
XML General Articles and Papers: Surveys, Overviews, Presentations, Introductions, Announcements
References to general and technical publications on XML/XSL/XLink are also available in several other collections:
- XML Article Archive: [Current XML Articles] [July - September 2001] [April-June 2001] [January-March 2001] [October-December 2000] [July-September 2000] [April-June 2000] [January-March 2000] [July-December 1999] [January-June 1999] [1998] [1996 - 1997]
- Articles Introducing XML
- Articles/Press Releases - XML Industry News
- Comprehensive SGML/XML Bibliographic Reference List
The following list of articles and papers on XML represents a mixed collection of references: articles in professional journals, slide sets from presentations, press releases, articles in trade magazines, Usenet News postings, etc. Some are from experts and some are not; some are refereed and others are not; some are semi-technical and others are popular; some contain errors and others don't. Discretion is strongly advised. The articles are listed approximately in the reverse chronological order of their appearance. Publications covering specific XML applications may be referenced in the dedicated sections rather than in the following listing.
December 2001
[December 31, 2001] "Data Capture: Extending the Net to New Capabilities." By Judith Lamont (Zentek). In KMWorld (January 2002), pages 8-9. "Paper-based forms still pervade the business world, despite the growth of online data capture. Account applications, invoices, taxes and a multitude of other forms remain largely paper-based. Major enterprises such as insurance companies and financial institutions have made significant commitments to dealing with this paper through automated data capture, scanning in forms to back-end systems. But U.S. companies, particularly small to midsize organizations, still spend billions of dollars each year keying in data. The cost of that work is estimated at $15 billion per year... The ability to handle Extensible Markup Language (XML) is a feature that most data capture companies have been adding to their repertoire. XML is becoming the de facto common language that can cross the lines between different enterprises, supporting e-commerce and other e-business initiatives. InputAccel from ActionPoint, for example, is geared for mid- to high-end applications and can convert scanned data to XML for delivery to back-end systems. After optical character recognition (OCR), the data is converted to the designated output format and directed by the InputAccel server to the appropriate repository. Data from a form can be split up so that one field is indexed and stored in a document management system, while another, such as order status information, is converted to XML for ready deployment on the Web... XML can also be captured at the front end. Ascent Capture from Kofax can import XML, printstream and other input, and convert it to an image. The image is then put through the OCR process and output in the desired format... Anything that can talk to XML, such as enterprise resource planning (ERP), can also talk to AscentCapture. Ascent Capture exports 50 different formats, including XML; data can be sent to FileNet, Documentum, and IBM's Content Manager, as well as to repositories of software products from many smaller firms. AscentCapture is also tightly integrated with Microsoft's newly introduced SharePoint. One of Kofax's strengths is an improved scanning method called virtual rescan (VRS), which was shown by Doculabs to produce a 35% increase in character and field recognition accuracy. The process evaluates the scanned images in real time and adjusts for brightness, contrast and other characteristics. VRS provides images that are easier to read, which also facilitates keying from image, and improves recognition significantly during the OCR process. Because the image quality is higher, users rarely need to rescan images, a time-consuming and expensive process. Datacap converts all intermediate data from OCR and intelligent character recognition (ICR) into XML format in its Task Master 5.0 three-tier (client, server and browser) capture environment. The data remains in XML while operations such as verification and corrections are performed. It can then be retained in XML or readily converted to some other format..."
[December 31, 2001] "Ubiquitous Web Services." By Maggie Biggs. In InfoWorld Issues 52/53 (December 24-31, 2001), page 31. "Web services hold significant promise for enterprises that need a better strategy for integrating enterprise applications and data with those of business partners. Combining the cross-platform strengths of Java with available XML-based Web services technologies provides a smooth path to rapid Web services deployments. This week, the Test Center examines three solutions that leverage the Java platform and Web services. We found that Java solution providers are well-prepared to support Web services in the enterprise with solutions that are economical as well as highly productive to use. For example, Borland's JBuilder 6, combined with its Web Services Kit, provides a fast path to SOAP (Simple Object Access Protocol), WSDL (Web Services Description Language), and UDDI (Universal Description, Discovery, and Integration). Likewise, Oracle9i JDeveloper 4 -- part of the Oracle9i Developer Suite -- provides tools that developers can use to rapidly create and deploy Web services. For example, programmers can use Oracle9i JDeveloper tools to easily generate WSDL from Java classes. SilverStream is also jumping on the Web services bandwagon with its SilverStream eXtend Workbench 1.1, which offers developers a wizard-based approach to Web services creation and deployment. These three solutions are but a few of the Java-based solutions already available across all tiers that can help enterprises rapidly roll out Web services..."
[December 31, 2001] "Oracle Spells Services." By Maggie Biggs.. In InfoWorld Issues 52/53 (December 24-31, 2001), page 33. "As enterprise it strategists hone their plans for Web services, corporate developers must begin working with tools that will let them rapidly create and deploy them. For Java-based enterprises, a plethora of tools is available that can speed up Web-services implementations. One such solution is Oracle9i JDeveloper 4, part of Oracle's Oracle9i Developer Suite. The newest release of Oracle's Java IDE (integrated development environment) sports several new additions that ease Web-services creation and deployment...When developers get JDeveloper navigation down, they will find several compelling additions in this release. Chief among these is new support for creating and deploying Web services. The IDE includes a Web Services Publishing wizard that helps developers create deployment descriptors and the WSDL (Web Services Description Language) necessary to publish Web services. We were able to quickly define which classes we wanted to publish as Web services, but we could deploy only to Oracle9i Application Server and Apache SOAP (Simple Object Access Protocol) Server with the default options presented in the IDE. As does JBuilder, JDeveloper 4 includes integrated support for UML (Unified Modeling Language) diagrams. Developers can quickly create activity or class diagrams. We constructed several class diagrams and found that JDeveloper's UML support is on par with that of JBuilder. Developers will be able to use the UML facilities to tighten up application and Web services designs... Oracle9i JDeveloper 4 also includes support for Javadoc, the tool created by Sun Microsystems to produce HTML-formatted code documentation, allowing developers to generate Javadoc files from the IDE. Moreover, the Oracle IDE includes support for rename and move refactoring. We found both the Javadoc and refactoring support to be on par with rivals such as JBuilder... New developers and those who may not be accustomed to using an IDE may have a tough time getting ramped up with Oracle9i JDeveloper 4. Nonetheless, available JDeveloper facilities that support Web services, XML, SQL , and J2EE development are quite compelling. Enterprises that need to move quickly on implementing Web services should give Oracle9i JDeveloper 4 a look..."
[December 31, 2001] "Web Services Wizardry." By James R. Borck.. In InfoWorld (December 21, 2001). "... Silverstream has taken hits from some early adopters of its application server because they found ROI elusive due to the solution's highly proprietary nature and limited feature set. The latest iteration has made vast improvements from previous iterations, boasting many enhanced enterprise features. It also supports deployment to other J2EE-compliant application servers, such as BEA WebLogic, Oracle9i, IBM WebSphere, and Jakarta Tomcat, to increase your options. Workbench lacks some of the editing and debugging sophistication found in competing products such as Borland's JBuilder and Delphi. We also would have preferred to see some additional tools for easing XML manipulation efforts... The IDE (integrated development environment) is bundled with jBroker Web, Silverstream's compiler, and SOAP (Simple Object Access Protocol) run-time engine for processing and invoking XML-based remote procedure calls. It was all up and running with minimal effort. Workbench meets compatibility requirements to operate with Web services standards, including SOAP, XML, UDDI (Universal Description, Discovery, and Integration), and WSDL (Web Services Description Language), and it delivers a battery of time-saving tools, editors, and wizards that we found greatly simplified the development process. Wizards facilitated the creation and editing of WSDL files, a UDDI manager offered easy registry querying and publishing, and the Web services wizard enabled us to easily create Web services-ready applications from Java classes, EJBs (Enterprise JavaBeans), and WSDL files. We were immediately comfortable in the structured, J2EE archive environment available to manage projects. Here too, wizards offered timesaving capabilities, speeding many tasks of J2EE development from archive creation to generating deployment descriptors. Workbench can create and package entity and session beans, produce servlet skeletons, JSP (Java Server Pages) code, and create new Java classes, and in our tests, it delivered fast deployment capabilities equally well to both our Silverstream application server and BEA WebLogic. Further, jBroker Web performed particularly well, processing SOAP requests with a remarkable speed that was noticeably faster than in comparable tests using the Apache SOAP server for parsing..." See also "SilverStream Releases UDDI Directory."
[December 31, 2001] "Character Model for the World Wide Web 1.0." W3C Working Draft 20-December-2001. Interim Working Draft. Version URL: http://www.w3.org/TR/2001/WD-charmod-20011220. Latest version URL: http://www.w3.org/TR/charmod. Edited by Martin J. Dürst (W3C), François Yergeau (Alis Technologies), Richard Ishida (Xerox, GKLS), Misha Wolf (Reuters Ltd.), Asmus Freytag (ASMUS, Inc.), and Tex Texin (Progress Software Corp.). "This Architectural Specification provides authors of specifications, software developers, and content developers with a common reference for interoperable text manipulation on the World Wide Web. Topics addressed include encoding identification, early uniform normalization, string identity matching, string indexing, and URI conventions, building on the Universal Character Set, defined jointly by Unicode and ISO/IEC 10646. Some introductory material on characters and character encodings is also provided." See (1) the W3C Internationalization Activity and (2) "XML and Unicode." [cache]
[December 31, 2001] "The ANTACID Replication Service: Protocol and Algorithms." By Michael F. Schwartz [WWW]. IETF Network Working Group, Internet-Draft. Reference: draft-schwartz-antacid-protocol-00. Date: October 7, 2001, Expires: April 7, 2002. See the following bibliographic item for the ARS Rationale and Architecture. ['This memo specifies the protocol and algorithms of the ANTACID Replication Service, designed to replicate hierarchically named repositories of XML documents for business-critical, internetworked applications.'] "This document specifies the protocol and algorithms used to implement the ANTACID Replication Service (ARS). Readers are referred to "The ANTACID Replication Service: Rationale and Architecture" [IETF 'draft-schwartz-antacid-service-00'] for a motivation of the problem addressed, the replication architecture, and terminology used in the current document. The current document assumes the reader has already read that document, and that the reader is familiar with XML. Moreover, since the ARS protocol is defined in terms of a BEEP profile, readers are referred to that document for background... We begin in Section 2 by walking through example ARS interactions, to give the reader a concrete flavor for how the protocol works. We then (Section 3) present the ARS syntax and semantics, and then provide algorithms and implementation details..." See the XML DTDs from Appendices D - I. See also: "Blocks eXtensible eXchange Protocol Framework (BEEP)." [cache, alt URL]
[December 31, 2001] "The ANTACID Replication Service: Rationale and Architecture." By Michael F. Schwartz [WWW]. IETF Network Working Group, Internet-Draft. Reference: 'draft-schwartz-antacid-service-00'. Date: October 7, 2001, Expires: April 7, 2002. See also the preceding entry. ['This memo presents the ANTACID Replication Service, which replicates hierarchically named repositories of XML documents for business- critical, internetworked applications.'] "In this document we present the motivation, design rationale, and architecture for the ANTACID Replication Service (ARS). ARS replicates repositories of hierarchically-named, well-formed XML documents in a manner that supports business-critical, internetworked applications (BCIAs). The ARS protocol and algorithmic details are defined in a companion document. By 'business-critical' we mean applications requiring stronger data coherence guarantees than file-by-file replication, but weaker than global ACID semantics (i.e., Atomic, Consistent, Isolated, Durable semantics spanning all replicas). Our motivation is that many commercial services require coherence guarantees for replicated data, but that global ACID semantics are not appropriate across the Internet because: (1) global ACID semantics don't scale (a point we will discuss in more depth later); and (2) applications requiring global ACID semantics (e.g., banking) often require privately owned, centrally controlled infrastructure rather than the open Internet. The 'ANTACID' part of ARS refers to data coherence semantics we define later in this document, which we believe are well suited to BCIAs... The current effort seeks to define a standard capable of replicating data for use by BCIA's, allowing a robust service to be deployed by configuration rather than custom development/integration. The current effort also seeks to incorporate lessons learned over the past 20 years from both the RDBMS and the IETF worlds. Both the protocol and the data units replicated by ARS are XML-based because we're betting on XML to become a dominant means of structuring data on the Internet..." [cache, alt URL]
[December 31, 2001] "The application/rss+xml Media Type." By Mark Nottingham (Burlingame, CA). IETF Network Working Group, Internet-Draft. Reference: 'draft-nottingham-rss-media-type-00'. Date: October 23, 2001. Expires: April 23, 2002. ['This document specifies the Media Type for the RSS format. RSS allows lists of information to be exchanged in an XML-based format.'] "RSS is a lightweight, multipurpose, extensible metadata description and syndication format. RSS is an XML application. RSS is currently used for a number of applications, including news and other headline syndication, weblog syndication, and the propogation of software update lists. It is generally used for any situation when a machine-readable list of textual items and/or metadata about them needs to be distributed. There are a number of revisions [.9, .91, .92, 1.0] of the RSS format defined, many of which are actively used. This memo defines a media type, application/rss+xml for all versions of RSS..." Note: Mark Nottingham also created xpath2rss [XPath-based HTML-to-RSS scraper] and MoinRSS [extension to MoinMoin to allow it to produce an RSS v1.0 feed] for RSS news feed creation. See "RDF Site Summary (RSS)." [cache]
[December 29, 2001] "XHTML+Voice Profile 1.0." W3C Note 21-December-2001. Edited by Jonny Axelsson (Opera Software), Chris Cross (IBM), Håkon W. Lie (Opera Software), Gerald McCobb (IBM), T. V. Raman (IBM), and Les Wilson (IBM). Latest Version URL: http://www.w3.org/TR/xhtml+voice. "This note outlines how a set of mature WWW technologies including XHTML 1.1, VoiceXML 2.0, Speech Synthesis Markup Language, Speech Recognition Grammar Format, and XML-Events can be integrated using XHTML modularization to bring spoken interaction to the WWW. The design leverages open industry APIs like the W3C DOM to create interoperable web content that can be deployed across a variety of end-user devices. Multiple modes of interaction are synchronized and integrated using the DOM2 Events model and exposed to the content author via XML Events... Profile XHTML+Voice brings spoken interaction to standard WWW content by integrating a set of mature WWW technologies such as XHTML and XML Events with XML vocabularies developed as part of the W3C Speech Interface Framework. The profile includes voice modules that support speech synthesis, speech dialogs, command and control, speech grammars, and the ability to attach Voice handlers for responding to specific DOM events, thereby re-using the event model familiar to web developers. Voice interaction features are integrated directly with XHTML and CSS, and can consequently be used directly within XHTML content. The XHTML+Voice profile is designed for Web clients that support visual and spoken interaction. To this end, this document first re-formulates VoiceXML 2.0 as a collection of modules. These modules, along with Speech Synthesis Markup Language and Speech Recognition Grammar Format are then integrated with XHTML using XHTML modularization to create the XHTML+Voice profile. Finally, we integrate the result with module XML-Events so that voice handlers can be invoked through a standard DOM2 EventListener interface..." See also the XML DTD and XML Schema.
[December 29, 2001] "Covisint to Start Auto Industry Initiative to Adopt ebXML and XML Schemas." By Ephraim Schwartz. In InfoWorld (December 27, 2001). "Soon after the new year begins, Covisint, the giant automotive industry exchange, will formally announce its intention to adopt a version of XML sponsored by international standards bodies as its standard document transport technology. The ebXML (e-business XML) specification is an XML-based standard in development that aims to facilitate the use of XML for e-business transactions, including messaging, data exchange, and registration of business processes. The project is sponsored by the United Nations body for Trade Facilitation and Electronic Business (UN/CEFACT) and the Organization for the Advancement of Structured Information Standards (OASIS) and was launched in September 1999. Covisint will continue to support the many versions of XML, but it will standardize its own systems around ebXML, said Tom Hill, a spokesman for Covisint... Hill also said suppliers using Covisint need not fear that their investment in EDI (electronic data interchange), an older standard that many thousands of suppliers in the auto industry continue to use, will not be accepted if they want to work with Covisint... In addition, Hill said the exchange intends to work more closely with the major standards bodies, such as the OAG, to set global standards for the auto industry." See other details in the eWEEK article cited below, and: (1) "Open Applications Group"; (2) "Electronic Business XML Initiative (ebXML)."
[December 28, 2001] "LEXML: A Network Community for XML and the Law." By Cecilia Magnusson Sjöberg (Professor of Law and IT, Faculty of Law, Stockholm University; email: [email protected]). In InterChange [ISUG Newsletter] Volume 7, Number 4 (December 2001), pages 8-10. The article surveys recent efforts to coordinate law-related XML activities, including the LEXML communities. LEXML has been confirmed as the 'European Network for XML' in the legal domain, as explained by Cecilia Magnusson Sjöberg. From the mission statement announced at the Berlin XML 2001 meeting: "(1) LEXML has been established to serve the growing interest in automated exchange of legal data. It serves as an open forum for the legal domain to exchange ideas and experiences associated with XML and related core standards. (2) LEXML is a point of co-ordination and a workforce for the development of standardized structures, vocabularies and data exchange tools. Lexml pursues its goals in particular through the development of a global legal data model and the development of an open source legal office program, which speaks and understands XML. (3) LEXML is a network of independently organised communities, which may be jurisdiction oriented (like Austria, Germany, Netherlands, Sweden) or subject-matter oriented. It is decentralized, with a peer to peer approach. Anyone can start a LEXML community. (4) LEXML may also be described as a network of websites linked together so as to compose a true information resource within the European legal domain. The communities stay in contact through mailinglists, meetings and by jointly working on cross-jurisdictional projects." Web sites have been set up in Austria, the Netherlands, and Germany; a Swedish LEXML site is also being constructed. For other references, see the papers presented at the Berlin meeting (May 2001). See also the "Legal XML Working Group."
[December 28, 2001] "Covisint Crafts XML Schema." By Renee Boucher Ferguson. In eWEEK (December 24, 2001). ['The auto industry e-marketplace will adopt OASIS' ebXML framework standard and align with the OAG to create an XML schema for the auto industry.'] "Covisint LLC, the auto industry e-marketplace backed by such heavyweights as DaimlerChrysler, Ford Motor Co. and General Motors Corp., is making decisive standards moves to improve efficiencies for its members. The Southfield, Mich., company will announce during the first week of January that it has aligned with the Organization for the Advancement of Structured Information Standards and will adopt that group's ebXML (Electronic Business XML) messaging standard. In addition, Covisint plans to announce in the first quarter that it has aligned with the Open Applications Group Inc. standards body to create an XML schema for the auto industry. Sponsored by two standards bodies, OASIS and the United Nations Centre for Trade Facilitation and Electronic Business, ebXML is a modular suite of specifications that provides a messaging and enveloping standard for companies to exchange electronic business messages, communicate data in common terms, and define and register business processes. Covisint currently receives XML purchase orders from DaimlerChrysler, Ford and GM, but they are received in three different flavors. Covisint also receives electronic data interchange documents from other members that are also enveloped in a variety of flavors. What Covisint is attempting to do with ebXML is define a standard envelope as well as a standard payload, according to Jeffrey Cripps, the company's director of industry relations. An XML schema is a data structure for documents that not only defines the syntax of a document -- what a field is called -- but also defines semantics, or what a specific field means. Cripps said the exchange seeks to create for the auto industry a schema for a global dictionary that can be used for interoperability among vertical markets--a huge gap in business-to-business. While aligning with ebXML is a significant move for the exchange, Covisint's work with the OAG could prove even more worthwhile by enabling it to develop proprietary standards for the automotive industry under the umbrella of an open-standards group, officials said. Cripps is in talks with the action groups of the North American and European automotive industries -- Automotive Industry Action Group and Odette, respectively -- to see if they will join Covisint and the OAG in developing the schema for the industry..." See: (1) "Open Applications Group"; (2) "Electronic Business XML Initiative (ebXML)."
[December 21, 2001] "Sun Adds Web Services to J2EE." By Matt Berger. In InfoWorld (December 17, 2001). "Sun Microsystems has brought its Java enterprise server platform up to speed with emerging Web services standards, releasing a set of extensions that allow developers to build and run XML applications on the Java platform. The Java XML Pack is the first certified release of Web services tools for J2EE (Java 2, Enterprise Edition), the server software platform that is based on the Java programming language. Java developers already have some tools provided by the open-source community that allow them to build XML-based Web services for J2EE, said Karen Shipe, a product manager with Sun's Java XML group. But Sun's release Monday is the first such technology that has gone through the Java certification process... Formerly known as the JAX Pack before Sun was forced to change the name due to a copyright conflict, the Java XML Pack adds capability for XML messaging and data binding, as well as remote procedure calls using SOAP (Simple Object Access Protocol). The Web services pack is missing support for the UDDI (Universal Description, Discovery, and Integration) directory as well as WSDL (Web Services Description Language), two standard pieces of the Web services puzzle. Sun plans to add support for those additional standards in a software download that will be available from the company within 30 days, Shipe said. Makers of server software products for the J2EE platform -- ranging from BEA Systems to Sun, which has its own iPlanet line of software products -- are racing Microsoft to offer tools for building XML-based Web services. Microsoft's Visual Studio.Net development software, which is still in beta testing, enables developers to build XML Web services to run on the Windows operating system. Sun's technology is aimed mainly at enterprise developers building J2EE applications who are looking to add support for XML and SOAP . Sun is also making the Web services pack available to major tool vendors who will incorporate the standards-based technology into future versions of their Java toolkits. Those toolkits include Sun's Forte for Java, Borland Software's JBuilder, Oracle JDeveloper, and WebGain's Visual Cafe..." See references in the news article.
[December 21, 2001] "IBM Connects Its Software Layers. [Integration.]" By Ed Scannell, Tom Sullivan, and Martin LaMonica. In InfoWorld Issue 51 (December 17, 2001), pages 15-16. ['IBM's focus for middleware growth, the CrossWorlds application integration product, will become IBM's process integration engine in WebSphere. The Xperanto database project, due in 2003, marries structured and unstructured data through XML. Xperanto also marks the materialization of IBM's work on other Web services-related standards such as XQuery and XML Schema. Server-based software such as WebSphere, MQSeries Integrator, and DB2 will gain features allowing them to interoperate more tightly for a wider range of integration among business processes.'] "IBM is embarking on a technical crusade to tie up key elements of its software and drive its users closer to the Holy Grail: business process integration and common access to structured and unstructured data... According to IBM officials, the company is already creating visual business process modeling with a 'microflows' tool in its WebSphere Business Integrator version, due to ship in the first quarter next year. The tool allows developers to visually compose a business process workflow between software systems. At the data level, IBM is hatching Xperanto, a native XML database that is currently in development at IBM's research labs and will function as a subset of the company's DB2 Universal Database, due in the fourth quarter of 2002. Xperanto will act as a dedicated server for information integration and will be packaged as a stand-alone server , as part of DB2 or WebSphere. By using XML and relying on XQL (XML Query Language), Xperanto will be a critical piece of IBM's long-term vision to marry structured and unstructured data... IBM is also stepping up a three-phase initiative to set new Web services standards through the World Wide Web Consortium (W3C). IBM executives believe such a concerted effort to establish Web services standards is necessary to crystallize the Web services vision to integrate applications, information, and business processes. 'We needed to get the acceptance of SOAP (Simple Object Access Protocol) and WSDL (Web Services Description Language), these so-called Phase 1 Web services standards. Unless you have the lower-level plumbing, you can't do upper-level functionality,' said Bob Sutor, director of IBM's e-business standards strategy. Phase 2 technologies, which are expected to be standardized by the end of the second quarter of 2002, comprise security , reliability, and authorization on a more granular level. Phase 3 technologies, which will overlap with the end of Phase 2 and are currently labeled 'enterprise Web services capabilities,' will address workflow, transactions, systems management, and provisioning... IBM, Microsoft, and the Business Process Management Initiative standards group are creating XML-based languages for describing business processes. IBM is proposing WSFL (Web Services Flow Language), which it expects to become a standard in 2002 and the mechanism for manipulating its own business process integration software. Some analysts caution that it will take IBM some time to pull together the far-flung pieces that are part of this initiative..." [XPERANTO 'provides a general and efficient means to (a) store and query XML documents using a relational database system and (b) publish existing relational data as XML documents. Some of the key architectural features of the XPERANTO system are that it provides users with a high-level, declarative, XML query interface, and that it executes XML queries efficiently by pushing most of the computation down to the underlying relational database system.'] See also: "Web Services Flow Language (WSFL)."
[December 21, 2001] "XML Gets Bigger DB2 Role." By John Dodge. In eWeek Volume 18, Number 49 (December 14, 2001), pages 1, 16. "IBM has an all-encompassing data management product on the drawing board that promises to further the company's efforts to marry structured and unstructured data. Known informally inside IBM as the 'information integrator,' or II, the product will combine capabilities from three existing products and add next-generation XML technology, according to Janet Perna, general manager of IBM Data Management Solutions, in Armonk, N.Y. The product enters pilot testing in the first half of next year and will be delivered in 12 to 18 months, Perna said. In a sense, II will be a business coming-out party for two of three existing products, which are largely used in the life sciences industries to search huge disparate database and data sources. They are DiscoveryLink and DB2 Relational Connect, informally known as 'data joiner.' DiscoveryLink allows scientists to access multiple data sources' databases with a single query, while DB2 Relational Connect provides DB2 with native read access to Microsoft Corp.'s SQL Server, Oracle Corp.'s Oracle and Sybase Inc.'s Sybase. The third IBM product -- Enterprise Information Portal -- is another querying tool, although it's unclear if it will be added totally. 'What's added to these three products over time is XML and greater integration capability. This supports relational, XML and rich-media views of the world,' said Jim Kleewein, an IBM distinguished engineer working on the project in IBM's Silicon Valley Laboratory, in San Jose, Calif. 'It takes you beyond just integrating data to merging business with IT processes along with structured and unstructured data.' What makes this more than just the sum of the three products together are two pieces of XML technology developed by IBM, according to Kleewein. The first is Xperanto, a code name for an XML foundation technology that supports XML within DB2. The second is an XML query language based on the XQuery technology developed by IBM and under consideration as a standard by the World Wide Web Consortium. XQuery is part of Xperanto. II supports IBM's belief that XML and relational data must live together instead of the former replacing the latter... [But] said International Data Corp. analyst Carl Olofson, in Framingham, Mass. 'It has to hang together as product rather than come across as a loose collection of things that weren't designed to work together. If most of them come out of the DB2 family, they probably will work together.' Another analyst discounted the notion that the unstructured world of XML and highly structured DB2 model will collide..."
[December 21, 2001] "IBM, Lotus Tie Up To Power Wireless Synchronization. WebSphere Everyplace Server Also to Support SyncML Standard." By Cathleen Moore. In InfoWorld (December 20, 2001). "IBM plans early in 2002 to unite its relational database wireless synchronization engine with the Lotus Domino Everyplace Server, in a new release of the WebSphere Everyplace Server family of software. The move is part of IBM's ongoing effort to realize closer technology ties with its Lotus Software subsidiary and to provide a more complete wireless synchronization offering to customers looking to wireless-enable business applications and information. IBM's DB2 Everyplace with relational database synchronization capabilities will come together with the e-mail and PIM synchronization in Lotus Domino Everyplace, in an attempt to address the requirement for synchronization that underlies enterprise efforts to extend e-mail and applications to wireless devices... Expected in the first quarter of 2002, the WebSphere Everyplace software family also will ship with support for the SyncML standard, an XML-based technology designed to enable synchronization of remote data and personal information across multiple networks, platforms and devices. IBM and Lotus are founding sponsors of the SyncML Initiative. SyncML support is critical to create the greatest amount of interoperability between all types of devices and servers, [IBM's] Prial said... IBM's long-term vision in the wireless space is to provide a common infrastructure for wireless, stitching together Lotus, Tivoli, and IBM technologies: 'We see the infrastructure requirement to support wireless devices coming together to a common infrastructure base, and IBM is bringing all those technologies together, whether it is synchronization, trans-coding, or subscription and device management. It is all part of a broader solution base'..." See also from August 2001, "IBM Retools WebSphere for Remote Access," - "...IBM announced plans to enhance parts of its WebSphere application server to make it easier for businesses to make information on the Web and in corporate databases available to mobile users, particularly using speech technologies. IBM said it juiced up its WTP (WebSphere Transcoding Publisher), a component of the application server used to reformat Web content and multimedia files so they can be accessed from PDAs, mobile phones, and other 'pervasive' devices..." See "The SyncML Initiative."
[December 20, 2001] "Intel Readies EDI Retirement." By Mitch Wagner. In InternetWeek (December 17, 2001), pages 8, 45. "Intel last week said it will replace EDI with RosettaNet standards by 2006, making it the first company to publicly commit to retiring electronic data interchange. The chip maker also said it's reached a RosettaNet milestone: By year-end, Intel will be swapping data in RosettaNet's XML formats over the Internet with 50 trading partners. Intel sees the use of RosettaNet and the Internet as superior to EDI in cost and flexibility; hence the five-year plan to phase out the legacy technology. Although some companies have been conducting EDI transactions over the Internet, newer XML technology offers several advantages. EDI exchanges data in batch mode -- meaning transactions occur at prescheduled intervals, such as daily -- whereas XML supports real-time exchanges. Moreover, RosettaNet's error-checking features -- absent in EDI -- have made its transactions three times as accurate as those in EDI, Intel said. The 50 Intel partners that will be using RosettaNet are mostly large companies that also have EDI connections. Intel's plans for 2002 call for using RosettaNet to communicate electronically with smaller suppliers as well... Intel could save as much as 2 percent of revenue, or roughly $564 million, annually by tuning its supply chain with Internet technology, estimated Vernon Keenan, founder of analyst firm Keenan Vision. That includes the move away from EDI. The savings would be realized as customers and suppliers enter their own data into Intel systems. That would eliminate the need for people to enter the data manually and for specialized networks to transfer the data. Intel would also be able to reduce sales head count as customers enter their own orders in self-service systems, and the company would save from a reduction in transactional errors... Intel customers currently online with RosettaNet include Compaq, IBM and distributor Arrow Electronics. The RosettaNet initiative is part of a big online push for Intel. The company started selling chips and subsystems over the Web in July 1998 and almost immediately ramped up to $1 billion per month in sales. Today, Intel counts both EDI and traditional Internet sales as Internet-based. That's because key EDI-related functions are performed over the Internet, including inventory management at Intel and at the customer site, as well as exchanging price and availability data, said Sandra Morris, vice president of Intel's e-business group..." Note also: "Intel Announces Results Of 'Interoperability Fest'." See "RosettaNet."
[December 20, 2001] "E-business Middleman. Native XML Databases." By Maggie Biggs. In InfoWorld Issue 51 (December 17, 2001), pages 37-38. ['Native XML databases tap heterogeneous back-end databases to feed Web-based applications and trading partners. A native XML database makes good economic sense for enterprises that must support XML document handling and interaction with multiple back-end data sources. In addition, native XML databases can simplify the management of enterprise data processing performance... An emerging technology, native XML databases are currently best suited to early adopters willing to experiment. When existing shortcomings -- such as query and update handling -- are resolved, these databases promise to make XML handling much more manageable for most IT shops.'] "Without a doubt, XML is fast becoming the lingua franca of b-to-b data exchange. As the use of XML increases, executives and IT managers must begin factoring in the growing number and differing types of XML solutions now coming to market before they can determine the most cost-effective XML strategy to implement. Recently major relational database vendors, such as Oracle and Microsoft, have introduced XML-enabling technologies in their products: Oracle's XDB and Microsoft's SQLXML. Rival IBM has offered an XML Extender for its DB2 database for some time. Another promising, more manageable approach to XML in the enterprise is the emerging NXDB (native XML database). An NXDB does not replace your existing enterprise data sources. Rather it acts as an intermediate cache that sits between back-end data sources and middle-tier application components. Using an NXDB provides two principal benefits. First, it's likely your enterprise has multiple back-end data sources and various types of middle-tier applications. Rather than liberally sprinkling XML capabilities across the middle tier and back end, which may significantly increase technology expenditures, you could add the XML support you need by implementing an NXDB. An NXDB supplies the programmatic interfaces and data access methods necessary to support multiple applications and data sources. Second, you might use an NXDB to augment the processing power of your primary enterprise databases. Rather than devote primary database processing cycles to XML translation, storage, and retrieval during peak hours, moving these operations to an NXDB can free primary databases for more important tasks, such as transaction processing. Interaction between the NXDB and your back-end data sources can then be performed at times of the day or night that allow you to optimize processing performance and reduce the load on back-end databases that must also serve other applications and end-users. Many of the XML handling capabilities recently added to RDBMSes provide functionality similar to that provided by an NXDB. This has caused some confusion and begs the question, What constitutes an NXDB? An NXDB differs from an RDBMS in three key ways... Executives and IT managers should consider NXDBs when formulating an XML strategy. However, NXDBs are an emerging technology; querying and update capabilities are still maturing..." See: "XML and Databases."
[December 20, 2001] "Tamino Moves Forward." By Maggie Biggs. In InfoWorld (December 14, 2001). "Native XML databases are certainly a promising technology that executives and IT managers will want to weigh carefully when determining enterprise XML strategies. Although the native XML database market is relatively new, several options must be considered. One of the better options is Software AG's Tamino 3.1. The newly released version of Tamino is a solid improvement over Version 2.3, which we also tested, and it is a worthy rival to Ipedo, another leading native XML database solution. Using the documentation included with Tamino, we had no problem installing and setting up the database. Although IT staff with XML experience and some understanding of native XML databases should not find the going difficult, administrators and developers without this background might have a tough time getting up to speed. Inclusion of more detailed tutorial materials would help. Version 3.1 shows good improvement in the areas of schema support, application accessibility, and management capabilities. We especially liked Tamino's new Schema Editor, which let us create and modify schema, as well as migrate schema we created with Tamino 2.3 to Tamino 3.1, easily and without incident. During schema creation, administrators define the elements and attributes of an XML document. Software AG has implemented a subset of the XML Schema Language defined by the World Wide Web Consortium (W3C) in its schema language, TSD 3 [Tamino Schema Definition 3]. Using the Tamino Schema Editor enabled us to create schema more rapidly than we could using a text editor... For enterprises that need to manage XML documents in heterogeneous data environments, Tamino 3.1 is definitely worth a look. With querying standards yet to fall into place for native XML databases, Tamino is still not a completely mature solution, but its good query support, broader support for Java applications, and capabilities for managing multiple databases push it beyond most competitors."
[December 20, 2001] "CDNs Edge Into App Delivery. [Content Networking.]" By Cathleen Moore, Stephen Lee, and Martin LaMonica. In InfoWorld Issue 51 (December 17, 2001), page 20. "The increased use of dynamic content and the rise of Web services are pushing enterprise application distribution to the edge of networks and into CDNs (content delivery networks). CDN providers such as Akamai Technologies are growing beyond first-generation Web content delivery functions into distributed application delivery, whereas network equipment providers such as Cisco are offering gear to build dynamic content networking platforms within enterprises. Cambridge, Mass.-based Akamai has tapped a technique called ESI (Edge Side Includes) to evolve its model for speeding Web content into a distributed computing network that executes applications at the edge of the network. Co-developed with Oracle, ESI is a markup language that creates an interface between application servers and a globally distributed network. Akamai has relationships with application server vendors, including IBM, Oracle, and BEA Systems. This month, CDN provider Speedera Networks, of Santa Clara, Calif., announced support for ESI... Akamai's network of 13,000 servers supports XSLT (Extensible Stylesheet Language Transformation), used to transform XML into various content formats. In the second half of next year, the company plans to build support for a variety of Web services standards and protocols into its network, said Kieran Taylor, Akamai director of product management..." [Edge Side Includes (ESI) is a simple markup language used to define Web page components for dynamic assembly and delivery of Web applications at the edge of the Internet. ESI provides a mechanism for managing content transparently across application server solutions, content management systems and content delivery networks. As a result, ESI enables companies to develop Web applications once and choose at deployment time where the application should be assembled -- on the content management system, the application server or the content delivery network, thus reducing complexity, development time and deployment costs. The ESI open standard specification is being co-authored by Akamai, ATG, BEA Systems, Circadence, Digital Island, IBM, Interwoven, Oracle, and Vignette."] See: "Edge Side Includes (ESI)."
[December 20, 2001] "XML Matters: XML-RPC as Object Model. A data bundle for the hoi polloi?" By David Mertz, Ph.D. (Sometime Attributor, Gnosis Software, Inc.). From IBM developerWorksm XML Zone. December 2001. ['XML-RPC for serialization? Columnist David Mertz examines XML-RPC as a way of modeling object data, and compares XML-RPC as a means of serializing objects with the xml_pickle module discussed in his earlier columns. Code samples illustrate this comparison in detail.'] "XML-RPC is a remote function invocation protocol with a great virtue: It is worse than all of its competitors. Compared to Java RMI or CORBA or COM, XML-RPC is impoverished in the type of data it can transmit and obese in its message size. XML-RPC abuses the HTTP protocol to circumvent firewalls that exist for good reasons, and as a consequence transmits messages lacking statefulness and incurs channel bottlenecks. Compared to SOAP, XML-RPC lacks both important security mechanisms and a robust object model. As a data representation, XML-RPC is slow, cumbersome, and incomplete compared to native programming language mechanisms like Java's serialize, Python's pickle, Perl's Data::Dumper, or similar modules for Ruby, Lisp, PHP, and many other languages. In other words, XML-RPC is the perfect embodiment of Richard Gabriel's 'worse-is-better' philosophy of software design. I can hardly write more glowingly on XML-RPC than I did in the previous paragraph, and I think the protocol is a perfect match for a huge variety of tasks. To understand why, it's worth quoting the tenets of Gabriel's 'worse-is-better' philosophy... By design, xml_pickle is more naturally extensible for representing new data types than is XML-RPC. Moreover, extensions to xml_pickle maintain good backward compatibility across versions. As its designer, I am happy with the flexibility I have included for xml_pickle. However, the fact is that XML-RPC is far more widely used and implemented. Fortunately, with only slight extra layering -- and without breaking the underlying DTD -- XML-RPC can also be adapted to represent arbitrary data types. The mechanism is somewhat less elegant, but XML-RPC is well thought out enough to allow compatibility with existing implementations after these adaptations..." See: "XML-RPC."
[December 20, 2001] "XML-RPC vs. SOAP. A simple guide to choosing the best protocol for your XML Remote Procedure Call needs." By Kate Rhodes. November 14, 2001. [Cited by David Mertz, above: "Kate Rhodes has written a nice comparison called 'XML-RPC vs. SOAP';in it, she points to a number of details that [give the lie to]SOAP's description as a 'lightweight" protocol'..."] "Within the world of XML there are two main ways to implement a Remote Procedure Call (RPC). XML-RPC and SOAP. This document will explore the differences between these two methods in order to help you decide which is best suited to your needs. ... When you get right down to it XML-RPC is about simple, easy to understand, requests and responses. It is a lowest common denominator form of communication that allows you to get almost any job done with a minimum amount of complexity. SOAP, on the other hand, is designed for transferring far more complex sets of information. It requires profuse attribute specification tags, namespaces, and other complexities, to describe exactly what is being sent. This has its advantages and disadvantages. SOAP involves significantly more overhead but adds much more information about what is being sent. If you require complex user defined data types and the ability to have each message define how it should be processed then SOAP is a better solution than XML-RPC (be sure to check out language specific solutions to this problem like Java's RMI). But, if standard data types and simple method calls are all you need then XML-RPC will give you a faster app with far fewer headaches..." See: "XML-RPC."
[December 20, 2001] "Clark Challenges the XML Community." By Edd Dumbill. From XML.com. December 19, 2001. ['James Clark opened the XML 2001 conference in Orlando, delivering his keynote speech on the subject of challenges facing the XML community. A highly respected figure, Clark provided a focus for many of the issues concerning those who develop XML programs and specifications.'] "Delivering the opening keynote at the IDEAlliance XML 2001 Conference in Orlando, Florida, James Clark described five challenges faced by the XML community. Just before delivering his speech, Clark was deservedly honored by the conference with the 'XML Cup' for his long-standing contributions to the world of XML. Though at the center of the development of XML 1.0 and XSLT, and much SGML technology before that, Clark has recently become an increasingly dissenting voice at the World Wide Web Consortium. He used his speech to set out his concerns about the position that the guardians of XML now find themselves in... [1] Making Progress While Keeping XML Simple; [2] Don't Neglect the Foundations; [3] Controlling the Processing Pipeline; [4] Improving XML Processing; [5] Avoiding Premature Standardization... Although there were those new to XML in the audience who didn't quite appreciate what Clark had to say, his speech was a very important one for the XML community. It summed up many of the issues expressed within the community over the last two years. In a sense, we were hearing little that was totally new; but the important thing was that it came from Clark, underlined by the fact that he showed that he was willing to throw away some of his own work and ideas in order to make XML better. It seems unlikely that the increasingly conservative W3C will adopt Clark's more radical suggestions. However, the speech had an energizing effect on many who heard it, highlighting as it did the potential for grassroots community members to change and improve XML -- with Clark leading by example..." See also the news item: "James Clark First Recipient of the IDEAlliance XML Cup Award."
[December 20, 2001] "Patents and Web Standards Town Hall Meeting." By Michael Champion. From XML.com. December 19, 2001. "On 16-August-2001, the W3C's Patent Policy Working Group released a working draft of a new framework governing the potential use of patented technology in W3C Recommendations. This draft described a process that would mandate that working groups specify in their charter whether they would operate in 'RF' or 'RAND' mode with respect to patented technology. The "royalty-free" (RF) mode working groups would refuse to consider any technology encumbered by patents that would not be freely licensed to all. RAND mode groups would consider technologies whose owners agreed to license them on 'Reasonable And Non-Discriminatory' royalty terms to all. The proposed policy drew almost no response until two days before the deadline for comments from the public. On 28-September-2001, Adam Warner wrote a piece for Linux Today describing the proposed policy and warning that there was little time to get in comments. This was picked up by Slashdot and triggered an unprecedented response on the W3C's public comment mailing list, almost all of it vehemently opposed to the working draft. The XML 2001 Conference and Exposition in Orlando, Florida sponsored a Town Hall meeting on 11-December-2001 that was billed as providing 'an opportunity to listen to speakers describe the issues at stake in this controversy and to participate in debate over the best way for the Web community to respond.' Despite vigorous efforts by conference chair Lauren Wood, the only person brave enough to face the public on this contentious issue was Daniel Weitzner, technology and society domain leader at the W3C and chair of the Patent Policy Working Group. Weitzner gave a 20-minute summary of the issues, the response from the public, and the reaction of the W3C Advisory Committee, then took comments and suggestions from the audience... The participants appeared to leave happy that the W3C planned to heavily favor technologies that could be licensed on royalty-free terms, but thoughtful about the possibility that this would limit the access of Web users to the best technology in specific application areas. The overwhelming consensus was that Daniel Weitzner had done a superb job in explaining the challenges the W3C faces here." See the W3C Patent Policy Working Group public home page.
[December 20, 2001] "Growing Ideas at XML 2001." By Simon St. Laurent. From XML.com. December 19, 2001. "The XML 2001 show floor displayed a wide variety of different offerings from over 50 vendors. Much of the show featured improved versions of what had come before, but there were some new ideas sprouting as well as different takes on older ideas. There was a much broader range of XSL Formatting Object implementations, with RenderX, AntennaHouse, ArborText, and Advent 3B2 showing off their XSL-FO support. ActiveState's Visual XSLT Debugger tools gave many developers hope of managing to debug their XSLT stylesheets. SVG was also a common topic of discussion on the floor, as the notion of XML for graphics seemed to be catching on... While many vendors offer editors which hide the markup or work as trees, Topologi is developing an editor that takes a very different approach. The Topologi markup editor keeps all of the markup accessible to writers while providing support for a wide variety of common tasks and teamwork. Aimed at customers who already intensively use XML or SGML, the Topologi editor is designed for people 'who want more exposure to angle brackets. They want to be close to the markup,' says CTO Rick Jelliffe..."
[December 20, 2001] "All We Want For Christmas is a WSDL Working Group." By Martin Gudgin and Timothy Ewald. From XML.com. December 19, 2001. "Dear Santa Claus: We have both been very good this year. We've done our best to promote peace and understanding among web service developers around the world. We have run into some problems, however, with the Web Service Description Language (WSDL). In case you aren't familiar with WSDL, it's an XML-based language that captures the mechanical information a client needs to access a web service: definitions of message formats, SOAP details, and a destination URL. (Of course the client also needs to understand the semantics of particular messages, but that information is still imparted the old-fashioned way, i.e., documentation.) WSDL files are often interpreted by software, which uses the metadata they contain to generate client-side proxy code for accessing a service. This is appealing to developers who do not want to program in raw XML... We agree with most people in the web service community that something like WSDL is necessary. However, we have a number of issues with WSDL as it stands today, and we are hoping that you can fix them. Here is our list... Actually, Santa, forget about our list. We just realized that all we really want for Christmas is a WSDL working group. If you can get us one of those, we'd be very happy..." See: "Web Services Description Language (WSDL)."
[December 20, 2001] "Versioning Problems. [XML Deviant.]" By Leigh Dodds. From XML.com. December 19, 2001. ['The biggest story of the week has been the release of the first working draft of XML 1.1, designed to resolve issues created by the relationship between XML and Unicode. The publication of the first draft of XML 1.1 is the cause of much dissent in the XML community. Leigh Dodds has been covering the reaction to the draft in the XML community.'] "This week saw the publication of the first Working Draft of XML 1.1. XML developers may well have felt their pulses rise at the pointy-bracketed pleasures that such a draft might contain. Disappointing, then, to discover the dismal taste of Blueberry on their palates. Regular XML-Deviant readers will remember that Blueberry was a sour summer fruit this year, causing a great deal of debate on the XML-DEV mailing list. The Blueberry requirements had a couple of aims: to extend the Unicode support to Unicode 3.1, and to accommodate some other changes to legal characters that would make life easier for some IBM mainframe users. XML is currently based on Unicode 2.0, and a number of new scripts have been added in later revisions of Unicode that are not currently legal to use in some aspects of XML markup, particularly tag names. This prevents truly internationalized markup. The debate, inevitably, ended up with some polarized viewpoints: those who believed that full internationalization was a worthwhile goal in itself, regardless of implementation costs, and those who saw those costs as too high considering the small returns involved. Alternatives were presented: IBM mainframe users could incur the cost to upgrade their text editors, and add some simple character conversions when producing XML from legacy systems; and international users would have to accept less freedom in choosing tag names than they have in the character content they can mark-up with those tags..." See (1) the XML 1.1 specification, and (2) the news item, "W3C Issues First Public Working Draft for XML Version 1.1."
[December 20, 2001] "Conceptual Model for Processing DocBook SGML and XML." By Nik Clayton (FreeBSD Documentation Project). This "maps out the relationships between the various components in the FreeBSD DocBook pulishing toolchain (used to generate high quality PS, PDF, TXT, PDB, RTF, and HTML output). I thought it might be useful for people who are trying to understand how the various technologies and tools fit together..." Reviewers may email Nik Clayton for information on a sample implementation of the infrastructure which supports this processing framework. See: "DocBook XML DTD." [cache]
[December 20, 2001] "XML Schema tome 0: Introduction." Recommandation du W3C du 2 Mai 2001. From W3C XML Schema Recommendation Part 0. Translated by Jean-Jacques Thomasson. Referenced by Eric van der Vlist: "It's my pleasure to announce the publication of an excellent translation of XML Schema part 0 by Jean-Jacques Thomasson on XMLfr...". Note: "Ce document est une traduction de la recommandation XML Schema du W3C, datée du 2 mai 2001. Cette version traduite peut contenir des erreurs absentes de l'original, introduites par la traduction elle-même." See the W3C web site for XML Schema and "XML Schemas."
[December 20, 2001] "Smart Tags are Helping the War -- And Businesses Too. Radio-frequency ID Tags Offer New Efficiency In Supply-Chain Management" By Steve Konicki. In InformationWeek Issue 867 (December 10, 2001), pages 22-24. "The U.S. military and commercial businesses have a common challenge: the need to skillfully manage supply-chain logistics. Be it the assembly of cars or the maintenance of attack helicopters, the timely coordination of parts and supplies is key to success. A new class of radio-frequency ID systems is being brought to bear in both arenas, bringing unprecedented efficiency and control to the shipment of everything from canned peas to Humvees. The military is using RFID in conjunction with the satellite-based global positioning system to track virtually every shipment destined for the war in Afghanistan. RFID smart tags can be affixed to boxes, pallets, and industrial shipping containers to transmit the location and status of goods en route... Basic RFID tags, such as the passive read-only type widely used in retail, have been around for more than 10 years, and their prices have dropped to as little as 25 cents each. Newer tags, called active tags, contain memory chips that can be programmed to include information about what's in a pallet or box. They can cost as little as $3 in large quantities. Savi's combination device that includes active RFID, GPS, and wireless communications can cost $500 each in quantities of 50,000. Throw in the cost of additional software and infrastructure upgrades, and a complete system can range from $150,000 to several million dollars. Kevin Ashton, executive director at the Massachusetts Institute of Technology's Auto-ID Center, which is researching new uses for RFID technology with sponsors such as Coca-Cola, Johnson & Johnson, and Wal-Mart, says the lack of software to manage the data these smart tags emit is a barrier to adoption... Savi's SmartChain software is designed to handle the large amounts of data generated by real-time tracking, but mainstream supply-chain management software typically can't do the job. Most RFID vendors say their software uses XML and open APIs to make integration easier with existing supply-chain apps. ... Volkswagen is using new technology, dubbed Intelligent Long Range RFID from Identec Solutions to check the location of finished and near-finished autos at plants in Germany. A single device that combines GPS and RFID capabilities is placed on the windshield of every car on large lots. A security guard making rounds takes inventory of cars every hour by driving around the lot on a golf cart equipped with an RFID reader connected to a notebook computer, which links via wireless LAN to Volkswagen's inventory-management software..." Note also a technology overview presented in the sidebar, "Bringing Real-Time Tracking To Logistics." Related references: (1) "Physical Markup Language (PML)" and the news item of 2001-11-21: "Auto-ID Center Uses Physical Markup Language in Radio Frequency Identification (RFID) Tag Technology."
[December 14, 2001] "Differences between XTM 1.0 and the HyTime-based meta-DTD." Edited by Michel Biezunski and Steven R. Newcomb. ISO/IEC JTC 1/SC34 N0277. Project: Topic Map Models. 8-December-2001. Editors' Draft, informational. "The ISO/IEC 13250:2000 'Topic Maps' International Standard has two interchange syntaxes, the HyTime-based meta-DTD, and the XTM DTD. The following is a survey of the relationships and differences between these two syntaxes. Describing the semantics of both syntaxes: One of the purposes of the layered model of Topic Maps Information is to provide a means of describing the semantics of such information, in general, regardless of the representations that may be used to interchange it. The layered model also can be used to show how each different syntax (or other representation) can be used to interchange or store Topic Map Information, and to compare the ways in which each syntax reflects the inherent character of the underlying model of Topic Map Information. In order to rigorously define and constrain the interpretation of each syntax, it is desirable to describe how instances of each syntax can be transformed into instances of the common underlying model, and how instances of the underlying model can be transformed into instances of each syntax. It is important to recognize that information that has the character of Topic Map Information is ordinarily expressed in many different notations. It is highly desirable to be able to federate all kinds of 'finding information', not just the finding information that happens to be expressed in one of only two syntaxes. The underlying layered model of Topic Map Information is applicable to any number of notations, although the ISO 13250 standard uses it only to constrain the interpretation of only two syntaxes -- the syntaxes that it happens to provide. Conformance to the underlying layered model will enable topic map applications to become omnivorous with respect to syntax..." In this connection, see the 2001-12-14 posting from James David Mason (Chairman, ISO/IEC JTC1/SC34) to the effect that "... the ballot to amend ISO/IEC 13250 has passed, [so] the XTM 1.0 DTD is now a part of the ISO/IEC standard. That means we shouldn't make distinctions in the future between 'ISO 13250' and 'XTM'... Both the HyTime metaDTD originally published in the standard and the XTM 1.0 DTD are now equally parts of the standard. Each one provides an approved ISO/IEC mechanism for interchange of Topic Maps. To avoid confusion, ISO/IEC JTC1/SC34 has adopted the practice of calling the original HyTime form 'HyTM', in parallel with 'XTM' for the later form... We expect the relationship between the two notational conventions to be further elucidated by revisions to the standards and by other work in progress in SC34. There is a graphic at http://www.y12.doe.gov/sgml/sc34/document/0278.ppt (or http://www.y12.doe.gov/sgml/sc34/document/0278.gif) that will be expanded into a full roadmap for the relationship among the various components of the Topic Map standardization project. We need to keep clear that the transfer serialzations are not the definition of Topic Maps: The standard is the definition. SC34 intends that the supplementary standards will clarify the meaning of Topic Maps without changing their essential nature. (We also recognize that other transfer serializations are possible, outside the standard.) The explanatory text of XTM 1.0 remains as it was, where it was. However, we should remember that this is provisional text and that the definitive interpretation now will be progressed by SC34 as we fill in the roadmap..." See: "(XML) Topic Maps." [cache]
[December 14, 2001] "Process Modeling for e-Business. Advantages, challenges, caveats, and implications." By Michael C. Rawlins December 13, 2001. Penultimate article #6 in the series ebXML - A Critical Analysis. "Those who haven't been involved in EDI standards development might be surprised to know that process modeling has long been a contentious topic of debate. After having been studied, developed, and promoted for several years, it recently became a key component of UN/CEFACT's work program. ANSI ASC X12 also decided in 2000 to incorporate modeling using CEFACT's methodology, but without the same "must do" mandate that CEFACT has imposed on its constituent work groups. CEFACT carried this modeling emphasis over into ebXML, and business process analysis using modeling techniques and methodologies is a core part of ebXML. However, there are still many people in both CEFACT and X12 who are not particularly enthusiastic about modeling and question its usefulness. There are many reasons for the controversy around this topic, but the primary reason is the tension between two basic facts about the current state of software engineering: (1) Business process analysis is "good" software engineering; (2) Very few organizations place a high priority on "good" software engineering... One of the foundation principles of software engineering is that it is much easier and less costly to correct requirements mistakes in the analysis phase of a project than it is in later phases of design, coding, and testing. Good analysis is of paramount importance in the efficient production of software systems that satisfy user requirements. There has been a great evolution in analysis techniques over the years. Today's prevalent technique, the Unified Modeling Language (UML), is an object oriented approach that incorporates key features of previous techniques (such as data flow diagrams and state charts). To these it adds its own object oriented viewpoint that meshes very well with today's prevalent OO design and programming approaches. Likewise, today's analysis methodologies, such as UN/CEFACT's UMM (the UN/CEFACT Modeling Methodology N090, based on Rational Software's Rational Unified Process), are based on years of experience. Consistency in techniques and methodologies not only forces discipline on analysts and produces better analysis, but also produces analysis in a form that can be more easily validated by subject matter experts and used by software developers... UML, when used as proposed by ebXML and CEFACT, can also be used to develop XML schemas. One can develop and view XSD complex types as object class hierarchies in UML. For many designers this might be more intuitive than trying to bottom-up trace extension from derived types in XML specific tools such as XML Spy. In addition, non-standard extensions to UML may be required for the XML schemas to be generated. Developers who work primarily in an XML environment may find that the overhead of using a UML tool in addition to their XML tools may not be justified. An ebXML BPSS instance document describing a business process can also be generated from a UML model. It is notable, however, that the ebXML BP team didn't want to force people to use UML. They provided a series of worksheets that enable a BPSS document to be created without having to do a full UML model... For CEFACT, the UMM is a big improvement over having practically no formal anlysis process. However, it may be a case of trying to go too far too fast. The bottom line is that even CEFACT work groups, who have a mandate to use the UMM, are probably going to find it hard to use. The benefits are going to come with a fairly high price. Other organizations may find the UMM helpful as a reference and may see benefits in developing some or even most of the components required in the UMM metamodel. But I think it unlikely that any organization outside of CEFACT is going to adopt the UMM in toto..." See next item for UMM.
[December 14, 2001] "UN/CEFACT's Modelling Methodology (N090)." Release 10. "The document describes UN/CEFACT's Modeling Methodology (UMM) that is being utilized by UN/CEFACT's Working Groups for its business process and information models. UMM is based on the Unified Modeling Language (UML) from the Open Management Group (OMG)." Historically, the definition of information constructs to support information exchange between business and individuals has been tightly tied to the business process they support and the technology syntax used to describe them. This has hampered the migration of existing, working inter-organization information exchanges to new technologies. In the historic methodologies the syntax is so tightly intertwined with the business semantics that it is not easy to retain the semantics (and business knowledge from which they derived) as one attempts to move to new syntaxes such as XML or Objects. To this end, this document describes a method and supporting components to capture business process knowledge, independent of the underlying implemented technology so that the business acumen is retained and usable over generations of implemented technology. Additionally, the UN/CEFACT Modelling Methodology implements processes that help insure predictable results from a software project. ... A primary vision of UN/CEFACT is to capture the business knowledge that enables the development of low cost software components by software vendors to help the small and medium size companies, and emerging economies engage in e-Business practices. By focusing on developing business process and information models in a protocol neutral manner, these UMM provides insurance against obsolescence by allowing recasting of the Open-edi scenarios into new technologies such as Extensible Markup Language (XML), or other technologies that may emerge ten to fifteen years from now. Hence UMM 'future-proofs' Open-edi scenarios against obsolescence by new protocol standards and technologies. The focus of the UMM developed by UN/CEFACT is predominately the technology neutral intersection of the UP phases of Inception and Elaboration and the Software Engineering project workflows of Business Modelling, Requirements, Analysis and Design. This intersection coincided well with the UN/CEFACT TMWG (Techniques and Methodologies Work Group) charter to define a methodology to support the BOV of ISO/IEC IS 14662 standard for the technology neutral definition of Open-edi scenarios..." See also the UN/CEFACT UML to XML Design Rules Project Proposal, the UML to XML Design Rules Project Team, and mailing list archives.
