[Cache from http://www.cse.unsw.edu.au/~soda/ 2000-11-03.]
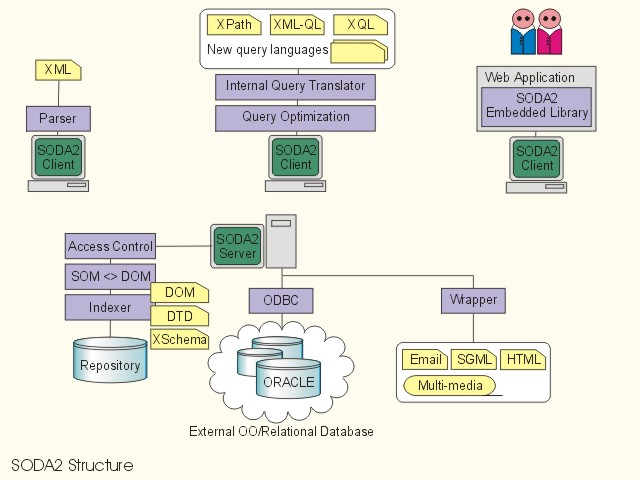
SODA2 (for Semistructured Object DAtabase, Version 2) is a client-server, semistructured database system which is tailor-made for managing XML information. Query processing and optimization are implemented in and executed by clients while the server is responsible for storing and retrieving objects; handling transactions, object locks, garbage collection, database backups and recovery. Object access management policies and transaction models can be changed to fit the needs of a specific application without affecting the application code. Online database backup is supported without stopping the client working with the database. A lazy object conversion approach is used for versioning. Different clients can simultaneously work with different versions of DTD.
SODA2 server is available on Linux, Solaris and Windows NT. Besides running on these platforms, its client library and tools are also available in Java.
The novel SODA2 architecture facilitates several crucial features which are seldom available in other database systems. The SODA2 query processor is mainly located at the client side. Each query processor contains an internal query translator that maps an query from one language into a SODA2 internal micro-query language. Therefore, SODA2 supports multiple query languages which include XPath expressions, XQL and XML-QL to date (SODA QL is supported for downward compatibility with SODA version 1).
Web and e-commerce applications can be built by linking to the SODA2 client library. The library interface supports embedded query languages such as XPath, XQL, and XML-QL for rapid application development. XML parser or loader is itself a database client and multiple loaders can be run simultaneously to load multiple documents while the database is being updated concurrently by multiple users at the same time. This feature is a must for large-scale enterprise applications instead of small corporate or personal applications.
Advanced wrapper system plays an important role in SODA2, as it provides a bridge between SODA2 database and other different data types or different data sources, for instance, emails, HTML, SGML, RTF, EDI, and so on.
SODA2 server itself consists of a number of components. Each of these components is responsible for its own task and interacts with other components by means of a strictly defined interface. These components include a storage memory manager, an access control manager, a transaction manager, a page pool manager, an object access manager and an index manager. The modular design makes SODA2 possible to choose different implementations for each component and also to fine-tune SODA2 according to the efficiency of various database management algorithms and strategies for specific application requirements. SODA2 server can hook to other relational database systems such as Oracle or Sybase through ODBC interface. The underlying physical repository supports standard DOM, and SOM (SODA Object Model) which provides system-level interface to the SODA2 physical storage. Compression and low-level optimization are supported with meta information such as DTD and XSchema defined by the users or automatically learnt from the XML documents.
SODA2 is designed to achieve maximum performance for handling simultaneous client requests. Advanced algorithms for caching and prefetching XML objects and storage pages are used for this purpose. By splitting work into separate threads of control, SODA2 exploits the benefits of parallel execution especially on multiprocessor architectures such as dual pentium PCs. A specially designed synchronization library provides a high-performance interface for multitasking (such as: mutex, event, semaphore) that could be more efficient than many default libraries come with an operating system or a compiler. Access mechanism to primitive XML objects is extensible so that it is possible to specify specific algorithms for object caching and synchronization, allowing to reach the highest degree of performance for specific application. SODA2 is tailor-made for XML data, even within the lowest layer of the storage and retrieval engine, everything is directly stored as XML nodes without mapping to another format, therefore it is fast and suitable for building web applications than other OO or relational database systems.
