Finkelstein (University College London, Department of Computer Science) describes the "preliminary technical release" of an XLink generator which the developers characterize as "a completely new class of internet technology." The tool 'xlinkit.com' [earlier: 'consistencycheck.com'] is a lightweight application service which provides rule-based link generation and checks the consistency of distributed documents and web content. You simply tell 'xlinkit.com' the information you want to link and rules that relate the information. 'xlinkit.com' will generate the links that you can then use for navigation. It will also diagnose inconsistent information (in other words make sure that you are not saying one thing in one place and another completely different thing in another place) and, if you want, provide you links directly to the inconsistent items of information. 'xlinkit.com' will eliminate the work required to directly author links and keep them up to date as well as simplifying the management of the consistency of distributed documents and web content. 'xlinkit.com' can link and diagnose any information expressed in XML and generates XLinks; both are open, non-proprietary internet standards. xlinkit.com is both scalable and highly customisable, you can handle large document sets and build rules of arbitrary complexity using our simple set-based rule language." 'xlinkit.com' can be applied "anywhere that you want to establish links between documents -- or more generally web-content -- where those links reflect relationships between document types. Examples: Customer Relationship Management, Product Catalogues, B2B Service-level Agreements, Requirements Management, Software Development, Software Development, Network Management Policy, Product Data Management." To use the tool one must write rules, and assemble rule-sets and document-sets; all such information is structured in XML. The web site provides the XML DTD for the rule language, together with an XSL stylesheet for visualising the rules. There is also an XML DTD for the rule-set language and a DTD for the document-set language. 'xlinkit.com' is based on an approach that builds on a substantial research background developed by the Software Systems Engineering Group at University College London. This research has been based on the problems of coordinating and managing consistency in distributed software engineering teams. See the publications page of Anthony Finkelstein for pointers. Example documents appropriate for 'xlinkit.com' are provided for anyone wishing to experiment with the application. The XLink generator tool is free and open for use for demo or trial application; it is accessible online. For other XLink software (mostly experimental), see "XML Linking Software." [September 15, 2000] New Working Draft for the Platform for Privacy Preferences 1.0 (P3P1.0) Specification. As part of the W3C P3P Activity, the P3P Specification Working Group has issued a revised working draft for the The Platform for Privacy Preferences 1.0 (P3P1.0) Specification. Reference: W3C Working Draft 15-September-2000, edited by (Massimo Marchiori (W3C/MIT/UNIVE); by [authors} Lorrie Cranor (AT&T), Marc Langheinrich (ETH Zurich), Massimo Marchiori (W3C/MIT/UNIVE), Martin Presler-Marshall (IBM), Joseph Reagle (W3C/MIT). "The Platform for Privacy Preferences Project (P3P) enables Web sites to express their privacy practices in a standard format that can be retrieved automatically and interpreted easily by user agents. P3P user agents will allow users to be informed of site practices (in both machine- and human-readable formats) and to automate decision-making based on these practices when appropriate. Thus users need not read the privacy policies at every site they visit. The P3P1.0 specification defines the syntax and semantics of P3P privacy policies, and the mechanisms for associating policies with Web resources. P3P policies consist of statements made using the P3P vocabulary for expressing privacy practices. P3P policies also reference elements of the P3P base data schema -- a standard set of data elements that all P3P user agents should be aware of. The P3P specification includes a mechanism for defining new data elements and data sets, and a simple mechanism that allows for extensions to the P3P vocabulary. P3P version 1.0 is a protocol designed to inform Web users of the data-collection practices of Web sites. It provides a way for a Web site to encode its data-collection and data-use practices in a machine-readable XML format known as a P3P policy. The P3P specification defines: (1) A standard schema for data a Web site may wish to collect, known as the 'P3P base data schema'; (2) A standard set of uses, recipients, data categories, and other privacy disclosures; (3) An XML format for expressing a privacy policy; (4) A means of associating privacy policies with Web pages or sites; (5) A mechanism for transporting P3P policies over HTTP. The goal of P3P version 1.0 is twofold. First, it allows Web sites to present their data-collection practices in a standardized, machine-readable, easy-to-locate manner. Second, it enables Web users to understand what data will be collected by sites they visit, how that data will be used, and what data/uses they may 'opt-out' of or 'opt-in' to." Contained also in separate files are (1) Appendix 4: XML Schema Definition (Normative) ['This appendix contains the XML Schema, both for P3P policy reference files, for P3P policy documents, and for P3P dataschema documents. An XML Schema may be used to validate the structure and datastruct values used in an instance of the schema given as an XML document. P3P policy and dataschema documents are XML documents that MUST conform to this schema'] and (2) Appendix 5: XML DTD Definition (Normative). See: "Platform for Privacy Preferences (P3P) Project." [September 14, 2000] Blocks Extensible Exchange Protocol Framework. An IETF Internet Draft written by Marshall T. Rose (Invisible Worlds, Inc.) outlines The Blocks eXtensible eXchange Protocol Framework and represents the latest in a series of IETF drafts on BXXP/BEEP. Reference: 'draft-ietf-beep-framework-01'. 58 pages. September 11, 2000. "This memo describes a generic application protocol framework for connection-oriented, asynchronous interactions. The framework permits simultaneous and independent exchanges within the context of a single application user-identity, supporting both textual and binary messages... At the core of the BXXP framework is a framing mechanism that permits simultaneous and independent exchanges of messages between peers. Messages are arbitrary MIME content, but are usually textual (structured using XML). Frames are exchanged in the context of a 'channel'. Each channel has an associated 'profile' that defines the syntax and semantics of the messages exchanged. Implicit in the operation of BXXP is the notion of channel management. In addition to defining BXXP's channel management profile, this document defines: (1)the TLS transport security profile; and (2) the SASL family of profiles. Other profiles, such as those used for data exchange, are defined by an application protocol designer. A registration template is provided for this purpose... Because BEEP uses XML technology to provide a more efficient application protocol framework, it is ideal for companies that use the Internet or other networking technologies to process enormous amounts of data." See especially: (1) section 2.2.2.2 on "XML-based Profiles", (2) section 6.2 for "BXXP Channel Management DTD", (3) section 6.4 for "TLS Transport Security Profile DTD", and (4) section 6.6 for "SASL Family of Profiles DTD." The Blocks eXtensible eXchange Protocol (BXXP, a.k.a. BEEP) is a protocol framework being developed under IETF rules. "A working group of the Internet Engineering Task Force (IETF) has been tasked with submitting revised specification to the Internet Engineering Standards Group (IESG) for consideration as a standards-track publication. Using BXXP as a framework for application protocols has these advantages: (1) All of the tips and tricks of experienced protocol designers are freeze-dried into a unified programming framework that can be used over and over again. (2) It is an application protocol framework for connection-oriented, asynchronous request/response interactions. (3) BXXP handles all the dirty work of initiating connections, framing, managing security, and multiplexing multiple channels in a single authenticated connection, freeing developers to work on adding new application features. (4) The protocol is designed for extensibility through the use of profiles that 'snap into' the BXXP framework. (5) Security profiles enable the reuse of security and authentication mechanisms among multiple applications. (6) Data communication profiles make it easy to determine the messages applications must exchange. (7) Profiles can be easily created and customized to quickly develop new Internet applications." For further description and references, see "Blocks eXtensible eXchange Protocol Framework (BEEP)." [September 14, 2000] W3C Announces XML Protocol Activity. Dan Brickley (W3C) posted an announcement describing the chartering of a new W3C XML Protocol Activity and new Working Group. "With the introduction of XML and Resource Description Framework (RDF) schema languages, and the existing capabilities of object and type modeling languages such as Unified Modeling Language (UML), applications can model data at either a syntactic or a more abstract level. In order to propagate these data models in a distributed environment, it is required that data conforming to a syntactic schema can be transported directly, and that data conforming to an abstract schema can be converted to and from XML for transport. The Working Group should propose a mechanism for serializing data representing non-syntactic data models in a manner that maximizes the interoperability of independently developed Web applications. Furthermore, as data models change, the serialization of such data models may also change. Therefore it is important that the data encapsulation and data representation mechanisms are designed to be orthogonal. Examples of relationships that will have to be serialized include subordinate relationships known from attachments and manifests. Any general mechanism produced by the Working Group for serializing data models must also be able to support this particular case... Particularly relevant to our recent threads about XML and graph data models." David Fallside (IBM) is Chair XML Protocol Working Group; the W3C mailing list xml-dist-app is to be the preferred channel of communication for the Working Group. From the new WG charter: "The initial focus of this Working Group is to create simple protocols that can be ubiquitously deployed and easily programmed through scripting languages, XML tools, interactive Web development tools, etc. The goal is a layered system which will directly meet the needs of applications with simple interfaces (e.g., getStockQuote, validateCreditCard), and which can be incrementally extended to provide the security, scalability, and robustness required for more complex application interfaces. Experience with SOAP, XML-RPC, WebBroker, etc. suggests that simple XML-based messaging and remote procedure call (RPC) systems, layered on standard Web transports such as HTTP and SMTP, can effectively meet these requirements. Specifically, the XML Protocol Working Group is chartered to design the following four components: (1) An envelope for encapsulating XML data to be transferred in an interoperable manner that allows for distributed extensibility and evolvability as well as intermediaries. (2) A convention for the content of the envelope when used for RPC (Remote Procedure Call) applications. The protocol aspects of this should be coordinated closely with the IETF and make an effort to leverage any work they are doing. (3) A mechanism for serializing data representing non-syntactic data models such as object graphs and directed labeled graphs, based on the datatypes of XML Schema. (4) A mechanism for using HTTP transport in the context of an XML Protocol. This does not mean that HTTP is the only transport mechanism that can be used for the technologies developed, nor that support for HTTP transport is mandatory. This component merely addresses the fact that HTTP transport is expected to be widely used, and so should be addressed by this Working Group." For other details, see the XML Protocol Working Group Charter and the W3C XML Protocol publicity document. [September 13, 2000] Rand Report on Standards for the Digital Economy. Rand's Science and Technology Institute was commissioned by the White House Office of Science and Technology Policy to prepare a report on the adequacy of today's digital standards. "RAND was also asked to analyze where these standards are taking the industry and whether government intervention will be required to address systemic failures in the standards development process." The published RAND report is now publicly available as: Scaffolding the New Web: Standards and Standards Policy for the Digital Economy. By Martin Libicki, James Schneider, Dave R. Frelinger, and Anna Slomovic. According to the announcement for the report, "the RAND research team conducted case studies that covered existing Web standards, the Extensible Markup Language (XML) [Appendex B, 20 pages], digital library standards, issues related to property and privacy, and transactions between buyers and sellers in electronic commerce. The team concludes that the current standards process 'remains basically healthy' but cautions that 'the success of standards in the marketplace depends on the play of larger forces.' HTML and Java a succeeded in the recent past because they were straightforward and unique ways of doing things, the analysts point out. Today, Web standards development is caught up in the contests between corporations that are trying to do end-runs around each other's proprietary advantages. Meanwhile, the standards governing the other case study areas are being buffeted by the varied interests of such affected groups as authors, librarians, rights holders, consumers, banks, merchants, privacy activities and governments. Government may not have a major role to play, according to the report. Washington might consider allowing researchers to use a fraction of their government research and development funding to work on standards, the authors suggest. But 'perhaps the best help the government can offer is to have the National Institute for Standards and Technology intensify its traditional functions: developing metrologies; broadening the technology base; and constructing, on neutral ground, terrain maps of the various electronic-commerce standards and standards contenders'." See the document summaries in the articles section. [September 13, 2000] New Release of xslide Emacs Major Mode for Editing XSL Stylesheets. Tony Graham (Mulberry Technologies, Inc.) has announced the release of xslide Revision 0.2 Beta 1. The xslide package provides the implementation of an Emacs major mode for editing XSL stylesheets. Features of xslide revision 0.2b1 include: "(1) XSL customization groups for setting some variables (2) Initial stylesheet inserted into empty XSL buffers; (3) "Template" menu for jumping to template rules in the buffer; (4) xsl-process function that runs an XSL processor and collects the output; (5) Predefined xsl-process command line templates and error regexps for XT and Saxon; (6) Font lock highlighting so that the important information stands out (font lock colours can be customized once xslide is loaded by Emacs); (7) xsl-complete function for inserting element and attribute names; (8) xsl-insert-tag function for inserting matching start- and end-tags; (9) Improved automatic completion of end-tags; (10) Improved automatic indenting of elements; and (11) Comprehensive abbreviations table to further ease typing. xslide is a work in progress. Code contributions and suggestions for improvements are always welcome. Use the xsl-submit-bug-report' function to report bugs." For related software tools, see "XSL/XSLT Software Support." [September 12, 2000] Praxis Announces Schemantix for XML Schema-Centric Web Application Development. Matthew Gertner (CTO, Praxis) posted an announcement for Schemantix version 0.3. "Schemantix is our contribution to the frequently recurring discussion about where XML, and XML schemas in particular, are actually useful. In essence, it is a Open Source system for developing web application using XML schemas as the core representation of application data structures. This provides a single point of maintenance for these applications and thus solves many of the problems associated with large-scale web applications written in template-based languages like ASP, JSP, PHP and ColdFusion. For much more on Schemantix, see www.schemantix.com. The current version is an alpha release that includes the functionality for generating HTML forms from XML schemas. The only schema language we currently support is SOX, but we will have preliminary XSDL and DTD support integrated over the next couple of weeks, as well as support for generating reports as well as forms. I'll make a followup announcement as new features become available. The entire system is available in full source code compliant with the J2EE platform. We'd be most interested in any feedback you might have, both with regard to the overall philosophy of the system and the specific implementation. This is an Open Source project, so if anyone would like to find out more about contributing, please contact me directly." Background: "As browser-hosted applications become increasingly complex and sophisticated, popular approaches to web development such as Microsoft Active Server Pages (ASP) and its open-source competitor PHP are reaching their limits. When underlying data structures are changed, each individual template must be checked and modified accordingly -- a maintenance nightmare for larger applications. Schemantix addresses these issues by moving application logic from the individual templates and back-end data sources into a single central location: XML schemas. XML schemas add powerful new facilities supporting object-oriented features such as inheritance, polymorphism and rich datatyping. As such, they represent an ideal repository for storing business and presentation logic that can be reused across an entire web application, from the browser-hosted user interface to the backend data storage engine." For schema description and references, see "XML Schemas." [September 08, 2000] Graph Exchange Language (GXL). Following a summer ICSE 2000 Workshop on Standard Exchange Formats (WoSEF, June 06, 2000, Limerick, Ireland), some fourteen research groups working in the domain of software reengineering and graph transformation agreed to collaborative future work on the Graph Exchange Language as a potential standard. These development teams from industry and academic areas committed "to refining GXL to be the standard graph exchange format, write GXL filters and tools or use GXL as exchange format in their tools." Graph Exchange Language (GXL) "is designed to be a standard exchange format for graphs. GXL offers an adaptable and flexible means to support interoperability between graph based tools. In particular, the development of GXL tends to enable interoperability between software reengineering tools and components like code extractors (parsers), analyzers and visualizers. GXL enables software reengineers to combine tools especially designed for special reengineering tasks like parsing, source code extraction, architecture recovery, data flow analysis, pointer analysis, program slicing, query techniques, source code visualization, object recovery, restructuring, refactoring, remodularization etc. into a single powerful reengineering workbench. Being a general graph exchange format, GXL can also be applied to other areas of tool interoperability like interchanging models between CASE tools, or exchanging data between graph transformation or graph visualization tools. GXL has also been designed in such a way that extensions are feasible for handling further kinds of graphs, such as hypergraphs and hierarchical graphs. GXL is a XML sublanguage. The syntax of GXL is given by a XML Document Type Definition. In the current (provisional) design, a gxl document consists of XML elements for describing nodes, edges, attributes. GXL documents can be attributed with a reference to an other GXL document (schema) defining the graph schema and a flag (identifiededges) indicating weather the represented graph requries edges having their own identifiers (this is necessary for graphs having multiple edges). The GXL Metaschema is to reflect the GXL DTD; first attempts at a GXL Metaschema were discussed at WoSEF 2000 in light of a draft proposal ("Components of Interchange Formats - Metaschemas and Typed Graphs"). The structure of graphs exchanged by GXL streams is given by a schema denoted as UML class diagrams which in turn can be exchanged by graphs represented as GXL document. GXL originates in the GRAph eXchange format, GraX (University of Koblenz, DE) for exchanging typed, attributed, ordered directed graphs (TGraphs), combined with the Tuple Attribute Language, TA (University of Waterloo, CA) and the graph format of the PROGRES graph rewriting system (University Bw München, DE). Furthermore GXL includes the exchange format of Relation Partition Algebra, RPA (Philips Research Eindhoven, NL) and Rigi Standard Format, RSF (University of Victoria, CA). Several published papers supply technical description for GXL, including (1) "A Short Introduction to the GXL Exchange Format", (2) "Looking for a Graph eXchange Language", (3) "GXL: Towards a Standard Exchange Format." The project is supported by a GXL mailing list, which is archived. For other references, see "Graph Exchange Language (GXL)." [September 08, 2000] Caxton Chess XML (CaXML). Eric Schiller's 'Caxton Chess XML' is now provisionally available under GNU license. Caxton XML "is an XML standard designed for the representation of chess game data using ASCII text files. Caxton is intended to enable sophisticated handling of chess data by programs written for 5th generation browsers. It is also designed to be legible to human interpreters. For the most part, data in Portable Game notation (PGN) can be cleanly converted to CaXML and vice versa. Because Chess Base and similar products have the limited number of fields, and limited size of each field, information will be lost when converting from CaXML to some proprietary chess database formats. The PGN standard enabled exchange of information between programs, but is ill-suited for the presentation of chess data on screen. The USCF standard of 1994 was created to address the problem in print publications, but the Internet demands a more dynamic data representation. The advent of XML makes this possible. Our goal is to create a seamless data interchange based on industry-standard tags. Translation between PGN and CaXML should be straightforward." The XML DTD for 'Caxton Extensible Markup Language' is available online, together with a sample XML instance and an XSLT stylesheet. Design rationale: "Extensible Markup Language (XML) is all the rage, and with new and improved support in Microsoft and Netscape browsers, as well as an abundance of tools which integrate XML into a variety of programming environments, webmasters and chess programmers can now take advantage of the power and flexibility of this new technology. The latest draft of the document type declaration document for Caxton XML is available, currently under development at Chessworks Unlimited. This DTD contains provisions for structuring game, tournament, and player information. In future installments we'll show the XML in use, but it will be a month or two before the specification is complete. The final specs will be distributed under an Open Source license, so the technology will be available to everyone." [September 08, 2000] XML-Based 'eStandard' for the Chemical Industry. A draft document specifying a 'Data-Exchange Standard for the Chemical Industry' has been prepared by BASF, Dow Chemical, and DuPont as an XML-Based 'eStandard', soon to be presented to CIDX (Chemical Industry Data Exchange). CIDX is a "recognized source for guidance on electronic commerce solutions for the chemical industry. CIDX products: its guidelines, publications, and communications, are highly relevant, timely and directly address the needs of the industry. CIDX provides a forum for the identification, evaluation and piloting of electronic commerce