[December 14, 2001] "Business Object Type Library." Draft Technical Specification. December 07, 2001. Posted by John Yunker to the ['Attached is the latest draft of the BOTL technical specification. Note that this is still at a conceptual level and will be moved more towards the concrete over the next few weeks as we gain agreement on the conceptual basis.'] "The eBTWG Business Object Type Library (BOTL) provides a framework of standardized Business Object Type (BOT) packages. These packages describe behavior, attributes and purpose of persistent business objects that are the subject of business collaborations. For businesses to optimize their execution of supply chain relationships they must align their definitions of the subjects of their collaborations. Often these business objects are the subject of multiple collaborations which occur over time. These business objects usually have persistent existence in the databases of both trading partners, and alignment of these instantiations to a shared definition is critical to achieving alignment between the partners' instances during process execution. The BOT specification provides a Business Operations Map (BOM) and Business Requirements View (BRV) mechanism for identifying and elaborating these objects. eBTWG and UMM context: The Business Object Type Library is intended to provide a resource for: (1) reusable definition of conditions (business object state) used for business collaboration preconditions, postconditions, and transitions; and (2) identification of business semantic for the referenced business object. In the context of the UMM this allows a more formal declaration and elaboration of the guards on start and end states, and the guards on transitions between business transactions in the definition of a complex collaboration. In the context of eBTWG this establishes a mechanism for mapping the collaborations onto an integrated and reusable set of domain definitions instead of the current complex conditionals that reference elements of transitory business messages. eBTWG is providing two primary interfaces for partner interaction: (1) Definition interface for a language for alignment (models, specifications, ontologies); and (2) Execution interface for artifacts of alignment (messages, services). These interfaces facilitate communication between partners..." Context: this is a work product from the Business Information Object Reference Library Project Team, being one of the project teams of the UN/CEFACT Electronic Business Transition Working Group. Other teams are designing a XML Business Document Library and UML to XML Design Rules.
[December 14, 2001] "Reliable XML Web Services." By Eric Schmidt (Program Manager, XML Core Services Team, Microsoft Corporation). December 11, 2001. "At PDC, I delivered a session on the topic of reliable XML Web services (Web services). This talk spawned from numerous conversations that I have had over the past year. Among the various FAQs about building XML Web services, reliability falls into the top five issues facing developers implementing decentralized Web services. The problem space, when broken down into small pieces, is not that difficult. So, this month I decided to jump off into the extreme area of building reliable XML Web services... One of the most exciting aspects of the Global XML Web services Architecture (GXA) is the ability to extend the architecture with composable processing protocols. These protocols, predominantly implemented through SOAP headers, can provide a wide spectrum of services including security, encryption, routing, and reliability. As you start building GXA-based applications, you will discover that GXA is a messaging architecture at the core. This messaging architecture provides interoperability between systems and services through a standards based encoding technology -- SOAP. The majority of implementation work to date has been focused on SOAP 1.1 and WSDL compliant services so that Web service implementations could interoperate across various languages and operating systems. This is an elegant concept. Any system can talk to any other system as long as they can parse XML and understand the rules of the SOAP specification. However, simple message exchange is not sufficient for sophisticated business applications. Real world applications, regardless of their internal domain architecture, need standardized services like security, licensing, and reliability exposed at the Web services messaging layer. There is tremendous momentum behind the creation and implementation of the Global XML Web service Architecture, specifically SOAP, SOAP modules, and infrastructure protocols. With the introduction of four new specifications this past October (WS-Routing, WS-Referral, WS-Licensing, and WS-Security), we are at the forefront of the next generation of XML Web service implementations. Even with this flood of new specifications, there are two areas that do not yet have public specifications -- transactions and reliable messaging. This is mainly because these infrastructure protocols are reliant upon lower level SOAP modules. For this column, I'm writing about what reliability and reliable messaging means in terms of a GXA environment. Specifically, I want to spend some time drilling down on what it takes to develop a reliability protocol by extending the existing Web service classes in the .NET Framework..." See "Microsoft Releases New XML Web Services Specifications for a Global XML Web Services Architecture" and Global XML Web Services Interoperability Resources.
[December 14, 2001] "XML Web Services Basics." By Roger Wolter. Microsoft Corporation. December 2001. ['An overview of the value of XML Web services for developers, with introductions to SOAP, WSDL, and UDDI.'] "XML Web services are the fundamental building blocks in the move to distributed computing on the Internet. Open standards and the focus on communication and collaboration among people and applications have created an environment where XML Web services are becoming the platform for application integration. Applications are constructed using multiple XML Web services from various sources that work together regardless of where they reside or how they were implemented. There are probably as many definitions of XML Web Service as there are companies building them, but almost all definitions have these things in common: (1) XML Web Services expose useful functionality to Web users through a standard Web protocol. In most cases, the protocol used is SOAP. (2) XML Web services provide a way to describe their interfaces in enough detail to allow a user to build a client application to talk to them. This description is usually provided in an XML document called a Web Services Description Language (WSDL) document. (3) XML Web services are registered so that potential users can find them easily. This is done with Universal Discovery Description and Integration (UDDI). I'll cover all three of these technologies in this article but first I want to explain why you should care about XML Web services..."
[December 14, 2001] "Using UDDI at Run Time." By Karsten Januszewski (Microsoft Corporation). December 2001. ['This article walks through using UDDI at run time and discusses how UDDI, both the public registry and UDDI Services available in Microsoft Windows .NET Server, can act as infrastructure for Web services to support client applications.'] "UDDI (Universal Description Discovery and Integration) is often called the 'yellow pages' for Web Services. While the yellow pages analogy is useful, it doesn't convey the complete story of how UDDI can be incorporated into a Web service-based software architecture. The yellow pages analogy only speaks to design-time usage of UDDI -- the ability to discover and consume Web services by searches based on keywords, categories or interfaces. From a design-time perspective, the yellow pages analogy is accurate: just as the yellow pages categorizes and catalogs businesses and their phone numbers, UDDI categorizes and catalogs providers and their Web services. A developer can find WSDL files and access points in UDDI and then incorporate those Web services into client applications. However, UDDI offers more than just design-time support. The yellow pages analogy does not speak to how UDDI offer run-time support. UDDI plays a critical role after the discovery process is complete. The ability to programmatically query UDDI at run time allows UDDI to act as an infrastructure to build reliable, robust Web service applications... UDDI provides important run-time functionality that can be integrated into applications so as to create more robust, dynamic clients. By using UDDI as infrastructure in a Web services architecture, applications can be written to be more reliable..." See: "Universal Description, Discovery, and Integration (UDDI)."
[December 13, 2001] "Effective XML processing with DOM and XPath in Java. Analysis of many projects yields advice and suggested code." By Parand Tony Darugar (Chief Software Architect, VelociGen Inc.). From IBM developerWorks XML Zone. December 2001. ['Based on an analysis of several large XML projects, this article examines how to make effective and efficient use of DOM in Java. The DOM offers a flexible and powerful means for creating, processing, and manipulating XML documents, but it can be awkward to use and can lead to brittle and buggy code. Author Parand Tony Daruger provides a set of Java usage patterns and a library of functions to make DOM robust and easy to use.'] "The Document Object Model (DOM), is a recognized W3C standard for platform- and language-neutral dynamic access and update of the content, structure, and style of XML documents. It defines a standard set of interfaces for representing documents, as well as a standard set of methods for accessing and manipulating them. The DOM enjoys significant support and popularity, and it is implemented in a wide variety of languages, including Java, Perl, C, C++, VB, Tcl, and Python. As I'll demonstrate in this article, DOM is an excellent choice for XML handling when stream-based models (such as SAX) are not sufficient. Unfortunately, several aspects of the specification, such as its language-neutral interface and its use of the 'everything-is-a-node' abstraction, make it difficult to use and prone to generating brittle code. This was particularly evident in a recent review of several large DOM projects that were created by a variety of developers over the past year. The common problems, and their remedies, are discussed below... The language-neutral design of the DOM has given it very wide applicability and brought about implementations on a large number of systems and platforms. This has come at the expense of making DOM more difficult and less intuitive than APIs designed specifically for each language. DOM forms a very effective base on which easy-to-use systems can be built by following a few simple principles. Future versions of DOM are being designed with the combined wisdom and experience of a large group of users, and will likely present solutions to some of the problems discussed here. Projects such as JDOM are adapting the API for a more natural Java feel, and techniques such as those described in this article can help make XML manipulation easier, less verbose, and less prone to bugs. Leveraging these projects and following these usage patterns allows DOM to be an excellent platform for XML-based projects." Article also in PDF format. See: "W3C Document Object Model (DOM)."
[December 13, 2001] "IBM Spills Beans on Xperanto Database Initiative." By Tom Sullivan and Ed Scannell. In InfoWorld (December 13, 2001). "XML has been causing quite a splash in the database world, particularly in the last few weeks, and IBM is the latest vendor to detail plans for the standard. In IBM's research labs, the company is working on a project, code-named Xperanto, which will be a native XML database that acts as a subset of DB2, said Janet Perna, general manager of Armonk, N.Y.-based IBM's data management solutions group. By using XML and relying on the XML query language XQL, Xperanto will be a critical piece of IBM's long-term vision to marry structured and unstructured data. 'The value of this is it's the next step beyond a federated database,' Perna said. That step, Perna added, is information integration. IBM has application integration via its WebSphere products, business process integration from its recent CrossWorlds acquisition, and Xperanto acts as a dedicated server for data or information integration. 'We have a new class of software that really is about information integration,' Perna said. Nelson Mattos, a distinguished engineer and director of information integration at IBM's Silicon Valley Labs, said that the customer pain point Xperanto is aimed at is how to tie together all the systems in an organization... Mattos continued that Xperanto will be the materialization of IBM's work on a number of Web services-related standards, including XQuery, XML Schema, UDDI (Universal Description, Discovery, and Integration), SOAP (Simple Object Access Protocol), WSDL (Web Services Description Language) and WSFL (Web Services Flow Language). The end goal of IBM's integration strategy is to be able to combine structured and unstructured data, thereby enabling access to a broader array of data sets within an organization, such as Office files. So organizations would be able to access the content in the Word files that reside on individual employees desktop systems. Both Microsoft and Oracle said they are working to enhance XML support in the database as well as toward the same goal of providing users more insight into all of the intelligence within an organization... Within IBM's strategy, DB2 handles structured data, OLTP (Online Transaction Processing), BI (business intelligence), and Web applications, while the Content Manager software takes care of unstructured information, such as rich media and flat files. Perna said that the widespread adoption of XML has made the idea of combining structured and unstructured data come alive..." See: "XML and Databases."
[December 13, 2001] "Digital Rights Management: Reviewing XrML 2.0. How well is ContentGuard responding to challenges to its rights description language?" By Bill Rosenblatt (President, GiantSteps Media Technology Strategies). In Seybold Report: Analyzing Publishing Technology [ISSN: 1533-9211] Volume 1, Number 18 (December 17, 2001). ['ContentGuard's second effort at a rights specification language offers more expressive power and now supports non-document content types, but it hasn't cured the complexity problem. Openness and outreach are the challenges that ContentGuard still faces.'] "With Extensible Rights Markup Language (XrML) 2.0 (www.xrml.org), the rights specification language from ContentGuard takes a further evolutionary step away from its roots in the Digital Property Rights Language (DPRL) invented by Dr. Mark Stefik of Xerox PARC in 1996. The first version of XrML moved the language's syntactic basis from its original Lisp to XML, but kept the semantics largely intact. Version 2.0 moves the syntax slightly from XML DTD to XML Schema and alters the semantics -- the power of the language -- significantly. Although the language has existed for a few years, XrML has been slow to be adopted by DRM technology vendors. DRM technologists have criticized it as too complex, making it difficult to implement, especially in post-PC Internet devices with slow processors and small memory footprints. This criticism has had some validity: The language tried to be all-encompassing and to muck around in DRM implementation details, such as levels of security, that DRM technology vendors have found unnecessary... Version 2.0 of the language is well integrated into the web of existing and emerging standards in the XML community, including Schema, namespaces, XPath and digital signature standards; in fact, one must be conversant with many of these to fully understand the language specification and to write good XrML code. ContentGuard is trying to find an existing and respected standards body to take responsibility for the language (IDEAlliance, keeper of both PRISM and ICE, would be a logical candidate). This is an improvement upon its previous intention of forming and managing an authoring group itself. ContentGuard's strategy appears to be to make money by licensing the technology -- whatever some outside body defines it to be. It can do this because its patents cover the idea of a rights language in general, no matter what the specifics of the language are... XrML 1.3 had a few features designed to support some service-oriented business models, such as subscriptions and private currencies (tickets), but the language's conceptions of both rights and consideration required for exercising rights were centered on document-like content. XrML 2.0 fixes this, all the way. The language can support any Internet-based service -- whether it involves 'content' or not. In fact, XrML 2.0 can support fine-grained rights control on individual pieces of data in a database. This feature is bound to generate some controversy among the Electronic Frontier Foundation and other advocates of the balance of interests in copyright law. Currently, individual data items ('facts') are not protected under U.S. copyright law, although there is an effort afoot among online database providers (and others) to make them so. Protecting online database records with a DRM system powered by XrML 2.0 would bypass this issue by doing an end run around the copyright laws..." See (1) "Extensible Rights Markup Language (XrML)"; (2) "XML and Digital Rights Management (DRM)."
[December 13, 2001] "XrML 2.0 Review." By [Bill Rosenblatt] GiantSteps/Media Technology Strategies 'DRM Watch'. November 26, 2001. ['ContentGuard releases version 2.0 of the Extensible Rights Markup Language (XrML), announces its intention to hand the language over to an as yet unnamed standards body for further stewardship, and submits it for consideration as a part of the MPEG-21 standard under development. ContentGuard restructured its business in July 2001 so that it now focuses exclusively on developing the XrML language, advancing it as a standard, and creating revenue through licensing fees. XrML 2.0 is the first major deliverable from the new ContentGuard, and the emphasis on the language (rather than on ContentGuard's former DRM products and services) is quite apparent nt'] "... Overall, XrML 2.0 is a positive step for ContentGuard, and by extension, for the DRM industry as a whole. But it's not the only rights description language vying for industry-standard status. For example, the aforementioned ODRL is also being submitted to MPEG-21. ContentGuard needs to continue building its momentum in the areas mentioned above to beat out these competitors and finally bring order to the chaotic world of DRM systems." [substantially re-published in the Seybold article, cited above] See (1) "Extensible Rights Markup Language (XrML)"; (2) "XML and Digital Rights Management (DRM)."
[December 13, 2001] "SAML Basics. A Technical Introduction to the Security Assertion Markup Language." By Eve Maler (XML Standards Architect, XML Technology Center, Sun Microsystems, Inc.). Presentation delivered at the Java in Administration Special Interest Group (JA-SIG) Conference, December 3, 2001. 51 slides. The session was designed to "provide a technical overview of SAML, the XML-based Security Assertion Markup Language being standardized at OASIS. It discusses how SAML enables Single Sign-On and other security scenarios, and provides details about the authentication, attribute, and authorization information that SAML can convey. The presentation also covers the protocol by which security information can be requested from SAML Authorities and the practical realities of how this information can be transported securely across domains... With XML, you often see standards that are simply wire protocols; no API is mandated, and in some cases no binding to some transport mechanism (such as HTTP or SMTP or whatever) is provided. We felt that the latter is definitely needed so that proprietary mechanisms don't creep in. What's needed is (1) A standard XML message format [It's just data traveling on any wire; No particular API mandated; Lots of XML tools available]; (2) A standard message exchange protocol [Need clarity in orchestrating how you ask for and get the information you need]; (3) Rules for how the messages ride 'on' and 'in' transport protocols, for better interoperability. SAML is an XML-based framework for exchanging security information: (1) XML-encoded security 'assertions'; (2) XML-encoded request/response protocol; (3) Rules on using assertions with standard transport and messaging frameworks..." See: "Security Assertion Markup Language (SAML)."
[December 13, 2001] "Assertions and Protocol for the OASIS Security Assertion Markup Language (SAML)." Reference: draft-sstc-core-21. Interim draft. 10-December-2001. 39 pages. From members of the OASIS XML-Based Security Services Technical Committee (SSTC). Contributors include: Carlisle Adams (Entrust), Nigel Edwards (Hewlett-Packard), Marlena Erdos (Tivoli), Phillip Hallam-Baker (VeriSign, editor), Jeff Hodges (Oblix), Charles Knouse (Oblix), Chris McLaren (Netegrity), Prateek Mishra (Netegrity), RL "Bob" Morgan (University of Washington), Eve Maler (Sun Microsystems, editor), Tim Moses (Entrust), David Orchard (BEA), and Irving Reid (Baltimore). "This specification defines the syntax and semantics for XML-encoded SAML assertions, protocol requests, and protocol responses. These constructs are typically embedded in other structures for transport, such as HTTP form POSTs and XML-encoded SOAP messages. The SAML specification for bindings and profiles provides frameworks for this embedding and transport. Files containing just the SAML assertion schema and protocol schema are available. .. An assertion is a package of information that supplies one or more statements made by an issuer. SAML allows issuers to make three different kinds of assertion statement: (1) Authentication: The specified subject was authenticated by a particular means at a particular time. (2) Authorization decision: A request to allow the specified subject to access the specified object has been granted or denied. (3) Attribute: The specified subject is associated with the supplied attributes. Assertions have a nested structure. A series of inner elements representing authentication statements, authorization decision statements, and attribute statements contains the specifics, while an outer generic assertion element provides information that is common to all the statements..." SSTC WG documents supportive of the Core Assertion Architecture specification inclued (1) SAML Profile of XML Digital Signature; (2) Assertion Schema Discussion; (3) Protocols Schema Discussion; (4) Assertion XML Schema 'draft-sstc-schema-assertion-21.xsd'; (5) Protocol Schema 'draft-sstc-schema-protocol-21.xsd'. Other Committee Drafts from the SAML working group include: Use Cases and Requirements Document, Domain Model, Bindings Model, Sessions, Security Considerations, Conformance Specification, Glossary, and Issues List. See: "Security Assertion Markup Language (SAML)." [source]
[December 13, 2001] "Comparing XML Schema Languages." By Eric van der Vlist. From XML.com. December 12, 2001. ['DTDs, W3C XML Schema, RELAX NG: what's the difference? And which is the best tool for the job? There is a healthy ecology in XML schema technologies: ranging from DTDs, through the W3C's XML Schema Definition Language to newer entrants such as RELAX NG and Schematron. In his article, Eric gives us a timeline of XML schema languages, and compares the strengths of each of these technologies. Eric's talk in Orlando "XML Schema Languages" was standing-room only.'] "This article explains what an XML schema language is and which features the different schema languages possess. It also documents the development of the major schema language families -- DTDs, W3C XML Schema, and RELAX NG -- and compares the features of DTDs, W3C XML Schema, RELAX NG, Schematron, and Examplotron... The English language definition of schema does not really apply to XML schema languages. Most of the schema languages are too complex to 'present to the mind' or to a program the instance documents that they describe, and, more importantly and less subjectively, they often focus on defining validation rules more than on modeling a class of documents. All XML schema languages define transformations to apply to a class of instance documents. XML schemas should be thought of as transformations. These transformations take instance documents as input and produce a validation report, which includes at least a return code reporting whether the document is valid and an optional Post Schema Validation Infoset (PSVI), updating the original document's infoset (the information obtained from the XML document by the parser) with additional information (default values, datatypes, etc.) One important consequence of realizing that XML schemas define transformations is that one should consider general purpose transformation languages and APIs as alternatives when choosing a schema language... One of the key strengths of XML, sometimes called 'late binding,' is the decoupling of the writer and the reader of an XML document: this gives the reader the ability to have its own interpretation and understanding of the document. By being more prescriptive about the way to interpret a document, XML schema languages reduce the possibility of erroneous interpretation but also create the possibility of unexpectedly adding 'value' to the document by creating interpretations not apparent from an examination of the document itself. Furthermore, modeling an XML tree is very complex, and the schema languages often make a judgment on 'good' and 'bad' practices in order to limit their complexity and consequent validation processing times. Such limitations also reduce the set of possibilities offered to XML designers. Reducing the set of possibilities offered by a still relatively young technology, that is, premature optimization, is a risk, since these 'good' or 'bad' practices are still ill-defined and rapidly evolving. The many advantages of using and widely distributing XML schemas must be balanced against the risk of narrowing the flexibility and extensibility of XML.There are currently no perfect XML Schema languages. Fortunately, there are a number of good choices, each with strengths and weaknesses, and these choices can be combined. Your job may be as simple as picking the right combination for your application." For XML schema language description and references, see "XML Schemas."
[December 13, 2001] "Driving XML Standards: Convergence and Interoperability." By Jackson He (Intel Corporation; Chair of the Business Internet Consortium XML Convergence WG). Presentation delivered at the "Electronic Business Interoperability Summit," December 6 - 7, 2001, Orlando, Florida, USA. 29 pages. This is one of eight presentations now available online. "Convergence Principles: (1) The lower the layer, the bigger the impact of deviation and duplication - converge from the bottom up; (2) Divide and conquer, each layer supports all those above it -- identify common functionalities converge layer by layer; (3) Not all layers are converge-able, however, broad agreement at lower layers allows effective diversity at the top layer; (4) If cannot converge, make them interoperable; (5) Continue looking for convergence opportunities, driving toward more converged horizontal standards, while allowing flexibilities to meet diverged business needs; (6) End-to-end solution is the key -- interoperability between multiple standards is needed. Convergence Strategies: (1) Be business requirement-driven, rather than technology driven [End-to-end customer requirements; Focus on what is good for customer, good for e-business, good for small and medium size businesses] (2) Coordination / Collaboration amongst standard bodies [ Division of labor based on a common framework / taxonomy definition, e.g., Interop Summit, Collaboration MOU; Building on-going coordination and collaboration mechanisms, e.g., Interop Summit, Common Taxonomy Registry, etc.; Build joint compliance programs to insure interoperability at all layers]." The document includes a useful final section with "Definition of Terms." See Alan Kotok's summit report (following bibliographic entry). On BIC, see "BIC Workgroup for XML-based eBusiness Standard Convergence." [cache]
[December 13, 2001] "Interoperate or Evaporate." [Interoperability Summit Report.]" By Alan Kotok. From XML.com. December 12, 2001. ['The week before the XML 2001 conference, an Interoperability Summit took place, the first of a series of meetings to find common ground among XML and e-business standards groups. "The key message from this summit," writes Alan Kotok, "is that the groups received a strong urging from vendors to cooperate and interoperate, or risk losing their support."'] "The Interoperability Summit, held 6-7 December 2001 in Orlando, Florida, was billed as the first of a series of meetings to find common ground among XML and e-business standards groups. The group of 80 participants heard, and in no uncertain terms, that customers are quickly running out of patience and resources to support multiple standards organizations. The participants succeeded in bringing out many of the factors that generate and perpetuate the multiple and overlapping specifications, and agreed on the first steps to start bridging the gaps. But it also exposed fault lines that show the task will not be easy. The meeting was sponsored by five organizations: OASIS, The UN's trade facilitation agency, UN/CEFACT, Object Management Group (OMG), HR-XML, and Extensible Business Reporting Language (XBRL)...From the outset the participants seemed ready for solutions to the problem of overlapping XML vocabularies and frameworks. The group consisted of representatives of industry organizations, solution providers, end-user companies, and government agencies from the U.S., Europe, and Asia. Most of whom spoke of the confusion and frustration in the marketplace caused by the proliferation of specifications developed for individual industries and business functions. Yet many of the participants also wore multiple hats, taking part in the very groups that generate the welter of specifications..." The conference included a brainstorming and facilitation exercise, led by Gary O'Neall of PlaceWare, to identify impediments to collaboration and to agree on steps for overcoming them. A brainstorming session designed to identify impediments to collaboration and to agree on steps for overcoming them generated a list of 42 items that the group boiled down to 13 factors, from which five emerged as the leading issues: (1) Roll your own: reluctance to give up turf, hidden agendas, and lack of trust among standards organizations; (2) Differing scopes and processes: incompatible operating processes, varying scopes of standards, different origins and missions of standards groups; (3) Lack of perspective: failure to see the need for multiple groups contributing to e-business standardization, tunnel vision/inability to see the big picture; (4) Lack of awareness of other groups: lack of knowledge of the existence of other groups, as well as their goals, missions, activities; lack of time and energy to keep up with standards world, lack of basic technical understanding; (5) Lack of common vocabularies: both industry and natural languages, as well as lack of international outlook." Other references: see (1) "Electronic Business Interoperability Summit," December 6 - 7, 2001, Orlando, Florida, USA; (2) the main web site and program, with at least eight (8) now-online presentations.
[December 13, 2001] "XML and Modern CGI Applications." By Kip Hampton. From XML.com. December 12, 2001. ['Kip Hampton provides us with his monthly installment of XML and Perl, exploring a modern CGI module. Turning his attention to the CGI::XMLApplication Perl module, Kip shows how XML has taken Perl CGI applications one step further. Using examples of an XSLT gateway and a shopping code, Kip offers a practical and useful introduction to this module. CGI::XMLApplication uses XML and XSLT to separate logic and presentation cleanly.'] "Perl owes a fair amount of its widespread adoption to the Web. Early in the Web's history it was discovered that serving static HTML documents was simply not a very interactive environment, and, in fairly short order. the Common Gateway Interface (CGI) was introduced. Perl's raw power and forgiving nature made it a natural for this new environment, and it very quickly became the lingua franca of CGI scripting. CGI is not without its weaknesses, and despite well-funded campaigns from a number of software vendors, CGI is still widely used and shows no signs of going away anytime soon. This month we will be looking at a module that offers a new take on CGI coding, Christian Glahn's CGI::XMLApplication. Borrowing heavily from the Model-View-Controller pattern, CGI::XMLApplication provides a modular, XML-based alternative to traditional CGI scripting. The typical CGI::XMLApplication project consists of three parts: a small executable script that provides access to the application, a logic module that implements various handler methods that are called in response to the current state of the application, and one or more XSLT stylesheets that are used, based on application-state, to transform the data returned by the module into something a browser can display to its user... CGI::XMLApplication offers a clean, modular approach to CGI scripting that encourages a clear division between content and presentation, and that alone makes it worth a look. Perhaps more importantly, though, I found that it just got out of my way while handing enough of the low-level details to let me focus on the task at hand. And that's a sure sign of a good tool. Includes sample code. See: "XML and Perl."
[December 12, 2001] "Clark Issues Challenges At XML 2001." By [Seybold Staff]. In Seybold Reports: The Bulletin. Seybold News and Views on Electronic Publishing Volume 7, Number 10 (December 12, 2001). "... [James] Clark laid down five challenges that the XML industry faces. First, he urged the community to continue to develop XML-related standards without compromising its strength, which Clark said was the diversity of its applications. Clark warned of the dangers of letting a few companies limit the standards-setting agenda and suggested that the community not forsake electronic publishing for e-business. Second, Clark advised the audience not to neglect the 'foundations' of XML, which were designed for simplicity in electronic publishing. 'The problem with the core standards is that they are too complicated, poorly structured, incomplete, and too hard to understand,' said Clark. But though the existing standards need care, Clark was adamant in saying he does not advocate a return to yesteryear: 'We should be free to stab what's left of the SGML community in the back,' he said, hinting that schemas, not DTDs, may be an important future direction for document definition. Clark's third, fourth and fifth challenges to the community were to supply the missing pieces, to improve XML processing and to avoid premature standardization..." See also: "James Clark First Recipient of the IDEAlliance XML Cup Award."
[December 12, 2001] "XML Tip: Using CSS2 to Display XML Documents. A less 'expensive' alternative to XSLT." By David Mertz, Ph.D. (This-Month-Examiner, Gnosis Software, Inc.). From IBM developerWorks. December 2001. ['Outside of custom editors and viewers, reading XML data is comparatively difficult. A lightweight approach for viewing XML is to attach a cascading style sheet (CSS2) to XML documents and then use a recent Web browser to view them (Mozilla is excellent, IE often adequate). developerWorks columnist David Mertz takes a look at this alternative approach in this tip.'] "Reading XML documents is not easy -- for a human. XML documents are all text, but the visual arrangement of parts does not necessarily correspond well to the conceptual connections between the parts. And finding the content amidst the tags makes skimming difficult. Of course, XML is rarely intended primarily as a format for humans to look at directly. Typically, an XML source is transformed into something else before it becomes ready for human consumption. For prose-oriented documents, usually the target is either an HTML page, or a PDF file -- via Formatting Object (FO) tags -- or perhaps a printed page. XSLT is often used to perform the transformations to human-readable format. For data-oriented XML documents, the target is usually the data format of a DBMS or an in-memory representation by an application that reads XML files... Recent versions of both Internet Explorer and Mozilla/Netscape make an effort to render XML documents along with HTML ones. Other browsers like Opera and Konquorer also implement CSS2 -- Opera 5+ does a flawless job, Konqueror 2.2 a moderately good one. In general Mozilla and Netscape 6 do an excellent and accurate job of displaying an XML document in the styles indicated in a CSS2 style sheet. Internet Explorer, at least as of version 6, does a fair job, but seems to ignore the display: inline attribute. This makes IE6 less suitable for displaying prose-oriented XML documents, but it is still good for data-oriented ones. However, IE6 does have the advantage of displaying XML documents that lack a CSS2 style sheet in a hierarchical tree, and it allows folding subtrees... Normally I either use XMetal (with some XMetal 'rules' provided by my developerWorks colleague Benoît Marchal) or write the source in what I call 'smart ASCII' and transform it to XML using the txt2dw.py tool I wrote that converts the text to the developerWorks' XML manuscript format. As an exercise I decided to write this tip using only a text editor (plus Mozilla 0.9.5). The exercise helped me understand the ins-and-outs of the Web browser-plus-CSS2 approach..." See "W3C Cascading Style Sheets."
[December 12, 2001] "Selectors." W3C Candidate Recommendation. 13-November-2001. Edited by Daniel Glazman (Netscape/AOL), Tantek Gelik (Microsoft Corporation), Ian Hickson, Peter Linss (former editor, formerly of Netscape/AOL), and John Williams (former editor, Quark, Inc.). Latest version URL: http://www.w3.org/TR/css3-selectors. "CSS (Cascading Style Sheets) is a language for describing the rendering of HTML and XML documents on screen, on paper, in speech, etc. To bind style properties to elements in the document, CSS uses selectors, which are patterns that match one or more elements. This document describes the selectors that are proposed for CSS level 3. It includes and extends the selectors of CSS level 2. The specification proposes new selectors for CSS3 as well as for other languages that may need them... A Selector represents a structure; this structure can be used as a condition (e.g., in a CSS rule) that determines which elements a selector matches in the document tree, or as a flat description of the HTML or XML fragment corresponding to that structure. Selectors may range from simple element names to rich contextual representations..." Review comments on this Candidate Recommendation will be evaluated by the W3C CSS Working Group through May 2002. See "W3C Cascading Style Sheets."
[December 12, 2001] "Trust-Based Security in Pervasive Computing Environments." By Lalana Kagal, Tim Finin, and Anupam Joshi (Computer Science and Electrical Engineering Department at the University of Maryland, Baltimore County). In IEEE Computer Volume 24, Number 12 (December 2001), pages 154-157. "Mobile users expect to access locally hosted resources and services anytime and anywhere, leading to serious security risks and access control problems. We propose a solution based on trust management that involves developing a security policy, assigning credentials to entities, verifying that the credentials fulfill the policy, delegating trust to third parties, and reasoning about users' access rights. This architecture is generally applicable to distributed systems but geared toward pervasive computing environments... Pervasive computing strives to simplify day-to-day life by providing mobile users with the means to carry out personal and business tasks via portable and embedded devices... The eBiquity Research Group at the University of Maryland, Baltimore County, is designing pervasive computing systems composed of autonomous, intelligent, self-describing, and interacting components. SmartSpaces are instances of pervasive systems in which the domain is divided into a hierarchy of spaces with a controller managing the services in each space... Our work is similar to role-based access control (RBAC) -- an approach in which access decisions are based on the roles that a certain action can actually delegate that action, and the ability to delegate itself can be delegated. Users can constrain delegations by specifying whether delegated users can redelegate the right and to whom they can delegate. Once users are given certain rights, they are responsible for the actions of the users to whom they subsequently delegate those rights and privileges. This forms a delegation chain in which users only delegate to other users that they trust. If any user along this delegation chain fails to meet the requirements associated with a delegated right, the chain is broken. Following the failure, no user can perform the action associated with the right... Our approach, however, uses ontologies that include not just role hierarchies but any properties and constraints expressed in an XML-based language, including elements of both description logics and declarative rules. For example, a rule could specify that any user in a meeting room who is operating the projector during a presentation is probably the presenter and should thus be allowed to use the computer as well. In this way, rights can be assigned dynamically to users without creating a new role. Similarly, access rights can be revoked from users without changing their role. Using an ontology-based approach is thus more flexible and main-tainable than RBAC... To protect the privacy of users who do not want the system to log their names and actions, we are replacing X.509 certificates with trusted XML signatures that do not include the bearer's identity, but only a role or designation. In our past work on distributed trust, we encoded actions, privileges, delegations, and security as horn clauses in Prolog. To develop an approach better suited to sharing information in an open environment, we are recasting this work in the DARPA Agent Markup Language. Built on XML and the Resource Description Framework, DAML provides a description logic language for defining and using ontologies on the Web in machine-readable form. In applying our framework, we are extending the initial DAML ontology by defining domain-specific classes for actions, roles, and privileges and creating appropriate instances..." See also: (1) "DAML Tools for supporting Intelligent Information Annotation, Sharing and Retrieval"; (2) "DARPA Agent Mark Up Language (DAML)."
[December 11, 2001] "Shoring Up Web Services." By James R. Borck. In InfoWorld Issue 49 (November 30, 2001), page 36. "Openness is both a blessing and a curse for Web services. On one hand, reliance on open standards such as XML, SOAP (Simple Object Access Protocol), and UDDI (Universal Description, Discovery, and Integration) has fostered seamless application-level interchange. On the other hand, the openness of the Web services delivery mechanism, namely HTTP over the public Internet, presents hurdles to deploying Web services in a way that meet business-grade requirements for functionality, security, and reliability. For Web services to deliver fast, seamless integration of business partners on an enterprise scale, such issues as QoS (quality of service), network reliability, real-time messaging , and billing mechanisms must be resolved. This is where a new class of service providers, Web services networks, hope to claim their fame... Reminiscent of the role value-added networks played in EDI (electronic data interchange) transactions, Web services networks sit between the Web service provider and Web service consumer, handling end-point authentication between partners and providing security, data encryption , and guaranteed nonrepudiation of transactions. Web services network vendors also offer features such as synchronous and asynchronous messaging , network-quality monitoring and error management, and data-compression schemes that help improve scalability and reliability. And centralized application management enables better control over testing, notification, and rollout of service updates; comprehensive logging and reporting features supply usage metering for billing purposes. Without demanding a reconfiguration of your applications, Web services networks can help reduce the time and costs required to implement Web services. They also offer an ongoing means of reducing the administrative overhead associated with services management. The number of vendors currently delivering solutions in this space is extremely limited, but major milestones have been seen from the likes of Grand Central, Flamenco Networks, and Kenamea. Already, we're seeing divergence in the way these vendors design, implement, and operate their Web services networks... As enterprise-class security and QoS requirements begin to be built into the next generation of XML and Web services standards, as well as arrive natively in vendor platform packages, larger companies will choose to deploy and manage services over their own networks..."
[December 11, 2001] "Tibco Software to Ease Application Integration." By Ann Bednarz. In Network World (December 03, 2001). "Application integration is a daunting task typically taken on by large companies with deep pockets and sophisticated software development resources. Tibco is looking to change that. The company's BusinessWorks software, being announced this week, claims to make the integration process more accessible to mainstream customers who want to solve specific business problems, not tackle all their software integration challenges at once... The idea behind BusinessWorks is to let companies start small and grow to an enterprisewide integration platform over time, Tibco says. This approach differentiates Tibco from other players in the application integration market, says Joanne Friedman, vice president of e-business strategies at Meta Group. Tibco's competition includes IBM, webMethods, Sybase and Vitria... BusinessWorks includes support for Web services standards, including Simple Object Access Protocol, an XML-based messaging protocol that lets Web applications communicate; Web Services Description Language, which standardizes how a service and its provider are described; Universal Description, Discovery and Integration, which is a registry of Web services resources; and XML Stylesheet Language Transformations, a language used to convert an XML document into other formats. With Web services support, customers can build connections to their trading partners' and customers' applications more easily than they could with previous Tibco products that relied on electronic data interchange and RosettaNet standards..." See the announcement, "Tibco Software Makes Business Integration More Widely Accessible. TIBCO BusinessWorks Is First Comprehensive, Packaged Integration Solution Supporting Web Services."
[December 11, 2001] "SilverStream Releases UDDI Directory." By Kathleen Ohlson. In Network World Fusion (December 11, 2001). "SilverStream Monday [2001-12-10] released a new Universal Description, Discovery and Integration (UDDI) directory for free to developers to bolster the use of Web services. UDDI is an 'online yellow pages' for businesses, meaning businesses would be able to provide their information about products and services online, as well as locate customers and partners. UDDI is one of the key standards in Web services, which make it possible to build applications that pull together information from multiple sources either internally or externally over the Internet. The Billerica, Mass., company is offering its eXtend JEDDI (Java Enterprise Description, Discovery and Integration) for free to developers to encourage them to use UDDI for publishing, managing and sharing Web services publicly and internally..." See the text of the announcement: "SilverStream Software Releases the SilverStream eXtend JEDDI Registry as a Resource for Developers. Available for Free Download to Foster the Adoption of UDDI Registries to Publish, Discover and Manage Web Services." References: "Universal Description, Discovery, and Integration (UDDI)."
[December 11, 2001] "Top Ten SAX2 Tips." By David Brownell. From XML.com. December 05, 2001. ['Learn how to get the best out of the Simple API for XML. The tips are written by David Brownell, an experienced implementor of XML parsers and author of O'Reilly's upcoming book on SAX2, to be published in January. Suitable for beginners and more experienced programmers alike, David's tips will give you useful insights on programming with SAX2 in Java.'] "If you write XML processing code in Java, or indeed most popular programming languages, you will be familiar with SAX, the Simple API for XML. SAX is the best API available for streaming XML processing, for processing documents as they're being read. SAX is the most flexible API in terms of data structures: since it doesn't force you to use a particular in-memory representation, you can choose the one you like best. SAX has great support for the XML Infoset (particularly in SAX2, the second version of SAX) and better DTD support than other widely available APIs. SAX2 is now part of JDK 1.4 and will soon be available to even more Java developers. In this article, I'll highlight some points that can make your SAX programming in Java more portable, robust, and expressive. Some of these points are just advice, some address common programming problems, and some address SAX techniques that offer unique power to developers. A new book from O'Reilly ['January 2002' estimated publication date], SAX2, addresses these topics and more. It details all the SAX APIs and explains each feature in more detail than this short article provides..."
[December 11, 2001] "Plaudits and Pundits. [<taglines/>.]" By Edd Dumbill. From XML.com. December 05, 2001. 'Edd Dumbill's column announces two items of interest: first, a Linux implementation of Adobe's SVG viewer, and second, the XML.com Anti-Awards -- the antidote to industry awards ceremonies. There are also details of the call for participation for next year's XML Europe 2002 conference.' [...] "Adobe has released a version of its SVG browser plug-in for Linux and Solaris... The start-up time for the plug-in is, unfortunately, disconcertingly long: one hopes that speed improvements will follow with later releases... Now that viewing SVG is really a cross-platform reality, I hope that open source developers -- who have contributed much to the XML software world -- will be encouraged to create more SVG software and help SVG to the ubiquity achieved by other XML technologies. If the recent mushrooming of traffic on SVG mailing lists is anything to go by, SVG's future looks bright..."
[December 11, 2001] "Far from Patchy Progress." From XML.com. December 05, 2001. By Leigh Dodds ['Leigh Dodds reviews the recent history of the Apache XML project, its the latest SOAP developments, and concludes that Apache XML has matured considerably.'] ["The author visits] the Apache XML project and reports back on current developments... new projects include Batik, the SVG toolkit, Apache SOAP, and the recently contributed XML Security implementation... In sum, the Apache XML community has a proven track record of organizing widescale development based on donated codebases, and it has obviously had to learn a few lessons about coordinating a diverse range of development teams that often have competing goals and priorities. The community appears to be going from strength to strength with the addition of new tools making Apache XML nearly a one-stop-shop for XML developers..."
[December 11, 2001] "Controlling Whitespace, Part Two." By Bob DuCharme. From XML.com. December 05, 2001. ['Bob DuCharme continues his three-part series on controlling whitespace in XSLT using xsl:text and other techniques.'] "In part 1 of this three-part series, we looked at how the xsl:strip-space and xsl:preserve-space instructions let you control extra whitespace from your source tree by element type. This month we'll look at how xsl:text can not only add whitespace where you want it, but also make it easier to prevent unwanted whitespace characters from showing up in your result tree. We'll also look at a built-in XSLT function that lets you make the use of whitespace in your result tree more consistent... In next month's final installment of this series on controlling whitespace, we'll look at how an XSLT stylesheet can add tabs to your result document and a built-in feature that automates intelligent indenting of your result documents."
[December 11, 2001] "Using Python and XML with Microsoft .NET My Services." By Christopher A. Jones. From the O'Reilly Network. December 03, 2001. ['Using Python and XML with Microsoft .NET My Services Chris Jones, coauthor of Python & XML, talks about using Python and XML with Microsoft .NET My Services, and he shows how to create a request for the simple .NET Contacts service using Python and XML on Linux.'] "Microsoft piqued developer interest when it announced a new project code-named 'HailStorm' in the spring of 2000. The idea of a distributed, XML-based data store that would allow your information to follow you from device to device, and from Web site to Web site, sounded attractive. The idea of Microsoft securing this data on your behalf, however, raised a few concerns. Well, Microsoft has been busily working on .NET My Services (the new name for HailStorm), and they recently released a beta version of the services at this year's Professional Developer's Conference. What many developers realized after viewing the beta code, presentations, and samples is that Microsoft has indeed been focusing on the nature of these XML-based Web services and their utility, and they've created a series of services with an infrastructure fabric underlying them. In this article, you'll learn a bit about .NET My Services, specifically the .NET Contacts service, and how you can program for it using Python and XML. ... In this article, we'll create a request for the simple .NET Contacts service. This service, in the simplest case, is a list of all your contacts, their phone numbers, email addresses, and any other information you would like to provide. This list is analogous to your address book in your desktop email program, PDA, or cell phone. In fact, the goal of the .NET Contacts service is to centralize your contacts list so that you can easily retrieve your contacts from your phone, PDA, or desktop email (or even a trusted Web site) without having to worry about synchronization or duplication..." Note: The author's sample Chapter 1, Python and XML, is available free online; see also the TOC.
[December 11, 2001] "Will Vector Graphics Finally Make It on the Web?" By Steven J. Vaughan-Nichols. In IEEE Computer Volume 24, Number 12 (December 2001), pages 22-24. "Multimedia technology is an increasingly important part of the Web. Because of this, multimedia vendors are always looking for a competitive edge, as well as a better way to present content. And now, these vendors are looking closely at an important technology: scalable vector graphics (SVG). Currently, the Web mainly runs on bitmap-image formats like GIF (graphics interchange format), PNG (portable network graphics), and JPEG (designed by the Joint Photographic Experts Group). However, bitmap files can run large, even with data compression, and don't scale well. Vector-graphic formats don't experience these problems but never caught on because the technology consists of incompatible proprietary standards. The World Wide Web Consortium (W3C), though, may have eliminated this concern recently when it released an open SVG standard with broad industry support. SVG was created by browser developers such as Microsoft, Netscape, and Opera Software, as well as graphics and Web-design companies such as Adobe Systems, Corel, Eastman Kodak, Macromedia, and Quark. SVG images are lightweight and look the same, within a browser's limitations, whether displayed on a workstation's high-resolution, color screen or on a smart phone's tiny, monochrome display... SVG is basically like other vector formats, except that it is standardized and has broad industry support. SVG expresses images first as sets of simple elements, such as lines and curves. The technology then uses these elements to help describe various aspects -- such as size and position -- of more complex geometric shapes like circles and polygons. Because SVG is XML-based, users can add text to a graphic simply by writing it into the XML code. And because XML permits cross-platform operability, Web developers can create a single set of descriptions for an SVG image, which all recipients can then use as long as their browsers understand SVG. This eliminates the need to create multiple files for different platforms, as is the case with bitmapped images. Meanwhile, smart cellular phones and PDAs could access any SVG-compliant Web site, rather than being restricted to scaled-down sites designed specifically for mobile technology. With XML, a browser's rendering engine determines the most suitable way to resolve an image for the host device. Thus, SVG images can easily scale up or down and render to the particular receiving device's best resolution. Among other benefits, this approach generates particularly accurate document printouts. Bitmapped graphics' resolution, on the other hand, is set for a particular image-map size and thus distorts when scaled to work with a small display or a high-resolution printer... SVG is based on XML, which developers can use for both images and text in the same document and which describes document content, not just appearance. Therefore, image files can contain searchable textual information. This text can either describe an image (this is a Persian cat) or provide additional information about the image (this cat doesn't like baths). Users can thus easily conduct text or Web searches of SVG graphics. For the same reason, SVG images work well with the screen readers used by people with vision problems..." See: "W3C Scalable Vector Graphics (SVG)."
[December 11, 2001] "W3C Proposal Ignites Standards Controversy." By Linda Dailey Paulson. In IEEE Computer Volume 24, Number 12 (December 2001), page 25. "A firestorm of criticism has forced the World Wide Web Consortium to reconsider a draft proposal to let companies enforce patents and charge royalties for technologies used in W3C standards. The W3C has now begun another draft of the proposed Patent Policy Framework. The consortium originally planned to finalize the policy by February 2002, a deadline it is unlikely to meet... The Patent Policy Framework would simply make explicit whether and under what circumstances the W3C will standardize technologies subject to licensing fees... However, some companies lambasted the Patent Policy Framework draft. Many critics said they prefer the traditional position that either standards aren't based on patented technologies or companies don't enforce patents on standardized technologies. Some critics said the draft would favor the large software companies that help develop technologies and standards and would question the W3C's role as a neutral Web-standards organization. Now, even some companies that have worked on the Patent Policy Framework draft have changed their stance on the current draft. For example, Scott Peterson said, HP was initially 'generally in favor' of the first draft but is not now. 'HP does not want to charge a fee for W3C standards,' he explained. 'It is HP's view that standards for the Web infrastructure need to be available on a royalty-free basis.' He said that most W3C members will favor the Patent Policy Framework if the consortium eliminates licensing fees for standardized technologies. 'The reason for standards is to move the industry forward. Using patented software really goes against the grain of openness,' said Kathy Harris, an analyst with market-research firm Gartner Inc. Enforcing patents on enabling technologies would stifle innovation, she added... Having core standards freely available makes the Internet work and ensures that 'no one can hijack a standard or hold it hostage for royalties,' said Internet Society President Mike Todd. 'The general fabric of the Internet should remain in the public domain as a stable platform for everyone to build on.' Web-infrastructure technology should remain royalty free to permit maximum innovation and fair competition, added Eve Maler, XML standards architect at Sun Microsystems and formerly the company's W3C voting representative. 'We cooperate on standards,' said Maler. 'We compete on implementations'..." See the Patent Policy Working Group public home page and mail archive; note the Town Hall Meeting at XML 2001, "Patent and Web Standards," 2001-12-11.
[December 11, 2001] "Graphical Stylesheets: Using XSLT to Generate SVG." By Philip A. Mansfield (President, Schema Software Inc., Vancouver, British Columbia, Canada) and Darryl W. Fuller (Schema Software Inc.). Presented by Philip Mansfield at XML 2001 Conference and Exposition. ['By combining XSLT with SVG, it's now practical to infuse your Web applications with rich, interactive graphics generated on the fly from changing or user-selected data. The presenters will discuss the technology and demonstrate a tool to create such Web applications.'] "Traditional stylesheets encode information about the appearance of text and the layout of content, thus enabling the separation of structure from presentation in the case of text-centric publications. Images are treated as single elements of content in such an approach, with very little flexibility for a stylesheet to vary their appearance. However, those images often arise as visualizations of structured data, such as graphs, maps or schematic diagrams of data. Hence the need for Graphical Stylesheets that encode how to draw specific visualizations of structured data. The structured data may start as XML or be returned from a database as XML. Graphical Stylesheets are then naturally encoded as XSLT with SVG as its target. This encoding takes advantage of widely-supported standards and therefore serves as a practical implementation. The use of SVG enables hyperlinked, animated, interactive vector graphics that can be further styled with CSS for purposes of accessibility or other adaptations. Graphical Stylesheets are applicable to such diverse areas as Business Graphics, Flowcharting, Project Plans, Engineering Blueprints, CAD, GIS, AM/FM, Meteorology, Statistical/Scientific Visualization, Environmental Engineering diagrams, Metadata Relationship diagrams, and Presentation/Courseware. The talk will explore Graphical Stylesheet use-cases within a number of these application areas, and demonstrate solutions encoded as XSLT with SVG as its target. The advantages of being able to vary the graphical styling separately from the data will be made explicit. For example, Graphical Stylesheets make it possible to generate visualizations on demand from changing or user-selected data. On the other hand, by varying the Graphical Stylesheet that you apply to your data, you can elicit or emphasize entirely different aspects of that data..." Note: SchemaSoft provided a number of free downloadable tools for authoring, converting, and viewing XML 2001 Conference Papers and Presentations; see "Tools for XML 2001 Conference Presentations." On SVG, see "W3C Scalable Vector Graphics (SVG)."
[December 11, 2001] "ToX: The Toronto XML Engine." By Denilson Barbosa (Department of Computer Science, University of Toronto), Attila Barta, Alberto Mendelzon, George Mihaila (IBM T.J. Watson Research Center), Flavio Rizzolo, and Patricia Rodriguez-Gianolli. Paper presented at the International Workshop on Information Integration on the Web, Rio de Janeiro, 2001. 8 pages (with 21 references). "We present ToX - the Toronto XML Engine - a repository for XML data and metadata, which supports real and virtual XML documents. Real documents are stored as files or mapped into relational or object databases, depending on their structuredness; indices are defined according to the storage method used. Virtual documents can be remote documents, defined as arbitrary WebOQL queries, or views, defined as queries over documents registered in the system. The system catalog contains metadata for the documents, especially their schemata, used for query processing and optimization. Queries can range over both the catalog and the documents, and multiple query languages are supported. In this paper we describe the architecture and main of ToX; we present our indexing and storage strategies, including two novel techniques; and we discuss our query processing strategy. The project started recently and is under active development... [Conclusions:] In this paper we introduced ToX, a heterogeneous repository for XML content that can be used for data integration. We discussed its architecture, and presented some of its features; namely, ToXin, ToXgene and a hybrid storage scheme. The main goal of this project is to understand how the characteristics of a document affect its storage and query processing. We expect to define ways of characterizing XML documents; define guidelines for their storage and indexing; design efficient native storage mechanisms; and, finally, better understand the factors that affect the performance of the various storage approaches. There are already a number of methods for storing and querying XML documents, using files (e.g., Kweelt); schema independent mappings (e.g., Edge Tables); schema dependent mappings; hybrid mappings (e.g., STORED and Ozone); and native storage mechanisms (e.g., Lore and Xyleme). ToX differs from all of them in the following ways: it allows heterogeneous data storage and indexing; it supports multiple query languages; it can be used as a data integration environment; and, most importantly, it uses the characteristics of the documents as the criterion for determining the way they are stored and indexed. Unlike query processors (e.g., Kweelt), ToX provides persistent storage for indices and other query optimization data. Note that although STORED and Ozone offer hybrid mappings, they rely on a single storage engine (a RDBMS and an ODBMS, respectively). Xyleme is intended to be a warehouse for all XML data on the Web. As such, it deals with the crawling and refreshing of documents, which are irrelevant in our context..." See: (1) "Toronto XML Server (ToX) Provides Repository for Real and Virtual XML Documents"; (2) "IBM alphaWorks Releases ToXgene Tool for Complex Template-Based XML Content Generation." [cache]
[December 11, 2001] "Integrating Network-Bound XML Data." By Zachary Ives, Alon Halevy, and Dan Weld. In IEEE Data Engineering Bulletin 24/2 (June 2001). "Although XML was originally envisioned as a replacement for HTML on the web, to this point it has instead been used primarily as a format for on-demand interchange of data between applications and enterprises. The web is rather sparsely populated with static XML documents, but nearly every data management application today can export XML data. There is great interest in integrating such exported data across applications and administrative boundaries, and as a result, efficient techniques for integrating XML data across local- and wide-area networks are an important research focus. In this paper, we provide an overview of the Tukwila data integration system, which is based on the first XML query engine designed specifically for processing network-bound XML data sources. In contrast to previous approaches, which must read, parse, and often store XML data before querying it, the Tukwila XML engine can return query results even as the data is streaming into the system. Tukwila features a new system architecture that extends relational query processing techniques, such as pipelining and adaptive query processing, into the XML realm. We compare the focus of the Tukwila project to that of other XML research systems, and then we present our system architecture and novel query operators, such as the x-scan operator. We conclude with a description of our current research directions in extending XML-based adaptive query processing..." Also in Postscript. A related paper ("An XML Query Engine for Network-Bound Data") has been submitted for publication (2001). See other XML-related publications from the University of Washington Database Research Group, including those of Zachary G. Ives. See: "XML and Databases."
[December 11, 2001] "Authenticating Web Services." By Brian Fonseca and Tom Sullivan. In InfoWorld Issue 49 (November 30, 2001), pages 32-33. "Secure web services authentication that not only recognizes users but also grants access to particular systems is becoming a thorny and contentious issue with few signs of clarity in the near term. With security so high in enterprises' minds, a storm is brewing over standards to ensure that Web services via the Internet can be combined without compromising authentication methods. Microsoft is at the center of the maelstrom, with Sun Microsystems and a cadre of third-party providers attempting to pose XML-based alternatives to Microsoft's controversial Passport authentication. Without many security standards in place, security vendors Netegrity, Oblix, and OpenNetwork are also readying products that allow users to pass along and manage user credentials among what may turn out to be disparate Web services environments. Even as vendors jockey for position, users say the absence of robust authentication and interoperability could be a stumbling block for nascent Web services technologies... XML standards consortium Oasis is steering plans to create a universal security standard to deliver authentication and authorization regardless of platform or vendor. Led by Patrick Gannon, president and CEO of Billerica, Mass.-based OASIS, the group is pushing for adoption of SAML (Security Assertion Markup Language). Developed within the OASIS XML-based Security Services Technical Committee, SAML will provide a basic and interoperable mechanism for exchanging authentication and authorization among applications and parties, Gannon says. 'The key paradigm of Web services is really extending application interaction outside of corporate boundaries. You want to have a standard way of receiving that,' he explains; SAML will help provision services by eliminating the need for users to log in each time to access 'second [level] and third level' application entitlements. A completed SAML draft is expected by early 2002. Oasis will accept specs for approval during the second quarter of 2002. CUNA Mutual Group, the Madison, Wis.-based provider of financial services to credit unions, chose Oblix's offerings due to its level of SAML involvement, says Steve Devoti, directory service manager at CUNA. 'We know to deliver the type of services to [customers], we're going to have to federate with people,' Devoti explains. 'We need [a standard] to ensure there's a smooth hand-off to other directions to ensure what [ID] credentials are.' Third-party security companies are looking to provide some of that interoperability, too, although offerings are still in the works..." See: "Security Assertion Markup Language (SAML)."
