
[October 24, 2000] A very provisional collection of references possibly relevant to the design of encoding/markup for ANE texts. Please send email to [email protected] with notices of additions and corrections.
| Last modified: February 12, 2002 |
| Encoding and Markup for Texts of the Ancient Near East |
Contents
Initiatives, Standards, and Digital Library Projects
- Achaemenid Royal Inscriptions Project
- Ancient Egyptian Dictionary Project, Berlin-Brandenburg Academy of Sciences and Humanities
- Computer Representation of Cuneiform Project
- Cuneiform Database Project, University of Birmingham
- Cuneiform Digital Library Initiative (CDLI)
- Electronic Standards for Biblical Language Texts Seminar
- Electronic Text Corpus of Sumerian Literature (ETCSL)
- Electronic Tools and Ancient Near Eastern Archives (ETANA)
- Initiative for Cuneiform Encoding (ICE)
- Ugaritic for Unicode
- ISO/IEC JTC1/SC2/WG2
- Oriental Institute, University of Chicago
- XML System for Textual and Archaeological Research (XSTAR)
- Pennsylvania Sumerian Dictionary Project
- Perseus Digital Library Project
- Text Encoding Initiative (TEI)
- Thesaurus Indogermanischer Text- und Sprachmaterialien (TITUS)
- Unicode Consortium
- XML Manuel de Codage for Hieroglyphic Texts
Initiatives, Standards, and Digital Library Projects
[Provisional reference list for resources and projects. Please send additions/corrections.]
Achaemenid Royal Inscriptions Project
"The aim of the Achaemenid Royal Inscriptions project is to create an electronic study edition of the inscriptions of the Achaemenid Persian kings in all of their versions: Old Persian, Elamite, Akkadian, and, where appropriate, Aramaic and Egyptian. The edition is to be accompanied by translations, glossaries, grammatical indexes, basic bibliographic apparatus, basic text critical apparatus, and some graphic apparatus (e.g., plans indicating provenience of the inscriptions, images of exemplars); the texts will be available for downloading and printing. The first stage of the project presents the inscriptions from Persepolis and nearby Naqsh-i Rustam, where the Oriental Institute of the University of Chicago carried out excavations between 1931 and 1939. Close study and accurate use of these texts calls for synoptic presentation of the versions. Yet no handy synoptic edition has replaced F. H. Weissbach's magisterial Keilinschriften der Achämeniden of 1911, because the development and divergence of scholarship on Old Persian and Old Iranian, Elamite, and Akkadian make replacing it with an equally compendious and authoritative printed edition a forbidding undertaking. On the other hand, the flexibility of the electronic media makes it possible to present useful working synoptic editions with apparatuses and illustrations that can be undertaken in stages, and that can be progressively enlarged, improved, and interconnected." [Project overview from Gene Gragg and Matthew Stolper (Oriental Institute, University of Chicago); presentation at the OI Conference, 1999.]
At the 1999 OI Conference, Gene Gragg "described the project's existing encoding scheme and his plans to convert this to XML. Gragg demonstrated the use of the XML-oriented Extensible Stylesheet Language (XSL) in Internet Explorer to generate various views of XML- encoded texts within a Web browser application."
Ancient Egyptian Dictionary Project, Berlin-Brandenburg Academy of Sciences and Humanities
"Since 1993, the Ancient Egyptian Dictionary project has been housed at the Berlin-Brandenburg Academy of Sciences and Humanities in Berlin. It aims to provide up-to-date lexical information on the Egyptian language, supplementing and replacing the great Wörterbuch der ägyptischen Sprache by Adolf Erman and Hermann Grapow, which appeared in twelve volumes between 1926 and 1963, and which is outdated in important respects. As in the Wörterbuch der ägyptischen Sprache, work at the Ancient Egyptian Dictionary project is centered on compiling a comprehensive corpus of Egyptian texts, which in turn provides the basis of the dictionary. Both the corpus of texts and the dictionary are produced as a database and will be published in due course on the Internet. In this context, encoding Egyptian texts in XML will play an important part..." [In his OI conference presentation "The Ancient Egyptian Dictionary Project: Data Exchange and Publication on the Internet"], PD Dr. Stephan J. Seidlmayer] described the history of the Ancient Egyptian Dictionary project and outlined the plan for taking it onto the Internet using XML; once a suitable XML markup scheme has been developed, this information will be converted to XML format and made available on the Internet, to facilitate international cooperation in this dictionary project."
Computer Representation of Cuneiform Project
". . . a joint undertaking of Karljürgen Feuerherm (SchoolWorks, Palmerston, Ontario) and Lloyd Anderson (Ecological Linguistics, Washington, D.C.). [CRC's goal] is to analyse the Mesopotamian Cuneiform writing system over the course of its history (ca. 3000 BCE - 100 CE), with a view to: (1) determining the base character set in use from time to time and place to place; (2) tracing the evolution of characters in time and space in terms of fundamental forms and attested variants; (3) discerning and analysing the issues fundamental to a systematic encoding of Mesopotamian Cuneiform; and (4) proposing a coherent set of principles to underlie an eventual encoding."
