[Mirrored from http://www.cogsci.ed.ac.uk/~ht/new-xml-link.html on February 11, 1997; see later versions from the official W3C sites]
This is a fragment of a revision of a W3C Working Draft for review
by W3C members and other interested parties. It is a draft document
and may be updated, replaced or obsoleted by other documents at
any time. It is inappropriate to use W3C Working Drafts as reference
material or to cite them as other than "work in progress".
A list of current W3C working drafts can be found at http://www.w3.org/pub/WWW/TR.
Note: Since working drafts are subject to frequent change,
you are advised to reference the above URL, rather than the URLs
for working drafts themselves.
This work is part of the W3C SGML Activity
(for current status, see http://www.w3.org/pub/WWW/MarkUp/SGML/Activity).
Extensible Hyper Linkage (XHL) is a simple set of constructs that
may be inserted into SGML documents to describe links between
objects. XHL is designed to use the power of SGML to create a
structure that can describe both the simple unidirectional links
of today's HTML, as well as more sophisticated multi-ended, typed,
self-describing links. The SGML constructs used in XHL are simple
enough to be available in the Extensible Markup Language (XML)
subset of SGML. XHL is completely described in this document.
11 February 1997
This draft is intended for public discussion.
It is subject to approval by the W3C SGML Editorial Review Board
1. Introduction
1.1 Origin and Goals
1.2 Relationship to Existing Standards
1.3 Notation
1.4 Terminology
1.5 Types of link types
2. Link Recognition
2.1 Link Recognition by Attribute
2.2 Link Recognition by Element Type
2.3 Link Recognition by Other Means
3. Link Elements
3.1 Information Associated With Links
3.2 Multilink
3.3 Terminus Links
4. Addressing
4.1 HREFs and Reference Types
4.2 Location Source
4.3 SGML Reference Types
4.4 URL Reference Types
4.5 TEI Locator Reference Types
4.6 Query Reference Types
5. Extended Link Groups
5.1 Identifying Extended Link groups
5.2 LINKS and LINKSET Elements
A. The TEI extended pointer syntax
A.1.1.1
Location Ladders
A.1.1.2
Location Terms
A.1.1.3
The ROOT Keyword
A.1.1.4
The HERE Keyword
A.1.1.5
The ID Keyword
A.1.1.6
The CHILD Keyword
A.1.1.7
The DESCENDANT Keyword
A.1.1.8
The ANCESTOR Keyword
A.1.1.9
The PREVIOUS Keyword
A.1.1.10
The NEXT Keyword
A.1.1.11
The PRECEDING Keyword
A.1.1.12
The FOLLOWING Keyword
A.1.1.13
The TOKEN Keyword
A.1.1.14
The SPACE Keyword
A.1.1.15
The FOREIGN Keyword
B. Production note
C. W3C SGML Working Group and Editorial Review Board
C.1 W3C SGML Working Group
C.2 W3C SGML Editorial Review Board
Extensible Hyper Linkage (XHL) describes a set of constructs which may be inserted in SGML documents to describe links between objects (the objects may or may not be (in) SGML documents). A link, as the term is used here, is a relationship between two or more data objects or portions of data objects, called its endpoints. Not all relationships are links: the relationship of a chapter to its paragraphs, of one word to the next, or any non-explicit relationship, are not considered links here. The relationship expressed using SGML's id and idref attributes is a link, subsumed within the framework presented here.
Links in XHL are described by elements contained in SGML documents. Such an element is called a link description, or linkd. The link description element itself may, but need not, be one of the endpoints of the link it describes. A link description can be understood as a mapping from document instances and their contexts to links.
Just as SGML Applications consist of a DTD and a specification of the meaning or significance of the structures defined therein, so an XHL Application must include a specification of the meaning or significance of the link names and endpoint names it employs.