technologies." The draft XML specification (180 pages, including prose and DTDs), is available for download on the CIDX web site. Overview: "In an effort by BASF, Dow, and DuPont, Version 1 of the XML-based eStandard has been developed for use by the Chemical Industry for exchanging data company-to-company and company-to-marketplace. By initiating this effort, there is foreseen substantial benefit to be gained by developing and adopting data interchange standards industry wide based for all of the Chemical Industry. This view has been validated with many other Chemical Industry companies during the project. All companies believe adopting industry standards will reduce the overall cost of implementation and enable e-business gains to be more fully realized. This eStandard was developed primarily by a limited number of subject matter experts. The intent was to develop an eStandard that is freely available for broad appropriate use without royalty by all Chemical Industry participants. This Version 1.0 eStandard will be submitted to the Chemical Industry Data Exchange (CIDX) for endorsement and on-going support to ensure that this eStandard is kept current with industry needs going forward. In doing so, BASF, Dow and DuPont intend that CIDX will be the standards owner and maintenance facility for XML-based standards for the Chemical Industry. Future eStandards and enhancements to those provided in this Version 1.0 will be developed and released in future versions of this XML-based eStandard... This Version 1.0 document provides 12 business transactions that support a general business-processing model. Specifically, the initial deliverable of the eStandard document supports data interchange in the following areas: (1) Customer/Company Information: Includes data interchanges necessary to support customer/company information sharing of related data with Marketplace(s). (2) Product Catalogs: Includes data interchanges necessary to support the promoting, selling, selecting and buying of products. (3) Orders: Includes data interchanges necessary to support the transmission of data regarding orders for products and related services. (4) Envelope and Security: Includes utilizing Internet protocols to identify and protect computer-to-computer transaction data shared between business entities. The 12 business transactions provided in this document are: Qualification Request,Qualification Request Response, Request for Quote, Product Catalog Update, Customer Specific Catalog Update, Create Order, Order Response, Order Status, Order Status Inquiry, Change Order, Cancel Order, and Cancel Order Response. Each eStandard message is an XML document conforming to a specific Document Type Definition (DTD) described in this standard for the transaction being executed. The DTDs for each of these transactions is described through the standard. Where there are any discrepancies between the narrative and the DTD that describes a message, the DTD should be considered correct. The XML specification describes structured data. XML document elements may either contain other data data elements or data (or both). The approach used in this eStandard is that message elements may only contain other elements or data." For other description and references, see "XML-Based 'eStandard' for the Chemical Industry." [September 08, 2000] W3C XML Base Specification Published as a Candidate Recommendation. The W3C XML Linking Working Group has issued XML Base as a CR specification. Reference: W3C Candidate Recommendation 8-September-2000, edited by Jonathan Marsh (Microsoft). It "proposes a facility, similar to that of HTML BASE, for defining base URIs for parts of XML documents." The specification is considered stable by the XML Linking Working Group. The Working Group invites implementation feedback during this period. Comments on this document should be sent to the public mailing list [email protected] by December 8 2000. Description: "The XML Linking Language defines Extensible Markup Language (XML) 1.0 constructs to describe links between resources. One of the stated requirements on XLink is to support HTML linking constructs in a generic way. The HTML BASE element is one such construct which the XLink Working Group has considered. BASE allows authors to explicitly specify a document's base URI for the purpose of resolving relative URIs in links to external images, applets, form-processing programs, style sheets, and so on. This document describes a mechanism for providing base URI services to XLink, but as a modular specification so that other XML applications benefiting from additional control over relative URIs but not built upon XLink can also make use of it. The syntax consists of a single XML attribute named xml:base. The deployment of XML Base is through normative reference by new specifications, for example XLink and the XML Infoset. Applications and specifications built upon these new technologies will natively support XML Base. The behavior of xml:base attributes in applications based on specifications that do not have direct or indirect normative reference to XML Base is undefined." For related specifications and references, see "XML Linking Language." [September 08, 2000] 'Final' W3C Working Draft for Canonical XML 1.0. The IETF/W3C XML Signature Working Group has released a new working draft specification for Canonical XML Version 1.0. Reference: W3C Working Draft 07-September-2000, edited by John Boyer (PureEdge Solutions Inc.). Document abstract: "Any XML document is part of a set of XML documents that are logically equivalent within an application context, but which vary in physical representation based on syntactic changes permitted by XML 1.0 and Namespaces in XML. This [Canonical XML] specification describes a method for generating a physical representation, the canonical form, of an XML document that accounts for the permissible changes. Except for limitations regarding a few unusual cases, if two documents have the same canonical form, then the two documents are logically equivalent within the given application context. Note that two documents may have differing canonical forms yet still be equivalent in a given context based on application-specific equivalence rules for which no generalized XML specification could account." Document status: WD-xml-c14n-20000907 "is the fourth draft of this (XPath based) Canonical XML specification, and it addresses all issues raised during the second Last Call which ended July 28, 2000. While this specification attempts to capture the resolution of all issues, the list and disposition of last call issues itself is a living document maintained by the XML Signature Working Group. The Working Group expects to finish the documentation on all issues within a week and then request that the W3C Director advance the document to Candidate Recommendation. This specification includes editorial and technical clarifications and corrections suggested by last call reviewers. Additionally, this version also includes examples as well as two substantive differences from the previous version: (1) The only change to the canonicalized output is the reduction of redundant namespace declarations (see section 4.6: Superfluous Namespace Declarations). (2) The processing model is changed with respect to the input expectations. Instead of an XPath expression, the canonical process expects an XPath node-set (or functional alternative such as octets that represent a well-formed XML instance)." [September 07, 2000] SVG RDF Tool for SVG-to-Text Conversion. Daniel Dardailler announced the availability of an 'SVG RDF tool': "With the summer over, I'm happy to release the work of a student we had here in Sophia, working on an SVG-to-text converter, using RDF statements to help with the inherent graphical semantics. The report, the tools and the schema are all at http://www.w3.org/WAI/ER/ASVG/. The 'SVG Linearizer Tools' project of Guillaume Lovet involved writing an SVG-to-text converter in three different steps: (1) The development of an RDF vocabulary, allowing the description of an SVG document (pictures, schemas, graphics), in order to make the information carried by such a document accessible, regardless of the support at one disposal to exploit it (computer screen, speaker, tactil screen). (2) The development of a tool (written in Java) able to exploit such an RDF description, thus using the elements of the previous vocabulary. The results of the proceeding will have to be presented in a textual form, ready then to be exploited by various accessibility tools (for example, a vocal module or a 'Braille' screen for people with visual impairment). (3) Eventually, the development of another tool (in Java again) implementing the edition process of an SVG document, in order to attach a description oriented to its accessibility. The user of such a tool will have few or no RDF notions, therefore the edition process will have to be as tranparent, simple and graphic as possible." The RDF vocabulary "is made of 29 properties (or words); this vocabulary forms the namespace axsvg (for Accessibity SVG), and has an associated RDF Schema. Most of these properties are 'by reference', i.e., in the RDF statement for which they are the predicate, the subject and the object are some 'entities' of the SVG document, identified by their 'id' attribute. [E.g., Structural: "Regroups, IsConvergencePoint, IsConnected, IsPartOf, PointsTo, Links, Contents, IsFatherOf, Has, SitsOnTop, HasOnTop, IsGoingThrough, IsLayeredOn, HasForValue, Associated"; Geographic: "AtRight, AtLeft, IsBehind, IsOver, InFrontOf, MaskedBy, On, Under"; Graphic properties, Special Properties, etc. The report also describes a Java translator and Java Editor. On RDF, see the W3C web site and "Resource Description Framework (RDF)." [September 06, 2000] Universal Description, Discovery, and Integration (UDDI). Lead by IBM, Ariba, and Microsoft, a broad coalition of business and technology leaders today announced the Universal Description, Discovery and Integration (UDDI) Project -- "a cross-industry initiative designed to accelerate and broaden business-to-business integration and commerce on the Internet. The Universal Description, Discovery and Integration (UDDI) standard (registry) is a new industry initiative [which] creates a platform-independent, open framework for describing services, discovering businesses, and integrating business services using the Internet. It is designed as a building block that will enable businesses to quickly, easily and dynamically find and transact business with one another using their preferred applications. UDDI is the first cross-industry effort driven by platform and software providers, marketplace operators and e-business leaders. These technology and business pioneers are acting as the initial catalysts to quickly develop the UDDI standard. The UDDI standard takes advantage of WorldWide Web Consortium (W3C) and Internet Engineering Task Force (IETF) standards such as Extensible Markup Languare (XML), and HTTP and Domain Name System (DNS) protocols. Additionally, cross platform programming features are addressed by adopting early versions of the proposed Simple Object Access Protocol (SOAP) messaging specifications found at the W3C Web site. The UDDI standard is the building block that will enable businesses to quickly, easily and dynamically find and transact with one another using their preferred applications. Some details of the architecture and its rationale are provided in the technical white paper: "The core component of the UDDI project is the UDDI business registration, an XML file used to describe a business entity and its Web Services. Conceptually, the information provided in a UDDI business registration consists of three components: 'white pages' including address, contact, and known identifiers; 'yellow pages' including industrial categorizations based on standard taxonomies; and 'green pages', the technical information about services that are exposed by the business. Green pages include references to specifications for Web Services, as well as support for pointers to various file and URL based discovery mechanisms if required. . . Even when one considers XML and SOAP, there are still vast gaps through which any two companies can fall in implementing a communications infrastructure. As any industry pundit will tell you: 'What is required is a full end-to-end solution, based on standards that are universally supported on every computing platform.' Clearly, there is more work to do to achieve this goal. The UDDI specifications borrow the lesson learned from XML and SOAP to define a next-layer-up that lets two companies share a way to query each other's capabilities and to describe their own capabilities. The core information model used by the UDDI registries is defined in an XML schema. XML was chosen because it offers a platform-neutral view of data and allows hierarchical relationships to be described in a natural way. The emerging XML schema standard was chosen because of its support for rich data types as well as its ability to easily describe and validate information based on information models represented in schemas. The UDDI XML Schema defines three core types of information that provide the kinds of information that a technical person would need to know in order to use a partners Web Services. These are: business information; service information, binding information; and information about specifications for services." Key specifications published to date include (1) UDDI Programmer's API Specification and (2) UDDI XML Structure Reference. The UDDI Programmer's API is a "programmatic interface provided for interacting with systems that follow the Universal Description Discovery and Integration (UUDI) specifications make use of Extended Markup Language (XML) and a related technology called Simple Open Access Protocol (SOAP), which is a specification for using XML in simple message based exchanges." The UDDI Programmers API Specification [XML Structure Reference] defines approximately 30 SOAP messages that are used to perform inquiry and publishing functions against any UDDI compliant service registry. This document outlines the details of each of the XML structures associated with these messages." For other information, see (1) the UDDI Project web site and (2) "Universal Description, Discovery, and Integration (UDDI)." [September 06, 2000] Gemini Observatory Project Uses XML. Several XML DTDs and XML-based authoring tools have been created for use within the Gemini Observatory Project. The Gemini project is "a multi-national effort to build twin 8.1 meter astronomical telescopes utilizing new technology to produce some of the sharpest views of the universe ever. One telescope will be located atop Hawaii's Mauna Kea and the other atop Chile's Cerro Pachón - together they will provide complete unobstructed coverage of both the Northern and Southern skies. Gemini is an international partnership managed by the Association of Universities for Research in Astronomy under a cooperative agreement with the National Science Foundation." Background: "Most observatories follow a similar process for allocating telescope time that consists of a series of steps or phases. Astronomers describe a scientific problem and request facility access during Phase 1 of the process. Gemini needed a document format that would allow the partner countries to submit their Phase 1 proposals to Gemini. XML was designed to provide precisely the capabilities that are needed by the Gemini Phase 1 document, [so the DTD was drafted]. Gemini plans on using a similar XML document for its Phase II science program definition." The Phase1 DTD Distribution includes the main XML DTD and associated DTDs used in the current version of the Gemini Phase 1 Tool to generate Gemini Phase 1 proposals: (1) The 'AstronomyPhase1.dtd' provides the XML Document Type Declaration (DTD) that describes the set of proposals accepted by the Gemini Multi-Observatory Phase 1 Tool. It allows multiple observatories to add their own information to a proposal while sharing common information. An instance of this DTD is required as part of submitting a proposal to the Gemini 8-m Telescopes Project. This DTD is explained in Description of an XML-based Phase 1 Document. (2) The file 'AstronomyPhase1Data.xml' supports the common part of the Phase 1 proposal; included is the set of keywords and keyword categories, along with a list of sites/institutions. (3) The 'Gemini.dtd' file stores an XML DTD for the Gemini 8m Telescope extensions and constraints; it uses the information in the 'AstronomyPhase1.dtd'. . . Each proposal recommended for time is sent by the NTACs/NGOs to Gemini as an XML (eXtensible Markup Language) document consisting of attribute/value pairs that encode the proposal information (e.g. PI name, target co-ordinates, instrument resources, scientific case) and, if required, associated files with figures etc. The Gemini Phase I Tool (PIT) automatically generates the XML file. Partners who have chosen to use their own web-based or other proposal systems must translate their internal formats into the correct XML structures. The XML format is described in a document package and has been defined to be of generic use for observatories other than Gemini." For other references, see "Gemini Observatory Project." Related topics: (1) "NASA Goddard Astronomical Data Center (ADC) 'Scientific Dataset' XML"; (2) "Astronomical Instrument Markup Language (AIML)"; (3) "Astronomical Markup Language"; (4) "Spacecraft Markup Language (SML)"; (5) "Extensible Scientific Interchange Language (XSIL)." [September 06, 2000] Marine Trading Markup Language (MTML). The Marine Trading Markup Language (MTML), formalized in the MTML Document Type Definition, "is a standard to help a broad base of small, medium and large buyers and suppliers in the marine trading industry conduct their fundamental trading transactions electronically via the Internet." MTML.org is an organization "dedicated to accelerating marine trading via the Internet." The MTML.org website contains resources promoting the understanding and adoption of the MTML e-commerce standard. Drawing upon the International Marine Purchasing Association's (IMPA) Electronic Trading Standard Format (ETSF) EDIFACT messaging structure and the Extensible Markup Language (XML), [MTML.org has developed a program to] establish and promote a standard that will allow the broadest set of participants to electronically conduct marine trading via the Internet." Background and rationale: "MTML is compatible with the International Marine Purchasing Association's (IMPA) Electronic Trading Standard Format (ETSF) which was based on the UN/EDIFACT standard for electronic data interchange and has been specifically designed for electronic exchange of purchasing information in the marine industry. Like IMPA ETSF, MTML is comprehensive and complete, and tailored to address trading issues unique to the maritime industry. Ten alternative XML standards efforts were reviewed prior to the decision to go with an IMPA ETSF foundation. It is patently clear that, even in the more general standards efforts, no one has as yet done the hard, cross-industry work to create standards that will really support many industries. None of the reviewed standards addressed the breadth of transactions needed to fully support the marine trading process as business is conducted today. One effort, ebXML, is in it early stages, but promises to offer the greatest industry acceptance and consistency of approach with IMPA ETSF, since it is jointly sponsored by UN/CEFACT and OASIS. As an alternative, cross-industry XML standard emerges over the next few years, we will certainly move to replace MTML with that standard. While maximizing the advantages of its XML foundation, the content and format of MTML messages has been kept as close as possible to IMPA ETSF. Those companies already utilizing IMPA ETSF should find that adding support for MTML requires minimal rework to existing software packages. Marine shipping companies and their suppliers can utilize MTML right now to produce and accept requisitions, requests for quotes, quotations, orders and related interchanges using simple interfaces to their business systems." For further description and references, see: (1) the MTML.org web site and (2) "Marine Trading Markup Language (MTML)." [September 06, 2000] Partner Interface Processes for Energy (PIPE) Version 3.0. In August 2000, the XML-based PIPE Specification was updated to version 3.0 and posted to XML-PIPE.org; a full set of XML sample files and W3C XML schemas now support this specification. PIPE (Partner Interface Processes for Energy) "is a set of XML documents with supporting schemas designed for electronic business to business (B2B) transactions." The PIPE specification documents have been developed by sponsor members of XML-PIPE.ORG (currently Keane, PricewaterhouseCoopers, and Excelergy), which is a "member sponsored organization established to further the development and acceptance of PIPE in the retail energy industry." Background: "Many states have followed the lead of Pennsylvania and adopted EDI (Electronic Data Interchange), a set of electronic business transactions (EBTs) developed by the Utility Industry Group (UIG) and other participating standards groups. While EDI has worked effectively to date, the costs associated with implementing, supporting, and transmitting EDI have proven to be expensive when compared with the promises of XML based PIPE. Trading partners and others need a common set of B2B transactions using a common set of schemas to send, receive, and process transactions efficiently. PIPE contains many common transaction schemas necessary to perform these electronic business transactions (EBTs). Trading partners in the deregulated energy industry who would benefit from the use of PIPE include: (1) LDCs [Local Distribution Companies]; (2) ESPs [Energy Service Providers]; (3) MSPs [Meter Service Providers]; (4) MDMA [Meter Data Management Agents]. XML-PIPE.ORG will enlist interested stakeholders in the retail energy industry to: (1) facilitate PIPE's momentum by developing and testing all necessary XML based B2B transaction sets for the retail energy sector; (2) promote the use of XML and PIPE as a necessary, efficient, and cost effective standard for industry stakeholders; (3) work with state utility commissions and their 'standards advisory groups' to approve and support PIPE standards for trading partners; (4) establish a working group to maintain the PIPE standards as necessary to ensure that PIPE's structures and schemas continue to meet the needs of all its trading partners." The 'PIPE Framework' package in the XML-PIPE.ORG library contains the schemas, XML sample files and transaction descriptions. Use the tree structure to view the individual Partner Interface Process (PIP) transaction components. The 'PIPE Download' contains the PIPE download including detailed information about the PIPE framework, schemas and sample XML files. The XML for Retail Energy Transactions white paper introduces a framework of business-to-business (B2B) electronic transactions using XML in the deregulated retail energy industry. It was first published in November of 1999. The Appendix has been updated as of August 2000 to reflect the evolution of the PIPE framework since the initial white paper release." For other references and description, see "Partner Interface Process for Energy (PIPE)." [September 05, 2000] Open Healthcare Group Announces XChart. A communiqué from Jonathan Borden on behalf of the Open Healthcare Group announces 'XChart' -- an XML-based open source electronic healthcare system. The Open Healthcare Group Community is composed of medical and technology professionals collaborating on technology standards "to make the healthcare system better and more efficient." The Open Healthcare Group's XChart Project is described as "a movement to create an electronic medical record that is easier than paper. XChart is a system designed to combine the ease, speed and portability of paper systems with the efficiencies of computerized records. XChart is browsable via the web with minimal training. XChart supports standards. The Open Healthcare Group has selected XML as a basis for the XChart repository because: (1) It is becoming ubiquitous. (2) It is easy to use. (3) It is portable across operating systems and languages [well specified hence allowing future generations to read documents created today; available on nearly every platform in existence with open source parsers available in nearly every language; has a well defined EBNF specification]. (4) XML can be transformed via XSLT into many presentation