- Project web site
- Project description
- "Introduction to Cuneiform Encoding." Presentation at the American Oriental Society Meeting, March 31, 2001. [cache]
Cuneiform Database Project, University of Birmingham
The Cuneiform Database Project is "a centrally-funded interdisciplinary team project at the University of Birmingham, working toward an interactive database of cuneiform signs. The project team comprises cuneiform specialists from the Department of Ancient History and Archaeology, digital imaging researchers from the School of Electronic and Electrical Engineering, and a forensic scientist from the Department of English Literature." A presentation given at the October OI Conference described a "proposed database format, issues relating to XML coding of the data, and plans to improve digital image representations of cuneiform signs."
- Web site
- [alternate domain]
- "XML and Digital Imaging Considerations for an Interactive Cuneiform Sign Database."
Cuneiform Digital Library Initiative (CDLI)
Earlier description:
"The Cuneiform Digital Library Initiative (CDLI) represents the efforts of an international group of Assyriologists, museum curators and historians of science to make available through the internet the form and content of cuneiform tablets dating from the beginning of writing, ca. 3200 B.C., until the end of the third millennium. This period of rich administrative and literary history of Babylonia is documented by nearly 120,000 Sumerian and Akkadian texts, the majority of which have remained largely inaccessible to specialists, let alone to interested linguists and historians."
"The Cuneiform Digital Library Initiative proposes to develop tools and techniques leading to the systematic digital documentation and new electronic publication of cuneiform sources. Despite the 150 years that have passed since first decipherment of cuneiform many basic research tools remain to be developed that will allow this material to be studied in depth by specialists and generally made available to the public. This project, conducted in close collaboration with a number of organizations (including the Max Planck Institute for the History of Science and the California Digital Library) will: (1) Create virtual archives of widely dispersed early cuneiform tablets; (2) Implement an integrative platform of data presentation combining raster, vector and 3D imaging with text translation and markup; (3) Establish for collaborating museums a lasting archive procedure for fragile and often decaying collection of cuneiform records. The project's dataset will be built using platform-independent text encoding and markup conventions and linked to accurate, high-resolution images. Typologies and extensive glossaries of technical terms will be included, later supplemented by linguistic tools for accessing the primary sources by non-specialists." [NSF grant abstract, September 18, 2000]
- Cuneiform Digital Library Initiative (CDLI) - UCLA
- Mirror Web Site - Berlin
- CDLI description
- Methods of Digitalization
- Cuneiform text markup. CDLI and PSD XML DTD. [alt URL, cache]
- [February 12, 2002] "Cuneiform for Everyman." By Robert K. Englund (Department of Near Eastern Languages and Cultures, UCLA). In D-Lib Magazine Volume 8 Number 1 (January 2002).
- "Silicon Babylon: Project Aims to Make Cuneiform Collections Available to Researchers Worldwide. [Babylon Online.]" By Scott McLemee. In Chronicle of Higher Education [Research and Publishing] November 09, 2001. [cache]
- CDLI Announcement 2001-06: Markup Proposals.
- NSF Award
Electronic Standards for Biblical Language Texts Seminar
A seminar approved for formation by the SBL Research and Publications Committee, 1997 ... focusing on the needs of authors and publishers working with biblical language texts...working on standards for the electronic encoding of biblical language texts ranging from modern articles to primary source materials. Such standards will facilitate the interchange, publication and analysis of materials of interest to biblical scholars. This SBL seminar focuses on "electronic communication between biblical scholars, publishing houses and software companies. In addition, it will focus on abbreviation standardization in academic publications, whether for print or electronic distribution." Working groups were formed for Critical apparatus, Dictionaries, Entity Sets and Writing System Declarations, Hebrew Syntax, and Imaging.
- Described in HUMANIST (1998) and OFFLINE 56 (1997).
- Contact [2000-11]: Bernard Taylor
Electronic Text Corpus of Sumerian Literature (ETCSL)
"The aim of this project is to produce a 'collected works' of over 400 poetic compositions of the classical [Sumerian] literature, equipped with translations. This standardised, electronically searchable SGML corpus, which is based to a large degree on published materials, comprises some 400 literary compositions of the Isin/Larsa/Old Babylonian Period, amounting to approximately 40,000 lines of verse (excluding Emesal cult songs, literary letters, and magical incantations). The full catalogue can be found elsewhere at this site. The compositions are presented in single-line composite text format (in a standardised transliteration) with newly-prepared English prose translations, and a full bibliographical database, thereby making available for the first time a collected works of Sumerian literature. The corpus is freely available to anyone who wishes to use it via this World Wide Web site... The texts are being encoded in Standard Generalized Markup Language (SGML), which will ensure the widest accessibility of the material in the future. In the next few months a parallel XML- and Unicode-based site will be developed, enabling much more sophisticated display and searching facilities... Members of the team are documenting, editing, translating and publishing an SGML-XML corpus of Sumerian literary texts from ca. 2000-1600 BC. They are now planning ways to analyse that corpus in order to document and describe aspects of its style, lexis, grammar and register." As of October 2000, initial work had begun on the creation of XML DTDs for transliteration-level encoding and for translations.
- ETCSL Web site
- Project technical information with DTDs
- ETCSL - Local description and references
Electronic Tools and Ancient Near Eastern Archives (ETANA)
"A planning grant of $27,000 has been awarded to advance a collaboration between the SBL and the American Oriental Society, the American Schools of Oriental Research, Case Western Reserve University Library, the Cobb Institute of Archeology, the Oriental Institute (University of Chicago), Vanderbilt University Press and the Heard Library at Vanderbilt. The collaborative project has been tentatively named ETANA (Electronic Tools and Ancient Near Eastern Archives). This effort will focus on primary and secondary materials relating to the ancient Near East ['many historic texts in a number of ancient languages'] and the technology necessary for scholars to access and produce them."