[December 11, 2001] "Controlling Access to XML Documents." By Ernesto Damiani (University of Milan), Pierangela Samarati (University of Milan), Sabrina De Capitani di Vimercati (University of Brescia), and Stefano Paraboschi (Milan Polytechnic). In IEEE Internet Computing Volume 5, Number 6 (November/December 2001), pages 18-28. Special Issue on Personalization and Privacy, guest edited by John Riedl (University of Minnesota). ['Access control techniques for XML provide a simple way to protect confidential information at the same granularity level provided by XML schemas.'] "XML's new features imply a complete paradigm shift from HTML that raises new security concerns in the WWW community. Initially, many practitioners assumed that XML documents would automatically benefit from the security standards already in place to deliver HTML pages via HTTP. Later, researchers began investigating XML-specific security measures that would address its richer data model and finer granularity control; work is under way to develop standard XML-based formats for the resources to be protected, their associated metadata, and the policies expressing authorizations. For instance, the adoption of XML for medical records requires tailoring information from XML data sources to the different needs of physicians and patients, preserving confidentiality and avoiding unnecessary duplications. In the same scenario, access control policies themselves should be easy to process and interchange and should check for compliance with externally defined regulations. In this article, we describe our approach to these problems and the design guidelines that led to our current implementation of an access control system for XML information... Our approach exploits XML's own capabilities, using XML markup to describe access authorizations to XML elements. The hierarchical structure of XML documents lets you intuitively specify an authorization's definition: authorizations, when stated for an element, can propagate to the other elements or attributes included in it, unless a more specific authorization is stated for them. The main features of our fine-grained authorizations include Authorization signs: Authorizations can be positive, granting access, or negative, denying access, to an XML element or attribute. The possibility of specifying negative authorizations, while increasing our model's expressive power, introduces potential conflicts among authorizations. Our approach solves such conflicts by giving priority to authorizations specified on more specific subjects or objects, and denying the access (denial takes precedence policy) for unresolved conflicts. Authorization levels: You can add security markup to XML documents and XML schemas to provide document- and schema-level authorizations with the granularity of XML elements and attributes. Schema- and document-level authorizations have complementary roles in increasing access control flexibility. Intuitively, as XML schemas specify structure and content of entire document classes, schema-level security markup lets you quickly and effectively state authorizations that apply to XML elements regardless of the specific document under consideration (as with a <CONFIDENTIAL> tag used consistently in a set of documents). Schema-level authorizations can serve to implement corporate-wide access control policies on document classes. Document-level security markup lets you tailor security requirements for each document, as is required when documents complying with the same XML schema contain information with different protection requirements... [Conclusions:] One of the evident features of our proposed system is its richness, which lets you define sophisticated security requirements but also might require the authorization designer to carefully consider each authorization's implications. Also, the system reads authorizations in an XML format, which the designer might find difficult to manage if the XML representation must be created with a text editor or an unspecialized XML tool. To solve both problems, we implemented a tool in Java offering a graphical interface to the ACP, supporting the definition of user-group hierarchies and authorizations and their rapid interactive evaluation on the XML repository..." See related works referenced in the list of publications from the University of Milan Security Group, Dipartimento di Tecnologie dell'Informazione, including these titles: "An Algebra for Composing Access Control Policies," "An Authorization Model for Temporal XML Documents," "A Component-based Architecture for Secure Data Publication," "Fine Grained Access Control for SOAP E-Services," "An Authorization Model for a Public Key Management Service," "Securing SOAP E-Services," and "Flexible Support for Multiple Access Control Policies." Compare Fine-Grained XML Access Control Project, and see "Extensible Access Control Markup Language (XACML)."
[December 11, 2001] "XML and Data Integration." By Elisa Bertino (University of Milan) and Elena Ferrari (University of Insubria). In IEEE Internet Computing Volume 5, Number 6 (November/December 2001), pages 75-76. Special Issue on Personalization and Privacy, guest edited by John Riedl (University of Minnesota). "XML is rapidly becoming a standard for data representation and exchange. It provides a common format for expressing both data structures and contents. As such, it can help in integrating structured, semistructured, and unstructured data over the Web. Still, it is well recognized that XML alone cannot provide a comprehensive solution to the articulated problem of data integration. There are still several challenges to face. ... XML provides a quite natural way of structuring data, based on hierarchical, graph-based representations. Such models have the advantage of being simple, standard, and well accepted, but also powerful enough to represent structured, unstructured, and semistructured information. Thus, XML works well as a common data model over the Web, and a variety of tools have been marketed to support database contents publishing in XML. In addition, several research efforts have investigated the use of graph-based data models for managing semistructured data and for integrating heterogeneous data sources... The problem of data integration is not new. It has been studied extensively long before XML came to the stage. Although XML can greatly help the task of data integration and reduce the work of reconciling heterogeneous data sources, it is not enough to address the articulated issue of data integration. A key element of data integration is a language for specifying the semantics associated with data content. The W3C has recognized this need. Both the Resource Description Framework (RDF) and Semantic Web working groups are addressing issues related to the representation of semantic aspects of Web data. The Semantic Web working group's primary goal is to define architectures, models, and standards for providing a machine-readable description of the semantics of Web resources. The research is still in its infancy, and several issues require further investigation. The most relevant issues for data integration are developing a formal foundation for Web metadata standards; developing techniques and tools for the creation, extraction, and storage of metadata; investigating the area of semantic interoperability frameworks; and developing semantic-based tools for knowledge discovery. The development of suitable tools for XML-based integration of heterogeneous sources is also important. Those tools must support integration -- automated as much as possible -- at all three data levels: model, schema, and instances..."
[December 11, 2001] "What's a Schema Anyway?" By Dave Peterson. In XML Files: The XML Magazine Issue 32 (December 2001). Edited by Dianne Kennedy. "... [DTD syntax is] a concise language, special purpose for DTDs. It was designed that way, because back in the '80s there were no authoring tools already existing; DTDs had to be read and written entirely by hand. The SGML designers considered writing DTDs using SGML 'tag' markup, but found it too hard to read. On the other hand, now there are tools for authoring XML (and SGML). And there is in the XML culture a desire to do everything with tags when possible. So the Schema designers chose to describe a Schema using an XML document -- that is, using 'tag' syntax. This makes written Schemas (properly called Schema Documents) somewhat 'wordier' -- more difficult to read -- than DTDs, in the raw, but also makes it easier to find tools to help deal with them. The standard that describes schemas makes an explicit distinction between the abstract set of information (the Schema) and the written description thereof (one or more Schema Documents). Not only does this make it easier to understand, it also makes it easier to consider alternate description languages. [With] Schemas you can say a lot more about permitted structures. First of all, not all data in the abstract has to be character strings. You can specify other types: various kinds of numbers, dates, times, etc., and require that certain occurances of data be interpreted as these other types. This is especially handy if you are dealing with all or partly non-character data. Most Schema processors will convert the character strings in the 'concrete' document into appropriate internal representations of the 'abstract' typed data for you, rather than having to have each application have the subroutines to do the conversion. This needs some explanation, since the bit-pattern representations are not specified by the Schema Recommendation -- these representations generally vary from implementation to implementation. Officially, a Schema processor will take the data structure generated by an ordinary XML parser and add to it information contained in the Schema, including information on how each of the character strings of data in the document is to be interpreted. I expect that most Schema processors will in addition directly provide the non-character representation appropriate for the system on which they are running -- why not? Less likelihood of error here, as well as cheaper applications... Schema lets you make these specifications rather uniformly for both attributes and PCDATA: the equivalent in DTD terms of being able to make lexical structure restrictions on PCDATA as well as attributes... There is just one thing you can do with a DTD that you can't do with a Schema: you can't declare entities..." For schema description and references, see "XML Schemas."
[December 10, 2001] "XTAML: XML Trust Axiom Markup Language." By Phillip Hallam-Baker (Verisign). Draft Version 0.12. October 17, 2001. 25 pages. Published by the Verisign XML Trust Center as a Research Note. "The XTAML specification is intended to complement other XML security standards and proposals, in particular XML Signature, XML Encryption, XML Key Management, and Security Assertion Markup Language (SAML). The XML Trust Axiom Markup Language (XTAML) defines SAML Trust Assertions that support the management of trust axioms. A trust axiom is analogous to a root certificate in a certificate based PKI. An important application of trust axioms is managing the trust relationship between a client and a trust service... XTAML is layered on the Security Assertion Markup Language (SAML). XTAML defines statement elements for specifying axiomatic and delegate keys and for asserting the validity status of another assertion. A new condition element is defined that makes the validity status of an assertion dependent on online verification. Two new advice elements are defined to allow an assertion to provide advice on the reissue of the assertion and for issue of related assertions... " Related references: (1) "Security Assertion Markup Language (SAML)"; (2) news item 2001-12-10: "W3C Announces Official XML Key Management Activity"; (3) XML Trust Assertion Service Specification (XTASS) and XML Key Agreement Service Specification (XKASS) from the Verisign XML Trust Center. [cache]
[December 10, 2001] "Internationalized Resource Identifiers (IRI)." By Larry Masinter (Adobe Systems Incorporated) and Martin Dürst (W3C/Keio University). IETF INTERNET-DRAFT. Reference: 'draft-masinter-url-i18n-08.txt'. November 20, 2001; expires May 2002. Abstract: "This document defines a new protocol element, an Internationalized Resource Identifier (IRI). An IRI is a sequence of characters from the Universal Character Set (ISO 10646). A mapping from IRIs to URIs (RFC 2396) is defined, which means that IRIs can be used instead of URIs where appropriate to identify resources. Defining a new protocol element was preferred to extending or changing the definition of URIs to allow a clear distinction and to avoid incompatibilities with existing software. Guidelines for the use and deployment of IRIs in various protocols, formats, and software components that now deal with URIs are provided." Change from v 07: allows 'space' and a few other characters in IRIs to be consistent with XML, XLink, XML Schema, etc. Design considerations: "IRIs are designed to work together with recent recommendations on URI syntax (RFC 2718). In order to be able to use an IRI (or IRI reference in place of an URI (or URI reference) in a given protocol context, the following conditions have to be met: (a) The protocol or format carrying the IRI has to be able to represent the non-ASCII characters in the IRI, either natively or by some protocol- or format-specific escaping mechanism (e.g., numeric character references in XML). (b) The protocol or format element used has to have been designated to carry IRIs (e.g., by designating it to be of type anyURI in XMLSchema)... Please note that some formats already IRIs, although they use different terminology. HTML 4.0 defines the conversion from IRIs to URIs as error-avoiding behavior. XML 1.0, XLink, and XML Schema and specifications based upon them allow IRIs. Also, it is expected that all relevant new W3C formats and protocols will be required to handle IRIs (see the CharMod document, "Character Model for the World Wide Web 1.0")..." Martin Dürst wrote 2001-12-10 with reference to 'draft-masinter-url-i18n-08.txt': [this ID] about the internationalization of URIs (called IRIs) has recently been updated and published. This has been around for a long time, but we plan to move ahead with it in the very near future. Please have a look at the document, and send me any comments that you have soon..." See "XML and Unicode." [cache]
[December 07, 2001] "The Changing Face of Repositories." By Lana Gates. In Application Development Trends Volume 8, Number 12 (December 2001), pages 25-30. ['Emerging industry standards are making distributed repositories a reality; the failed centralized model gives way to a more realistic strategy of using multiple smaller stores for specific functions.'] "As the industry embraces more of a collaborative effort in regard to repositories, the benefits increase for all those involved. Collaboration is a key ingredient the repositories of old lacked. Developers today are more interested in sharing information about assets for developing and describing information to make it available for sharing. For some, that means the Extensible Markup Language (XML). 'We're going to a massively distributed repository with people agreeing on a standard way to share information in those repositories,' noted Dan Hay, product manager for Visual Studio.NET at Microsoft Corp., Redmond, Wash. And that is exactly where the market is now. New industry standards have emerged that help to make distributed repositories a reality. The two most relevant standards in this regard, according to Unisys' Iyengar, are the Meta-Object Facility (MOF) and the XML Metadata Interchange (XMI). Iyengar, who is on the architecture board of the OMG, helped to architect both specifications. MOF is an open, CORBA-compliant framework for describing, representing and manipulating meta information (data describing data). It defines a meta model of an object-oriented application. The meta model is the basic concept a developer puts into a model and then uses to build an application. It can be an attribute, association, class or the like. All of these meta models can be kept in a repository; when they are combined, they become more useful. MOF, which uses the Unified Modeling Language (UML), makes them interoperable... A handful of repository builders have already jumped on the XMI bandwagon, and others are following suit. The recently released Version 2.0 of MetaMatrix's MetaBase Repository is both MOF-based and XMI-compliant. While most repositories in the market were built for the purpose of creating and maintaining data warehouses, MetaBase was created to serve as a meta data management system for information integration... Unisys Corp.'s Universal Repository (UREP), which was available before MetaBase, embraces the OMG's UML, MOF and XMI. The repository supports information sharing across development tools, which is made possible by an extensible, object-oriented meta model, versioning services, configuration management and team-based development approaches. Unisys stopped marketing its repository last year, however, because the market was fairly small and the number of customers ready for a global implementation was a minority, the firm's Iyengar said. Instead, Unisys has 'OEMed' its repository to some independent software vendors while using the technology internally... Microsoft is taking a slightly different tack than the others by focusing more on the Universal Description Discovery and Integration (UDDI) industry standard. Formed by IBM, Microsoft and Ariba Inc., Sunnyvale, Calif., UDDI serves as a repository for Web services, allowing e-businesses to define their business, discover other businesses and share information. UDDI, while not based on a meta model, is an important step in building a distributed infrastructure in the Internet age, according to IDC's Hendrick. It serves as a method to catalog Web services and componentize things... Another area to watch is the OMG's Model Driven Architecture (MDA), which will play an important role in the migration to distributed repositories. MDA, built on UML, MOF, XMI and CWM, is a software architecture based at the model level. Because every year or two a new interoperability paradigm emerges, firms and enterprises conducting business over the Internet need to interoperate with myriad protocols to work with customers and suppliers..." See: (1) Object Management Group (OMG) and XML Metadata Interchange Format (XMI); (2) OMG Common Warehouse Metadata Interchange (CWMI) Specification; (3) OMG Model Driven Architecture (MDA).
[December 07, 2001] "The Repository Returns." By Michael W. Bucken. Editorial. In Application Development Trends Volume 8, Number 12 (December 2001), page 4. "... The idea of a repository brought us IBM's AD/Cycle strategy, whose promise prompted Microsoft to sign up Texas Instruments Inc. to build the Microsoft Repository. This led the former Platinum Technologies Inc. to buy the BrownStone and Reltech repositories, each based on much touted technologies that promised to radically change the corporate development process. Unfortunately, for more reasons than we can recount here, repository-based development failed to deliver the goods to IT development shops... In this month's Cover Story, regular contributor Lana Gates and ADT Editor-at-Large Jack Vaughan examine how some newer, lighter-weight technologies and emerging industry standards are leading to the creation of distributed repositories that observers see as more modest and cost-effective than the centralized model, but promising support for a slew of tools and technologies. As IDC analyst Steve Hendrick points out, the definition of a development repository has evolved from a centralized storage facility for general information to a specialized store for specific development and deployment activities based on open industry standards. An embrace of emerging standards like XML, XMI, RDF and others could create a distributed repository to support multiple tools, programming languages and methods -- a far more advanced solution than AD/Cycle or the Microsoft Repository. But the new architecture is totally dependent on standards. Throughout the history of this business, standards have promised to provide a level playing field for providers of development solutions, and a far easier decision-making process for the buyers of those products... IT firms can guard against a similar bastardization of repository standards by demanding that suppliers support the standards as written by the Object Management Group and World Wide Web Consortium (W3C). New repository technologies can bring IT organizations some significant benefits. But you must keep the pressure on vendors to follow the standards..."
[December 07, 2001] "Java and .NET Can Live Together." By Richard Adhikari. In Application Development Trends Volume 8, Number 12 (December 2001), pages 31-33. ['Even Microsoft concedes its highly touted .NET platform won't purge IT units of Java tools and technologies. Tools to ease the process of linking Java and .NET technologies are emerging quickly.'] "With Microsoft throwing its formidable weight behind .NET services, there is little doubt that people will begin using it. But this will not make Java go away. Like the hardy mainframe, which not only refused to disappear with the advent of client/server but also remained strong enough to co-exist with the technology, Java is here to stay. That means corporations need to find some way to get their Java and .NET applications to talk to one another... Among the solutions on the market is bridging software to enable Java and .NET applications to communicate. JavaCOM applications can also serve as bridges, but developers can run into various snags while using them. Then there are Web services and the industry-driven Simple Object Access Protocol (SOAP). Proponents say these technologies will link Java and .NET services. But SOAP has its own problems, and skeptics say it will be just another solution instead of the be-all and end-all its supporters claim it will be... One currently available software bridge is the Remote Java ActiveX (R-JAX) Server from Halcyon Software Inc., San Jose, Calif. R-JAX links Microsoft ActiveX, DLL and COM to any Java application, running either remotely or locally, on any Java-enabled platform, whether it is Windows or not. Users can manipulate the available methods and properties and get back results. Users can generate proxy Beans with the R-JAX Bean Generator. This allows users to create JavaBean components, including remote connectivity code, based on the COM or DLL object description. It lets the components created communicate with the R-JAX server, making remote COM components accessible... Users with internal human resources applets or other applets with light footprints can use R-JAX's client-level API, noted [Naufal] Khan. This allows them to invoke a method without generating a proxy. R-JAX supports HTTP, Remote Method Invocation (RMI), a key protocol in Java for remote procedure calls, and the Transmission Control Protocol (TCP). Users, including developers, do not need to know how to configure these protocols, said Khan; they just select what they want from a pull-down menu...Many vendors agree that SOAP-based Web services will provide the bridge between Java and .NET. 'If you have a single standard that uses HTTP as its support, you can access data from different sources without rewriting the underlying code,' said Tom Clement, director of emerging technologies at Avinon Inc., San Francisco. 'There are tools that let you take older COM-based objects and expose them as a SOAP-based Web service and they are also available for J2EE.' SOAP's possibility of creating interoperability between Java and .NET is 'more than a promise, but less than reality' because there are no universally accepted standards now, he added... David Spicer, CEO and CTO at Flamenco Networks Corp., Alpharetta, Ga., said the emergence of the Web Services Description Language (WSDL) and SOAP have released a pent-up demand to get applications talking. 'You can now hook up Pascal programs to Java programs and they're all communicating through Web services,' Spicer said, adding that SOAP will create a bridge between Java and .NET..."
[December 07, 2001] "Knowledge Portals and the Emerging Digital Knowledge Workplace." By R. Mack, Y. Ravin, and R. J. Byrd. In IBM Systems Journal Volume 40, Number 4 (2001). Special Issue on Knowledge Management. Article with 83 references. ['Knowledge portals are single-point-access software systems intended to provide easy and timely access to information and to support communities of knowledge workers who share common goals. In this paper we discuss knowledge portal applications we have developed in collaboration with IBM Global Services, mainly for internal use by Global Services practitioners. We describe the role knowledge portals play in supporting knowledge work tasks and the component technologies embedded in portals, such as the gathering of distributed document information, indexing and text search, and categorization; and we discuss new functionality for future inclusion in knowledge portals. We share our experience deploying and maintaining portals. Finally, we describe how we view the future of knowledge portals in an expanding knowledge workplace that supports mobility, collaboration, and increasingly automated project workflow.'] "We refer to information portals used by knowledge workers as knowledge portals (or K Portals for short) to differentiate this KM role and usage from other portal roles, such as consumer shopping or business-to-business commerce. K Portals are rapidly evolving into broad-based platforms for supporting a wide range of knowledge worker (KW) tasks... [Figure 9 on] portal application architecture and implementation' indicates the major K Portal components we have developed, beginning with 'Gather/Analyze Content.' This crawling component gathers and extracts text and meta-data content from collections of documents distributed in multiple repositories over a network. The extracted content is rendered in a standard XML format, which allows its exploitation by various text analysis and indexing processes. The XML meta-data are loaded into relational database (RDB) tables, as are the category features. The text content of the documents is indexed in a searchable text index, and the documents are automatically categorized. Search and navigation functions in the application client (UI) are based on real-time access of text search engines and RDB tables by a set of run-time classes... The Knowledge Map editor (K-Map) tool is used to create specifications that control crawling and categorization. Note that the use of the term K-Maps is rapidly becoming a generic term with slightly different meanings in different contexts, e.g., in the IBM Global Services K Portal and the Lotus Knowledge Discovery System. However, most uses refer to the capability of building and editing taxonomies. From a knowledge administrator's point of view, K-Maps are intended to specify what repositories to access for the portal and how to categorize documents. K-Maps are implemented as XML descriptions that can be interpreted by the K Portal indexing, analysis, and categorization programs in order to control their behavior. K-Maps are high-level tools used to create taxonomies. They have the look and feel of a directory navigator, and allow users to drag and drop training documents into subcategories. Other capabilities under development include forms for capturing rules that specify what repositories to crawl, or alternative rule-based methods for categorizing documents. From a programming viewpoint, K-Maps are intended to facilitate the maintenance of K Portal administration programs with declarative specifications for how to organize information and manage the interoperability of software components. For example, in the IBM K Portal context, K-Maps might be used to control the crawling process (specifying sources and crawling parameters), to control how crawler output is to be used in text indexing and categorization processes, and to specify how users view and navigate taxonomies in the K Portal Web client user interface. K-Maps are a major step toward a new information and software architecture where software components are services that interact in a standard XML protocol, and where a declarative set of attributes represents implied rules for the operation of each service, its required input, and the results it produces. The use of XML is also changing the nature of the analysis processes -- text analysis and information extraction are now XML enabled. New search engines are being developed to allow searches on XML structures that represent both textual features and meta-data.58 As a consequence, component applications do not need to be compiled together, but can interact in simple, standard ways, based on simple Web-based client-server protocols..." Also available in PDF format.
[December 07, 2001] ZVON Cheatsheets. From the Zvon 'Guide to the XML Galaxy.' Notice posted by Jiri Jirat: "We have prepared paper versions of some our references... these include XHTML, XML Schema, MathML, Schematron, ... I hope, you'll find them useful. BTW, it's an example of XSLT + XSL FO + SVG in action :-)..." Includes paper versions of these reference compilations: XSL FO Reference, VoiceXML Reference, MathML Reference, [XHTML Basic] Reference, XHTML Reference, XML Schema 2001 Reference, XML Schema 2000/10 Reference, Schematron reference.
[December 07, 2001] Practical Formatting Using XSLFO. Extensible Stylesheet Language Formatting Objects. Book excerpt (179 of 341 pages). By G. Ken Holman, from Crane Softwrights Ltd. First Edition, 2001-12-05. ISBN: 1-894049-07-1. 341 Pages. Ken writes: "The XSLFO book is in its first release. This book has hyperlinks from the text of the renditions directly to the W3C Recommendation document, allowing you to learn from our book yet have instant access to the W3C documents. Both editions have the following hyperlinks [note in Acrobat reader the ctrl-left arrow is the Back key]: (1) page references in text (2) chapter references in module summary (3) section references in chapter summary (4) table of subsections at back of book (5) external links to web browser... In addition to the PDF renditions, we now include an accessible version of each of our books and the previews for the books. These renditions use monospaced fonts that are friendly to screen readers. These are produced using XSLFO using RenderX (previous editions were published using DSSSL) ... all our training material is authored in XML..." For related resources, see "Extensible Stylesheet Language (XSL/XSLT)."
[December 07, 2001] "UBL: The Next Step for Global E-Commerce." UBL White Paper. UBL Marketing Subcommittee Draft 0.14. 5 December 2001. 11 pages. "XML is often described as the lingua franca of e-commerce. The implication is that by standardizing on XML, enterprises will be able to trade with anyone, anytime, without the need for the costly custom integration work that has been necessary in the past. But this vision of XML-based 'plug-and-play' commerce is overly simplistic. Of course XML can be used to create electronic catalogs, purchase orders, invoices, shipping notices, and the other documents needed to conduct business. But XML by itself doesn't guarantee that these documents can be understood by any business other than the one that creates them. XML is only the foundation on which additional standards can be defined to achieve the goal of true interoperability. The Universal Business Language (UBL) initiative is the next step in achieving this goal... The primary deliverable of UBL is a set of standard formats for common business documents such as invoices, purchases orders, and advance shipment notices. These formats are designed to be sufficient for the needs of many ordinary business transactions and, more importantly, to serve as the starting point for further customization. To enable this customization, the standard document formats will be made up of standard 'business information entities,' which are the common building blocks (addresses, prices, and so on) that make up the bulk of most business documents. Basing all UBL document schemas on the same core information entities maximizes the amount of information that can be shared and reused among companies and applications. In a UBL-enabled world, companies publish profiles of their requirements for the business documents involved in specific interactions. These profiles specify the business context of each transaction, that is, specific parameters such as the industries and geographic regions of the trading partners. The context parameters are applied to the standard formats to create new formats specific to a given transactional setting. Since these context-specific formats are based on the standard components, interoperability is guaranteed while taking into account the requirements of each party to a particular transaction..." Reference posted on the UBL mailing list December 5, 2001. 'The draft of a white paper on UBL prepared by the UBL Marketing Subcommittee can be found [online]; please review and send comments to Jon Bosak [Chair, UBL Marketing Subcommittee].' Document also available in StarOffice version 6.0 format. See: "Universal Business Language (UBL)." [source]
[December 06, 2001] "Using Emacs for XML Documents. Install add-ons to the powerful Emacs text editor to build a platform-independent (and free) environment for working with XML." By Brian Gillan (Software engineer, ID Technology and Design Group, IBM). From IBM developerWorks XML Zone. December 2001. PSGML is based upon Lisp code that configures menu options and other behaviors of Emacs to create a menu-driven, syntax-controlled editing environment sensitive to constraints and options expressed in XML DTDs. ['Emacs, best known as a powerful text editor for UNIX developers, can be an ideal XML editor for MS-DOS, Windows, and MacOS. The author describes how to install the right add-on packages and modify settings to create a powerful XML/SGML editing-and-validation environment in Emacs with extensions such as PSGML and OpenSP. Most of the work involved in setting up this environment ends with downloading and installing Emacs and the individual packages, but you must also configure Emacs properly and enable the DTDs you plan to work with. The article includes sample configuration files and XHTML DTDs.'] "Though it's best known as a powerful text editor favored by UNIX developers, Emacs can be used to work with XML in non-UNIX platforms such as Windows, MS-DOS, and MacOS. Emacs works as a full-blown development environment for processing text, writing applications, and, as I'll discuss, creating structured information like XML and SGML. I use it as a general-purpose editor for creating and managing some of my programming projects, and for writing XHTML and playing around with SGML and XML. In fact, I used it to write this article. This article tells how to install Emacs and the extensions PSGML and OpenSP. It also outlines how to customize Emacs to make it function with a variety of DTDs. I present many of the Emacs customizations one piece at a time. However, you can download a zip file with sample DTDs and all of the Emacs customizations. My intent is to get you started using Emacs by providing you with just enough information for you understand what's going on. Then you'll be able to add DTDs and customize Emacs based on your needs and preferences..." PSGML version 1.2.3 was released on SourceForge November 8, 2001; see the download. References: (1) the tutorial from Bob DuCharme, "SGML CD: Free SGML Software and How to Use It"; (2) PSGML links in "PSGML, by Lennart Staflin and David Megginson."
[December 06, 2001] "Interview: Oracle's Jeremy Burton Talks XML." By Michael Vizard and Steve Gillmor. In InfoWorld (December 5, 2001). "At its Oracle OpenWorld user conference in San Francisco this week, Oracle jumped into the Web services fray with both feet. In a bid to gain marketshare in the J2EE (Java 2, Enterprise Edition) application server world, Oracle has added support for Web services standards in Oracle9iAS, along with better clustering, wireless capabilities, and bolstered security. To make XML-based Web services integral to its flagship relational database, Oracle is detailing a project called XDB (XML database support), which is designed to provide high-performance XML document storage. Oracle's vice president of worldwide marketing Jeremy Burton spoke to InfoWorld editors Michael Vizard, Steve Gillmor, Martin LaMonica, Tom Sullivan, and Mark Leon about Oracle's views on emerging software technologies and architectures... [What are the different levels of 'XML support'?] Burton: [The first level is] if we look at the tags in the XML document and we can build an index based on those tags, and although the document is stored in kind of one big chunk, we can make the document searchable from standard SQL. The next level I guess would be is as the document goes in, you do a certain amount of parsing of the XML document and you apply structure to the data as it goes into the database. Now, the overhead is that you've got to do parsing so there's a performance hit there. But the upside is that you can add a bit more structure to that document, you don't store it in one piece. So if you just want to search abstracts, for example, or conclusions of documents that are tagged with XML, then you can do that. So maybe you've got XML documents which have an introduction, body, and conclusion. You could store the introduction, body, and conclusion separately and search those three things independently. Or, if you want to take more of a hit when the document goes in, you can write some code to parse the entire document so you can do more granular searching. The big problem with doing a lot of parsing and adding structure is that you take a performance hit. Why? Because when you've got a relational database, a table is a different shape to a series of nested structures, which is what an XML document is... So most [vendors], right now, they can take the document and store it in a database and make it opaque. I think ourselves and probably IBM can index the document as it goes in and make it searchable. And I guess there's much debate over how much structure you can add to a document and how searchable you can make it. I'd say we do some things that IBM can't do, but it's not a long-term defensible advantage. So we set about kind of solving the problem for good, and one of the things that we have [is] called XDB, a project at Oracle. One of the underlying technologies that our new system is based on is objects. If you look at an XML document, it's a series of nested structures. If you look at objects in the database, it's a series of nested structures. And the XML document by and large is exactly the same shape as the object in the database. If you're then [storing] that object, you can do it in a very high-performance way -- there's no huge amount of parsing and flattening of structures and then reconstituting them later. The beauty of it as well from the way we've implemented our objects is that your application need not know nor care whether they're dealing with SQL, relational information, or structured XML-related information. And we also store the document in a very highly compressed way. We add structure to the document, we store it in the objects. And then the tags we pull out and store in a separate metadata directory. All the time we're building a directory of every tag available that your company deals with, and it often means we can store the information in a very highly compressed form..." See: "XML and Databases."
[December 06, 2001] "XML Watch: Bird's-eye BEEP. Part 1 of an introduction to the Blocks Extensible Exchange Protocol standard of the IETF." By Edd Dumbill (Editor and publisher, xmlhack.com). From IBM developerWorks. December 2001. ['While debate continues on reusing HTTP as a convenient way to connect applications, a new protocol called BEEP -- Blocks Extensible Exchange Protocol -- has been standardized by the Internet Engineering Task Force (IETF). Making use of XML itself, BEEP does for Internet protocols what XML has done for documents and data. In his first column for developerWorks, seasoned XML observer Edd Dumbill explains how BEEP provides a framework that allows developers to focus on the important aspects of their applications rather than wasting time with the detail of establishing communication channels.'] "Welcome to the first article in a series that will examine the practicalities of using new XML-based technologies. In these columns, I'll take a look at an XML technology, and at attempts to deploy it in a practical system. In addition to reporting on the deployment experience, I expect to have some fun along the way too. I won't expect too much prior knowledge from the reader, but a grounding in basic Web standards such as XML and HTTP will help. Why [do] we need another type of distributed computing protocol to add to CORBA/IIOP, SOAP, XML-RPC, and friends.... BEEP sits at a different level. It's a framework. SOAP can happily be implemented on top of BEEP. BEEP takes care of the connections, the authentication, and the packaging up at the TCP/IP level of the messages -- matters that SOAP deliberately avoids. BEEP really competes on the same level as HTTP... This is the best way to look at BEEP: it is essentially a refactoring of an overloaded HTTP to support the common requirements of today's Internet application protocols. BEEP is a peer-to-peer protocol, which means that it has no notion of client or server, unlike HTTP. However, as with arguments and romance, somebody has to make the first move. So for convenience I'll refer to the peer that starts a connection as the initiator, and the peer accepting the connection as the listener. When a connection is established between the two, a BEEP session is created. All communication in a session happens within one or more channels, as illustrated in Figure 1. The peers require only one IP connection, which is then multiplexed to create channels. The nature of communication possible within that channel is determined by the profiles it supports (each channel may have one or more.) The first channel, channel 0, has a special purpose. It supports the BEEP management profile, which is used to negotiate the setup of further channels. The supported profiles determine the precise interaction between the peers in a particular channel. Defining a protocol using BEEP comes down to the definition of profiles..." Article also in PDF format. See: "Blocks eXtensible eXchange Protocol Framework (BEEP)."
[December 06, 2001] "IETF BEEP (RFC 3080). A Framework for Next Generation Application Protocols." By Eamon O'Tuathail. November 2001. Technical Whitepaper by Clipcode.com. "BEEP (the Blocks Extensible Exchange Protocol) is a new specification that provides a common set of services to help designers of application protocols. In the past, when designers were faced with the need for a new application protocol, they had to either face the daunting task of designing a complete new protocol - which is a lot of work, or somehow piggyback on top of an existing protocol (usually HTTP) - and live with all the advantages and disadvantages of the existing protocol. BEEP is a new approach that recognizes that many application protocols are trying to solve the same set of issues again and again. "How do I set up a connection?" "What message exchange styles should be supported (e.g. one-way, request/response, request/N-response)?" "What about security?" "Who can initiate a message exchange -- the client, the server, or both?" "Is asynchronous messaging to be supported (sending multiple messages at the same time)?" The reusability theory that object-oriented professionals have been preaching since the '80s can easily be applied to the design of application protocols - and that is exactly what BEEP does. BEEP tackles those issues that are common to many application protocols once, and leaves the design of the remaining 10% to 20% of issues that are unique to each application protocol to the designers of that application protocol...Example uses of BEEP include distributed application-to-application communication, distributed user interfaces, web services and peer-to-peer services. Rather than targeting every possible application protocol type, BEEP is aimed at a specific subset with a well-defined list of attributes. BEEP is connection-oriented -- which means that a connection is established and maintained -- and then messages flow over this, and sometime later the connection is closed. BEEP supports asynchronous interactions, which mean either party to the connection can initiate a message exchange. BEEP defines the concept of discrete messages that belong to well-defined message exchange patterns. The result of this is that BEEP is suitable for some application protocols, such as peer-to-peer communications, and not suitable for others..." See: "Blocks eXtensible eXchange Protocol Framework (BEEP)."
[December 05, 2001] "Mesh Based Content Routing Using XML." By Alex C. Snoeren, Kenneth Conley, and David K. Gifford (MIT Laboratory for Computer Science, Cambridge, MA, USA 02139). Presented at the 18th ACM Symposium on Operating Systems Principles (October 21-24, 2001, Chateau Lake Louise, Banff, Canada; sponsored by ACM SIGOPS). 14 pages, with 43 references. "We have developed a new approach for reliably multicasting time-critical data to heterogeneous clients over mesh-based overlay networks. To facilitate intelligent content pruning, data streams are comprised of a sequence of XML packets and forwarded by application-level XML routers. XML routers perform content-based routing of individual XML packets to other routers or clients based upon queries that describe the information needs of down-stream nodes. Our PC-based XML router prototype can route an 18 Mbit per second XML stream. Our routers use a novel Diversity Control Protocol (DCP) for router-to-router and router-to-client communication. DCP reassembles a received stream of packets from one or more senders using the first copy of a packet to arrive from any sender. When each node is connected to n parents, the resulting network is resilient to (n-1) router or independent link failures without repair. Associated mesh algorithms permit the system to recover to (n-1) resilience after node and/or link failure. We have deployed a distributed network of XML routers that streams real-time air traffic control data. Experimental results show multiple senders improve reliability and latency when compared to tree-based networks... Our work on XML routers and DCP builds on a large body of past work in reliable multicast and overlay networks. We consider related work in four areas: reliable multicast, overlay networks, redundant coding and transmission schemes, and publish-subscribe networks. Of particular note is RMX, which shares similar goals with our work. RMX provides real-time reliable multicast to hetero-geneous clients through the use of application-specific transcoding gateways. For example, it supports re-encoding images using lossy compression to service under-provisioned clients. By using self-describing XML tags, our architecture allows similar functionality to be provided in a general fashion by having clients with different resource constraints subscribe to different (likely non-disjoint) portions of the data stream... [Conclusions and future work:] This paper presented three key ideas. First, we introduced the idea of XML routers that switch self-describing XML packets based upon any field. Second, we showed how XML routers can be organized into a resilient overlay network that can tolerate both node and link failures without reconfiguration and without interrupting real-time data transport. Finally, we introduced the Diversity Com-munication Protocol as a way for peers to use redundant packet transmissions to reduce latency and improve reliability. A wide variety of extensions can be made to the work presently reported, both in protocol refinements and additional functionality. We are actively investigating methods of DCP self-tuning, both for adaptive timers and sophisticated flow control. DCP can also can be used for uninterpreted byte streams. Thus, DCP-like ideas may find application in contexts outside of XML routers. For example, contemporary work on reliable overlay networks (RONs) could use DCP as a RON communication protocol to maximize performance and reliability... Within the scope of XML routing, our current XML routers could be extended to support: (1) More sophisticated XML mesh building and maintenance algorithms. (2) Combiners that integrate multiple XML streams for multicast transport as a single stream. (3) Using XML routers for duplex communication. Other XML network components, such as stream storage and replay. (4) Transcoding XML routers that produce output packets that are derivatives of input packets, based upon client queries. Even in its current form, however, we believe our architecture demonstrates XML is a viable mechanism for content distribution, providing a natural way to encapsulate related data, and a conve-nient semantic framing mechanism for intelligent network transport and routing..." On RMX, see following item. [cache]
[December 05, 2001] "RMX: Reliable Multicast in Heterogeneous Environments." By Yatin Chawathe, Steven McCanne, and Eric Brewer. In Proceedings of IEEE INFOCOM 2000 (Tel Aviv, Israel, March 2000), pages 795-804. "Although IP Multicast is an effective network primitive for best-effort, large-scale, multi-point communication, many multicast applications such as shared whiteboards, multi-player games and software distribution require reliable data delivery. Building services like reliable sequenced delivery on top of IP Multicast has proven to be a hard problem. The enormous extent of network and end-system heterogeneity in multi-point communication exacerbates the design of scalable end-to-end reliable multicast protocols. In this paper, we propose a radical departure from the traditional end-to-end model for reliable multicast and instead propose a hybrid approach that leverages the successes of unicast reliability protocols such as TCP while retaining the efficiency of IP multicast for multi-point data delivery. Our approach splits a large heterogeneous reliable multicast session into a number of multicast data groups of co-located homogeneous participants. A collection of application-aware agents -- Reliable Multicast proXies (RMXs) -- organizes these data groups into a spanning tree using an overlay network of TCP connections. Sources transmit data to their local group, and the RMX in that group forwards the data towards the rest of the data groups. RMXs use detailed knowledge of application semantics to adapt to the effects of heterogeneity in the environment. To demonstrate the efficacy of our architecture, we have built a prototype implementation that can be customized for different kinds of applications..." [alt URL, cache]
[December 05, 2001] "The Platform for Privacy Preferences 1.0 Deployment Guide." W3C Note 30-November-2001. Author/Editor: Martin Presler-Marshall (IBM). This release updates the version of 2001-07-24. Version URL: http://www.w3.org/TR/2001/NOTE-p3pdeployment-20011130. Latest VersionURL: http://www.w3.org/TR/p3pdeployment. "This is a guide to help site operators deploy the Platform for Privacy Preferences (P3P) on their site. It provides information on the tasks required, and gives guidance on how to best complete them. The Platform for Privacy Preferences (P3P) provides a way for Web sites to publish their privacy policies in a machine-readable syntax... A Web site will deploy P3P in order to make its privacy practices more transparent to the site's visitors. P3P defines a way for sites to publish statements of their privacy practices in a machine-readable format. A visitor's Web browser can then download those machine-readable privacy statements, and compare the contents of those statements to the user's preferences. This way, the user's browser can automatically notify the user when they visit a site whose practices match the user4s preferences - or warn the user if the practices and preferences don't match... A P3P policy file contains a description of data collection, use, and sharing practices. It does not, however, declare what that policy applices to. P3P uses a separate file, called a policy reference file, to list the P3P policies in use at a site (or portion of a site), and what portions of the site and what cookies are covered by each policy... P3P policy reference files list the P3P policies which a site is currently using, and map out what parts of the site each one applies to. This mapping is done by giving a list of one or more URL patterns that each policy applies to. Each pattern is a local URL, and is allowed to contain wildcards. Thus a policy reference file might say that policy 'policy-1' applies to just /index.html, or to /content*, which means 'all URLs on this host that begin with /content'. Policy reference files use the <INCLUDE> element to indicate what URLs are covered by a specific policy." Principal document revisions: [1] Addition of a section describing restrictions in the use of the compact policy format. "In addition to the full XML privacy statements defined by P3P, P3P also defines a compact policy format. The compact policy summarizies the portion of the P3P policy which applies to the cookies in a response. The summary is sent in a simple, compact syntax. The compact policy is returned as an HTTP response header. This means that the client will have the compact policy available to it when it considers any cookies sent by the site. The use of compact policies is optional for Web sites; however, their use is strongly encouraged. Due to their location and simple syntax, compact policies can be quickly processed by clients, allowing them to make decisions on processing the cookies in that response. [2] An updated Appendix section A.3 'Microsoft Internet Information Server' which covers Microsoft Internet Information Server (IIS) on a Microsoft Windows 2000 Server platform; the P3P header can be added through the IIS snap-in from the Computer Management console (MMC) on a Microsoft Windows 2000 server. This section shows how to associated a web page with its P3P privacy policy. See also the W3C P3P specification and the list of P3P implementations. Local references: (1) the news item, and (2) "Platform for Privacy Preferences (P3P) Project."
[December 03, 2001] "Zvon Relax NG Reference." By Jiri Jirat. From the Zvon.org "Guide to the XML Galaxy." November 21, 2001 or later. Note that the Relax NG Reference guide available 2001-12-02 reflects the RELAX NG Committee Specification 0.9 of August 11, 2001. The release of RELAX NG Version 1.0 as a Committee Specification has been announced.
[December 03, 2001] "The XMLReader Interface." By Elliotte Rusty Harold. Chapter 7 of Processing XML with Java. Published on Cafe con Leche. ['Processing XML with Java is a complete tutorial about writing Java programs that read and write XML documents. This is an approximately 700 page book that will be published by Addison-Wesley in Spring 2002.'] This chapter covers: (1) Locating XML parsers with XMLReaderFactory; (2) The different kinds of SAXException; (3) Reading a document from an InputSource; (4) Using EntityResolver to substitute DTD modules and other entities; (5) Reading DTDs with DeclHandler; (6) Accessing unparsed entities and notations through DTDHandler; (7) Lexical events reported by the LexicalHandler; (8) Configuring the parser with features and properties... The XML specification grants parsers a sometimes confusing amount of leeway in processing XML documents. Parsers are allowed to validate or not, resolve external entities or not, treat non-deterministic content models as errors or not, support non-standard encodings or not, check for namespace well-formedness or not, and much more. Depending on exactly which choices two parsers make for all these options, they can actually produce quite different pictures of the same XML document. Indeed, in a few cases one parser may even report a document to be well-formed while another reports that the document is malformed. To support the wide range of capabilities of different parsers, the XMLReader interface that represents parsers in SAX is quite deliberately non-specific. It can be instantiated in a variety of different ways. It can read XML documents stored in a variety of media. It can be configured with features and properties both known and unknown. This chapter explores in detail the configuration and use of XMLReader objects..."
[December 01, 2001] "Improving Web Linking Using XLink." By David Lowe (University of and Technology, Sydney) and Erik Wilde (Swiss Federal Institute of Technology, Zürich). Paper presented at Open Publish 2001 (First Open Publish Conference. July 30, 2001 - August 02, 2001. Sydney Hilton Hotel, Sydney, Australia). ['XML has heralded a substantial change in the way in which content can be managed. Prominent among these changes is the greatly enhanced model for linking functionality that is enabled by the emerging XLink and XPointer standards.'] "Although the Web has continuously grown and evolved since its introduction in 1989, the technical foundations have remained relatively unchanged. Of the basic technologies, URLs and HTTP has remained stable for some time now, and only HTML has changed more frequently. However, the introduction of XML has heralded a substantial change in the way in which content can be managed. One of the most significant of these changes is with respect to the greatly enhanced model for linking functionality that is enabled by the emerging XLink and XPointer standards. These standards have the capacity to fundamentally change the way in which we utilise the Web, especially with respect to the way in which users interact with information. In this paper, we will discuss some of the richer linking functionality that XLink and XPointer enable -- particularly with respect to aspects such as content transclusion, multiple source and destination links, generic linking, and the use of linkbases to add links into content over which the author has no control. The discussions will be illustrated with example XLink code fragments, and will emphasise the particular uses to which these linking concepts can be put..." See "XML Linking Language." [cache]
November 2001
[November 30, 2001] "UDDI Promises Link To Web Services. Upcoming version in early 2002 will include security, way to link registries; may jump-start vendor-led standard." By Tim Wilson. In InternetWeek (November 26, 2001). "UDDI, which was developed by Ariba, IBM, Intel, Microsoft and SAP, is a set of specifications designed to help companies publish information about themselves, their Web services and the interfaces required to link with those services. Essentially, UDDI is a combination of three elements. An electronic 'white pages' lists basic contact information for parties involved. A 'yellow pages' offers details about companies and descriptions of the electronic capabilities they offer to their trading partners. And a data dictionary, or 'green pages,' lists the standards and software interfaces that partners must comply with to execute those electronic functions using XML as a common language... So far, UDDI is very much in its pilot phase. IBM and Microsoft have established working UDDI Business Registry nodes. And Hewlett-Packard and SAP are scheduled to launch nodes by the end of this year. A few smaller service providers, including Cape Clear and TransactTools, have rolled out UDDI offerings, but most user companies haven't done much more than provide their names and addresses. About 5,000 companies have added their contact information to the white pages portion of the UDDI Business Registry, said Tom Glover, program manager for the UDDI.org consortium. A reasonable percentage have added yellow pages data about what they do and the Web services they plan to offer, Glover said. UDDI's green pages have yet to be populated... Today, most businesses use the Internet to communicate on a bilateral, ad hoc basis. For example, if Company A wants to send a purchase order via the Web to Company B, an IT person from Company A must call Company B on the phone, find out if it accepts Web-based purchase orders, and collect information on acceptable purchase order formats and interfaces for linking to Company B's order-entry application. Multiply this process by 100 different documents--invoices, shipping confirmations, requests for information--and 1,000 different suppliers, and it becomes a time-consuming and resource-intensive effort. With UDDI, companies would enter those capabilities in a registry, essentially a listing of all the electronic functions that a company offers to its partners. Public registries, such as those currently offered by IBM and Microsoft, are likely to be accessible by any company doing business on the Internet. Most companies, however, will build private registries that can only be accessed by approved trading partners, analysts say. Using the XML descriptions stored in the registry, companies will find out if a particular supplier supports specific types of Web interfaces, such as RosettaNet or Microsoft BizTalk. Once a company has found the interface for linking to the supplier, its IT staff can use the registry to pull up the exact technical steps required to link to that supplier. Then the two companies can use the emerging Simple Object Access Protocol (SOAP) to exchange data via the Internet, even if their back-end systems are made by different vendors. The UDDI specification itself is a set of rules for describing electronic capabilities via XML and a method of registering and discovering those descriptions via the Web. The second version of the UDDI specification also describes a way for linking registries, so that if a company puts information about itself in one registry, the data can be shared by other registries as well. All companies must enter their own information in the registry, but many companies will rely on a third party -- such as a public e-marketplace or industry Web portal -- to search out potential partners and the means of accessing their services, experts said..." See: (1) description of version 2 beta implementations; and (2) references in "Universal Description, Discovery, and Integration (UDDI)."
[November 30, 2001] "Two Ways to Bring XML to Your Databases." By Maggie Biggs. In InfoWorld Issue 49 (November 30, 2001), page 20. "It's no wonder relational databases are beginning to support the XML standard; XML is fast becoming the de facto method of data exchange in e-business settings. But before you implement your XML processing strategy, you need to consider another option: native XML databases. Native XML databases do not replace your traditional relational database, nor do they negate the benefits of native XML support in relational databases. Native XML databases support a variety of database access types and application programming interfaces you can use to perform XML translations and to store XML documents in their native form. By using a native XML database to stage data for XML processing, you can effectively support all of your data sources without having to outfit each one with native XML handling capabilities. There are two principal reasons to implement a native XML database..."
[November 30, 2001] "Pushed Off The Fence. Prodded by Intel to replace EDI, Air Products becomes XML Activist." By Mike Koller. In InternetWeek (November 26, 2001), pages 1, 50. "Pressured to adopt XML by Intel, one of its biggest customers, Air Products and Chemicals, Inc. quickly morphed from fence-sitter to evangelist. Now the company plans to deploy XML for transactions with its top 50 customers by the end of 2002. Intel wanted the $5.5 billion maker of industrial gases to certify the purity of gas cylinders used to clean wafer chips in its manufacturing process, and it wanted the documents in a format that could easily accept Intel's changes to specifications. Air Products, a large Microsoft shop, chose the software developer's BizTalk Server to format those documents in XML and transmit them over the Internet. It was able to begin conducting XML transactions in just six weeks, at a cost of under $1 million. That speed was a critical factor in retaining Intel's business. Now, Air Products has set its sights on managing transactions with nearly two dozen customers -- including Dow Chemical and BASF -- through the Elemica chemical industry exchange and its ChemXML implementation. It will connect another two dozen or so customers through a combination of exchanges and point-to-point connections similar to those it has with Intel. Because XML runs over the Internet or an e-marketplace, it eliminates fees to EDI value-added network providers. It's also easier to use and more flexible, so it requires less investment in systems maintenance. The lower cost, in turn, translates into easier and more voluminous connections with suppliers, and therefore the ability to conduct more transactions electronically. Air Products' partners are bullish about transacting business with XML. Intel pushed Air Products toward XML after increasing the amount of data required in its documentation. EDI, the existing communications mechanism between the two companies, couldn't easily accommodate the changes, explained Dave Beltz, manager of B2B integration at Air Products... In response, Air Products implemented BizTalk Server, which costs $25,000 for an enterprise edition. Though Air Products wouldn't provide precise cost figures, an XML conversion effort of this nature typically carries many costs besides the software license, said Forrester Research analyst Chris Dial. They include building adapters to connect systems to BizTalk, which often means hiring systems integrators for custom development. Today, the process works like this: When a gas cylinder is filled, an Air Products technician tests a sample of the gas. Results of the test are stored in a mainframe application, prompting creation of a 'certificate of analysis' that's sent via FTP to BizTalk, running on two load-balanced Windows 2000 servers. BizTalk converts the document to XML, and a copy is stored in Air Products' SQL Server 2000 database. The document is then delivered to Intel over the Net. From January through November, Air Products has shipped more than 15,000 cylinders to Intel, with the certificates of analysis delivered by XML. Based on how well this process works, Air Products believes it can tap a mother lode of opportunity by conducting XML transactions via Elemica. Air Products and other Elemica participants aim to deliver XML purchase orders, invoices and shipping documents. The larger goal is to use Elemica as the conduit to link ERP systems. In the case of Dow, the chemical company buys a large number of products from Air Products, including raw materials used in its urethanes. In a Dow-Air Products connection, Dow will enter an order in its ERP system, and it will flow from there, via XML, to Elemica and then to Air Products. Air Products will then respond with an order acceptance, advance shipping notice and electronic invoice using ChemXML... Dow believes that handling orders in this way could ultimately eliminate the need to make corrections, which currently afflicts about 10 percent of orders. By 2005, the company believes it can conduct 50 percent of its B2B transactions using XML, thereby saving 20 percent of the cost of managing the transactions. Air Products' XML effort demonstrates that some companies are ready to make the leap from EDI. EDI lacks the flexibility to easily enter new data elements, because doing so requires a standards committee to reach agreement on such changes, said Giga Group analyst Ken Vollmer..." See also (1) "Microsoft Prepares CIDX Software Development Kit"; (2) Air Products Case Study. On ChemXML (alko known as "Chem eStandards"), see "XML-Based 'Chem eStandard' for the Chemical Industry."
[November 30, 2001] "Air Products and Chemicals. Air Products Finds Right Chemistry Using Microsoft BizTalk Server to Create an ERP-to-ERP Customer Portal." BizTalk Server 2000 Case study. "Air Products and Chemicals, Inc. is the world's only combined gases and chemicals company. Founded more than 60 years ago and headquartered in eastern Pennsylvania's Lehigh Valley, the company has annual revenues of $5.7 billion US and operations in 30 countries. Air Products is a market leader in the global electronics and chemical processing industries, and a longstanding innovator in basic manufacturing sectors including steel, metal, glass, and food processing. When one of its major customers requested delivery of data using the Extensible Markup Language (XML), the customer-focused Air Products moved quickly to respond to what represented a significant challenge. The problem was that Air Products' electronic transactions were based on electronic data interchange (EDI)... Beltz bet on XML and gathered a team to design and deploy an ERP-to-ERP solution based on BizTalk Server. The customer's requested turnaround time was daunting, but Beltz had developers with experience creating Microsoft-based solutions. The team used Microsoft Windows. 2000 Advanced Server, Microsoft BizTalk Server 2000, Microsoft SQL Server 2000, and Windows Load Balancing. Active Server Pages (ASP) was used to create a front end to the solution. The team used BizTalk tools for its development environment... [see previous bibliographic entry and "XML-Based 'Chem eStandard' for the Chemical Industry."]
[November 30, 2001] "Biztalk Mixes Standards With Lock-in." By Curtis Franklin. In InternetWeek (November 26, 2001), page 50. "Enterprise application integration (EAI) and B2B collaboration are increasingly important elements of IT strategy. Microsoft aims to address both requirements with BizTalk Server, a set of tools and services letting business processes and data move across the enterprise and out to customers and partners. A key piece of Microsoft's .Net strategy, BizTalk makes use of XML and SOAP, among other standards, to build process frameworks and transport data between organizations... Although Microsoft is often criticized for its approach to standards, its adherence to industry specifications is genuine in BizTalk. The product uses the latest versions of XML and SOAP as internal data definition and transport mechanisms, respectively. Using these standards within BizTalk, though, means making a substantial commitment to Microsoft's Windows 2000 server and SQL Server. Because standards like XML place controls on the way data is defined while leaving it for individual vendors to decide how those controls are delivered, Microsoft is able to support standards while tying customers more tightly into the .Net framework..."
[November 30, 2001] "Ahead of the Curve: A Memo to Pat Sueltz." By Tom Sullivan and Ed Scannell. In InfoWorld Issue 48 (November 26, 2001), page 78. An open memo from Steve Gillmor (InfoWorld) to Patricia C. Sueltz (President, Software Products and Platforms, Sun Microsystems). "Pat, it's time to declare victory. Java won. If Gartner is right, moving forward the market will be split 40-40 between J2EE (Java 2 Enterprise Edition) and Microsoft's .Net. With Java developers earning more than their VB (Visual Basic) counterparts, Microsoft has countered with C# to stem developer hemorrhaging. So Java won. The loose coalition of J2EE vendors has successfully sold the idea to Wall Street and beyond that Microsoft is all about lock-in, and Java is about open. Microsoft has countered with XML, and SOAP (Simple Object Access Protocol), and UDDI (Universal Description, Discovery, and Integration): A stack of XML Web services that promise interoperability and plug-and-play components seamlessly meshing across the global Net. Here's the hard part. If you declare victory on Java, then it's time to put Java on the mantelpiece alongside "Microsoft owns the desktop" and join the XML revolution. No holds barred. Not the begrudging embrace of SOAP only after Elvis had left the building. So Java won. Long live XML. Take the marketing ball back from Redmond and trumpet your advantages. J2EE 1.4 may be six months away (at least) with its built-in Web services stack, but you've got some powerful allies who are in the thick of it... What if the best strategy to counter Microsoft is to emulate its XML Web services message, invest in matching the discounts and media tie-ins that will evangelize this pervasive platform, and stitch together the necessary ingredients from your coalition of X2EE partners? Specifically, integrate SOAP with Jxta's peer-to-peer architecture to provide thick-client support not just for Palm devices but Pocket PC and Symbian devices as well. Make an aggressive effort to make the Liberty Alliance interoperable with Passport via SOAP and XML-RPC (Remote Procedure Call) now, not later when you have to leap on board as the train pulls out of town. Take a page from Nokia's playbook and team with BEA, Iona, Hewlett-Packard, SilverStream, and startups such as Kenamea to fast-track XML Web service infrastructure targeted at both server and desktop spaces..."
[November 30, 2001] "Microsoft Tosses a DIME for Web Services." By Cathleen Moore. In InfoWorld (November 27, 2001). Working to hammer out the technical details of Web service interactions, Microsoft this month quietly submitted to the IETF (Internet Engineering Task Force) a message format protocol designed to simplify the transmission of video, graphics, and sound files in Web services. Building on the success of the MIME (Multipurpose Internet Mail Extensions) specification, which allows graphics, audio, and video files to be sent and received in e-mail, DIME (Direct Internet Message Encapsulation) sets out to streamline the MIME standard for use in Web services. DIME addresses the difficulties involved in embedding binary data, such as video, graphics, and sound, into XML documents and in putting an XML document in another XML document, according to Philip DesAutels, product manager for XML Web services at Microsoft. The Redmond, Wash.-based company submitted DIME as an IETF Internet Draft on November 14, 2001. Hewlett-Packard and Microsoft earlier this year submitted for standards consideration development work that described how to use MIME and SOAP (Simple Object Access Protocol) to combine binary data and multiple messages together. From this development work in using SOAP with attachments, Microsoft saw a need for a simpler format for combining multiple chunks of information into one message, DesAutels said... The end goal of DIME, DesAutels said, is to untangle complex Web service interactions, which could involve passing images and video feeds as part of a service." See the news item of June 06, 2001: "Microsoft Publishes XML Web Services Specifications."