XHL is part of the overall XML effort, on which see .... It aims to provide an effective yet compact means for describing links that can have multiple named endpoints, indirection, and flexible yet precise means for locating endpoints in all kinds of data. It also aims to represent the abstract structure and significance of links, leaving rendering and other issues of link-engendered behaviour to stylesheets or other mechanisms as far as practical (it is acknowledged that there is a grey area here).
Three standards have been especially influential on XHA:
Many other relevant linking systems have also informed this design, including Dexter, MicroCosm, InterMedia, and others.
The following basic terms for parts of links and link descriptions apply in this document. They also appear on the following structural diagram of a simple link.
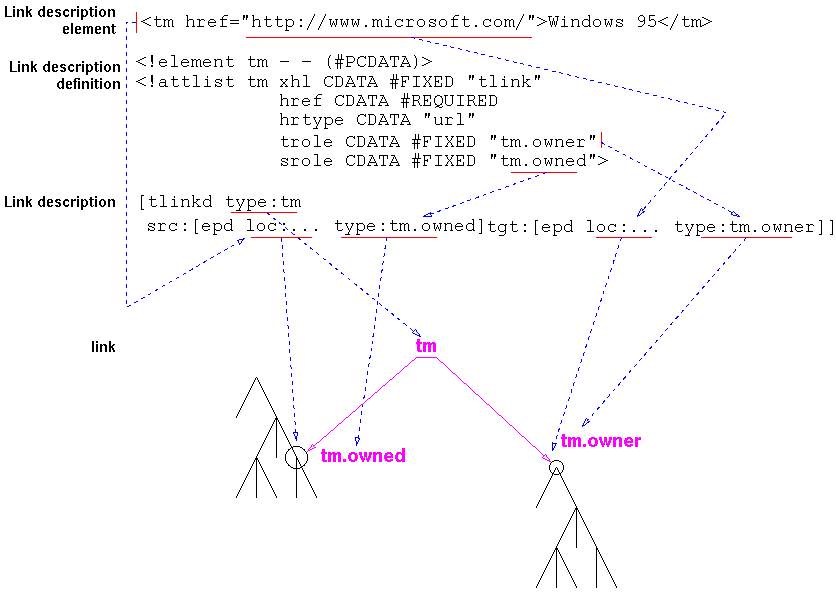
Many papers have been written on how to categorize links by type. The XHL effort distinguishes several major axes for organization. XHL provides ways to define a link's type along each axis, but only provides a standard vocabulary for the first kind of typing, namely link relationships. The vocabulary of XHL link types can be extended by creating sub-types at all levels.
An XHL Link is an element contained in an SGML document. The fact that an element is a link must be recognized reliably by software in order to provide appropriate display and behavior. XHA links may be recognized based on the use of specially reserved attributes, the use of specially reserved element types, or through other means not described in this specification.
A link may be recognized based on the value of a reserved attribute
named XHL-. Possible values are MLINK,
TLINK, POINTER, XLG, and
XLD, signalling in each case that the element may
be treated as an element of the indicated type, as described in
this specification.
An example of such a link:
<A XHL-="TLINK" HREF="http://www.w3.org/">The W3C</A>
|
If the document is an XML document, a link may be recognized based
on the use of the reserved types -XML-MLINK, -XML-TLINK,
-XML-POINTER, -XML-XLG, and -XML-XLD.
An example of such a link:
<-XML-TLINK HREF="http://www.w3.org/">The W3C</A>
|
The fact that a particular element type is to be recognized as an XHL link may be asserted by external means to the software processing the document. For example, such a program might have special sensitivity to the syntax of HTML, HyTime or some other hyperlinking syntax which is compatible with XHL.
An example of such a link:
|
XHL defines two types of Link Elements. First, a general Multilink
(MLINK) which is out-of-line and may be used for
multi-pointer links, links into read-only data, and so on. Second,
a more constrained Terminus Link (TLINK), which is
always in-line and one-directional, very like the HTML <A>
element.