- Vanderbilt Announcement
- SBL Announcement
- Contact: Paul M. Gherman (Vanderbilt)
Initiative for Cuneiform Encoding (ICE)
"ICE is an international group of cuneiformists, Unicode experts, software engineers, linguists, and font vendors organized for the purpose of proposing a standard computer encoding for Sumero-Akkadian cuneiform, the world's oldest attested writing system." [from the conference announcement]
ICE participants have planned an initial meeting to "establish a working group to develop such a proposal, and to hold discussions on pertinent theoretical and practical issues." This inaugural meeting is to be held November 2-3, 2000 at The Johns Hopkins University. Presentations include (tentatively): (1) "Rationale and Guidelines for Encoding Large, Complex Scripts in Unicode," by John Jenkins [System Software Engineer, Apple Computer, Unicode Technical Director, East Asian Scripts]; (2) "A Prototype Electronic Sign List for Cuneiform," by Dr. A. Livingstone [Reader in Assyriology, School of Historical Studies, University of Birmingham and Mr. T.R. Davis, Lecturer in Bibliography and Palaeography, School of Humanities, University of Birmingham]; (3) "Towards the Development of a Cuneiform Character Code: Diagraphemes and Related Matters," by Karljürgen Feuerherm [PhD Candidate in Akkadian, Computer Scientist, University of Toronto].
A self-subscribing public mailing list supporting ICE work is currently [2000-10-25] hosted by the Unicode Consortium. This list is open to anyone who wishes to be involved in technical discussions of Cuneiform script extensions to Unicode / ISO10646. Interested parties may contact Dean A. Snyder for mailing list particulars.
- ICE web site
- ICE Conference Announcement, 2000-10-19.
- Report of the First ICE Conference, [cache]
- [November 07, 2000] "Cuneiform: From Clay Tablet to Computer." Report on the "Initiative for Cuneiform Encoding (ICE) Conference," The Johns Hopkins University, Baltimore, Maryland, USA, November 2-3, 2000. From Dean Synder (JHU).
- [November 15, 2000] "Oldest written language to get a digital update." By Michael Stroh (Baltimore Sun Staff). In Baltimore Sun, November 13, 2000. ['In efforts to help researchers and to renew interest in ancient cultures, scientists are trying to convert cuneiform into the binary code used by computers.'] "... Ancient tongues and pictographic scripts such as Chinese - with up to 100,000 written characters - were even more complex, and the computer industry eventually adopted a new numbering scheme, called Unicode, which has room for more than 1,000,000 characters. That's enough for all the world's languages, alive and dead. Most of the 7,000 languages in use today have been converted to Unicode, largely as a result of the growth of the Internet. The researchers who gathered at Hopkins will have to decide how to fit cuneiform's 600 characters into the Unicode system." [cache]
- [November 15, 2000] "Cuneiform Scholars Take High-Tech Road to Translation." By Leslie Rice. In [The Johns Hopkins University] Gazette Online Volume 30, Number 11 (November 13, 2000). "The Initiative for Cuneiform Encoding, an international group of cuneiformists, Unicode experts, software engineers, linguists and font architects, convened for the first time Nov. 2 and 3 on the Homewood campus. Their purpose was to begin the proposal process for a standard computer encoding for Sumero-Akkadian cuneiform, the ancient Near Eastern writing system used for a number of languages from the end of the fourth millennium B.C. until the first century B.C. [...]"
Ugaritic for Unicode
Ugaritic for Unicode website: "presents the results of international discussions occurring among Ugaritologists in preparation for a formal proposal to the Unicode Consortium for the computer encoding of Ugaritic cuneiform.
- Ugaritic for Unicode email list: "hosted by The Johns Hopkins University. This is an unmoderated email list dedicated to discussing issues related to developing a formal, scholarly proposal for the adoption of Ugaritic cuneiform into the Unicode computer encoding standard. The website associated with this email list can be found at http://www.jhu.edu/ice/ufu/." See the invitation for participation.
