[This local archive copy mirrored from the canonical site: http://www.gca.org/conf/meta98/xmldev98/index.htm, 1998-08-19. The document has been enhanced with additional links/anchors for referencing. Annotations have been made. Updated 1998-09-25.]
XML Developers' Conference
August 20-21, 1998
Montréal, Canada
Thursday
August 20 |
Speaker |
Title |
| 0900-0915 |
Jon Bosak, Sun Microsystems |
Introductory Remarks |
| 0915-1000 |
David Turner, Microsoft |
XML Support in Internet Explorer |
| 1000-1030 |
Ramanathan Guha, Netscape |
XML Support in Netscape Navigator |
|
| 1030-1100 |
BREAK |
| 1100-1130 |
David Brownell, Sun Microsystems |
The Sun XML Library |
| 1130-1200 |
Dave Hollander, Hewlett-Packard |
XML in the InfoWorks Document Management System |
| 1200-1230 |
Neel Sundaresan, IBM Almaden Research Center |
RDF in Java |
| 1230-1400 |
LUNCH |
| 1400-1445 |
Lloyd Rutledge, CWI |
SMIL within Hypermedia Environments |
| 1445-1530 |
Matthew Fuchs and Murray Maloney, Veo Systems |
When Documents and Objects Meet: Using Schemata in Software Development |
| 1530-1600 |
BREAK |
| 1600-1630 |
Liam Quin and Ian Graham, GroveWare
| GroveWare Inc. XML Database |
| 1630-1710 |
Steve Withall |
XXX - eXpandable XML eXploitation |
| 1710-1730 |
Ken Holman, OASIS |
Report on XML Conformance |
| |
Friday
August 21 |
Speaker |
Title |
| 0900-0930 |
Brian McFadden, Xtenit |
Filtering XML Documents and Data Sets |
| 0930-1000 |
Paul Prescod |
Python: the 100% Buzzword Compliant XML Processing Language |
| 1000-1030 |
Tim Bray, Textuality |
Reifying the DPH |
| 1030-1100 |
BREAK |
| 1100-1145 |
Rob Brown, InDelv |
InDelv WYSIWYG XML/XSL editor |
| 1145-1230 |
Tim Bray, Textuality |
Construction of the Annotated XML Specification |
| 1230-1400 |
LUNCH |
| 1400-1445 |
Peter Murray-Rust, VHG Consulting |
The Virtual Hyperglossary -- Adding Semantics and Ontology to XML |
| 1445-1530 |
Kurt D. Fenstermacher |
Using XML in Knowledge Management |
| 1530-1600 |
BREAK |
| 1600-1645 |
Eliot Kimber, Isogen |
Grove-based XLink Implementations |
| 1645-1730 |
David Megginson, Megginson Technologies
| XAF: Using Architectural Forms with XML |
| |
Presentation Abstracts
By Ramanathan Guha, Netscape.
The presentation slides are [will be] available online.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/db.htm]
David Brownell
Java Software Division
Sun Microsystems, Inc.
Sun Microsystems has played a key role in the development of XML.
As the creator of the Java™ programming language, Sun also
recognizes the complementary benefits of using Java technology with XML
for middleware messaging, for online publishing based on
structured content, and for other classes of Internet applications.
Accordingly, there are a variety of XML-related projects in development
at Sun.
This session will discuss one of those projects: a highly modular
XML library that has been developed by the Java Software Division of
Sun. The XML library is written in the Java programming language and
provides support for the latest version (July) of the W3C DOM APIs and
for the SAX 1.0 API. The XML package includes:
- Fast validating and nonvalidating XML parsers
- Preliminary support for XML Beans
- Examples including an XML Validation Service
This presentation discusses the initial version of this library,
including its basic performance statistics and extensions to SAX and DOM.
Some other XML-related projects at Sun will also be discussed. Developer
feedback is solicited, particularly from other Java-oriented XML development
projects.