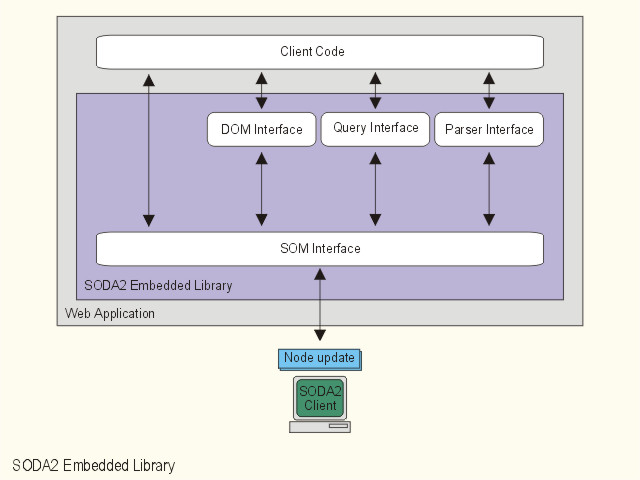
Each SODA2 client contains an XML parsing interface, an query interface, and a DOM interface. Parsing interface provides functions for parsing and validating XML data from clients, it is also responsible for pretty-formatting XML document output. The query interface provides an embedded query interface to allow user developed applications to query SODA2 in the easiest way. As SODA2 query processor contains a query translator and operates internally on a micro-query language and SOM, multiple query languages are supported. Curently SODA2 supports XPath expressions, XQL, and XML-QL. It follows the W3C's DOM recommendations so that non-database applications can be easily built and ported to SODA2 with DOM interface and ignore without its rich database functionalities. Alternatively, advanced users can call more sophisticated functions defined in the SODA2 Object Model (SOM) interface from the lower layer to develop time-critical applications or create customized plug-ins with their own indexing and optimization schemes.
XML is open and portable but it sacrifices storage space by making it verbose in text file format. The SODA2 physical repository compresses XML documents by learning their DTDs and Schemas to achieve an extraordinary high compression ratio.
SODA2 follows the Unicode standard for support of multilingual documents and country-specific character set.
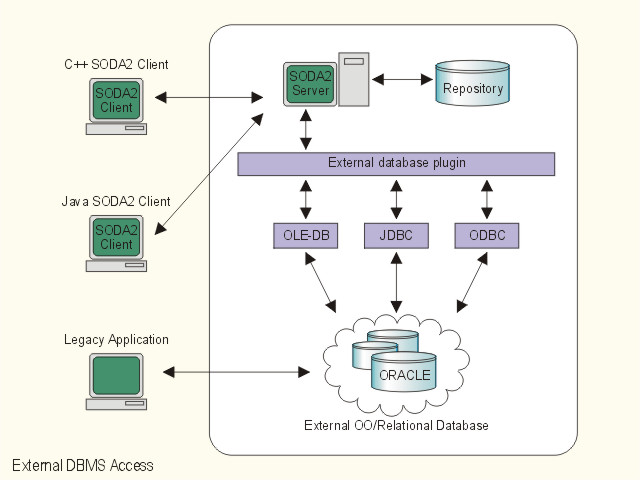
SODA2 follows the DBMS interface standard such as ODBC, JDBC and OLE-DB (NT version only). As a result, SODA2 applications can also query other third parties' database systems through these interfaces. Legacy database applications and SODA2 clients can co-exist in harmony and thus application porting/migration is no longer expensive.
| Relational DBMS | SODA2 |
|---|---|
| Data is stored in multiple tables | Data is stored in a single tree |
| Adding fields to just one record involves restructuring of entire tables | Adding fields to a record is a trivial operation which does not affect other records |
| Minor extensions or changes to database structure may require rewrite of client programs | Most changes to database will not break old clients, due to the flexible nature of the SODA2 XML query language |
XML data can be stored in raw form (ie as a text
file) and must be parsed at the client in order to gain
benefits of XML structure
XML data is stored in a table format which sacrfices information about tree structure |
XML data is stored in a tree structure which preserves all XML information and allows efficient query and update of this information at the server level |
| Table structure allows some query optimisation which is not possible with tree structure. | Tree structure allows some query optimisation which is not possible with table structure. |
| Storing information about relationships in the data requires careful design of database. Querying this information can get complicated. | XML structure implicitly holds a lot of information about relationships between data. Query language is designed to take advantage of this. |
| It's designed based on old database principles. In order to take full advantage of XML, either simplicity or speed, and often both, must be sacrificed. | It's designed and built specifically for storing and querying XML data. |
Similar comparisons can be made against OODBs.
SODA2 extends the idea of DOM further. Information regarding access control, recent query results, schemas, indexes and internal system states are stored together with the XML documents under one XML tree with unified node structure. The whole system can be maintained by the appropriate queries, updates or system commands. Unified structure helps the storage manager for space allocation and defragmentation. Database snapshots and backup can be done easily or in remote without stopping the clients working with the database.