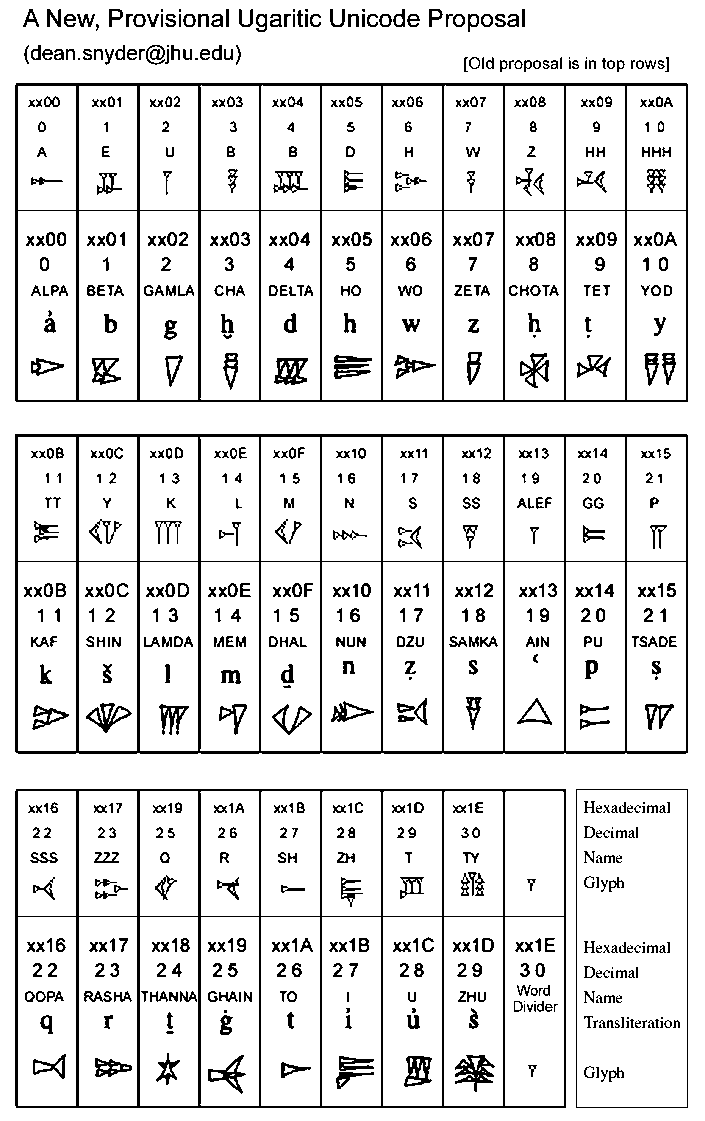
- A New, Provisional Ugaritic Unicode Proposal By Dean Snyder. 2001-03-15. [cache]
- See also Proposal for the Universal Character Set. From Michael Everson, 15-Mar-2001 or later. Older draft is: WG2-N1640, "Proposal to encode Ugaritic Cuneiform in Plane 1 of ISO/IEC 10646-2". [cache]
- [April 17, 2001] Proposal to encode Ugaritic in the UCS. By Michael Everson, Rick McGowan, and Ken Whistler. ISO/IEC JTC1/SC2/WG2 N2338. 2001-04-01. 6 pages. [cache]
ISO/IEC JTC1/SC2/WG2
"ISO/IEC JTC1/SC2/WG2 is the international standardization working group for the coded character set UCS - the Universal Multiple-Octet Coded Character Set - ISO/IEC 10646. The scope is to develop a universal multiple-octet coded character set that encompasses the world's scripts."
- SC2/WG2 Web site
- Document register
- Publicly Available ISO/IEC Standards
- [January 09, 2001] Roadmap for Semitic Languages Character Encoding. By Michael Everson. N2311. source]
Oriental Institute, University of Chicago
"The Oriental Institute is a museum and research organization devoted to the study of the ancient Near East. Founded in 1919 by James Henry Breasted, the Institute, a part of the University of Chicago, is an internationally recognized pioneer in the archaeology, philology, and history of early Near Eastern civilizations. The Institute has undertaken projects in every part of the ancient Near East, including the Nile Valley, Mesopotamia, Persia, parts of the Ottoman Empire, and the lands of the Bible. Institute scholars also maintain research projects in Chicago, such as dictionaries and lexicons of ancient Akkadian, Hittite, Demotic, Egyptian, and Sumerian."
A communiqué from Charles E. Jones and Patrick Durusau invites submissions for two panel sessions on "Electronic Markup and Publication of Ancient Near Eastern Texts," to be held at the Annual Meeting of the Society of Biblical Literature in Denver, CO, November 17-20, 2001. The NEML (Near Eastern Markup Language) symposium is jointly sponsored by the Oriental Institute (University of Chicago) and The Society of Biblical Literature. The symposium builds upon the work of a variety of individuals, groups, and organizations to articulate "technical standards for the interchange of Near Eastern data in digital form, seeking to develop stable platforms for the electronic publication of scholarly work in ancient Near Eastern studies utilizing preexisting markup languages and planning for the implementation of widely accepted standards." [Details]
The Oriental Institute of the University of Chicago sponsored a conference "Electronic Publication of Ancient Near Eastern Texts" on October 8-9, 1999. The conference was organized by Gene Gragg, Charles Jones, John Sanders, and David Schloen. This conference will likely be recognized as a milestone event in terms of progress toward a community consensus that encoding/markup standards would enhance scholarly communication and publication of ancient Near Eastern texts. A published announcement read (in part): "The focus of this conference will be on Web publication of 'tagged' texts using the new Extensible Markup Language (XML), although other aspects of electronic publication may also be discussed. The purpose of the conference is to bring together researchers who have begun working on electronic publication in various ways using such tools as SGML, HTML, and XML, or who are interested in exploring these techniques. Through a combination of formal presentations and informal discussions ideas will be exchanged concerning the conceptual and practical issues involved in using XML on the Web. In this way the conference organizers hope to foster collaboration in the development of specific XML/SGML tagging schemes, especially for cuneiform texts, in which a number of the confirmed conference participants specialize. The conference will inaugurate a formal 'Working Group on Cuneiform Markup' to provide an ongoing forum for communication and collaboration in this field."