-------------------
Note: [September 25, 1998 update.] On September 16, 1998, Sun Microsystems, Inc. released an 'Early Access 1' version of The Sun XML Library. The September 16th version is the the first early access release, "addressed to Java developers who want access to Sun's fast and fully conformant XML library core for their development of extensible, conformant XML-enabled services and applications. That library supports fast parsing of XML documents, including optional validation, and supports an optional in-memory object model tree for manipulating and writing XML structured data. In addition, the core functionality supports an implementation of the W3C DOM APIs and the XML Namespaces proposal. The library is 'core' in the sense that significant XML based applications can be written using only this functionality, and that it is intended that other XML software be layered on top of it. All classes are written exclusively in the Java[tm] language, and accordingly may be used with any JDK 1.1 conformant system, including JDK 1.2 conformant systems. Developers have expressed strong interest in seeing XML enabling technology emerge from Sun because of the key role Sun has played in developing the XML specification and in creating the Java platform. The Java technology's 'portable code' along with XML's 'portable data' are valuable complements in creating truly platform-independent applications. Through the early access release, developers have an unique opportunity to participate in defining and evolving the XML Library." [adapted from the XML Library 'README' and FAQ documents]
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/dmh.htm]
Abstract for Presentation at XML DevCon
Dave Hollander
XML Architect
Hewlett-Packard Company
Hewlett-Packard is extending their InfoWorks marketing document management system to
add formalization to the content creation process by enhancing the documents as XML
described objects as chunked data resources for intelligent custom delivery. The goals of
this program are the classic write-once/deliver-many goals:
- Save time and money .
- Easy access to timely, reliable content.
- Accurate, thorough, timely electronic content.
To allow these goals to be achieved, we are enhancing Infoworks to establish a
repeatable, predictable and manageable separation between information development
processes and information delivery processes. Central to these features are XML encoded
chunks of information and templates which are used to create, manage and deliver the
information.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/neel.htm]
In this presentation we will discuss RDF in Java, a processor for RDF
(Resource Description Framework) written in Java. This processor provides
facilities for building RDF structures, navigating and querying them,
manipulating them, and converting them to their equivalent XML
forms. It also has facilities to perform I/O operations on RDF
structures.
RDF is a foundation for processing metdata; it provides
interoperability between applications that exchange
machine-understandable information on the Web. It can be used in a variety
of areas including resource discovery for search engines, cataloging for
describing contents, content rating, and so on. It is a simple graph
language for describing resources and properties associated with
resources. The goal of RDF is to provide
a mechanism to describe resources and their properties in a domain-independent
way. RDF uses XML as one of its encoding
syntax, the other two being graphs and tuples. Two W3C groups are
working on RDF mechanisms : the RDF syntax and model
working group, and the RDF Schema working
group.
The current implementation of RDF in Java conforms to the
working draft dated 02/16/1998 of the W3C RDF Syntax and Model working
group. It performs the recommended abbreviations in the document.
The tool is available for free download from the IBM Alphaworks web-site at
http://www.alphaworks.ibm.com.
The first version of the tool has been downloaded by over 2000 users
and has been used to build web document summaries, sitemaps, geneology
structures, and Java serialization structures. The processor is being
updated to support the latest document dated 06/15/1998 and to provide
complete support for RDF schema.
In this presentation we will discuss RDF, the RDF in Java tool and its
functionalities, and describe some of the applications that have been built
using the tool.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/lloyd.htm]
SMIL within Hypermedia Environments
Lloyd Rutledge,
Lynda Hardman, and Dick C. A. Bulterman
CWI (Centrum voor Wiskunde en Informatica)
P.O. Box 94079
1090 GB Amsterdam
The Netherlands
phone: +31 20 592 4127
fax: +31 20 592 4199
{lloyd|lynda|dcab}@cwi.nl
SMIL (Synchronized Multimedia Integration Language, pronounced
"smile") is a recent W3C recommendation for hypermedia presentations.
An XML-compliant, DTD-defined format, SMIL can be roughly
characterized as "HTML for interactive multimedia". SMIL version 1.0
was designed for easy integration of anticipated XML-related
specifications such as XLink, XPointer and namespaces. Features of
SMIL include:
- Easily-defined basic timing relationships
- Fine-tuned synchronization
- Spatial layout
- Direct inclusion of non-text and non-image media
- Hyperlink support for time-based media
- Adaptiveness to varying user and system characteristics
We at CWI were involved in the creation of SMIL and have developed an
authoring and playback environment called GRiNS (GRaphical iNterface
for SMIL). This has evolved out of our research on adaptive
hypermedia with the Amsterdam Hypermedia Model, an extension of the
Dexter hypertext model. Features of GRiNS include:
- Playback, logical structure, resource, and hyperlink views of presentation
- Visual manipulation of screen regions
- Visual manipulation of image portions for linking
- Establishing of broad timing relationships
- Specification of SMIL adaptiveness constructs
- Interpretation and display of hierarchy-defined timing
- Display and manipulation of fine-tuned synchronization
- Turning on and off of resources and screen regions
- Facilitated link management
- Checking and maintaining of XML-compliance and SMIL DTD-compliance
We have also designed Berlage, an automated, complete
storage-to-presentation generation environment. Berlage is built
entirely from existing public standards and publically available free
tools. This work has evolved out of our research on modeling abstract
presentation-independent document structure and our research on the
style sheet issues that are particular to hypermedia. Components of
the Berlage environment include:
- HyTime for representing presentation-independent storage structure
- Additional SGML architectures
- SP for validating architectural conformance
- DSSSL for defining transformation to final-presentation(s)
- DSSSL libraries for HyTime property processing
- Jade for processing presentation generation
- SMIL for presentation encoding
- GRiNS player for final presentation
This talk presents SMIL, GRiNS and Berlage. An overview of SMIL is
given, along with a discussion of its current and anticipated
relationship with other XML-related current and developing formats.