This specification describes a variety of information that may be (and in some cases is required to be) associated with a link. As a matter of principle, this information is given entirely as markup rather than as character data; thus, any text contained in the link elements may be assumed to be a valid candidate for display along with the rest of the document in which the link is embedded.
The following information may be provided with link elements:
Type
TYPE
attribute. A set of pre-defined link types is included in this
specification. A sub-type may be created by appending "."
and the sub-type name. This process may be repeated in order to
create type hierarchies.
Role
ROLE attribute.
A starter set is similarly provided and similarly extensible.
Terminus
HREF, HRTYPE, LOCSRC,
IMPLIED-LOCSRC) as described in the next major section,
Addressing.
Explainer
TITLE
attribute. This specification does not require that applications
make any particular use of the explainer.
Behavior
BEHAVIOR attribute may be used for an author
to communicate intentions concerning the traversal behavior of
the link; this specification does not provide any default values,
nor does it require that applications make any particular use
of this information.
Formatting and Display
RENDER attribute may be used for an author
to communicate intentions concerning how the link and its termini
should be rendered; this specification does not provide any default
values, nor does it require that applications make any particular
use of this information.
A multilink can associate any number of termini, and an application may be expected to provide traversal between all of them (subject to semantic constraints outside the scope of this paper). The key issue with multilinks is how to find them, since they do not necessarily co-occur with any of their termini, and often are located in completely separate documents. This process is discussed under XHA Link Groups below.
A multilink's pointers are expressed as child elements of the multi-link, each with its own set of attributes. Here is the declaration for the XML form of the multilink:
|
Terminus links are very much like HTML <A> or TEI <XREF> elements, but with more general reference capabilities. A terminus link may contain only one pointer; thus there is no necessity for a separate child element, and the pointer attributes appear attached directly to the terminus link. The location where the link is placed is not required to act as a terminus; that is to say, there is no requirement that this location can be reached from the explicit terminus, though applications are free to provide that capability if they have a means of knowing the link exists.
For simplicity and compatibility with existing practice, the link TYPE and ROLE may be omitted.
Here is the declaration of the XML form of the terminus link:
|
XHA links can use many kinds of data as termini:
Note also that there is no requirement that a terminus be a singular data object; there is sufficient opacity in addressing methods that a single pointer might in fact address multiple data objects, which together would be considered a terminus.
A special case arises when the terminus indicated by a pointer proves to be another link element. When an application traverses or displays such a link, it may be desired to read and traverse that link to whatever its terminus (termini) is (are) and operate on the result of that traversal. This has the benefit of allowing greatly increased indirection and flexibility; on the other hand, it might lead to potentially unbounded delays in traversing simple-looking links. This specification does not constrain the behavior of applications in this situation.
Each pointer is required to address a terminus using an HREF (HREF may have at one point stood for "Hypertext reference"; the name is adopted for compatibility with existing practice). An HREF is a character string containing the information used to address the terminus. An HREF may operate as a locator, as with a URL, a name, as with a URN or SGML FPI, or a query.
The HREF and reference type are provided, respectively, in the
HREF and HRTYPE attributes.
The location source is specified using the the location-source
attribute. The format of the location-source string is not specified;
to be useful, clearly it must be in a form that can be processed
by the processor that can deal with the HREF and reference type
to which it is attached. If the location-source attribute is omitted,
the location source is implied according to the rule indicated
by the IMPLIED-LOCSRC attribute.
The implied-locsrc attribute takes one of the values
REFERRER or DOCELEM. The value REFERRER
indicates that the implied location source is the referrer element.
The value DOCELEM indicates that the location source
is the document element, the document's root element.
The default value for implied-locsrc is DOCELEM.
SGML HREFs use standard SGML Element and Entity addressing mechanisms.