- SBL Annual Meeting 2001, Denver, CO, USA. November 17-20, 2001. Session S18-15. Theme: Near Eastern Markup Languages. Charles E. Jones (The Oriental Institute) Presiding. Papers include: (1) "Integrating Ancient Near Eastern Information via XML," by David Schloen, University of Chicago; (2) "Beyond Encoding: XML/XSLT as Analytic Tool," by Scobie P. Smith, Harvard University. [Note re: SPSmith research on 'Hurrian Grammatical Interference in Nuzi Akkadian': "... This research is a focused analysis of the Hurrian influences on the language of the Akkadian dialect of Nuzi, in particular as represented by first and second generation scribes. Texts examined are those known to belong to scribes of the first generation or scribes descending from Apil-Sin and belonging to the second generation. New editions are presented for all texts involved. The corpus is digitized and analyzed with the aid of computational tools (XML/XSL). More information will be forthcoming at http://www.nuzi.org."
- "Electronic Publication of Ancient Near Eastern Texts." By Charles E. Jones and David Schloen. In Ariadne [ISSN: 1361-3200] Issue 22 (December 1999). 'The authors report on the conference and on the past and potential futures, and in particular on the potential for XML to provide a medium for acceptable standards.' Excerpt: "A major goal of our conference was to assess the prospects for establishing a formal international standards organization charged with setting technical standards for the interchange of Near Eastern data in digital form. Both the conference and the establishment of such an organization are timely in light of the recent development of internet-oriented data standards and software that now provide a common ground for cooperation among diverse philological and archaeological projects, which have heretofore adopted quite idiosyncratic approaches. This common ground, not just for academic research but in all areas of information exchange, is created by the Extensible Markup Language (XML) and a growing array of software tools that make use of XML to disseminate information on the Internet... There was a consensus among the conference participants that XML should be used as the basis for future electronic publication of Near Eastern data. The establishment of a formal working group for Near Eastern text markup was also strongly endorsed, as a vehicle for the collaborative development and dissemination of suitable XML tagging schemes and associated software. Stephen Tinney of the University of Pennsylvania, the editor of the Pennsylvania Sumerian Dictionary, who has substantial experience in electronic text processing and in the use of SGML and XML, in particular, was elected to be the chair of the working group..."
- Conference Announcement: Electronic Publication of Ancient Near Eastern Texts
- Conference program; [cache]
- Announcement posted at UMichigan.
- Oriental Institute Web site
XML System for Textual and Archaeological Research (XSTAR)
The goal of the XSTAR project "is to create a sophisticated Internet-based research environment for specialists in textual and archaeological studies. In particular, XSTAR is intended for archaeologists, philologists, historians, and historical geographers who work with ancient artifacts, documents, and geographical or environmental data. It will not only provide access to detailed, searchable data in each of these areas individually, but will also integrate these diverse lines of evidence as an aid to interdisciplinary research... consists of both a database structure and related interface software that will make it possible to view and query archaeological, textual, and linguistic information in an integrated fashion via the Internet. The XSTAR database structure is expressed in terms of hierarchies of interlinked data elements using the Extensible Markup Language (XML)... XSTAR's XML data format is based on and incorporates ArchaeoML (Archaeological Markup Language), an XML tagging scheme previously developed at the University of Chicago's Oriental Institute."
- XSTAR web site
- "XML System for Textual and Archaeological Research (XSTAR)" - Local reference page
Pennsylvania Sumerian Dictionary Project
Researchers at the University of Pennsylvania Museum are creating an electronic edition of the Pennsylvania Sumerian Dictionary. It is being designed as a pure-XML corpus-based dictionary in which the lexicon, meta-data (bibliographies, lists of personal names, signlists etc.) and primary textual data are all integrated within a single framework. Computerizing the PSD involves the development of an XML framework for integration of primary texts with tools such as signlists and lexicon.
Steve Tinney (Babylonian Section, University of Pennsylvania Museum) presented an overview of the ongoing development of an electronic version of the Pennsylvania Sumerian Dictionary (e-PSD) at the OI Conference, 1999. As reported in the conference summary, "Tinney surveyed some of the basic concepts underlying XML and the 'markup' approach to electronic text representation, and then he outlined his ideas concerning the implementation of a corpus-based lexicon such as the Pennsylvania Sumerian Dictionary on the Internet using XML. He pointed out that such a lexicon can and should transcend the limitations of existing printed dictionaries. In particular, an electronic lexicon would not be a static entity but would be the dynamic product of three types of interlinked and constantly updated data, comprising primary text corpora, grammatical analyses, and secondary literature. In other words, the same data would be reusable in different contexts, and many possible views of the data could be constructed for different users. One such 'view,' of course, is a printed or printable version of the lexicon in the traditional format. Tinney concluded his talk by presenting and commenting briefly on an XML 'document type definition' (DTD) which defines a set of element (tag) types and their attributes by means of which a corpus-based lexicon, for any language, could be represented."
- PSD web site
- Index to Sumerian Secondary Literature (ISSL) Search and online documentation.
- "XML and the Corpus-Based Dictionary: Development and Implementation of the Pennsylvania Sumerian Dictionary." To be presented by Steve Tinney at the Workshop on Web-Based Language Documentation and Description, December 12-15, 2000, Institute for Research in Cognitive Science (IRCS) University of Pennsylvania Philadelphia, Pennsylvania, USA.
Perseus Digital Library Project
The Perseus Project has encoded several thousand documents of early Greek and Latin using SGML/XML markup. It is one of the most elaborate and successful digital library projects ever designed.
- Perseus Project
- More complete references and descripton: "Perseus Project."