The work behind developing GRiNS is discussed, along with the
XML-related issues that were behind this development. Finally, the
Berlage environment is described, with its use of XML- and
SGML-related standards.
References
The CWI SMIL Page. http://www.cwi.nl/SMIL/.
The CWI GRiNS Page. http://www.cwi.nl/SMIL/GRiNS/.
Lloyd Rutledge, Jacco van Ossenbruggen, Lynda Hardman, and Dick C. A. Bulterman, "Practical
Application of Existing Hypermedia Standards and Tools",
Proceedings of Digital Libraries
98, June 1998.
Note: The presentation slides for "SMIL within Hypermedia Environments" are available in Postscript format [local archive copy].
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/veo.htm]
When Documents and Objects Meet
Using Schemata in Software Development
Matthew Fuchs, PhD
Murray Maloney
Veo Systems, Inc.
What is the value of having a schema language, beyond expressing DTDs
in instance syntax? Veo has been developing CBL, a library of XML
components for common business transactions to become the basis for
electronic commerce. Building something as complex as CBL, and
getting it right, requires a tight iterative loop between specifying
CBL components on the one hand and testing them in actual software on
the other. We needed to drastically reduce the cycle time for each
iteration to have a hope of delivering a product within the same
millenium we started in. We chose to develop an object-oriented
schema language, the Business Interface Description Language (bidl) to
do this.
The normal process is for a DTD designer to go about his or her
business, and then hand the DTD, with comments and documentation, to
the programming staff. The programming staff then looks at this stack
of paper or electrons and then starts determining how to implement
it. This waterfall methodology is known to fail, especially when
hacking into new territory.
The central problem was in conveying intent. XML, we realized, had
great facilities for describing how to express information, but very
few for actually modeling it. It turns out XML is great for
expressing other semantics but has very weak internal semantics. DTD
designers have been forced to do their modeling with very primitive
tools that completely predate the object revolution and then convey
their intentions (such as the semantic relationships among elements)
with out-of-band data. By exploiting object-oriented constructs in
BIDL (such as inheritance of structure and interface) the DTD designer
(or schemographer, as it were) could convey much more of his intent in
a succinct (and formal manner). A programmer can look at a bidl
instance and know what her code will look like - and call the designer
up and ask why? Where the intention is complex, and text is required,
bidl has a built in notion of literate programming, so those
explanations are never lost.
Veo has brought, side by side, world-class XML talent and world-class
programming talent (and a couple who've done both). We've designed
leading edge DTDs and world-spanning distributed systems. Now we
needed to do both. Developing bidl became an iterative process around
the desires of our XML experts and the needs of our (Java)
programmers. Constructs in bidl were added because of evident need
and their meaning honed in actual use. This process was not without
its long walks, discussions and arguments - no one in Veo lacks
opinions. But the lessons learned have been significant.
Running the world on XML implies that everyone will receive lots of
XML from a variety of domains. In a peer-to-peer world we'll all need
applications to handle these messages, and these applications imply
lots (and lots)+ of code. For those organizations (such as our own)
not yet in the Fortune 100, this is a daunting task. We believe that
bidl, and the work processes we have built around it, are key to
making this vision possible.
Note: See now "Bringing XML into the World of Objects. Using Schemata in Software Development." By Matthew Fuchs and Murray Maloney [Veo Systems]. Slides from the presentation at XML Developers' Day, August 21, 1998. Alternately, the slides are available from the GCA Web site.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/quin.htm]
GroveWare Inc. XML Database
Liam Quin and Ian Graham
We at GroveWare Inc. have been
working on a database/repository for XML documents, built on an
object oriented database, and with an Web-based interface.