[November 30, 2001] "Direct Internet Message Encapsulation (DIME)." IETF INTERNET-DRAFT 'draft-nielsen-dime-00'. Edited by Henrik Frystyk Nielsen, Henry Sanders, and Erik Christensen (Microsoft). November 2001. Expires May 2002. "Direct Internet Message Encapsulation (DIME) is a lightweight, binary message format that can be used to encapsulate one or more application-defined payloads of arbitrary type and size into a single message construct. Each payload is described by a type, a length, and an optional identifier. Both URIs and MIME media type constructs are supported as type identifiers. The payload length is an integer indicating the number of octets of the payload. The optional payload identifier is a URI enabling cross-referencing between payloads. DIME payloads may include nested DIME messages or chains of linked chunks of unknown length at the time the data is generated. DIME is strictly a message format, provides no concept of a connection or of a logical circuit, and does not address head- of-line problems... The design goal of DIME is to provide an efficient and simple message format that can accommodate the following: (1) Encapsulating arbitrary documents and entities, including encrypted data, XML documents, XML fragments, image data like GIF and JPEG files, etc. (2) Encapsulating documents and entities initially of unknown size. This capability can be used to encapsulate dynamically generated content or very large entities as a series of chunks. (3) Aggregating multiple documents and entities that are logically associated in some manner into a single message. For example, DIME can be used to encapsulate a SOAP message and a set of attachments referenced from that SOAP message... URIs can be used for message types that are defined by URIs. Records that carry a payload with an XML-based message type may use the XML namespace identifier of the root element as the TYPE field value. A SOAP/1.1 message, for example, may be represented by the URI http://schemas.xmlsoap.org/soap/envelope/..." See (1) the news item of June 06, 2001: "Microsoft Publishes XML Web Services Specifications."; (2) "Simple Object Access Protocol (SOAP)."
[November 30, 2001] "XML Dominates Database File Formats. [Tracking Down the XML Reward. Web Services.]" By Tom Sullivan and Ed Scannell. In InfoWorld Issue 48 (November 26, 2001), pages 1, 17-18. "With Oracle's annual OpenWorld conference on the horizon, database vendors are preparing for battle once again. This time around, the big three -- IBM, Oracle, and Microsoft -- are brandishing XML as the not-so secret weapon for making their databases faster and using it to anchor Web services. Microsoft is readying its charge into the enterprise-class arena with the forthcoming version of SQL Server, code-named Yukon. Yukon is being hailed as an XML-savvy, back-end engine for Microsoft's .Net Web services initiative. The second, and perhaps more important, design goal for Yukon is language independence, said Barry Goffe, group product manager of the .Net enterprise server group. 'We've had this vision for a long time: to have a multilanguage database,' Goffe said. To create that multilanguage database, Microsoft is arming Yukon to host XML natively in the database and is making XML a definable column type, which enables XML data to more effectively be searched and retrieved, said Stan Sorenson, director of server marketing at Microsoft. Although the delivery date for Microsoft's next generation of SQL Server has thus far been a closely guarded secret, a company official said that the Redmond, Wash.-based giant has a specific time frame in mind for the product to be finished... Microsoft has been adding support for emerging XML standards in a series of Web releases, the latest of which, SQLXML 2.0, came in October. SQLXML 2.0 contains support for XSD (XML Schema Definition), a specification designed to ease data integration from the World Wide Web Consortium (W3C) standards body in Cambridge, Mass. Oracle and IBM, meanwhile, are also sharpening their XML battle-axes. Jeremy Burton, vice president of worldwide marketing at Oracle in Redwood Shores, Calif., said that Oracle will be touting an XML-related technology called XDB (XML database support) at the company's annual Oracle OpenWorld conference the week after next in San Francisco. Burton, however, declined to provide further details about the future of XDB, now part of 9i. Not to be outdone, IBM officials say they have a rolling head start on Oracle and Microsoft, noting they have already delivered key database-related technology pieces and have employed all the right programming standards and protocols. Big Blue, in fact, is stressing that the combination of DB2 and its XML Extender provides the functional equivalent of Oracle's XDB technology, said Jeff Jones, director of strategy for IBM data-management solutions at IBM's labs in San Jose, California..." See: "XML and Databases."
[November 30, 2001] "Oracle to Boost XDB, Web Services Support." By Mark Leon and Tom Sullivan. In InfoWorld Issue 39 (November 30, 2001), page 20. "Oracle says it will raise the bar in XML database and Web services support next week at the Oracle OpenWorld conference in San Francisco. The buzz surrounds Oracle's XDB (XML database support) that the company reports will utilize the object database functions it built in the mid-90s that allow users to store XML as an object and index the tags, then stored it in a compressed table. Oracle has also revealed it will use OpenWorld to unveil added support for Web services standards and J2EE 1.3 in the Oracle application server. 'We are also putting support for Web services in our JDeveloper tool,' said Jeremy Burton, vice president of worldwide marketing at Oracle in Redwood Shores, Calif. As for the advantages of XDB, Burton explained that XML documents are stored 'natively' but will not require special treatment. 'You can use SQL, and don't need to master the new XML query languages like XQuery,' Burton said. 'The object technology that makes this possible was a hammer looking for a nail,' Burton said, 'and XML is suddenly the biggest nail on the planet. If XML had not come along, you could argue that a lot of our object development efforts were wasted effort.' 'With XDB,' Burton continued, 'the overhead of managing XML, parsing for example, largely disappears.' Meanwhile, Oracle remains lukewarm to XQuery, the emerging XML query language from the World Wide Web Consortium (W3C). 'It is still very early stages for XQuery,' said John Magee, senior director of Oracle 9i product marketing in Redwood Shores, Calif. 'Any vendor who says they are offering [XQuery] is blowing smoke and not doing their customers any service.' IBM is more actively pushing XQuery. 'We plan to have an alpha version [of XQuery] in DB2 next year,' said Nelson Mattos, director and distinguished engineer at IBM's Silicon Valley Lab in San Jose, Calif. And Gordon Mangione, vice president of SQL Server at Microsoft, in Redmond, Wash., said, 'The next big [development] is XQuery, how you query against XML data. It will be part of our strategy to present SQL Server as a Web service.' The biggest XML issue for all the database vendors is how to store the data. 'The debate has always been,' explained Magee, 'do you store XML in document format or do you break it up into relational tables?' He said the jury is in and the consensus is that you need to do both. 'You can store an XML document as a BLOB [Binary Large OBject] and search on it with Oracle Text,' said Magee, 'or you can define a mapping that maps XML data to the standard relational format.' The issue is important because there is a new crop of XML database vendors that claim the ability to do it better. 'We store the XML document natively, just as it is,' said Lawell Kiing, vice president of software development at XML Global Technologies in Vancouver, Canada. 'Our query engine is based on the latest draft of XQuery.'... Where other vendors are concerned, Software AG plans to add XQuery to Tamino, its XML database. Currently Tamino uses a query engine based on XPath. 'Oracle essentially [performs XQuery functions] with smoke an mirrors, storing the entire XML document as a column in a relational table and allowing you to search it with their text engine,' said John Taylor, senior technology officer at Software AG in Reston, Va. No one, however, expects these XML pure plays to take on the relational vendors directly. 'Software AG initially positioned Tamino as an alternative to relational databases,' said Susan Funke, an analyst with IDC in Framingham, Mass. 'But they quickly realized the better strategy was to pursue symbiotic partnerships with other vendors including IBM, BEA, Sun, and HP to promote its solution.'...Analysts say integration is behind the XML database craze. 'With more b-to-b sites, people are going to be passing XML documents back and forth,' said Carl Olofson, an analyst with IDC in Framingham, Mass. 'It will be really important to store these things'..." See: "XML and Databases."
[November 29, 2001] "Preserving Modularity in XML Encoding of Description Logics." By Jérôme Euzenat (INRIA Rhône-Alpes, Montbonnot, France). Working notes. 10 pages, with 11 references. Presented at the 2001 International Description Logics Workshop (DL-2001). Stanford, USA, August 1-3, 2001. Published in the Workshop Proceedings. "Description logics have been designed and studied in a modular way. This has allowed a methodic approach to complexity evaluation. We present a way to preserve this modularity in encoding description logics in XML and show how it can be used for building modular transformations and assembling them easily. We show how the modularity of description logics, that has mainly be used at a theoretical level, can be turned into an engineering advantage in the context of the semantic web. For that purpose, we introduce a description logic markup language (DLML) which encodes description logics in XML and preserves their modularity. We then present transformations that are described on individual constructors and can be composed to form more complex transformations. By factoring out syntactic rules and processing methods, the same set of transformations can apply to many logics. Section 2 presents the syntactic encoding of description logics in XML. The third section illustrates the use of transformation of the XML form in order to achieve relatively complex transformations... The DLML framework offers a general encoding of description logics in XML such that the modularity of description logics can be used in XML (for extending the language, building transformation stylesheets). Although it has been illustrated only by restricted examples, such an encoding has great potential for the interoperability of knowledge representation systems. In particular, it allows the implementation of the 'family of languages' approach to semantic interoperability which takes advantage of a group of comparable languages (here description logics) in order to select the best suited for a particular task. We are currently experimenting the proof-carrying transformation idea in this context..." See: "Description Logics Markup Language (DLML)." [source, Postscript]
[November 29, 2001] "Web Ontology Reasoning in the SHOQ(Dn) Description Logic." By Jeff Z. Pan (Department of Computer Science, University of Manchester). WWW. Presented at the M4M-2 [Methods for Modalities] Workshop, Amsterdam, November 2001. 12 pages (with 12 references). "The Semantic Web is a vision of the next generation Web in which semantic markup will make Web resources more accessible to automatic processes. Ontologies will be key components of the Semantic Web, and it is proposed that Description Logics will provide the formal underpinnings and reasoning services for Web ontology languages. In this paper we will show how one such description logic, SHOQ(D), can be extended with n-ary datatype predicates, to give SHOQ(Dn), and we will present an algorithm for deciding the satisfability of SHOQ(Dn) concepts, along with a proof of its soundness and completeness. The work is motivated by the requirement for n-ary datatype predicates in relation to 'real world' properties such as size, weight and duration, in the Semantic Web applications..." See: (1) "Description Logics Markup Language (DLML)"; (2) "XML and 'The Semantic Web'."
[November 29, 2001] "XML Transformation Flow Processing." By Jérôme Euzenat (INRIA Rhône-Alpes) and Laurent Tardif (Monash University). In Proceedings of the Second Extreme Markup Languages Conference, Montréal, Canada, August, 2001. Pages 61-72. "XML has stimulated the publication of open and structured data. Because these documents are exchanged across software and organizations, they need to be transformed in many ways. For that purpose, XSLT allows the development of complex transformations that are adapted to the XML structure. However, the XSLT language is both complex in simple cases (such as attribute renaming or element hiding) and restricted in complex cases (complex information flows require processing multiple stylesheets). We propose a framework which improves on XSLT by providing simple-to-use and easy-to-analyse macros for common basic transformation tasks. It also provides a superstructure for composing multiple stylesheets, with multiple input and output documents, in ways not accessible within XSLT. Having the whole transformation description in an integrated format allows better control and analysis of the complete transformation... [Conclusion:] We have presented the Transmorpher system and principles which aim at complementing XSLT on the issue of simple transformations and complex control of transformations. It tries to implement for transformations, the slogan 'Make simple things easy and complex ones possible'. Although only limited experiments have been conducted with the system it behaves the way it was intended. The concepts that have been proposed in this paper are viable ones and overcome some limitations of XSLT (more generally, of stand-alone one-pass template-only transformation systems). As Cocoon demonstrates, Transmorpher corresponds to a real need and we expect to see more systems of its kind in the next few years. The bibliography example is a real example available from our web site. Transmorpher has not been designed for efficiency but for intelligibility: Our ultimate goal is to offer an environment in which we will be able to certify that a particular output of a compound transformation satisfies some property (e.g., hiding some type of information, preserving order, or preserving 'meaning'). Another good property of intelligibility (through modularity) is that it is easy to imagine a graphical user interface to Transmorpher." For related resources, see "Extensible Stylesheet Language (XSL/XSLT)."
[November 29, 2001] "Introduction to dbXML." By Kimbro Staken. From XML.com. November 28, 2001. [An introduction to dbXML, an open source native XML database. The dbXML database offers XPath-based query over collections of semi-structured XML documents.'] " In this article we'll take a look at a native XML database implementation, the open source dbXML Core. What it Offers The dbXML Core has been under development for a little more than a year. The current version is 1.0 beta 4 with a 1.0 final release expected to appear shortly. Full source code is available from the dbXML web site. Most of the basic native XML database features are covered, including: (1) storage of collections of XML documents, (2) multi-threaded database engine optimized for XML data, (3) schema independent semi-structured data store, (4) pre-parsed compressed document storage, (5) XPath query engine, (6) collection indexes to improve query performance, (7) XML:DB XUpdate implementation for updates, (8) XML:DB Java API implementation for building applications, and (9) complete command line management tools. Proper transaction support is the major missing feature right now; it will appear in the 1.5 release... Like all native XML databases dbXML is just a tool. It will be right for some jobs and completely wrong for others, and like all tools the best way to find out if it works is to try it. This is an exciting time for dbXML; it's on the verge of an initial production release and will soon be receiving a new name and a new home. Development of dbXML is coming under the stewardship of the Apache Software Foundation XML sub-project, and dbXML will be renamed Xindice in the process. The project has come a long way, and now is the best time to get involved to help shape the future of open source native XML database technology..." See: "XML and Databases."
[November 29, 2001] "ScrollKeeper: Open Source Document Management." By Kendall Grant Clark. From XML.com. November 28, 2001. ['Tying together the diverse world of open source documentation. Kendall Clark has taken a look at the ScrollKeeper project. For UNIX-like systems, among others, multiple and diverse sources of documentation creates a document management problem. Building on an application of the Dublin Core Metadata Element Set, ScrollKeeper provides an XML-based solution for documentation management.'] "... ScrollKeeper has been guided by the document collection needs of the GNOME project in particular, with Dan Mueth, lead of the GNOME Documentation Project, and Sun's Laszlo Kovacs contributing design ideas and code. This should come as no surprise since one aim of GNOME is to provide a consistent, unified interface for Unix-like systems, and that means not only providing consistent help and documentation tools for GNOME applications, but for the underlying system documentation as well... Since document collections can be conceptualized as trees, and since XML/SGML is very good at representing data as trees, it's unsurprising to learn that ScrollKeeper uses XML extensively. There are three central parts of ScrollKeeper currently -- a contents list, a table of contents, and an extended contents list -- which it creates at document install or uninstall time and stores as XML... Like most open source projects, ScrollKeeper has an ambitious plan for future expansion and, from the looks of it, could use more help. In the short term internationalization and localization improvements are planned, as well as improved searching and indexing functionality. In the longer term, ScrollKeeper may expand to deal with non-local documents and resources, including using a remote OMF server for synchronizing LAN, WAN, and Internet-wide document collections, and so on. When I was first thought about writing this article, I stumbled over the fact that the way ScrollKeeper uses XML is neither novel nor cutting-edge. In fact, it's rather ordinary, even pedestrian. Then I realized that that's exactly the point. ScrollKeeper's utility lies not in the way it uses XML, but that, by using XML, it allows developers, admins, and others to leverage existing XML tools and knowledge to manage document collections; that it makes possible the creation and growth of useful metadata, which aids both document producers and consumers; and that it does so in a relatively simple and easy to understand way. In the final estimation, surely that is what makes XML a good and useful thing..."
[November 29, 2001] "SVG: Where Are We Now?" By Antoine Quint. From XML.com. November 21, 2001. ['SVG expert Antoine Quint surveys the current state of tool support for the W3C's Scalable Vector Graphics Recommendation.'] "On September 4th 2001, the W3C published the Scalable Vector Graphics 1.0 specification. For some people, including a large number of early adopters who followed the specification's evolution since the early drafts, SVG 1.0 was a long time coming -- it had been two and half years since the first public draft of February 1999. However, SVG was a much needed leap forward for web graphics. If you look at the specification, you'll notice it is exhaustive (600+ pages), detailed, and complex (in places, filters and animation, for example). SVG's long gestation resulted in a specification that had some solid and diverse support from the moment it was released. This article aims at providing an overview of available SVG tools, including highlights of what's cooking in the short term in the SVG world. This article focuses on the most interesting, advanced, and tested active projects... Probably the first thing you'll want to know about SVG is how you or anyone else can view SVG contents. Today, there are two main kinds of SVG viewing tool: standalone SVG viewers and SVG-enabled browsers... [Conclusion:] I hope this overview of SVG tools currently available gives you a good idea of what tool you need and what you can expect of SVG in today's products. I think the state of SVG's support in the industry is astonishing since its still in its early stages. It is also interesting to take into account the speed at which progress has been and is still being made. At this pace, this article will need a complete overhaul in six months..." See also (1) SVG Implementations and (2) general references, "W3C Scalable Vector Graphics (SVG)."
[November 29, 2001] "XML Schema Toolkit: An Explanation." By Alex Selkirk. October 09, 2001. "Schema Toolkit consists of a main application, SchemaCoder.exe, and a number of components: XMLParser.dll (which parses schema-valid XML), XMLSchema.dll (containing schema structure code) and XMLDataTypes.dll (schema types). Functionality common to all XML components is contained in a static library, XMLLibrary.lib. There is also a sample application, TestDisplay.exe... The schema toolkit has two parts: the first is an application to convert XML schemas into C++ code. This involves either creating classes for the elements (and attributes) defined in the schema, or converting them to basic variable types, such as string or integer. These classes will compile without any further changes (using Microsoft's Visual C++ application) to form a dynamic link library (DLL). However to provide any useful functionality, the classes will have to be extended by a programmer. How this is done is demonstrated by a fully-functional example application that displays text and diagrams from a number of simple XML display vocabularies. The second part of the schema toolkit is to create the functionality to run the created code once it has been compiled. The following diagram shows how the constituent parts fit together for a generic XML application. The application calls functionality within XMLParser.dll. This DLL uses the Microsoft XML Parser (MSXML3.dll) to parse the XML document, but it builds an object heirarchy [from the SAX events], calling the created schema dynamic link libraries when needed by the document. At the end of the process, the application is given a pointer to the object representing the base element..." See the web site for download details. For schema description and references, see "XML Schemas."
[November 28, 2001] "ContentGuard Advances XrML. Version 2.0 of Rights-Expression Language Proposed to MPEG and TV-Anytime." By Mark Walter. From the Seybold E-Book Zone. November 26, 2001. "Taking steps to execute the new strategy the company outlined in August, ContentGuard this week announced XrML 2.0, as well as accompanying developer tools, and also will submit the rights-expression language to two standards bodies that are working on digital rights management (DRM) interoperability. The moves are designed to bolster XrML's chances of being named the standard rights expression language, which would pave the way for ContentGuard to make a business out of dishing out royalty licenses... Despite the thoroughness of the XrML specification (in some cases because of its thoroughness and complexity), Miron has had trouble drumming up industry support for it as a standard. This week he's traveling to Thailand, where ContentGuard is expected to submit XrML to the MPEG-21 committee as a proposed rights-specification language. The MPEG-21 committee, which sets technical standards for motion pictures, set a November 21 deadline and is expected to convene in early December to consider the submissions... As a potential vendor-neutral rights-expression language, XrML remains one of only a few alternatives to crafting one from scratch. The complaint-that it's too hard-will likely persist with 2.0, but an expression language ought to be rich in order to satisfy different needs across different industries. The debates taking place in various working groups are, as usual, as much about politics as they are technical standards, and forecasting the outcome is akin to predicting an election. XrML may be the front-runner, but write-in candidates are still a distinct possibility..." See: (1) the news item "ContentGuard Releases XrML Version 2.0 and Submits Specification to Standards Bodies"; (2) the related MPEG submission, "ODRL Version 1.0 Submitted to ISO/IEC MPEG for Rights Data Dictionary and Rights Expression Language (RDD-REL)"; (3) general references in "XML and Digital Rights Management (DRM)."
[November 28 2001] "Expanding the Digital Content Rights Concept." By Jeffrey Burt. In eWeek (November 27, 2001). "ContentGuard Inc. on Monday released the latest version of its standard language for digital content rights, expanding the concept beyond simply protected digital content to other business models, such as Web services. The Bethesda, MD., company also released a software developer's kit that enables developers to build applications or other solutions using Extensible Rights Markup Language, or XrML. ContentGuard already has submitted Version 2.0 to two standards bodies -- MPEG-21 and TV Anytime -- and CEO Michael Miron said on Monday that the company will submit the technology to any standards body that needs a digital rights management tool. Earlier versions of XrML were primarily content centric, Miron said. Version 2.0 expands the range of the standard: it not only deals with traditional issues such as music, but also ones such as network resources and access to chat rooms. Also, whereas most digital rights products deal with issuing licenses to people, Version 2.0 deals with licenses to devices and applications as well, Miron said. 'It could be licenses to an application or a person or a group of people who have access to one device,' he said. The updated XrML also delves more deeply into the issues of rights -- can the licensee print the content, or just view it -- and the conditions of the license, from payment to time limits. The updates give businesses a greater number of options for licensing their content and services, Miron said. For example, a financial services firm that uses password access to its online content can now customize and personalize that access for each customer, or for each piece of content and service..." See references in: (1) the news item "ContentGuard Releases XrML Version 2.0 and Submits Specification to Standards Bodies"; (2) the related MPEG submission, "ODRL Version 1.0 Submitted to ISO/IEC MPEG for Rights Data Dictionary and Rights Expression Language (RDD-REL)."
[November 21, 2001] "NeoCore XMS from NeoCore Inc. Information-Centric Native XML Management." By Philip E. Courtney. In eai Journal Volume 3, Number 11 (November 2001), page 11. ['First Impression. NeoCore XML Management System is a fully transactional database that leverages the extensibility of XML and delivers the high-performance and scalability needed for large-scale business systems using digital pattern processing.'] "A high-performance, scalable, and information- centric approach toward XML information management is crucial to supporting the rapid delivery of new business systems and adapting existing applications to new requirements... NeoCore XML Management System (XMS), from NeoCore Inc., is a fully transactional database that leverages the extensibility of XML and delivers the high-performance and scalability needed for large-scale business systems. NeoCore XMS innovatively 'derives' data structures from within XML documents during posting and modification. It automatically and intuitively self-constructs the database, and dynamically aligns content and context, allowing the rapid development of adaptable applications and dynamic integration of existing systems. NeoCore XMS is schema-neutral, greatly reducing time-consuming activities such as database design and table creation, while providing an extremely flexible environment that supports heterogeneous and variable data...Typically, native XML databases have taken a document-centric view of XML in order to maintain extensibility. Updates to a single XML data element require transport of an entire document to the client so that it can be updated, returned to the originating server, re-stored, and re-indexed -- functions more akin to document management than database management. NeoCore XMS updates XML in place. With its unique information-centric approach, the product sends simple, small commands to the server via HTTP to insert, modify, and delete data or metadata contents. More important, NeoCore XMS can dynamically alter data structure whenever data requirements change -- much like adding of columns 'on-the-fly' to selected individual rows within RDBMS. NeoCore XMS removes the perceived performance penalty of working with XML in native mode -- it can easily assemble and deliver XML documents at a pace exceeding 40 megabytes per second. Further, it can query, retrieve, and return entire documents or fragments of documents at speeds crucial to supporting high-volume Web-based or e-business transactions. NeoCore XMS achieves high-performance and low resource utilization because of its patented Digital Pattern Processing (DPP) technology. With DPP, NeoCore XMS describes XML documents and their component contents in numeric finite-width fields. This ensures that performance remains unaffected by the length of tag names, element content, or document hierarchy. To further improve performance, DPP enables NeoCore XMS to index every tag, element, and combination, ensuring extremely fast searches on tags and data..." See further detail (1) in the FAQ document and (2) in the NeoCore XMS white paper "What is NeoCore XMS?."
[November 21, 2001] "GXS Releases XML Schema Plug-in. Saves Time Converting Between XML and Other Formats." In eai Journal (November 13, 2001). ['Mapping transactions from proprietary data formats, such as those for enterprise ERP or legacy systems, into XML is a time-consuming process. GXS XML Schema Plug-in saves time in this mapping process by allowing the use of XML schemas to help define the structure, content, and semantics of XML documents.'] "GE Global eXchange Services (GXS) has released XML Schema Plug-in, e-business software that will allow companies to more quickly integrate XML transactions into back office systems. The new software can help companies save time and reduce costs associated with exchanging XML documents with suppliers, customers, and other trading partners. The Plug-in works in conjunction with the GXS data transformation engine, allowing customers to import XML schemas into the mapping tool, and then validate XML messages against the schemas. Platforms supported by the Plug-in include Windows and Unix. Said Jim Rogers [GXS general manager of integration solutions]: 'Clients who are implementing their e-buy process using XML will find that this capability can save them a great deal of time and effort in integrating XML B2B transactions with their ERP or legacy business applications'..." For schema description and references, see "XML Schemas."
[November 21, 2001] "New Standard Closes the Loop for Web Services." By Ed Anuff. In eAI Journal Volume 3, Number 11 (November 2001), pages 16-17. ['Web Services User Interface (WSUI) describes SOAP and XML interfaces as multi-page end-user applications that can be embedded in Web sites. It provides a reusable approach to Web application integration.'] New standards are emerging to let companies build applications that work together using eXtensible Markup Language (XML) messaging. The standards include: Simple Object Access Protocol (SOAP); Web Services Description Language (WSDL); Universal Description, Discovery, and Integration (UDDI); Web Services User Interface (WSUI). These standards provide a good foundation for machine-to-machine communication and will help XML Web services usher in the next-generation Internet. WSUI is especially valuable because it addresses the lack of a standard user-interface layer for Web services. The proposed WSUI standard lets Web services with SOAP-Remote Procedure Call (RPC), XML, or WSDL SOAP interfaces be described as complex, multi-page, end-user applications that can be easily embedded in Websites. WSUI leverages the benefits of an XML-based interface to an application -- benefits that make Web services an ideal machine-to-machine transport layer. Among the benefits are separating implementation from interface and enabling diverse implementation platforms to interoperate. By standardizing the display layer of Web services, vendors can more easily embed their applications in Web application delivery platforms without expensive, vendor-specific implementations... WSUI leverages the basic XML technologies supported in open-source toolkits such as the Apache XML project as well as vendor toolkits that implement core XML specifications. WSUI is specifically engineered to expose components, which expose any number of end-user views in a browser. Usually, the purpose is supporting form and menu-driven user interaction with back-end services. A WSUI component can call XML, SOAP RPC, and WSDL SOAP services. More service types can be easily added in the future. WSUI's creators acknowledge that many Web services will never be interacted with via a user interface. Nevertheless, many services that end users and customers want to aggregate are user-facing. That's where WSUI is beneficial because it offers a standard mechanism for integrating user-facing services via standards- based XML messaging... WSUI makes several key assumptions about the interested parties. A service provider exposes any number of XML or SOAP services. A service consumer is a Web publishing platform or portal, which is running a WSUI container implementation and constructs Web pages based on user requests. Users interact with Web pages to interact with a WSUI service. Architecturally, WSUI assumes that the services exposed via XML or SOAP exist as-is. For a Web publishing platform to integrate the service as an application that can be accessed by end-users requires only a WSUI descriptor file plus a series of XML Stylesheet Language Transformation (XSLT) templates. Developers can create the actual WSUI file and XSLT templates needed to integrate existing services. An application or service vendor can package the WSUI/XSLT files with a standard interface to facilitate other Websites embedding their applications..." See: "Web Services User Interface (WSUI) Initiative." [cache]
[November 21, 2001] Coping with Standards Diversity in e-Commerce." By Doron Rotem, Frank Olken, and Robert Shear. In eAI Journal Volume 3, Number 11 (November 2001), pages 18-23. "... As business transactions continue to migrate onto electronic networks, the complexity of maintaining a shared language and a common understanding mounts... Linguistic conventions, often implicit in human interactions, must be made explicit for effective electronic transactions. As the scope of e-commerce expands, we can no longer rely on implicitly shared conventions for the meanings of messages, terms, contract provisions, or even measurement units. This is where standards come in and the controversy begins. In standards for e-commerce, one size doesn't fit all... [Native Support vs. Translation] There are really two ways to deal with multiple e-commerce standards: (1) Choose a set of standards to support natively in all your applications and systems and expect the rest of the world to comply. This compliance may be gained through an industry group, at the insistence of a dominant company, or a governmental agency. (2) Build a translation capability that allows you to accommodate multiple evolving standards. With this approach, you can communicate with and between multiple standards and adapt to changing business conditions. Which approach is right for you will depend on several business and technical factors... Translation Technologies: Message format translation typically involves two steps: syntax translation and data translation. The former involves structural transformations (splitting one field into several or merging fields), reordering portions of a message, and renaming fields (i.e., XML tags). Data translation (conversion) involves such matters as date format conversion, measurement unit conversion, code set (abbreviation) conversion (e.g., three- vs. four-letter codes for airports), and conversion between different controlled vocabularies. It's common for message translators to first transform incoming messages into a standard (canonical) encoding, before attempting further translation. This avoids the need to construct a quadratic number of translators (all n-to-n translations among n message formats). Instead, only a linear number (2N) of translators needs to be constructed (n translators into the canonical format, and n translators from the canonical format to the variant formats). Note that the canonical format must be sufficiently expressive to cope with any of the message formats... Repositories (registries or data dictionaries) are the IT equivalent of a thesaurus or dictionary. They record metadata in machine-readable form. Repositories were originally developed to support database design and database applications development. Subsequently, repositories were used to support schema and internal application integration. Recently, repositories are being deployed to support inter-organizational e-commerce standards development, deployment, and integration. The EBXML e-commerce standards effort is based on repositories. Repositories vary in their granularity. Some, such as those operated by the OASIS and BizTalk organizations, are collections of XML schemas (message formats). Other repositories, such as those standardized by ISO/IEC 11179, are concerned primarily with data element specifications (data element names, data element definitions, type specifications, measurement units, etc.). Repositories used to support schema design and integration are often multi-level, containing both data element-level information and entire schemas (either database or message schemas). Repositories used to support schema integration or message translation will typically also include information about mappings among messages and data elements, as well as data conversion instructions... Schemas are often encoded as trees, graphs, or hypergraphs (e.g., relational schemas). Hypergraphs are akin to graphs except that edges may connect sets of vertices. Mappings between schemas are represented either as graphs, hypergraphs, or graph grammars (mappings of subgraphs to subgraphs). The need for more elaborate mappings arises from the possibility of splitting or merging of objects or attributes..."
[November 21, 2001] "Bar Codes In A Chip. Technology Could Transform Product Tracking." By Margie Semilof. In InternetWeek (November 16, 2001). "A growing number of companies that make and sell consumer products are testing a budding technology that could transform the way industries use the Internet to track goods in their supply chains. The technology, under development at the Massachusetts Institute of Technology, takes over where bar codes leave off. Whereas bar codes use an imprint that must be manually scanned, the so-called Auto-ID technology uses a microchip tag that contains an electronic product code. The tag is affixed to a pallet of goods, and wireless readers placed on forklifts, walls or store shelves automatically track the merchandise as it moves from place to place... Consumer goods companies are hopeful that RF ID tags will cut supply chain management costs by billions of dollars. Today's manually operated bar code scanners are imperfect because they're prone to human error. Companies can easily lose track of cases that accidentally aren't scanned...As the technology improves, pallets will give way to cases and perhaps individually packaged goods, ultimately enabling companies to follow those goods to the point of sale. The Auto-ID project is spearheaded by some of the world's largest consumer packaged goods, retail and computer companies, including International Paper, Procter & Gamble, Sun Microsystems, Unilever and Wal-Mart, and is supported by the Uniform Code Council, a standards body that represents companies in 23 industries. After two years of planning and design, MIT's Auto-ID Center started test-driving its prototype on October 1. In the test, a commercially made radio frequency (RF) tag was affixed to a pallet of Procter & Gamble's Bounty paper towels at a factory in Cape Girardeau, Mo., to track the pallet's progress all the way to a Wal-Mart Sam's Club warehouse in Tulsa, Okla. Two million such tags have been tested, and next month the trials will escalate when Unilever and Gillette join in. The second phase of the trial will begin early next year, when participants start tagging cases of goods instead of pallets... Tags' DNS System: One important consideration is who will manage an MIT-developed object naming service, which helps identify new items as they arrive on a loading dock for the first time. The ONS, a key part of the system, works the same way the Internet's Domain Name System searches for URLs. When a product arrives on a shipping dock and the receiver can't identify the contents, the tag's ID code is sent via the Internet to the ONS, which looks up the information. The ONS uses a specially created physical markup language, based on XML but for physical objects, to cross-check information on the RF tag with information in the ONS. Future owners of the ONS might be either the World Wide Web Consortium or the Internet Engineering Task Force, said Kevin Ashton, executive director of MIT's Auto-ID Center." See "Physical Markup Language (PML)."
[November 21, 2001] "Boeing Links Apps Via XML. Space Division Using Portal Across Project Groups to Improve Product Life Cycle Management." [Managing The Enterprise.] By Jade Boyd. In InternetWeek (November 12, 2001), page 29. "Reeling from the effects of the September 11 attacks on its commercial airline business and a failed bid for a $200 billion defense contract late last month, Boeing Corp. is applying XML and portal technology in other business units in an effort to do more with less... The company's space and communications division is providing uniform Web access to a score of applications it currently uses for product life cycle management. About 7,000 Boeing employees in Huntington Beach, Calif., are using the I-Man portal, which was launched with the help of EDS. Starting this month, that portal will supply access to data, including preliminary designs from NASA's Space Launch Initiative (SLI), a multiyear plan to design a replacement for the aging space shuttles. Boeing plans eventually to move data that currently resides in its multiple systems into a single database for easier administration...The key to Boeing's I-Man initiative is pulling together data into a single repository, Jensen said. That repository -- an Oracle database that supports XML -- will make it possible for everyone to access project files from a single source. As a first step, documents are being extracted from the company's various legacy systems and converted to XML as queries are invoked. When users call up a file for the shuttle or another legacy program, a Java component queries the corresponding legacy system, which delivers the file to the Oracle database. Custom code developed by Boeing converts the file to XML. Files created for the SLI program will be stored directly within I-Man's Oracle database. During the next two years, the design and development team at Huntington Beach will transfer all product data files of major programs -- including the International Space Station, SLI and the Delta rocket -- from legacy databases to the I-Man Oracle database. Boeing wouldn't say how much revenue these programs generate annually, but officials said design work represents 5 percent to 10 percent of Boeing's work on the shuttle and about 80 percent of its work on the space station and Delta programs. Boeing will benefit from the consolidation effort because it will have one database to manage, instead of 20 separate databases for the 20 programs involved... It will take at least two years to convert data from SLI into an XML format that can be accessed through the I-Man portal. Boeing hopes to have design data for the shuttle, space station and Delta rocket programs accessible via the portal by 2004, Jensen said. To do that, Boeing has a team of 10 developers working on the middleware to link each legacy application to the portal..."
[November 21, 2001] "Keep Patents Out Of Standards, But Reward Innovation." By Richard Karpinski. In InternetWeek (November 16, 2001). "As the World Wide Web Consortium this month continues to discuss and debate the role of patents in its standards processes, InternetWeek readers are taking a surprisingly open-minded approach. Most respondents to our recent poll on the topic were adamant that the W3C keep patents, in any form, out of standards-making. But there was a distinct undercurrent of belief that innovative companies should be rewarded for their work. If only this debate were truly about innovation. In reality, it's more about tech behemoths (you know the usual suspects) maintaining a path to profits even as they adopt standards and open-source technologies. It's still not clear how this controversy will shake out. The W3C won't deliver its formal policy until next year. In the past, the group has supported so-called royalty-free licensing models for technologies based on its standards. Now, it's proposing the addition of licensing based on 'reasonable and nondiscriminatory,' or RAND, terms. RAND licensers would be able to charge for access to their patents, even if the patents are part of a W3C standard. It's hard to defend the intertwining of Web standards and patents. Where would we be today without royalty-free standards like HTML, HTTP and XML? But it's not surprising to see this development occur. Savvy vendors, from IBM to Microsoft to Sun, have been 'gaming' the standards process for years now. When operating from a position of weakness -- think of Microsoft early in the Web browser game, or today with instant messaging -- vendors typically have touted open standards in a tactical move. Alternatively, when a vendor owns a de facto standard, the W3C or other standards bodies often become an afterthought. But let's not minimize the significance of the W3C's decision on patents. We've reached an important fork in the road. Attempting to patent W3C contributions takes that gamesmanship to dangerous levels and threatens the very foundation of the Web..."
[November 21, 2001] "Modeling Interorganizational Workflows with XML Nets." By Kirsten Lenz and Andreas Oberweis (Institute of Information Systems, J.W. Goethe-University). Published in Proceedings of the Hawai'i International Conference on System Sciences (January 3-6, 2001, Maui, Hawaii). Extent: 11 pages, with 21 references. "Efficient interorganizational business processes in the field of e-commerce require the integration of electronic document and data interchange and interorganizational processes. We propose to support interorganizational business processes by so-called XML nets, a new kind of high-level Petri nets. XML nets are a formal, graphical modeling language that allows to model both the flow of XML documents and the business process. XML nets are based on GXSL, a graphical XML schema definition language, and its related graphical XML document manipulation language (XManiLa). They can be directly executed by a workflow engine. Advantage of the formal foundation of XML nets can be taken e.g. when analyzing a (global) interorganizational workflow model: XML nets support the process of identifying relevant process fragments, assigning them to the appropriate organizational units, and thus help deriving an improved, process-oriented organizational structure... The XML document type definition represents a grammar for the declaration of documents. It consists of a set of markup declarations of different types: element, attribute list, entity or notation declaration. Unfortunately, this grammar is textual so that the DTDs for complex objects often may become quite unreadable. The advantages of a graphical schema definition language (like the entity/relationship model for the database design) are missing. In the following, we propose a graphical schema definition language for the design of XML document types, that we call graphical XML schema definition language (GXSL). The presented version of GXSL is DTD-based, i.e., a DTD can be unambiguously derived from the graphical XML schema (GXS). Instead of creating a completely new graphical modeling language for XML document types, we rely on well known data modeling concepts (of the E/R-model and other semantic data models), which all had their impact on the static modeling concepts of the Unified Modeling Language (UML). The main advantage of UML is that it is a highly accepted integration of well-known modeling concepts and guidelines and that it comprises a generic notation for the derivation of new graphical modeling languages for specific purposes... In this contribution, we have introduced XML-nets, which integrate behavior- and document-related aspects of workflows. In the future, GXSL might be adopted to XML schemas as soon as ongoing work on XML schemas has lead to a W3C recommendation. Moreover, XManiLa will be extended to querying the sequential order of elements of the same element class. For the geographical distribution of XML net-based workflows, principles of distributed database management systems may be transferred to the management of distributed XML documents, focussed for example on the management of document replication. Finally, criteria for the allocation of workflow fragments depending on the allocation of documents, mass data and other relevant resources must be found. We plan to extend an existing Petri net simulation tool in order to simulate and validate distributed workflows which are modeled as XML nets..." See the web site: XMLNet: Modellierung von Geschäftsprozessen im E-Business mit XML-Netzen. References: see "XML and Petri Nets." [alt URL; cache]
[November 20, 2001] "MPEG-7 Tackles Multimedia Content." By Neil Day (President, MPEG Industry Forum, Sunnyvale, CA). In EE Times (November 12, 2001). "The September 2001 debut of the MPEG-7 standard heralds a new wave of applications for managing the exponential growth and distribution of multimedia content such as content over the Internet, digital broadcast networks and home databases. MPEG-7 makes searching the Web for multimedia content as easy as searching for text-only files. The MPEG-7 standard will prove particularly useful in large-content archives, which the public can now access, and in multimedia catalogs in which consumers identify content for purchase. Content-retrieval information may also be used by agents, for the selection and filtering of broadcast "push" material or for personalized advertising. Further, MPEG-7 descriptions will allow fast and cost-effective use of the underlying data, by enabling semiautomatic multimedia presentation and editing. In essence, MPEG-7 is the metadata standard, based on XML Schema, for describing features of multimedia content and providing the most comprehensive set of audio-visual description tools available. These description tools are based on catalog (title, creator, rights); semantic (the who, what, when and where information about objects and events); and structural (the measurement of the amount of color associated with an image or the timbre of a recorded instrument) features of the audio-visual content. They build on the audio-visual data representation defined by MPEG-1, -2 and -4... MPEG-1, -2 and -4 make content available. MPEG-7 lets you to find the content you need. Because of that, it's important to note that MPEG-7 addresses many different applications in many different environments. It provides a flexible and extensible framework for describing audio-visual data, by defining a multimedia library of methods and tools. It standardizes: (1) A set of descriptors. A descriptor is a representation of a feature that defines the syntax and semantics of the feature representation. (2) A set of description schemes. A description scheme specifies the structure and semantics of the relationships between its components, which may be both descriptors and description schemes. (3) A language that specifies description schemes, the Description Definition Language (DDL). It also allows for the extension and modification of existing description schemes. MPEG-7 adopted XML Schema Language as the MPEG-7 DDL. However, the DDL requires some specific extensions to XML Schema Language to satisfy all the requirements of MPEG-7. These extensions are being discussed through liaison activities between MPEG and W3C, the group standardizing XML. (4) A binary representation to encode descriptions. A coded description is one that's been encoded to fulfill relevant requirements such as compression efficiency, error resilience and random access..." See (1) "Moving Picture Experts Group: MPEG-7 Standard"; (2) "MPEG Rights Expression Language."
[November 20, 2001] "An XML-message Based Architecture Description Language and Architectural Mismatch Checking." By Bo Zhang, Ke Ding, and Jing Li (Chinese Academy of Sciences, Beijing, China). Email: [Bo Zhang] [email protected] - {zb, dingke, lij}@otcaix.iscas.ac.cn. Paper presented at COMPSAC 2001 (25th Annual International Computer Software and Applications Conference), 8 -12 October 2001, Chicago, Illinois, USA. Paper Session 11B "Extensible Markup Language (XML)," chaired by Thomas Weigert (Motorola Global Software Group, USA ) and T.Y. Lin (San Jose State University, USA). Published in the Conference Proceedings Volume [IEEE: 0730-3157/02]. "Current component interfaces, such as those defined by CORBA, are devoid of additional constraints that make helps in the task of composing software, therefore the dependent relations and interaction protocols among components are hidden within the implementations. The 'implicity' reduces the composability and makes it difficult to reuse, validate and manage components. This paper presents a message based architectural model and an XML-message based Architecture Description Language (XADL). XADL promotes the description of dependent relations from the implementation level to the architectural level and enhances the interface specification by adding the sequencing, behavior and quality constraints. Furthermore, we formulate the notion of architectural mismatch and propose a checking algorithm to prevent systems from potential mismatches. The use of XML facilitates not only the specification descriptions but also the system implementations, and increases the openness of the whole system as well... Software architecture shifts the focus of developers from lines-of-code to coarser-grained architectural elements and their overall interconnection structure. The message based architectural model we proposed promotes the description of dependent relations among components from the implementation level to the architectural level and decreases the coupling of the components in the system. So the components can be used as to some extent independent building blocks in system constructing. Architecture description languages have been proposed as modeling notations to support architecture-based development. Many ADLs are proposed for diverse purpose, such as UniCon, Wright, SADL, Rapide, C2 and ACME etc. A classification and comparison framework is also provided to support intensive researches on ADLs. XADL models most of the aspects outlined by the framework, including components, connections and configurations. Compared with the ADLs we mentioned above, XADL is akin to Rapide due to both event-based style. However, Rapide employs complex event patterns to specify the event sequences while XADL adopt simpler finite-state automata to do so. The differences mainly result from their distinct purposes: Rapide is for architecture simulation where event patterns fit well; and system reasoning is one of the motivations of XADL, so we choose the finite-state automata. Additional constraints on interface specification can help in the task of composing software. It helps the programmers of modules by allowing tools to automatically check that the module obeys the constraints given in the specification, and helps users of the module by formally documenting usage assumptions... Although not discussed in this paper, we have provided two tools for XADL: one is the mismatch detector that implements the algorithm proposed in section 3; another is the implementation generator that maps the XADL specifications into implementation skeletons. According to our experience with XADL, choosing XML to specify the messages exchanged among components can not only ease the description of the specifications such as behavior and quality constraints, but also can simplify their implementation... The contributions of this paper fall into three categories: software architecture, component interface definition and component system reasoning. We have presented a message based architectural model that makes it explicit the dependent relations among components. Based on this model, XADL, an XML-message based architectural language, is proposed to support the description of components and their combining relations. XADL enhances the interface specification by adding the sequencing, behavior and quality constraints to it. So we can specify the interface at different levels. Sequencing constraints, together with the description of connections, define the interaction protocols of message orderings among components. Moreover, we formulate the notion of architectural mismatch and propose the checking algorithm, preventing systems from such errors. The use of XML eases both the description and the implementation, and increases the openness of the whole system as well..." For another 'xadl' see "ArchStudio Software Development Environment Uses xADL DTD for XML-based Integration Stategy."
[November 20, 2001] "Representing Product Family Architectures in an Extensible Architecture Description Language." By Eric M. Dashofy and André van der Hoek (Institute for Software Research, University of California, Irvine). In Proceedings of the International Workshop on Product Family Engineering (PFE-4) (Bilbao, Spain, October 2001). "Product family architectures need to be captured much like 'regular' software architectures. Unfortunately, representations for product family architectures are scarce and a deep understanding of all of the necessary features of such representations is still lacking. In this paper, we introduce an extensible XML-based representation that is suitable as a basis for rapidly defining new representations for product family architectures. We describe some of the details of this representation and present how Koala and Mae, two early representations for product family architectures, can be mapped onto our XML-based representation with relatively little effort. Research in the area of product family architecture is still maturing at a rapid pace. It would be imprudent at this early stage in the development of product family architecture representations to attempt to define a universal or all-encompassing representation format. Simply put, we do not know all the aspects of a product family that we may want to capture. Yet, we want to leverage early representations as much as possible in our future explorations. In this paper we have presented aspects of xADL 2.0, a modular and extensible representation for product family architectures that makes this possible. Leveraging XML schemas and a flexible code generator, xADL 2.0 provides developers with the ability to quickly and easily create new representations that explore new directions in product family architecture research. We have demonstrated this ability through our mappings of two existing representations for product family architectures. Our future work includes the development of additional XML schemas to provide an increasing set of "standard" product family architecture features, experimentation with new features for product family architectures, and further dissemination of the schemas and toolset to allow an increasing set of other parties to develop XML schemas for xADL 2.0..." See references in "ArchStudio Software Development Environment Uses xADL DTD for XML-based Integration Stategy." [cache]
[November 20, 2001] "Building and Managing XML/XSL-powered Web Sites: An Experience Report." By Clemens Kerer, Engin Kirda, Mehdi Jazayeri, and Roman Kurmanowytsch (Technical University of Vienna). Paper presented at COMPSAC 2001 (25th Annual International Computer Software and Applications Conference), 8 - 12 October 2001, Chicago, Illinois, USA. Paper Session 11B "Extensible Markup Language (XML)," chaired by Thomas Weigert (Motorola Global Software Group, USA ) and T.Y. Lin (San Jose State University, USA). Published in the Conference Proceedings Volume [IEEE: 0730-3157/02]. "The World Wide Web Consortium's Extensible Markup Language (XML) and the Extensible Stylesheet Language (XSL) are standards defined in the interest of multi-purpose publishing and content reuse. XML and XSL have been gaining popularity rapidly both in industry and in academia. Although much has been written on XML/XSL-based solutions, there exists a gap between theory and practice. In this paper, we report our experiences in deploying XML/XSL in the implementation of two industry Web sites and summarize nine lessons we drew from our experiences... MyXML template engine: MyXML is an XML/XSL-based template engine for the development of flexible, dynamic Web services. Besides the separation of layout and content using XML/XSL, MyXML enables the business logic of Web applications to be separated as well. A separation of the business logic increases the flexibility of dynamic Web services. We have been using our MyXML technology in the case studies. A detailed description of MyXML is beyond the scope of this paper, but more information can be found in [online]... In our projects, we were able to confirm that XML/XSL deployment indeed increases layout flexibility and provides multi-language and navigation support. Although a strict LC separation achieved through XML/XSL has many advantages, a considerable effort is involved in using these technologies. The lack of experience in LC separation concepts and XML/XSL can be a major cause for the extra effort. We observed a significant gap between XML/XSL theory and practice. Most Web development companies are still reluctant to deploy XML/XSL in their projects. In order to highlight the benefits of these technologies, there is a need for Web developers to report their practical XML/XSL experiences in real-world conditions. Furthermore, there is a great need for proven, easy-to-use XML/XSL Web development tools and methodologies. XML and XSL in Web development can contribute to creating highly flexible, device-independent Web services, but they will not remedy all problems found in Web sites. The advantages provided by XML/XSL may not be apparent during the implementation phase, but the extra deployment effort will pay off once requirements start to change, the site has to be re-engineered, or there is a need for supporting mobile devices..."
[November 20, 2001] "Using SOAP to Clean up Configuration Management." By Paul O'Connell and Rachel McCrindle. Paper presented at COMPSAC 2001 (25th Annual International Computer Software and Applications Conference), 8 -12 October 2001, Chicago, Illinois, USA. Paper Session 11B "Extensible Markup Language (XML)," chaired by Thomas Weigert (Motorola Global Software Group, USA ) and T.Y. Lin (San Jose State University, USA). Published in the Conference Proceedings Volume [IEEE: 0730-3157/02]. "Software products have become increasingly complicated over the past decade. For example, software is no longer restricted to a single binary file constructed from a small number of source files residing at a single location. Products today are frequently split across client and server architectures with further complications arising through the need for the client and the server to be built and run on different platforms, developed and deployed in multiple physical locations and by workers spanning several different time zones. These factors contribute to making modern software configuration management (CM) a vital but extremely complex process. In this paper we describe a new method for managing the configuration management of evolving modern day distributed systems based on the use of emerging web technologies, specifically XML (Extensible Markup Language) XML-RPC (XML-Remote Procedure Call) and SOAP (Simple Object Access Protocol). We have currently designed and implemented a proof of concept prototype that enables the files that make up the configuration of a product to be distributed across a network of disparate machines and operating systems, yet appear to a user to be locally stored on a single client machine. We are now in the process of improving and extending this system. Currently the Repository module is brought into existence when it is needed. It would improve performance and make the system more scalable if the server created a thread pool. Each thread would contain an instance of the Repository module. This would extend to all other modules and the administrator could specify the size of the thread pool for each module. Simple load balancing could also be added. In this instance, if a client logs into a server that thinks it is too busy then the server could reply with the name of a different server to log into. The client software would then try the log on again to the new machine without the user knowing that a switch is necessary. Compression could be added on the server end. This would reduce the amount of disk space required to store a CI. This can be done already on a server running on Windows NT, because any directory can be compressed by the operating system itself if the administrator of the operating system requests this. Linux does not have a compressed file system yet. The compression would save a considerable amount of space because the data is stored in text file, which will compress well." See "Simple Object Access Protocol (SOAP)."
[November 16, 2001] "E-Books and Digital Rights Management Struggle Together." By Mike Letts. In Seybold Report: Analyzing Publishing Technology [ISSN: 1533-9211] Volume 1, Number 15 (November 1, 2001), pages 8-12. ['E-book and rights-management vendors have come to understand that they are in the same boat: They both depend on finding a new balance between property rights and fair use. Meanwhile, both are avoiding consumer markets in favor of enterprise publishing and reference works.'] "Recurring themes were prevalent at Seybold San Francisco 2001, with digital rights management and electronic book vendors hedging bets on exactly when electronic content distribution will take hold among consumers. The more important question is where to focus their attention until it does...If nothing else, the DRM developments of the past several months -- though overshadowed by the Dmitry Sklyarov debacle and the ensuing debates about the Digital Millennium Copyright Act -- have made it clear that there are still issues that must be hashed out... A large and increasingly vocal portion of the industry has already written DRM off, offering intriguing arguments for the ubiquitous 'freedom' of content, while others are equally insistent on protecting the financial basis of the industry. The rest of the attendees could only hope that a middle ground may be found through revamped legislation and better-developed rights-management systems. On the [Seybold San Francisco] show floor, it was clear that the e-book and DRM vendors have come to a general understanding: For at least the time being, they're traveling in the same boat. Until a more equitable balance between copyright law and fair use can be reached, both DRM and e-book vendors are tiptoeing away from consumer e-books... Microsoft technology partner and electronic-content service provider OverDrive made several announcements, one of which included DRM vendor and XrML developer ContentGuard. ContentGuard, a Xerox spinoff that has developed the rights-description language XrML, gained a valuable teammate at Seybold San Francisco. OverDrive announced that not only will it work with ContentGuard to promote XrML as an industry standard, but it will begin using XrML across its service offerings. Specifically, [OverDrive CEO] Potash mentioned three of the company's offerings, ReaderWorks, Midas and ContentReserve. Each addresses a different point of exchange... The OverDrive announcement entrenches XrML in the Microsoft camp. Representatives from Microsoft and OverDrive repeatedly affirmed their strong commitment to XrML (which is also the rights-expression language used by Microsoft's DAS solution) throughout the week. The proclamations were most likely designed to assuage potential fears among publishers that ContentGuard's recent struggles might put XrML at risk. ContentGuard was forced to undergo some corporate refocusing over the last several months and has shifted from a services-based approach to focusing solely on licensing its XrML technology and related patents. As a DRM developer, ContentGuard certainly isn't alone in its troubles, but XrML has gained significant mindshare during the past 12 months. OverDrive is one of the leading conversion and service providers for publishers looking to implement Microsoft's .LIT format, and its partnership with ContentGuard is a very positive step forward in its goal of pushing XrML as an industry standard. As the DRM and e-book shakeout continues -- and, as usual, it appears to be a bipolar Microsoft vs. Adobe world on both fronts -- these partnerships will become more and more valuable..." [See Planet eBook index for Dmitry Sklyarov and DMCA.] References: "XML and Digital Rights Management (DRM)."
[November 16, 2001] "XML in Electronic Court Filing." By Ken Pittman. From XML.com. November 14, 2001. ['How XML is used in electronic filing systems in the US.'] "With over 90 million cases filed each year in the United States, electronic filing is emerging as a proven alternative to conventional case filing for courts and litigants alike. Increasingly, court clerks, judges, and attorneys are trying out the services in a growing number of pilot programs which courts are offering their constituents... Electronic filing works by replacing the traditional method of filing, serving, storing, and retrieving court documents with a more efficient electronic process. Instead of duplicating, packaging, and manually delivering copies of documents to the court and service parties, you send them electronically over the Internet.... Mapping the right information to the right parties presents a challenge uniquely suited to an XML-based solution. Courts require both the filing or the document stating the plaintiff's case (pleadings) and the necessary supporting information such as information supporting submission to the dockets: case summaries, case details, criminal or civil charges and court verdicts, plaintiff, defendant, and other parties as necessary. Each court may define these requirements to suit its specific needs. Court staff involvement varies from court to court. Many courts are relying on established vendors to build solutions, while others are building e-file applications in-house. New Jersey, due to the centralized nature of their court system, built their e-file system using in-house staff. New Jersey's system is built with Visual Basic. Most courts are heavily involved in the business process definition phase and requirements definition..." [See references at LegalXML, Inc., which is "is a non-profit organization comprised of volunteer members from private industry, non-profit organizations, government, and academia; its mission is to develop open, non-proprietary technical standards for legal documents," chiefly through its workgroups.]
[November 16, 2001] "XML::LibXML - An XML::Parser Alternative." By Kip Hampton. From XML.com. November 14, 2001. "The vast majority of Perl's XML modules are built on top of XML::Parser, Larry Wall and Clark Cooper's Perl interface to James Clark's expat parser. The expat-XML::Parser combination is not the only full-featured XML parser available in the Perl World. This month we'll look at XML::LibXML, Matt Sergeant and Christian Glahn's Perl interface to Daniel Velliard's libxml2. Expat and XML::Parser have proven themselves to be quite capable, but they are not without limitations. Expat was among the first XML parsers available and, as a result, its interfaces reflect the expectations of users at the time it was written. Expat and XML::Parser do not implement the Document Object Model, SAX, or XPath language interfaces (things that most modern XML users take for granted) because either the given interface did not exist or was still being heavily evaluated and not considered 'standard' at the time it was written. The somewhat unfortunate result of this is that most of the available Perl XML modules are built upon one of XML::Parser's non- or not-quite-standard interfaces with the presumption that the input will be some sort of textual representation of an XML document (file, filehandle, string, socket stream) that must be parsed before proceeding. While this works for many simple cases, most advanced XML applications need to do more than one thing with a given document and that means that for each stage in the process, the document must be serialized to a string and then re-parsed by the next module... XML::LibXML offers a fast, updated approach to XML processing that may be superior to the first-generation XML::Parser for many cases. Do not misunderstand, XML::Parser and its dependents are still quite useful, well-supported, and are not likely to go away any time soon. But it is not the only game in town, and given the added flexibility that XML::LibXML provides, I would strongly encourage you to give XML::LibXML a closer look before beginning your next Perl/XML project..."