If the reference type is ENTITY,
then the HREF must be an entity name which references an external
entity. If the reference type is ELEMENT,
then the HREF must be the value of a unique identifier attribute
within the current document. If the reference type
is SGML, then the HREF must contain an entity name
interpreted as with ENTITY, followed by the character
"#", followed by the value of a unique
identifier attribute within the document referenced by the leading
entity name.
If the reference type is URL,
then the HREF must be a URL.
URLs may be used to refer to data objects of any kind.
If the reference type is TEI,
the HREF must be a TEI locator.
XHA uses a subset of the syntax defined for TEI extended pointers. These operate on groves as defined in DSSSL, using the grove plan (set of structural information) specified in HyTime. Every construct in such locators has a corresponding expression in DSSSL's SDQL query language, and most also have direct equivalents in the HyTime location module. A full description of the syntax is available in the TEI Guidelines; a summary appears as Appendix A of this document.
The basic form of such a locator is a series of location terms, each of which specifies a location, either absolute or (more frequently) relative to the prior one. Each term has a name, such as ID, CHILD, ANCESTOR, and so on, and can be qualified by parameters such as an instance number, element types, or attributes. For example, the locator string "CHILD (2 CHAP) (4 SEC) (3)" refers to the 3rd child of the 4th SEC within the 2nd CHAP within the referenced document.
Such a locator can be considered a query, and the extended pointer syntax a query language. Thus it can be appended to a URL that identifies an appropriate document, in order to locate some portion of that document; or can be declared as a HyTime query, and thus used in a fully HyTime-conforming manner. [need to add an example of the necessary declarations, similar to Eliot's straw proposal].
XHA omits some features of TEI extended pointers:
[We may want to include a proposed TEI addition that provides for pointing directly to the values of attributes per se]
[Add a way to specify additional query languages]
XHL describes the syntax of link elements embedded in documents. Many applications, when processing a document, may wish to process not only the links embedded in that document, but links in other documents which point into it. For example, it may be desirable to highlight the termini of such links to make the linkage network's existence apparent. In other words, it may be appropriate to process, rather than a single document, a group of interlinked documents.
XLG and XLD elements, just as with MLINK, TLINK, or POINTER elements,
may be recogized by the use of the XHL- attribute
with the values XLG or XLD, in XML documents
by the use of the reserved element types -XML-XLG
and -XML-XLD, or through other external mechanisms.
Here is the declaration for the XML form of the XLG and XLD elements:
<!ELEMENT -XML-XLG (-XML-XLD*)>
|
Multilinks may only occur in restricted contexts, in order to facilitate software finding them (their related termini, of course, may be anywhere at all).
First, multilinks may occur in the LINKS element of a document, which is part of its header. So long as any part of the document remains open, all termini of all multilinks in the header shall be known to the software and available to the user. Applications may apply their own conventions for when a document is no longer considered "open", except that any document any part of which remains in view, is open by definition.
Second, multilinks may occur in separate documents that contain only multilinks, called LINKSETS. Any document may specify any number of other documents and/or LINKSETS that should be opened. All termini specified in a LINKSET shall remain active at least as long as any of documents that points to that linkset remains open. [There is an argument to be made for keeping them open longer, such as for a whole session, or while any documents that have termini in the linkset are open; or for letting the referencing document(s) state how long they want it open; etc]. Software shall also provide a way for users to specify global or other LINKSETS, which should be kept open more persistently, such as throughout an entire user session, or automatically for all user sessions.
Each location pointer specification consists of a sequence of location term s, each of which consists of a keyword specifying a location type followed by one or more parenthesized parameter lists, each of which specifies a location value via a list of parameters. Location types and values, and the parameters within a location value, must be separated by white space characters.
Using terms borrowed from HyTime , we say that each TEI location term in a specification provides the location source for the next, and the entire specification is equivalent to a location ladder . By specifying the entire ladder in a single attribute value, the TEI extended pointer mechanism greatly reduces the syntactic and processing complexity of hypertextual pointers.