formats including HTML for rendering within browsers and WML for wireless devices. Using XML, a portable and ubiquitous information system can be created." XChart will be intuitive and will operate across a wide range of devices including desktop machines, laptops, and handheld wireless devices. XChart has been designed around RDF to allow intelligent agents to operate on the repository, enabling the next generation of medical research. Because the information is stored as native XML, it is independent of the particular operating system and software implementation. This strategy supports the goal of supporting a universal, long lasting, indexed, searchable electronic medical record. The team is also in the process of developing a grove system to enable XML based processing of XML as well as other information standards such as MIME, EDI and traditional HL-7. A demonstration of a Java Servlet/XSLT based system which creates operative reports is now available. The servlet implementation uses the XMTP technique of transforming the source MIME request into an XML represention. Technical information on the system design is available in a background paper. For example, the team has "developed techniques to interoperate with traditional (SQL) database systems which have been used in the initial implemention, now in clinical use. They are currently in the process of transforming this system into a fully native XML system and have developed techniques to edit XML files as if they were SQL tables. The operative note generator has been tested against Saxon, XT, Xalan and MSXML XSLT processors." The Open Healthcare Group development team will also be releasing a number of specifications and software projects which serve as a basis for the XChart project. Members of the Open Healthcare Group "are actively seeking collaborators in the medical, open source and XML communities for the XChart project." For additional information, see the Open Healthcare Group Web site and the reference document "Open Healthcare Group 'XChart'." For related research and development, see: (1) "ISIS European XML/EDI Healthcare Pilot Project (XMLEPR)"; (2) "DocScope: Open Source XML Healthcare Project"; (3) "Health Level Seven XML Patient Record Architecture (PRA)"; (4) "ASTM XML Document Type Definitions (DTDs) for Health Care"; (5) "The CISTERN Project - Standard XML Templates for Healthcare." [September 01, 2000] W3C Publishes First Public Working Draft of DOM Level 3. Philippe Le Hégaret (W3C, DOM Activity Lead) announced the publication of a first public Working Draft specification for W3C DOM Level 3. The DOM specification has been separated in several documents -- one module per document. The specification has been produced by members of the DOM working group as part of the W3C DOM Activity. Comments may be sent to the public mailing list, which is archived. (1) Document Object Model (DOM) Level 3 Core Specification Version 1.0 [W3C Working Draft 01-September-2000], edited by Arnaud Le Hors (IBM). "This specification defines the Document Object Model Core Level 3, a platform- and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure and style of documents. The Document Object Model Core Level 3 builds on the Document Object Model Core Level 2." Also: PDF, PostScript, and HTML/XML in .ZIP. (2) Document Object Model (DOM) Level 3 Events Specification Version 1.0 [W3C Working Draft 01-September-2000], edited by Philippe Le Hégaret (W3C) and Tom Pixley (Netscape Communications Corporation). "It defines the Document Object Model Events Level 3, a platform- and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure and style of documents. The Document Object Model Events Level 3 builds on the Document Object Model Events Level 2. . . The goal of the DOM Level 3 Events specification is to expand upon the functionality specified in the DOM Level 2 Event Specification. The specification does this by adding new interfaces which are complimentary to the interfaces defined in the DOM Level 2 Event Specification as well as adding new event sets to those already defined. This specification requires the previously designed interfaces in order to be functional. It is not designed to be standalone. These interfaces are not designed to supercede the interfaces already provided but instead to add to the functionality contained within them." Also: PDF, PostScript, and HTML/XML in .ZIP. (3) Document Object Model (DOM) Level 3 Content Models and Load and Save Specification Version 1.0 [W3C Working Draft 01-September-2000], edited by Ben Chang (Oracle), Andy Heninger (IBM), and Joe Kesselman (IBM). "This specification defines the Document Object Model Content Models and Load and Save Level 3, a platform- and language-neutral interface that allows programs and scripts to dynamically access and update the content, structure and style of documents. The Document Object Model Content Models and Load and Save Level 3 builds on the Document Object Model Core Level 3." Also: PostScript, PDF, and HTML/XML in .ZIP. See: "W3C Document Object Model (DOM)." [September 01, 2000] IDOOX Smart Transcoder and Updated Zvon Resources. Miloslav Nic recently announced the availability of several new and updated XML resources from Zvon/IDOOX. (1) IDOOX Smart Transcoder is "an integrated framework for information processing that can be seamlessly incorporated into existing architectures. The new product combines the power of XML with distributed computing, creating a strong foundation for network-based applications (peer-to-peer networks, web portals, publishing). Its main features: works with both XML and non-XML formats (HTML, graphical formats, ...), processing instructions given by XSLT, Java, CC++, ..., modular processing based on SAX events, individual processing steps can be arbitrarily chained, processes data according to user-defined rules, rule-based processing can exploit features of XML Schema types, inheritance, ...) and/or DTD, simple integration of external resources (databases, servers, ...), graphical administration console, SOAP interface, implemented in CC++, optional seamless Java integration, tested on Linux and Microsoft Windows 2000. Smart Transcoder will provide open-source code." (2) The Zvon Soap 1.1 reference provides linked hypertext access to SOAP elements, faults, and types; it is crosslinked with the W3C NOTE [Simple Object Access Protocol (SOAP) 1.1 specification] and W3C draft for XML Schema Part 2: Datatypes; types are provided examples. (3) A reference resource for numeric representation of dates and times, based on the International Standard ISO 8601: Data elements and interchange formats. (4) XSLT, CSS and Regular expressions references have now a searchable interface; these tools may be downloaded and used from your own computer. (5) Also, the IdooXoap sources have now been released: IdooXoap is a Java implementation of a SOAP library, compatible (in supported features) with MS and Apache implementations. The sources are under a BSD-style licence, and efforts are underway to coordinate with the Apache group. See the Zvon.org Web site for tutorials, references (XSLT, XUL, SOAP, CSS), and other XML-related tools. [September 01, 2000] Relaxer Generates Java Classes from RELAX Modules. Murata Makoto (IBM, Tokyo Research Laboratory) recently posted a reference for a tutorial and presentation on 'Relaxer' given at the Montréal Extreme Markup Languages Conference 2000. Relaxer has been designed and develped by Asami-san [ASAMI Tomoharu]. RELAX (REgular LAnguage description for XML) is a namespace-aware specification for describing XML-based languages which borrows rich datatypes from XML Schema Part 2; the RELAX grammar can be written as an XML document. Relaxer is the Java class generator that addresses a XML document complied with the XML model defined by RELAX. According to the published abstract for "Relaxer: Java classes from RELAX modules": "Relaxer is a Java program that generates Java classes from RELAX modules: XML documents valid against a RELAX module can be handled by the Java classes generated from that RELAX module. Relaxer liberates programmers from tedious work: (1) Variables in generated classes have programmer-friendly names, since they are borrowed from RELAX modules; (2) Datatypes specified in RELAX modules are used as datatypes of Java variables; (3) Convenient methods such as reader/writer for XML documents and access function are generated; and, (4) Functions for design patterns 'factory', 'composite' and 'visitor' are generated. Unlike other Java class generators or XML-Java mapping tools, Relaxer supports all features of RELAX Core including mixed content models, element content models, and standard attributes such as xml:lang, xml:space and xml:base. Relaxer has been extensively used by some early adopters, and has received very positive feedback." The Relaxer Tutorial and Relaxer slide presentation are available online. See also the posting on XMLHACK. Note also in this connection that the RELAX Verifier for Java has been updated. The RELAX Verifier can validate XML document against RELAX grammar, reporting errors in XML documents and their locations; it can be used both from an application and command-line. Recent changes: (1) RELAX Verifier is now capable of generating validation record (role,label, and datatype information); (2) Some methods/members are renamed according to Java fashion; (3) The DOMVerifier class as a separate class is obsoleted; it is re-written by using DOM2SAXFilter class; (4) The Filter mechanism is rewritten by using ForkDocumentHandler. For related description and resources, see (1) the RELAX Web site and "REgular LAnguage description for XML (RELAX)." [August 31, 2000] Revised Submission for OMG XMLDOM: A DOM-Based XML/Value Mapping. As part of the standardization effort for OMG IDL representation of XML documents, several companies have released a joint submission specifying XMLDOM: A DOM/Value Mapping. This revised submission provides a specification for DOM-based XML/Value Mapping [XMLDOM], in response to the ORBOS RFP - XML/Value Mapping. The relevant OMG XML/Value RFP requests a "standard way to represent XML documents using OMG IDL data types -- primitive data types, constructed data types (structs, sequence, unions), and value types." The joint submission has been provided by: BEA Systems, Cape Clear Software Ltd, Hewlett-Packard Company, International Business Machines Corporation, IONA Technologies PLC, Oracle Corporation, PeerLogic, Inc., Persistence Software, Rogue Wave Software, and Unisys Corporation. The RFP requests "a standard way to represent XML values (documents) using OMG IDL non-object (value) types." This response provides an XML to IDL mapping leveraging the Document Object Model (DOM) technical recommendation from the World Wide Web Consortium (W3C). The DOM is an extensively used standard mechanism for defining access to XML content. The DOM includes a set of interfaces defined in IDL with mappings to Java and C++. The purpose here is to enable IDL users to access XML content using IDL valuetypes while maintaining maximum DOM compatibility. To this end, DOM level 1 and level 2 interfaces are re-declared as IDL valuetypes instead of the IDL interfaces in the DOM standard. The RFP does not request a mapping from IDL to XML. Mapping from IDL to XML is already accomplished using the MOF and XMI OMG standards." The new submission "provides two essential scenarios for using XML to create IDL valuetypes. The first scenario, where dynamic information is present, leverages existing standards to provide access to the full contents of an XML document in terms of IDL valuetypes. The second scenario builds upon the first where additional static information is present from XML DTDs and (in the future) XML Schemas. The DTDs / Schemas are metadata used to generate Valuetypes that match the types of information expected to be present in XML documents. The metadata from the DTDs / Schemas and Valuetypes may be imported into CORBA Interface Repositories and the Meta Object Facility, providing wide metadata distribution through OMG standards. The dynamic information scenario is the processing of an XML document when the meaning of the XML elements found in the document is not defined. In this case, only minimal information is known - what is in the XML document and little else. The DOM is a standard representation for the complete contents of an XML document. The DOM satisfies the requirement of the W3C XML Information Set (Infoset) to provide an access mechanism to the document contents. By expressing the DOM in terms of IDL valuetypes, a CORBA implementation has practical, standardized, and direct access the full information in of the XML document." For further description and references, see (1) the extended abstract and (2) "Object Management Group XML/Value RFP". [August 31, 2000] DocBook XML Version 4.1.2 Released. Norman Walsh (Chair, DocBook Technical Committee) recently announced the release of the DocBook XML DTD Version 4.1.2 (27-Aug-2000). Version 4.1.2, principally a maintenance release, is the current XML version of DocBook; The XML DTD has been in development beginning with version 4.0. The EBNF Module is an extension to DocBook XML V4.1.2; it adds support for EBNF (extended Backus-Naur form) diagrams. Other extensions: the MathML Module adds support for MathML in equation markup; the HTML Forms Module adds support for HTML Forms markup. DocBook "is a DTD maintained by the DocBook Technical Committee of OASIS. It is particularly well suited to books and papers about computer hardware and software, though it is by no means limited to these applications. The DocBook Technical Committee maintains both SGML and XML versions of the DocBook DTD. To the extent that it is practical, these DTDs are identical. There is no intentional difference between the DTDs, they are supposed to accept the same set of documents. Because it is a large and robust DTD, and because its main structures correspond to the general notion of what constitutes a 'book,' DocBook has been adopted by a large and growing community of authors writing books of all kinds. DocBook is supported 'out of the box' by a number of commercial tools, and there is rapidly expanding support for it in a number of free software environments. These features have combined to make DocBook a generally easy to understand, widely useful, and very popular DTD. Dozens of organizations are using DocBook for millions of pages of documentation, in various print and online formats, worldwide." DocBook: The Definitive Guide (Norman Walsh) provides a complete resource for understanding and implementing the DocBook DTD. For other references, see (1) the DocBook FAQ and (2) "DocBook XML DTD." [August 31, 2000] Polymorphic XML Parser (PXP) Released. A communiqué from Gerd Stolpmann (Darmstadt, Germany) reports on the new release of a validating XML parser called PXP, or 'Polymorphic XML Parser'. A pre-release version was called 'Markup'. Gerd writes: "PXP is the XML parser of choice for Objective Caml, a modern programming language developed by the French institute INRIA. PXP is not only a full-featured validating XML parser; it is also fast and reliable . . . The parser is polymorphic, and besides the programming language this is the main difference to other parsers. 'Polymorphic' means that the type of nodes can be customized by the using application, and the parser even allows it to generate trees in which different element types are represented by different classes... For PXP I have chosen the luxury representation as object tree, in which every XML node is stored as two objects. One object contains the set of methods describing the fixed properties of every node; the other object is called the extension object and can be configured by the user of the parser. The extension object is the polymorphic part of the representation. The type of the class may be arbitrary (except three base methods which connect the object to the tree), and the parser has a mechanism to dynamically select the class of the object depending on the element type of the XML node. The parser has been written in the programming language Objective Caml, as this is a stable, fast and expressive programming environment. It is addressed to researchers who are already working with Objective Caml as well as at interested industrial developers...The xduce project already uses a pre-release version of PXP for its XML transformation language [XDuce is a typed programming language that is specifically designed for processing XML data]. The PXP software and documentation can be freely downloaded from the homepage; PXP is covered by a BSD-like open source license." For related tools, see (1) the parser list in the 'Free XML Tools' document maintained by Lars Marius Garshol; this 'parser' list covers Architectural forms engines, DOM implementations, DSSSL engines, RDF parsers, SGML/XML parsers, XLink/XPointer engines, XML middleware, XML parsers, XML validators (software for validating XML documents by other means than DTDs), XSL engines, XSLT engines, etc. and (2) "XML Parsers and Parsing Toolkits." [August 30, 2000] DIG35 Metadata Specification Released. A recent announcement from the Digital Imaging Group describes the completion of the 'DIG35' Digital Imaging Metadata Standard, together with its specified XML encoding. Excerpt: "The Digital Imaging Group (DIG) today released the final DIG35 Metadata Specification providing a cohesive and consistent set of metadata definitions to the imaging industry. DIG35 provides the first persistent way for digital images to become rich, completely self-contained sources of information, regardless of where they travel on the global network. With millions of digital images now produced yearly, this capability is critical for enabling users to effectively organize, find, retrieve and share their images instantly. The specification also includes a reference encoding method using the current industry standard language XML. Using the XML DTD and schema provided, developers can easily implement the DIG35 Metadata Specification in their own imaging applications. Additionally, DIG35 can be used as a single standard interchange format between existing applications that each use different proprietary metadata formats, allowing users to greatly extend and leverage their existing intellectual capital investments. The DIG35 Metadata Specification has been reviewed by the public, by several universities, and by organizations such as the National Information Standards Organization (NISO) and the International Organization for Standardization (ISO) JPEG2000 Working Group. The relevant portions of the specification have been submitted to the JPEG2000 file format subgroup and have been incorporated into the JPEG2000 Part 2 specification committee draft. The DIG35 Metadata Specification, including the XML DTD and schema, is available today for public download on the DIG Web site. . . Businesses, professionals and consumers can all utilize metadata in order to manage images. For example, e-commerce businesses can manage and utilize their assets more effectively and efficiently by simply being able to quickly retrieve the right image for any given purpose. Instead of spending valuable time painstakingly looking at each image file to determine the content, businesses can search by any associated metadata to locate an image and read the descriptive elements. By using XML as the recommended encoding method, DIG35 is Internet ready and easy to implement on e-commerce sites. Professional photographers can associate information about camera settings, copyright information and image manipulation techniques within the image in order to recreate images and recap their work. Additionally, consumers can easily share their captured experiences by using metadata to tell the story or narration behind their images. For example, they can use image-editing software on their PC to add explanatory captions to each photo from their vacation in China, and then upload those photos to a photo sharing Web site. The DIG35 enabled photo Web site would understand and save all the captions, freeing the user from having to input the information a second time. Friends and family around the globe can then not only see the pictures, but also experience the entire story and history behind them in the storyteller's absence." Composed of 'approximately 80 member companies, the DIG is a consortium engaged in the development and introduction of innovative digital imaging standards and technologies.' See the full text of the announcement, "Digital Imaging Group (DIG) Announces the Completion of DIG35, the Digital Imaging Metadata Standard. New Specification Available for Public Download on DIG Web Site For Developers of Imaging Products and Services." For other references, see "DIG35: Metadata Standard for Digital Images." [August 30, 2000] The CISTERN Project - Standard XML Templates for Healthcare. CISTERN (Clinical Information Systems Interoperability Network) is a multi-vendor initiative to define and demonstrate XML-based methods for exchanging healthcare data securely between applications using the Internet. CISTERN is neutral forum for HIS vendors, consultants, and users organized to hammer out real-world data exchange standards. CISTERN grew out of the experiences of Killdara and other vendors participating in the HL7 interoperability demonstration at the HIMSS conference in April, 2000. A number of XML DTDs have been proposed, and several have now been drafted: order request message. order response message, admit/visit notification, transfer a patient, discharge/end visit, register a patient, pre-admit a patient, update patient information, cancel admit/visit notification, unsolicited transmission of an observation message, query for results of observation, response to query, post detail financial transaction, etc. Model development: "Development of a coherent set of messages from the Information Model requires a process for mapping the structure and content of the Information Model to the syntax of the messages. This was started in IEEE P1157, has been advanced by the work of CEN TC251 and is being adopted by the HL7 committee for development of their future messaging standards. HL7 Version 3.0 will be based upon an explicit object-oriented information model. Killdara's approach is to use an Object Oriented Design complemented by a message profile, which is based on business logic, and use case modeling. Our goal is to provide a balance between specificity and flexibility of messaging with deliverables being: (1) use case model, (2) dynamic definition (sequence diagram, ASN.1 dynamic profile identifier), (3) static definition (message profiles, segment profiles, ASN.1 static profile identifier, and user friendly XML DTDs). In order to accomplish this we have drawn upon the work done by the Andover Working Group (AWG) now the HL7 Conformance SIG, The Specification for Message profile Content V2.1 March 9, 2000, and when needing further clarification the HL7 Standard documentation." Background: "Hospitals, labs, and physician offices currently exchange vast amounts of complex patient information - by fax, phone and courier. It is notoriously difficult and expensive to integrate different healthcare information systems (HIS). XML, PKI and the Internet are seen as the way forward, but there is no accepted set of DTDs for healthcare documents such as admissions, discharge, transfers, lab results and so on." For references, see "The CISTERN Project - Standard XML Templates for Healthcare." For related research and development, see: (1) "ISIS European XML/EDI Healthcare Pilot Project (XMLEPR)"; (2) "DocScope: Open Source XML Healthcare Project"; (3) "Health Level Seven XML Patient Record Architecture (PRA)"; (4) "ASTM XML Document Type Definitions (DTDs) for Health Care." [August 29, 2000] Encoded Archival Description (EAD) Project News. Timothy Young (Archivist, Beinecke Rare Book and Manuscript Library, Yale University) recently announced updates to the EAD Help Pages at the University of Virginia. The UVA web site, sponsored by the EAD Round Table of the Society of American Archivists, "now offers extended help for EAD implementation in the form of an XML FAQ written by David Ruddy of Cornell University Library and the EAD COOKBOOK from Michael J. Fox of the Minnesota Historical Society. The XML in EAD page covers many of the frequently asked questions about how XML differs from SGML and what steps should be taken to easily work with the XML version of the EAD.DTD. The new EAD COOKBOOK is a guide to implementing EAD, using an example finding aid, complete with several style sheets and auxiliary files to