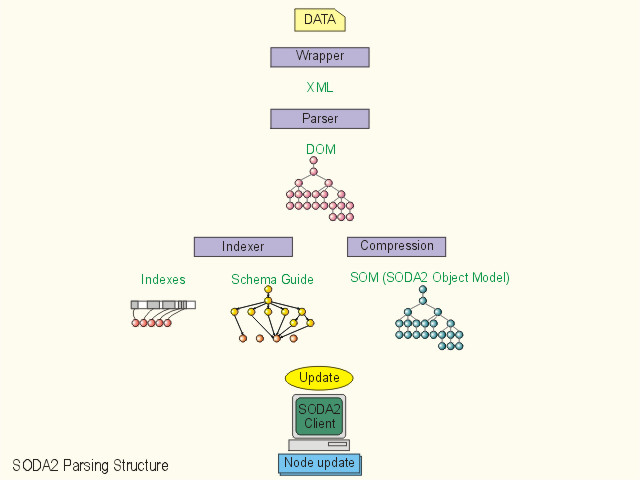
A SODA2 tree consists of a collection of nodes. There is exactly one root node, which has no parent. All other nodes have exactly one parent. Each node may have zero or more children. Each node has a type and may contain encoded Binary Data (usually representing a string). It maintains also an extra Attachment Link pointing to other nodes and storage structures in the database. The purpose of the Attachment Link depends on the node type.
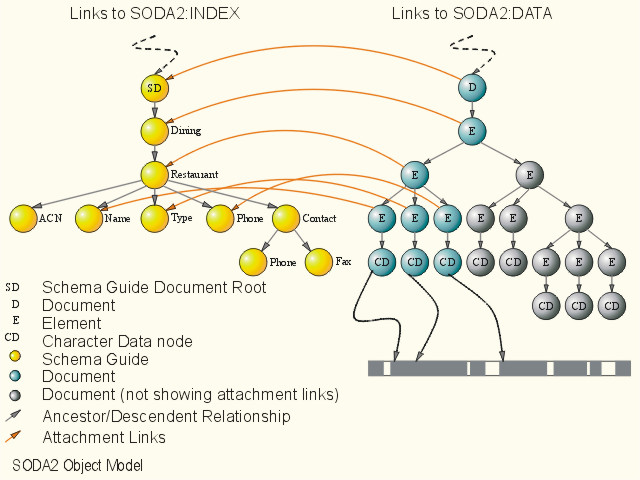
The XML document below will generate a SODA2 tree which can be visualized logically in the above diagram.
<?xml version='1.0'?>
<Dining>
<Restaurant ACN="1012385">
<Name> The Bamboo Restaurant </Name>
<Type>Vegetarian</Type>
<Phone> 92312210 </Phone>
</Restaurant>
<Restaurant ACN="1372358">
<Name> Chen's Seafood Restaurant </Name>
<Type> seafood </Type>
<Contact>
<Phone> 90123210 </Phone>
<Phone> 90123219 </Phone>
<Fax> 90128899 </Fax>
</Contact>
</Restaurant>
</Dining>
A Schema Guide is built incrementally for each XML document. A Schema Guide represents a logical view of a given XML document. It may contain the metadata of that document and some system parameters or statistics. The SODA2 XML parser will make use of any internal or external DTD to help generating the Schema Guide, or the parser will generate the DTD itself if none is provided. Element names from XML documents are stored as Schema Guide elements. Each XML element node (E) locates its name (i.e., element name) by following its link pointer to the associated Schema Guide element node. Since typical XML documents tend to have repeated, long element names (more than 6 characters) and thus the above method give a good compression ratio.
Attributes are stored within the Element node itself in the Binary Data field which differs to the Schema. Attribute name-value pairs are encoded using simple offset. Assuming the fact that typical attribute length is small and attributes are less frequently updated than CData or elements. Hence fewer objects and persistent object pointers are required and thus less page fault is resulted.
The Character Data for each document is stored in a special structure. This structure has two parts: index and data. The index is a linked list of pointers to the cdata strings in the data part, in the order of its occurrence at the XML document. CData nodes in the document tree keep track of its location at the document tree. Since cdata is not stored within the document tree, traversal of the document tree for operations which only involves cdata is avoided. This certainly improves the performance due to better locality of reference in pure text search.