- "Knowledge Management in the Perseus Digital Library." By Jeffrey A. Rydberg-Cox, Robert F. Chavez, David A. Smith, Anne Mahoney, and Gregory R. Crane. In Ariadne [ISSN: 1361-3200] Issue 25 (September 2000). "The Perseus digital library is a heterogeneous collection of texts and images pertaining to the Archaic and Classical Greek world, late Republican and early Imperial Rome, the English Renaissance, and 19th Century London. The texts are integrated with morphological analysis tools, student and advanced lexica, and sophisticated searching tools that allow users to find all of the inflected instantiations of a particular lexical form. The current corpus of Greek texts contains approximately four million words by thirty-three different authors. Most of the texts were written in the fifth and fourth centuries B.C.E., with some written as late as the second century C.E. The corpus of Latin texts contains approximately one million five hundred thousand words mostly written by authors from the republican and early imperial periods. The digital library also contains more than 30,000 images, 1000 maps, and a comprehensive catalog of sculpture. Collections of English language literature from the Renaissance and the 19th century will be added in the fall of 2000. In developing this collection of SGML and now XML documents, we have benefited from the generality and abstraction of structured markup which has allowed us to deliver our content smoothly on a variety of platforms. The vast majority of our documents are tagged according to the guidelines established by the Text Encoding Initiative (TEI). While we have had a great deal of success with these guidelines, other digitization projects have found other DTDs more useful for their purposes. As XML becomes more widely used, more and more specifications for different subject fields and application domains are being created by various industries and user communities; a well known and extensive list of XML applications includes a wide variety of markup standards for different domains ranging from genealogy to astronomy. Customized DTDs ease the encoding of individual documents and often allow scholars to align their tags with the intellectual conventions of their field. At the same time, they can raise barriers to both basic and advanced applications within a digital library. . . One of the challenges in building this type of [digital library] system is the ability to apply these sorts of tools in a scalable manner to a large number of documents tagged according to different levels of specificity, tagging conventions, and document type definitions (DTDs). To address this challenge, we have developed a generalizable toolset to manage XML and SGML documents of varying DTDs for the Perseus Digital Library. These tools extract structural and descriptive metadata from these documents, deliver well formed document fragments on demand to a text display system, and can be extended with other modules that support the sort of advanced applications required to unlock the potential of a digital library." [cache]
- "Generalizing the Perseus XML Document Manager." By Anne Mahoney, Jeffrey A. Rydberg-Cox, and Clifford E. Wulfman. To be presented at Workshop on Web-Based Language Documentation and Description, December 12-15, 2000, Institute for Research in Cognitive Science (IRCS) University of Pennsylvania Philadelphia, Pennsylvania, USA.
- Designing Documents to Enhance the Performance of Digital Libraries." By Gregory Crane. In D-Lib Magazine Volume 6 Number 7/8 (July/August 2000). "In tagging texts, we begin with the basic document structure: chapters, sections, headers, notes, blockquotes, etc. We have only begun the process of identifying individual bibliographic citations and linking these to formal bibliographic records for author and work. We have tagged most foreign language quotations, letters, extracts of poetry, etc. by hand. Two other levels of information are added to the documents. The boundary between these levels is flexible but the general distinction is clear. When we can identify particular semantic classes with reasonable reliability, we encode this information as tags within the SGML/XML files. The Perseus XML Document manager processes the tagged texts and images. A linked GIS manages the geospatial data. Many operations are performed on the data, the most important of which establish automatic connections between different and otherwise isolated parts of the collection..."
Text Encoding Initiative (TEI)
"The Text Encoding Initiative (TEI) is an international project to develop guidelines for the preparation and interchange of electronic texts for scholarly research, and to satisfy a broad range of uses by the language industries more generally... The writing system declaration or WSD is an auxiliary document which provides information on the methods used to transcribe portions of text in a particular language and script. We use the term writing system to mean a given method of representing a particular language, in a particular script or alphabet; the WSD specifies one method of representing a given writing system in electronic form. A single WSD thus links three distinct objects: (1) the language in question; (2) the writing system (script, alphabet, syllabary) used to write the language (3) the coded character set, entity names, or transliteration scheme used to represent the graphic characters of the writing system..."
- TEI Home Page
- TEI Writing System Declaration - "P4" version. See also P3.
- Reference Manual for the MASTER Document Type Definition. For analytical bibliography: the 'Master' project defines "a very detailed set of extensions for the detailed description of manuscripts."
- Description of Medieval Manuscripts (TEI Work Group)
- Text Encoding Initiative (TEI) - local references
- See also: "Language Identifiers in the Markup Context."
Thesaurus Indogermanischer Text- und Sprachmaterialien (TITUS)
"The TITUS server is a joint project of the Institute of Comparative Linguistics of the Johann Wolfgang Goethe-Universität, Frankfurt am Main, the Ústav starího Predního vychodu of Charles University, Prague, the Institut for Almen og Anvendt Sprogvidenskab of the University of Kopenhagen and the Departamento de Filología Griega y Lingüística Indoeuropea de la Universidad Complutense de Madrid." Project affiliates Carl-Martin Bunz and Prof. Dr. Jost Gippert have presented theoretical papers at the Unicode conferences.
Unicode Consortium
Scripts for several (ancient) Near Eastern languages are handled by Unicode [Hebrew, Arabic, Syriac]; other scripts are under consideration. A mailing list supports discussion of character encoding for (Mesopotamian) cuneiform.