Information is stored internally in Java objects, using a Schema for
simple run time typing information and content validation.
All user interaction is through HTTP, using dynamically generated
HTML and forms; DSSSL style sheets are used to format the XML information
on the fly (currently with Jade) and to present them as HTML to users.
The first product using this engine is now shipping; we are working
on a revised version of the engine for the future.
Note: The presentation slides are now available in HTML and PowerPoint format.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/stevew.htm]
XXX - eXpandable XML eXploitation
By Steve Withall
Synopsis
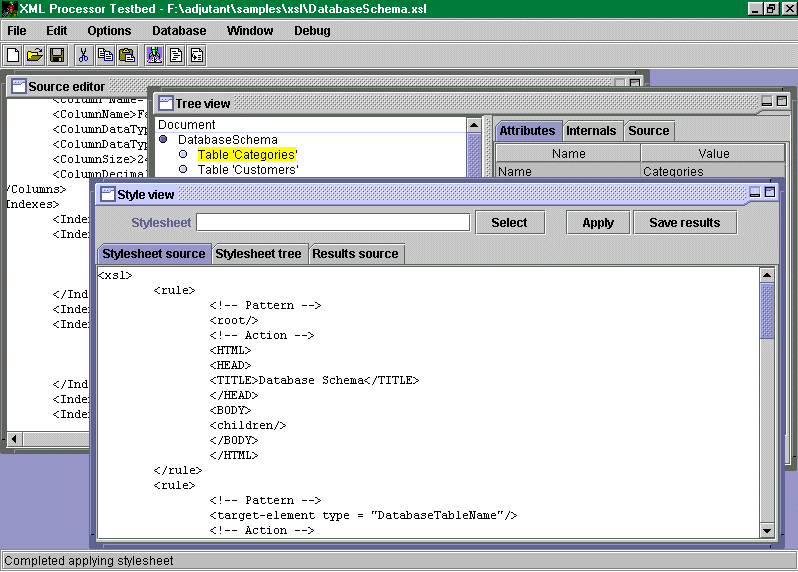
This presentation describes a number of design ideas for flexible, expandable applications that manipulate and otherwise exploit XML documents. Steve will demonstrate these ideas using a Java 'XML Testbed' application. (Steve intends to publicly release all his source code either at or prior to the conference - including his own parser and XSL engine.)
Expandable Application Structure
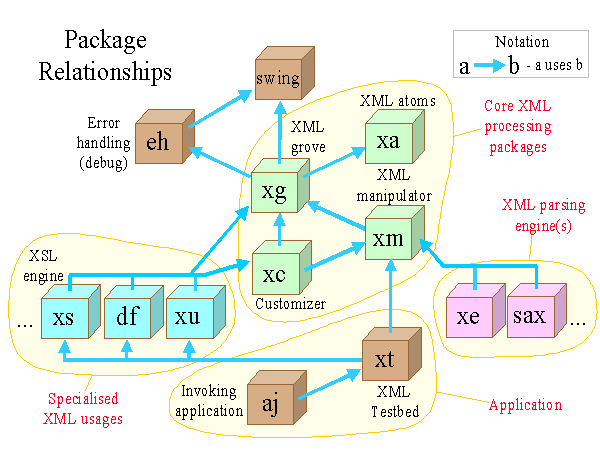
Steve divides the application into four parts:
Core XML Processing
Four Java packages provide functions for representing and manipulating XML documents:
- XML Atoms
(package xa) to encapsulate low-level knowledge of the XML language itself. While normally embedded in parsers themselves, the idea is to allow other software (eg. an editor) to use this information.
- Grove
(xg). Nothing revolutionary here!
- XML Manipulator
(xm) provides a range of document manipulation capabilities, including factory classes, a base parsing 'engine' class, and document model and document listener classes (to co-ordinate changes made in multiple document views). This package also contains a registry for specialised element and other classes.
- Customizer
(xc), fulfilling the same role as JavaBean customizers via a collection of classes to display and edit the standard types of XML entities.
XML Parsing Engines
Any supported parser can drive the application, in a similar manner to SAX, but at a higher level. (SAX is, however, a supported 'parser').
Specialised XML Usages
The vanilla application manipulates vanilla XML documents, but semantic knowledge can be embedded in specialised classes. Steve will demonstrate three such usages: an XSL engine, UI configuration, and rendering a database schema in XML via JDBC. The basis for expandability is to 'register' information about specific XML element types:
- Element class name
. Specialised element classes can contain whatever specialised processing they wish. Steve (sacrilegiously) invokes a 'verify()' method on each element when its parsing is complete, to perform specialised checking during parsing.