[November 16, 2001] "DOM and SAX Are Dead, Long Live DOM and SAX." By Kendall Grant Clark. From XML.com. November 14, 2001. ['DOM's too dumb and SAX is too hard say XML developers.'] "Most serious books, tutorials, or discussions of XML processing for programmers mention, even if only in passing, DOM and SAX, the two dominant APIs for handling XML. A general discussion of XML programming which failed to mention DOM and SAX would be as neglectful of its duty as would a monarchical subject who, upon entering the royal chambers, failed to acknowledge the presence of the King and Queen. Failing to acknowledge the potentate is simply one of the things one must never do. Just as the permissible forms of obligatory acknowledgment of the royal personage are both highly ritualized and customary, so, too, are the forms with which DOM and SAX are customarily introduced. We will be told, one may rest assured, that DOM is a tree-based API, one which builds an in-memory representation of an XML instance. Likewise, we will be told that SAX is an event-driven API, one which, rather than building an in-memory representation of an XML, calls event handlers as it encounters, serially, particular features of the XML instance. The moral of this highly ritualized story is invariably: one may often wish to use DOM parsing, but SAX is helpful when the size of XML instances exceeds available system memory. One might suppose that every competent programmer with real-world XML experience has a firm grasp upon, if not fully mastered, both DOM and SAX, and that in consequence of such widespread competence there is very little left of interest to be said about them by and to an expert audience. And yet as a recent XML-DEV discussion seems to have proved, things are neither always as one might reasonably suppose, nor are they always as purely technical as one might wish..."
[November 14, 2001] "XML Codes Data for Net Connection." By Charles Gordon )Principal Engineer, NetSilicon Inc.Waltham, MA, USA). In EE Times (November 14, 2001). "Making devices communicate with one another is not as simple as putting them all on a network. Devices must understand each other's data formats if they are to exchange information successfully. That means the devices' manufacturers have to agree on a common data format, specify it in an unambiguous way and then implement the communications firmware according to the specification. Design engineers can use the Extensible Markup Language for specifying the format of data records. XML is based on the Standard Generalized Markup Language (SGML) but is much simpler. Developers specify the format of data records by creating an XML schema, or data file that describes the formats of XML records... There are two standard application programming interfaces for XML parsers. The Simple API for XML (SAX) is event-driven. SAX defines a set of functions that must be implemented in the application. The parser calls those functions when certain events occur as it parses data records. Those events include encountering the beginning and end of data records and fields within data records, and encountering data contained within the fields. The other standard API is the Document Object Model (DOM). When the DOM API is used, the parser processes the entire data record and builds a DOM tree (a linked list data structure) to represent it. The DOM tree is passed to the application in its entirety after the parser has finished processing the data record. To generate a data record, the application uses the DOM API to construct a DOM tree and passes it to the parser, which encodes it. The most obvious way of implementing support for XML in an embedded system is to port an existing parser. Many XML parsers are available on the Internet, and many of those are very good and are kept up to date with the latest developments in XML. Free source code is available in C, C++ and Java. Porting one of them to an embedded application is a fast way of implementing full-featured support for XML..."
[November 12, 2001] Orlando: A Logical Mnemonic Model for Calendaring and Scheduling." By Greg FitzPatrick. November 7, 2001 or later. ['The aim of the paper is to formalize a logical and mnemonic model for the representation of Temporal information. The model, which we are calling Orlando, is evolved from the iCal RFC2445 datetime and datetime reoccurrence rules.'] "The Concept of Universal Synchronization Any resource or directory of resources, where temporal-spatial considerations are of significance for the resource, or to the human or electronic agent seeking to know about or utilize the resource, will publish, in a machine-readable format, the temporal-spatial coordinates of that resource. Any person or person's electronic agent wishing to know about, use, or negotiate the use of a resource will have the option of declaring in a machine-readable format any of their own temporal-spatial coordinates that might serve to optimize possible transactions. Any person or person's electronic agent wishing to interact with any other person or their electronic agent may optimize that interaction through publishing, in a machine-readable format, the temporal-spatial coordinates that might add value to that interaction Without debating the feasibility, utility or desirability of Universal Synchronization, this paper will present the Orlando model for representing temporal coordinates in a machine-readable format that utilizes the mnemonics of the common calendar and wall clock... You can program a machine to do repetitive things at very erratic intervals. The SMIL 2.0 Timing and Synchronization Module, which has little need for datetime unit symmetry, is an example of this, but datetime symmetric loops are very convenient for people. And equally important, datetime units reflect usage. The Orlando model incorporates the common date-date units of everyday scheduling. The accent is on reoccurrences of a more persistent nature, such as the opening and operating hours of businesses and services, but singular events may also be declared using this model. The ultimate use-case is that in which all human digiphernalia can access and interact (voluntarily - one hopes) with the temporal-spatial coordinates of all possible resources. Orlando both reformulates and extends the reoccurrence rules of RFC2445, the iCal Calendaring and Scheduling standard that is predominate (at the time of this writing) for mainstream computer based calendaring and scheduling systems. Like RFC2455, XML Schema Datatypes, and other standards work dealing with the representation of time, Orlando uses the datetime terms and representations standardized in ISO8601. Orlando also defines types which ISO8601 does not cover. ISO8601 does not attempt to standardize the use of named datetime units; the days of the weeks and months; Monday to Sunday and January to February. No doubt internationalization issues are involved in that decision. We will use English datetime units here, assuming these to have equivalents in any modern language... The major source of information on calendaring and scheduling used in preparing this paper comes from the work in process of the CALSCH WG in the IETF Applications Area. The mailing list is accessible, but the most expedient access to the iCalendar knowledge base is via a search application maintained by one of our members, Bruce Kahn of IRIS Systems. RFC2445 is available at the IETF archives or at the iCal Org home page. Please note that RFC2445 is only one member of a family of documents describing iCal..." See "iCalendar DTD Document (xCal)."
[November 12, 2001] "XML for Instrument Control and Monitoring. Exchanging Data Between Instruments." By David Cox. In Dr Dobb's Journal [DDJ] (November 2001) #330, pages 83-85. [Embedded Systems. The Instrument Markup Language is an XML dialect designed to aid in the exchange of data and commands with remote instruments. Additional resources include listings, ixml.txt.] "Objects are used for machine-to-machine communications. However, both Microsoft's DCOM object technology and the Object Management Group's CORBA are "multiport protocols," which means they don't work too well with firewalls that limit the number of open ports. So much for efficient machine-to-machine communications. Partly because of this, Microsoft introduced a third protocol -- the Simple Object Access Protocol (SOAP) -- that piggybacks on the single port protocol, HTTP. All three protocols -- DCOM, CORBA, and SOAP -- let client applications create objects that appear to be local, but really execute elsewhere on a network. In the near term, DCOM, CORBA, and SOAP will likely remain the preferred choices for distributed computing. Even in the world of instrument monitoring and control, for instance, COM and DCOM have been adopted as a standard for controlling instruments, at least in terms of the Open Process Control (OPC) Standard, promoted by the OPC Foundation. However, efforts are underway to use XML for electronic data interchange and all types of business transactions, as people begin exchanging everything from purchase orders to medical records as XML-formatted messages... a group at NASA's Goddard Space Flight Center is using a dialect of XML called the "Instrument Markup Language" (IML) to control remote instruments. IML is being developed by NASA and Commerce One with the goal of creating a very general and highly extensible framework that applies to any kind of instrument that can be controlled by a computer. The Astronomical Instrument Markup Language (AIML) is the first implementation of IML. Although AIML was created for the astronomy domain in general and infrared instruments in particular, both AIML and IML were designed to apply to just about any instrument control domain... IML is a specification for using XML to aid in the exchange of data and commands with instruments. XML itself is not sent between computer and instrument. However, XML is used to describe the commands and data that can be transferred. For instance, a software tool reads the XML, automatically creates an appropriate user interface for issuing commands, and finally sends the commands in response to user input. When responses come back, the same tool can -- using the XML specification -- interpret the incoming data and automatically present it with an appropriate user interface. The original version of IML was written as an XML Data Type Declaration (DTD). The most recent version is written as an XML Schema..." See "Astronomical Instrument Markup Language (AIML)."
[November 12, 2001] "Inside eBook Security." By Daniel V. Bailey (Brown University, Department of Computer Science). In Dr Dobb's Journal [DDJ] (November 2001) #330, pages 42-45. ['Daniel reports on Dmitry Sklyarov's analysis of PC-based digital rights management security techniques.'] "Partly in an attempt to protect the interests of publishers, the U.S. Congress in 1998 enacted national copyright laws called the 'Digital Millennium Copyright Act' (DMCA). Among other things, this legislation (Public Law 105-304) makes it a crime to circumvent security controls in DRM-secured content. In a July 15, 2001 presentation at the Def Con 9 security conference Dmitry Sklyarov presented the results of his Ph.D. research analyzing Adobe's DRM security system for protecting PDF files. But before departing for his native Russia, Sklyarov became the first person to be arrested for criminal violation of the DMCA. Social, economic, and moral analyses of the DMCA and Sklyarov's case are to be found elsewhere (for instance, see http://www.eff.org/). This article describes the techniques Sklyarov used to defeat portions of Adobe's DRM security for PDF files... Add-in hardware for PCs exists that protects keys from prying eyes, but it remains expensive, nonstandardized, and still not entirely beyond the reach of determined adversaries. Use of such hardware is thus not an attractive option to mainstream publishers. In each case, Sklyarov's ability to defeat Adobe's eBook plug-in security results from one or both of these failures on the part of the plug-in -- either the cryptography in the plug-in did not embody its security in a key too big for an attacker to guess, or system-level attacks revealed keying material... There are two technical lessons which can be learned from Dmitry Sklyarov's work. First, bad cryptography will be broken. Second, PCs inherently offer no way to protect secrets. Even with the use of good cryptographic algorithms and reasonable system design, this is a fundamental problem. In short, in their current incarnation, PCs aren't well suited for digital rights management systems." See: "XML and Digital Rights Management (DRM)."
[November 09, 2001] "Content Syndication Tech Talk." By Alan Karben. In ContentWire Fresh Picks October 24, 2001. "Last year NewsML was introduced as the XML format of choice for information exchange, now it turns out That everybody is using NITF. It also turns out that lots of people have not quite heard of it yet. Alan Karben, VP, Product Design, ScreamingMedia, has been working at the project, he takes our questions. ['NITF 3.0 includes several improvements, you say, including a 'cleaner' DTD. What is DTD?'] The XML standard is a set of instructions on how to create data formats for various purposes. XML itself says nothing about what properties should be in those formats. That all goes into a Document Type Definition, or DTD. Examples of DTDs include NITF for news articles, NewsML for complex multimedia news packages, MDDL for markets data, SportsML for sports data. There have been probably 100,000 DTDs created, for everything from a repair manual for an airplane, to a logical description of a pizza. The NITF DTD contains the properties you'd expect to find labeled in a news article: headline, byline, metadata, paragraph, image, caption, credit, etc... NITF was designed by individuals with strong backgrounds in news editorial systems. These people come from name-brand newspapers and newswires such as The New York Times, The Wall Street Journal, AP, UPI, Reuters, dpa, AFP, PA, etc. So, if you are publishing a newspaper, newswire, or news website, or receive content from them, than NITF was designed exactly for your needs... Europe has seen excellent adoption of NITF over the years. Distribution from Germany's largest news agency, dpa, has been in NITF for years. Sweden's newswire also chose NITF. They've added a few variations to the standard, but it is basically the same thing. AFP in France uses NITF embedded into NewsML packages, another IPTC standard. Companies that specialize in content syndication, such as ScreamingMedia (where I work), allow clients to receive news from thousands of different publications from around the world, all translated into NITF..." See (1) "News Industry Text Format (NITF)", and (2) the announcement for NITF v30, "IPTC Issues NITF 3.0. Improves Metadata Capabilities of Leading XML Structure for News Articles."
[November 09, 2001] "Single Source Publishing: XML For Multimedia Data Exchange." By PG Bartlett (VP Marketing, ArborText). In ContentWire Fresh Picks November 07, 2001. ['One thing you should do before acquiring your Content Management System: make sure it outputs XML'] "Most organizations have strong commitments to their existing tools and processes for creating and publishing information. But information is fragmented. Physical fragmentation, the storage of business-critical unstructured information dispersed across many personal and workgroup file systems, means that data retrieval is expensive. Format Fragmentation , whereby information exists in a separate format that must be separately maintained, makes the cost of maintaining information as much as twenty times more expensive than creating that information in the first place. Maintenance and updates are especially difficult because changes to the information are costly, slow and manual. The Extensible Markup Language (XML) offers the potential of solving the 'format fragmentation' problem: unlike proprietary content formats that are optimized for a specific use on a specific medium, XML can represent information in a media-neutral format that can serve as a single source for automatic transformation for specific purposes on specific media... XML's media-neutral format allows the capture of content in a form that's independent of any particular medium. That means that instead of embedding formatting information within the content, it's applied separately through a 'stylesheet' that can vary based on the target medium. By using a different stylesheet for each medium, one can generate many different forms from the same source of content -- which enables information to remain consistent regardless of media type: Web, print, CD-ROM, wireless. Further, you can adjust the output to take advantage of the capabilities of each medium..."
[November 09, 2001] XSL Template Collection for XLIFF/TMX. November 09, 2001. 'A set of XSL templates to execute various tasks. It includes for example: XLIFF to Java properties file conversion, XLIFF to TMX, TMX to tab-delimited, Leveraging of existing translation into an XLIFF document, conversion to UTF-8 encoding for any XML document, etc.' From the posting of Yves Savourel 2001-11-09 (and see the README): "...a note to let you know that there is now a small collection of XSL templates freely available that offers utilities for XLIFF and TMX. For now it includes 6 templates: (1) LeverageXLIFF.xsl - Leverages the existing translation of a XLIFF document into a newer XLIFF document. (2) XLIFFToPO.xsl - Converts the <target> elements of an XLIFF document into a PO (Portable Object) file. (3) XLIFFToProperties.xsl - Converts the <target> elements of an XLIFF document into a Java properties files. (4) XLIFFToTMX.xsl - Converts an XLIFF document into a TMX document. (5) TMXToTDF.xsl - Converts the entries of a TMX document into a tab-delimited file. (6) ToUTF8.xsl - Converts any XML file into UTF-8 encoding. More will come later (suggestions are welcome)..." See: (1) "XML Localization Interchange File Format (XLIFF)", and (2) "Translation Memory Exchange." [cache]
[November 09, 2001] "Service Registry Proxy: A higher-level API." By Alfredo da Silva (Advisory Software Engineer, IBM). From IBM developerWorks. November 2001. ['In order to provide additional tools to the Web services developer, this article discusses a new API -- the Service Registry Proxy, or SRP -- which helps to raise the abstraction level during application development and promotes seamless integration between UDDI and WSDL elements.'] "The release of the UDDI4J API enabled the creation of UDDI-aware applications, making the publish, unpublish and find operations available from an open-source API. In order to allow WSDL documents to be part of this equation, a new layer called the Service Registry Proxy API (or SRP), which sits on top of the UDDI4J, has been devised. The SRP API elements encapsulate classes present in the UDDI4J API, and some defined by the WSDL4J API, and offer a comprehensive set of methods for interfacing with a UDDI Registry. Its model simplifies the development of applications because it raises the level of abstraction, enabling the developer to concentrate on entities directly related to the Web services architecture domain. SRP supporting classes The SRP API is structured around the following main elements: Service Provider (SP), Service Definition (SD), Service Implementation (SIMP), and Service Interface (SITF)... SP (The Service Provider) represents an entity capable of providing services. It encapsulates a reference to the UDDI4J class BusinessEntity. SD (The Service Definition) describes a service by breaking it down into two pieces: implementation (SIMP) and a list of the implemented interfaces (SITF). SIMP (The Service Implementation) has a dual role. It exposes the related WSDL implementation document (see Resources) and also has a reference to the UDDI4J class BusinessService. SINT (The Service Interface) also encapsulates two entities: a WSDL interface document and a reference to the UDDI4J class TModel. The WSDL capabilities presented by SIMP and SINT are inherited from their parent class WSDLServiceInfo. This organization enables SRP to tie together UDDI and WSDL elements and, at the same time, abstract their concepts -- thereby making the creation of Web services a more productive task." Article also in PDF format. See also: (1) "Web Services Description Language (WSDL)", and (2) "Universal Description, Discovery, and Integration (UDDI)."
[November 09, 2001] "Rules: Leaders Avert Standards Battle -- For Now." By Wylie Wong. In CNET News.com November 05, 2001. "Not long ago, the idea would have been unthinkable: Microsoft and IBM, sworn enemies after their struggle for control of the PC operating system in the early 1990s, laying down their swords and cooperating to create an industry standard for an important new technology. Yet that's exactly what has happened in the emerging market for Web-based software and services. It is a testament to vastly changing times in the high-tech industry, when longtime rivals are seeking such truces to survive a combination of global economic malaise, dot-com bust and saturation of the PC market. Although Web services look to some to be simply the latest ploy in an industry that depends on marketing hype, the extraordinary cooperation by Microsoft and IBM, and more recently by Sun Microsystems, may be an indication that the latest trend is more than just vaporware. 'We have not created multiple standards, but rather we've gone out and supported interoperability,' said Philip DesAutels, Microsoft's product manager for XML Web services. 'It's safe to assume the goal is to have one standard.' The goal is also the straightest line to profitability, instead of the consumption of time and resources in costly industry infighting over which specifications should be used and who would benefit most from them. The incentive is even more understandable when the stakes are assessed: If the concept of Web services catches on, it could fundamentally change the way companies do business and people use the Internet. The idea is to sell software as a subscription-based service over the Web instead of through traditional methods such as boxed copies at retail stores. By running software on central Web servers, as opposed to on individual PCs, people can theoretically have access to all manner of applications and services from any computer, cell phone, handheld device or anything else connected to the Internet, with updates made automatically, in real time. At the heart of this broad vision is a technology known as XML, or Extensible Markup Language, which allows companies to more easily exchange data online. Last year, Microsoft, IBM, Sun, Oracle and others put aside their competitive differences to agree on three Web standards related to XML that serve as the underlying technology for Web services..."
[November 09, 2001] "Core Components Technical Specification, Part 1." By eBTWG CC Project Team Participants. United Nations Centre for Trade Facilitation and Electronic Business. Draft Version 1.7. 31-October-2001. 92 pages. "This Core Component technical specification provides a way to identify, capture and maximize the reuse of business information to support and enhance information interoperability across multiple business situations. The specification focuses both on human-readable and machine-processable representation of this information. The system is more flexible than current standards in this area because the semantic standardisation is done in a syntax-neutral fashion. UN/CEFACT can guarantee that two trading partners using different syntaxes (e.g., XML and EDIFACT) are using business semantics in the same way. This enables clean mapping between disparate message definitions across syntaxes, industry and regional boundaries. UN/CEFACT Business Process and Core Component solutions capture a wealth of information about the business reasons for variation in message semantics and structure. In the past, such variations have introduced incompatibilities. The core components mechanism uses this rich information to allow identification of exact similarities and differences between semantic models. Incompatibility becomes incremental rather than wholesale, i.e., the detailed points of difference are noted, rather than a whole model being dismissed as incompatible." See the 2001-11-09 news item for details.
[November 08, 2001] "High Hopes for the Universal Business Language." By Edd Dumbill. Interview with Jon Bosak. From XML.com. November 07, 2001. "OASIS, an international consortium that develops XML-based industry specifications, including DocBook, ebXML, and RELAX NG, recently announced the formation of a new Technical Committee (TC) to pursue the development of UBL, the Universal Business Language. Those swimming in the acronym soup of industry XML specifications would be forgiven for being underwhelmed at the news of another XML language. This time, however, it's different for two reasons. First, UBL aims to clear up the current state of confusion, rather than add to it. Second, UBL's being spearheaded by Jon Bosak, who championed the development of XML 1.0 at the W3C. We interviewed Jon Bosak about the new UBL activity, its relationship to ebXML, and its status with regard to intellectual property concerns. ['What were the reasons that led to the formation of the UBL effort?' Bosak:] "Two things, basically. First, the current multiplicity of XML business schemas (cXML, xCBL, RosettaNet, OAGIS, etc.) is causing a lot of headaches for systems integrators and IT managers. This situation is great for companies that sell professional services and transformation software, because it creates a demand for adaptors that can translate between these different formats, but it's a real pain for everyone else, and technically it's completely unnecessary. There are good reasons why a purchase order designed for the auto industry in Detroit won't work 'as is' for the shoe industry in Brazil, but there's no good reason at all why a shoe wholesaler has to buy extra software to enable him to do business with two different Brazilian shoe manufacturers using different purchase order formats to do exactly the same thing. Businesses operating in the same business context should be able to use the same forms of data representation. The second reason for UBL is to jumpstart a worldwide transition to electronic commerce from traditional business processes. Most of the emphasis so far has been on how to enable big multinationals to do business with each other, while relatively little attention has been paid to how we enable small companies to compete in the same virtual business environment. But most of the world's business is, in fact, done by small companies. I want to enable a five-person manufacturer of fabrics in Pakistan to bid on supplying a hundred units out of a purchase request for a million seat covers from General Motors. Seeing both parties to this transaction benefit equally is for me what this is all about... UBL will create a 'Universal Business Language' that will be a synthesis of existing XML business document libraries. We're going to begin with xCBL 3.0 -- because it's already widely deployed and because it's freely available without any legal hassles -- and then we're going to evolve that into UBL by modifying xCBL in order to bring it into line with the other widely used XML business languages and with EDI and the Core Components data dictionary work done in the ebXML initiative. The result of this will be a standard set of XML business document schemas that anyone, anywhere can download and use without having to pay for the privilege and without running into any ownership problems..." See (1) "Universal Business Language (UBL)", and (2) the OASIS TC web site.
[November 08, 2001] "Controlling Whitespace, Part 1." By Bob DuCharme. From XML.com. November 07, 2001. ['DuCharme shows how to strip and preserve whitespace with XSLT.'] "XML considers four characters to be whitespace: the carriage return, the linefeed, the tab, and the spacebar space. Microsoft operating systems put both a carriage return and a linefeed at the end of each line of a text file, and people usually refer to the combination as the 'carriage return'. XSLT stylesheet developers often get frustrated over the whitespace that shows up in their result documents -- sometimes there's more than they wanted, sometimes there's less, and sometimes it's in the wrong place. Over the next few columns, we'll discuss how XML and XSLT treat whitespace to gain a better understanding of what can happen, and we'll look at some techniques for controlling how an XSLT processor adds whitespace to the result document... when you're using XSLT to create XML documents, you shouldn't worry too much about whitespace. When using it to create text documents whose whitespace isn't coming out the way you want, remember that XSLT is a transformation language, not a formatting language, and some other tool may be necessary to give you the control you need. Extension functions may also provide relief; string manipulation is one of the most popular reasons for writing these functions..." For related resources, see "Extensible Stylesheet Language (XSL/XSLT)."
[November 08, 2001] "Identity Crisis: Understanding the ID." By Leigh Dodds. From XML.com. November 07, 2001. ['Leigh Dodds' XML-Deviant article focuses on a problem that's been puzzling the XML developer community of late: identifying ID attributes without a DTD or schema, in much the same way as anchors are used in an HTML document. Several proposals have been made, and Leigh covers the debate.'] "The high level of activity on XML-DEV over the last few weeks has been sustained with a recent flurry of emails being exchanged on the topic of unique identifiers within XML documents. The issue surfaced following a seemingly straightforward problem statement from Fabio Dianda: how does you identify ID attributes without a DTD or when using a non-validating parser? The problem seems straightforward because the answer is that you can't. The only way to discover if an attribute is an ID is by using a schema, or if your application is hard-coded with its name. Game over. However for several people, including Tim Bray and James Clark, this isn't an acceptable situation... one can only link to an element within an arbitrary XML document using a bare XPointer if the element has an ID attribute and if the document has a DTD. Thus, XPointer doesn't play well with simple well-formed documents, arguably one of XML's greatest gifts... While the primary use case presented so far as been the need to link to portions of XML documents on the Web, the scope of the problem actually seems wider. CSS allows styling to be applied to individual elements, using id selectors. Acknowledging that this feature is problematic without a DTD (or guarantee that a user agent may read the DTD), the CSS authors ended up recommending a work-around to avoid the problem altogether. If a generic means of attaching an identifier to an element without using a DTD were available, then this uncertainty could be resolved... Most of the proposals suggested so far have targeted a general solution... The xml:idatt proposal from James Clark has received the most vocal support so far: 'An alternative would be to have an attribute that declares the name of the attribute that is an ID attribute, say xml:idatt. To make this usable, xml:idatt would be inherited. In the typical case where all elements use the same attribute name for an ID, this means that a user has only to add something like xml:idatt="id" or xml:idatt="rdf:ID" to their root element and everything works. You would also need to allow xml:idatt="" to disable inheritance'... If consensus settles on an XPointer-only fix, then there is likely to be pressure applied by the community to have the specification returned to Working Draft status to resolve this issue. It's disappointing that a specification can get this close to becoming a Recommendation with such a big loophole. Something has failed somewhere. In fact it may turn out that this problem has already been considered and rejected. Without disclosure of Working Group discussion it's difficult to surmise anything. If the consensus is that a more general solution is required, then the appropriate way forward seems to be for a Note to be submitted to the W3C documenting the proposal with the aim of it becoming a separate Recommendation."
[November 07, 2001] "Navy Issues XML Guide." By Christopher J. Dorobek. In Federal Computer Week (November 07, 2001). "As the Navy moves forward with its effort to put many of its applications online, the Navy Department's Office of the Chief Information Officer has published a guide on the use of Extensible Markup Language (XML). An initial version of the XML Developer's Guide has been rushed into publication so it might offer guidance to those who are Web-enabling applications under the Navy's Task Force Web initiative, said Michael Jacobs, data architecture project leader for the CIO's office. That initiative seeks to put at least 50 applications online by 2003. The guide is the first thing published by the Navy Department's newly created XML Work Group... The Navy's developer's guide attempts to provide some direction to those creating applications, Jacobs said. The guide, however, does not address the more complex issue of defining a vocabulary and naming scheme. That task will be addressed in the coming months, Jacobs said. The guide builds on a September 06 2001 memo from Navy CIO Dan Porter that recommended developers use the Defense Information Systems Agency's Common Operating Environment XML registry..."
[November 07, 2001] "XMI and UML Combine to Drive Product Development. Ideogramic Suite Demonstrates UML-oriented XML Processing." By Cameron Laird (Vice president, Phaseit Inc.). From IBM developerWorks. October 2001. ['Countless organizations rely on UML (Unified Modeling Language) in the software development process. But software to manage UML itself has a well-earned reputation for being inflexible and difficult. This article describes how the Danish development house Ideogramic ApS extended XMI (an XML specification targeted at such metadata as UML), and explores both the benefits and limitations of "XMLization".'] "UML (Unified Modeling Language) is a software modeling notation. That's generally taken to mean that UML practitioners don't start a software development project by writing computer programs. Instead, they talk, write notes on index cards, draw pictures, perform tiny technical dramas, criticize diagrams, and undertake other abstractions designed to lead to greater efficiency when it comes time to code. Typical UML 'work products' include class profiles captured on stacks of physical note cards, diagrams, and narratives called use cases that describe how users are expected to interact with the deliverable software product... These methods have proven to be well matched with human expressive patterns, but they do not lend themselves to the process of computerization. While it's possible to capture a whiteboard drawing digitally, it's generally an expensive operation, and the resulting datum is clumsy to transmit, version, archive, validate, and transform. The computing infrastructure is far better prepared to manage data in the form of source code, or the HTML that underlies this Web page. XML bridges part of that gap, by providing the building blocks for 'serializing' UML data textually. XML Metadata Interchange (XMI) is an open industry standard that applies XML to abstract systems such as UML. Its method is to capture and express the relationships UML expresses, while discarding most of the visual details of a particular UML diagram. This partitioning into essential content and dispensable form enhances UML's manageability. This article studies the impact of XMI on a small development house, Ideogramic ApS. In particular, it looks at how the XML standard, and the growing sophistication of tools to integrate that standard with others on the market, has enabled one organization to focus on its own product development. XMI is a working example of the benefits of XML standardization. With XML as a base technology, organizations are encouraged to focus attention on their own unique products, trusting that an XML 'bus' will enable them to connect to processes and data in other organizations... In this article, I've shown how Ideogramic ApS exploits XMI to connect its Gesture Recognition product to Rational Software's range of UML products, thus enriching the use of both product sets for the developer community. I've also shown how Ideogramic has extended XMI to suit its particular objectives. In some cases, this extension has proven fairly simple and effective, in others it's both complex and partial. In either case, it seems clear that the effort has paid off for one small, highly innovative startup. Although both UML and XMI remain a bit incomplete, each is sufficiently mature to support successful commercial products, including Ideogramic's Gesture Recognition. And, as I believe this case study shows, the resulting implementation is much like any other XML engine and specific DTD-based application..." See "XML Metadata Interchange (XMI)."
[November 07, 2001] "Building an XML-based Message Server. An Illustrative Example of an XML-based Message Server." By George Franciscus (Nexcel). From IBM developerWorks. November 2001. ['This article shows how to code a lightweight, transport-protocol-agnostic, XML-based message server that not only allows clients to place and pick up messages on queues, but also transform messages using XSL. Written in the Java language, eight code listings take you from opening a client connection to invoking XSL transformations on messages.'] "Using messaging, the purchaser sends the supplier a message containing order information. Since the supplier may not be online when the purchaser sends the message, the message is sent to a repository that stores the message until the supplier is ready to ask for it. Upon picking up and processing the order, the supplier sends a confirmation message to the purchaser by depositing a message in the repository. The purchaser checks the repository from time to time to get a confirmation message from the supplier. The software that manages this repository is the message server. If you are thinking that this sounds an awful lot like a message broker such as IBM's MQSeries, you're right. The topic of this article is to build a simplistic XML-based message server that mimics some of the functionality found in MQSeries... In message servers that are not XML based, there is no practical limitation to the message size. However, the client and the server must agree on the size of the header section and the size of the fields it contains. XML can eliminate this inflexibility. When the message is built as XML, an XML parser can be used to extract the content of message fields without regard to the size of the content. Therefore, there are no programming changes required if the message ID must be lengthened to ensure uniqueness. It also means that new fields can easily be added to the header without impacting messages already stored in the queue. This message server supports an XML payload. An XML format can easily support payload transformations by allowing the client to request XSL transformations. Clients can now request a subset of the payload to minimize download times, or perhaps retrieve the data sorted. The server can expand its collection of transformation rules by adding additional XSL programs. In our server, the client is required to provide the XSL file name. Adding a new transformation rule is as easy as dropping an XSL program into a directory... This message server is lightweight and it satisfies the requirement of running on any old box you have laying around the office. It can do this because it doesn't need to implement the server on top of a transport protocol such as HTTP or SMTP. You don't need a Web server or servlet engine. All you need is a JVM and an XML parser that supports XSL. We needed to implement a simple transport protocol to address issues that are usually addressed with HTTP or some other transport protocol. The client needed to know what to send and what it would receive. If we wanted to augment the set of commands, we would need to make some code changes. Fortunately, SOAP (Simple Object Application Protocol) presents us with an alternative. If we are willing to implement on a transport protocol such as HTTP or SMTP we can make our lives a whole lot easier. The payback is that we are now able to use a popular XML-based protocol that enables us to easily extend the set of commands without using the Java Reflection API. SOAP deals with the format for the messaging infrastructure and HTTP deals with the transport needs. With message formatting and transport needs dealt with, the only thing we have to worry about is the payload..." Code for this article is also available.
[November 07, 2001] "Microsoft Combines Servers Into Supplier Enablement Package." By Tom Sullivan. In InfoWorld November 06, 2001. "Looking to simplify supply chains, Microsoft on Tuesday pulled three of its server-side products together and branded the newly formed trio the Microsoft Solution for Supplier Enablement. Consisting of Microsoft's SQL Server, Commerce Server, and BizTalk Server, the solution can either be installed inside the firewall or subscribed to via a host. It is designed to help companies connect their partners into the supply chain and more effectively manage the process... As the database anchor, SQL Server contributes native XML support, a data store, and an OLAP (online analytical processing) engine. SQL Server's built-in BI (business intelligence) functions also enable customers and partners to ask BI-type questions of the overall supply chain system... Commerce Server brings XML-based catalog, order processing, Web site, and personalization capabilities. BizTalk, meanwhile, handles XML delivery, business processes, as well as mapping and transformation. An included BizTalk Accelerator for Suppliers acts as a supplier interface, with intelligent adapters for a variety of XML standards, and provides remote shopping capabilities. Furthermore, BizTalk's integration functionality enables the system to get at data in other systems, such as ERP (enterprise resource planning) and CRM (customer relationship management) applications. Each of the included servers is a full version and can be used for other tasks as well. For instance, companies could double SQL Server as a database for other applications. The overall solution is more than a triptych of servers, however, and includes interfaces for trading partner management, order management, and catalog publishing. Microsoft is expecting customers to use this for multichannel selling, including business-to-business marketplaces, procurement systems, and direct Web sales..." See the MS anouncement: "Suppliers of All Sizes Reduce Operational Costs and Increase Revenue Using Microsoft Solution for Supplier Enablement. New Solution Offers Suppliers Greater Opportunity in Business-to-Business Selling." Excerpt: "Microsoft Corp. today announced the availability of the Microsoft Solution for Supplier Enablement, an integrated technology solution that provides powerful business results by enabling suppliers to connect to any customer's e-procurement system or marketplace in a cost-effective way. Suppliers of all sizes will benefit from reduced operational costs while gaining access to new revenue opportunities. Further, this new solution is built to maximize suppliers' existing IT investments, reducing integration work and allowing suppliers to achieve faster return on investment. For many companies, integrating new systems with existing applications and infrastructure requires months and can run well into seven figures. The Microsoft Solution for Supplier Enablement is designed to lower the cost of integration with existing technologies such as ERP, CRM and catalog management systems. Combining the strengths of the Microsoft .NET Enterprise Servers, including BizTalk Server 2000, Commerce Server 2000, SQL Server 2000 and BizTalk Accelerator for Suppliers, with public Internet standards such as XML, the Microsoft Solution for Supplier Enablement offers robust capabilities to solve the integration challenges suppliers face in today's business-to-business environment. In addition, the solution comes with comprehensive architectural guidance and complete solution support, so the implementation effort is significantly reduced... The Microsoft Commerce Server 2000 provides rich catalog features, including custom pricing and an XML-based catalog schema..."
[November 07, 2001] "Object Role Modeling: An Overview." By Terry Halpin (Microsoft Corporation). November 2001. 22 pages. "This paper provides an overview of Object Role Modeling (ORM), a fact-oriented method for performing information analysis at the conceptual level. The version of ORM discussed here is supported in Microsoft Visio for Enterprise Architects, part of Visual Studio .NET Enterprise Architect... It is well recognized that the quality of a database application depends critically on its design. To help ensure correctness, clarity, adaptability and productivity, information systems are best specified first at the conceptual level, using concepts and language that people can readily understand. The conceptual design may include data, process and behavioral perspectives, and the actual database management system (DBMS) used to implement the design might be based on one of many logical data models (relational, hierarchic, network, object-oriented, and so on). This overview focuses on the data perspective, and assumes the design is to be implemented in a relational database system. Designing a database involves building a formal model of the application area or universe of discourse (UoD). To do this properly requires a good understanding of the UoD and a means of specifying this understanding in a clear, unambiguous way. Object Role Modeling (ORM) simplifies the design process by using natural language, as well as intuitive diagrams which can be populated with examples, and by examining the information in terms of simple or elementary facts. By expressing the model in terms of natural concepts, like objects and roles , it provides a conceptual approach to modeling..." See also the ORM web site, which notes Microsoft's plans "to release Visio for Enterprise Architects in late 2001 as part of Visual Studio .NET Enterprise Architect . Visio for Enterprise Architects includes Visio Professional 2002 as well as enhanced versions of the database and software modeling solutions formerly in Visio Enterprise 2000: its database modeling solution provides deep support for ORM and logical/physical database modeling. A beta version of Visio for Enterprise Architects is currently included in Visual Studio .NET Enterprise beta 2." On conceptual modeling, see "Conceptual Modeling and Markup Languages."
[November 07, 2001] "Database Modeling in Visual Studio .NET." [Visio-Based Database Modeling in Visual Studio .NET Enterprise: Architect: Part 1.] By Terry Halpin (Microsoft Corporation). November 2001. ['This three-part series on the new Visio tool for database modeling explains how to create a basic ORM source model, how to use the verbalizer, how to add set-comparison constraints, and much more.'] "The database modeling solution within Microsoft Visio Enterprise 2000 provided basic support for conceptual information analysis using Object-Role Modeling (ORM), as well as logical database modeling using relational, IDEF1X, crowsfoot and object-relational notations. ORM schemas could be forward engineered to logical database schemas, from which physical database schemas could be generated for a variety of database management systems (DBMSs). Physical databases could have their structures reverse engineered to logical database schemas or to ORM schemas. The recently released Microsoft Visio 2002 products include Standard and Professional editions only. The Professional edition subsumes the formerly separate Technical edition, but does not include Enterprise. Although Visio 2002 Professional does include an ORM stencil, this is for drawing only -- its ORM diagrams cannot be mapped to logical database schemas and cannot be obtained by reverse engineering from a physical database. Visio 2002 Professional includes a database modeling solution for defining new logical database schemas or reverse engineering them from existing databases, but forward engineering to physical database schemas is not provided. For some time, Microsoft has supported database design and program code design (using UML) in its Visual Studio product range. After acquiring Visio Corporation, Microsoft had two separate products (Visio Enterprise and Visual Studio) that overlapped significantly in functionality, with each supporting database design and UML. As a first step towards unifying these product offerings, the deep modeling solutions formerly within Visio Enterprise have been enhanced and moved into a new Microsoft product known as Visio for Enterprise Architects (VEA), included in Microsoft Visual Studio .NET Enterprise Architect. These Visio-based modeling solutions are included in beta 2 of Visual Studio. NET Enterprise, with the final release to follow later. The deep ORM solution in VEA is completely different from the simple ORM drawing stencil in Visio Professional, and cannot translate between them. However, the database modeling solution in VEA can import logical database models from Visio Professional, and then forward engineer them to DDL scripts or physical database schemas..."
[November 07, 2001] "ISO15022 XML Design Rules. Technical Specification." By Kris Ketels, for ISO/TC68/SC4/WG10. Document Version 2.3a. Document Issue Date October 26, 2001. Extent: 49 pages. From the Introduction: "XML is a technical standard defined by W3C (the World Wide Web Consortium) and leaves a lot of freedom for the exact way it is used in a particular application. Therefore, merely stating that XML is used is not sufficient, one must also explain HOW it will be used. The use of XML is part of the overall approach for the development. This development focuses on the correct definition of a business standard using modelling techniques . The resulting business standard is captured in UML (Unified Modelling Language) and is stored in an electronic repository, the 'ISO Repository'. Business messages are defined in UML class diagrams and XML is then used as a physical representation (i.e., the syntax) of the defined business messages. A set of XML design rules, called ISO XML, define in a very detailed and strict way how this physical XML representation is derived from the business message in the UML class diagram. This document explains these XML design rules. This document does not explain how a message should be created in UML. It explains, once a message is created in UML, how it will be mapped into XML... General mapping rules. Mapping rules from UML to ISO XML are governed by the following design choices: (1) ISO XML representation to be as structured as possible: [1] Business information is expressed as XML elements/values; [2] Metadata information is expressed as XML attributes. XML attributes are not to be conveyed 'on the wire' in the XML instance, unless required to remove ambiguity. (2) The current work is based on W3C's Recommendation of May, 2001. (3) The names used in ISO XML are the XML names or, when absent, the UML names. (4) ISO XML elements are derived from the UML representation of a business message. They can only be derived from UML-classes, UML-roles or UML-attributes. (5) Each ISO XML element must be traceable to the corresponding UML model element. (6) Currently ISO XML only runtime Schemas are generated. Runtime Schemas only contains information required to validate XML instances. No documentation nore implementation information (e.g.,elementID, version, etc.) is mentioned..." The document was posted to the UBL-Comment list ['[email protected]'] by Kris Ketels, 2001-11-07. [Kris wrote: 'One of the missions of SWIFT as a standardisation body is to drive towards a single standardisation solution within the financial industry. We believe a convergence between the major initiatives that are currently going on (ISO, UN/CEFACT/eBTWG and UBL) is an important and even indispensable step to achieve this. We would therefore like to submit our contribution -- under the umbrella of ISO -- to this [UBL] group. The document, ISO15022 XML design rules, is a draft submission to ISO for approval. It describes how XML messages can be instantiated (M0) from a given UML model (M1), and also its corresponding XML Schema (M1).'] See: (1) Minutes of the OASIS UBL TC Meeting, 2001.10.29-11.01; (2) Reports of UBL TC Subcommittees [Accepted by the UBL TC 1 November 2001]; (3) "Universal Business Language (UBL)."
[November 05, 2001] "LINGUIST List Language Database." Posting from Anthony Aristar (Department of English, Wayne State University). The LINGUIST Public Lookup Pages allows one to look up a language, family, or language code; to show all ancient languages in the LINGUIST Database; and to show all constructed languages in the LINGUIST Database. "We have now finished putting together the initial version of the language database facility we talked about in Santa Barbara. This system includes all of Ethnologue (which SIL has generously allowed us to use) as well as a supplementary database of ancient and constructed languages, which we ourselves have put together, and which includes brief descriptions and unique codes. The intent is to allow us to precisely categorize by language any data we encounter. The language search facility based on this database allows four kinds of searches: (1) Search by language name; this searches a database of around 48,000 alternate names, and does a fuzzy match on your input; (2) Search by Ethnologue or LINGUIST code; (3) Search by family of subgroup name; this will return a list of languages if the node dominates language names, and a clickable tree if it doesn't; (4) Generate a tree of any of the language families in the database. These last two [kinds of searches] will only work properly if you have Java enabled on your machine. We've also set up pages that will give quick listings of all the ancient and constructed languages in the database. Some caveats apply [minor changes to Ethnologue system; system can be slow as of 2001-11-05.] Background: see "Language Identifiers in the Markup Context," and in particular, "E-MELD Language Codes Workgroup."
[November 05, 2001] "XML Internationalization FAQ." From Opentag.com. Updated October 29, 2001 or later. "You will find here answers to some of the most frequently asked questions about XML internationalization and localization, including XSL, CSS, and other XML-related technologies..." The document contains some thirty-seven (37) questions and answers on matters of Character Representation, Encoding, Language Identification, Presentation and Rendering, and Localization. Sample questions on Language Identification: (1) What is the xml:lang attribute? (2) Do I need to declare the xml:lang attribute? (3) What are the values for the xml:lang attribute? (4) In XHTML should I use lang or xml:lang? (5) What about multilingual documents? (6) Can I use Unicode Language Tags in XML? (7) How do I use the lang() function in XPath? (8) How do I use the lang() selector in CSS? Comments to [email protected]. See the Q/A snapshot from 2001-10-29. See also (1) "XML and Unicode"; (2) "Language Identifiers in the Markup Context."
[November 05, 2001] "Professional XML Web Services.. Overview of the book by Patrick Cauldwell, Rajesh Chawla, Vivek Chopra, Gary Damschen, Chris Dix, Tony Hong, Francis Norton, Uche Ogbuji, Glenn Olander, Mark A Richman, Kristy Saunders, and Zoran Zaev. Published by Wrox Press, September 2001. ISBN: 1861005091. 1000 pages. "Web Services are self-describing, modular applications. The Web Services architecture can be thought of as a wrapper for the application code. This wrapper provides standardized means of: describing the Web Service and what it does; publishing it to a registry, so that it can easily be located; and exposing an interface, so that the service can be invoked -- all in a machine-readable format. What is particularly compelling about Web Services is that any client that understands XML, regardless of platform, language and object model, can access them. This book provides a snapshot of the current state of these rapidly evolving technologies, beginning by detailing the main protocols that underpin the Web Services model (SOAP, WSDL, and UDDI), and then putting this theory to practical use in a wide array of popular toolkits, platforms, and development environments. The technologies presented in this book provide the foundations of Web Services computing, which is set to revolutionize Distributed Computing, as we know it. The book covers: (1) The architecture of Web Services -- past, present, and future; (2) Detailed explanation of SOAP 1.1; (3) An overview of SOAP 1.2 and XML Protocol; (4) IBM's Web Services Toolkit and Microsoft's SOAP toolkit 2.0; (5) Other SOAP implementations in Perl, C++, and PHP; (6) Java Web Services with Apache SOAP; (7) WSDL 1.1, UDDI 1.0, and 2.0; (8) Creating and deploying Web Services using .Net; (9) Building Web Services using Python; (10) Applying security at both transport and application levels." See the online Table of Contents and the sample chapter on "SOAP Basics." See "Simple Object Access Protocol (SOAP)." [cache]
[November 05, 2001] "Core Components : Delivering on the ebXML Promise." By Alan Kotok (Data Interchange Standards Association - DISA). Published by MightyWords, Inc. October 02, 2001. 71 pages. ISBN 0-7173-1939-3. [Excerpt from a briefing which] "discusses Electronic Business XML or ebXML, a new global standard for conducting e-business, and focuses on the part of ebXML that deals with business semantics, called core components. It provides an overview of this innovative technology, to help business people begin planning for its adoption and benefits. Once implemented in business software and services, ebXML will make it possible for any company of any size in any industry to do e-business with any other company in any other industry, anywhere in the world. To achieve this ambitious goal, ebXML sets out to do what no other business standard has tried to do, namely develop a way for companies to talk business systematically and accurately across industry or linguistic boundaries. Core components are the basic data items that business documents can use and reuse from one document to the next. Many common business documents have the same basic structure and underlying data content. However, different industries use different terms for the same ideas, and for businesses to communicate with each other, they need a way of breaking through these semantic barriers, without asking companies to change their long-standing business practices. This briefing describes how core components fit into the overall ebXML architecture, discusses their derivation and use in business documents, and provides a real-life example showing the potential for generating new business opportunities... The work on core components includes not only the identification of these interchangeable parts in business documents, but the systematic and consistent definition of the business context - the substance of industry business practices and terminology - that give the components their precise meaning in business documents. The systematic combination of core components with context allows for the automatic assembly of e-business documents exchanged with trading partners... EbXML is still a work in progess. The development phase ended in May 2001,ethe core components team having completed its basic methodology and proposed a starter set of core components.. Since then, the two leading e-business standards organizations have joined to continue the work. Industry organizations and individual companies should consider taking part in this important exercise, since it will likely determine the language of e-business for many years to come." An online document in PDF format supplies a longer extract from the briefing. See: "Electronic Business XML Initiative (ebXML)." [cache]
[November 05, 2001] "Professional ebXML Foundations." Overview of the book by Pim Van Der Eijk, Duane Nickull, J. J. Dubray, Colleen Evans, David Chappell, Betty Harvey, Marcel Noordzij, Jan Vegt, Tim McGrath, Vivek Chopra, and Bruce Peat. [To be] published by Wrox Press, November 2001. ISBN: 1861005903. 600 pages. "ebXML is a framework of specifications that enables businesses to collaborate electronically using XML-based technologies. The framework comprises modular components, addressing each of the key functions required to implement a complete e-business solution. These functions include: defining business processes and associated roles and activities, creating and publishing business profiles in a registry, storing business information in a repository, searching for other business partners, agreeing trading protocols, creating business documents, and sending them via secure and reliable messaging systems. ebXML is open, interoperable, and affordable. Maintained by industry consortia (OASIS and UN/CEFACT) and based on XML, it allows companies to benefit from electronic trading via a global network regardless of size or geographical location, both within and across industries. The book features: (1) An overview of electronic business and the interrelation of the ebXML framework components; (2) Modeling business processes and documents with ebXML BPSS, UMM, and XML Schemas; (3) Defining trading profiles and setting up collaborative agreements with ebXML CPP/CPA; (4) Attracting and discovering business partners using ebXML Registry/Repository or UDDI; (5) Creating business message payloads using ebXML Core Components, XML, and non-XML content; (6) Transporting messages using ebXML Messaging Services, SOAP, JMS, and JAXM; (7) Implementing secure, flexible ebXML solutions; (8) Real world case studies. See the online Table of Contents and the description from Amazon. See: "Electronic Business XML Initiative (ebXML)."
[November 05, 2001] "ebXML and SMEs. How ebXML measures up for small to medium enterprises." By Michael C. Rawlins (Rawlins EC Consulting). November 2, 2001. [The latest article in a series on "ebXML - A Critical Analysis". This series presents an analysis of the products of ebXML, its success in achieving its stated objectives, and an assessment of the long-term impact of the initiative.] "From several studies as well as professional experience from those involved in EDI implementations for SMEs, there are several reasons that SMEs find e-business, particularly in the form of EDI, difficult. The cited reasons range from too expensive and too costly, to standards being too hard to use, to poor application integration. Despite the wide variety of reasons, the sources of the problems basically break down into two major areas: application support and application integration. Application support for e-business is a fairly wide area because it is strongly affected by the particular business processes that larger partners want to implement electronically. One example is a suppliers business application being able to create the data for a shipment notice electronically to a customer before the goods are shipped, and print a bar code label for the package. Another is the ability to maintain a cross-reference of customer item numbers to internal item numbers. The technical infrastructure side of ebXML deals with lower level middleware and does not address this type of application support. So, no help is provided to SMEs at this level. Another aspect of ebXML and SME problems is the definition of the business processes in which the SMEs participate. ebXML did not define the business processes, but only aspects of the methodology for defining them. I will discuss this in a later article, but it suffices for the purposes of this article that ebXML did nothing immediate for SMEs in this area either. So, ebXML provided no help to SMEs in application support for e-business. The other area is in application integration, i.e., interfacing or integrating the e-business middleware with the business application. Perhaps the best way to determine what ebXML did in this area is to examine the functions and architecture of current EDI and future ebXML based systems, and see if there is any improvement... The short answer is that it made it easier and more efficient for large enterprises to conduct business electronically. For example, an SME dealing with six large customers gains no appreciable benefits by being able to electronically configure its system for trading with them. However, a large enterprise with hundreds or even thousands of suppliers sees significant benefits. There are also a few very nice pieces of work in specific areas in ebXML. However, as good as they may be, the market may not be very interested in them in the long run. My next article will review the likely market impact of the ebXML infrastructure specifications." See: "Electronic Business XML Initiative (ebXML)."
[November 02, 2001] "XML-based Method and Tool for Handling Variant Requirements in Domain Models." By Stan Jarzabek and Hongyu Zhang (Department of Computer Science, School of Computing, National University of Singapore). In Proceedings Fifth IEEE International Symposium on Requirements Engineering (RE 2001), pages 166-173 (with 17 references). Toronto, Ontario, Canada, 27-31 August 2001. Published by IEEE Computer Society. "A domain model describes common and variant requirements for a system family. UML notations used in requirements analysis and software modeling can be extended with variation points to cater for variant requirements. However, UML models for a large single system are already complicated enough. With variants UML domain models soon become too complicated to be useful. The main reasons are the explosion of possible variant combinations, complex dependencies among variants and inability to trace variants from a domain model down to the requirements for a specific system, member of a family. We believe that the above mentioned problems cannot be solved at the domain model description level alone. We propose a novel solution based on a tool that interprets and manipulates domain models to provide analysts with customized, simple domain views. We describe a variant configuration language that allows us to instrument domain models with variation points and record variant dependencies. An interpreter of this language produces customized views of a domain model, helping analysts understand and reuse software models. We describe the concept of our approach and its simple implementation based on XML and XMI technologies... Recently, we designed a variant configuration language called XVCL which implements essential frame concepts in XML. We designed XVCL to address variants in a domain model. XML-based Variant Configuration Language (XVCL for short) is a simple markup language based on XML conventions. We use XVCL to organize domain knowledge and to instrument domain defaults with variants. We use term x-frame to refer to domain defaults instrumented with variants marked as XVCL commands. An x-frame can be processed by the XVCL interpreter (i.e., the XML implementation of the FVC tool). In this paper, we describe how we applied XVCL to handle variants in UML domain models represented as XMI documents. We chose XMI, as modeling tools such as Rational Rose adopt XMI standards as a common, exchangeable representation for software models. In this solution, an FVC is an XVCL interpreter implemented on top of JAXP, an open framework for parsing XML documents. The reader should notice that the very concept of our approach to supporting domain modeling is not limited to XML, JAXP or XMI... UML notations may be extended with 'variation points' to cater for variant requirements. A generic software model (analysis component) is customized by attaching one or several variants to its variation points. In analogical domain analysis, one attempts to build abstract models for problems that recur in different application domains. Abstract models are then instantiated for reuse by injecting domain-specific variants into them. Domain Specific Languages (DSL) and application generation techniques provide a powerful method to deal with variants in system families. A DSL allows one to specify variants in application domain terms . Variant specifications in DSL guide generation actions that produce a custom program that meets required variants. In contrast to the above approaches, the method described in this paper is domain-independent. We concentrate on a problem of how variants affect domain views expressed in commonly used notations such as UML. Unlike DSLs, our variant specification language XVCL carries no semantics of a domain. Our tool uses simple adaptation and composition rules, rather than generation techniques, to produce customized domain model views from generic model components... As the volume of information grows, domain models become notoriously difficult to understand. The main problems are in explosion of possible variant combinations, complex dependencies among variants and inability to trace variants from a domain model down to requirement specifications for a specific member of a system family. In this paper, we proposed a new approach to handle variants in a domain model. The main idea of our solution is to define default domain model views and provide a semi-automatic way to modify and extend these defaults. We proposed a flexible variant configuration component (FVC for short) as an integral part of a domain model. The role of FVC is to help analysts in interpretation and manipulation of domain variants. In the paper, we described a simple implementation of the above concepts using XML and XMI technologies. The XVCL and XML-based tool for model customization were inspired by Bassett's frames..." See related publications from Stan Jarzabek. In particular: Stan Jarzabek, Wai Chun Ong, and Hongyu Zhang, "Handling Variant Requirements in Domain Modeling," Proceedings of the Thirteenth International Conference on Software Engineering and Knowledge Engineering (SEKE '01), Knowledge System Institute, June 2001, Buenos Aires, Argentina, pages 61-68, accepted for a special issue of Journal of Software and Systems. [source]
- [November 02, 2001] " The WS-Inspection and UDDI Relationship." By William A. Nagy (IBM) and Keith Ballinger (Microsoft). From IBM DeveloperWorks. November 2001. ['The Web Services Inspection Language (WS-Inspection) and the Universal, Description, Discovery, and Integration (UDDI) specification both address issues related to Web service discovery. Even so, they were designed with different goals in mind, and thus exhibit different characteristics which must be evaluated before an application of the technology can be made. This paper describes the Web services discovery space in terms of an analogy to personal information discovery and illustrates how the two specifications may be used jointly to address a variety of requirements.'] "In addition to the patterns which they support, discovery mechanisms may be characterized according to two other attributes: by the choice of the point of dissemination of information, and by the costs associated with the discovery process. During discovery, information may be extracted either directly from the source/originator of the information or from a third-party. Retrieving information directly from the source increases the likelihood of the information being accurate, while fetching it indirectly gives the opportunity to utilize additional services provided by the third-parties and doesn't require that the original source always be available or easily locatable. The costs associated with the discovery techniques also vary. Certain environments have a much higher cost associated with storing and presenting the information than do others. From the attributes listed above, a taxonomy can be constructed through which discovery techniques and their supporting mechanisms can be compared and contrasted. To summarize, discovery mechanisms can be categorized according to the following criteria: (1) Which discovery patterns are supported? Does the mechanism support only focused discovery patterns, only unfocused discovery patterns, or combination of both? If it is a combination, to what extent is each category of patterns supported? (2) Where is the point of dissemination? Is the information generally discovered directly from the source/originator or through a third-party? (3) What is the overhead associated with the discovery mechanism? Is there a basic cost associated with storing and presenting the information for discovery, and if so, how significant is it? Note: This is the cost to the information/infrastructure provider for supporting the discovery mechanism; the differences in the cost of consuming the information can be assumed to be negligible... Here we describe several mechanisms used for personal information discovery, and classify them according to the above taxonomy. We apply the same taxonomy to the Web services space, and describe where the UDDI and WS-Inspection mechanisms fit..." See: "IBM and Microsoft Issue Specification and Software for Web Services Inspection Language."