take advantage of some of the most used XML software. The EAD COOKBOOK is intended to be downloaded in its entirety, so there are two versions available: one in Word 95 format, another as a PDF file - for Adobe Acrobat Reader." The EAD Document Type Definition (DTD) is "a standard for encoding archival finding aids using the Standard Generalized Markup Language (SGML) and Extensible Markup Language (XML). The standard is maintained in the Network Development and MARC Standards Office of the Library of Congress (LC) in partnership with the Society of American Archivists. The Encoded Archival Description standard is now used widely in academic institutions, museums, public libraries, and government projects. For example, Elizabeth Perkes (Electronic Records Archivist, Utah State Archives) recently reported that the Utah State Archives and Records Service just completed its EAD/XML conversion project. Some 614 legacy finding aids for series inventories and 125 agency histories are publicly accessible. A description of the conversion/encoding methodology is available online, as are the encoded finding aids records. For other references, see "Encoded Archival Description (EAD)." [August 29, 2000] XHTML Events - An Events Syntax for XHTML. The W3C HTML Working Group has issued a second public working draft specification for XHTML Events - An updated events syntax for XHTML. Reference: W3C Working Draft 28-August-2000, edited by Ted Wugofski. Document abstract: "This specification defines the XHTML Event Module, a module that provides XHTML host languages with the ability to uniformly integrate behaviors with Document Object Model (DOM) Level 2 event interfaces. This specification also defines the XHTML Basic Event Module, a module which subsets the XHTML Event Module for simpler applications and simpler client devices, and the XHTML Event Types Module, a module defining XHTML language event types. The DOM specifies an event model that provides the following features: (1) the event system is generic, (2) a means is provided for registering event handlers, (3) events may be routed through a tree structure, and (4) context information for each event is available. In addition, the DOM provides an event flow architecture that describes how events are captured, bubbled, and canceled. In summary, event flow is the process through which an event originates from the DOM implementation and is passed into the document object model. The methods of event capture and event bubbling, along with various event listener registration techniques, allow the event to then be handled in a number of ways. It can be handled locally at the target node level or centrally from a node higher in the document tree. The XHTML Event Module contains an onevent element is used to represent the DOM event listener. As with the DOM Level 2 event interfaces, the XHTML Event Module provides a means for authors to listen to events during the capturing and bubbling phases, as well as when an event reaches its target node." [August 28, 2000] Open Digital Rights Language (ODRL). A communiqué from Renato Iannella (Chief Scientist, IPR Systems Pty Ltd) announces the development of a digital rights language which "provides the semantics for digital rights management (DRM) in open and trusted environments whilst being agnostic to mechanisms to achieve the secure architectures." He writes: "We have been developing a digital rights language called the 'Open Digital Rights Language' (ODRL) and are making it available (as a work-in-progress) for comment to the wider community. Version 0.5 of ODRL is available from http://purl.net/ODRL/. We also see ODRL as input and discussion for an upcoming W3C Workshop on rights management (to be formally announced soon). All comments, contributions, and feedback welcome." The authors of the draft document "consider that traditional DRM (even though it is still a new discipline) has taken a closed approach to solving problems. Hence, [they] see a movement towards 'Open Digital Rights Management' (ODRM) with clear principles focused on interoperability across multiple sectors and support for fair-use doctrines." The ODRL "is a standard vocabulary for the expression of terms and conditions over assets. ODRL covers a core set of semantics for these purposes including the rights holders and the expression of permissible usages for asset manifestations. The ODRL is positioned to be extended by different sectors (e.g., ebooks, music, software) and be a core interoperability language. The ODRL complements existing analogue rights management standards by providing digital equivalents, and supports an expandible range of new services that can be afforded by the digital nature of the assets in the Web environment. ODRL is focused on the semantics of expressing rights languages. ODRL can be used within trusted or untrusted systems. However, ODRL does not determine the capabilities nor requirements of any trusted services (e.g. for content protection and payment negotiation) that utilises its language." ODRL specifies an XML binding and is expected to be utilized within open and trusted environments. As outlined in the draft specification, various models in the architecture (ODRL Foundation Model, ODRL Usage Model, ODRL Administration Model) are expressed in XML notation; appendices A and B of the revised specification are to provide the XML DTDs and XML schema. ODRL defines [only] "a core set of semantics. Additional semantics can be layered on top of ODRL for third-party value added services. ODRL does not enforce or mandate any policies for DRM, but provides the mechanisms to express such policies. Communities or organisations, that establish such policies based on ODRL, do so based on their specific business or public access requirements. The ODRL model is based on an analysis and survey of sector specific requirements (models and semantics), and as such, aims to be compatible with a broad community base." The proposed ODRM Framework "would consist of Technical, Social, and Legal streams and would 'plug into' an open framework that enables peer-to-peer interoperability for DRM services. The ODRM Technical stream consists of an Architecture (ODRA), Trading Protocol (ODRT) and Protection (ODRP) mechanisms with ODRL clearly focused on solving a common and extendable way of expressing Rights within this Architecture." See further references in "Open Digital Rights Language (ODRL)." For other DRM designs using XML, see (1) "Extensible Rights Markup Language (XrML)" and (2) "Digital Property Rights Language (DPRL)." [August 28, 2000] XSLT Version 1.1 Requirements Specification. Vincent Quint (W3C/INRIA) recently posted an announcement for the first public release of a new requirements document for XSLT version 1.1: "The W3C Working Group on XSL has just released a document describing the requirements for the XSLT 1.1 specification. The primary goal of the XSLT 1.1 specification is to improve stylesheet portability. The new draft is available at http://www.w3.org/TR/xslt11req. Discussion is invited and comments can be sent to the editors." See XSL Transformations Requirements Version 1.1, W3C Working Draft 25-August-2000, edited by Steve Muench. Description: "In addition to supporting user-defined extensions, numerous XSLT 1.0-compliant processors have exploited the XSLT 1.0 extension mechanism to provide additional built-in transformation functionality. As useful built-in extensions have emerged, users have embraced them and have begun to rely on them. However the benefits of these extensions come at the price of portability. Since XSLT 1.0 provides no details or guidance on the implementation of extensions, today any user-written or built-in extensions are inevitably tied to a single XSLT processor. The XSLT user community has consistently voiced the opinion that the non-portability of stylesheets is a key problem. The primary goal of the XSLT 1.1 specification is to improve stylesheet portability. This goal will be achieved by standardizing the mechanism for implementing extension functions, and by including into the core XSLT specification two of the built-in extensions that many existing vendors XSLT processors have added due to user demand: (1) Support for multiple output documents from a transformation (2) Support for converting a result tree fragment to a nodeset for further processing By standardizing these extension-related aspects which multiple vendor implementations already provide, the ability to create stylesheets that work across multiple XSLT processors should improve dramatically. A secondary goal of the XSLT 1.1 specification is to support the new XML Base specification. This document provides the requirements that will achieve these goals. The working group has decided to limit the scope of XSLT 1.1 to the standardization of features already implemented in several XSLT 1.0 processors, and concentrate first on standardizing the implementation of extension functions. Standardization of extension elements and support for new XML Schema data type aware facilities are planned for XSLT 2.0." [August 28, 2000] XML-PC (SOAP) and OMG Corba Integration. A posting from Anders W. Tell (Financial Toolsmiths AB) describes ongoing effort toward adapting SOAP to work with Corba messaging and ObjectModel: "We are hard at work writing the specification, but not ready to release it yet; we should be able to release working documents within a couple of weeks, tops. Otherwise we plan to discuss SOAP 1.1 or XML-PC to OMG Corba integration in the following egroup list: http://www.egroups.com/group/xmlpc-corba. This group is intended to host development and usage discussions before and after OMG has started its standardization process through the issuing of an RFP and following submissions. The list also may hosts discussions relating to fortcomming W3C's XML-PC activities. I have also created the 'outline' for a FAQ document at http://www.toolsmiths.se/xml/corba/xmlpc-corba-faq.html. Another idea is to contribute code to Apache XML codebase in order to make it easier to use Corba encodingStyle." See "Object Management Group Readies Standards Upgrades," by Tom Sullivan, in InfoWorld (August 24, 2000). For other details, see Eegroups 'xmlpc-corba' mailing list. For other references to XML-Corba and the Object Management Group (OMG), see (1) "XML and CORBA" and (2) "Object Management Group (OMG) and XML Metadata Interchange Format (XMI)." [August 23, 2000] Open Archives Metadata Set (OAMS). The 'Open Archives Metadata Set' describes a collection of metadata elements used in the Santa Fe Convention. The Santa Fe Convention [Santa Fe, New Mexico, October 21-22, 1999], adapted for use by the Open Archives Initiative "presents a technical and organizational framework designed to facilitate the discovery of content stored in distributed e-print archives. It makes easy-to-implement technical recommendations for archives that will allow data from e-print archives to become widely available via its inclusion in a variety of end-user services such as search engines, recommendation services and systems for interlinking documents. The Open Archives Initiative aims to support archives, both those focused on e-prints (e.g., preprints and reprints, often connected with journals and conferences) and those representing a wide variety of other content types (e.g., theses and dissertations, Web log files, and educational resources). The emphasis has been on allowing harvesting of metadata that describes diverse "records" of content, stored in managed repositories. As of June 2000, there were six (6) conforming archives with content available for harvesting." XML is used as the transfer syntax for the Open Archives Metadata Set, per a consensus agreement in the Santa Fe meeting that the participants "would use a common syntax, XML, for representing and transporting both the OAMS and archive-specific metadata sets." The semantics of the Open Archives Metadata Set "has purposely been kept simple in the interest of easy creation and widest applicability. The expectation is that individual archives will maintain metadata with more expressive semantics and the Open Archives Dienst Subset provides the mechanism for retrieval of this richer metadata." A number of different metadata formats are used by data providers in the context of the Open Archives Initiative. For example, the Virginia Tech Digital Library Research Laboratory "has undertaken to create an XML DTD to support wider distribution of MARC records within the Open Archives community." [The researchers now] provide a freely available set of Java classes to handle translations between MARC tape format and OAi XML. The design providea two layers of classes: a MarcRecord class that can read and write both MARC tape format and the OAi MARC XML format, and a MarcDocument subclass that can provide additional translations, for instance to Open Archives Metadata Standard (OAMS) records and to pretty-printing HTML. As of 4-July-2000, the Java MarcRecord object can read and write both MARC tape format and OAi MARC XML. The program has been tested on over 4,000 MARC records, moving from tape format to XML and back to tape format without losing a character. The MarcDocument object can now produce short and long description in ASCII or ANSEL, long descriptions in HTML, and something approximating OAMS metadata records in the XML transport defined in the Santa Fe Convention." See description in "MARC as an Open Archives Metadata Standard." Similarly, an XML DTD has been prepared to represent the elements of the RFC 1807 Metadata Set (Format for Bibliographic Records). Another XML DTD has been constructed for the Dublin Core Metadata Set. See further references for the Open Archives project in "Open Archives Metadata Set (OAMS)." [August 22, 2000] FpML Architecture 1.0 Working Draft Advanced to Last Call. A communiqué from Cathy S. Yesenosky announces that the Financial Products Markup Language (FpML) Architecture document is now in last call review. Members and Working Groups of the FpML Consortium and other interested parties released the FpML specifications as working drafts July, 2000. The principal FpML Version 1.0 Specifiction (together with the FpML XML DTD) is currently in a last call review phase which ends on 25-August-2000. FpML (Financial Products Markup Language) "is a business information exchange standard for electronic dealing and processing of financial derivatives instruments. It establishes a new protocol for sharing information on, and dealing in, financial derivatives over the Internet. It is based on XML (Extensible Markup Language) and initially focuses on interest rate swaps and Forward Rate Agreements (FRAs). FpML has been designed to be modular, easy-to-use and in particular intelligible to practitioners in the financial industry. Ultimately, it will allow for the electronic integration of a range of services, from Internet-based electronic dealing and confirmations to the risk analysis of client portfolios. It is expected to become the standard for the derivatives industry in the rapidly growing field of electronic commerce. The standard, which will be freely licensed, is intended to automate the flow of information across the entire derivatives partner and client network, independent of the underlying software or hardware infrastructure supporting the activities related to these transactions." The announcement says: "the FpML Architecture Version 1.0 Working Draft has been advanced to the Last Call stage. The Last Call period is expected to end September 1, 2000. We encourage interested parties to provide comments on the specification as soon as possible. Please send comments via email to [email protected]. Please report each issue in a separate email message. An archive of the comments is available at: http://www.egroups.com/messages/fpml-issues. An issues list is also maintained on the web site. The FpML specifications are available at http://www.fpml.org/spec/. For description and references, see "Financial Products Markup Language (FpML)." [August 21, 2000] W3C XForms Working Group Publishes XForms Requirements Specification. Members of the W3C XForms working group have released a working draft document specifying the XForms Requirements. Reference: W3C Working Draft 21-August-2000, edited by Micah Dubinko (Cardiff), Sebastian Schnitzenbaumer (Mozquito Technologies), Malte Wedel (Mozquito Technologies), and Dave Raggett (W3C/HP). This document has been produced as part of the W3C work on XForms. "Forms were introduced into HTML in 1993. Since then they have gone on to become a critical part of the Web. The existing mechanisms in HTML for forms are now outdated, and W3C has started work on developing an effective replacement. This document outlines the requirements for 'XForms', W3C's name for the next generation of Web forms. After careful consideration, the HTML Working Group decided that the goals for the next generation of forms are incompatible with preserving full backwards compatibility with browsers designed for earlier versions of HTML. A forms sub-group was formed within the HTML Working Group, later becoming the XForms Working Group. It is our objective to provide a clean new forms model ('XForms') based on a set of well-defined requirements. The requirements described in this document are based on experience with a broad spectrum of form applications. This document provides a comprehensive set of requirements for the W3C's work on XForms. We envisage this work being conducted in several steps, starting with the development of a core forms module, followed by work on additional modules for specific features. The Modularization of XHTML provides a mechanism for defining modules which can be recombined as appropriate for the capabilities of different platforms." See: "XML and Forms." [cache] [August 15, 2000] W3C Publishes Working Draft for XML Query Requirements. The W3C XML Query Working Group has published a revised working draft specification for XML Query Requirements. Reference: W3C Working Draft 15-August-2000, edited by Don Chamberlin (IBM Almaden Research Center), Peter Fankhauser (GMD-IPSI), Massimo Marchiori (W3C/MIT/UNIVE), and Jonathan Robie (Software AG). The document "specifies goals, requirements, and usage scenarios for the W3C XML Query data model, algebra, and query language." The goal of the XML Query Working Group is "to produce a data model for XML documents, a set of query operators on that data model, and a query language based on these query operators. The data model will be based on the W3C XML Infoset, and will include support for Namespaces. Queries operate on single documents or fixed collections of documents. They can select whole documents or subtrees of documents that match conditions defined on document content and structure, and can construct new documents based on what is selected." The working draft outlines several usage scenarios which are "intended to be used as design cases during the development of XML Query, and should be reviewed when critical decisions are made. These usage scenarios should also prove useful in helping non-members of the XML Query Working Group understand the intent and goals of the project: (1) Human-readable documents: Perform queries on structured documents and collections of documents, such as technical manuals, to retrieve individual documents, to generate tables of contents, to search for information in structures found within a document, or to generate new documents as the result of a query. (2) Data-oriented documents: Perform queries on the XML representation of database data, object data, or other traditional data sources to extract data from these sources, to transform data into new XML representations, or to integrate data from multiple heterogeneous data sources. The XML representation of data sources may be either physical or virtual; that is, data may be physically encoded in XML, or an XML representation of the data may be produced. (3) Mixed-model documents: Perform both document-oriented and data-oriented queries on documents with embedded data, such as catalogs, patient health records, employment records, or business analysis documents. (4) Administrative data: Perform queries on configuration files, user profiles, or administrative logs represented in XML. (5) Filtering streams Perform queries on streams of XML data to process the data in a manner analogous to UNIX filters. This might be used to process logs of email messages, network packets, stock market data, newswire feeds, EDI, or weather data to filter and route messages represented in XML, to extract data from XML streams, or to transform data in XML streams. (6) Document Object Model (DOM) Perform queries on DOM structures to return sets of nodes that meet the specified criteria. (7) Native XML repositories and web servers Perform queries on collections of documents managed by native XML repositories or web servers. (8) Catalog search Perform queries to search catalogs that describe document servers, document types, XML schemas, or documents. Such catalogs may be combined to support search among multiple servers. A document-retrieval system could use queries to allow the user to select server catalogs, represented in XML, by the information provided by the servers, by access cost, or by authorization. (9) Multiple syntactic environments Queries may be used in many environments. For example, a query might be embedded in a URL, an XML page, or a JSP or ASP page; represented by a string in a program written in a general-purpose programming language; provided as an argument on the command-line or standard input; or supported by a protocol, such as DASL or Z39.50." For related references, see "XML and Query Languages." [August 15, 2000] XSet: An XML Property Set Description of XML 1.0 and XML Namespaces. Jonathan Borden (The Open Healthcare Group) has announced the availability of a short working description of an 'XSet' XML EBNF property set description. Background: "ISO Groves and Property Sets are a formal mechanism to unify the addressing schemes of HyTime and DSSSL. Groves allow addressing and linking into multimedia formats which have defined Property Sets: essentially a 'grand unified theory' of addressing. In practice, EBNF grammars are widely used to specify formats including XML, MIME, URIs etc. The XSet production language is proposed as an alternative to ISO Groves to enable grove based processing of formats defined in EBNF." Description: "XSet is an XML property set description of XML 1.0 and XML namespaces. The description is a result of translating the Extended Backus-Naur Form (EBNF) productions into an XML language: the production rule langage (PRL). XSet xml.xml is an RDF description of the productions in XML 1.0 and XML Namespaces. RDF is used to provide metadata about the production set, including that it is 'about' XML 1.0 and 'about' XML Namespaces. RDF adds very little overhead to the property set which is itself a compact description. XSet enables XPath based indexing and addressing of the full fidelity grove of an XML document. Bonsai is a pruning and compression diagram which maps the full XSet specification onto a subset or grove plan. Examples of XSet bonsai are (1) the XML Infoset, (2) the XPath data model, (3) the DOM data model, (4) Common XML and (5) Eric van der Vlist's technique of exposing entities through the SAX model." Jonathan also writes: "On the topic of using XSLT to transform RDF<->Infoset, Dan Conolly has posted links to a couple of nice XSLTs at http://lists.w3.org/Archives/Public/www-rdf-interest/2000Aug/0061.html. . . Eric van der Vlist and I have been having an offline discussion about the similarities between his technique of using a special SAX parser to 'expand' entity declarations into 'Common XML' content. The advantage of this approach is that XPath and XSLT can be used to process the resultant abstract document (which in his example preserves the entity reference). This is very similar to the approach of XSet which logically 'expands' an XML document into a full-fidelity grove. . . A goal is to provide an XSet 'bonsai' or pruning, twisting and compression document which directs the processor as to what level of detail to provide. For example: should it generate 'element' events alone, or add STag, ETag and EmptyElementTag events. XMTP [http://www.openhealth.org/documents/xmtp.htm] is an XSet expansion of a MIME document. In the same way that an XSet expansion of an XML document can be produced by a modified SAX parser, an XMTP expansion of a MIME message can be produced by a MIME parser which emits SAX events. This technique provides a general mechanism for XPath/XPointer addressing of, and XSLT transformation