In formal terms:
ladder ::= locterm | ladder locterm
|
The keywords used in location terms are these; references to the tree mean the tree representing the SGML document hierarchy.
root
here
id
ref
child
descendant
ancestor
previous
next
preceding
following
pattern
token
str
space
foreign
In formal terms:
|
The keywords are not case sensitive.
Each location term specifies a location in the target document;
this location may be a single point, more often a span of text
(often the span of a single element) within the target document.
The location ladder as a whole is interpreted from left to right,
and each location term specifies a location relative to the location
specified by the sequence prior to that point (i.e. to its location
source). Unless here or id is specified
as the first location term, the beginning location source is always
root . An empty location sequence thus is the same
as root and specifies the entire destination entity.
Some of the location terms make sense only in documents that have
tree-like representations; these are id , child
, ancestor , descendant , previous
, next , preceding , and following
. The latter six involve traversing the tree representing the
SGML document hierarchy and are most easily understood when their
location source is a single SGML element. If the location source
is not a single SGML element, the tree-traversal keywords operate
upon its beginning end-point, its front end (in English, this
will be the leftmost point of the location source; in Arabic or
Hebrew it will be the rightmost point). In this case child
and descendant have no meaning, since character data
has no descendants in the document tree; the first ancestor
of such a location source is the element immediately containing
the character data in question, and the siblings referred to by
next and previous are the other children
of that immediately containing element.
The details of each keyword are given below, along with definitions of their syntax and semantics of their results. Examples are also provided. It is strongly recommended that when IDs are available, they should be used in preference to the other methods for pointing defined here.
For all keywords, the description assumes that the target document does in fact contain a span or element which matches the description; otherwise, the location term has no referent and is said to fail . If any location term fails, the entire pointer fails. No backtracking or retrying is performed.
The location term root selects the document element.
Since root is assumed as the implicit first term
in any ladder, the following two location ladders have the same
meaning:
ROOT DESCENDANT (2 DIV1) DESCENDANT (2 DIV1)
|
The keyword here designates the location at which
the pointer element itself is situated; it allows extended pointers
to select items like the paragraph immediately preceding the one
within which this pointer occurs . Since it ignores any existing
location source, this keyword typically makes sense only as the
first location term in a location specification.
To designate the paragraph preceding the current one , the following location ladder could be used:
|
(See below for descriptions of the keywords
ancestor
and previous .)
The resulting location is the element within the destination entity whose ID attribute has the value specified as the location value.
For example, the location specification
|
chooses the necessarily unique element of the destination entity which has an attribute of declared value of type ID, whose value is
a27 .
The child location type specifies an element or span
of character data in the document hierarchy using a location value
which functions as a domain-style address. The
value is a series of parenthesized steps, separated by white space.
Each such step represents one level of the hierarchy within the
location source. Each step may contain one or more parameters
separated by white space and interpreted in order as follows:
ALL
In formal terms, the location value of child is a
series of steps :
|
Location values of the same form are also used by the keywords
descendant , ancestor , previous
, and next.
If an instance indicator alone is specified, as a number n
, it selects the n th child of the location source. If
the special value ALL is given, then all
the children of the location source are selected. If the instance
indicator is specified with following parameters, it selects all,
or the n th, among those children of the location source
which satisfy the other parameters. Negative numbers count from
the last child of the location source to the first. The location
source must contain at least n children; if it does not,
the child term fails.
In formal terms, the first parameter of a step is an
instance indicator, which in turn is either the special value
ALL or a signed integer:
|
If a second parameter is given, it is interpreted as an SGML generic identifier, and only elements of the type indicated will be selected. For example, the location specification
|
chooses the 29th paragraph of the fourth sub-division of the third major division of the initial location source.