[November 02, 2001] "An Overview of the Web Services Inspection Language. Distributed Web Service Discovery Using WS-Inspection Documents." By Peter Brittenham (Web Services Architect, IBM Corporation). From IBM DeveloperWorks. November 2001. ['Service discovery defines a process for locating service providers and retrieving service description documents, and is a key component of the overall Web services model. Service discovery is a very broad concept, which means that it is unlikely to have one solution that addresses all of its requirements. The Universal Description, Discovery and Integration (UDDI) specification addresses a subset of the overall requirements by using a centralized service discovery model. This article will provide an overview of the Web Services Inspection Language (WS-Inspection), which is another related service discovery mechanism, but addresses a different subset of requirements using a distributed usage model. The WS-Inspection specification is designed around an XML-based model for building an aggregation of references to existing Web service descriptions, which are exposed using standard Web server technology.'] "The Web services architecture is based upon the interactions between three primary roles: service provider, service registry, and service requestor. These roles interact using publish, find, and bind operations. The service provider is the business that provides access to the Web service and publishes the service description in a service registry. The service requestor finds the service description in a service registry and uses the information in the description to bind to a service... The WS-Inspection specification does not define a service description language. WS-Inspection documents provide a method for aggregating different types of service descriptions. Within a WS-Inspection document, a single service can have more than one reference to a service description. For example, a single Web service might be described using both a WSDL file and within a UDDI registry. References to these two service descriptions should be put into a WS-Inspection document. If multiple references are available, it is beneficial to put all of them in the WS-Inspection document so that the document consumer can select the type of service description that they are capable of understanding and want to use..." See also (1) the Web Services Inspection Language (WS-Inspection) 1.0 Specification, and (2) the announcement: "Microsoft and IBM Unveil New XML Web Services Specification. Web Services Inspection Specification Defines an Additional Method for Discovering XML Web Services." Full references: see "IBM and Microsoft Issue Specification and Software for Web Services Inspection Language." [PDF, cache]
[November 01, 2001] "How to Develop Stylesheets for XML to XSL-FO Transformation." From Antenna House. 2001-10-24. "The 63 page tutorial developed by Antenna House, Inc. for customers of XSL Formatter is [here] made public. This is not only useful for better understanding of XSL and XSLT but also this may be used as a practical sample of XML and XSLT stylesheet. The source file is an XML document based on "sampledoc.dtd"; the source XML file; the XSLT Stylesheet to transform the source XML file to XSL formatting objects tree. PDF versions are available. They is formatted from the source XML and XSLT Stylesheet by XSL Formatter and printed to PDF file using Acrobat..." See the reference page and complete set of source file including graphics files. W3C note: "it conforms only to the XSL 1.0 CR, but the differences between CR and Rec are minor." For related resources, see "Extensible Stylesheet Language (XSL/XSLT)." [cache]
[November 01, 2001] "Introduction to the Darwin Information Typing Architecture: Toward Portable Technical Information." By Don R. Day, Michael Priestley, and David A. Schell (IBM Corporation). From IBM developerWorks. Updated October 2001. Original publication: March 2001. ['The Darwin Information Typing Architecture (DITA) is an XML-based architecture for authoring, producing, and delivering technical information. This article introduces the architecture, which sets forth a set of design principles for creating information-typed modules at a topic level, and for using that content in delivery modes such as online help and product support portals on the Web. This article serves as a roadmap to the Darwin Information Typing Architecture: what it is and how it applies to technical documentation. The article links to representative source code.'] "The XML-based Darwin Information Typing Architecture (DITA) is an end-to-end architecture for creating and delivering modular technical information. The architecture consists of a set of design principles for creating information-typed topic modules, and for using that content in various ways, such as online help and product support portals on the Web. At the heart, the DITA is an XML document type definition (DTD) that expresses many of these design principles. The architecture, however, is the defining part of this proposal for technical information; the DTD, or any schema based on it, is just an instantiation of the design principles of the architecture..." Note from Don Day, Lead DITA Architect: "After a round of bug fixes, evaluation of suggestions, and use in prototype projects, the DITA DTDs and tools are now available in a new update package on developerWorks. This version includes more examples of specialization and of topic reuse within example build frameworks. The DTD updates extend what can be done with semantics and domain-specific vocabularies built on a standard extensibility mechanism. For an introductory approach, follow the Resources link in any of the updated DITA articles. The article updates are relatively minor; the tools package is the major part of this update release. Or go directly to the package. Unzip the package to any handy directory; its contents will unpack within a "dita" top-level directory that will be created for you. Check out the README file in that directory to see what is in the package and what has been changed since the first release." See also: (1) the DITA FAQ set; (2) "Specialization in the Darwin Information Typing Architecture," a companion article which outlines how to implement DITA; (3) the news item of March 16, 2001, "IBM's Darwin Information Typing Architecture (DITA)." [Cache article, PDF; package]
[November 01, 2001] "Introduction to Native XML Databases." By Kimbro Staken. From XML.com. October 31, 2001. ['The choice of storage system for XML-based applications is a crucial one. In his article, Staken explains the strengths and weaknesses of native XML stores as opposed to conventional databases. Staken's "Introduction to Native XML Databases" is the first in a three-part series that will also take in the dbXML project and the XML:DB API.'] "The term native XML database (NXD) is deceiving in many ways. In fact many so-called NXDs aren't really standalone databases at all, and don't really store the XML in true native form (i.e., text). To get a better idea of what a NXD really is, let's take a look at the NXD definition offered by the XML:DB Initiative, of which the author is a participant. A native XML database... (1) Defines a (logical) model for an XML document -- as opposed to the data in that document -- and stores and retrieves documents according to that model. At a minimum, the model must include elements, attributes, PCDATA, and document order. Examples of such models are the XPath data model, the XML Infoset, and the models implied by the DOM and the events in SAX 1.0. (2) Has an XML document as its fundamental unit of (logical) storage, just as a relational database has a row in a table as its fundamental unit of (logical) storage. (3) Is not required to have any particular underlying physical storage model. For example, it can be built on a relational, hierarchical, or object-oriented database, or use a proprietary storage format such as indexed, compressed files... An NXD can store any type of XML data, but probably isn't the best tool to use for something like an accounting system where the data is very well-defined and rigid. Some potential application areas include Corporate information portals, Catalog data, Manufacturing parts databases, Medical information storage, Document management systems, B2B transaction logs, and Personalization databases... NXDs aren't a panacea and they're definitely not intended to replace existing database systems. They're simply another tool for the XML developers' tool chest, and when applied in the right circumstances they can yield significant benefits. If you have lots of XML data to store, then an NXD is worth a look, and might just prove to be the right tool for the job..." See: (1) "XML and Databases," by Ronald Bourret; (2) local reference page "XML and Databases."
[November 01, 2001] "Building XML-RPC Clients in C." By Joe Johnston. From XML.com. October 31, 2001. ['Much XML development has traditionally used the Java programming language. However there are scenarious where, for reasons of speed, portability or history, C is the language of choice. Joe Johnston shows how to take advantage of web services from C programs. Special care is taken to bring programmers with rusty C-hacking skills up to speed.'] "XML-RPC is a useful protocol for building cross-platform, client-server applications. Often XML-RPC is demonstrated with high-level interpreted languages like Perl and Python. In this article, Eric Kidd's XML-RPC C library is used to build a simple, yet powerful debugging client. Special care is taken to bring programmers with rusty C-hacking skills up to speed. XML-RPC is a wire protocol that describes an XML serialization format that clients and servers use to pass remote procedure calls to each other. There are two features that make this protocol worth knowing. The first is that the details of parsing the XML are hidden from the user. The second is that clients and servers don't need to be written in the same language... Many articles written about XML-RPC use Java, Perl, Python, or PHP to demonstrate building Web Services. However, real life programming requirements often mitigate against the programmer's first choice of implementation language, perhaps because access to a resource whose only API is a C library is required. In this case, building an XML-RPC server to this resource opens it up to any client that supports XML-RPC..." See: (1) Programming Web Services with XML-RPC, by Simon St.Laurent, Joe Johnston, and Edd Dumbill; with Foreword by Dave Winer (O'Reilly); (2) Joe Johnston's article "Binary Data to Go: Using XML-RPC to Serve Up Charts on the Fly," which shows how XML-RPC and Web services can create simple charts for client programs; (3) reference page "XML-RPC."
[November 01, 2001] "Browser Lockouts and Monopoly Power." By Kendall Grant Clark. From XML.com. October 31, 2001. "Last week, Microsoft sparked a storm of protest by blocking certain web browsers from its MSN.com portal. Perhaps the most worrying aspect of this episode was the bogus claim that these browsers, including Mozilla and Opera, did not support the latest W3C standards. In the XML-Deviant column this week, Kendall Clark surveys the reaction to this incident on XML-DEV, and the implications for the Microsoft antitrust negotiations..."
[November 01, 2001] "Extending Schemas." Edited by Paul Kiel (HR-XML). Contributors: Members of the HR-XML Technical Steering Committee. Working Draft 2001-09-11, Version 1.0. "HR-XML Consortium specifications are meant to model specific business practices. Recognizing that it cannot satisfy the needs of all implementers all the time, the need for a standard way to extend schemas becomes clear. This document is aimed to provide guidance regarding the extension of XML Schemas so that trading partners can exchange information in the real world as well as experiment with new data that could be incorporated into a future specification... Given that extension is a reality, how can we accommodate extensions without undermining the principle of open standards? This document is meant to provide guidance on the best practice for extending schemas. Its goal is to show: (1) Official endorsement of different methods for implementation; (2) Conventions for creating extensions to encourage consistency... This document focuses on XML Schema extension methods. Where possible, references to DTD equivalent issues are included. Addressing all possible extension methods for DTDs (i.e., internal subsets) is not in scope... As discussed here, 'extending' is meant to 'add additional elements and attributes to an existing schema'. This is not to be confused with how Roger Costello uses it in the XML Schemas: Best Practices discussion; he refers to 'extending' meaning adding functionality to schema that does not currently exist... The Technical Steering Committee has approved two methods that enable extension of HR-XML schemas without undermining an open standards mission. The 'wrapper' and 'ANY' techniques are explained herein. Additionally, a 'Namespace' extension method was examined and rejected, details in Appendix C..." [Comment from Chuck Allen: "Like every other organization developing XML schemas, HR-XML is wrestling with 'standard' approaches to extending 'standards'. The editors welcome comments on the extension document; send email to Chuck Allen or Paul Kiel. See: (1) "HR-XML Consortium"; (2) Elists for lists.hr-xml.org. [source .DOC]
[November 01, 2001] "[XML Schema] Enumeration Extension." By Paul Kiel (HR-XML). 2001-10-29. 5 pages. "HR-XML Consortium work groups are increasingly grappling with a common problem regarding the use of enumerations in schemas. The traditional use of enumerations consists of a fixed number of provided values, which are determined at the time of the schema design. The problem arises when a business process is modeled with a schema that includes enumerated lists that do not cover 100% of the foreseen cases. The main question arises: how can a work group standardize enumerated values when less than 100% of the foreseeable values are known at design time? The objective of this text is to endorse a method for standardizing enumerated values without preventing extensions to cover unknown or trading partner specific values... The two most debated approaches to standardizing incomplete enumeration lists are a union of values with a string, essentially a convention, and a union of values with a string pattern, known as pattern extension... The Technical Steering Committee has determined that while the principle of separating data from metadata has significant merit, in this case, making the best use of the parser can be more important. Consequently, it endorses the Pattern Extension method of standardization of incomplete enumeration lists when most of the values are known. When only a few values are know, the Convention Method is acceptable as well as using an atomic data type such as a simple string..." Comment from Chuck Allen: "We regard this document on handling enumerations as a schema design technique with some use in certain circumstances. We're also interested in the notion of 'interfaces to taxonomies' -- being able to reference or (carry along) taxonomies that would provide data values. One of our use cases is posting job openings to job boards; each job board has a different classification system (these usually translate to drop-down lists in a web user interface). We definitely will not take on the task of try to develop standard skill and job taxonomies, but we want to be able to plug-in those in use by major job boards and by government agencies (US Dept of Labor and many other national labor boards have developed skill/job taxonomies). While our use case is specific to HR, the basic problem of referencing and using external taxonomies is not unique to our problem domain..." See: (1) "HR-XML Consortium"; (2) Elists for lists.hr-xml.org. [source .DOC]
[November 01, 2001] "[HR-XML] Payroll Benefits Contributions 1.0." Edited by Penni Kessler and Kim Bartkus. By Members of the HR-XML Payroll work group. Working Draft Version 1.0. 2001-Oct-29. "This document describes HR-XML's Payroll Benefit Contributions schema. The schema allows the capture of information used by third party administrators to manage employees benefit contributions. Many companies have defined/deferred contributions as part of their benefits packages that they offer to employees. In order to process these contributions correctly, the employees' participation information must be used to interface with the payroll system and third party administrators. This document specifies the data elements that will be necessary to process benefit contributions within a payroll and to send information to the third party administrators... The SPARK standard was forwarded to the payroll workgroup to define the benefit contributions information to be transmitted between a payroll vendor and a third party administrator. The first phase of this project was to convert the SPARK standard to XML. The payroll transmission was demonstrated during a conference using a demo XML format. This initial phase was called the Son of SPARK. [SPARK, the Society of Pension Administrator and Record Keepers, has developed an ASCII file format that has been adopted by some of the major third party administrators. Instead of having payroll vendors converting to SPARK formats and then having to convert to XML formats a short time later, we are trying to reduce the amount of programming that will need to be done.]... See also the XML Schema. References: "HR-XML Consortium" [Cache PDF and schema.]
[November 01, 2001] "The NISO Circulation Interchange Protocol (NCIP). An XML Based Standard." By Mark Needleman, John Bodfish, Tony O'Brien, James E. Rush, and Patricia Stevens. In Library Hi Tech Volume 19, Number 3 (2001), pages 223-230. ISSN: 0737-8831. "The article describes the NISO (National Information Standards Organization) Circulation Interchange Protocol (NCIP) and some of the design decisions that were made in developing it. When designing a protocol of the scale and scope of NCIP, certain decisions about what technologies to employ need to be made. Often, there are multiple competing technologies that can be employed to accomplish the same functionality, and there are both positive and negative reasons for the choice of any particular one. The article focuses specifically on the areas on which the protocol would be supported. The authors give particular emphasis to the decision to choose XML as the encoding technology for the protocol messages. One of the main design goals for NCIP was to try to strike the appropriate balance between ease of implementation and providing appropriate functionality. This functionality includes that needed to support both those application areas that the NISO committee anticipate will use the protocol in the short term and new applications that might be developed in the future." See: (1) "NISO Circulation Interchange Protocol (NCIP)"; (2) "MARC (MAchine Readable Cataloging) and SGML/XML."
[November 01, 2001] "VoiceXML Developer Series: A Tour Through VoiceXML, Part V." By Jonathan Eisenzopf. From VoiceXMLPlanet. November 01, 2001. ['In the previous edition of the VoiceXML Developer, we created a full VoiceXML application using form fields, a subdialog, and internal grammars. In this edition, we will learn more about one of the most important, but rarely covered components of a VoiceXML application, grammars.'] "Now that we've built a few applications, it's time to talk about grammars. Grammars tell the speech recognition software the combinations of words and DTMF tones that it should be listening for. Grammars intentionally limit what the ASR engine will recognize. The method of recognizing speech without the burden of grammars is called "continuous speech recognition" or CSR. IBM's Via Voice is an example of a product that uses CSR technology to allow a user to dictate text to compose an email or dictate a document. While CSR technologies have improved, they're not accurate enough to use without the user training the system to recognize their voice. Also, the success rate of recognition in noisy environments, such as over a cell phone or in a crowded shopping mall, is reduced greatly. Pre-defining the scope of words and phrases that the ASR engine should be listening for can increase the recognition rate to well over 90%, even in noisy environments. The VoiceXML 1.0 standard uses grammars to recognize spoken and DTMF input. It doesn't, however, define the grammar format. This is changing however with the release of VoiceXML 2, which defines a standard XML-based and alternate BNF notation grammar format. Still, the fact that VoiceXML relies heavily on grammars means that we must create or reuse grammars each time we want to gather input from the user. In fact, the time required to create, maintain, and tune VoiceXML grammars will likely be several magnitudes greater than the time you will take to develop the VoiceXML interfaces. Not having high-quality and complete grammars means that the user will spend too much of their time repeating themselves. A system that cannot recognize input the first time, every time, will alienate users and cause them to abandon the system altogether. Therefore, we are going to spend a bit of time talking about grammars for VoiceXML 1.0 (and now VoiceXML 2) in the coming articles so that you will be armed with the knowledge you need to create successful VoiceXML applications. The first grammar format we are going to learn is GSL, which is used by the Nuance line of products... I want to reflect on some of the things that I've learned as I've been developing new VoiceXML applications over the past year as it relates to grammars. First, grammars can be difficult to develop and time consuming to tune. And things don't stop there. You will probably need to tune the dictionary that the system is using to include alternate word pronunciations as you begin to collect data on where the ASR application is failing. It's very important that the application will be able to recognize what the user is saying most of the time. Because DTMF input is almost 100% accurate, it should be preferred over speech for things like phone and credit card numbers. However, some voice interface designers recommend that you don't mix a touch-tone input with speech input. I'd say it's better than the alternative if you are having problems recognizing number sequences. Remember, speech recognition has gotten much better, but it still takes a great deal of work and care to reach the high 90s percentile success rates that vendors often mention. Thanks again for joining us for another edition of the VoiceXML Developer. In the next edition of the VoiceXML Developer, we will continue our exploration into grammars as part of our tour of the VoiceXML 1.0 specification..." See "VoiceXML Forum."
[November 01, 2001] "Understanding Web Services." By Sebastian Holst. In The Gilbane Report Volume 9, Number 8 (October, 2001), pages 1-8. ['Many of the goals of Web Services have been around since long before the Web. Distributed object computing, object-oriented programming, and related efforts were aimed at more efficient ways to share code and content across networks (although 'content' was not an 'in' term then, the code still had to act on something). It now seems hard to imagine that those early goals could ever be achieved without at least the Internet infrastructure we have today combined with the phenomenal success of XML. Not that we have everything in place that we need, but widespread sharing of code and content is now easily conceivable and in some cases practical. The easiest way to convince yourself how important web services will be is to think about them in the context of the computing and communication. Web services will eventually be revolutionary because they will do for communica-tion between computing applications what the Web has done for communi-cation between applications and humans. While the ultimate effect of Web Services will be profound, there will not be an overnight revolution. As you will see in this month's article by Sebastian Holst there are still some barriers to widespread adoption. At the same time, you need to understand the impact Web Services will have, and can have, on your IT strategies. Sebastian's article will help you understand enough about Web Services to start planning.'] "Web services are most likely going to be the next next big thing, and in some (developer) circles already are. Of course, there are very few things that are less appealing in today's climate of economic and political uncertainty than another next big thing. Databases, object-orientation, the Internet, and their ilk were big because of the technical, organizational, economic and cultural discontinuities they implied. Web services promise to have this kind of impact. Will they? What should you do? And when should you do it? A basic understanding of the underlying technologies, relevant standards and commercial activity to date can paint a fairly complete picture of what web services should be able to do and when. In this article we provide you with the basic information you need to determine the affect of web services on your IT strategy, including what web services are, how to think about an adoption strategy, what the barriers to adoption are, who is involved, and how web services relate to content management. Web services offer developers a distributed and loosely coupled computing environment like none before. Its agnostic architecture, potential to work cleanly across firewalls and reasonably clean fit with the full family of XML recommendations positions it to be the catalyst that connects worldwide computing as today's web has transformed interactive applications..."
[November 01, 2001] "XML Rules OK!" By March Hare. From ITdirector.com. October 31, 2001. "Web guru Tim Berners-Lee's recent pronouncement that the future web is an intelligent one, based on XML, received some further boosts from OASIS and EECMA last week. OASIS (the Organisation for the Advancement of Structured Information Standards) announced new committees to create a standard business vocabulary and develop a web services component model. EECMA (the European Electronic Component Manufacturers' Association) announced delivery of a standard trading partner agreement... The new [OASIS] committee's approach to providing the needed standards will focus on facilitating document exchange between different organisations and take existing XML business libraries as a starting point. It's easy to be cynical about standards and new committees but this one should have a good chance of delivering its proposed Universal Business Language in reasonable time. It has that chance because business definitions are something that business managers understand and should be prepared to push for. Also, many already understand the limitations of having to manually map the definitions used in their own businesses to those defined differently in others with whom they trade. Starting by synthesising the best of what's around already, which is what the new committee is proposing to do, is a pragmatic way of kicking off this important initiative. And, in the case of OASIS, business users are backed by a raft of the largest IT suppliers. Not content with that, OASIS has also started a committee to devise a Web Component Model that will define web services for interactive application access over a variety of channels: directly through a browser, indirectly through a portal or embedded into a third-party application. This will involve neutrality with respect to web platform, application format and receiving device and so will probably take significantly longer than the UBL initiative but is worthwhile nonetheless. XSL style-sheets are typically used at the moment to sort out at least the device differences and some greater standardisation would help everyone... Meanwhile, EECA in conjunction with similar bodies such as RosettaNet and EDIFICE, has now delivered a standard trading partner agreement (TPA) for XML-based eCommerce transactions. Elements of this were already around in the EDI world (as are many other useful standards for business information exchange) but the world is moving away from EDI and towards XML. The new standard TPA should prove enormously helpful in B2B eCommerce projects..." See "Universal Business Language (UBL)."
October 2001
[October 31, 2001] "XML FAQ in Amharic." Referenced in a communiqué from abass alamnehe (EthiO Systems). "The XML FAQ, by Peter Flynn, is now translated into Amharic. Amharic is the official language of Ethiopia and its writing system is Ethiopic. The FAQ is presented in different document formats including HTML, PDF, and Postscript. You need Ethiopic Unicode fonts to read the HTML (UTF-8) format and you may download a truetype Ethiopic Unicode font."
[October 31, 2001] "SGML and XML Document Grammars and Exceptions." By Pekka Kilpeläinen and Derick Wood. In Information and Computation Volume 169, Number 2 (September 2001), pages 230-251 (with 19 references). "The Standard Generalized Markup Language (SGML) and the Extensible Markup Language (XML) allow users to define document-type definitions (DTDs), which are essentially extended context-free grammars expressed in a notation that is similar to extended Backus-Naur form. The right-hand side of a production, called a content model, is both an extended and a restricted regular expression. The semantics of content models for SGML DTDs can be modified by exceptions (XML does not allow exceptions). Inclusion exceptions allow named elements to appear anywhere within the content of a content model, and exclusion exceptions preclude named elements from appearing in the content of a content model. We give precise definitions of the semantics of exceptions, and prove that they do not increase the expressive power of SGML DTDs when we restrict DTDs according to accepted SGML practice. We prove the following results: (1) Exceptions do not increase the expressive power of extended context-free grammars. (2) For each DTD with exceptions, we can obtain a structurally equivalent extended context-free grammar. (3) For each DTD with exceptions, we can construct a structurally equivalent DTD when we restrict the DTD to adhere to accepted SGML practice, (4) Exceptions are a powerful shorthand notation-eliminating them may cause exponential growth in the size of an extended context-free grammar or of a DTD." See the following bibliographic entry for a related version. On the topic, see "Use (and Non-use) of Exceptions in DTDs."
[October 31, 2001] "SGML and XML Document Grammars and Exceptions." By Pekka Kilpeläinen and Derick Wood. Technical Report HKUST-TCSC-99-10. The Hong Kong University of Science and Technology. January 1999. 35 pages. "The Standard Generalized Markup Language (SGML) and the Extensible Markup Language (XML) allow users to define document type definitions (DTDs), which are essentially extended context-free grammars expressed in a notation that is similar to extended Backus-Naur form. The right-hand side of a production, called a content model, is both an extended and a restricted regular expression. The semantics of content models for SGML DTDs can be modified by exceptions (XML DTDs do not allow exceptions). Inclusion exceptions allow named elements to appear anywhere within the content of a content model, and exclusion exceptions preclude named elements from appearing in the content of a content model. We give precise definitions of the semantics of exceptions, and prove that they do not increase the expressive power of SGML DTDs when we restrict DTDs according to accepted practice. We prove the following results: (1) Exceptions do not increase the expressive power of extended context-free grammars; (2) For each DTD with exceptions, we can obtain a structurally equivalent extended context-free grammar; (3) For each DTD with exceptions, we can construct a structurally equivalent DTD when we restrict the DTD to adhere to accepted practice; (4) Exceptions are a powerful shorthand notation -- eliminating them may cause exponential growth in the size of an extended context-free grammar or DTD." See the reference page and the Postscript version. On the topic, see "Use (and Non-use) of Exceptions in DTDs."
[October 30, 2001] "An Introduction to the Provisioning Services Technical Committee." Draft 10/16/2001 or later. "The purpose of the OASIS Provisioning Services Technical Committee (PSTC) is to define an XML-based framework for exchanging user, resource, and service provisioning information. The Technical Committee will develop an end-to-end, open, provisioning specification developed from several supporting XML specifications... This document is intended to precede the formal standards definition process within the PSTC and set the stage for the initial discussions of the committee, compiling pre-existing XRPM and ADPR efforts, into a single, high level outline. It is intentionally devoid of much of the detail already defined and discussed in supporting materials. It aims provide a high level definition of provisioning within the context of the PSTC, an overview of the proposed scope, and a suggested road map for the first committee meeting... In our context, provisioning refers to the 'preparation beforehand' of IT systems' 'materials or supplies' required to carry out some defined activity. In general, it goes further than the initial 'contingency' to the onward management lifecycle of the managed items. This could include the provisioning of purely digital services like user accounts and access privileges on systems, networks and applications. It could also include the provisioning of non-digital or 'physical' resources like the requesting of office space, cell phones and credit cards..." See: "XML-Based Provisioning Services." [.DOC source]
[October 30, 2001] "Provisioning Services Technical Committee (PSTC) FAQ Document." By Kelly Emo, John Aisien, and Gavenraj Sodhi. 2001-10-28. For the OASIS Provisioning Services TC. See the news item and main reference document.
[October 29, 2001] "Descriptive Meta Data Strategy for TEI Headers: A University of Michigan Library Case Study." By Lynn Marko and Christina Powell (University of Michigan, Ann Arbor). In OCLC Systems And Services Volume 17, Number 3 (2001), pages 117-120. ISSN: 1065-075X. "The Text Encoding Initiative (TEI) standard was developed for humanities scholars to encode textual documents for data interchange and analytic research. Its header segment contains rich tag sets, which can sufficiently support library cataloging practice with AACR2 rules and authority control. This article presents a strategy that is currently used by the Making of America (MoA) project for transferring complete MARC data created on the library's online system to the header of the TEI encoded documents. It also describes the cooperation for achieving this task between the Digital Library Production Services (DLPS) and Monograph Cataloging Division at the University of Michigan library." See with DLPS the University of Michigan Digital Library eXtension Service (DLXS) which "provides the foundation and the framework for educational and non-profit institutions to fully develop their digital library collections. The newest DLXS enhancement, XPAT, is a powerful, SGML-aware search engine, and an ultra-versatile tool for the development of digital libraries. XPAT provides excellent support for word and phrase searching, indexing of SGML elements and attributes, fast retrieval, and open systems integration... The XPAT engine is an XML/SGML-aware search engine that the University of Michigan has deployed with an extremely diverse set of digital library resources. XPAT is based on the search engine previously marketed by Open Text as OT5, and sometimes referred to as 'Pat' and 'Pat5.0.' Because of XPAT's origins and the extent to which it has been employed in University of Michigan digital library projects, we are confident about the search engine's reliability, its core functionality, and many aspects of its scalability. XPAT provides excellent support for word and phrase searching, indexing of XML and SGML elements and attributes, extremely fast retrieval, and open systems integration. For example, among the many collections that use XPAT is the 3 million page, 7Gb, 1.5 billion word Making of America collection. As part of the UM DLXS, the University of Michigan Digital Library Production Service has launched a continuous development process in which we have added a number of features to XPAT. We have introduced support for valid and well-formed XML, Linux binaries, better error handling, and improved indexing performance for XML/SGML elements, attributes, and tags." Contact John Price-Wilkin." See: (1) "Text Encoding Initiative (TEI) - XML for TEI Lite"; (2) "The Making of America II Project."
[October 29, 2001] "The Implications of TEI. [Editorial.]" By Sheau-Hwang Chang. In OCLC Systems And Services Volume 17, Number 3 (2001), pages 101-103. ISSN: 1065-075X. The author summarizes the importance of the TEI Guidelines for the Open eBook Initiative, American Memory Project, Medlane MARC XML Project, etc. Note the journal scope and TEI/EAD special issues: "OCLC Systems And Services is a refereed journal for information professionals, LIS educators and students, researchers, and archivists worldwide, devoted to the study and best use of the OCLC cataloguing system. This journal covers broad subject areas in information processing, management, and dissemination. Web metadata standards such as Dublin Core, EAD (Encoded Archival Description), and TEI (Text Encoding Initiative) are some recent features; also SGML (Standard Generalized Markup Language), and XML (eXtensible Markup Language) . In addition, OCLC system and service applications will continue to be among this journal's main topic areas. A feature column follows the global development, impact, and implementation of Dublin Core in an effort to promote effective Web resource discovery. In addition to the usual diverse spectrum of submitted articles, vol. 17, will devote two issues (no.2 and no.3) to two topics: TEI (Text Encoding Initiative) and EAD (Encoded Archival Description), respectively. Since these two encoding standards have increasingly been used to make textual documents and archival finding aids accessible on the Web, each issue will cover how-to, tools, current state, and future perspectives. Our feature column, On the Dublin Core Front, will continue to update readers on the global development and implementation of Dublin Core and other metadata standards. Other articles will discuss local search engines for accessing archival collections on the Web, cataloging Internet resources, customizing the OPAC display for Web resource access, and other emerging Web technologies and services." Contact the journal editor: Sheau-Hwang Chang (Associate Librarian, Clement C. Maxwell Library, Bridgewater State College)
[October 29, 2001] "Meta Data for E-Commerce: The ONIX International Standard." By Norm Medeiros (Coordinator for Bibliographic and Digital Services, Haverford College, USA). In OCLC Systems And Services Volume 17, Number 3 (2001), pages 114-116 (with 7 references). ISSN: 1065-075X. "The Online Information Exchange (ONIX) international standard is a collaborative project aimed at developing descriptive and administrative meta data for books. ONIX was first published in January 2000, and was a result of funding from the Association of American Publishers. It was conceived in order to provide Internet booksellers with rich, standardized data that could promote e-commerce. The metadata initiative is currently in release 1.2, dated November 24, 2000, and is maintained cooperatively by three bodies: EDItEUR, an international group, which coordinates standards for electronic commerce; the Book Industry Communication, a London-based organization charged with exploring electronic data interchange; and the Book Industry Study Group, a non-profit association stationed in New York, which develops technical standards for the book world." See (1) the main reference page "ONIX International XML DTD" and (2) the Version 2.0 ZIP file which contains the version 2.0 set of text files which together constitute a formal definition allowing standard XML software to parse, verify and operate on the content of correctly formulated ONIX Product Information messages.
[October 29, 2001] "A Commitment-Based Approach for Business Process Interoperation." By Jie XING, Feng WAN, Sudhir Kumar RUSTOGI, and Munindar P. SINGH. In IEICE Transactions on Information and Systems (October 2001), pages 1324-1332. The Institute of Electronics, Information and Communication Engineers (IEICE) / IEEE Joint Special Issue on Autonomous Decentralized Systems and Systems' Assurance. "Successful e-commerce presupposes techniques by which autonomous trading entities can interoperate. Although progress has been made on data exchange and payment protocols, interoperation in the face of autonomy is still inadequately understood. Current techniques, designed for closed environments, support only the simplest interactions. We develop a multiagent approach for interoperation of business process in e-commerce. This approach consists of (1) a behavioral model to specify autonomous, heterogeneous agents representing different trading entities (businesses, consumers, brokers), (2) a metamodel that provides a language based on XML for specifying a variety of service agreements and accommodating exceptions and revisions, and (3) an execution architecture that supports persistent and dynamic (re)execution..." [cache]
[October 29, 2001] "A Decentralized XML Database Approach to Electronic Commerce." By Hiroshi ISHIKAWA and Manabu OHTA. In IEICE Transactions on Information and Systems (October 2001), pages 1302-1312 (with 19 references). The Institute of Electronics, Information and Communication Engineers (IEICE) / IEEE Joint Special Issue on Autonomous Decentralized Systems and Systems' Assurance. "Decentralized XML databases are often used in Electronic Commerce (EC) business models such as e-brokers on the Web. To flexibly model such applications, we need a modeling language for EC business processes. To this end, we have adopted a query language approach and have designed a query language, called XBML, for decentralized XML databases used in EC businesses. In this paper, we explain and validate the functionality of XBML by specifying e-broker business models and describe the implementation of the XBML server, focusing on the distributed query processing." See also the following bibliographic item. See "XML and Query Languages." [cache]
[October 29, 2001] "An Active Web-based Distributed Database System for E-Commerce." By Hiroshi Ishikawa and Manabu Ohta (Tokyo Metropolitan University, Department of Electronics and Information Engineering). Paper presented at the International Workshop on Web Dynamics held in conjunction with the 8th International Conference on Database Theory, London, UK, 3-January-2001. 10 pages. "EC business models like e-brokers on the Web use WWW-based distributed XML databases. To flexibly model such applications, we need a modeling language for EC businesses, specifically, its dynamic aspects or business processes. To this end, we have adopted a query language approach to modeling, extended by integrating active database functionality with it, and have designed an active query language for WWW-based XML databases, called XBML. In this paper, we explain and validate the functionality of XBML by specifying e-broker and auction business models and describe the implementation of the XBML server, focusing on the distributed query processing in the WWW context... We take an ordered directed graph as a logical model for an active query language XBML as a modeling language of EC businesses. That is, the data model of the XBML can be represented as data structures consisting of nodes (i.e., elements) and directed edges (i.e., contain, or parent-child relationships), which are ordered. We also use e-broker business models based on XML data for describing the XBML functionality. Here we will provide the working definition to EC business models in general. The EC business models consist of business processes and revenue sources based on IT such as Web and XML.. XBML provides the following functions for describing product search processes: (1) XBML allows product search by selecting products based on their attributes, such as titles and authors, and constructing search results based on them. (2) XBML allows ambiguous search by allowing partially-specified strings and path expressions. (3) XBML supports data join used in related search to promote cross-sell and up-sell. (4) XBML configures search results by sorting and grouping them based on product attributes. (5) XBML supports "comparison model" of similar products by allowing search multiply bound across shopping sites. (6) XBML provides localized views (e.g., prices) of global products by introducing namespaces (i.e., contexts. Note that we cannot describe sorting, grouping, and namespaces due to the limit of space... There are no high-level language approaches to modeling EC business processes, in particular, no other work on validating the modeling language by applying it to EC business models. XBML can provide a more direct and universal tool for modeling distributed XML data applications than server-side scripting tools such as CFML, ASP. Now we will compare our XBML with other query language proposals from the viewpoint of process specification since XBML contains the query language functionality as a basic part. XML-QL has comprehensive functionality and has much in common with our XBML. However, condition specification in XML-QL is rather verbose. If applied to business modeling, XML-QL would make query formation rather complex. XQL has compactly-specified functionality and has common functionality with our XBML. XQL focuses more on filtering a single XML document by flexible pattern match conditions similar to XSL. If applied to specifying EC business models involving multiple sites, XQL would require the user to write extra application logic in addition to query formation. Lore provides a powerful query language for retrieving and updating semi-structured data based on its specific data model OEM, but it lacks some functionality such as multiple binding. So far we have compared XBML with the other works only from the viewpoint of query languages. However, the above languages are largely different from XBML for the following reasons. First, we focus our efforts on the distributed query processing in the Web context. However, the above works don't cover such a topic. Second, we think that the functionality of ECA rules is mandatory in order to model control flow of E-businesses. However, all of the above query languages lack ECA rules. Web query languages, such as W3QL, view the Web as a single huge database and enable to address the structures and contents. XBML views a single Web source as a database and allows queries over Web-based distributed databases. The active views focuses on the comprehensive functionality of ECA rules. On the other hand, we have concluded the necessity of ECA rules from the experiences of applying XBML to concrete businesses. We extend the query optimization in relational databases to the distributed context..." See "XML and Query Languages." [cache]
[October 29, 2001] "An Autonomous Decentralized Architecture for Distributed Data Management and Dissemination." By Malworsth Brian BLAKE and Patricia LIGUORI. In IEICE Transactions on Information and Systems (October 2001), pages 1394-1397. The Institute of Electronics, Information and Communication Engineers (IEICE) / IEEE Joint Special Issue on Autonomous Decentralized Systems and Systems' Assurance. "Over recent years, "Internet-able" applications and architectures have been used to support domains where there are multiple interconnected systems that are both decentralized and autonomous. In enterprise-level data management domains, both the schema of the data repository and the individual query needs of the users evolve over time. To handle this evolution, the resulting architecture must enforce the autonomy in systems that support the client needs and constraints, in addition to maintaining the autonomy in systems that support the actual data schema and extraction mechanisms. At the MITRE Corporation, this domain has been identified in the development of a composite data repository for the Center for Advanced Aviation System Development (CAASD). In the development of such a repository, the supporting architecture includes specialized mechanisms to disseminate the data to a diverse evolving set of researchers. This paper presents the motivation and design of such an architecture to support these autonomous data extraction environments. This run-time configurable architecture is implemented using web-based technologies such as the Extensible Markup Language (XML), Java Servlets, Extensible Stylesheets (XSL), and a relational database management system (RDBMS)." [cache]
[October 29, 2001] "An Automated Client-Driven Approach to Data Extraction using an Autonomous Decentralized Architecture." By Malworsth Brian Blake and Patricia Liguori (Department of Computer Science Georgetown University Washington DC). Paper presented at the Fifth International Symposium of Autonomous Decentralized Systems (ISADS2001), IEEE Computer Society Press, Dallas, TX, March 2001. "... The customers' query page specifications are encapsulated in the HttpServletRequest. This information can be parsed and used to generate the specifications for the HTML-based query form. This module stores this user preference information as an XML file in share file system location. In building this XML file, the module may have to gather database specific information. The intent is to use the XML file with a generic XSL file to automatically create the HTML-based query form. This XML file is the centerpiece of the architecture. This file contains a great deal of detailed information that allows the Presentation and Query Module to be generic. The benefit here is to allow outside sources to use the same XML format, and without the Interface Specification module, to have the ability to use the Presentation and Query module for data retrieval..." See the related paper from 1999, cache.
[October 26, 2001] "Blueprint Emerging for User Facing Web Services." By Cathleen Moore. In InfoWorld October 25, 2001. "Momentum is quietly gathering behind a prospective standard for defining how Web services will find their way into the hands of business users. At this week's Web Services Edge 2001 West show, in Santa Clara, California, OASIS (Organization for the Advancement for Structured Information Standards) announced the formation of a technical committee for the WSCM (Web Services Component Model). Influential vendors, such as IBM, Epicentric, Hewlett-Packard (HP), and Documentum have thrown their weight behind it. WSCM aims to foster the development of business user-facing Web services by defining a set of XML vocabularies and Web services interfaces that allow vendors to deliver Web applications to end-users, according to Charles Wiecha, OASIS WSCM technical committee chair and IBM research manager... The committee's development work will be particularly important for the enterprise information portal market, in terms of integrating Web services and other applications for end-user consumption, IBM's Wiecha said. IBM said it intends to contribute to the WSCM committee its work in the Web Services Experience Language, a component model for interactive Web applications. Initial members of the OASIS WSCM Technical Committee include IBM, Epicentric, Hewlett-Packard, DataChannel, Documentum, Macromedia, Sterling Commerce, Cyclone Commerce, Logistics Management Institute, Republica, and U.S. Defense Information Systems Agency. San Francisco-based portal player Epicentric, which has been driving the development of a similar specification, dubbed Web Services User Interface, said it will submit its technical efforts over to the WSCM standards push. 'We feel this is a major milestone for proving app interoperability at a user presentation level,' said Ed Anuff, chief strategy officer at Epicentric. 'A Web service up until now using SOAP [Simple Object Access Protocol] and WSDL [Web Services Description Language] has had no presentational aspect to it. With component model Web services you can provide a complete user interface for an end-user involved in that which can be dynamically plugged into a portal without development efforts.' As the WSCM committee moves further along with a technical specification, the movement is likely to draw support from a wide array of vendors that are rushing to stake territory in the emerging Web services model, according to Wiecha... The first meeting of the WSCM technical committee will be held in January when the group plans to lay out milestones for specification efforts and other technical goals toward standard completion." See: "Web Services Component Model (WSCM)."
[October 26, 2001] "Groove's Rubber Soul. [Opinions.]" By Steve Gillmor. In InfoWorld Issue 43 (October 22, 2001), page 70. "The rubber meets the road this week as Microsoft unveils .NET My Services at its Professional Developers Conference (PDC) in Los Angeles. And what a fitting location for .NET's Trojan horse, next door to Hollywood's dream factory. While Sun trumpets its Liberty Alliance and privacy groups fret over Passport, the technology formerly known as HailStorm is poised to slip Web services into production sooner than commonly expected. Most analysts agree that Web services will first be adopted internally, as companies wire existing applications together via SOAP (Simple Object Access Protocol) and private UDDI (Universal Description, Discovery, and Integration) repositories. As XML security standards become stable, the next step will be to extend these pilot efforts out to partners, suppliers, and eventually, customers. But a quick flashback suggests another possible scenario. Remember how home users bought their kids cheap, fast PCs preloaded with Windows 95 and Office 97, then drove IT crazy at work with ad hoc upgrades of OS and productivity apps? When the smoke cleared, Office was on its way to 90 percent market share. Same thing with instant messaging: ICQ started as a hacker and gamer tool, but America Online's decision to open its buddy lists to the Web jump-started a 100-million member platform. Only then did corporate teams adopt the technology, ignoring the security and intellectual property holes punched in the network. Thus came Napster and its peer-to-peer partners in crime. The jury is still out on how to productize decentralized systems, but Microsoft's investment in Ray Ozzie's Groove startup only cements a collaboration that has been in play for more than a year. Sun's JXTA suggests a marriage of convenience between the open-source, Java, and XML communities. On the surface, the Groove-Microsoft alliance is a severe case of strange bedfellows... To some, Groove seems to be swimming against the open-standards tide. SOAP co-author Dave Winer calls Groove a closed architecture; XML pioneer Tim Bray thinks it struggles against rather than works with the Net... It's easy to see what Ozzie gets out of the relationship with Microsoft. Groove leverages COM as its object model, bootstrapping Visual Studio as its IDE. But the real common ground with .NET is XML, and here Groove engineers have contributed significantly to the underlying services shared by peer and Web services... Lucovsky's HailStorm XML effort is the leading edge of a revolution at Microsoft that may well sweep through the next generation SQL Server architecture, code-named Yukon, and lead a transformation of the underlying platform. Lucovsky's design leverages XML not just as a method of transporting data between systems, but as an object model to be programmed against... Ozzie insists he hasn't sold his soul, not even a percentage of it. Groove's XML, SOAP, and XML-RPC underpinnings allow Groove services to work with other platforms as they gain market and mind share." See the announcement: "Microsoft and Groove Networks Announce Strategic Relationship."
[October 26, 2001] "Microsoft Gives SQL Server More XML Fluency." By Tom Sullivan. In InfoWorld October 26, 2001. "At its ProfessionaL Developers Conference (PDC) this week, Microsoft quietly revealed an updated version of its SQLXML Web release add-on for the SQL Server 2000 database. All of the major database players, in fact, have been adding XML to their software over the last several months. Microsoft's SQLXML 2.0 contains support for XSD (XML Schema Definition), a specification from the W3C (World Wide Web Consortium) standards body, in Cambridge, Mass., that eases data integration and interoperability. SQLXML 2.0 enables developers to program XML features in SQL Server 2000 with Visual Studio.NET, thereby bringing the database up to speed for developers building Web services, said Jeff Ressler, a SQL Server product manager at Redmond, Wash.-based Microsoft. Previously, developers used Visual Studio 6.0 with SQL Server, and now they have the option of using either version of the toolbox. Another important benefit is that SQLXML can be used to enable XML processing at the middle tier. For instance, a typical scenario may include one database and a dozen application and Web servers. When one of the application servers calls the database, that application server can process the XML, instead of the database having to process every XML-related query and then sending it back to the application server. 'It offloads work from the database server, which means the database server has more CPU cycles to do more important things,' Ressler said. Microsoft has been using the Web release method to keep SQL Server up to date with W3C standards, Ressler added. When it shipped, SQL Server 2000 supported XML, Xpath (XML Path Language), and XSLT (eXtensible Style Sheet Language Transformations) out of the box. The first Web release of SQLXML contributed support for XML bulk loading to the database. Xpath is a language for addressing parts of an XML document, designed to be used by XSLT, which is a language for transforming XML documents. XML bulk loading provides a means to get XML data into databases..."
[October 26, 2001] "Discover XML for SQL Server." Microsoft Technical Resources. "SQLXML 2.0 for SQL Server 2000: Microsoft released to the Web for immediate download SQLXML 2.0, a set of components that extend the industry leading XML functionality of SQL Server 2000. These capabilities allow developers to efficiently and flexibly create standardized schemas to improve interoperability and simplify data integration, improve XML bulk data capabilities, and provide XML capabilities on the data tier, middle tier and client tier. SQLXML 2.0 further enhances developer productivity by making these capabilities available through Visual Studio .NET and through a set of native .NET Framework components... Microsoft SQL Server 2000 introduced several new features for querying database tables and receiving the results as an XML document. Web release 1 of SQLXML (XML for SQL Server) added Updategrams and XML Bulk Load functionality, as well as a host of other features to the SQL Server 2000 base. Continuing the Web Release strategy, SQLXML 2.0 adds support for XSD mapping schemas, Client-Side XML functionality, a new SQLXML OLEDB provider, a tool to convert XDR mapping schemas to XSD, and significant performance improvements. SQL Server 2000 users can use client-side XML functionality to move XML processing to the middle tier for better scalability or to wrap SQL Server Stored Procedures with the Transact-SQL FOR XML clause. SQLXML 2.0 also introduces a set of SQLXML Managed Classes that allows .NET developers to access SQLXML functionality..." See the download page.
[October 26, 2001] "Universal Vocabulary Could Break E-Commerce Language Barrier." Written by Michael Gomez. Analytical source: Rita Knox (Gartner Group, XML lead analyst). In ZDNet TechInfo October 23, 2001. "The Organization for the Advancement of Structured Information Standards (OASIS), a nonprofit consortium that promotes development of XML as the foundation descriptive language for e-commerce, announced it had formed a technical committee to define a Universal Business Language (UBL). UBL would provide a set of XML building blocks and a framework that will enable trading partners to exchange business documents in specific contexts. Enterprises eager for standard, reusable vocabularies to facilitate e-commerce no longer fret over who will win the markup language skirmish. Rather, they want to know how to: (1) build transactions in XML; (2) exchange data with business partners, customers, and vendors; (3) assure longevity in the XML data messages that they do adopt. Instead of a 'one true way' consensus XML language, Gartner believes that the answer lies in building e-commerce transactions from reusable XML vocabularies that adopt the same terms when the same meanings and interpretations (by applications) are intended. The components of business exchanges (e.g., 'company,' 'address,' 'part number' and 'price') recur in different messages and among different industries. However, custom XML-defined transactions in every line of business would perpetuate proprietary solutions. If each exchange is unique (i.e., it uses new terms even if the same meaning is intended), computers will confront a tangle of incompatible languages; therefore, they will be unable to share data or reuse software to process the same data stream. OASIS knows about the proliferation of markup languages -- it maintains a database of proposed standards (see www.xml.org). By taking a mediating role in resolving the markup language fracas, OASIS can help achieve cost and time savings in many processes in many industries. Initially, UBL aims to prevent chaos by defining a specific vocabulary for e-commerce. If successful, UBL may then prove useful as a framework for creating 'words' in other fields such as science, healthcare, politics, or art. Despite uncertainty over how this initiative will be executed in what will likely be a contentious environment, OASIS's attempt to create vocabularies rather than complete transactions takes a step that enterprises understand and seem ready to support..." See: "Universal Business Language (UBL)."
[October 26, 2001] "Syncing data. An Introduction to SyncML." By Scott Stemberger (Manager, Etensity). From IBM developerWorks. October 2001. ['In recognition of the fact that as the number of unique devices and the desire to access different enterprise resources proliferates, the SyncML initiative was formed to provide a uniform synchronization protocol for connecting multiple devices over any network to any data store. This article provides an overview of the open industry specification for data synchronization, SyncML, designed to meet the needs of the mobile user and their any-device, any-network synchronization needs.'] "The SyncML specification was designed with two primary goals in mind: (1) Synchronize networked data with any mobile device; (2) Synchronize a mobile device with any networked data. To accomplish these goals, SyncML was designed as a platform, network, and application-agnostic protocol, allowing for 'any-to-any' synchronization and, thereby, access to more types of data. SyncML is based on XML, so it works especially well handling cases in which network services and devices each store the data being synchronized in different formats, and which use different software systems... SyncML is comprised of two protocols: SyncML representation protocol and SyncML Sync Protocol. The first one can be envisioned as guiding the intricacies within the SyncML Framework, while the SyncML Sync protocol guides actions on the SyncML client and server. The SyncML data synchronization protocol is essential for gaining interoperable data synchronization. It essentially defines the protocol for different sync procedures, which occur between a SyncML client and SyncML server in the form of message sequence charts (MSCs). Examples of sync types are two-way syncs between server and client, or one-way syncs between the two. The SyncML representation protocol is defined by a set of well-defined messages (XML documents or MIME) that are shared between synchronizing devices. It supports data synchronization models that are based upon a request/response command structure, or those based upon a 'blind push' structure. The SyncML representation protocol specifies what the result of various synchronization operations should be, based upon a synchronization framework and format that accommodates different data synchronization models... SyncML is certainly the protocol of the future, as interoperability between devices, transport protocols, and network databases becomes a bigger priority for businesses and consumers. However, SyncML does face some challenges along the way. First and foremost is that SyncML is a standard, not an application or software. It allows device and server manufacturers to move to one clearly defined standard in which their products can be interoperable; unfortunately, it does not guarantee compliance. This leads to the next challenge -- partial implementation of the standard by vendors. In a perfect world, our syncing devices will be entirely plug-and-play with any data store on any network, enabling a device to sync with any database, in any location, at any time. Reality says that this level of cooperation among vendors will be challenging, to say the least, exhibited by the fact that many vendors have claimed full support of SyncML, but have yet to implement the standard into their products while continuing with their proprietary syncing efforts. A third challenge is the fact that the standard is in its infancy, and with that comes certain assumptions within the industry. Similar to the sentiment surrounding young standards such as WAP, certain vendors or businesses may be loathe to implement a 'young' standard for fear that the standard is still evolving at such a rate that their implementation will be at risk in a year's time... In light of intermittent network connections and relatively high cost of ownership for wirelessly connected devices, SyncML may very well be the missing piece of the puzzle that moves society into truly embracing mobile data services." Also in PDF format. See "The SyncML Initiative."
[October 26, 2001] "An introduction to Web Services." By Tracy Gardner (Advisory Software Engineer, IBM United Kingdom Laboratories, Hursley). In Ariadne Issue 29 (September 2001). Published by UKOLN. ['Tracy Gardner introduces web services -- self-describing applications which can be discovered and accessed over the web by other applications.'] "The term web services has gaining visibility in recent months, there has been a W3C workshop on web services and the big industry players such as IBM, Microsoft and Sun have been announcing their web services strategies. So what's it all about and should you be involved? This article aims to be a starting point for answering these questions. Well, the term web services is fairly self-explanatory, it refers to accessing services over the web. But, there's more to it than that, the current use of the term refers to the architecture, standards, technology and business models that make web services possible. In this article we will use a definition of web services taken from an IBM web services tutorial: 'Web services are a new breed of Web application. They are self-contained, self-describing, modular applications that can be published, located, and invoked across the Web. Web services perform functions, which can be anything from simple requests to complicated business processes.' In other words, web services are interoperable building blocks for constructing applications. As an example, we can imagine a distributed digital library infrastructure built on web services providing functionality such as distributed search, authentication, inter-library loan requests, document translation and payment. These web services would be combined by a particular digital library application to offer an environment for reaching information resources that is tailored to its particular user community. Where the current web enables users to connect to applications, the web services architecture enables applications to connect to other applications. Web services is therefore a key technology in enabling business models to move from B2C (Business to Consumer) to B2B (Business to Business)..."
[October 26, 2001] "Subject Portals." In Ariadne Issue 29 (September 2001). Published by UKOLN. ['Judith Clark describes a 3-year project to develop a set of subject portals - part of the Distributed National Electronic Resource (DNER) development programme.'] "The RDN portals are primarily concerned with technologies that broker subject-oriented access to resources. Effective cross-searching depends on consistent metadata standards, but these are still under development and although the RDNs collection is governed by sophisticated metadata schemas, this is not the case for many of the other resources targeted by the portals. Z39.50 is the standard that has been adopted for the preliminary cross-search functionality. Further portal functionality is being developed using RSS (Rich Site Summary) and OAI (Open Archives Initiative). Other standards applications that underpin the portals are notably Dublin Core and a variety of subject-specific thesauri such as the CAB Thesaurus and MeSH... [The OAI protocol provides a mechanism for sharing metadata records between services. Based on HTTP and XML, the protocol is very simple, allowing a client to ask a repository for all of its records or for a sub-set of all its records based on a date range. An OAI record is an XML-encoded byte stream that is returned by a repository in response to an OAI protocol request for metadata from an item in that repository.] The RDNs services today fulfil an expressed goal of the eLib programme, which in 1994 funded a series of demonstrator services designed to create a national infrastructure capable of generating significantly more widespread use of networked information resources. Those services, then known as subject gateways, developed in response to community interests specific to each gateway. The RDN itself was established in 1999 to bring the gateways together under a federated structure. The Hubs are based around faculty-level subject groupings, chosen with a view to potential for partnership, sustainability, and growth, while preserving legacy investments. The RDNs internet resource catalogues include records describing almost 40,000 web sites and are growing steadily as new subject areas are encompassed..." See technical details in "The DNER Technical Architecture: Scoping the Information Environment" [also PDF] References: see "Open Archives Metadata Set (OAMS)."
[October 26, 2001] "XML Data Binding with Castor." By Dion Almaer (CustomWare). From The O'Reilly Network, OnJava.com. 10/24/2001 "In this article, we will walk through marshalling data to and from XML, using a XML data-binding API. The first question is, why? Why not use SAX or DOM? Personally, when I sit down to work with XML, I get frustrated with the amount of code that you need to write to do simple things. I came across JDOM and found it to be something I was looking for. DOM is built to be language-agnostic, and hence doesn't feel very 'Java-like.' JDOM does a great job in being DOM, in a way I would like to use it in Java. For some applications, I don't want to even think about 'parsing' data. It would be so nice if I could have a Java object to work with, and have it saved off as an XML representation to share, or store. This is exactly what XML data-binding can do for us. There are a few frameworks to help us do this, but we will walk through Castor, an open source framework from Exolab. Castor is a data-binding framework, which is a path between Java objects, XML documents, SQL tables, and LDAP directories. Today, we will work with Castor XML, the XML piece of the Castor project We will discover the different aspects of Castor XML as we develop an Address Book XML document. We will create, read, and modify this XML document via the data-binding framework. All of the code from this article should work with any JVM supporting the Java 2 platform... Conclusion We have shown that working with XML doesn't mean that you have to delve into the books to learn SAX, DOM, JAXP, and all the other TLAs. Castor's XML data-binding provides a simple but powerful mechanism to work with XML and Java objects."
[October 26, 2001] "Q&A: OASIS Exec Discusses Role in Web Services." By Kathleen Ohlson. In Network World Fusion October 10, 2001. "OASIS is a nonprofit, international organization that creates interoperable industry specifications based on public standards such as XML and Standard Generalized Markup Language, an international standard for electronic document exchange. Members include IBM, BEA Systems, Accenture, Oracle and Sun. In 1999,OASIS teamed up with the United Nations Center for Trade Facilitation and Electronic Business (UNCEFACT). Since then, the two have been working on a way for businesses to connect over the Internet and conduct e-commerce. Their efforts have resulted in e-business XML (ebXML), which defines a common way for companies -- no matter their industry -- to handle and route data to each other over the Internet. Now ebXML is expected to play a part in Web services, which are XML- and HTML-based tools that allow businesses to integrate applications internally and externally over the Internet. Patrick Gannon, OASIS president and CEO, recently sat down with Network World Senior Writer Kathleen Ohlson to discuss Web services and how OASIS is involved with Web services adoption. [Gannon says:] 'OASIS provides an open environment to develop application-oriented standards, as well as help users with implementation activities. Our overall mission is the acceptance and adoption of interoperable specifications, and to move [those specifications] from adoption to implementation. EbXML is an excellent example of that. We worked together with an industry association, the UNCEFACT. It created an opportunity to bring together vendors to define a business process. We were able to create proof of concept demos [from there]. The technology has existed [for Web services], but we needed the framework to be able to do modular component computing. We now can make this possible with the adoption and the acceptance of a few core interoperability standards -- UDDI [Universal Description, Discovery and Integration] and SOAP [Simple Object Access Protocol]. We believe the definition of Web services spans the whole spectrum. In terms of simple Web services, it's a discrete process that gets information and doesn't depend upon a prior process -- for example, if you're looking up a currency exchange and you want to know what the U.S. dollar amount is for the French franc. Complex Web services are multiple discrete transactions integrated with multiple trading partners. An application is invoked by another application - looking up a business partner, searching a UDDI and receiving an interactive display with your results... Web services and ebXML will move beyond the technology. They will offer a new way to do business at a lower cost. We'll have faster and richer tools. We'll combine tools together and construct new business processes. Our role at OASIS is to bring together development tools, industry organizations and end-user companies and put them together for pilot implementation projects. There are activities already under way [to make SOAP and UDDI standards], but we could be the organization that organizes the tech committee for them that moves them beyond as initiatives. As part of another effort, we're independent and we can expand the adoption view and make them a piece of a broader whole...'."