- Unicode Web site
- See the Pipeline Table and Proposed New Scripts for notes on Linear B, Aegean scripts, Cypriot syllabary, Phoenician, Ugaritic Cuneiform, Old Persian Cuneiform, South Arabian, Basic Egyptian Hieroglyphics, etc.
- Unicode Technical Report #3: Exploratory Proposals. [Proposals for Less Common Scripts]. 1992-1993, various dates. ['The Glagolitic proposal was written by Joe Becker. All other proposals herein were written by Rick McGowan.'] Includes discussion of Early Aramaic; Old Persian Cuneiform; Phoenician; Epigraphic South Arabian; Syriac; Ugaritic Cuneiform; Hurrian; Ancient Egyptian (Hieroglyphic); Akkadian, Babylonian, Sumerian; Hittite Hieroglyphics, etc. "The material in this technical report contains the original 1992 exploratory proposals for the encoding of many scripts. Since its first publication, several scripts have been encoded in the standard, or are in the process of being encoded. Thus, UTR#3 is now considered mostly superseded by more recent proposals; it is now mainly a historical document." [cache]
XML Manuel de Codage for Hieroglyphic Texts
"Since 1985 there has existed in Egyptology a standard for the encoding of hieroglyphic texts for computer input, the so-called Manuel de Codage. This standard has been implemented in the three major hieroglyphic text-processing programs: Glyph, MacScribe, and Inscribe. The Manuel de Codage offers guidelines for alpha-numeric (ASCII) and phonetic encoding of the signs, as well as the grouping of signs and layout of the text as a whole. Though an alternative system is now under construction by the Unicode consortium which makes a 16-bit set of character encodings available on any platform, the Manuel de Codage standard will no doubt keep dominating electronic hieroglyphic text processing for years to come. The main reason for this is the fact that producers of the established hieroglyphic text processing programs will not easily switch to another standard, in order not to confuse their customers, though ways may be found to make them compatible. Though standard-ized character sets help out when it comes to working on text publications and grammars, a problem lies in the growing desire of modern Egyptologists to do electronic epigraphy and palaeography. It is quite common that newly recorded texts yield previously unknown signs or character anomalies. To be able to record these the hieroglyphic text-processing software will have to find new and more flexible ways of working with character sets and character encoding. The coming of XML with its flexible element, attribute and entity declarations, and its flexible tag set, holds great promise for achieving this goal without giving up the established encoding system. . ." Summary from "Egyptian Hieroglyphic Text Processing, XML, and the New Millennium," presented by Hans van den Berg (Center for Computer-aided Egyptological Research, Utrecht University) at the OI conference, 1999.
Online Publications
[October 26, 2000] Here follows a small collection of uncategorized/unordered online publications. Please send email notification with URLs for documents which deserve mention. Subject to some limitations, I am able to host relevant documents on this web site on behalf of authors who otherwise do not have a good 'publication' venue.
XML and Digital Imaging Considerations for an Interactive Cuneiform Sign Database." PowerPoint. By Alasdair Livingstone, Sandra Woolley, Tom Davis and Theodoros Arvanitis. Electronic Publication of Ancient Near Eastern Texts (Conference), The Oriental Institute of the University of Chicago, October 8-9, 1999. Also in HTML.
"3D Capture, Representation and Manipulation of Cuneiform Tablets." By Dr Sandra I. Woolley, N.J.Flowers, Dr Theodoros N. Arvanitis, Dr Alasdair Livingstone, Tom R.Davis, and John Ellison. For presentation at IST/SPIE Electronic Imaging 2001, San Jose, 21-26 January 2001. "This paper will present the digital imaging results of a collaborative research project working toward the generation of an on-line interactive digital image database of signs from ancient cuneiform tablets. An important aim of this project is to enable the forensic analysis of the cuneiform symbols to identify scribal hands. The paper will describe the challenges encountered in the 2D digital image capture of a sample set of tablets held in the British Museum, explaining the reasons for attempting 3D imaging and the results of initial experiments...When reading the tablets, experts tend to rotate them constantly; both grossly in order to present all the signs to inspection, but also subtly in order to use light and shadow to bring out the indentations clearly. In a digitised tablet, this manipulation would ideally be enabled with high-resolution 3D rendering, rotation control and light source adjustment. Our experiments indicated that sufficiently high-resolution scans are not easily realisable, and that in any case the resulting file sizes would prohibit remote access and real-time manipulation. Experimental scans were performed using laser stripe triangulation at resolutions of 10 and 25 lines per millimetre producing files in excess of 100Mbytes. The current cost and complexity of the appropriate scanning processes make remote capture, formatting, storage and communication even more challenging. The paper will present the results of experimental 3D laser scans from the smaller, more densely inscribed tablets; we will also discuss the tractability of 3D digital capture, representation and manipulation, and investigate the requirements for scaleable data compression and transmission methods..." [cache, abstract]
"Encoding Scripts from the Past: Conceptual and Practical Problems and Solutions." By Carl-Martin Bunz, M.A. (Universität des Saarlandes, Saarbrücken, Germany [see bio]). Presented at the 17th International Unicode Conference, San Jose, California, September 2000. Based upon a paper presented at IUC 16 (Amsterdam, March 2000). 33 pages. "This paper outlines a strategy how to tackle the encoding of historic scripts in Unicode and ISO/IEC 10646. By means of a categorization of the historic script material, this strategy might help to make up a reasonable and realistic operative roadmap for the encoding efforts of historic scripts." Abstract: "My paper 'Scripts from the Past in Future Versions of Unicode' delivered on IUC 16 (slot B5) was received with interest so that a subsequent tutorial appears to be useful in order to deal more explicitly with the problems involved when historic scripts are to be prepared for a standardized encoding. While my previous talk focussed on the classification of the scripts according to both user interest and encodability, my tutorial (4 hours) is to cover, in the first place, the systematic differences between the encoding processes of current and historic scripts respectively. By introducing palaeography and a palaeographic database the fundamental split becomes salient. Second, repertoires of historic writing symbols necessitate a new look on the notion of script Unicode adheres to. I intend to point out the main difficulties different script concepts involve, depending on different levels of abstraction. In the view of ISO and Unicode as well as the scholarly community, compromising between scientific treatment, engineering and marketing, seems to be the most viable method to follow in order to find practicable solutions. Third, the Unicode compliant definitions of Character and Glyph must be checked against the situation of historic script data. All this will be illustrated by numerous examples from various writing traditions. In a second part, the results of part 1 will be analysed with a view to ranks of encodability. Designing a roadmap for the inclusion of historic scripts in Unicode, however, cannot be done with regard to encodability only, but has to take into account user interests as well, which are to be reviewed at this point. In conclusion, the tutorial will synthesize the two rankings in order to elaborate a sound strategy of how to approach the encoding of the historic scripts of the world." [Canonical] source URL pending.