- Customizer class name
, for specialised display and editing.
- Parser class name
, primarily to allow special PI parsers to be slotted in.
Application
Steve will demonstrate these ideas using his XML Testbed application, which implements them all and is also a basic XML authoring environment. Steve hopes to demonstrate nearly-WYSIWYG XML editing driven by XSL style rules - if it's working in time.
About the Presenter
Steve Withall has been developing commercial software for eighteen years, the last eight designing large-scale object-oriented systems. He currently works for Access Systems in Sydney, a company formed to develop Interactive Television applications. For this, he and his colleagues developed a language for describing ITV user interfaces: PNML - Pretentiously Named Markup Language. (Why couldn't XML have been around then?!) While the company has moved on from ITV, PNML is still used for various purposes. Steve comes to XML from a very different direction than the SGML gurus!
Responsible for, among other things, extracting documentation from thirty unruly software engineers, Steve has an active interest in automatically generating system documentation where possible, and is using XML and XSL to develop solutions for this problem.
Note: The details of the Java 'XML Testbed' application used to demonstrate these ideas are now documented online, and the software is available from the W3C web server. Slides from the Montréal presentation are also available. - rcc, 980827
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/holman.htm]
XML Conformance
By Ken Holman
[This would be a brief report.]
At the first XML Developers' Day in 1997, OASIS (the Organization
for the Advancement of Structured Information Standards) announced the
early formation of a technical subcommittee to explore XML
Conformance. Over the first year, this committee has explored the
requirements for XML Conformance while the XML Community has finalized
the standard and begun real-world implementations of the technology.
This presentation briefly overviews the status of the work of the
subcommittee, the approaches being considered for use in the committee
results, and the needs for input from the XML Community that will help
advance the effort.
Note: The presentation slides for "Report on XML Conformance" are available in HTML format. See the main database entry, XML Conformance.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/brian.htm]
Filtering XML Documents and Data Sets
Brian McFadden, Xtenit, Inc.
To meet the needs for several content management applications, we are developing a general
filter that will use a simple yet powerful syntax for selecting and filtering XML documents and
data sets. This filter will be used in several applications for routing, categorizing , and retrieving
XML documents and data sets. Characteristics and advantages of the syntax used are:
- Standard if-then-else form with boolean Operators (AND, OR, NOT)
- Support for standard operators (<, >, =, etc.) for strings and numeric data
- Scope specific (i.e. (Parent).(child).(name) ) and global (i.e. *.(name) ) element selection
- Implicit support for elements with multiple occurrences, object data, and tabular data
- Able to reference all elements and attributes in any well formed XML document.
The core process for the filter supports distributed sets of rules, and each rule can reference data from
multiple documents and data sets, (for example document selection rules could reference both
profile and content).
Examples of applications include:
- Information Routing - Intelligent routing applications match XML content to profiles
(also in XML) based on rule sets that contain both general rules and rules specific to the each content
and profile item. This allows delivery of both general and specific real-time, event-driven
information to the appropriate audience.
- Refined Text Retrieval - The filter is used to assist in indexing of stored documents.
Applications sitting on top of the indexed archive use the filter and
rule syntax to refine searches and eliminate extraneous results.
- Agent Servers -- Agents defined by a profile (in XML) and a set of rules use the filter to
process and categorize a stream of XML content.
Our presentation will discuss our approach, summarize the syntax used, and give specific
examples of applications with XML documents and DTD's.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/papresco.htm]
Python: the 100% Buzzword Compliant XML Processing Language
By Paul Prescod (ISOGEN International Corporation)
Python is a simple, powerful programming language. It is designed to
solve many of the same problems addressed by Perl (text processing), TCL
(embedding), Visual Basic (user interfaces and prototyping) and to a
lesser extent, Java (distributed, portable applications). Instead of being
yet another over-specialized "scripting" language, Python shares its best
features with many great languages and integrates them in a predictable
way. With Smalltalk and Scheme it shares flexibility and simplicity, with
the Algol family, a familiar infix syntax, with the Simula family, object
oriented programming features and with Perl, an open development model,
powerful text processing features and a versatile set of standard
libraries (including XML processing tools).
These features make it perfect for processing XML and SGML documents
efficiently and conveniently. The Python XML Special Interest Group
has been charged with the task of making libraries and documentation
for processing XML and SGML documents, W3C DOM objects,
ISO Groves and SAX data streams.