of arbitrary syntaxes expressable in EBNF. This is the essence of the grove paradigm." Dan Connolly's work was presented under the title "XML in RDF in XML via XSLT: An infoset implementation." One stylesheet 'content.xsl' "takes piece of XML content (i.e., stuff matching the content production, like you might find inside a parseType="literal" element in RDF) and represents it in RDF, per the schema in the infoset specification." Connolly will integrated this with the stylesheet rdfp.xsl (RDF parser in XSLT); "This highlights some of the differences between the infoset data model and the XPath data model, since I'm using XPath to destructure the input. I think it also clarifies some stuff about how [the attribute] xml:lang fits into the RDF model, and about how XML Schema datatypes (and structured types, for that matter) fit with RDF..." For other background, see "Groves, Grove Plans, and Property Sets in SGML/XML/DSSSL/HyTime." [August 15, 2000] W3C XForms Working Group Publishes Interim Working Draft for 'XForms 1.0 Data Model'. The XForms Working Group, operating within the domain of the W3C HTML Activity, has released a revised (interim) working draft document for the XForms data model: XForms 1.0: Data Model. Reference: W3C Working Draft 15-August-2000, edited by Micah Dubinko (Cardiff), Sebastian Schnitzenbaumer (Stack Overflow), and Dave Raggett (W3C/HP). W3C 'XForms' is the next generation of Web forms: "The key idea is to separate the user interface and presentation from the data model and logic, allowing the same form to be used on a wide variety of devices such as voice browsers, handhelds, desktops and even paper. XForms bring the benefits of XML to Web forms, transferring form data as XML. XForms aim to reduce the need for scripting, and to make it easier to achieve the desired layout of form fields without having to resort to using nested tables etc." The present draft effectively obsoletes the previous working draft document issued on 06-April-2000. The XForms Working Group is currently "studying how to support forms where the data model is defined by an XML Schema plus form specific properties. The plan is for the next revision to this Working Draft to provide a description of the functional requirements for the XForms data model and logic, together with proposals for meeting these requirements using XML Schema plus XForms property annotations, and an alternative lighter weight syntax aimed at HTML authors. Later specifications will focus on the user interface aspects of XForms, and the means to submit, suspend and resume forms." Further information on the XForms activity may be found in the XForms Working Group Charter and the XForms Requirements document. For other references, see "XML and Forms." [August 15, 2000] W3C Releases Working Draft for XML 1.0 Second Edition (Review Version). Paul Grosso (Co-Chair XML Core WG) announced that the W3C XML Core Working Group has released a draft of the Extensible Markup Language (XML) 1.0 Second Edition for public review: Extensible Markup Language (XML) 1.0 (Second Edition) Review Version; Reference: W3C Working Draft 14-August-2000. "The second edition is not a new version of XML; it is designed to bring the XML 1.0 Recommendation up to date with the XML 1.0 Specification Errata (first edition)." Reviewers are asked to report errors to the '[email protected]' mailing list, which is publicly archived. Paul writes: "At this time, we are making two versions of the draft Second Edition available for a four week public review, and all interested parties are invited to review the current drafts and submit comments. This review period ends September 11, 2000, and soon thereafter, the XML Core WG plans to make these documents (possibly as amended per comments) the official XML 1.0 Recommendation Second Edition. All these public review documents are linked from the W3C TR page. The 'plain' draft Second Edition is at http://www.w3.org/TR/2000/WD-xml-2e-20000814.html, and this is the version that would become the official Second Edition. We have also produced a 'review copy' which highlights changes between the first edition and this Second Edition, and it is at http://www.w3.org/TR/2000/WD-xml-2e-review-20000814. This may be provided along with the official Second Edition if it is deemed useful and appropriate, but the 'plain' version is the official one. Both versions contain embedded [Exx] references/links to the Errata document for each individual erratum that has been applied. (If we decide to maintain the 'review' version, we may decide to delete the [Exx] references from the 'plain' one.) Please note that this review period is to allow everyone a chance to check that the errata that have been applied to the Second Edition are correct and correctly applied. Reports of further errata or ambiguities in XML 1.0 are welcome, but they will likely be saved to be considered for possible application to a later edition, not added to this Second Edition." For other versions of the XML 1.0 specification and its translations, see "XML Specifications: Reference Documents." [cache] [August 14, 2000] Microsoft Releases BizTalk Server 2000 Beta. From a recent company announcement: "Microsoft Corporation today announced the public availability of the beta version of Microsoft BizTalk Server 2000. A member of the .NET Enterprise Server family of products, BizTalk Server 2000 will make it fundamentally easier to orchestrate the next generation of Internet-based business solutions. Eagerly awaited by customers and industry partners, BizTalk Server 2000 will unite, in a single product, enterprise application integration (EAI), business-to-business integration and the much-anticipated BizTalk Orchestration technology to allow developers, IT professionals and business analysts to easily build dynamic business processes that span applications, platforms and businesses over the Internet. Based on industry standards for data exchange and security such as SOAP 1.1 (Simple Object Access Protocol), XML and S/MIME, the BizTalk Framework enables the secure and reliable exchange of business documents over the Internet. Development of the BizTalk Framework is overseen by the BizTalk Steering Committee, which is comprised of industry partners, consortiums and standards bodies. BizTalk Server 2000 customers can also take advantage of BizTalk.org, a community resource to accelerate the expression of business processes in XML. As the world's largest open XML business process schema repository with over 400 industry schema, BizTalk.org provides immediate access to XML schema from industry standards bodies like ACORD, BASDA, the HR-XML Consortium and OAG as well as popular applications vendors like Autodesk Inc., Clarus Corp., Commerce One Inc. and Great Plains. BizTalk Server 2000 will offer a broad set of tools and an infrastructure to simplify and speed the orchestration of applications and businesses together into next-generation solutions: (1) Rapid development of dynamic business processes. BizTalk Orchestration technology builds on the Visio diagramming platform to provide a familiar graphical environment for quickly building dynamic, distributed business processes, and an advanced orchestration engine for executing and managing those processes. (2) Easy application and business integration. BizTalk Server 2000 provides powerful tools to easily integrate applications and businesses both behind the firewall and across the Internet using industry standard XML. (3) Interoperability with industry standards. BizTalk Server 2000 supports a multitude of transports and protocols in addition to XML, including EDI (X12 and UN EDIFACT), HTTP, HTTPS, Microsoft Message Queue Server (MSMQ), SMTP (e-mail), and flat file transfer. (4) Reliable document delivery over the Internet. Support for the BizTalk Framework ensures reliable, 'guaranteed once only' delivery of business documents, such as purchase orders or insurance claims, over the Internet. (5) Secure document exchange. BizTalk Server 2000 supports industry-standard security technologies such as public key encryption and digital signatures to ensure secure document exchange with trading partners. (6) XLANG support. XLANG is an XML-based language for describing business processes. The BizTalk Editor and the BizTalk Mapper are included for developing and transforming XML schema and business documents. The beta version of BizTalk Server 2000 is available immediately for download." For details, see the complete text of the announcement: Microsoft Announces Availability of BizTalk Server 2000 Beta. Revolutionary New Product Will Orchestrate the Next Generation Of Internet-Based Business Solutions." [August 14, 2000] RSS 1.0 Specification Proposal and RSS-DEV Mailing List. Rael Dornfest recently announced the publication of an RSS 1.0 Specification Proposal and the formation of an RSS-DEV Mailing List [[email protected]]. The RSS 1.0 Specification Proposal has been written by Gabe Beged-Dov (JFinity Systems LLC)), Dan Brickley (ILRT), Rael Dornfest (O'Reilly & Associates), Ian Davis (Calaba, Ltd.), Leigh Dodds (xmlhack), Jonathan Eisenzopf (Whirlwind Interactive), David Galbraith (Moreover.com), R.V. Guha (guha.com), Eric Miller (Online Computer Library Center, Inc.), and Eric van der Vlist (Dyomedea). "RSS ('RDF Site Summary') is a lightweight multipurpose extensible metadata description and syndication format. RSS is an XML application, conforms to the W3C's RDF Specification and is extensible via XML-namespace and/or RDF based modularization. The modular extension of existing RSS through XML Namespaces and RDF stressing backward compatibility with RSS 0.9 for ease of adoption by existing syndicated content producers. . . Much of RSS's success stems from the fact that it is simply an XML document rather than a full syndication framework such as XMLNews and ICE." Description and background: "An RSS summary, at a minimum, is a document describing a 'channel' consisting of URL-retrievable items. Each item consists of a title, link, and brief description. While items have traditionally been news headlines, RSS has seen much repurposing in its short existence. RSS 0.9 was introduced in 1999 by Netscape as a channel description framework / content-gathering mechanism for their My Netscape Network (MNN) portal. By providing a simple snapshot-in-a-document, web site producers acquired audience through the presence of their content on My Netscape. A by-product of MNN's work was RSS's use as an XML-based lightweight syndication format, quickly becoming a viable alternative to ad-hoc syndication systems and practical in many scenarios where heavyweight standards like ICE were overkill. And the repurposing didn't stop at headline syndication; today's RSS feeds carry an array of content types: news headlines, discussion forums, software announcements, and various bits of proprietary data. RSS 0.91, re-dubbed 'Rich Site Summary,' followed shortly on the heals of 0.9. It had dropped its roots in RDF and sported new elements from Userland's scriptingNews format -- most notable being a new item-level <description> element, bringing RSS into the (lightweight) content syndication arena. While Netscape discontinued it's RSS efforts, evangelism by Userland's Dave Winer led to a groundswell of RSS-as-syndication-framework adoption. Inclusion of of RSS 0.91 as one of the syndicaton formats for its Manila product and related EditThisPage.com service brought together the Weblog and syndication worlds. . . . As RSS continues to be re-purposed, aggregated, and categorized, the need for an enhanced metadata framework grows. Channel- and item-level title and description elements are being overloaded with metadata and HTML. One proposed solution is the addition of more simple elements to the RSS core. This direction, while possibly being the simplest in the short run, sacrifices scalability and requires iterative modifications to the core format, adding requested and removing unused functionality. A second solution is the compartmentalization of specific functionality and purposing into the pluggable RSS modules. This is one of the tacts taken in this specification, said modularization being accomplished via XML Namespaces, the sequestering of vocabularies into their own private packages. Adding and removing RSS functionality is then just a matter of the inclusion of a particular set of modules best suited to the task at hand. No reworking of the RSS core is necessary. . . The 12 months since version 0.91 was released has seen the surfacing of various novel uses for RSS. RSS is being called upon to evolve with growing application needs: aggregation, discussion threads, job listings, multiple listings (homes), sports scores, etc. Via XML-namespace based modularization and RDF, RSS 1.0 builds a framework for both standardized and ad hoc re-purposing." Note also (1) the 'XSLT Stylesheets to convert older RSS formats to RSS 1.0' (from Eric van der Vlist) and (2) the latest version of the XML::RSS Perl module for processing RSS 0.9, 0.91, and 1.0 (Jonathan Eisenzopf). References: see "RDF Rich Site Summary (RSS)." [August 11, 2000] OpenTravel Alliance (OTA) Releases Version 1.0 Specifications. The OpenTravel Alliance (OTA) has announced the publication of its version 1.0 specifications for the travel industry. The OpenTravel Alliance (OTA) is a consortium of suppliers of travel services -- airline, hotel, car rental, passenger rail, travel arrangers, leisure -- and companies that provide distribution and technology support to the industry. The distribution package includes 'versioned' and 'non-versioned' XML message DTDs. From the executive summary: "The OpenTravel Alliance Message Specification, version 1 (OTA version 1) provides a common customer profile that travelers can fill out once and exchange among various travel services over the Internet. The specification provides a uniform vocabulary that captures and exchanges data on a traveler's identity, affiliations including employer, loyalty programs, forms of payment, travel documents, and detailed travel preferences. A key feature of the profile allows customers to define collections of travel preferences in terms of their own travel plans and experiences, and includes preferences for various travel services (air, hotel, car rental, other) as well as common preferences across services. The specification allows for straightforward preferences as well as collections meeting complex conditions, including choices to avoid. OTA version 1 also allows customers to identify related travelers, such as family members, companions, or fellow business colleagues, and link to their profiles. The OTA specification uses the Extensible Markup Language (XML) that allows for the exchange of structured data -- the kind of data stored in databases -- as well as processing instructions over the Web. With XML, OTA defined a common vocabulary in terms of data items called elements, attributes, or reusable entities reflected in unique tags that identify the data in messages. The hierarchical structure of these data items in a set of electronic rules is called a document type definition (DTD) that allows parties exchanging customer profiles to validate the messages. A separate DTD specifies basic error conditions and administrative messages independent of OTA's specification versions. OTA version 1 specifies that parties send profile messages as pairs of requests with corresponding responses. The messages contain four basic functions: (1) creating a profile, (2) reading a profile, (3) updating a profile, and (4) deleting a profile. The update process is the most complex and can address individual parts of the profile record. The other functions address the profile record as a whole. The specification provides tag-naming conventions, which include the version and hierarchy of the elements in each tag. OTA version 1 recommends security features providing authentication of parties, confidentiality, and integrity of messages, and provides a control section in each message, separate from the business content, for these security features. The specification also has strict privacy requirements that lets the customer indicate which data to share with other parties, even for routine functions like keeping all copies of the profile on remote sites identical with the original." For other references, see "OpenTravel Alliance (OTA)." Related standards work is referenced in "Hospitality Industry Technology Integration Standards (HITIS) Project." [August 10, 2000] Web Modeling Language (WebML). Several papers have now been published describing the work of an Italian team (Dipartimento di Elettronica e Informazione, Politecnico di Milano, Milano, Italy) on a Web Modeling Language (WebML). The project web site provides links to the relevant XML DTDs, examples, tutorial description, and technical papers. Web Modeling Language (WebML) is "a notation for specifying complex Web sites at the conceptual level. WebML enables designers to express the core features of a site at a high level, without committing to low-level architectural details. WebML concepts are associated to an intuitive graphic representation, which can be supported by CASE tools with user-friendly interfaces, and can be communicated to users and non-technical members of the site development team (e.g., to graphic designers and content producers). WebML also supports an internal XML syntax, which instead can be fed to software generators for automatically producing the implementation of a Web site. . . WebML enables the high-level description of a Web site under distinct dimensions: (1) its data content [structural model], (2) the pages that compose it [composition model], (3) the topology of links between pages [navigation model], (4) the layout and graphic requirements for page rendering [presentation model], (5) and the customization features for one-to-one content delivery [personalization model]. All the concepts of WebML are associated with a graphic notation and a textual XML syntax. WebML specifications are independent of both the client-side language used for delivering the application to users, and of the server-side platform used to bind data to pages, but they can be effectively used to produce a site implementation in a specific technological setting. WebML guarantees a model-driven approach to Web site development, which is a key factor for defining a novel generation of CASE tools for the construction of complex sites, supporting advanced features like multi-device access, personalization, and evolution management." For references and other description, see "Web Modeling Language (WebML)." [August 10, 2000] XML and Encryption. Interest in "encrypted XML" is growing rapidly, as indicated by the number of technical papers, journal articles, and activity on the public W3C XML Encryption Mailing List. Barb Fox is (unofficially) "working with Joseph Reagle [W3C] to prepare a W3C Briefing Package/Proposal for a W3C working group on XML Encryption..." Recently, Ed Simon and Brian LaMacchia posted a document "XML Encryption Syntax and Processing" to the W3C XML Encryption list: "This strawman proposal describes how the proposed W3C XML Encryption specification might look and work should the W3C choose to charter an XML Encryption Work Group. Though it is conceivable that XML Encryption could be used to encrypt any type of data, encryption of XML-encoded data is of special interest..." The W3C list, inaugurated in April 2000, is designed "for discussion about XML encryption and related (potential) IETF or W3C activity. The purpose of this list is to foster the development of a community of interest and a set of design issues and requirements that might prompt a BOF or workshop on the topic. This discussion list is public, it is not moderated, and it is not part of an chartered activity of the IETF or W3C. Appropriate content for this list includes discussion of requirements, dependencies, and technical proposals; and drafts of specifications, code, charters and calls for participation. Inappropriate materials include commercial advertisements and announcements that are not immediately relevant to XML encryption. (e.g., general announcements about XML or cryptographic conferences or books.) Please feel free to introduce yourself to the list expressing your own interest or any issues that you think are relevant." The list maintainer is Joseph Reagle (IETF/W3C XML-Signature Co-Chair). To subscribe, send a request to [email protected]. For a provisional collection of references, see "XML and Encryption." [August 09, 2000] W3C Working Draft: Speech Synthesis Markup Language Specification for the Speech Interface Framework. The W3C Voice Browser working group has released a working draft Speech Synthesis Markup Language Specification for the Speech Interface Framework. Reference: W3C Working Draft 08-August-2000, edited by Mark R. Walker (Intel) and Andrew Hunt (SpeechWorks International). The draft specification "describes markup for generating synthetic speech via a speech synthesiser, and forms part of the proposals for the W3C Speech Interface Framework. This document has been produced as part of the W3C Voice Browser Activity, following the procedures set out for the W3C Process. The authors of this document are members of the Voice Browser Working Group." Document abstract: "The W3C Voice Browser working group aims to develop specifications to enable access to the Web using spoken interaction. This document is part of a set of specifications for voice browsers, and provides details of an XML markup language for controlling speech synthesisers. The draft document describes a XML markup language for generating synthetic speech via a speech synthesiser. Such synthesisers embody rich knowledge about how to render text, and the role of the markup language is to give authors a standard way to control aspects such as volume, pitch, rate and other properties. [...] This markup language is intended for use by systems that need to produce computer-generated speech output such as Voice Browsers, web browsers and accessible applications. The language provides a set of elements that are focussed on the specific challenges of automatically producing natural-sounding, understandable speech output." Section 5 of the document supplies the 'DTD for the Speech Synthesis Markup Language'. The design and standardization process for the specification "has followed from the Speech Synthesis Markup Requirements for Voice Markup Languages published December 23, 1999 by the W3C Voice Browser Working Group." The W3C Standard is known as the Speech Recognition Grammar Specification and is based upon the JSML specification, which is owned by Sun Microsystems, Inc., California, U.S.A. Comments on the specification may be sent public mailing list, which is archived.. For related research and development, see (1) "Java Speech Markup Language (JSML/JSpeech)," (2) "SSML: A Speech Synthesis Markup Language," (3) "SABLE: A Standard for Text-to-Speech Synthesis Markup," and (4) "SpeechML." [August 09, 2000] W3C Note on Accessibility Features of SVG. The W3C has published a NOTE on Accessibility Features of SVG. Reference: W3C Note 7-August-2000, edited by Charles McCathieNevile and Marja-Riitta Koivunen. As with the ISO 8632 Computer Graphics Metafile (CGM), SVG's "plain text" notation and design features allow XML-based metadata markup internal to graphics for the support of rich hypermedia performance, including personalization and accessibility. Document abstract: "Scalable Vector Graphics (SVG) offers a number of features to make graphics on the Web more accessible than is currently possible, to a wider group of users. Users who benefit include users with low vision, color blind or blind users, and users of assistive technologies. A number of these SVG features can also increase usability of content for many users without disabilities, such as users of personal digital assistants, mobile phones or other non-traditional Web access devices. Accessibility requires that the features offered by SVG are correctly used and supported. This Note describes the SVG features that support accessibility and illustrates their use with examples." Rationale: "One major accessibility benefit derived from XML is that an SVG image is encoded as plain text. Authors can create and edit it with a text-processor or XML authoring tool (there are other properties of SVG that make this easier than it might seem at first). A number of popular Web design tools are in fact enhanced text-editing applications, and for users with certain types of disabilities, these are much easier to use. Naturally, it is also possible to use graphic SVG authoring tools that