[October 24, 2001] "HR-XML: Enabling Pervasive HR e-Business." By Chuck Allen (President, Structuredmethods.com; Director HR-XML Consortium, Inc.) and Lon Pilot (Watson Wyatt Worldwide; Chairman, HR-XML Consortium). Paper presented at XML Europe 2001 (21-25 May 2001, Internationales Congress Centrum (ICC), Berlin, Germany). "The HR-XML Consortium is a non-profit group that is developing standard XML vocabularies for the human resources management profession. With more than 120 member organizations around the world, HR-XML is one of the largest and best-supported groups developing XML standards in support of specific business functions. Human resource management is an enormous and complex domain. Simply stated, the HR management function supports organizational effectiveness by recruiting, identifying, assessing, hiring, retaining, motivating, training, and compensating the people organizations need to execute their missions. While much has been done to Web-enable HR software and services, employers and service providers still often encounter barriers to easy data integration. For instance, exchanging data with a new partner or service provider too often requires decisions about the format of the 'data feed' and custom development of software interfaces to move data into and out of computer systems. Moreover, while the Web browser has become a universal, easy-to-use interface for users to enter data and interact with applications, the frequent need for users to enter data into Web forms from paper sources, to 'cut and paste' data between different applications, or to re-enter the same data within different forms is symptomatic of the data integration problems common today. This paper provides background on some of the data interchange barriers within the HR management domain and what members of the HR-XML Consortium are doing to eliminate those barriers. The paper briefly reviews the Consortium's methodology and the status of its current projects... HR-XML develops Document Type Definitions (DTDs) and XML schemas defining messages for key HR transactions. HR is a large and complex problem domain. The number of HR transactions that could be supported through standard messaging is enormous [necessitating clear strategies for deciding] where to focus efforts and ensuring consistency across its specifications Some of the principles that are driving the work of the HR-XML Consortium include: (1) Member-driven project priorities. The work of the HR-XML Consortium is member-driven. Members decide what projects the Consortium will undertake. This helps ensure that the Consortium's investments of time and money are spent on the members' most pressing data interchange problems. (2) Management of 'Cross-Process Objects.' HR-XML has created the "Cross-Process Objects" workgroup, which is responsible for developing durable, reusable models for objects that are shared across many types of processes. Examples of cross-process objects (CPOs) are Person Name, Postal Address, Contact Information, Government Identification Code, etc. (3) Proceeding from a common reference model and glossary. The Consortium's Glossary Project supports the Consortium's various workgroups by developing a baseline system of knowledge, terms, and concepts to be extended throughout the work of HR-XML. The reference model and glossary are intended to provide important context to the Consortium's process-specific workgroups." References: see (1) the HR-XML Consortium web site; (2) the recent news item, "HR-XML Consortium Approves New Standards for Human Resources E-commerce"; (3) the "HR-XML Consortium" main reference page. Paper also available in PDF format. [cache]
[October 24, 2001] "TEI and XML: A Marriage Made in Heaven. An Introduction to The Future of Digital Information." By Lou Burnard (Manager of the Humanities Computing Unit at Oxford University Computing Services; TEI Editor, Europe). Presented at "Computing Arts 2001: Digital Resources for Research in the Humanities," University of Sydney 26 - 28 September 2001. "One of the more striking features of XML, by comparison with its progenitor SGML, is the fact that you can use XML without having to know what a document type definition (DTD) is. Documents need only be syntactically valid, and there is no longer any requirement of an application to understand their structure in advance. One consequence of this is that the most effective ways of using XML are in well-defined application areas, or well-defined user communities, where there is a pre-existing consensus as to the meaning of elements and their attributes. Another is that in larger application areas and less well-defined user communities would-be XML users continue to need ways of defining DTDs if they are to benefit from the claimed advantages of XML for document interchange and re-usability. If XML is to be the basis of a new digital demotic, in which a thousand distributed applications can share access to a pool of distributed digital resources, we need to define something more than structure and syntax for that demotic. In this talk I will outline how the Text Encoding Initiative (TEI) 'Recommendations' of 1994 attempted to define an effective framework for the construction of user- and application- specific DTDs. The abbreviation 'DTD' actually has two expansions -- document type Declaration, and document type Definition -- which should not be confused. Originally expressed as a large but modular Document Type Definition, the TEI Guidelines consist essentially of intended semantics for several hundred element types. This definitional work, by setting out formally a broad based consensus as to the topoi of scholarly encoding, is probably one of the more significant contributions to scholarly work made by the TEI. In addition, the Guidelines may be seen as a very loose and generic Document Type Declaration, providing a syntactic framework within from almost any desired document grammar can be constructed. Separating these two aspects helps us see how the TEI recommendations are peculiarly apt for the XML age. They define a number of distinct vocabularies, simplifying where simplification is appropriate, but allowing for any required depth of semantic complication or enrichment. Because these vocabularies share a common syntactic basis, their exploitation by a wide range of open software tools and systems is greatly facilitated. Because they are robustly and formally defined, moreover, it is possible to add new vocabularies which can build on existing fragments in a controlled and compatible way. With the establishment of a new Consortium to manage and promote the further development of the scheme, and in particular with the publication of the new XML based version (P4), the groundwork has been laid for a new chapter in this attempt to apply the creative energies of the humanistic research community to its traditional task of communicating and preserving cultural heritage and its interpretation. The presentation will briefly review the history and motivation of the design of the TEI system and will also give a flavour of the range of application areas in which it has been successful. The main focus however will be on the future development of the TEI in its new guise as an environment for the construction of compatible XML vocabularies appropriate to many different research areas." See (1) "Text Encoding Initiative Consortium Releases P4 Draft Guidelines in XML and SGML," and (2) "Text Encoding Initiative (TEI) - XML for TEI Lite."
[October 24, 2001] "Microsoft Sprinkles SALT on Developers." By Ephraim Schwartz. In InfoWorld October 23, 2001. "In a classic example of how the high-tech industry works, on the same day that Microsoft's chief architect Bill Gates announced support for one speech recognition technology known as SALT (Speech Application Language Tags), the WC3 (World Wide Web Consortium) announced support for another, VXML. Microsoft this week at its Professional Developer's Conference (PDC) released what it called a '.NET Speech SDK technology preview,' a speech specification for its .NET initiative and for more powerful handhelds. The specifications for Web developers uses SALT to allow developers to create speech tags for HTML, xHTML, and XML markup languages. SALT will make it easier for Web developers to incorporate speech and it will be supported in Internet Explore, Pocket IE, ASP.net, and Visual Studio.net. According to Kai-Fu Lee, vice president of the Natural Interactive Services Division for Microsoft. While Gates announced support for SALT during his keynote address at PDC and Microsoft released preliminary specs, the W3C announced formal acceptance of Voice XML as the standard for adding speech recognition to make Web-based applications accessible over the telephone network... SALT, which is also targeted at Web developers, is meant to create a voice-activated user interface as part of a larger multi-modal UI for handheld devices. On handhelds, voice is expected to be one of many ways to access information. Although VXML and SALT are targeted at two different platforms, a turf war appears inevitable and Microsoft is being accused of rubbing SALT into an industry already wounded by high expectations and poor follow-through... If SALT is only a small set of lightweight tags as its proponents claim, then it cannot be used for speech applications, nor does it have an inherent advantage over VXML for multi-modal devices, Herrel said. In Herrel's capacity as the speech technology analyst at Giga, she issued a statement advising developers incorporating speech into applications to use VXML. Speaking as a member of the SALT Forum Glen Shires, director of media servers (telephony) at Intel, said he believes both languages have different strengths, VXML for telephony and SALT for multi-modal. However, when asked if developers would then need to learn two development environments to have a complete voice-enabled application, he said, 'It is possible to do everything in SALT.'... This opinion is backed by James Mastan, group product planner for Microsoft .NET Speech Technologies, who also said VXML was created for IVR-based services. He admitted it remains problematic whether VXML could be used for handheld devices: 'Technically it is extremely difficult to go from the voice area [VXML] and extend that to the multi-modal space. It is much easier to take existing HTML markup language and add a few small elements,' Mastan said. Nigel Beck, a member of the VXML Forum, said that the WC3 is investigating creating multi-modal extensions for VXML. The initial strategy behind the VXML initiative rested on the simple fact that cell phone growth is increasing by an order of magnitude faster than any other segment of the wireless market. Thus, VXML's goal is to make that lucrative channel available for current Web services. What is unclear is if SALT proponents will eventually want to target the same lucrative market..." See (1) "Speech Application Language Tags (SALT)"; and (2) W3C Working Draft for Voice Extensible Markup Language (VoiceXML) Version 2.0."
[October 23, 2001] "Sun to Advance Web Services Plan." By Stephen Shankland and Wylie Wong. From CNet News.com October 22, 2001. "Sun Microsystems is set to further define its vision for Web services as it vies with rival Microsoft for control over the future of business computing on the Internet. On Tuesday at a Sun conference in Santa Clara, Calif., Chief Operating Officer Ed Zander and other Sun executives will advance Sun's support for the standards behind the creation of Web services software. In addition, as reported by CNET News.com, Sun will begin selling a new instant messaging product aimed at corporate users, the iPlanet Instant Collaboration Pack. Web services, a trend sweeping the computing industry, involves reworking actions that currently happen on a desktop computer or a server so they take place on a mesh of servers and desktops that can seek each other out on the Internet... Sun One is emerging in two major software initiatives at Sun: the iPlanet application server software for tasks such as selling books online and disseminating information from internal corporate Web sites or e-commerce sites; and the Java software that lets a program -- at least theoretically -- run on different computers without having to be rewritten for each one. Some developers have reported mixed success with Java server program portability. The iPlanet products already support one component of Web services, sending messages using the Extensible Markup Language (XML) standard. Tuesday, Sun will announce that the iPlanet application server and Web server products will include built-in support for another key standard, Simple Object Access Protocol (SOAP), used to send instructions from one machine to another using XML, Breya said. And to lure customers to the iPlanet application server, which trails in the market after competing products from IBM and BEA Systems, Sun will offer the product free for development use. Sun will detail Tuesday the schedule for supporting other Web services standards in the server version of Java by the end of 2002, Breya said: the Universal Description, Discovery and Integration (UDDI) standard, a sort of online yellow pages for listing Web services, and Web Services Description Language (WSDL), a standard way of describing specific services..."
[October 23, 2001] "Microsoft Debuts Tools, Web Services Specifications." By Wylie Wong and Mike Ricciuti. From CNet News.com October 22, 2001. "Microsoft Chairman Bill Gates told software developers Tuesday that they will play a key role in driving Microsoft's .Net Web services plan... Microsoft also announced several new tools and distributed near-final versions of its Visual Studio.Net and .Net Framework tools to conference attendees. Those tools are key to rallying developers around the company's .Net Web services plan. Microsoft faces competition from Sun Microsystems and companies including Oracle, IBM and others supporting Java... The new specifications are part of a new software-development architecture, called the Global XML Web Services Architecture, that Microsoft previewed Tuesday. The company also previewed four new related specifications that it will submit to standards bodies after a review period. Microsoft did not specify how long the review period will be or which standards body will handle the submission. But Extensible Markup Language (XML), upon which the new architecture is based, is a World Wide Web Consortium (W3C) standard. Microsoft said the architecture adheres to a road map outlined by it and IBM this spring at a W3C workshop. Microsoft, Sun and other companies are battling to provide tools and other software to flesh out their plans for new Web services technology. Web services is largely a reinterpretation of older development techniques combined with new Web-based standards to build software programs that seek each other out over the Internet and perform tasks automatically... (1) .Net My Services technology preview, a software development kit that lets programmers build and test .Net My Services Web services. (2) SQLXML 2.0, which adds additional XML support to Microsoft's SQL Server database software. (3) XML Core Services version 4.0, which lets developers add XML support to programs they write. (4) Office XP Web Services Toolkit, which links Office programs to Web services via the UDDI specification. (5) Visual Studio.Net Toolkit for Windows XP, sample code and libraries that let developers use .Net components to take advantage of Windows XP's real-time communications features for building audio and video chat applications..." See the text of the announcement.
[October 23, 2001] "Global XML Web Services Architecture." XML Web Services/ By Microsoft Corporation. White Paper. October 2001. "ver the past five years, Microsoft has worked with other computing industry leaders to create and standardize a set of specifications for a new model of distributed computing called XML Web services. Already there are hundreds of customers deploying and running XML Web services and thousands more in the process of development. XML Web services standards, which include SOAP, XML, and WSDL, provide a high level of interoperability across platforms, programming languages and applications, enabling customers to solve integration problems easily. But as XML Web services solutions become more global in reach and capacity -- and therefore more sophisticated -- it becomes increasingly important to provide additional capabilities to ensure global availability, reliability and security. Recognizing the need for standardizing these additional capabilities, Microsoft has released a new set of specifications that are the beginning of the Global XML Web Services Architecture. The aim of this architecture is to provide additional capabilities to baseline XML Web services specifications. The Global XML Web Services Architecture specifications are built on current XML Web services standards. Microsoft intends to work with key industry partners and standards bodies on these and other specifications important to XML Web services. This paper outlines the state of XML Web services today. It demonstrates the need for a set of additional capabilities as companies deploy XML Web services to support increasingly sophisticated business processes. Finally, it addresses how Microsoft is beginning to address the need for additional capabilities with the Global XML Web Services Architecture and its supporting specifications... s the business requirements that drive XML Web services become more complex, the architecture for XML Web services requires additional capabilities to handle the increasingly complex nature of XML Web services solutions. Recognizing this emerging need for additional capabilities, Microsoft has released a new set of specifications that are the beginning of the Global XML Web Services Architecture. The aim of this architecture is to provide additional capabilities to current XML Web services standards. Microsoft intends to work with key industry partners and standards bodies on these and other specifications important to XML Web services." See the news item "Microsoft Releases New XML Web Services Specifications for a Global XML Web Services Architecture."
[October 23, 2001] "ebXML CPP/A APIs for Java." Java Specification Request #157. Specification Lead Dale Moberg (Cyclone Commerce Inc.). Contact Person: Himagiri (Hima) Mukkamala (Sybase Inc.) Summary: "This JSR is to provide a standard set of APIs for representing and manipulating Collaboration Profile and Agreement information described by ebXML CPP/A (Collaboration Protocol Profile/Agreement)documents." Detail: "This JSR is to provide a standard set of APIs for representing and manipulating Collaboration Profile and Agreement information described by ebXML CPPA (Collaboration Protocol Profile/Agreement)documents. These APIs will define a way to construct and manipulate various profile information corresponding to the CPP/A. In addition, these APIs will provide a way to negotiate CPAs between two partners enabling them to conduct e-business. The profile information can be derived from a CPP document or constructed through the API provided or constructed by accessing a ebXML Registriy/Repository using JAXR. The APIs would also assist users in creating a CPA document from merging to CPP documents by doing a selective merge of the profile information or by providing infrastructure to negotiate between the partners. The APIs would also enable users to create a base profile by taking information from a Business Process Specification document... By design, this proposed specification depends on the ebXML CPP/A specification. ebXML CPP/A is an XML format for describing profile and agreement information for partners agreeing to collaborate based on ebXML as the underlying architecture. In addition, since the ebXML CPP/A specification is bound to the ebXML MSH specification and ebXML BPSS specification, this specification is dependent on these." Need: "This set of APIs will allow developers to build ebXML based e-business applications without directly having to access the CPP/A documents. These will also let users of the APIs create CPA documents for taking part in collaborations." Existing documents, specifications, or implementations that describe the technology: (1) ebXML CPP/A; (2) ebXML MSG. See: "Electronic Business XML Initiative (ebXML)."
[October 23, 2001] "XML Transactioning API for Java (JAXTX)." Java Specification Request (JSR) #156. Specification Lead: Mark Little (Hewlett-Packard). Contact Person: Bob Bickel (HP). Companies supporting this JSR: HP, IBM, IONA Technologies, Choreology Limited, and TalkingBlocks. Summary: "JAXTX provides an API for packaging and transporting ACID transactions (as in JTA) and extended transactions (e.g., the BTP from OASIS) using the protocols being defined by OASIS, W3C." Detail: "This JSR requests the creation of the XML Transactioning API's for Java 1.0 specification (JAXTX). This specification will describe Java API's designed specifically for the management (creation and lifetime) and exchange of transaction information between participating parties in a loosely coupled environment. Rather than communicating via IIOP, such parties will typically use SOAP and XML document exchange to conduct business 'transactions'. If these 'transactions' are to be conducted in an ACID transaction manner, then information (e.g., the transaction context) will need to accompany these XML documents and be managed appropriately. In addition, there is work going on within OASIS (the Business Transactions protocol) and the JCP community (JSR 95) to provide extended non-ACID transactions to users that will enable applications to run business transactions that span many organisations, last for hours, days, and weeks, and yet still retain some of the fault-tolerant and consistency aspects of traditional ACID transactions. The business community is working to converge on a set of standard message headers and industry-specific message payloads. It is planned that this JSR will leverage work currently under way in the OASIS, W3C, and potentially other relevant and open standards bodies to produce an API that will accomodate both strict ACID and relaxed ACID transactional applications. This JSR does not aim to define either XML messaging standards or XML schemas for particular tasks. These networking and formatting standards belong in networking standards bodies such as OASIS or IETF. Instead this JSR aims to define standard Java APIs to allow convenient access from Java to emerging XML messaging standards... The JAXTX 1.0 specification will be provided initially as a standard extension but will be incorporated into the Java 2 Enterprise Edition platform as soon as this is practical and there is sufficient demand to warrant such integration." Rationale: "Existing transaction standards such as JTA/JTS assume a closely coupled environment, with participants communicating via IIOP. In loosely coupled environments such as the web, the individual components of these transaction standards (e.g., transaction coordinator, transcional resource) would be offered as services, communicating via SOAP and XML. There is no industry standard for how these services may be presented to a Java programmer, and how XML exchanges between distributed spaces may be augmented with transactional payloads. In addition, there are newly emerging business transaction standards specifically designed for loosely coupled environments where relaxation of ACID properties is a requirement. For example, BTP from OASIS. However, these standards tend to address the issues of message communication in a language neutral manner. Therefore, once again their is no standard API for Java programmers to use." Starting points for the work include the OASIS BTP specification, JSR 95, and JTA/JTS. "The key transaction technology for J2EE is JTA/JTS."
[October 23, 2001] "Java MARC Events [James]." From a posting of Bas Peters (2001-10-23). "James (Java MARC Events) is a free Java package that provides an event model for MARC records through Java callbacks. James is inspired by the Simple API for XML (SAX). Using James you can write programs that involve MARC records without knowing the details of the MARC record structure. James provides a sequential model to access a collection of MARC records in tape format. The goal of James is to provide a generic application interface to records that conform to the ISO-2709 exchange format. The MARCHandler interface provides methods to get information about the record label (record position 00-23), control fields (001-009) and data fields (010-999), including indicator values, tag names, subfield codes and data. The character encoding of the original records is preserved. Field data is returned in character arrays. The optional ErrorHandler interface provides methods to handle error messages. The current release of James does not support character conversions. Included with James are two sample programs. The com.bpeters.samples.TaggedPrinter program converts MARC records to a tagged display format and the com.bpeters.samples.XMLPrinter program builds a JDOM document out of MARC records and writes the JDOM document as XML to a file. The current version of James is beta 1. The release contains binary and source distributions. James is published under the terms of the GNU General Public License as published by the Free Software Foundation. Downloads and additional information can be found at http://www.bpeters.com. Related: "MARC (MAchine Readable Cataloging) and SGML/XML"; "BiblioML - XML for UNIMARC Bibliographic Records"; "bibteXML: XML for BibTeX"; "Medlane XMLMARC Experiment - MARC to XML." See the .ZIP distribution [cache]
[October 22, 2001] "Web Services Experience Language." By Angel Diaz (IBM Research), John Lucassen (Emerging Technologies, Application and Integration Middleware Division), and Charles F Wiecha (IBM Research). From IBM developerWorks, Web services. October 2001. "WSXL (Web Services Experience Language) is a Web services centric component model for interactive Web applications. WSXL is designed to achieve two main goals: enable businesses to distribute Web applications through multiple revenue channels, and enable new services or applications to be created by leveraging existing applications across the Web. To accomplish these goals, WSXL components can be built out of three basic Web service types for data, presentation, and control, the last of which is used to "wire together" the others using declarative language based on XLink and XML Events. WSXL also introduces a new description language for adapting services to new distribution channels. WSXL is built on widely accepted established and emerging open standards, and is designed to be independent of execution platform, browser, and presentation markup. Interactive Web applications that are developed using WSXL can be delivered to end users through a diversity of deployment channels: directly to a browser, indirectly through a portal, or by embedding into a 3rd party Web application. New Web applications can be created by seamlessly combining WSXL applications and adapting them to new uses. WSXL applications can easily be modified, adapted, aggregated, coordinated, synchronized or integrated by simple declarative means to ultimately leverage a worldwide pallet of WSXL components... WSXL is the next piece of the Web services stack. WSXL provides a Web services standards based approach for Web application development, deployment and maintenance. WSXL enables Dynamic e-Business, by moving from transactions driven by a single business entity to a world of electronic transactions involving multiple business entities who compose and aggregate re-usable Web applications. As a result, these applications can leverage new and innovative revenue models." WSXL is being contributed by IBM to the work of the OASIS WSCM Technical Committee; see the news item "OASIS to Develop Interactive Web Applications Standard Through a Web Services Component Model (WSCM)."
[October 22, 2001] "Microsoft and Sun Heat Up the Web Services Race." By Tom Sullivan and Ed Scannell. In InfoWorld October 22, 2001. "Microsoft and Sun Microsystems are racing to make major Web services announcements this week, making it clear that users will soon receive the components needed to build Web services. At the same time, users are clamoring for the flexibility to mix and match emerging building blocks. Microsoft will advance its Web services cause at its Professional Developer's Conference (PDC) in Los Angeles this week, while to the north, in Santa Clara, Calif., Sun will parry Microsoft with an event aimed at positioning some of its own Web services pieces. Fortifying its Web services strategy, Microsoft will announce at PDC that its Visual Studio.NET toolkit has entered the Release Candidate stage and will be released to manufacturing by the end of the year, said Eric Rudder, senior vice president of the development and platforms evangelism division at Redmond, Wash.-based Microsoft. Microsoft will hand out code for the Visual Studio.NET Release Candidate; ASP.NET, a Web services development platform for ASPs (Active Server Pages); the .NET Framework, an XML Web services integration engine; and the .NET Compact Framework for handheld devices, embedded operating systems, and devices without operating systems, Rudder said. Sharing the spotlight at PDC will be an SDK for HailStorm, the code-name for .NET My Services, said an industry source. A bundle of online personal productivity applications, .NET My Services is going live this week, meaning that some Microsoft partners will be able to begin using it and developers will be able to start writing applications for it, according to the source. With the goal of helping users mix and match best-of-breed Web services, Microsoft's upcoming .NET My Services is essentially a collection of 14 components made up of new services such as .NET Presence and .NET Location, along with pieces that make up its Outlook mail client such as .NET Calendar, .NET Contacts, .NET Inbox, and .NET Lists... Sun will position its own Web services software via its Palo Alto, Calif.-based subsidiary, iPlanet, which plans to integrate an instant collaboration platform into its Portal Server product. The iPlanet Portal Server Instant Collaboration Pack is designed to bolster the portal server's current collaboration capabilities with the addition of instant messaging, file sharing, polling functionality, and real-time alerts. Real-time communication services embedded within the portal will open up collaborative possibilities for workers and will allow project teams to reach decisions faster, according to iPlanet officials. iPlanet's conglomeration of software servers work in conjunction with Sun's SunONE strategy as a Web services platform..."
[October 19, 2001] "Extracting UML Conceptual Models from Existing XML Vocabularies." Presentation to be given by Dave Carlson, 29-October-2001 at the UBL Meeting in Menlo Park, California. "This talk will review specific examples of reverse engineering UML conceptual model diagrams from several xCBL SOX modules, e.g., Catalog, Order, TradingParty, and Auction. The goal of this prototype work is to extract an accurate vocabulary structure that is independent of the schema implementation language. The resulting UML models can be more easily reviewed, refined and submitted as an initial library of ebXML Core Components..." From a posting by Jon Bosak to the UBL mailing list (October 18, 2001) [source]. Related references: (1) "UML/XML Submissions for the UN/CEFACT eBTWG 'UML to XML Design Rules' Project"; (2) "UML to XML Design Rules Project"; (3) "Conceptual Modeling and Markup Languages"; (4) "Universal Business Language (UBL)."
[October 19, 2001] eBTWG - Scope and Requirements for UML2XML Design Rules." UN/CEFACT/CSG/eBTWG UML2XML Design Rules project. Preliminary Draft. Revision #1. October 17, 2001. Posted by Frank Vandamme. The document [graphic] "visualizes the relationship between the major concepts of the UN/CEFACT EBTWG e-Business architecture that are relevant to the UML2XML project scope. The text explains this picture, identifies the elements that are part of the UML2XML project scope and identifies their relation with other eBTWG projects. (1) Storage of standards development models: Under normal conditions all standards development will be done according to the UMM-methodology, leading to a set of UML-models that describe the business collaborations, the business processes and the business information. These models will be stored in the 'BPI Model Store' in a format that allows the exchange of these models. This requirement is currently being defined in the BPIMES-project (Business Process and Information Model Exchange Scheme). The UML2XML project will support the BPIMES-project by investigating the suitability of XMI and RDF as the format to store and retrieve these models. (2) Storage of Core Components and related elements: Core Components (CCs) are discovered based on so-called 'Business Information Entities' (BIEs). These BIEs are either extracted from business information models that are based on the UMM-approach or from legacy documents that describe existing standards. In both cases a discovery, analysis and harmonization process will lead to the definition of Core Components and Contexts. BIEs, CCs and context are all stored in the 'CC Store' in line with the technical specifications defined by the Core Components project. The UML2XML project will support the Core Components project by investigating the suitability of XMI as the format to store and retreive these elements. (3) Storage of formal specifications for e-Business solutions: e-Business solutions are formally described in a Business Process Specification Scheme (BPSS). This BPSS contains the process steps that will be executed in an e-Business solution and references the documents that need to be exchanged during these process steps. The documents to be exchanged are formally described in 'Assembly Documents' that refer to the used CCs and BIEs. The definition of a BPSS and its Assembly Documents will normally be the result of the UMM-approach, continuing from the Business Process and Information Models. Nevertheless, the possibility to define both BPSS and Assembly Documents in a manual way must be considered as well. Both BPSS and Assembly Documents are stored in a 'BP Specification Store'. The UML2XML project will support the BPSS project at two levels: By investigating the suitability of XMI as the format to store and retrieve the BPSS and the Assembly Documents [and] by defining a set of design rules to generate the BPSS and Assembly Documents from the Business Process and Information Model... (4) The UML2XML project will support message realization at following levels: (a) By defining rules and guidelines on the syntax-neutral definition of Assembly Documents and their relation to CCs and BIEs; (b) By defining the set of meta-information that is required to realize a Payload Definition in XML; this meta-information will be stored in the CC Store; (c) By defining a set of design rules to convert syntax-neutral BIEs into an XML-realization..." See the context and source. Additional references: see background discussion in the archives of the "UML to XML Design Rules Project."
[October 19, 2001] "Modeling XML Vocabularies with UML: Part III." By Dave Carlson. From XML.com. October 10, 2001. ['The third and final part of Dave Carlson's series on modeling XML vocabularies covers a specific profile of UML for use with XML Schema, and describes how UML can contribute to the analysis and design of XML applications.' See previously Part I and Part II.] "This article is the third installment in a series on using UML to model XML vocabularies. The examples are based on a simple purchase order schema included in the W3C XML Schema Primer, and we've followed an incremental development approach to define and refine this vocabulary model with UML class diagrams. The first objective of this third article is to complete the process of refining the PO model so that the resulting schema is functionally equivalent to the one contained in the XSD Primer. The second objective is to broaden our perspective for understanding how UML can contribute to the analysis and design of XML applications... The following list summarizes several goals that guide our work. (1) Create a valid XML schema from any UML class structure model, as described in the first two parts of this series. (2) Refine the conceptual model to a design model specialized for XML schema by adding stereotypes and properties that are based on a customization profile for UML. (3) Support a bi-directional mapping between UML and XSD, including reverse engineering existing XML schemas into UML models. (4) Design and deploy XML vocabularies by assembling reusable modules. Integrate XML and non-XML information models in UML; to represent, for example, both XML schemas and relational database schemas in a larger system... Even this relatively narrow scope covers a broad terrain. The following introduction to a UML profile for XML adds a critical step toward all of these goals. These extensions to UML allow schema designers to satisfy specific architectural and deployment requirements, analogous to physical database design in a RDBMS. And these same extensions are necessary when reverse engineering existing schemas into UML because we must map arbitrary schema structures into an object-oriented model... One of the benefits gained by using UML as part of our XML development process is that it enables a thoughtful approach to modular, maintainable, reusable application components. In the first two parts of this series, the PurchaseOrder and Address elements were specified in two separate diagrams, implying reusable submodels. UML includes package and namespace structures for making these modules explicit and also specifying dependencies between them... A package, shown as a file folder in a diagram, defines a separate namespace for all model elements within it, including additional subpackages. These UML packages are a very natural counterpart to XML namespaces. A dashed line arrow between two packages indicates that one is dependent on the other. When used in a schema definition, each package produces a separate schema file. The implementation of dependencies varies among alternative schema languages. For DTDs they might become external entity references. For the W3C XML Schema, these package dependencies create either <include> or <import> elements, based on whether or not the target namespaces of related packages are equal. A dependency is shown from the PO package to the XSD_Datatypes package, but an import element is not created because this datatype library is inherently available as part of the XML Schema language. This object-oriented approach to XML schema design facilitates modular reuse, just as one would do when using languages such as Java or C++..." See: "Conceptual Modeling and Markup Languages."
[October 19, 2001] "tML Guidelines for Mapping UML Notation to XML Schemas and Vice Versa." Telecommunications Markup Language. PROJECT T1M1-26. Document T1M1/2001-100R3. Submitted for eBTWG work by Raymond E. Reeves. "This technical proposed standard provides guidelines for defining Telecommunications Markup Language (tML) Schemas based on Unified Modeling Language (UML) notation design models and vice versa. This work is proposed to help TMN paradigm independent design models to be mapped with little or no effort to an Extensible Markup Language (XML) implementation. Efforts underway in the ANSI T1 and ITU-T bodies to create implementation independent models will take advantage of this recommendation." From followup comments: "...the draft standard prepared by T1M1 tries to address the UML and XML Schema mapping from a bi-directional standpoint. Though the document is organized from a UML viewpoint (UML2XML view?, i.e., model management view, static view, etc.), it purports to provide all necessary rules for doing round-trip engineering. Next version (release 4) will describe, in a more explicit fashion than the up to now implied, 'UML Profile for XML Schemas' used throughout the document. The importance of this effort within T1M1 and ITU-T (because it is an ITU-T work item) lies in the fact that many other T1M1 (and, why not?, ITU-T) XML-ization efforts (e.g., Service Ordering, Trouble Administration, DSL Service Provisioning, etc.) use a model-driven approach where a UML model is prepared from which a t/XML Schema is prepared following the guidelines stated by the T1M1 UML to XML Schemas, and vice versa, draft standard..." See also the note by Dave Carlson: "I've taken a quick read through your T1M1 mapping spec and it is very similar to my approach. My default mapping is aligned with the schema production rules in the XMI spec, but with a few additions. For example, XMI requires a role name on every navigable association end. And the schema includes a container element for this role, and a content element for the destination class. I've found that many schema designers want to create more compact vocabularies that omit the container element or make the destination class name anonymous. Both of these extensions can be made without modifying the UML conceptual model itself, but specifying preferences in the schema generator. Or by setting properties only on the top-level UML model or packages. So this retains the goal of technology indepencence that has been stated in other messages. I share that goal..." See (1) "UML to XML Design Rules Project", and (2) "Telecommunications Markup Language (tML)." [alt URL, cache]
[October 18, 2001] "Using the Sun Multi-Schema XML Validator." By Kohsuke Kawaguchi. Sun Developer's Notebook. October 2, 2001. ['Learn about the latest version of the Sun Multi-Schema XML Validator (MSV), a Java technology tool for validating XML documents against XML schemata.'] Sun's Multi-Schema XML Validator (MSV) software has two faces (and many uses). First, the MSV is a command-line tool to validate XML documents for those who write XML by hand. We designed the MSV to produce high-quality error messages by diagnosing situations where an error occurs. Since some of the modern schema languages are hardly legible, you can't expect all the document authors to read schemas. Therefore, you want to know what caused an error and how it can be fixed, without reading the schema file closely. Second, the MSV serves as a Java technology-based library that you can use for schema-related tasks. For developers, this face of the MSV is potentially more interesting. Probably the most important task is the validation. In this article, I'll explain how you can use the MSV as the validator in your application. The XML MSV is available for download... The MSV is designed to support more complex tasks than simple validation. For example, some tools read a schema and then do something smart, such as produce a nicely formatted documentation, perform stronger error checks, or generate Java source code. All those programs involve schema parsing, and you can use the MSV for that purpose. Other tools such as XML editors provide a list of possible tag names whenever you type '<' or they provide a list of possible attributes when it's appropriate. These applications require a customized validating mechanism, and you can use the MSV for that as well. The most likely use of the MSV is as a validator. Whenever you develop an application that receives XML from the other programs, you need to validate the document. You can rely on an XML parser to do this, but usually there are some problems in doing so. (1) Your XML parser limits your choice of schema language. Most of the available XML parsers provide very limited options when it comes to schema language. This will sometimes force you to adopt a schema language that is too complex to use, or a schema language that is too weak to capture all the constraints. (2) In most cases, there is no easy way to cache schemas. When you develop an application, typically it validates countless documents against a single schema. Since parsing a schema is not a cheap operation, you want to parse it once and use it again and again for performance reasons. But XML parsers usually do not provide a way to do this. (3) Why do you want to validate documents? To protect your application from irregular documents. To do this, you need to apply your own schema to them, not the one designated by them. Take DTD as an example; an XML document can modify DTD internally in whatever way desired by using the feature called DTD internal subset. But you definitely don't want the documents to modify the rule itself. However, most XML parsers do not provide the functionality to apply your own schema without any interference from documents. (4) Sometimes you want to validate part of the document. And sometimes you want to validate a document before you send it to somebody else. The validation engine in a typical XML parser cannot be used for these purposes. So there are certain merits in using a standalone validation engine, like the MSV... Schema technology for XML is gradually maturing, but it's still hard to tell which schema languages will be widely used. I hope the MSV will provide you an opportunity to experiment with various schema languages and will help you pick the right one for your needs." See "Sun Microsystems Releases Generalized Schema-Related Tools for Validation and Conversion."
[October 18, 2001] "Evolution or Revolution? Standardizing XML Technology." By Kammie Kayl. From Sun [java.sun.com] Features. October 04, 2001. "Dozens of exhibitors and hundreds of attendees spoke the language and shared the possibilities of XML (Extensible Markup Language) technology at the XML One/Web Services One conference this week. As the exhibitors showed their wares, attendees got a glimpse of the near future -- the necessity for more software vendors, software developers and publishing houses to cooperate and provide a service-based value chain to millions. Attendees saw many components of a web service, but it is clear that the construction of the bridges that will seamlessly link businesses and consumers within a vast Web service network has just begun. Bill Smith, director of Sun Microsystems' XML Technology Center, former president of OASIS (Organization for the Advancement of Structured Information Standards) and member of the former ebXML initiative executive committee, delivered a keynote speech to IT professionals, publishers and passionate software developers using XML technology. During the keynote, 'The Importance of Standards on the Road to Web Services,' Smith painted a broader picture of how XML fits into our world. He posed a business case for deploying XML and JavaTM technologies. He continued by explaining how XML technology stacks up. 'The XML stack,' as Smith put it, is comprised of six layers. The base layer, the Web framework, is comprised of the basic Internet protocols such as TCP/IP, HTTP and DNS. On top of that is the next horizontal layer, called XML core processing, which would be XML itself, including XSLT and schemas. The third layer is basic XML functions. The fourth layer, horizontal XML vocabularies, includes things like ebXML and Scalable Vector Graphics. This layer meets a horizontal dotted line. Above the dotted line lives the horizontal Web services functions such as SOAP, UDDI, WSDL. The top layer is comprised of many smaller vertical language modules. Vertical industries such as OTA, RosettaNet and eDub will define this layer, i.e., how to use the technology for business transactions. 'Now, many systems have dependencies on many parts of this stack. It is critical for the stack to be stable and unambiguously defined,' said Smith. According to Smith, work on the stack is nearly done, with many V1.0 specifications approved and some up to V2.0..."
[October 18, 2001] "HL7 ebXML Demonstration Overview. Introduction for HL7." By Todd Freter (XML Technology Center, Industry Initiatives, Sun Microsystems, Inc.) October 2, 2001. 17 pages. "Health Level 7 (HL7) is a non-profit consortium dedicated to the development and publication of protocol specifications for application level communications among diverse health data acquisition, processing, and handling systems. This annotated presentation by Todd Freter of the Sun XML Technology Center provides an overview of HL7's ebXML proof-of-concept demonstration. ebXML: [The author describes who launched the ebXML initiative, who is supporting it, and where to go for basic information; presents the five layers of the ebXML e-business framework, starting at the highest level and descending down to the wire-level. It also mentions the technical architecture description and quality review process, which keep the effort honest...; makes the point the ebXML enjoys support and participation from around the globe, and that the effort has garnered several important endorsements.... showsprovides the phases in which ebXML is delivering its work products. In May 2001, ebXML voted to accept all of its specifications either as full specifications or as technical reports to be developed into full specifications. Since then the ongoing work has been divided between the UN and OASIS... It's important to note that the technical effort is also motivated by a desire to enable second- and third-world economies to participate in the internet economy without having to incur the high cost of EDI. To that end, the notion of royalty-free licensing of ebXML specifications is a key consideration..." See "Electronic Business XML Initiative (ebXML)" and (2) "Health Level Seven XML Patient Record Architecture." [cache]
[October 18, 2001] "Joint Venture XML Message Specification." ACORD Corporation. Version 2001.1. September, 2001. 62 pages. "The Joint Venture Insurance and Reinsurance Service Business Message Specification provides the insurance industry with a common set of Business Level Messages that may be used to provide message-processing services across multiple organizations and networks. This document defines the information that must be sent in a message from a business perspective and provides message semantics. This document provides the basis for business-level information flow reinsurers, intermediaries, cedents and third party Service Providers. This document is intended to be independent of any technology implementation but it is expected that the creation of technology-specific standards for the industry will use this document during the definition process. It identifies logical groupings of information that can then be expressed in a given technology, today in particular, XML... The Joint Venture Data Dictionary includes data defined by JV partners (and their memberships) for the areas of placing, technical accounting, claims advice and payment, financial accounting, and the supporting areas of bordereau and transactions used for responses/updating references and processing indicators When defining data for this dictionary, JV's primary aim was to clearly express the data standard that had been agreed by business users and implementers over a number of years when the specific JV messages and implementation guidelines were developed. Throughout the creation of the dictionary elements, the JV has maintained a mapping the XML and EDIFACT standards to assist developers in designing software that may need to exchange information with existing EDIFACT standards-based systems. Joint Venture XML Document Type Definition This specification, in conjunction with the JV data dictionary, has been compiled into a Document Type Definition (DTD) file... While the important foundations of the IFX Specification, including data types, elements, aggregates, messages, transactions, services, naming conventions, usage rules, and documentation conventions are in the IFX specification, anywhere where the JV deviated from those conventions is documented below, as far as possible. JV acknowledges any and all copyrights owned by IFX Forum. Note that attributes are expressed in this specification by ='value' and the actual values are found in the JV codelists... The Joint Venture Insurance and Reinsurance Service Business Message Specification is the result of a cooperative industry effort of JV members including ins/reinsurers, ins/reinsurance intermediaries, clients/cedents and technology service providers. It leverages existing JV EDIFACT messages, a JV data dictionary and data model and the IFX Specification to provide the definition of business messages to be used by the insurance industry using electronic commerce to conduct the business of insurance..." Source: 'Joint Venture XML Specification, DTD and Transaction Templates'. See also the XML DTD and the news item.
[October 18, 2001] "XML Events. An Events Syntax for XML." W3C Working Draft 16-October-2001. Edited by Shane McCarron (Applied Testing and Technology, Inc.), Steven Pemberton (CWI), and T. V. Raman (IBM). Version URL: http://www.w3.org/TR/2001/WD-xml-events-20011016. Latest version URL: http://www.w3.org/TR/xml-events. Also PDF version and ZIP archive. ['The HTML Working Group has released the fourth public Working Draft of XML Events. The specification was renamed from XHTML Events, with significant changes. It defines a module used to associate behaviors with document-level markup through DOM Level 2 event model support.'] "The XML Events module defined in this specification provides XML languages with the ability to uniformly integrate event listeners and associated event handlers with Document Object Model (DOM) Level 2 event interfaces. The result is to provide an interoperable way of associating behaviors with document-level markup... An event is the representation of some asynchronous occurrence (such as a mouse click on the presentation of the element, or an arithmetical error in the value of an attribute of the element, or any of unthinkably many other possibilities) that gets associated with an element (targetted at it) in an XML document. In the DOM model of events, the general behavior is that when an event occurs it is dispatched by passing it down the document tree in a phase called capture to the element where the event occurred (called its target), where it then may be passed back up the tree again in the phase called bubbling. In general an event can be responded to at any element in the path (an observer) in either phase by causing an action, and/or by stopping the event, and/or by cancelling the default action for the event at the place it is responded to..."
[October 17, 2001] "WebDAV Protocol Comes Of Age. Technology for collaboration via the Web arrives." By Cathleen Moore. In InfoWorld October 12, 2001. "Incubating in the standards process for several years, the WebDAV (Web-based Distributed Authoring and Versioning) protocol -- designed to add interoperability and collaborative capabilities to the Internet -- has been steadily making its way into the everyday tools of business users and stands poised to transform how users interact with the Internet. WebDAV is a set of extensions to the HTTP protocol that allows users to collaboratively edit and manage files on a remote Web server. Whereas the Internet historically has been limited to display and download capabilities, WebDAV embedded in software and systems promises to turn the Internet into a writable medium capable of supporting collaboration and distributed file sharing. The protocol, which is still being refined and tweaked through the Internet Engineering Task Force (IETF) standards process, has some features that include locking and unlocking capabilities to prevent the overwriting of changes, XML properties for the storage of metadata, and namespace manipulation capability copying and moving data. To ensure security, WebDAV adds SSL (Secure Sockets Layer) technology and wraps all transmissions in 128-bit encryption. Other important features that are being developed include version control and the ability to set access control lists. Among the many potential applications of WebDAV, secure Web-based file sharing holds the biggest promise for business users...for example, multiple remote workers using WebDAV-enabled systems and software can collaborate on shared documents wherever they are as long as they have Internet access. Other potential uses for WebDAV include editing contents of a document management system via the Web and virtual product development across distributed enterprises, according to observers. The protocol is just now at a stage of maturity, providing useful function in products that are currently hitting the market, [Bill] North says. A diverse array of vendors are embracing WebDAV across applications, software, servers, and OSes... Oracle currently supports WebDAV in iFS (Internet File System) and plans to add WebDAV functionality to Release 2 of its Oracle 9iAS Portal product, due by the end of the year... Microsoft for its part has built WebDAV support into its many products, including SharePoint Portal Server, Office XP, and Windows XP, which is due to be formally rolled out this month. WebDAV support integrated into Windows XP is notable because it enables any application running on top of it to be WebDAV-enabled as well... Other OSes from Apple and Novell are also taking advantage of WebDAV's collaborative functionality... Another vendor leveraging WebDAV is San Jose, Calif.-based Adobe Systems. The newest edition of Adobe Acrobat, Version 5.0, takes advantage of WebDAV to allow users to collaborate on and edit PDF documents via the Web. Using the WebDAV functionality embedded in Acrobat 5.0, a user viewing a PDF file can upload comments and edits to a shared data repository, which can be tapped by and added to by other workers connected to the Web server..." See "WEBDAV (Extensions for Distributed Authoring and Versioning on the World Wide Web."
[October 16, 2001] "Versioning Extensions to WebDAV." IETF Internet-Draft. Reference: 'draft-ietf-deltav-versioning-18'. September 11, 2001; Expires March 11, 2002. 106 pages. By Geoffrey Clemm (Rational Software), Jim Amsden (IBM), Tim Ellison (IBM), Chris Kaler (Microsoft), and Jim Whitehead (U.C. Santa Cruz). ['The IESG has approved the Internet-Draft 'Versioning Extensions to WebDAV' (draft-ietf-deltav-versioning-18.txt) as a Proposed Standard. This document is the product of the Web Versioning and Configuration Management Working Group. The IESG contact persons are Ned Freed and Patrik Faltstrom.'] Abstract: "This document specifies a set of methods, headers, and resource types that define the WebDAV Versioning extensions to the HTTP/1.1 protocol. WebDAV Versioning will minimize the complexity of clients that are capable of interoperating with a variety of versioning repository managers, to facilitate widespread deployment of applications capable of utilizing the WebDAV Versioning services. WebDAV Versioning includes: (1) Automatic versioning for versioning-unaware clients, (2) Version history management, (3) Workspace management, (4) Baseline management, (5) Activity management, and (6) URL namespace versioning." Namespace, etc: The DAV:href XML element is defined in RFC 2518, Section 12.3. Although WebDAV request and response bodies can be extended by arbitrary XML elements, which can be ignored by the message recipient, an XML element in the DAV namespace must not be used in the request or response body of a versioning method unless that XML element is explicitly defined in an IETF RFC... A 'precondition' of a method describes the state on the server that must be true for that method to be performed. A 'postcondition' of a method describes the state on the server that must be true after that method has completed. If a method precondition or postcondition for a request is not satisfied, the response status of the request must be either 403 (Forbidden) if the request should not be repeated because it will always fail, or 409 (Conflict) if it is expected that the user might be able to resolve the conflict and resubmit the request. In order to allow better client handling of 403 and 409 responses, a distinct XML element type is associated with each method precondition and postcondition of a request. When a particular precondition is not satisfied or a particular postcondition cannot be achieved, the appropriate XML element must be returned as the child of a top-level DAV:error element in the response body, unless otherwise negotiated by the request. In a 207 Multi-Status response, the DAV:error element would appear in the appropriate DAV:responsedescription element..." [cache]
[October 16, 2001] "Adobe Unveils its Metadata Framework -- XMP. [Adobe's XMP: Is it an End To Metadata Madness? Standards.]" By Mark Walter. In Seybold Report: Analyzing Publishing Technology [ISSN: 1533-9211] Volume 1, Number 13 (October 1, 2001), pages 3-4. ['When a database is more overhead than you want, Adobe's eXtensible Metadata Platform will let you keep metadata within each content file and transport it across applications. It bids fair to become a standard--there is no competing technology -- but you'll have to upgrade to use it... Recognizing the need to carry metadata inside of content files, Adobe has created a common framework that all of its desktop applications will use to embed metadata into the files they create. Will the eXtensible Metadata Platform (XMP) become as popular as PDF?'] "Adobe introduced the Extensible Metadata Platform (XMP) and announced that all of its products would use the framework to embed metadata inside the files they create. The first products to support XMP are Adobe Acrobat 5 and the upcoming InDesign 2 and Illustrator 10, but Adobe pledged to add XMP support to Photoshop, GoLive and eventually all of Adobe's desktop products. Equally interesting, Adobe is publishing the XML spec and giving away a developer's kit under open-source licensing in an effort to win wider support for XMP as an industry standard. As a platform, XMP includes more than just a definition of how to write labels. The four components at the time of the launch included: (1) XMP Framework. The XMP description component is a subset of the Resource Description Format (RDF) developed by the World Wide Web Consortium (W3C). (2) XMP Packets. For transporting the metadata from one program to another, Adobe's XMP packet technology also follows the W3C's lead. XMP packets are the means by which XML metadata are enclosed inside application files. (3) Schema. The actual categories and terms used in a label are defined in XML schemas. Adobe is proposing that XMP have 13 core schemas, including the Dublin Core, media asset management, digital rights, and others. XMP integrators can also include their own schemas for enclosure inside XMP packets. (4) Sample software. Reading this new binary format requires software. Adobe is seeding the market with a software development kit that's available free of charge under open-source licensing terms... XMP has a lot going for it as a potential standard. It has no competition yet and it also helps that Adobe has anticipated the need for user-definable schemas, and that it is following W3C conventions for the nitty-gritty details of how the bytes get written. On the downside, Adobe's basic metadata set will not be sufficient for many applications, so users -- in cooperation with their integrators -- will still have to define schemas and develop customizations, just as they do now. Another drawback is that XMP is not binary compatible with older applications -- all of your software in a workflow that touch an XMP file will have to be upgraded in order to read the file -- even if the application data inside would be recognized. For this reason, one of the first XMP utilities we'd like to see added to the SDK is a 'packet stripper' that removes the label. In short, it will take time for XMP's impact to be felt, but in the long run it should be a very positive step toward better metadata handling by Adobe's applications, and, if we're lucky, by others as well..." See: "Extensible Metadata Platform (XMP)."
[October 16, 2001] "SOAP Version 1.2 Test Collection." From the W3C XML Protocol Working Group. Edited by Hugo Haas (W3C) and Oisin Hurley (IONA Technologies). ['Demonstrating interoperability, the tests are intended to show that SOAP 1.2 meets its goal for conformance requirements, and that implementations exist for each of its features. Instructions are linked from the call for contributions.'] Abstract: "This document draws a list of testable assertions found in the SOAP Version 1.2 specification, and provides a set of tests in order to show whether the assertion is implemented in a SOAP processor. The goal of this document is to get a list of features whose implementation can be tested in order to satisfy the entrance criteria of the Proposed Recommendation stage. It is incorrect to claim to be compliant with the SOAP Version 1.2 specification by passing successfully all the tests provided in this test suite. An implementation which would pass all the tests below may claim to be compliant with the test suite dated 2001/10/12 21:14:17..." See "Simple Object Access Protocol (SOAP)."
[October 15, 2001] "The Design of RELAX NG." By James Clark. [October 15, 2001 or later] draft version of paper to be presented at XML 2001 in Orlando in December, 2001. URL: http://www.thaiopensource.com/relaxng/design.html. Abstract: "RELAX NG is a new schema language for XML. This paper discusses various aspects of the design of RELAX NG including the treatment of attributes, datatyping, mixed content, unordered content namespaces, cross-references and modularity." Excerpt: "RELAX NG is a schema language for XML, based on TREX and RELAX. At the time of writing, RELAX NG is being standardized in OASIS by the RELAX NG Technical Committee (TC). A tutorial and language specification have been published by the TC. This paper describes the thinking behind the design of RELAX NG. It represents the personal views of the author and is not the official position of the TC. RELAX NG is an evolution of XML DTDs. It shares the same grammar-based paradigm. Based on experience with SGML and XML, RELAX NG both adds and subtracts features relative to XML DTDs. The evolutionary nature of RELAX NG has a number of advantages. XML DTDs can be automatically converted into RELAX NG. Experts in designing SGML and XML DTDs will find their skills transfer to designing RELAX NG. Design patterns that are used in XML DTDs can be used in RELAX NG. Overall, RELAX NG is much more mature and it is possible to have a higher degree of confidence in its design than it would be if it were based on a completely different paradigm. A major goal of RELAX NG is that it be easy to learn and easy to use. One aspect of RELAX NG that promotes this is that the schema can follow the structure of the document. Nesting of patterns in the schema can be used to model nesting of elements in the instance. There is no need to flatten the natural hierarchical structure of the document into a list of element declarations, as you would have to do with DTDs (although RELAX NG allows such flattening if the schema author chooses). An XML DTD consists of a number of top-level declarations. Each declaration associates a name (the left hand side of the declaration) with some kind of object (the right hand side of the declaration). With some kinds of declaration (e.g., ELEMENT, ATTLIST) the name on the left hand side occurs in the instance, for others (parameter entity declarations) the name is purely internal to the DTD. Similarly, W3C XML Schema distinguishes between definitions and declarations. The name of a declaration occurs in an instance, whereas names of definitions are internal to the schema. RELAX NG avoids this complexity. RELAX NG has, in the terminology of W3C XML Schema, only definitions. There is no concept of a declaration. Names on the left hand side of a definition are always internal to the schema. Names occurring in the instance always occur only within the right hand side of a definition. This approach comes from XDuce..." See (1) OASIS RELAX NG Technical Committee and other references in (2) "RELAX NG."
[October 12, 2001] "XML Metadata Interchange (XMI). Response to the RFP ad/2000-01-04 for XMI Production of XML Schema." Joint Revised Submission by International Business Machines (IBM), Unisys, and SofTeam. OMG Document ad/2001-06-12. June 18, 20001. 164 pages. Send comments on this submission to [email protected]. All questions about the submission should be directed to Stephen A. Brodsky, Ph.D., International Business Machines Corporation, +1 (408) 463-5659. ['This submission is an extension to the XMI 1.1 specification, ad/99-10-02.'] From the Introduction: "XMI is a widely used interchange format for sharing objects using XML. Sharing objects in XML is a comprehensive solution that build on sharing data with XML. XMI is applicable to a wide variety of objects: analysis (UML), software (Java, C++), components (EJB, IDL, Corba Component Model), and databases (CWM). Over 30 companies have XMI implementations. XMI defines many of the important aspects involved in describing objects in XML: (1) The representation of objects in terms of XML elements and attributes is the foundation. (2) Since objects are typically interconnected, XMI includes standard mechanisms to link objects within the same file or across files. (3) Object identity allows objects to be referenced from other objects in terms of IDs and UUIDs. (4) The versioning of objects and their definitions is handled by the XMI model. (5) Validation of XMI documents using DTDs and Schemas. XMI describes solutions to the above issues by specifying EBNF production rules to create XML documents, DTDs, and Schemas that share objects consistently. XMI 1.1 defines production two kinds of production rules for sharing objects with XML: [A] Production of XML DTDs starting from an object model, and [B] Production of XML documents starting from objects. In addition to generating XMI 1.1 compliant Schemas, we have produced a mapping for how XMI looks if we used new features in Schemas that are not available in DTDs. Based on these experiences, we can recommend a course for XMI as well as suggest improvements to XML Schema. This new form, called XMI 2.0, is a successor to the XMI 1.1 form. With the recent work by the W3C in XML Schemas, a more comprehensive form of XML document validator, this submission adds these production rules: (1) Production of XML Schemas starting from an object model; (2) Production of XML Documents compatible with XML Schemas; (3) Reverse engineering from XML to an object model. MOF is the foundation technology for describing object models, which cover the wide range of object domains: analysis (UML), software (Java, C++), components (EJB, IDL, Corba Component Model), and databases (CWM). XMI is applicable to all levels of objects and metaobjects. Although this document focuses on MOF metaobjects, general objects may be serialized and interchanged with XMI. The term 'XML document' in this specification is equivalent to a general stream of XML data..." Also in PostScript and .ZIP/PDF format; see the document listing. References: "UML to XML Design Rules Project." [cache PDF]
[October 10, 2001] "SWIFTStandards XML Design Rules." Technical Specification. Version 2.3 5. September 5, 2001. 52 pages. Submitted [October 6, 2001] by Frank Vandamme to the UN/CEFACT eBTWG Open Process. ['Please find attached the SWIFT initial contribution on UML to XML design rules...'] From the document Introduction: "XML is a technical standard defined by W3C (the World Wide Web Consortium) and leaves a lot of freedom for the exact way it is used in a particular application. Therefore, merely stating that XML is used is not sufficient, one must also explain how it will be used. The use of XML is part of the overall approach for the development of SWIFTStandards. This development focuses on the correct definition of a business standard using modelling techniques. The resulting business standard is captured in UML (Unified Modelling Language 2 ) and is stored in an electronic repository, the "SWIFTStandards Repository" . Business messages are defined in UML class diagrams and XML is then used as a physical representation (i.e., the syntax) of the defined business messages. A set of XML design rules, called SWIFTStandards XML, define in a very detailed and strict way how this physical XML representation is derived from the business message in the UML class diagram. This document explains these XML design rules. The document does not explain how a message should be created in UML. It explains, once a message is created in UML, how it will be mapped into XML. [General mapping rules:] Mapping rules from UML to SWIFTStandards XML are governed by the following design choices: (1) SWIFTStandards XML representation to be as structured as possible: [Business information is expressed as XML elements/values. Metadata information is expressed as XML attributes. XML attributes are not to be conveyed 'on the wire' in the XML instance, unless required to remove ambiguity. (2) The current work is based on W3C's Recommendation of May, 2001. (3) The names used in SWIFTStandards XML are the XML names or, when absent, the UML names. (4) SWIFTStandards XML elements are derived from the UML representation of a business message. They can only be derived from UML-classes, UML-roles or UML-attributes. (5) Each SWIFTStandards XML element must be traceable to the corresponding UML model element. (6) Currently SWIFTStandards XML only runtime Schemas are generated. Runtime schemas only contains information required to validate XML instances. No documentation nore implementation information (e.g., elementID, version, etc.) is mentioned. ... SWIFTStandards XMLTag is assigned according to following rules: [1] For a SWIFTStandards XML element derived from a class if that class contains the stereotype <<message>>: the XML name of the class or by default the name of the class. [2] For a SWIFTStandards XML element derived from a role: The XML name of the role or by default the name of the role. If no rolename is specified in the UML model, the name (XML name or name by default) of the class which is at the end of the aggregation. [3] For a SWIFTStandards XML element derived from an attribute: (3) The XML name of the attribute or by default the name of the attribute. [Note: Classes that don't contain the stereotype <<message>> do not have a corresponding XML element.]..." References: "UML to XML Design Rules Project."