Python code can run in a highly portable, Python-optimized bytecode
interpreter, or in any Java virtual machine. When run in the Java
environment, Python code can be distributed across the network in JVM
classfiles. This code can use any Java classes and libraries (including
SAX parsers and the AWT). Thus, Python can be used either instead of, or
in addition to Java, especially where a project requires faster coding or
more flexibility than Java provides.
In short, Python is an easy to learn, scriptable, portable,
distributed, multithreaded, web-aware, embeddable object oriented language
for everything from rapid prototyping to large system development. Thanks
to the efforts of the XML SIG, it is also shaping up to be a very robust
platform for XML processing. This talk will describe the products and
plans of the SIG.
The presentation slides are available online.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/tbray2.htm]
Reifying the DPH
Tim Bray
Textuality
Meeting the needs of the symbolic DPH (Desperate Perl Hacker) has
always been one of the key design goals of the XML project.
Fortunately, the perl community has decided to meet us half-way. This
short presentation describes the work accomplished to date on giving
perl the ability to process XML, which has involved wiring in the
expat XML processor.
The work has progressed far enough to allow the construction of a
variety of different experimental interfaces to XML documents for perl
programmers. Several such APIs are now available. I will describe
how one goes about constructing such APIs, and will demonstrate the
use of one aimed directly at the DPH.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/rbrown.htm]
InDelv XML/XSL editor and Java class library
Rob Brown
InDelv, Inc.
First public presentation of a wysiwyg XML editor which accurately renders
XML using XSL style sheets. This software was developed by rewriting a
commercial text class library from scratch, specifically for Java and the
new XML family of standards. It creates documents which can be displayed
or printed internally, exported as XML / XSL for use in other tools, or
converted to HTML for viewing by traditional web browsers.
XSL is used as the internal rendering model with DSSSL based flow objects
and format characteristics. Support for the DSSSL formatting model roughly
corresponds to the DSSSL Online proposal of August 96. XSL will be supported
to the greatest extent possible relative to the XSL Working Draft due in
July 98 (hopefully including element reordering, literal text and named
styles).
The document model implements DOM (Core) Level 1 and parsing is handled
by any SAX compliant XML parser. The linking and text selection model is
based on XLL. Key design goals include fast on-screen rendering, accurate
printing and flexible application setup. XML is used to specify menu definitions,
key maps, view and window layout, event hooks, nls string translation and
user preferences. The intent is that 'XML applications' can be created
and deployed by non-programmers and so far the results have been promising.
The version being presented is a 'Technology Introduction' and is intended
for use by experienced programmers and visionary XML hackers. Some capabilities
will be limited. In particular, it will have minimal support for DTD's
and traditional SGML authoring features. The editor can enforce hierarchical
integrity and infer types for new elements, however much of the work planned
in this area will wait for DOM DTD support to stabilize and a validating
SAX to emerge.
A retail product based on this class library is targeted to ship in
late August (Java and Smalltalk) on a fully supported basis. It would be
useful for developers who want to begin working visually with XML now and
yet are willing to wait for additional features. More details will be made
available at the session.
Note: InDelv has now annnounced its plans to offer a new commercial XML/XSL editor in mid-September. It is to support the new XSL working draft released by W3C on August 18, 1998. [announcement, local archive copy] -rcc 980826
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/tbray.htm]
Construction of the Annotated XML Specificiation
Tim Bray
The idea of the annotated XML specification is simple; a collection of
relatively small pieces of commentary attached directly to the electronic
version.
Since there are some parts of the XML spec that clearly cause people trouble,
it is important that the annotations be very highly localized.
The decision to use XLink and XPointer was easy, and the result was
gratifying, but the
hurdles along the way were of considerable technical interest.
The included:
- Implementation of partial XLink and XPointer processors.
- Design of a language to contain the annotations and all the XLink
and XPointer apparatus.
- Bridging the gap between the XML form of the spec and annotations, and
the XML-oblivious browsers of the world.
This presentation will introduce each of these technical hurdles, describe
the chosen solutions, and offer a hindsight-based opinion as to what the
correct solutions might be.
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/peterm-r.htm]
The Virtual HyperGlossary - adding semantics and ontology to XML
Peter
Murray-Rust and
Lesley West
VHG Consulting, Ltd
XML allows authors to create their own markup (e.g.