require very little reading and writing, which helps people with other types of disabilities. Plain text encoding also means that people may use relatively simple, text-based XML user agents to render SVG as text, braille, or audio. This can help users with visual impairments, and can be used to supplement graphical rendering. The separation of style from the rest of the content is very important for accessibility. Authors may use CSS or XSL style sheets to control the rendering of SVG images, a feature common to all markup languages written in XML. Users who might otherwise be unable to access content can define stylesheets to control the rendering of SVG images, meeting their needs without losing additional author-supplied style." Background: "Images, sound, text and interaction all play a role in conveying information on the Web. In many cases, images have an important role in conveying, clarifying, and simplifying information. In this way, multimedia itself benefits accessibility. However the information presented in images must be accessible to all users, including users with non-visual devices. Furthermore, in order to have full access to the Web, it is important that authors with disabilities can create Web content, including images as part of that content. The working context of people with (or without) disabilities can vary enormously. Many users or authors: may not be able to see the images at all or may have impaired vision or hearing; may have difficulty reading or comprehending text; may not be able to move easily or use a keyboard or mouse when creating or interacting with the image; may use a device with a text-only display, or a small or very magnified screen view. Increasing the accessibility of images can benefit a wide variety of users and authors including many people who do not have a disability but who have similar needs. For example, someone may be working in an eyes-busy environment and thus may require an audio equivalent for information they cannot view. Users of small mobile devices (with small screens, no keyboard, and no mouse) have similar functional needs to users with certain disabilities." See: "W3C Scalable Vector Graphics (SVG)." [August 09, 2000] Multimodal Presentation Markup Language (MPML). MPML (Multimodal Presentation Markup Language) is an XML-based markup language under development at Ishizuka Lab (Department of Information and Communication Engineering, School of Engineering, University of Tokyo. Functionally, the Multimodal Presentation Markup Language bears several similarities to Synchronized Multimedia Integration Language (SMIL). The goal of MPML is "to allow an easy and uniform high-level description for the multimodal presentations employing various lifelike agents; it enables users to write attractive multimodal presentations easily. MPML is a markup language that conforms to XML (Extensible Markup Language) and which supports functions for controlling verbal presentations and scripting agent behaviors." The MPML project is part of a broader research endeavor at the Tokyo School of Engineering: 'Multimodal Anthropomorphic Agent System and Media Processing.' The developers say: "As a promising new style of human interface beyond currently dominating GUI (Graphical User Interface), we are working on a research and development of a multimodal anthropomorphic interface agent called VSA (Visual Software Agent), which has a realistic moving face, a vision function, speech communication capability and an access function to inofo rmation sources in the Internet. The VSA, which is technically realized by integrating several technologies such as realtime image synthesis/recognition, speech recognition/synthesis, dialogue management, access technologies to the Internet and WWW (World Wide Web), etc., enables a friendly multimodal human interface environment close to daily face-to-face d ialogue. We have constructed an experimental guidance system with this VSA system and multimedia presentation." The MPML development Web site also provides an MPML Player (ViewMpml) which utilizes Microsoft Agent to perform the Multimodal Presentation. For further references, see "Multimodal Presentation Markup Language (MPML)." [August 09, 2000] CenterPoint Releases XML Class Library for C++. Guenter Obiltschnig (CenterPoint Connective Software Engineering GmbH.) recently announced the public availability of CenterPoint/XML, an XML class library for C++. "CenterPoint/XML is a class library with SAX (Simple API for XML) and DOM (Document Object Model) conforming interfaces for reading and writing XML files. CenterPoint/XML is built upon expat, the XML Parser Toolkit. You must download the sources of expat version 1.1 from ftp://ftp.jclark.com/pub/xml/expat.zip to be able to build CenterPoint/XML. Documentation for CenterPoint/XML is currently available only in the form of header file comments. CenterPoint/XML has been tested on the following platforms: Windows NT/VC++ 6.0; Linux/gcc 2.95.2; HP-UX 10.20/gcc 2.95.2; OpenVMS/Compaq C++ 6.2." The library is available under the CenterPoint open source license. For other details, see the company web site. [August 09, 2000] Oracle Releases News Implementations for XML Schema. Mark Scardina recently announced three new/updated XML Schema implementations now available on the Oracle Technology Network. Each of these versions is compliant with the W3C XML Schema Working Drafts of April 07, 2000, viz., XML Schema Part 0: Primer, XML Schema Part 1: Structures, XML Schema Part 2: Datatypes. (1) The XML Schema Processor for Java v1.0.0 Second BETA release supports simple and complex types and is built upon the XML Parser for Java v2. The Oracle XML Schema Processor for Java supports both simple and complex data types. It works with the XML Parser for Java - also included in the Oracle XDK. With the XML Parser and its integrated XSL Processor, you can transform one XML document into another, convert XML to other formats, such as HTML, or extract data and save it into the Oracle8i database in a single process. The XML Schema Processor automatically gives you the ability to easily validate the structure of XML data and documents and their included data types before manipulating them with the parser. As any other component of the Oracle XDK, you can use the Oracle XML Processor for Java on the client, application server, and database tiers of your applications. (2) The XML Schema Processor for C v1.0.0 First BETA release supports simple and complex types and is built upon the XML Parser for Java v2. The XML Schema Processor for C "is a companion component to the XML Parser for C that allows support to simple and complex datatypes into XML applications with Oracle8i. The Schema Processor supports the XML Schema Working Draft, with the goal being that it be 100% fully conformant when XML Schema becomes a W3C Recommendation. This makes writing custom applications that process XML documents straightforward in the Oracle8i environment, and means that a standards-compliant XML Schema Processor is part of the Oracle8i platform on every operating system where Oracle8i is ported." (3) The XML Schema Processor for C++ v1.0.0 First BETA release supports simple and complex types and is built upon the XML Parser for C++ v2. "The XML Schema Processor for C++ is a companion component to the XML Parser for C++ that allows support to simple and complex datatypes into XML applications with Oracle8i." About the Oracle XML Developer's Kit: "The Oracle XML Developer's Kit (XDK) contains the basic building blocks for reading, manipulating, transforming and viewing XML documents. To provide a broad variety of deployment options, the Oracle XDK is available for Java, C, C++ and PL/SQL. Unlike many shareware and trial XML components, the Oracle XDK is fully supported and comes with a commercial redistribution license. The Oracle XDK consists of the following items: (1) XML Parsers: supporting Java, C, C++ and PL/SQL, the components create and parse XML using industry standard DOM and SAX interfaces. (2) XSL Processor: transforms or renders XML into other text-based formats such as HTML. (3) XML Schema Processor: allows use of XML simple and complex datatypes. (4) XML Class Generator: automatically generates Java and C++ classes to send XML data from Web forms or applications. (5) XML Transviewer Java Beans: visually view and transform XML documents and data via Java components. (6) XSQL Servlet: combines XML, SQL, and XSLT in the server to deliver dynamic web content." For schema description and references, see "XML Schemas." [August 08, 2000] PricewaterhouseCoopers to Develop XML-Based Protocol 'Data Link for Intermediaries Markup Language (daliML)'. PricewaterhouseCoopers has announced Data Link for Intermediaries Markup Language (daliML) as a new XML-based protocol "for Internet-based electronic sharing of withholding and payment information. The protocol specification will initially target foreign intermediaries who choose to apply to the IRS for Qualified Intermediary status. daliML is the backbone of the Data Link for Intermediaries (DALI) system. daliML is based on the XML - Extensible Markup Language. XML is the emerging Internet standard for data sharing between applications. With XML you can organize elements based on a structural hierarchy. It is independent of any underlying programming language, transport mechanism or messaging protocol. Due to a lack of standardization on a set of technology tools, it takes a considerable amount of work for different business groups to communicate. daliML will facilitate inter-system communication. Using daliML and core technology to support XML-based information exchange the data can be readily exchanged between diverse sets of applications in different areas." Background is provided in the announcement: PricewaterhouseCoopers, the world's largest professional services organization, is creating an electronic communications system and central repository called Data Link for Intermediaries (DALI) at the request of The Depository Trust & Clearing Corporation (DTCC) and a consortium of global financial institutions including Goldman, Sachs & Co., Merrill Lynch, Morgan Stanley Dean Witter and Salomon Smith Barney - a member of Citigroup. DALI, among other things, will be a global, Internet-based, real-time communications tool that will help financial institutions meet new reporting requirements by facilitating the interaction between U.S. withholding agents and their non-U.S. intermediary customers. In addition, PricewaterhouseCoopers has developed a communications protocol for DALI called daliML. The system will be piloted during the fourth quarter of 2000 and is scheduled to be fully operational by 2001. The Depository Trust Company, a subsidiary of DTCC, will host and operate the system. The protocol, daliML, is based on eXtensible Markup Language (XML), the emerging Internet standard for data sharing between applications. This specification is expected to set the standard within the withholding and reporting area of the financial services industry. DALI leverages the innovation and [XML] standardization work from the Internet community; it treamlines data transmission procedures and minimizes processing delays and creates a standardized set of data elements. DALI will serve as a central document and data repository for required tax documents and core account information between US financial institutions and foreign intermediaries as prescribed by the 1441 Tax Regulations." For details, see the full text of the press release, "PricewaterhouseCoopers to Develop Electronic Solution for Global Financial Institutions to Handle Changes in U.S. Withholding Tax Regulations. PricewaterhouseCoopers-Developed Communications Protocol, daliML, Will Be Backbone to New System." For other references, see: "Data Link for Intermediaries Markup Language (daliML)." [August 08, 2000] New BPMI Initiative Proposes Business Process Modeling Language (BPML). A recent announcement from Intalio, Inc. describes the formation of a industry group "to define standards for the management of mission-critical business processes that span multiple applications, corporate departments, and business partners." Sixteen companies and organizations have founded the initiative. The initiative's first deliverable is an XML schema formalizing a 'Business Process Modeling Language (BPML).' "The first draft of the BPML Schema will be released to the public in Q4 2000 and cover transactions and compensating transactions, dataflow, messages and scheduled events, business rules, security roles, and exceptions. BPMI.org will eventually lead to the additional development of a management protocol based on industry standards such as SOAP and DAV for the deployment and management of business processes modeled accordingly to the forthcoming BPML Schema. The [related] Business Process Query Language (BPQL) defines a standard interface to forthcoming Business Process Management Systems (BPMS). It will allow system administrators to manage the BPMS and business analysts to query instances of business processes running on it. The BPML Schema will initially cover transactions and compensating transactions, dataflow, messages and scheduled events, business rules, security roles, and exceptions. The covering of distributed resources might be eventually added in order to support the workflow-related standards developed by the WfMC. BPMI.org will put a very strong emphasis on three major aspects: First, the BPML Schema will be used by Business Process Management Systems for mission-critical applications and therefore must offer an explicit support for synchronous and asynchronous distributed transactions. Second, the BPML Schema will be used for modeling business processes deployed behind the firewall and over the Internet, and therefore must offer advanced capabilities related to security. Finally, the BPML Schema will be used through Integrated Development Environments allowing business analysts, system analysts and developers to collaborate over the entire project's lifecycle, and therefore must offer advanced capabilities related to project management. [...] BPMI.org and ebXML are addressing complementary aspects of e-Business process integration. While ebXML provides a standard way to manage Collaborative Business Processes (CBP), BPMI.org focuses on the modeling, deployment, and management of Enterprise Business Processes (EBP)." From the announcement: "Intalio, the Business Process Management Company, with Aventail, Black Pearl, Blaze Software, Bowstreet, Cap Gemini Ernst & Young, Computer Sciences Corporation, Cyclone Commerce, DataChannel, Entricom, Ontology.Org, S1 Corporation, Versata, VerticalNet, Verve, and XMLFund announced today that they will form a group to define standards for the management of mission-critical business processes that span multiple applications, corporate departments, and business partners. The XML-based standards generated from the initiative will support and complement existing business-to-business collaboration protocols such as RosettaNet, BizTalk, and ebXML, as well as technology integration standards including J2EE and SOAP. The first deliverable of the Business Process Management Initiative will be the specification of the Business Process Modeling Language (BPML). BPML is an XML Schema that provides a standard way to model mission-critical business processes. XML (eXtensible Markup Language) is the new Internet standard for marking up data to facilitate exchanges of information between businesses, independently of applications and platforms. By covering many dimensions of business process modeling that are specific to processes deployed internally to the enterprise, including business rules, security roles, distributed transactions, compensating transactions, and exception handling, BPML will bridge the gap between legacy IT infrastructures and emerging business-to-business collaboration protocols such as RosettaNet, BizTalk, and ebXML. The Business Process Modeling Language will enable the enterprise to model, deploy, and manage business processes such as order management, customer care, demand planning, product development, and strategic sourcing. This will allow the IT infrastructure to provide greater adaptability to the business of the enterprise and easier manageability of constantly evolving business processes, eventually leading to higher levels of profitability." See: "Business Process Modeling Language (BPML)." [August 05, 2000] Sun Releases Tools for XML-Based Scalable Vector Graphics (SVG). Sun Microsystems recently announced the availability of several resources supporting the W3C Scalable Vector Graphics (SVG) specification, recently promoted to the level of a W3C Candidate Recommendation. Resources include: (1) Graphics 2D SVG Generator, which "allows Java language applications to export their graphics to Scalable Vector Graphics (SVG) format. You can then import the SVG files in the growing set of graphics editing tools that support SVG. The generator now supports all Java 2D API text rendering primitives, including AttributedCharacterIterator and GlyphVector. Furthermore, the generator can now optionally stream out SVG content using XML attributes or CSS properties for all the rendering attributes used in SVG." (2) SVG Slide Toolkit, "which transforms an XML file that uses a specific DTD into an SVG (Scalable Vector Graphics) slide presentation. This allows you to separate the content of a presentation from its look and feel. This separation allows you to modify independently the content, the presentation style or both. One advantage of this is that you can then use the same content for different audiences or events. Similarly, you can use the same look and feel for different content. The SVG Slide Toolkit includes the following components: Cascading stylesheet containing style definitions used by the elements in the generated SVG output file; DTD for slide presentations; Stylesheet for slide navigation; A test SVG file that you can use to verify that files were extracted properly from the archive and that the SVG viewer is installed correctly; Sample template file that you can use to create your own XML slide files; Presentation about SVG that you can use to test your installation and to learn more about SVG; Main (driver) stylesheet for building slides; Customizable stylesheet for slides." (3) Several introductory and tutorial articles describing SVG and its use with Java, including: (a) "Scalable Vector Graphics (SVG): An Executive Summary [by Vincent Hardy, Senior Staff Engineer, Sun Microsystems XML Technology Center] - this article "provides a brief introduction to SVG, followed by four examples of SVG graphics, and links to two code samples. (b) "Tutorial on Java Server Pages technology and SVG" - covers "Setting the generated document's MIME type, Declaring Java language variables, Using variables in the generated SVG content, and Extracting request parameters for use in the SVG content." (c) "Writing a custom Graphics2D implementation to generate SVG images", by Vincent Hardy - illustrates "how to take advantage of the Java 2D API's extensible architecture to write a new Graphics2D implementation, SVGGraphics2D, which allows all Java programming language applications to export their graphics to the SVG format." Other details are provided in a company announcement, "Sun Microsystems Delivers Tools to Help Developer Community Leverage XML Standards for Graphics. New Tools Enables Web Developers to Leverage Power of Java Technology and XML-based Scalable Vector Graphics (SVG)." The press release says, in part: Sun Microsystems, Inc. today announced the beta availability of the 2D graphics SVG generator software, downloadable for no charge at www.sun.com/xml. This easy-to-use tool, developed by Suns XML Technology Center, underscores Sun's commitment to provide the Java technology developer community with software that leverages the power and growing ubiquity of XML. XML's universal, standards-based syntax will play an important role in graphics rendering as well as data portability and usability, and Sun is progressive in meeting developer demand for the needed tools in these areas. Scalable Vector Graphics (SVG) is in development at the World Wide Web Consortium (W3C) and is a file format that describes two-dimensional vector graphics in XML. The latest specification was released by the for Candidate Recommendation today. The Java platform and XML are complementary technologies that together serve as the foundation for network-centric computing. Taking advantage of these technologies' synergy, Sun's 2D graphics SVG generator software allows Java technology applications to export graphics to the XML-based SVG format. The SVG files can then be imported into the growing number of graphics editing/authoring tools and viewers that support SVG. 'As our networked world takes shape, developers will increasingly require rich graphics that work well on a range of devices, screen sizes, and printer resolutions. SVG meets these requirements and finally brings the full benefits of XML, such as interoperability and internationalization, to the graphics space,' said Bill Smith, engineering manager of Suns XML Technology Center. 'Once again, Sun is pleased to deliver to its developer community a powerful tool -- the 2D graphics SVG generator software -- based on two open, industry collaborative technologies: the Java 2 platform and the XML-based SVG format.' SVG has many advantages over graphics formats in use today, such as JPEG or GIF. Since SVG is a plain text format, its files are readable and generally smaller than comparable graphical images. SVG images are also "zoomable" or "scalable", meaning users can zoom in on a particular area of a graphic, such as a map, and not experience any image degradation. Because SVG is scalable, SVG images can be printed with high quality at any resolution. Text within an SVG-based image, such as a city name on a map, is both selectable and searchable. Applications written in SVG can be made accessible through means for describing the visual information in textual detail. Lastly, SVG supports scripting and animation, which enables unprecedented dynamic, interactive graphics." For related references, see "W3C Scalable Vector Graphics (SVG)." [August 03, 2000] XBRL News - Specification and First Taxonomy Released. A communiqué from Charles Hoffman reports on the new release of an XBRL specification, together with a taxonomy for financial reporting of commercial and industrial companies. The team also reports that some ten (10) other taxonomies, mostly international, are now under development. The taxonomy document provides a 'taxonomy for the creation of XML-based instance documents for business and financial reporting of commercial and industrial companies according to US GAAP'; it is now published as "XBRL Taxonomy: Financial Reporting for Commercial and Industrial Companies, US GAAP." Reference: 2000-07-31, edited by Sergio de la Fe, Jr. (CPA, KPMG LLP), Charles Hoffman (CPA, XBRL Solutions, Inc.), and Elmer Huh (Morgan Stanley Dean Witter). Abstract: "This documentation explains the XBRL Taxonomy Financial Reporting of Commercial and Industrial Companies, US GAAP, dated 2000-07-31. This taxonomy is created compliant to the XBRL Specification. It is for the creation of XML-based instance documents that generate business and financial reporting for commercial and industrial companies according to US GAAP. XBRL is a specification for the eXtensible Business Reporting Language. XBRL allows software vendors, programmers, and end users who adopt it as a specification to enhance the creation, exchange, and comparison of financial reporting information. Financial reporting includes, but is not limited to, financial statements, financial information, non-financial information and regulatory filings such as annual and quarterly financial statements." The specification document (in PDF, HTML, or .DOC formats) is Extensible Business Reporting Language (XBRL) Specification."; reference 2000-07-31, edited by Walter Hamscher and David Vun Kannon. Abstract: "XBRL is the specification for the eXtensible Business Reporting Language. XBRL allows software vendors, programmers and end users who adopt it as a specification to enhance the creation, exchange, and comparison of business reporting information. Business reporting includes, but is not limited to, financial statements, financial information, non-financial information and regulatory filings such as annual and quarterly financial statements. This document defines XML elements and attributes that can be used to express information used in the creation, exchange and comparison tasks of financial reporting. XBRL consists of a core language of XML elements and attributes used in document instances as well as a language used to define new elements and taxonomies of elements referred to in document instances." The DTD and XML Schema are also published. For the taxonomy, the web site provides (1) a summary description and (2) an XML Schema. [cache] For other details, see the full text of the announcement, "XBRL Committee Releases First Specification for Financial Statements. Leads to Significant Expansion of Corporate Membership. Committee to Form International Organization to Position for Rapid Global Expansion and Adoption." - "The XBRL Committee announced today that several new, leading companies and organizations have joined the XBRL initiative: ACCPAC International, Inc.; ACL Services Ltd; Bridge Information Systems; Dow Jones & Company, Inc.; e-Numerate Solutions Incorporated; eLedger.com, Inc.; Fidelity Investments; Financial Software Group; First Light Communications, Inc.; MIP, Inc.: Multex.com, Inc.; Oinke, Inc.; PeopleSoft, Inc.; U.S. Advisor, Inc.; Virtual Growth, Inc.; and XBRL Solutions, Inc. XBRL Committee membership now exceeds 50 companies and organizations from around the world and is expanding globally as industry sectors and foreign jurisdictions begin development of XBRL specifications. In addition, the XBRL Committee announced the on-time release of the first specification for U.S. companies, XBRL for Financial Statements. With the release of the first specification this month, both public and private companies can begin to incorporate XBRL into their financial reporting processes and immediately realize some of its major benefits: a streamlined financial reporting process, technology independence, full interoperability, and reliable extraction of financial information. In order to meet the rapidly increasing demand for XBRL specifications in other countries, the XBRL Committee announced today its intent to form XBRL.org, an international organization to facilitate the global expansion and adoption of XBRL. XBRL.org's mission will be to develop XBRL specifications on a global scale according to the accounting principles of individual geographies and jurisdictions. More than 80% of major US public companies provide some type of financial disclosure on the Internet. As a result, investors need accurate and reliable financial information that can be delivered promptly over the Internet to help them make informed financial decisions. XBRL for Financial Reporting meets these needs and leverages efficiencies of the Internet as today's primary source of financial information. 