[October 10, 2001] "Bolero Document Modeling Conventions." By Phil Goatly (Bolero). October 2001. 31 pages. Submitted [October 5, 2001] by Phil Goatly to the UN/CEFACT eBTWG Open Process. "The following submission documents the modeling conventions used by Bolero in phase one of UML to XML conversion. They are submitted to the group in the knowledge that somethings could be done better. Currently we are working on phase 2 which involves schemas and changes to the conventions, as such, this document may be regarded as a prototype - but even prototypes have their uses. Many of the conventions used in this document will be changed in phase 2. The submission is submitted in the hope that it will stimulate discussion, and allow us to submit our thoughts on the future of the important topic of UML to XML production rules... BoleroXML makes a distinction between a message and a document. A document contains only data, whereas a message contains data and involves a sender and one or many receivers. This report is only concerned with data modelling for documents. The interface between this document model and the message model is construed via the parties who send the messages and by the data which they send. The document model is the 'data model' and the message model is the 'data flow model'. ... BoleroXML's key objective is for the document models to have no dependency on the technology solution used for implementation. This safeguards the use of document definitions against any impact from changing technology where changes can be addressed without having to redefine the underlying business requirements. In support of this objective, BoleroXML has chosen to model the requirements for these document definitions in Unified Modelling Language (UML), with a set of rules and conventions described in this document. UML was selected to support BoleroXML's vision of being able to house all definitions in a single repository, ensuring unambiguous data definitions and consistency across all documents. The goal is to be able to extract the document definition, by means of an automated conversion, from UML to any desired implementation tool.." [Note with submission to eBTWG: "Please find attached a submission from Bolero. This is a document showing our Phase one UML to XML documentation. It may be regarded as a prototype since we have learnt so much for producing 70+ documents for international trade using modeling conventions and the generator over the last 2 years. see our website for details We are now well into phase 2 of rationalisation of our modeling techniques and conventions-schemas - normalization etc. with many changes taking into account our 20/20 vision in hindsight and to correct thos things we which we got blatantly wrong... we are producing a normalised model of the international trade domain. From that every 'Trade Document" will be a view.i.e. Not all links will be seen on every document neither will every 'field' be seen. We have produced s/w to import the 'normalised database' into UML. We will then produce diagrams of 'documents' and our generator will work from these diagrams on a WYSIWYG basis. Our experience hase been to hide the complexities og UML from the BA and to generate DTDs etc. from the simple UML..."] See also the original .DOC/Word version and BoleroXML.
[October 10, 2001] "Pre-trade/trade -- Is Interoperability Achievable?" From SWIFT. "Securities participants left Sibos in San Francisco feeling generally upbeat about the possibilities for closer dialogue between SWIFT and FIX on aligning their respective standards. That feeling was vindicated in July when FIX Protocol Ltd. (FPL) and SWIFT announced an agreement to seek convergence of their respective messaging protocols. The agreement centres on the adoption of ISO 15022 XML as a common industry standard. Under the terms of the agreement, FPL and SWIFT will actively support the efforts of the ISO Working Group 10 (WG10), which aims to evolve the ISO 15022 scheme for securities message types to a single standard, expressed in XML. The agreement leverages the expertise of FPL in the pre-trade/trade domain and SWIFT in the post-trade domain. Both organisations will work to develop mapping documentation to support the industry's migration to ISO 15022 XML and the coex-istence of FIX, ISO 15022 and ISO 15022 XML... Interoperability and convergence are two compatible, though not necessarily linked approaches to that alignment. 'Interoperability would ease convergence but is not necessary to achieve it,' suggests panellist Jean-Marie Eloy , head of standards, SWIFT. 'I would define interoperability as the ability to transfer the technical format or syntax of one standard into the format of another, with defined syntax mapping rules using some kind of middleware. It also has to consider things like business process and work flow,' explains panellist John Goeller, director, CSFBNext, convener of the ISO 15022 XML Working Group and a long-time FIX participant. 'Convergence, on the other hand, means that two standards have combined into one through agreement of a common technical syntax and business process.' While aiming for convergence of standards, it is, says Mr Goeller, 'perfectly logical to start with how those standards will interoperate'..." [From: SWIFT Sibos Issues On-site, 15 - 19 October 2001] See "swiftML for Business Messages."
[October 06, 2001] "Possible Extensions to RELAX NG. DSDL Use Cases." By Martin Bryan (The SGML Centre). BSI IST/41. Posted to the RELAX-NG mailing list. "In talking to James Clark earlier today about the relationship between RELAX NG and the proposed new ISO Document Structure Definition Language (DSDL) James asked if I could provide some use cases that would justify the initial set of requirements that the DSDL proposal contained. The attached document starts by listing the requirements identified as being essential for DSDL, and then provides a set of use case statements that seeks to justify each requirement. It also contains brief use cases for supporting three optional features of SGML that are not supported by XML, and not listed as being requirements for DSDL, but for which cases can be made within data streams being used by businesses..." See: "Document Schema Definition Language (DSDL)." For schema description and references, see "XML Schemas."
[October 05, 2001] "Rewiring EDI: XML Makes New Connections." By Dave Hollander (CTO, Contivo Inc. in Mountain View, California. 'He is a co-inventor of XML and currently co-chairs the W3C XML Activity and Schema Work Group.'). In Application Development Trends Volume 8, Number 10 (October 2001), pages 25-30. Cover story. ['EDI may be forgotten by many, but it's still used by countless firms for B2B transactions. EIM aims to synchronize XML and EDI content and pave the way to a quicker, easier upgrade of the mature e-commerce systems.'] "As B2B e-commerce grows, trading partners seeking to capitalize on XML's benefits are moving to streamline and automate their relationships. With thousands of products and trading partners, many firms must support extremely reliable connections to ensure quick delivery and efficient operations. Yet, challenging the growth of B2B e-commerce is the complex task of linking applications between trading partners. Many companies are now aiming to eliminate this obstacle, which represents the potential for costly, time-consuming friction in the supply chain... The evolution has only just begun, and the transition from EDI to XML-based systems will not occur overnight. Many companies will migrate systems to XML-driven infrastructure only as standards consolidate and the technology stabilizes as the mainstay of business computing. One of the challenges facing companies looking to integrate EDI and XML-based systems is linking and synchronizing the business content, including the documents, policies and procedures that form the foundation of the two types of infrastructure. Firms planning to make the EDI-to-XML migration can apply a different technological approach--canonical modeling -- to create a smooth transition with a stable foundation for future adaptability and rapid deployment timelines.... Though EDI continues to dominate transactions between large enterprises, it is too expensive and cumbersome for small to mid-sized enterprises (SMEs) to adopt. Since many large firms seek to upgrade their SME vendors to electronic transactions, XML offers a viable communications channel. But XML itself is not a standard -- it is a way of expressing data that is particularly well suited to communities defining their own standards. The result is nearly 900 published XML schemas, all of which require a significant amount of EDI development unique to each firm using them... For example, manually programming a single link for a common business document such as a purchase order can require up to 40 hours and rare domain expertise of multiple EDI/XML standards. Multiplied by hundreds of transaction types and standards, the linking process becomes too cumbersome to be fast, flexible or practical. It is little wonder that EDI remains a trusted, reliable standard with ample vendor resources to ensure continued operations... But a new approach to B2B integration architecture can automate linking and synchronizing XML and EDI business content. Known as Enterprise Integration Modeling (EIM), this new integration approach leverages a repository-based model -- much like a thesaurus -- to automatically identify matches between business trading partners' business content, regardless of whether it is contained in an XML- or EDI-based system. By automating this critical process, EIM has the potential to accelerate adoption of XML-based trading partner networks, while preserving and leveraging vast corporate investments in EDI-based systems. So what is the technology that makes the EIM approach possible, and how can automation be applied to the tasks of connecting, linking and synchronizing business documents, policies and procedures between XML and EDI systems? [Modeling] Modeling and model-driven technologies enable teams to leverage their previous development efforts. In IT systems, model-driven technologies help automate the process of interconnecting systems and managing shared processes. Modeling, already broadly used in applications, is poised to take on increasing importance in interface development as it provides the means to directly impact the behavior of systems based on business models. Modeling technologies aggregate and reuse knowledge regarding the documents and processes that fuel business. This in turn enables tight integration with existing business systems without giving up flexibility and adaptability. For the emerging EDI-to-XML transition, modeling represents a primary method of transferring business rules and common business document information between applications and trading partners... Canonical modeling is an information architecture strategy to establish a shared, common view of business information by eliminating insignificant differences in the representation of enterprise data resources. Eliminating these redundancies in data representation improves the data integrity and greatly eases the translation of EDI systems to XML-based networks. If the basis for the canonical model is adopted from organized open standards, the value added to the enterprise data resources is increased. Done correctly, standards-based models benefit from the collective experience of the membership of the standards group; that is, defining the correct representation of data may have already been done by another member. So, if canonical modeling is a key component of an integration architecture, what should it look like? [...]"
[October 05, 2001] "EDI Plus XML Boosts B2B." By Michael W. Bucken. In Application Development Trends Volume 8, Number 10 (October 2001), page 4. [Editorial.] "Electronic Data Interchange, or EDI, long held promise as a worldwide business-to-business panacea. But for too many years, the technology was to complex and too pricey, among other things, to spread beyond the world's largest corporations that could afford to implement the technology for B2B transactions. While EDI never reached the heights predicted on-and-off over the past couple of decades, it remains a key technology in some very important locations. At the same time, the spread of Internet technologies through the late 1990s and beyond promised cheaper, less complex B2B technology for the majority of businesses large and small without the time or finances to implement an EDI network. The emergence of the Extensible Markup Language (XML) is promising to join the two worlds and connect EDI and Web-based B2B networks, significantly expanding the reach of all size firms with their suppliers and customers. The question for IT development managers is whether an integration of XML and EDI technology can only be done by hand -- a costly, complex and labor-intensive process. In this month's cover story ('Rewiring EDI: XML makes new connections'), consultant and XML guru Dave Hollander explains how a new integration approach called Enterprise Integration Modeling (EIM) can automate the linking and synchronizing of XML and EDI business content. The model-driven approach, Hollander wrote, can enable IT developers to leverage previous efforts and thus significantly cut labor costs. Hollander outlines the process of implementing EIM and hazards likely to be seen by development managers. Though he concludes EIM is a very important advance in B2B technologies, Hollander also notes that it's not a panacea. Nonetheless the falling B2B stars like Ariba and CommerceOne shouldn't sway corporations away from a B2B model. Despite the crash of a slew of B2B technology suppliers, the potential still exists for huge business benefits. But it's important to do it right. This story will help in the decision-making process..."
[October 05, 2001] "Meta Data Conundrum Carries On." By Richard Adhikari. In Application Development Trends Volume 8, Number 10 (October 2001), pages 49-53. [Data Management Feature Article.] "A new approach to managing meta data currently in the works will free CIOs from having to cope with constantly changing technological standards. The Needham, Mass.-based Object Management Group (OMG) is leading work on this approach with the support of major software vendors, including IBM, Sun Microsystems and Oracle. The new approach consists of a model-driven architecture that will transcend individual technologies so it will be valid even when underlying technologies change. To create the new architecture, its builders have expanded the meaning of meta data. They are also leveraging the object-oriented paradigm so that corporations can create reusable meta data objects from data about their existing resources -- including computer languages, file systems and software architecture--by wrapping the data with Extensible Markup Language (XML) descriptions. The new architecture will be the sole enterprise meta data management standard available because the OMG merged last year with another standards body, the Meta Data Coalition, whose efforts were built around Microsoft's Open Information Model (OIM), and OMG is merging OIM-based work with its own. But XML is fragmented, and pulling together cross-industry definitions is a Herculean task... While it does not matter which language the meta data is expressed in, XML has become the language of choice because it is a good means of transmitting data between different systems. One example of leveraging XML meta data wrappers is an application created by custom software developers Interface Technologies Inc., Raleigh, N.C., for a Boston-based client. The client, startup firm Virtual Access Networks, wanted an application that would help end users migrate personalization data such as bookmarks and address books from their existing desktop systems to new ones during upgrades. Normally, such data is not migrated during hardware or operating system upgrades... UML is a common modeling language for application development and it is an OMG standard. It was extended to create an object-oriented meta data standard, Meta Objects Facility (MOF). MOF consists of the core OO model from the Unisys repository, Urep, which was integrated with UML. MOF lets developers build meta data for the various domains in a consistent, object-oriented fashion, Brodsky said. IBM and other major vendors are working with the OMG to standardize these key meta data domains by creating models of the type of information to be obtained from the domains. The OMG's new approach will take meta data management to the next level. Called the Model-Driven Architecture (MDA), it is being built around MOF and UML. Until August 2000, there were two meta data management standards: the OMG's Common Warehouse Metamodel, and the Meta Data Coalition's Object Information Model (OIM), which was created by Microsoft. At the end of August, the OMG and Meta Data Coalition merged, and OIM is being subsumed by CWM. CWM is built on UML, XML and XMI. It establishes a common meta model (a model about models) for warehousing and also standardizes the syntax and semantics needed for import, export and other dynamic data warehousing operations. CWM supports data mining, transformation, OLAP, information visualization and other end user processes. Its specifications include application programming interfaces (APIs), interchange formats and services that support the entire life cycle of meta data management, including extraction, transformation, transportation, loading, integration and analysis... A whole slew of standards revolve around MDA. There is MOF, which lies at the core of MDA. Then there is the Java Meta data Interface (JMI), a mapping from MOF to Java. Because MOF is an abstract model, there are also mappings from MOF to XML and Interface Definition Language (IDL), an OMG standard for any CORBA environment, similar to Microsoft's and DCE's IDLs. MOF is an extension of UML; it ties in with CWM, which includes OIM. MOF will be integrated with J2EE, and a New York-based company called MetaMatrix is 'the first company that said they will do this integration,' Iyengar said. JMI will be integrated with J2EE..." References: (1) "OMG Model Driven Architecture (MDA)"; (2) "Object Management Group (OMG) and XML Metadata Interchange Format (XMI)"; (3) "OMG Common Warehouse Metadata Interchange (CWMI) Specification"; (4) "MDC Open Information Model (OIM)."
[October 05, 2001] "Is Openness Enough for IBM?" By Michael W. Bucken and Jack Vaughan. In Application Development Trends Volume 8, Number 10 (October 2001), pages 62-68. ['IBM broadens the effort to open its development and middleware technologies by supporting an ever-increasing list of standards led by Web services, XML and Java; targets Oracle, Microsoft in aggressive push. The article looks at IBM's evolving strategy for its middleware and development tools and services. As of this fall, the strategy revolves around an expanded WebSphere platform that encompasses everything from traditional development tools, to transaction processing monitors like CICS and Encina, to updated application servers. In this story, several top IBM Software Group executives explain the strategy and direction for the new WebSphere line with some important input from customers and analysts. The IBM folks maintain that the strategy could spell trouble for rivals like Oracle, BEA and Microsoft. We'll wait and see.] "The IBM development strategy today is, in a word, WebSphere. The strategy places IBM tools from myriad sources under the WebSphere moniker and reflects the Armonk, N.Y.-based computer giant's latest embrace of technology standards, open source technologies and a newfound willingness to join forces with a variety of suppliers. The strategy revolves around integrating existing systems and extending legacy systems to the World Wide Web using Web services, XML, Java and a variety of other middleware technologies. IBM is betting that standards-based technologies can solve the age-old quandary of connecting dissimilar systems...According to Mills, IBM's interoperability and e-business strategy prompted the acquisitions of Lotus and Tivoli, the aggressive development of application server technologies and the aggressive push to attack database leader Oracle Corp. with its DB2 Universal Database. The use of industry standards allows interoperability between these technologies, third-party offerings and potentially proprietary systems built by IT development operations. Mills and other IBM executives are quick to list the standards that contribute to the IBM interoperability strategy -- HTML, XML, J2EE, Web services and open source/Linux technologies. 'I can't emphasize the importance of open standards enough,' Mills said. 'The accumulation of IT stuff put in place over a couple of decades is not going away. The problem is fitting the new technologies in with the old. Open standards are critical to solving the problem.' Web services, based on industry standards like Simple Object Access Protocol (SOAP), Universal Description, Discovery and Integration (UDDI) and Extensible Markup Language (XML), are another key to their strategy. 'We view Web services as the most important issue in addressing software/application development,' said Irving Wladawski-Berger, IBM vice president of technology and strategy. 'Building applications by connecting reusable modules or objects -- that's the Holy Grail of development. Web services is the best chance we have to reach that Holy Grail.' Adds Rob Lamb, director of business process management at IBM, 'For IBM, Web services is about two things: integration and transactions. Both of those are strengths for IBM.' On the whole, IBM hopes that the effort will convince corporate users that its WebSphere software is open enough to seriously consider running on non-IBM hardware platforms and with non-IBM databases. Executives point to a contract signed last month calling for eBay Inc., San Jose, Calif., to use WebSphere as the technology foundation for the next version of its Internet auction and trading site... A slew of changes planned for the IBM line of development products will be formally revealed this fall, though IBM executives have been discussing the plans in recent months. The latest effort comes just about three years after IBM redeployed the bulk of its middleware offerings into WebSphere. Along with the Apache-based WebSphere application server, the MQSeries message-oriented middleware and some of mainstay transaction systems, CICS and Encina were added to the family, and responsibility for the transaction processing technology was brought into the development unit under John Swainson, whose latest title is vice president and general manager of IBM's application and integration middleware unit. The new WebSphere will include all of the middleware offerings, the VisualAge line of toolsets, all of the transaction processing technologies, portal technology from Lotus Development Corp., e-commerce technology from the DB2 unit, all of the current WebSphere products and perhaps isolated technologies from other units..."
[October 04, 2001] "The Role of XML in Electronic Commerce. Toward a Universal Business Language." By Jon Bosak (Chair, UBL Group; Designated Chair, OASIS UBL TC). Presented at Web Services Japan 2001, Yokohama [25 July 2001] and also for the XML Consortium of Japan, Tokyo [26 July 2001]. Posted to the OASIS UBL list ['[email protected]'] October 4, 2001 under the subject "The July UBL presentation." With comment: "As I noted during our UBL Group meeting in Montréal, the first mention of UBL to the general public came in a keynote speech on electronic commerce that I gave in late July at Web Services Japan 2001. Those of you who caught my earlier presentations at the March EWG meeting and the June X12 and OAGI meetings saw basically the same material. A colleague has just forwarded me a very nice two-page spread on this presentation from the September issue of Nikkei Open Systems, Japan's largest computer magazine. In keeping with the thrust of the talk, the report gives greatest prominence to ebXML, but I am pleased to see that several mentions of the UBL project came through as well. Since this presentation is probably the best set of slides on the subject that I will be able to assemble for a while, I have put a copy [online]. Feel free to forward this URL to anyone needing some background on the UBL initiative at this point..." Available in PDF format (both A4 and 8.5x11), as well as in XML and HTML-slides format. Japanese speakers: "Please see the article about this presentation in the September 2001 issue of Nikkei Open Systems, pages 242 and 243." On Universal Business Language (UBL), see (1) the [proposed] OASIS UBL TC web pages, and (2) the reference page "Universal Business Language (UBL)." For the relationship between OASIS UBL and UN/CEFACT eBTWG XBDL (both engaged in development of 'ebXML TNG'), see the current UBL and XBDL positioning statements from some of the principals. [cache PDF, A4, XML]
[October 04, 2001] UN/CEFACT/eBTWG Approved Projects. From Klaus-Dieter Naujok (UN/CEFACT/eBTWG & TMWG Chair). Posted to the UN/CEFACT eBTWG List ['[email protected]'] October 4, 2001 under the subject "Project Team Leads." Excerpt: "The [UN/CEFACT Electronic Business Transition Working Group] Executives are happy to announce a more complete list of project team leads. The previously announced project team leads include: (1) Core Component Specification -- Hartmut Hermes; (2) eBusiness Architecture Specification -- Duane Nickull; (3) Business Collaboration Patterns and Monitored Commitments Specification -- David Welsh. Having searched around and talked to many of the BP team members we have come to an agreement. The following eBTWG members have agreed to lead: (4) Business Process Schema Specification (Brain Hayes); (5) Business Collaboration Protocol Specification (Jim Clark); (6) Business Process Information Model Exchange Schema Specification (John Yunker); (7) Business Information Object Reference Library (Paul Levine); (8) UML2XML Design Rules Proposal (Frank Vandamme). We are currently awaiting confirmation from two companies/organization to support their members to lead: (9) XML Business Document Library; (10) Common Business Process Catalog. We will announce their names shortly. I hope you all join us in extending our support to those volunteers that have agreed to take on the responsibility of project team leaders..." References: See the UN/CEFACT Electronic Business Transition Working Group and the elists for lists.ebtwg.org.
[October 04, 2001] "SAP to Operate UDDI Registry." By Rick Perera. In InfoWorld (October 4, 2001). Business software maker SAP has announced plans to become an operator for the UDDI (Universal Description, Discovery and Integration) Business Registry. SAP will build, run, and maintain a global UDDI node, joining existing operators Microsoft, IBM, and Hewlett-Packard, Peter Barth, SAP's technology marketing director, said Thursday. The UDDI registry, billed as the first true Yellow Pages for the Web, seeks to make it easier for businesses to provide information about their products and services on the Web, as well as to locate partners and customers. Companies can submit information to the registry free of charge, to be posted using a common set of identifiers. The registries are replicated across all nodes on a regular basis, making the same data available to all users, but on a noncentralized basis. In addition to its role as an operator, SAP will let its customers register for the UDDI registry through its SAP Service Marketplace, integrating information from back-office systems into the registry..." See: (1) the announcement, "SAP Fully Embraces UDDI. SAP Becomes UDDI Business Registry Operator."; (2) the reference page, "Universal Description, Discovery, and Integration (UDDI)."
[October 4, 2001] "Extensible Provisioning Protocol." Internet Engineering Task Force (IETF) Internet-Draft. Reference: 'draft-ietf-provreg-epp-05.txt'. October 2, 2001. Expires: April 2, 2002. By Scott Hollenbeck (VeriSign Global Registry Services, Dulles, VA, USA). Abstract: "This document describes an application layer client-server protocol for the provisioning and management of objects stored in a shared central repository. Specified in XML, the protocol defines generic object management operations and an extensible framework that maps protocol operations to objects. This document includes a protocol specification, an object mapping template, and an XML media type registration." Notation: "EPP is specified in XML Schema notation. The formal syntax presented here is a complete schema representation of EPP suitable for automated validation of EPP XML instances." Details: "This document describes specifications for the Extensible Provisioning Protocol (EPP) version 1.0, an XML text protocol that permits multiple service providers to perform object provisioning operations using a shared central object repository. EPP is specified using the Extensible Markup Language (XML) 1.0 as described in [XML REC] and XML Schema notation as described in [W3C Schema Specs]. EPP meets and exceeds the requirements for a generic registry registrar protocol as described in [Generic Registry-Registrar Protocol Requirements]. EPP content is identified by MIME media type application/epp+xml. Registration information for this media type is included in an appendix to this document. EPP is intended for use in diverse operating environments where transport and security requirements vary greatly. It is unlikely that a single transport or security specification will meet the needs of all anticipated operators, so EPP was designed for use in a layered protocol environment. Bindings to specific transport and security protocols are outside the scope of this specification. This original motivation for this protocol was to provide a standard Internet domain name registration protocol for use between domain name registrars and domain name registries. This protocol provides a means of interaction between a registrar's applications and registry applications. It is expected that this protocol will have additional uses beyond domain name registration... EPP is an XML protocol that can be layered over multiple transport protocols. Protected using lower-layer security protocols, clients exchange identification, authentication, and option information, and then engage in a series of client-initiated command-response exchanges. All EPP commands are atomic (there is no partial success or partial failure) and idempotent (executing a command more than once has the same net effect on system state as successfully executing the command once). EPP provides four basic service elements: service discovery, commands, responses, and an extension framework that supports definition of managed objects and the relationship of protocol requests and responses to those objects." See (1) "Extensible Provisioning Protocol (EPP)" and (2) the proposed OASIS TC for "XML-Based Provisioning Services." [cache]
[October 03, 2001] "New Logistics Standard Launched." By Heather Harreld. In InfoWorld (October 3, 2001). "In an effort to eliminate one of the major barriers now plaguing the electronic logistics arena, Logistics.com has developed a logistics standard designed to allow multiple industry players and software programs to communicate more effectively. The Burlington, Mass.-based company, which markets software to help shippers and carriers buy, sell, manage, and optimize logistics, launched a logistics event management architecture this week designed to foster business process and integration standards in the logistics industry, according to company officials. The new system features tXML (TransportationXML) to enable standard application integration among all members of a logistics chain as well as intra-enterprise requirements between legacy and new systems. The backbone of the architecture, which is called Logistics Event Management Architecture (LEMA), is its message bus designed to integrate with more than 70 external business protocols such as EDI (electronic data interchange), HTTP, SOAP (Simple Object Access Protocol), and XML over the web. Logistics.com already has established the LEMA set of standards with many of its customers, said John Lanigan, Logistics.com CEO. The company now is seeking to expand LEMA participation through the endorsement of standards body, he added... LEMA will provide application integration, free flow of information, and the reduction of cycle time in processing logistics events, such as simultaneous offer and acceptance of shipment moves, according to company officials. It is designed to allow multiple organizations to process the same logistics event through independent workflows and customize their own specific view of that event's activity." See: "TransportationXML (tXML)."
[October 03, 2001] "XML in Java: Document models. Part 1: Performance. A look at features and performance of XML document models in Java." By Dennis M. Sosnoski (President, Sosnoski Software Solutions, Inc.). From IBM developerWorks. September 2001. ['In this article, Java consultant Dennis Sosnoski compares the performance and functionality of several Java document models. It's not always clear what the tradeoffs are when you choose a model, and it can require extensive recoding to switch if you later change your mind. Putting performance results in the context of feature sets and compliance with standards, the author gives some advice on making the right choice for your requirements. The article includes several charts and the source code for the test suite.'] "Java developers working with XML documents in memory can chose to use either a standard DOM representation or any of several Java-specific models. This flexibility has helped establish Java as a great platform for XML work. However, as the number of different models has grown it has become difficult to determine how the models compare in terms of features, performance, and ease of use. This first article in a series on using XML in Java looks at the features and performance of some of the leading XML document models in Java... The models are listed below with brief introductions and version information. Just to clarify the terminology used in this article: (1) parser means the program that interprets the structure of an XML text document (2) document representation means the data structures used by a program to work with the document in memory (3) document model means a library and API that supports working with a document representation. [...] Conclusions: The different Java XML document models all have some areas of strength, but from the performance standpoint there are some clear winners. XPP is the performance leader in most respects. For middleware-type applications that do not require validation, entities, processing instructions, or comments, XPP looks to be an excellent choice despite its newness. This is especially true for applications running as browser applets or in limited memory environments. dom4j doesn't have the sheer speed of XPP, but it does provide very good performance with a much more standardized and fully functional implementation, including built-in support for SAX2, DOM, and even XPath. Xerces DOM (with deferred node creation) also does well on most performance measurements, though it suffers on small files and Java serialization. For general XML handling, both dom4j and Xerces DOM are probably good choices, with the preference between the two determined by whether you consider Java-specific features or cross-language compatibility more important. JDOM and Crimson DOM consistently rank poorly on the performance tests. Crimson DOM may still be worth using in the case of small documents, where Xerces does poorly. JDOM doesn't really have anything to recommend it from the performance standpoint, though the developers have said they intend to focus on performance before the official release. However, it'll probably be difficult for JDOM to match the performance of the other models without some restructuring of the API. EXML is very small (in jar file size) and does well in some of the performance tests. Even with the advantage of deleting isolated whitespace content, though, EXML does not match XPP performance. Unless you need one of the features EXML supports but that XPP lacks, XPP is probably a better choice in limited-memory environments. Currently none of the models can offer good performance for Java serialization, though dom4j does the best. If you need to transfer a document representation between programs, generally your best alternative is to write the document out as text and parse it back in to reconstruct the representation. Custom serialization formats may offer a better alternative in the future."
[October 03, 2001] "Web Application Development with JSP and XML. Part IV: Using J2EETM Services from JSP." By Qusay H. Mahmoud. From Sun Java Developer Connection. October 2001. "The Java 2 Enterprise Edition (J2EE) is a standard that defines an environment for the development and deployment of enterprise applications. It reduces the cost and complexity of developing multitier enterprise applications as it provides a multitier distributed application model. In other words, it is inherently distributed and therefore the various parts of an application can run on different devices. Web applications developed using JavaServer Pages (JSP) may require some interaction with J2EE services. For example, a web-based inventory control system may need to access J2EE's directory services to gain access to a database. Or you may want to use Enterprise JavaBeans (EJB) in your application. This article presents a brief overview of J2EE, then it shows how to: (1) Describe J2EE services in a Web Deployment Descriptor [web.xml]; (2) Reference J2EE services; (3) Access and use J2EE services from JSPs... The J2EE is a standard platform for the development and deployment of enterprise applications. The architecture of J2EE, which is component-based, makes developing enterprise applications easy because business logic is organized into reusable components and the underlying service is provided by J2EE in the form of a container for every component type. Think of a container as the interface between the component and the low-level functionality that supports the component. Therefore, before an application client component can be executed, it must be configured as a J2EE service and deployed into its container... J2EE offers many services that are invaluable for Web applications. These services range from opening a connection to a database using JDBC, to sending an email, to accessing and using enterprise beans. This article, along with sample programs, shows how to access J2EE services from within JSPs. Incorporating EJBs into your JSPs can be easily done, creating a reusable solution by developing custom tags. Why don't we access J2EE services from Servlets? While it is possible to do that, you would end up writing more unreusable code. If you wish to use J2EE services from JSPs, developing custom tag libraries provides reusable solutions that can even be used by content developers who have no Java experience..."
[October 03, 2001] "XML Security for Multipart MIME: Multipart/Signed and Multipart/Encrypted." IETF Network Working Group, Internet Draft. Reference: 'draft-fhirsch-xml-mime-security-00'. October 1, 2001. Expires: April 1, 2002. By Frederick Hirsch (Zolera Systems). Abstract: "This draft defines how XML Digital Signatures and XML Encryption may be used with Multipart MIME security to provide MIME integrity and confidentiality. It extends RFC 1847 by defining application/signature+xml and application/encryption+xml protocols for the Multipart/Signed and Multipart/Encrypted MIME types. Although non-XML content may be signed or encrypted based on XML signing and encryption, additional capabilities are available for XML MIME content. This draft defines a signature transform parameter for partial signing or manipulation of XML MIME content as well as processing rules in addition to the XML Digital Signature and XML Encryption processing rules." From the Introduction: "RFC 1847 defines a general mechanism for security multiparts in MIME, defining the Multipart/Signed and Multipart/Encrypted types. This mechanism uses a protocol parameter to specify the signature or encryption mechanism. Multipart/Signed enables the first MIME part to contain arbitrary MIME content and the second to contain a signature over that content. Common mail applications currently use application/x-pkcs7-signature as the signing protocol, creating a PKCS#7 signature in the signature part. Multipart/Encrypted uses the first part to contain encryption control information, and the second part encrypted content. An alternative to Multipart/Encrypted is to pass a single MIME part containing encrypted content using using application/x-pkcs7-mime, as done by common mail applications. XML DIGITAL SIGNATURE and XML ENCRYPTION recommendations enable signing and encryption of arbitary content as well as providing advanced support for XML content. This includes the ability to sign or encrypt portions of XML, reference multiple objects in a signature and include metadata information with signed or encrypted content. XML signatures support multiple signatures, useful when content is routed for approvals. Both XML Signatures and Encryption support inclusion of the signature or encrypted content in the orginal XML document, creating a close binding. Signatures may also be separate from the signed content, especially useful when the content is large or binary and would interfere with XML processing of the signature. Likewise, encrypted cipherdata may be included in an XML encrypted element or managed separately. Combining the XML security mechanisms with Multipart MIME security enables MIME applications to benefit from XML security as well as enabling XML security to use a defined mechanism for handling multiple parts. This draft extends the existing Multipart MIME security mechanism by defining two new protocol parameters to be used with RFC 1847, application/signature+xml and application/encryption+xml. These names follow the XML naming convention defined in RFC 3023, XML MEDIA TYPES. This draft defines these parameters and a minimal set of processing rules..." Also in text format. See (1) XML Media/MIME Types"; (2) "XML Digital Signature (Signed XML - IETF/W3C)"; (3) "XML and Encryption."
[October 03, 2001] "Sign-On-And-Go Security." By Brian Ploskina. In InteractiveWeek (October 1, 2001). "The technology exists today to deploy a single sign-on Web services marketplace, even as Microsoft and Sun Microsystems duel to build competing identification systems. Security Assertion Markup Language is an almost completed standard by the Organization for the Advancement of Structured Information Standards, a nonprofit consortium for the creation of interoperable industry standards. Based on XML, SAML allows a single sign-on for Web applications across the multitude of Web access management platforms available today. Leaders in Web access management - such as Access360, Baltimore Technologies, Entrust, Hewlett-Packard, IBM, Netegrity, Oblix and VeriSign - have committed to the standard. When it's ratified early next year, these companies can incorporate SAML in their software, enabling an interoperable infrastructure for identity and access management. Many of them have already incorporated early versions of the standard in the software they sell today, with free upgrades promised when SAML is complete... Examples of how the technology could be used include business-to-employee portals that provide employees access to their health benefits, time sheets, expense reports and 401(k) portfolios, all using a single user profile; and a business-to-consumer portal in which a credit card company partners with several online retailers to allow customers to shop from site to site without ever having to re-enter their ID numbers. 'The value to the end user is convenience,' said Enrique Salem, Oblix's senior vice president of products and technology. SAML will allow companies to know a customer has permission to conduct business on various participating networks, said Bill Bartow, Netegrity's vice president of marketing. 'SAML is the language used to describe this communication.' SAML does have obstacles. No. 1 is that Microsoft's Passport and Windows platforms so far don't support it. Instead, Microsoft is using Kerberos - a standard protocol developed by the Massachusetts Institute of Technology that runs on the Unix platform - as its authentication mechanism..." See: "Security Assertion Markup Language (SAML)."
[October 03, 2001] "Editorial Interfaces and Enterprise-Enabled Content." By Bill Trippe and David R. Guenette. In The Gilbane Report Volume 9, Number 7 (September, 2001), pages 1-8. "Today, there's little question about structured content being an essential requirement for content management. As our last report discussed, content management and XML are part and parcel of the new enterprise infrastructure. Content is drawn from a variety of internal and external sources, must be kept up to date, often needs to effectively address various audiences, and be displayed and distributed through a growing number of formats and devices. The integration of content management systems into enterprise information portals, personalization servers, localization and translation applications, integrated business applications, and content security platforms -- to name just some applications -- demands that the content being managed has intelligence applied to it. We refer to such content as enterprise-enabled content; that is: content that can be accessed and utilized by multiple types of users and applications. Enterprise-enabled content has business rules and other metadata associated with it. But if structured content is a requirement, does it follow that 'structured editing' must go with it? And does 'structured editing' mean XML editors for every user? So far, the answer from the marketplace seems to be no. HTML forms-based in-terfaces dominate, and if content management vendors see a next phase for the editorial interface, they seem to be leaning toward tighter integration of Microsoft Word. Some hope, of course, that the market will turn, en masse, to XML editing tools. But our analysis suggests that likely won't happen anytime soon. The state of the art in editorial interfaces is a mixed bag, and likely will remain so -- with some XML editing, some forms editing, some integration of tools like Microsoft Word, and an assortment of specialized tools for conversion, pre-tagging, and post-tagging of content as it goes in and out of content manage-ment repositories. enterprise might use... Tools that may work well for web publishing or single-purpose applications quickly break down when faced with application and information integration requirements. How do you create and maintain enterprise-enabled content? XML editors are certainly one option, but many users need more traditional word processing access or highly customized interfaces to specific content components and metadata... This analysis suggests, and we think realistically, that not all content will be XML or will have to be XML. However, enterprise-enabled content needs to compo-nentized and structured and needs to be accessible by a variety of editorial interfaces. These interfaces are best thought of as an application. The reality is that a mix of data types will continue to exist, and the editorial interfaces to such data must deal with this reality. Requirements analysis and design undertaken as you roll out enterprise content solutions is becoming more complex but also more critical. The analysis should be clear-eyed, realistic, and thorough. The resulting interfaces should be sturdy, useful, and self-revealing. The goals should include data quality and integrity, but also productivity. The business of content man-agement is critical to many organizations; putting the right tools in the hands of the content creators may be the best money an organization can spend in the months ahead..."
[October 02, 2001] Zvon XML Schema Reference. [Another cool tool] Prepared by Jiri Jirat and Miloslav Nic. The Schema reference is based on the W3C XML Schema Recommendations [updated from CR specifications]. The reference tool consists of two parts: (1) A Schema browser, based on the analysis of normative XML Schema; (2) A DTD browser, based on the analysis of non-normative DTD. The reference features hyperlinked clickable indexes and schemas: clicking on 'Annotation Source' or 'Go to standard' leads you to the relevant part of the specification. For schema description and references, see "XML Schemas."
[October 02, 2001] "NewsML -- Enabling a Standards-Led Revolution in News Publishing." By Tony Allday (Reuters Media Group). In EBU Technical Review Number 287 (June 2001). ISSN: 1609-1469, from the European Broadcasting Union (EBU), Geneva, Switzerland. Special Issue: 'XML Technologies in Broadcasting.' 8 pages. "NewsML has been developed and ratified as an open standard by the International Press Telecommunications Council (IPTC), for the structuring of multimedia news. This article provides an introduction to NewsML, which is a derivative of the rapidly-spreading XML standard.... NewsML is an XML language for the news industry. It is intended, as the IPTC says, to represent and manage news throughout its lifecycle. It is designed to provide a media-independent structural framework for news, so that publishers can work quickly and efficiently in the new digital environment, to the benefit of those who consume their content. Crucially, NewsML is an open standard, which means it can be easily adopted and used by any publisher... NewsML simply takes the form of an XML document which has a series of components -- or elements -- that are used to structure and process the actual news content. For example, consider the way in which a single piece of news content -- such as a text story, a digital image, or an audio or video clip -- would be handled. NewsML is media-neutral, so no assumptions are made about the media type, format or encoding of the data. The news content itself is carried as a data element within a ContentItem. If encoded, this may have an Encoding element, and an optional Characteristics element that can specify the requirements for the system which is to carry the data; for example, the file size. The ContentItem may also contain a wide range of metadata elements, a few examples of which are media type, format and notation. At the next level up, the ContentItem is carried by a NewsComponent. This exists mainly to provide a way of establishing relationships between multiple items of news content. The NewsComponent enables, for example, the specification of whether two pictures are equivalent (i.e., the same image at different resolutions) and whether the picture is a complement to a news story. At the next layer, the NewsItem is the central component of NewsML. It is a standalone, manageable, piece of news that must have both Identification and NewsManagement elements and which contains a single NewsComponent. At the top level, the NewsML element contains one or more NewsItems and a NewsEnvelope. The latter contains workflow-related data such as the date and time of issue, sender, recipient, and priority information: the NewsEnvelope can even specify whether the contents of a transmission form part of a particular product..." See (1) the NewsML web site and (2) the reference page, "NewsML and IPTC2000." [cache]
[October 02, 2001] "NewsML for Dummies." By Laurent Le Meur (Direction Technique - Direction Développement Multimédia AFP). September 30, 2001. Draft version 2. 19 pages. "This document is an introduction to the NewsML structure, and its use by AFP. It is intended to help XML developers understand the logic of NewsML, under its apparent complexity. It doesn't preclude the study of the NewsML functional specifications. AFP now distributes its multimedia services in the NewsML format. This document describes the AFP implementation of NewsML, and constitutes a guideline for developers of news systems receiving those AFP services... NewsML is a media independent standard for describing news in an electronic service environment. NewsML defines an XML based language for expressing the structure of news , associated metadata, and relationships between news, throughout their lifecycle. NewsML introduces several types of objects, each of them representing a level of news information. From the lower level to the upper, they are: (1) content item (ContentItem) used to wrap information content, (2) news component (NewsComponent) used to structure and describe news information, (3) news item (NewsItem) used to identify news information, (4) news document (NewsML) used to transport news information, (5) news package [e.g., MIME multipart-related envelope] used to package news data. NewsItems, NewsComponents and ContentItems are generically referred as news objects. The granularity of those objects has been chosen to get clear and non overlapping functions in the architecture..." See "NewsML and IPTC2000."
[October 02, 2001] "Binding Points for Subject Identity. The case for standard Published Subject Indicators." By Bernard Vatant (Mondeca). Paper presented at Extreme Markup 2001 - Montréal, August 2001. With a slide presentation. "Exchanging information about a subject with semantic tools, and singularly topic maps, demands both human and computer readable ways of agreement about this subject identity. Since subjects are always addressed through representations, hence agreement about subject identity must be grounded on some sort of representation, be it a name, an addressable resource, an URL or an XML <topicMap> element in a <topicMap> document. An overview is made of how those different representations can achieve or not the task of indicating subject identity in a non-ambiguous way. To address this problem, the XTM specification recommends that subject identity should be defined as far as possible by reference to Published Subject Indicators. But requirements for any standard definition, structure, management and validation of those PSIs remain to be defined, and in fact such requirements were deliberately considered out of the specification scope by its authors. Propositions are made for such requirements, grounded on the claim that a PSI should be a binding point for every possible representation of its subject. Beyond this problem of definition lies another important one. What are the best semantic ways to use PSIs? Merging topics has been a widely addressed process in the Topic Map community, and is in fact the only one really tackled by the XTM specification. But using PSIs as binding points for collaborative Semantic Networks of independent topic maps is proposed as an alternative to merging Very Large Topic Maps. Such distributed process could lead to a new vision of Subject Identity, grounded on dynamic knowledge organized around such binding points..." Note in this connection the [proposed] formation of an OASIS Topic Maps Published Subjects Technical Committee. Related references: "(XML) Topic Maps."
[October 02, 2001] "Template-Based, Format-Extensible Authoring for BS Digital Data Broadcast Service." By Ryuichi OGAWA, Kazuo YANOO, and Daigo TAGUCHI (NEC Internet Systems Research Laboratories). In NEC Research and Development Volume 42, Number 3 (July, 2001), pages 286-291 (with 10 references). "This paper gives an outline of a template-based authoring system for BS (Broadcast Satellite) digital data broadcast service started in December 2000 in Japan.The system is designed to compose multimedia documents in BML (Broadcast Markup Language) format. BML is an XML (Extensible Markup Language) based data specification language adopted as Japanese standard for the service.The authoring system provides template functions to combine XML data sources with BML style templates. Also it provides data-binding rules with the templates to generate BML instances automatically.The templates and the rules are extensible so that they can generate multi-format contents written in BML and HTML for cross-media services..." Note also the presentation on "Template-Based, Format-Extensible Authoring for BS Digital Data Broadcast Service" given by the authors an the Workshop On Highly Distributed Systems, 2001 Symposium on Applications and the Internet (SAINT-2001), San Diego-Mission Valley, California, USA, January 9-12, 2001. See: "Broadcast Markup Language (BML)."
[October 01, 2001] "WSDL: An Insight Out." By Sethuraman Ramasundaram. In XML Magazine Volume 2, Number 5 (October / November 2001), pages 40-44. ['Use WSDL to invoke Web services, or exploit WSDL to expose your service with the same advantages for its users.'] "Today programmers talk less about building applications from scratch; instead, they prefer to assemble applications from available third-party services through the Internet. Consider a scenario where you want to access a third-party remote service over the Internet for, say, credit card authorization. To do this, you need to know certain things such as the method signature (input/output parameters, and so forth); the protocol to be used (IIOP, SOAP, and so on); the network address; and the data format (encoding schemes). This is precisely what the Web Services Description Language (WSDL) specification defines in an XML format. The official definition of WSDL goes like this: 'WSDL is an XML format for describing network services as a set of end points operating on messages containing either document-oriented or procedure-oriented information.' By using WSDL as a standard, you can easily invoke remote services; conversely, if you have a remote service, exposing it using WSDL offers the same advantage to its requesters. Let's see how this works by looking at how WSDL fits into the Web services model, generating a WSDL document, and using it for invoking a remote service. ... Consider the position of WSDL in the big picture of Web services. In simple terms, Web services are clearly defined, third-party applications that can be invoked over the Internet. Examples of Web services might include credit card processing, shipment tracking (for example, FedEx), or even a simple time zone converter. The steps involved in creating and using a Web service are: (1) The service provider creates a service and registers it with a registry. The most common are UDDI registries. (2) The service requester [the person who wants to use a service] searches the registry and finds corresponding services. Now how does he or she know which service uses which protocol to communicate, what parameters to pass, and what result to expect? This is where WSDL springs into action. When the service providers register their services with the registry, they define the service in the form of a WSDL document. Thus by searching the registry, the service requester can retrieve corresponding WSDL documents. (3) As the WSDL document defines everything from the protocol to the service parameters, the service requester now writes the client to access the service... WSDL has support from many heavyweights in the industry. The WSDL specification was a combined effort of IBM, Microsoft, and Ariba. There is even a Java specification request present for a WSDL API, which aims at providing a Java API for constructing and manipulating service descriptions (see Resources ). For any standard to be successful, adherence by industry giants is essential. Since there is great support for WSDL, you might want to consider WSDL seriously for your Web services." See: "Web Services Description Language (WSDL)."
[October 01, 2001] "Character Model for the World Wide Web 1.0." W3C Working Draft 28-September-2001. Produced by the W3C Internationalization Working Group. Edited by Martin J. Dürst, François Yergeau, Misha Wolf, Asmus Freytag, Tex Texin, and Richard Ishida. Latest version URL: http://www.w3.org/TR/charmod. "The goal of this document is to facilitate use of the Web by all people, regardless of their language, script, writing system, and cultural conventions, in accordance with the W3C goal of Universal Access. One basic prerequisite to achieve this goal is to be able to transmit and process the characters used around the world in a well-defined and well-understood way... This document defines some conformance requirements for software developers and content developers that implement and use W3C specifications. It also helps software developers and content developers to understand the character-related provisions in other W3C specifications. The character model described in this document provides authors of specifications, software developers, and content developers with a common reference for consistent, interoperable text manipulation on the World Wide Web. Working together, these three groups can build a more international Web. Topics addressed include encoding identification, early uniform normalization, string identity matching, string indexing, and URI conventions. Some introductory material on characters and character encodings is also provided. Topics not addressed or barely touched include collation (sorting), fuzzy matching and language tagging. Some of these topics may be addressed in a future version of this specification. At the core of the model is the Universal Character Set (UCS), defined jointly by The Unicode Standard and ISO/IEC 10646. In this document, Unicode is used as a synonym for the Universal Character Set. The model will allow Web documents authored in the world's scripts (and on different platforms) to be exchanged, read, and searched by Web users around the world..." See also the mailing list archive. Related references: (1) "XML and Unicode"; (2) "Language Identifiers in the Markup Context."
[October 01, 2001] "Interactive Web Services with XForms." By Micah Dubinko. From XML.com. September 26, 2001. ['The W3C's new XForms technology can be used to attach user interfaces to web services, making efficient use of existing infrastructure. Micah shows how the common core of XML between XForms and web services simplifies the creation of user interfaces.'] "A form -- whether a sheet of paper or a web page -- represents a structured exchange of data. Web services, as typified by emerging standards like SOAP, WSDL, and UDDI, is an excellent approach to exchanging data in a structured way, although usually the exchange is between machines. Since computers are much better at, well, computing, web services is an important and overdue development in the evolution of the Web. Nevertheless, web services applications exchanging information only between machines isn't very interesting: lots of electronically accessible information originates with ordinary human beings... WSDL talks about transmission primitives between endpoints defined for Web Services, including (1) Request-response (The endpoint receives a message, and sends a correlated message); (2) Solicit-response (The endpoint sends a message, and receives a correlated message). It's not hard to imagine either of these scenarios applying to an "endpoint" constituted by a person using a networked device. Such a point of view is attractive since it simplifies the creation of web applications that contain the necessary semantic hints to be equally valuable to people or machines. For this concept to gain widespread acceptance, however, a better method is needed to combine forms and XML across a wide variety of devices, including alternate accessibility modalities (such as audio browsers), and to do so in a streamlined way that fits well with XML and Schema-based back ends. XForms provides this critical link between people and interactive web forms, enabling the best of both worlds: a Web populated with resources which are accessible to humans and machines... Authoring XForms is simple, taking only two steps, and you can reuse Schemas and instance data already available in a web services environment. The main issue at this point is the lack of conforming XForms Processors with which to utilize forms on the client side. The XForms specification is still a moving target, still in the "Working Draft" phase. The XForms Working Group is actively seeking feedback and implementation experience. In the short term, server-side tools that transform XForms into browser-digestable HTML are a good solution..." See (1) the W3C XForms web site and the main reference page "XML and Forms."
[October 01, 2001] "XML Divided. [<taglines/>.] By Edd Dumbill. From XML.com. September 26, 2001. ['XML is on the move, and specifically it's getting bigger and bigger. Up to now, the XML community's been surprisingly cohesive, but now a divergence is inevitable. The editor muses on the consequences of this divergence, and make a plea for continued interoperability.'] "Change is one of life's inevitable constants, yet there are certain times at which we recognize it more than others. In the terrible events of the past few weeks, we've been forced to accept that many things are not as we thought they were. Over the last six months, the downturn in the tech sector has dampened many a wild and hopeful grab for dot-com glory, and we're now faced with the prospect of an even more widespread economic malaise. So there are points of inflection in our comprehension of the world around us. We are now at such a point in the XML world, too. This is not to say that the future for XML looks bleak -- in many ways it's never looked better -- but tomorrow's XML will be very different from what we're used to... Until the publication of the W3C's XML Schema Recommendation earlier this year, our industry had been very focused on the activities of the relatively few standards makers, centered mostly at the W3C. We've tussled and mused over the power games of standards. Several important victories for interoperability have been won, and the disastrous 'browser wars' scenario that left HTML so broken and stagnant has been averted... XML is now well on its way to becoming a computing commodity, functionality taken for granted on any platform. And the thing about commodities is that they're, well, fairly uninteresting. Doubtless the W3C will continue to produce various XML specifications. Some of these are necessary housekeeping, and others will be significant only to certain portions of the XML world... XML's very success necessitates that it can no longer hold together in one monolithic grouping. Distinct communities are developing around printing and graphics, web services and object technology, databases, and electronic business. For the XML community, the route of divergence is pragmatic, practical, and inevitable. The support or neglect of core interoperability, however, remains a choice..."
[October 01, 2001] "Valid Frustrations. [XML Q & A.]" By John Simpson. From XML.com. September 26, 2001. ['John explores how to squeeze XML DTDs to provide validation over particular numbers of elements, and introduces some alternative approaches.'] "I am having trouble with a DTD not enforcing some rules I'm trying to create... For example, a fruit_basket element must contain between 9 and 11 banana elements... This limitation of DTD content models is one which XML Schema is designed to fix... in general, an element type's content model is built by declaring that element type with an xsd:complexType element; children of this element include various xsd:element elements, each of which may have a minOccurs and a maxOccurs attribute. The values of these attributes are integers, representing respectively the minimum and maximum number of times which that child element type may appear within that parent. The default value for both is 1, which is consistent with DTD syntax..." For schema description and references, see "XML Schemas."
[October 01, 2001] "OAGIS Implementation Using the ebXML CPP, CPA and BPSS Specifications v1.0." OAGI White Paper. By Jean-Jacques Dubray (Eigner US, Inc.). 9/27/2001. Version 1.03. 64 pages. The OAGI (Open Applications Group, Inc.) has developed the largest set of business messages and integration scenarios for enterprise application integration and business-to-business (B2B) integration. However, OAGI does not specify an implementation architecture (also called an implementation framework). Three major B2B implementation architectures have been developed to this day: RosettaNet, BizTalk, and ebXML. They provide the basis for interoperability between different vendor and home-grown solutions alike. The OAGI policy is to be technology sensitive but not specific, and to use existing open standards when possible. This white paper provides a detailed recommendation for how to transport OAGI BODs (Business Object Documents) using ebXML v1.0 dated 5/14/2001. The reader is expected to have a thorough understanding of the OAGI BOD structure and the ebXML v1.0 specifications. The reader is encouraged to read the OAGI BOD Architecture documents and the ebXML specifications. These documents can be freely obtained from the OAGI and ebXML Web sites... This document provides a general recommendation for the usage and configuration of the ebXML implementation architecture in carrying out electronic transactions with OAGI BODs. In particular, it specifies how to define Collaboration Definitions for scenario diagrams. It also specifies how to declare CPPs and corresponding CPAs based on these Collaborations. The CPPs can be published to an ebXML Registry just like any other CPP. The Messaging Service can be used as is since it is content agnostic. This document also describes the relationship between the infrastructure level messages (Signal Messages) used by ebXML and OAGI (Confirm BOD) to identify message receipt or exceptions. This white paper does not deal with the aspects of ebXML that are not yet part of the specification (such as Core Components). In addition, this paper recommends the use of Business Collaborations outside the context of ebXML. A Collaboration Definition can be used outside the scope of an ebXML solution and consequently could be used to formalized all OAGI scenario diagrams even the one that do not involve B2B communication. This approach may be desirable in order to provide a commercial OAGI solution with out-of-the-box capabilities while retaining the ability to customize the use of scenario diagrams for internal applications. The OAGI Integration Specification (OAGIS) includes a broad set of BODs and integration scenarios that can be used in different business environments, such as A2A and B2B. BODs are message definitions that can be used broadly across many different industries (for example, telecommunications and automotive) and aspects of Supply Chain Automation (for example, Ordering, Catalog Exchange, Quotes, etc.). OAGI also defines the OAMAS (Open Application Middleware API Specification), which is an application programming interface (API) for application integration that provides an abstraction from specific vendor solutions..." See the overview/download page for other eBusiness Framework White Papers. See: (1) "Open Applications Group" and (2) "Electronic Business XML Initiative (ebXML)." [cache]
Earlier XML Articles
- XML Articles and Papers October - December, 2001
- XML Articles and Papers July - September, 2001
- XML Articles and Papers April - June, 2001
- XML Articles and Papers January - March, 2001
- XML Articles and Papers October - December, 2000
- XML Articles and Papers July - September, 2000
- XML Articles and Papers April - June, 2000
- XML Articles and Papers January - March, 2000
- XML Articles and Papers July-December, 1999
- XML Articles and Papers January-June, 1999
- XML Articles and Papers 1998
- XML Articles and Papers 1996 - 1997
- Introductory and Tutorial Articles on XML
- XML News from the Press




{kind=link}
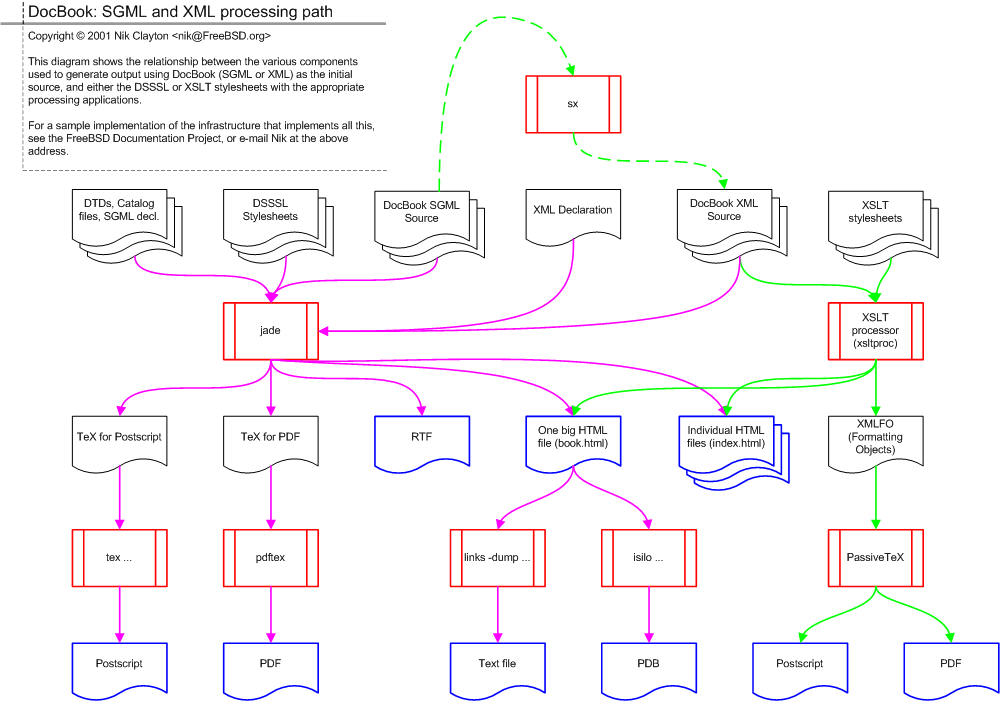{kind=link}
{kind=link}