<DOMAIN>), but no direct handle for answering 'what does
this mean?'. One of the most powerful (but very cost-effective) ways of
adding meaning is by linking to terminological resources such as glossaries
or dictionaries. Although there are a large number of HTML-based glossaries
(often of very high quality) on the WWW there is no consistent syntax. It
is almost impossible to search for terms in a robust and meaningful manner.
For example the semantics of brackets in "Domain (DNS)" are different from
the semantics in "eXtensible Markup Language (XML)". The first is a
qualifier, perhaps distingusing the term from "Domain (protein)", while the
second is an acronym.
We have developed a simple but scalable DTD for terminology based on ISO
12620 (Data Categories for Terminology). This DTD uses a deliberately small
subset of about 12 categories (e.g. <term>, <acronym>,
<synonym>, <abbreviation>, <definition>). Others
can be added through an attribute-based syntax. Hyperglossary is
used in a wide sense to include any semantic resource composed of
standardised subcomponents such as data sheets or catalogues. Thus a
molecular hyperglossary could include chemical structures, measured
properties and commercial availability.
Because XML is tree-based it supports hierarchical collections (thesauri,
catalogs, etc.) in a natural and powerful manner and we have found that
most of our current examples fall into it. For non-hierarchical
relationships (<see>, <seeAlso>, multiple
broaderTerms, etc.) the VHG uses the full power of XLink to add additional
structure. Thus terms can be grouped in different classifications by using
xml:link="extended" with locator references to
the linked terms. Equivalences (e.g. in multilingual glossaries) can be
defined through an external link database. This allows different language
curators to develop their glossaries in parallel and link the terms through
XML ID's.
Curators are a key aspect of VHGs and we expect that many VHGs will be
XLinked to 'neighbouring glossaries' especially where the curators know
each other. This avoids the pitfall of a 'grand universal classification'
and allows readers to explore multiple interpretations of the same term.
Learned societies and other authoritative providers of public information
can benefit by making their current terminologies (often paper-based)
available. We shall show an example from a collaborating International
Union and we are also partnering with providers of commercial semantic
resources.
For organisations developing 'knowledge capture' strategies, terminology is
an essential component. By encouraging distributed hyperglossaries on an
Intranet an organisation can empower invidividual units to capture and
manage their terminology without excessive central overheads.
The VHG is applicable to any domain, but has specific support for technical
subjects. We have encoded scientific units (SI and non-SI) into VHG format
and this means that unit conversions (currently very problematic) can
become automatic.
The VHG DTD is completely implemented in JUMBO-VHG (JUMBO is a freeware
system based on SwingSet) and demonstrations of many applications will be
given. These will include component-based creation and editing of
glossaries. We shall also show Virtual HyperMarkup which is the
detection of terms in XML-based documents and their linking to appropriate
glossaries. This enhances the semantic value of the document and should
also lead to normalisation of information if glossaries are widely
available, e.g. through cascading glossary servers.
Example
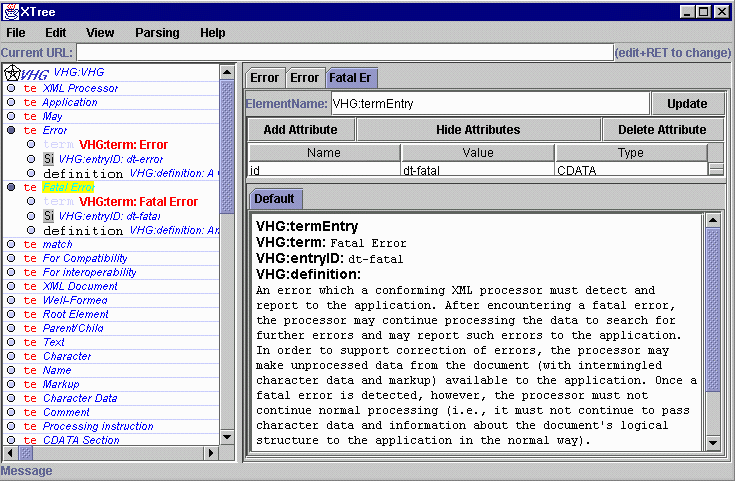 The terms in REC-xml-19980210.xml have been abstracted and
transformed to validate against the VHG DTD. They are displayed in
JUMBO-VHG with the terms in a 2-level tree (left) and a specific term
(dt-fatal) shown right. The style is one of 7 builtin JUMBO styles.
The terms in REC-xml-19980210.xml have been abstracted and
transformed to validate against the VHG DTD. They are displayed in
JUMBO-VHG with the terms in a 2-level tree (left) and a specific term
(dt-fatal) shown right. The style is one of 7 builtin JUMBO styles.