'The AICPA has been working with major companies and international organizations for more than a year to develop the current XBRL specification and to determine the future development cycle of XBRL for other countries,'said Barry Melancon, president of the American Institute of Certified Public Accountants. 'With the launch of XBRL for Financial Statements for U.S. companies, we see the need to create an international organization with jurisdiction beyond the United States. Its purpose would be to develop and launch specifications for other countries based on strong global demand from members of the financial information supply chain'." [cache] For other references, see "Extensible Business Reporting Language (XBRL)." [August 03, 2000] XML Specifications for News - NewsML Update. Reuters and the International Press Telecommunications Council recently issued several announcements concerning the progress of NewsML, "an XML encoding for news which is intended to be used for the creation, transfer, delivery and archiving of news." NewsML is one of several XML-based markup specifications under development. David Megginson recently wrote in summary: "NITF is a format for textual news stories, and can be used within NewsML, which is a larger framework for news resources. XMLNews-Story [part of the XMLNews standard] is a simplified (and cleaned-up) profile of NITF, so there is no conflict; XMLNews-Meta is a different solution to the problems that NewsML addresses..." Now David Allen has announced the availability of a NewsML XSLT Stylesheet "designed to show the structure of a NewsML documents and how reference can be made to an external Controlled Vocabulary... I have produced a XSLT stylesheet so that NewsML instances can be visualised using IE5.0 with MSXML3 dated May 2000. The aim is to show the NewsML structure and how a controlled vocabulary may be accessed and its contents added in the viewer. The stylesheet and an example of xml instances can be found at http://www.iptc.org/NewsML/IPTCNewsML.xsl and http://www.iptc.org/NewsML/mlking.xml . . . The NewsML version 1.0Beta DTD is available online together with supporting vocabularies and may been downloaded as a zipped package [cache]. The version 1.0-Beta specification is also available; it has been issued a NewsML NewsItem with a ContentItem (PDF) that is the document itself. The Functional Specification contains an updated Glossary of Terms. Reuters is promoting the NewsML specification, as illustrated in a recent announcement, "Reuters to Pioneer New Multimedia News Delivery. Global News Delivery Standard To Allow Text, Pictures and Video To Be Delivered Through A Single Multimedia Channel.": (in part) "Reuters, the global information and news group, announced today it plans to pioneer the packaging and distribution of multimedia news using a new computer language, NewsML, that it expects will become a news industry standard. NewsML, a derivative of the Internet's eXtensible Markup Language (XML), lets journalists and other publishers produce and assemble stories in video, text, graphics, pictures and audio, in any language and for platforms ranging from financial service desktops to Web sites to mobile phones. It provides a standard framework to describe, package, store and deliver multimedia news. Reuters was a leader in the creation of NewsML and has contributed to its development via the International Press Telecommunications Council (IPTC), the news industry's standards body, which this month approved a beta release and anticipates a final version in October. Thomas Glocer, CEO of Reuters Information commented, 'NewsML is at the heart of Reuters strategy to deploy leading technologies to create and deliver multimedia news content. Reuters was very active in the development of NewsML with the IPTC. We look forward to its formal designation as an open standard in October and expect to be the first organization to deploy it in our global news operations.' Reuters plans to demonstrate NewsML on www.reuters.com in September [2000] and at a number of XML and news industry events during the coming months. The demonstrations will highlight NewsML's multimedia, multilingual news capability to deliver a single package to suit diverse client needs. The variety of user benefits will include the ability to choose text in several different languages, photos in various resolutions or sizes and the facility to bypass current Internet bandwidth limitations. NewsML is an XML-based standard that describes and packages multimedia news in various formats for delivery to any platform. At the heart of NewsML is the concept of the NewsItem, which can contain various media, including text, pictures, graphics and video. NewsML is flexible and extensible and uses standard Internet naming conventions for identifying the news objects in a NewsItem. Content does not have to be embedded in a NewsItem; pointers can be inserted to content held on a publisher's website. This means subscribers retrieve the data only when they need to and makes NewsML bandwidth-efficient." See for other details: (1) NewsML and IPTC2000; (2) XMLNews: XMLNews-Story and XMLNews-Meta; (3) News Industry Text Format (NITF); (4) News Markup Language (NML); also (5) adXML.org: XML for Advertising and (6) Newspaper Association of America (NAA) - Standard for Classified Advertising Data. [August 03, 2000] Annotations on Markup Languages: Theory and Practice Volume 2, Issue 1. The 'Winter 2000' issue of the academic journal Markup Languages: Theory and Practice (MIT Press) has been published, so I have prepared an annotated Table of Contents document for this publication: Volume 2, Issue 1 (Winter 2000). The document provides extended abstracts/summaries for the feature articles and some additional links. MLTP 2/1 has a mix of excellent articles: XML/EDI best practices, system architectures for structured documents, topic maps, web content authoring and transcoding, caterpillar expressions for tree matching, parameter entity tricks, book review. The subscription price for Markup Languages: Theory and Practice ($50 annual/individual) is very reasonable as technical journals go; readers are therefore encouraged to subscribe and to consider submission of technical articles for publication. Details of editorship and publication are available in: (1) the journal publication statement; in (2) the journal description document; and in (3) the overview of the serials document, Markup Languages: Theory & Practice. See also the annotated TOCs for previous issues 1/1, 1/2, 1/3, and 1/4. [August 02, 2000] Dialogue Moves Markup Language (DMML). An article recently published in Communications of the ACM (CACM) presents the "Dialogue Moves Markup Language (DMML)" in the context of this CACM special issue on 'Personalization'. An excerpt: "The pragmatic goal of natural language (NL) and multimodal interfaces (speech recognition, keyboard entry, pointing, among others) is to enable ease-of use for users/customers in performing more sophisticated human-computer interactions (HCI). NL research attempts to define extensive discourse models that in turn provide improved models of context-enabling HCI and personalization. Customers have the initiative to express their interests, wishes, or queries directly and naturally, by speaking, typing, and pointing. The computer system provides intelligent answers or asks relevant questions because it has a model of the domain and a user model. The business goal of such compterized systems is to create the marketplace of one. In essence, improved discourse models can enable better one-to-one context for each individual. Even though we [IBM] build NL systems, we realize this goal cannot be achieved due to limitations of science, technology, business knowledge, and programming environments. [...] We would add another problem to this list: Our repositories of knowledge are not designed for NL interaction.. . . We address the issue of managing the business complexities of dialogue systems (for example, using NL dialogue on devices with differing bandwidth) by describing a piece of middleware called Dialogue Moves Markup Language (DMML). One of the key aspects of engineering is to design the middleware (middle layer)... which typically contains a dialogue manager, an action manager, a language-understanding module, and a layer for conveying messages between them... Universal Interaction uses the same mechanism for different communication devices (such as phones, PDAs, and desktop computers). This means conveying the same content through different channels by suitably modifying the way it is represented. Universal Interaction architecture is tailor-made for personalization: the actual interface for each user can be specifically constructed for him or her based upon geography-specific, user-specific, and style-specific transformations. How do we transform the content to fit into different representations? A potentially good idea is to use an XML/XSL-based architecture for the separation of form, content, style, and interactions. To make the idea more specific, imaging how one can represent a dialogue move in a stock trading scenario. DMML -- inspired by the theory of speech acts and XML -- is an attempt to capture the intent of communicative agents in the context of NL dialogue management. The idea is to codify dialogue moves such as greetings, warnings, reminders, thanks, notifications, clarifications, or confirmations in a set of tags connected at runtime with NL understanding modules, which allow us to describe participants' behaviors in terms of dialogie moves, without worring about how they are expressed in language. For instance, 'any positive identification must be followed by a confirmation.' The tags can also encode other parameters of the dialogue, such as the type of channel and personal characteristics. Thus, the dialogue can reflect the channel characterstics, which connects DMML and Universal Interaction. [Figure 2 presents a stock-trading transaction in DMML markup notation.] DMML thus illustrates the concept of communication middleware in dialogue systems, and is very well suited for personalization." See the full presentation: "Natural Language Dialogue for Personalized Interaction," by Wlodek Zadrozny, Malgorzata Budzikowska, J. Chai, Nanda Kambhatla, Sylvie Levesque, and Nicolas Nicolov (IBM T.J. Watson Research Center). In Communications of the ACM (CACM) Volume 43, Number 8 (August, 2000), pages 116-120. Further background to this research has been published in "DSML [Dialog System Markup Language]: A Proposal for XML Standards for Messaging Between Components of a Natural Language Dialog System." By Dragomir R. Radev, Nanda Kambhatla, Yiming Ye, Catherine Wolf, Wlodek Zadrozny In Proceedings of the Artificial Intelligence and Simulation of Behaviour (AISB) 1999 Convention; the workshop on Reference Architectures and Data Standards for Natural Language Processing, Edinburgh, UK, April, 1999. For other references, see "Dialogue Moves Markup Language (DMML)." [August 02, 2000] Scalable Vector Graphics (SVG) 1.0 Specification Published as a W3C Candidate Recommendation. The W3C SVG Working Group has issued the Scalable Vector Graphics (SVG) 1.0 Specification as a W3C Candidate Recommendation as part of the W3C Graphics Activity. Reference: W3C Candidate Recommendation 02-August-2000, edited by Jon Ferraiolo (Adobe). Document abstract: "This specification defines the features and syntax for Scalable Vector Graphics (SVG), a language for describing two-dimensional vector and mixed vector/raster graphics in XML." Description: "SVG is a language for describing two-dimensional graphics in XML. The SVG language, as described in the present Candidate recommendation, allows for six main types of graphic object: vector graphic shapes (for example, paths consisting of straight lines and curves), images, gradient fills, filters, reusable components such as symbols and markers, and text. Graphical objects can be grouped, styled, transformed and composited into previously rendered objects. The feature set includes nested transformations, clipping paths, alpha masks, filter effects, template objects and both procedural and declarative animation. SVG thus allows for three types of graphic objects: vector graphic shapes (e.g., paths consisting of straight lines and curves), images and text. Sophisticated applications of SVG are possible by use of supplemental scripting language with access to SVG's Document Object Model (DOM), which provides complete access to all elements, attributes and properties. A rich set of event handlers such as onmouseover and onclick can be assigned to any SVG graphical object. Because of its compatibility and leveraging of other Web standards, features like scripting can be done on XHTML and SVG elements simultaneously within the same Web page. SVG is a language for rich graphical content. For accessibility reasons, if there is an original source document containing higher-level structure and semantics, it is recommended that the higher-level information be made available somehow, either by making the original source document available, or making an alternative version available in an alternative format which conveys the higher-level information, or by using SVG's facilities to include the higher-level information within the SVG content." Work status: "This is the Candidate Recommendation of the Scalable Vector Graphics (SVG) 1.0 specification. This means that the SVG Working Group considers the specification to be stable, and encourages implementation and comment on the specification during this period. The Candidate Recommendation review period ends when there exists at least one SVG implementation which passes each of the Basic Effectivity (BE) tests in the SVG test suite. Due to the already very good implementation status of SVG, we anticipate this to take approximately one month. Should this specification prove very difficult or impossible to implement, the Working Group will return the document to Working Draft status and make necessary changes. Otherwise, the Working Group anticipates asking the W3C Director to advance this document to Proposed Recommendation." See the W3C press release and 'Testimonials for Scalable Vector Graphics Candidate Recommendation.' For additional references, see "W3C Scalable Vector Graphics (SVG)." [July 31, 2000] Microsoft Announces MSXML Beta with Visual Basic SAX Support and Conformance with the OASIS Test Suite. Microsoft recently announced the 'July 2000 MSXML Beta Release' -- "The newest drop of its XML parser with new Visual Basic SAX support and conformance with the OASIS Test Suite. . . The July 2000 Microsoft XML Parser (MSXML) Beta Release is an update to the May 2000 technology preview. This latest release of MSXML represents a step beyond the May 2000 release, providing improved XSLT/XPath standard compliance, Microsoft Visual Basic support for SAX2 (Simple API for XML), a number of bug fixes, and the closest conformance yet with the Organization for the Advancement of Structural Information Standards (OASIS) Test Suite. This version of the parser marks the transition from 'technology preview' to full beta, with general product availability scheduled for Web release in fall 2000. XML is a key technology of the Microsoft .Net Platform, and MSXML3 lays the groundwork for that vision by allowing developers to rapidly build and deliver XML-based Web services today. Interoperability is one of the primary benefits of using XML for communications and data exchange, but can only be achieved when producers and consumers of XML process the language in a consistent way. This does not require the use of the same software or programming language, or even the same operating system, but it does mean that both applications must conform to the World Wide Web Consortium (W3C) XML 1.0 Recommendation. To help ensure vendors support this recommendation in a consistent way, OASIS - working with the support of the National Institute of Standards and Technology - has produced the XML Conformance Test Suite containing over 1,000 tests. Microsoft is committed to supporting and ensuring the interoperability of XML, as demonstrated by the significant advances in this beta release. . . Visual Basic Support for SAX2: The July 2000 MSXML Beta Release provides Visual Basic support for SAX2. Now developers have a choice of creating SAX2 applications using Microsoft Visual C++ or Visual Basic. With the MSXML SAX2 implementation, developers can implement a low-level parser to improve performance in scenarios such as the following: (1) High-throughput situations where the application needs to quickly scan the XML document for a few particular nodes. For example, you may scan a purchase order for the name of the customer and then pass it on. (2) Processing large documents on the server, where creating an entire Document Object Model (DOM) tree might be too expensive. XSLT/XPath Support: features implemented in this release include (1) <xsl:key>, which provides a more flexible way of identifying elements within a document than using id. (2) <xsl:message>, which outputs a message and is generally used to report error conditions. (3) <xsl:fallback>, which can be used to handle situations where the parser cannot process an XSL element that may be part of a new version. (4) <xsl:namespace-alias>, which provides a way to map a namespace in a style sheet to a different namespace in the output. In addition, the following XPath functions are now implemented in this release: (5) Document function, which provides access to XML documents other than the main source document. (6) Key function, which provides an efficient way to find nodes that have been identified with a named key." MSXML Beta is now available for download. For other details, see (1) "What's New in the July 2000 Microsoft XML Parser Beta Release," by Charlie Heinemann, and (2) the May 2000 Microsoft XML Parser Technology Preview Release. [July 31, 2000] Open Philanthropy Exchange (OPX) Consortium Releases XML Specification for Gift Information Transfer. OPX (Open Philanthropy eXchange) was founded "to help the philanthropic community make effective use of the growing number of technology opportunities currently available. OPX provides a standard for formatting and exchanging digital information about donors, gifts, volunteers, members and events. By using a common data format, nonprofit organizations and service providers can streamline communications between Web sites and back-office databases. Software applications with incompatible formats can use OPX to transfer information using a common language. The OPX Consortium brings together diverse industry partners to define and shape the OPX standard. The consortium will comprise many different organizations -- software vendors, charitable donation capture Web sites, and other nonprofit solution providers -- to ensure OPX is truly an open, industry-wide tool. OPX is based on XML (Extensible Markup Language). XML is a standard language used to structure and describe data so that a broad range of applications can understand it. OPX defines an XML grammar that allows for a flexible, standard way to tag specific pieces of information such as donor names, gift amounts, membership levels, event registrations and volunteer opportunities. The most important goal of the OPX development team was to define the OPX wire format (or layout) in an industry standard fashion. Therefore, XML 1.0 serves as the basis for the OPX layout. All HTTP requests contain an XML payload conforming to the OPX document type definition. Using XML technology allows the standard to be flexible and easily expanded. XML is also both platform and system independent, companies can employ OPX without drastic change to their existing systems. A company can install any web server that accepts HTTP POST requests; this will act as an OPX server. XML presents no constraints on implementation; the company determines how best to integrate OPX into its systems. The consortium will help define future versions of OPX. OPX 1.0 provides the foundation for the OPX initiative. Future versions will define data exchanges for volunteers, events, memberships, as well as matching information, and other types of data relevant to nonprofit operations." From the text of the 2000-07-31 announcement: "The Open Philanthropy eXchange (OPX) Consortium today announced the release of the initial specification for an open technical standard for use by the nonprofit community and organizations that provide services to that sector. Based in the programming language XML, these specifications are the first step in an evolving process to develop and maintain an open data exchange standard that benefits the entire sector. The OPX standard can be accessed at www.opxinfo.net. The development of open standards helps to speed the adoption of technology and Internet-based applications and services. OPX was founded to help the philanthropic community make effective use of the growing number of technology opportunities currently available. This initial release of the OPX specification facilitates the seamless transfer and importing of donor and gift information from e-commerce-enabled Web sites to nonprofits' database software, and other donor relationship management tools." For additional details and references, see "Open Philanthropy Exchange (OPX)." [July 31, 2000] SourceForge XMLConf: Conformance Testing for XML and Related Technologies. David Brownell recently posted an announcement for SourceForge XMLConf - a 'Conformance Testing Project for XML and Related Technologies', including XML, XML Schema, DOM, Performance, SAX, and XSLT. The XMLConf project "hosts XML related testing efforts, focusing initially on conformance testing. At this writing, it's in the very early stages ... so if there's something you think needs fixing, please help fix it! It's a good time to join. Notice that all of this software is under the GPL. The first testing effort hosted here addresses XML conformance. It includes test harnesses for Java (with