Comments on proposals for the Universal Multiple-Octed Coded Character Set. Document: ISO/IEC JTC1/SC2/WG2 N2097. From Prof. Dr. W. Röllig through DIN (Engish translation from German by Marc Wilhelm Küster). Germany's feedback on Semitic languages: update of N2025-2.
"Response to comments on the question of encoding Old Semitic scripts in the UCS (N2097)." By Michael Everson. ISO/IEC JTC1/SC2/WG2 N2133. Date: 1999-10-04. "Wolfgang Röllig responded to my exploratory proposals to encode a number of Old Semitic scripts in the UCS in SC2/WG2 N2097. In this paper I will try to address the numbered points in Dr Röllig's contribution."
"Unicode, Ancient Languages and the WWW." By Carl-Martin Bunz, M.A. (Universität des Saarlandes, Saarbrücken, Germany) and Prof. Dr. Jost Gippert (Johann Wolfgang Goethe-Universität, Frankfurt/M., Germany). Tuesday, March 11, 1997. IUC 10.
"Browsing the Memory of the World." By Carl-Martin Bunz. Thursday, September 4, 1997. IUC 11.
"The Computer Representation of Cuneiform: Towards the Development of a Character Code." By Karljürgen Feuerherm. Paper presented at Rencontre Assyriologique Internationale, Paris, July 13, 2000. [cache]
"Proposal for encoding the Phoenician script in ISO/IEC 10646." From Michael Everson. 1997-05-27. "This document contains the proposal summary (ISO/IEC JTC1/SC2/WG2 form N1352) and contains a complete proposal to encode the Phoenician script in ISO/IEC 10646. This proposal is a minor revision of a proposal by Rick McGowan, taken from Unicode Technical Report No. 3" (referenced above).
"Proposal to encode Old Persian Cuneiform in Plane 1 of ISO/IEC 10646-2." By Michael Everson. 1997-09-18. ISO/IEC JTC1/SC2/WG2 N1639.
Proposal: Old Persian [SGML] Entity Set. Version: 0.51. Date: 1996-08-17. By Anders Berglund. Part of the "SGML Public Entity Sets," by Anders Berglund.
Ugaritic Cuneiform. "Proposal to encode Ugaritic Cuneiform in Plane 1 of ISO/IEC 10646-2." ISO/IEC JTC1/SC2/WG2 N1640. 1997-09-18. By Michael Everson.
Ugaritic Entity Set. Prepared for ISO 9573, ISO/IEC TR 9573:1988 (E). Information Processing - SGML Support Facilities - Techniques for Using Standard Generalized Markup Language (SGML). Version: 0.45. Date: 1997-05-12. Part of the "SGML Public Entity Sets," by Anders Berglund and Robin Cover (contributions for the Ugaritic RAC forms). See following entry.
"SGML Public Entity Sets, Proposals." By Anders Berglund and others; copyright BC&TF, 1997. Proposals for Ugaritic, Old Persian, Glagolitic - Croatian, Buginese, Cherokee, Gothic Uncials. "SGML, ISO/IEC 8879:1986, contains a mechanism to refer to characters, syllables and symbols that are not to be found on normal keyboards or that are difficult to store and transmit unambigously. It is acheived by defining so called (SDATA) Entities, where one has essentially given a name to a character, syllable or symbol and is assuming that a system processing the SGML data will be able to understand the reference, either by its name or the so called replacement text. To refer to an entity in an SGML file the name is prefixed by '&' and followed by ';'. For example α to refer to the greek alpha. ISO has published some number of collections of entities; the Public Entity Sets, and work is in progress to add a large number of entity sets for non-latin languages. For the purposes of reviewing and commenting on the sets the name and comment are the only relevant parts. The pubished entity sets also refer to characters, if present, in ISO 10646 as well as to entries in the International Glyph Registry, for which AFII is the registrar..." [cache]




{kind=link}
{kind=link}