References
Full information about the VHG including references can be found at the
VHG Home Page
(a) Also at Virtual School
of Molecular Sciences, University of Nottingham, UK
(b) VHG is being registered as a trademark by VHG Consulting, Ltd.
Note: See the main database entry, "Virtual Hyperglossary (VHG)."
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/fensterm.htm]
Using XML in Knowledge Management
Kurt D. Fenstermacher
Intelligent Information
Laboratory
University of Chicago Dept. of
Computer Science
We are building a system (called SingleSource) for
information capture and
access within a strategic consulting firm. Within the firm, consultants
working with
clients request information on topics ranging from: "What's the GDP
per capita of
India?" to "What factors will impact the demand for petroleum
products over the
next decade?" While researching these questions, information
professionals need to
search and collate results from many sources, both online and offline.
Our prototype
provides a front-end for researchers within the organization to search
multiple online
sources, view clustered search results and finally produce a finished
document summarizing
the requested information.
Smart information retrieval
The SingleSource environment will aid researchers in finding
information,
while simultaneously storing information about their search strategies.
As the system
"learns" search strategies for kinds of search queries, it will
use that
information to improve later retrievals. For example, if one researcher
(who specializes
in the automotive industry) frequently uses only a handful of sources to
answer questions,
the system will store an association between automotive questions and
those few (but
highly relevant sources). When a less experienced researcher has a
question about the
automotive industry, SingleSource will focus the queries on the
best automotive
sources, and recommend the automotive specialist as a contact.
XML in SingleSource
The prototype system depends on XML (or XML-based technologies) in
several ways (each
description is followed by a note regarding its likely stage of
completion by conference
time):
- Many system components often need to share information, and XML
documents are used to
pass object-oriented information from component to another. For
example, a single search
query is sent to multiple information sources, and the results are
combined and then
clustered into semantically similar groups. The clusters (which can
themselves contain
clusters) are represented in a tree structure, which is then output
as an XML document.
(Will be completed by conference.)
- Knowledge capture is an important aspect of SingleSource.
In particular, we
plan to store information about searches as they are
conducted. (For example, we
will track which sources were used for a query, and which sources
consistently return the
most useful results over time.) We are currently working on a
process to generate
this meta-information in an XML-based format (such as RDF or MCF).
(Will be completed by
conference.)
- To be a useful front-end, the system must seamlessly integrate many
different
information sources (including Web-based, intranet and CD-ROM
databases, for example).
Representations of what data is available, and how to access it, must
be built for current
sources. In addition, new sources should be easily described, so they
can be incorporated
into SingleSource on-the-fly. We are currently evaluating
WIDL for this purpose,
although a custom-designed alternative would also be XML-based. (Will
be completed by
conference.)
- SingleSource generates extensive information about the
context of a task (which
will be stored in an XML document) and that task information must be
stored and managed
persistently. Because we can easily transfer data between XML and
object representations,
we are incorporating an object-oriented database (Object
Design's
ObjectStore) to store XML and other object data. (Likely to be
completed by conference.)
[GCA Website URL: http://www.gca.org/conf/meta98/xmldev98/kimber.htm]
Eliot Kimber Presents: Grove-based XLink Implementations
Eliot Kimber (Isogen) will give a demonstration of PHyLIS, Personal HyTime
Link Information System, an attempt to implement the HyTime standard using
componentized software techniques (ActiveX). PHyLIS uses a literal
grove-based
approach and demonstrates the ability to apply XLink, SGML architecture
(AFDR),
and HyTime processing to XML documents in a completely standards-based
environment. PHyLIS is designed to be an open integration platform that is
infinitely extensible. See www.phylis.com for details, including source code.
Eliot will also demonstrate an implementation of an XLink processor
developed by Masatomo Goto of Fujitsu Laboratories. This processor uses an
implementation of the XLink property set based on the HyTime property set.
Supported features include:
- Simple and Extended links
- Unidirectional and multidirectional links
- Inline and out-of-line links
- Extended link groups
- Attribute remapping (xml:attributes)
Fujitsu Laboratories plans to integrate this XLink processor with its
"HyBrick"
browser later this year. For further information on "HyBrick", see
http://collie.fujitsu.com/HyBrick.
Note: Presentation slides for "Grove-based XLink Implementations" ['Xlink and Groves'] are available online. See also the main section for XLL (XLink, XPointer).