SAX/SAX2) and for JavaScript (with DOM/COM). The second such effort is currently in its early stages, and addresses XML Schema conformance. Other projects discussed include DOM testing, performance measurement, XSLT conformance ... the whole gamut. Basically, if it's an XML related technology and there's enough of a standard API that an automated harness could usefully compare different implementations, it could fit in here. The intention here is provide a home for open, public, collaborative development of harnesses and test cases for testing XML (and related) processors. It complements the corresponding efforts of W3C, NIST, OASIS, and many others. . . If you are working on XML-related conformance testing, including verification of an implementation you are providing or maintaining, please consider helping out. If you package and document your test cases appropriately, you'll be helping achieve the community goal of fully interoperable implementations for all basic Web protocols." Principal collaborators named in the announcement include David Brownell, Curt Arnold, Joe Polastre, and Richard Tobin. For related references, see "XML Conformance". [July 31, 2000] W3C Releases Revised SMIL Animation Specification. A new working draft version of the SMIL Animation specification has been published by the W3C. Reference: W3C Working Draft 31-July-2000, edited by Patrick Schmitz (Microsoft) and Aaron Cohen (Intel). Document abstract: "This is a working draft of a specification of animation functionality for XML documents. It describes an animation framework as well as a set of base XML animation elements suitable for integration with XML documents. It is based upon the SMIL 1.0 timing model, with some extensions." Description: "This document describes a framework for incorporating animation onto a time line and a mechanism for composing the effects of multiple animations. A set of basic animation elements are also described that can be applied to any XML-based language. A language with which this module is integrated is referred to as a host language. A document containing animation elements is referred to as a host document. Animation is inherently time-based. SMIL Animation is defined in terms of the SMIL timing model. The animation capabilities are described by new elements with associated attributes and semantics, as well as the SMIL timing attributes. Animation is modeled as a function that changes the presented value of a specific attribute over time. The timing model is based upon SMIL 1.0, with some changes and extensions to support interactive (event-based) timing. SMIL Animation uses a simplified 'flat' timing model, with no time containers (like <par> or <seq>). This version of SMIL Animation may not be used with documents that otherwise contain timing." The SMIL Animation specification has been produced as part of the W3C Synchronized Multimedia Activity. The document has been written by the SYMM Working Group working with the SVG Working Group. The goals of the SYMM group are discussed in the SYMM Working Group charter. This specification is a revision of the 'Last Call Working Draft' SMIL Animation of 28-January-2000, incorporating editorial suggestions received in review comments. Before the Working Group will consider moving this document to Candidate Recommendation stage, additional changes are still required to align this draft with the developments in SMIL Boston. Specifically, requested revisions to the 'Last Call Working Draft' included incorporation of some of the advanced timing features of SMIL Boston which were still being developed at the time of publication of this draft. For related references, see "Synchronized Multimedia Integration Language (SMIL)." [July 31, 2000] XML-Based File Formats to be Developed in Sun's StarOffice Technology. A recent announcement by Sun Microsystems, Inc. at the O'Reilly Open Source Convention describes plans to "work with the leaders of the free software and open source community to make the source code for its StarOffice software suite freely available under the GNU General Public License (GPL). In addition, Sun will commit the efforts of its development team, as well as the resources of a $14 billion global company, to work side by side with members of the community to continue to develop the code at OpenOffice.org." Sun announced that "it will release the source code of its StarOffice Suite, a leading, high quality, office productivity application software suite, to the open source community under the GNU General Public License (GPL). Much like Linux vendors distribute packaged versions of the free operating system, Sun will continue to drive the development of the OpenOffice.org source code and distribute its own certified, StarOffice branded version of the OpenOffice.org software for free. To ensure consumer confidence and promote uniformity, OpenOffice.org will also allow other companies the opportunity to license the source for commercial release under a royalty-free Sun Industry Standards Source License (SISSL) that requires only that they maintain compatibility with the GPL reference implementation. Companies that meet this requirement may also qualify for and license the StarOffice brand for use on their product. . . Sun also announced OpenOffice.org will be formed and managed by Collab.Net and will serve as the coordination point for the source code, the definition of XML-based file formats, and the definition of language-independent office application programming interfaces (APIs.) OpenOffice.org will host StarOffice source code. OpenOffice.Org will also specify XML file formats for documents; specify language-independent APIs; and provide Microsoft Office file filters, so developers can more easily modify existing programs and customize specific applications to fit their needs. StarOffice is a leading, full-featured productivity suite for all major platforms, including Solaris Operating Environment, Windows, Linux, and, later in the year, the Macintosh. StarOffice 6, the next version currently in development, will serve as the source code base for OpenOffice.org. With the upcoming StarOffice 6 technology, the next generation architecture of separate applications and componentized services will be introduced." For details, see (1) the full text of the announcement: "Sun Microsystems Opens StarOffice Technology. Source Code Offered Via GNU General Public License and to Reside at www.OpenOffice.org."; (2) the notes and licensing terms for developers; and (3) the announcement from September 01, 1999: - "Sun Microsystems Offers Free StarOffice Productivity Suite." [July 31, 2000] XML-DBMS Available as a Perl Module. Ronald Bourret (Technical University of Darmstadt) announced the availability of a PERL version of XML-DBMS: "Nick Semenov has ported XML-DBMS to PERL. XML-DBMS is middleware for transferring data between XML documents and relational databases. . . XML-DBMS views the XML document as a tree of objects in which element types are generally viewed as classes and attributes and PCDATA as properties of those classes. It then uses an object-relational mapping to map these objects to the database. An XML-based mapping language is used to define the view and map it to the database. XML-DBMS preserves the hierarchical structure of an XML document, as well as the data (character data and attribute values) in that document. If requested, it also preserves the order in which the children at a given level in the hierarchy appear. (For many data-centric applications, such order is not important and the code runs faster without it.) Because XML-DBMS seeks to transfer data, not documents, it does not preserve document type declarations, nor does it preserve physical structure such as entity use, CDATA sections, or document encodings. In particular, it does not attempt to implement a document management system on top of a relational database. XML-DBMS is available both as a set of Java packages and as a PERL module." Perl XML-DBMS is now available on the XML-DBMS home page. In this connection, see also Ron Bourret's informative document XML and Databases" and his "XML Database Products." [July 29, 2000] Learning Material Markup Language (LMML). A recent communiqué from Christian Süss (Forschungsgruppe Datenbanken, Universität Passau) reports on the ongoing development of the Learning Material Markup Language (LMML). LMML is "an implementation of the XML binding of the teachware-specific meta-model described in Christian Süss, A Meta-Modeling Adaptive Knowledge Management: Approach and its Binding to XML (2000). As an instance of this framework you can find here the Learning Material Markup Language for Computer Science (LMML-CS), a language for specifying teachware from the domain of application of teaching and learning computer science as described in Christian Süss, Burkhard Freitag, Peter Brössler, Metamodeling for Web-Based Teachware Management (1999)." The project web site supplies relevant Document Type Definitions (DTDs), samples, and documentation. For additional references, see the LMML web site and "Learning Material Markup Language (LMML)." [July 11, 2000] W3C Speech Recognition Grammar Specification. The first public working draft version of a 'Speech Recognition Grammar Specification' has been issued by the W3C Voice Browser Working Group as part of the W3C Voice Browser Activity, viz.: Speech Recognition Grammar Specification for the W3C Speech Interface Framework. Reference: W3C Working Draft 10-July-2000, edited by Andrew Hunt (SpeechWorks International) and Scott McGlashan (PipeBeach). Abstract: "This document defines syntax for representating grammars for use in speech recognition so that developers can specify the words and patterns of words to be listened for by a speech recognizer. The syntax of the grammar format is presented in two forms, an augmented BNF syntax and an XML syntax. The specification intends to make the two representations directly mappable and allow automatic transformations between the two forms. The W3C Voice Browser Working Group is seeking input on whether the final specification should include both forms or be narrowed to a specific form." Description: "This document defines the syntax for grammar representation. The grammars are intended for use in speech recognition so that developers can specify the words and patterns of words to be listened for by a speech recognizer. The syntax of the grammar format is presented in two forms, an augmented BNF syntax and an XML syntax. The specification intends to make the two representations directly mappable and allow automatic transformations between the two forms. The W3C Voice Browser Working Group is seeking input on whether the final specification should include both forms or be narrowed to a specific form. Augmented BNF syntax (ABNF): this is a plain-text (non-XML) representation which is similar to traditional BNF grammar and to many existing BNF-like representations commonly used in the field of speech recognition including the JSpeech Grammar Format from which this specification is derived. Augmented BNF should not be confused with Extended BNF which is used in DTDs for XML and SGML. XML: This syntax uses XML elements to represent the grammar constructs and adapts designs from the PipeBeach grammar (W3C Members only), TalkML and a research XML variant of the JSpeech Grammar Format. Section 5 outlines area of Future Study around Grammar representations for speech recognition. In addition to the decision about supporting an XML form, the ABNF form or both, the committee is currently considering a proposal for representing statistical language models -- specifically "n-grams" -- that are used in many speech recognition systems. The W3C Standard is known as the Speech Recognition Grammar Specification and is based upon the JSGF specification, which is owned by Sun Microsystems." See related references in "Java Speech Markup Language (JSML/JSpeech)." [July 10, 2000] Revised W3C Working Draft for Scalable Vector Graphics (SVG). The SVG Working Group has released a revised working draft for the Scalable Vector Graphics (SVG) 1.0 Specification as part of the W3C Graphics Activity, Reference: W3C Working Draft 29-June-2000, edited by Jon Ferraiolo (Adobe). Abstract: "This specification defines the features and syntax for Scalable Vector Graphics (SVG), a language for describing two-dimensional vector and mixed vector/raster graphics in XML. [...] SVG allows for three types of graphic objects: vector graphic shapes (e.g., paths consisting of straight lines and curves), images and text. Graphical objects can be grouped, styled, transformed and composited into previously rendered objects. The feature set includes nested transformations, clipping paths, alpha masks, filter effects and template objects. SVG drawings can be interactive and dynamic. Animations can be defined and triggered either declaratively (i.e., by embedding SVG animation elements in SVG content) or via scripting. Sophisticated applications of SVG are possible by use of supplemental scripting language with access to SVG's Document Object Model (DOM), which provides complete access to all elements, attributes and properties. A rich set of event handlers such as onmouseover and onclick can be assigned to any SVG graphical object. Because of its compatibility and leveraging of other Web standards, features like scripting can be done on XHTML and SVG elements simultaneously within the same Web page. SVG is a language for rich graphical content. For accessibility reasons, if there is an original source document containing higher-level structure and semantics, it is recommended that the higher-level information be made available somehow, either by making the original source document available, or making an alternative version available in an alternative format which conveys the higher-level information, or by using SVG's facilities to include the higher-level information within the SVG content. The SVG XML DTD is provided in Appendix A of the working draft; discussion pertaining to the specification may be read in the archives of the public mailing list." "Status: This working draft attempts to address most of the review comments that were received during the second Last Call period, which started 3 March 2000, and also incorporates other modifications resulting from continuing collaboration with other working groups and continuing work within the SVG working group. Among the areas of the specification that are known to require further work are the text, font, animation chapters and any sections relating to events. Most of the further work is expected to be primarily editorial in nature with few further changes to the language itself. Depending on feedback to this draft, the goal is to publish a Candidate Recommendation soon once outstanding issues are addressed." See "W3C Scalable Vector Graphics (SVG)." [July 05, 2000] Smalltalk Interchange Format in XML (SMIX). Masashi Umezawa is developing 'Smalltalk Interchange Format in XML (SMIX)' as "a new Smalltalk Interchange Format. It is basically based on the ANSI Smalltalk Interchange Format (version 1.0)." The web site provides a SMIX XML DTD, a sample XML document, and an alpha version of a simple SMIX generator. The author's Dandelion tool will generate SMIX format. Dandelion is "a generic Smalltalk code analysis/output framework; you can analyze your code and output the information in various formats." See the SMIX web site for other references. See XML.smalltalk.org for other references to 'Smalltalk and XML'. [SMIX DTD, cache] [July 05, 2000] W3C XSL Working Group is Rechartered. The W3C XSL Working Group, as part of the W3C User Interface Domain and participant in the Style Sheets Activity, has recently published a new charter. The document supplies detailed [public] information on the working group's Primary deliverables, Duration and Milestones, Relationship to other W3C activities, Liaison with groups outside the W3C, etc. Excerpt: "The XSL Working Group is chartered to continue the development of XSL (extensible stylesheet language), a style sheet and transformation language for XML and other structured markup languages. The overall goal of this work is to define a practical style and transformation language capable of supporting the transformation and presentation of, and interaction with, structured information (e.g., XML documents) for use on servers and clients. The language is designed to build transformations in support of browsing, printing, interactive editing, and transcoding of one XML vocabulary into another XML vocabulary. To enhance accessibility, XSL is able to present information both visually and non-visually. XSL is not intended to replace CSS, but will provide functionality beyond that defined by CSS, for example, element re-ordering. The intent of the XSL effort is to define a style specification language that covers at least the formatting functionality of both CSS and DSSSL. The intent is also that within XSL, the formatting properties and values of CSS can be used with their current meaning. Where the functionality of CSS and XSL overlap, the style information shall be exportable in both XSL and CSS. As the XSL activity goes forward, the formatting model will be extended as a joint effort of the CSS and XSL working groups. XSL is constituted of three main components, a transformation language known as XSLT, an expression language for addressing parts of XML documents, known as XPath, and a vocabulary of formatting objects with their associated formatting properties. . . [Some of the deliverables under the renewed charter include deliverables of the XSL WG are:] (1) A specification of the Extensible Stylesheet Language, version 1.0, as a Recommendation (2) A requirements document for the next version of XSL, XSLT, and XPath covering the transformation language (XSLT), the addressing language (XPath), and the formatting objects and properties (3) A specification of XSLT 2.0 and XPath 2.0. Note that it is anticipated that there will be some joint development and coordination with the XML Query WG on issues related to compatibility and extensions. (4) A specification of version 2.0 of formatting objects. For the complete text, see the XSL Working Group Charter document. [July 04, 2000] NISO's XML DTD for Digital Talking Books (DTB). An XML DTD for Digital Talking Books (DTB) has been made available for review by the Digital Talking Book Standards Committee of The National Information Standards Organization (NISO). A NISO Digital Talking Book (DTB) "is envisioned to be, in its fullest implementation, a group of digitally-encoded files containing an audio portion recorded in human speech; the full text of the work in electronic form, marked with the tags of a descriptive markup language; and a linking file that synchronizes the text and audio portions. The Digital Talking Book 3.0 provides the means to package a published book with the combination of professional narration, navigation into that narration, and the text of the book marked with tags to convey its structure, content, and metadata about the book and its structure. The XML Document Type Definition (DTD) defines the allowable element types and their attributes that can be used to markup the text of the book sufficiently that textual material can be synchronized with the professionally narrated version of that book. The synchronization can permit concurrent display of the text being narrated, and the textual material can be searched to locate material desired for narration. This application of XML is the next generation after the DAISY 2.0 DTD, for the Digital Audio-based Information System. That application developed a Navigation Control Center (NCC) for synchronizing document structure with narration. The NCC will become another XML application derived from the markup of documents tagged using the dtbook3 DTD. Richer structuring capability is one of the objectives of this DTD. The Synchronized Multimedia Integration Language (SMIL) 1.0 will be used. . ." For description and references, see "NISO Digital Talking Books (DTB)." [July 03, 2000] XML Linking Language (XLink) Advanced to W3C Candidate Recommendation. The W3C specification XML Linking Language (XLink) Version 1.0 has been promoted to the status of Candidate Recommendation. Reference: W3C Candidate Recommendation 3-July-2000. Edited by Steve DeRose (Brown University), Eve Maler (Sun Microsystems), David Orchard, and Ben Trafford (Yomu). The specification "is considered stable by the XML Linking Working Group and is available for public review during the Candidate Recommendation stage ending 3 October 2000." Feedback from the 'Last Call' review has been analyzed, and the disposition of comments is available on-line; further comments on implementation of the CR specification may be sent to the public mailing list or to the XML Linking Working Group Chairs (Eve Maler, Daniel Veillard). Abstract: "This specification defines the XML Linking Language (XLink), which allows elements to be inserted into XML documents in order to create and describe links between resources. It uses XML syntax to create structures that can describe links similar to the simple unidirectional hyperlinks of today's HTML, as well as more sophisticated links." Description: "This specification defines the XML Linking Language (XLink), which allows elements to be inserted into XML documents in order to create and describe links between resources. XLink provides a framework for creating both basic unidirectional links and more complex linking structures. It allows XML documents to: (1) Assert linking relationships among more than two resources; (2) Associate metadata with a link; (3) Express links that reside in a location separate from the linked resources. . . The model defined in this specification shares with HTML the use of URI technology, but goes beyond HTML in offering features, previously available only in dedicated hypermedia systems, that make hyperlinking more scalable and flexible. Along with providing linking data structures, XLink provides a minimal link behavior model; higher-level applications layered on XLink will often specify alternate or more sophisticated rendering and processing treatments. Integrated treatment of specialized links used in other technical domains, such as foreign keys in relational databases and reference values in programming languages, is outside the scope of this specification. An XLink link is an explicit relationship between resources or portions of resources. It is made explicit by an XLink linking element, which is an XLink-conforming XML element that asserts the existence of a link. There are six XLink elements; only two of them are considered linking elements. The others provide various pieces of information that describe the characteristics of a link. (The term 'link' as used in this specification refers only to an XLink link, though nothing prevents non-XLink constructs from serving as links.) When a link associates a set of resources, those resources are said to participate in the link. Even though XLink links must appear in XML documents, they are able to associate all kinds of resources, not just XML-encoded ones..." For related W3C specifications, see (1) the W3C overview "XML Pointer, XML Base and XML Linking" and (2) "XML Linking Language." [July 02, 2000] Thai Open Source Software Center. A web site of potential interest to the XML development community is 'The Thai Open Source Software Center,' which "is being established as a center for the development of open source software in Thailand. The aim of the Center is not so much to adapt existing software to Thai needs but to develop new, world-class open source software. The Director of the Center is James Clark. The Center will assume distribution and maintenance of all James Clark's existing software. We aim to develop software that is: (1) useful, (2) high-quality, (3) internationalized, (4) cross-platform, (5) standards-based (W3C, IETF or ISO). We expect to focus initially on text-processing software. We plan to use XML pervasively. Our policy towards the commercial software world is one of peaceful coexistence. We will use the MIT license, which allows unrestricted commercial use of the software. We are recruiting staff." A recent offering is a "12-May-00 01:11" version of expat. [from James Clark]
What Was New in 1995 - 2000
Other SGML/XML news items recorded for 1995 and later may be found in separate online documents:
|








 | Receive daily news updates from Managing Editor, Robin Cover.

 |
|


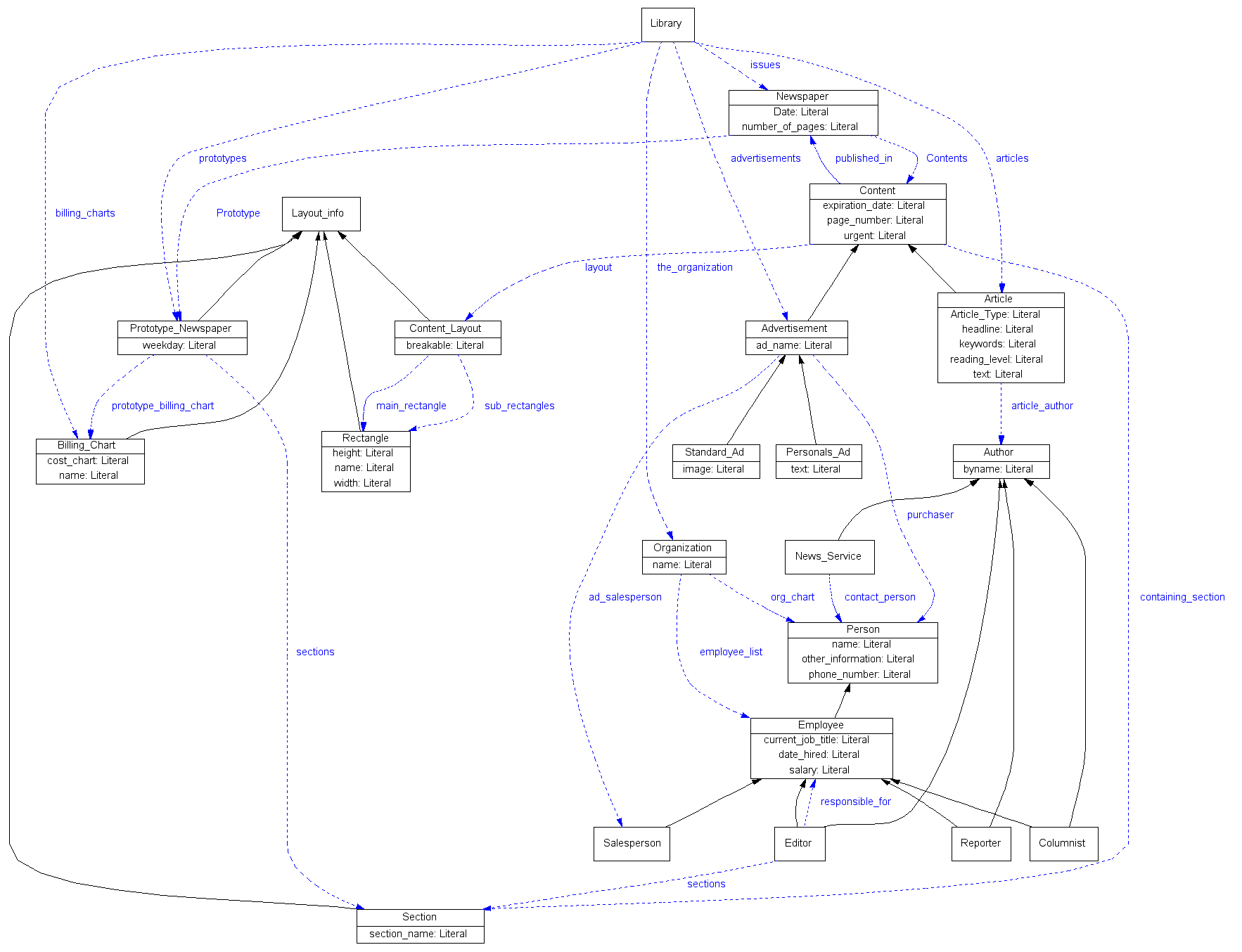{kind=link}
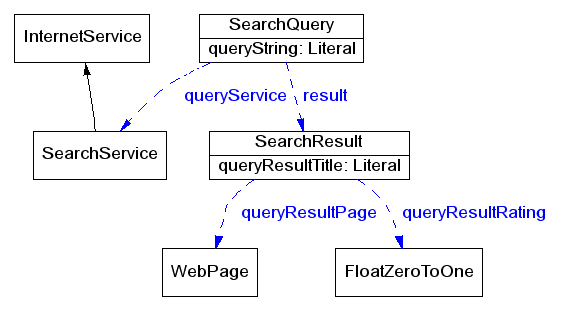{kind=link}
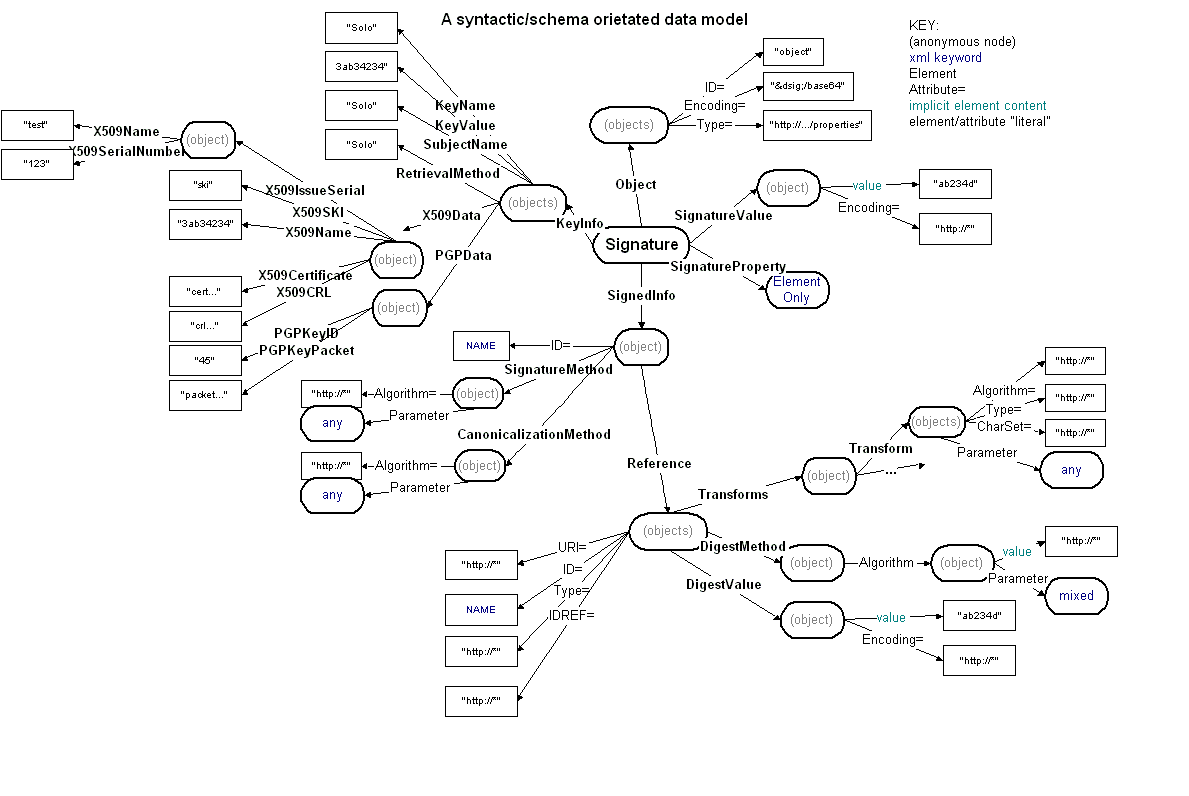{kind=link}