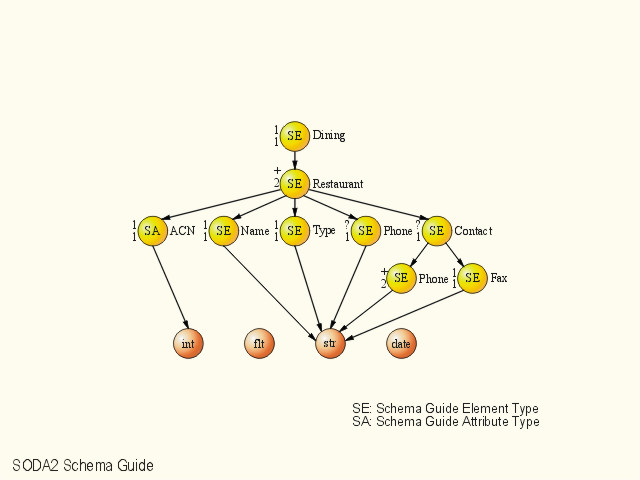
Each XML Document Node has a node link to its corresponding Schema Guide. Schema Guide summarizes the structure, datatype and statistics of XML documents stored in SODA2. A Schema Guide is being generated when an XML document is loading into the repository. It will be incrementally maintained and updated every time when its corresponding XML document is updated.
In general, Schema Guide is significantly smaller than its corresponding XML Document. Therefore, it is usually much faster to acquire the idea of the document from the Schema Guide before searching the actual document tree for the query answer. For example, queries with path expressions that do not match any paths encoded in the Schema Guide can simply be rejected. However, without Schema Guide, this query costs the examination of every node at the Document tree in the worst case. Schema Guide also store the occurrence of the descendant nodes, queries containing exists, sequence or position can be speeded up when no possible result can be determined from the Schema Guide.
For query optimization and efficient processing of primitive query operators, Schema Guide also includes the datatype of character data and information about XLink and XPointer.
Each query result is cached under the SODA:WORKSPACE, with the statistics including the query processing time and number of requests received, etc. Query result node contains solely links to the satified result nodes. A result node with all children satifies a query will only be pointed by a single cached query result node otherwise the result node will be expanded in that particular descendent level. For example a simple query that selects the whole XML document will generate only one result node or, otherwise, the whole XML document would be duplicated. This saves storage space and hence query processing time ( and re-query time too), but it introduces many technical challenges concurrency control and transaction management. Garbage collector makes use of the query history statistics to determine when the data in the query cache should be freed.
To support concurrent queries and updates, SODA2 supports several locking schemes to suit different applications.
A SODA2 query does retrieval without updating the data, thus it never changes the data involved in the result of another query. However, when an update statement changes the data involved in the result of the previous query, the cached query result would be marked as dirty and will be garbage collected. Alternatively, users may turn a parameter on such that the cached result would still be marked as dirty but will not be garbage collected. Document fragments linked from the cache will still be output but user will get informed. This feature is useful if an user want to know when a particular part of an XML document has been updated. When a node deleted within an XML document, it would be stored at a separate list in order to avoid dangling links at the cached query results. Deleted nodes and cached query results are periodically garbage collected. Frozen version of the query result is supported by materialized views by cloning the query result. Materialized views can be incrementally maintained or static.
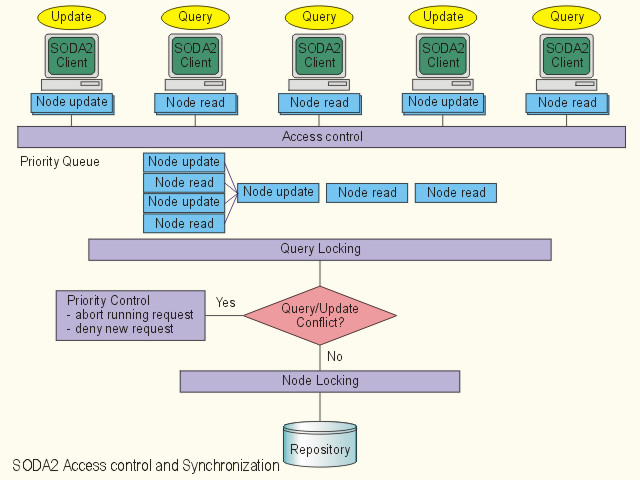
Each query or update has an associated Locking and Priority Level. Query about the internal SODA2 nodes always have higher priority than the queries regarding document data. There are different types of priority level (real-time, system, data) to suit different application requirements. Queries and updates can execute in parallel even within a same XML document unless someone is already holding a write lock for the whole document. Higher priority request is able to abort an execution of a lower priority request and the lower priority request need to be restarted afterwards. Running time is also a factor to determine the priority level when aborting an executing request is needed. The object manager in the server always make sure every single node query and update are atomic.
Acknowledgement: This page is created by Raymond Wong with contributions from Franky Lam and Milivoj Savin