Constraint by generic identifier is strongly recommended, because it makes links more perspicuous and more robust. It is perspicuous because humans typically refer to things by type: as the second section , the third paragraph , etc. It is robust because it increases the chance of detecting breakage if (due to document editing) the target originally pointed at no longer exists.
The generic identifier may be specified as a normal SGML name
or using the reserved values #CDATA or *
. If the generic identifier is specified as * , any
generic identifier is matched; this means that CHILD (2 *) is
synonymous with CHILD (2) . If the second parameter
is #CDATA , the location term selects only untagged
sub-portions of an element having SGML mixed content.
The location ladder
|
thus chooses the third span of character data directly contained by the current location source. If the location source is a paragraph containing
where the three sentences A, B, and C are character data enclosed
by no element smaller than the paragraph itself, then CHILD
(3 #CDATA) selects sentence C, while CHILD (3)
selects sentence B.
If specified as a name, the generic identifier is case sensitive if and only if the SGML declaration specifies that generic identifiers are case sensitive (by default they are not).
In formal terms the second parameter of a step is defined thus:
|
The third and fourth parameters, if given, are interpreted as an attribute-value pair, and only elements which match that pair in the way described below will be selected; the fourth and fifth parameters, and all following pairs of parameters, are interpreted in the same way. When more than one pair is given, all must be matched.
The third, fifth, seventh, etc., parameters are interpreted, if
specified, as attribute names. Like generic identifiers, attribute
names may be specified as * in location ladders in
the (unlikely) event that an attribute value constitutes a constraint
regardless of what attribute name it is a value for.
For example, the location term
|
selects the first child of the location source for which the attribute target has a value.
As with generic identifiers, attribute names are case sensitive if and only if the SGML declaration says they are.
In formal terms, the attribute-name parameter of a tree-traversal step is defined thus:
attribute ::= NAME | '*'
|
If a fourth, sixth, eighth, etc., parameter is specified, it is interpreted as an attribute value, and only elements satisfying the other constraints and also bearing an attribute of the specified name and value will be selected. The attribute value may be specified exactly as in an SGML document; as a consequence, if the attribute value to be specified contains white space characters, it must be enclosed in quotation marks. The attribute value may also be specified using the two special values
#IMPLIED and
* .
For example, the location specification
|
chooses an element using the global n attribute. Beginning at the location source, the first child (whatever kind of element it is) with an n attribute having the value
2 is
chosen; then that element's first direct sub-element having the
value 1 for the same attribute is chosen.
If specified with quotation marks or as a regular expression, the attribute-value parameter is case-sensitive; otherwise not.
The location specification
|
selects the first child of the location source which is an fs element for which the resp attribute has been left unspecified.
In formal terms, the attribute-value parameter of a tree-traversal step is defined thus:
|
If the descendant keyword is used, the location term
selects an element or character-data string which is a descendant
of the current location source. The parameters are the same as
for child. The set of elements and strings which
may be selected, however, is the set of all descendants of the
location source (i.e. the set of all elements contained by it),
rather than only the set of immediate children.
The location specification
|
thus selects the second term element with a lang of
de
occurring within the element with an id of a23 .
The search for matching elements occurs in the same order as the
SGML data stream; in terms of the document tree, this amounts
to a depth-first left-to-right search.
If the instance number is negative, the search is a depth-first right-to-left search, in which the right-most, deepest matching element is numbered -1, etc. The location specification
|
thus chooses the last note element in the document, that is, the one with the rightmost start-tag.
The ancestor location term selects an element from
among the direct ancestors of the location source in the document
hierarchy. The location value is of the same form as defined for
the child. However, the ancestor keyword
selects elements from the list of containing elements or ancestors
of the location source, counting upwards from the parent of the
location source (which is ancestor number 1) to the root of the
document instance (which is ancestor number -1).
For example, the location term
|
first chooses the smallest element properly containing the location source and having attribute n with value
1
; and then the smallest div element properly containing it.
The previous keyword selects an element or character-data
string from among those which precede the location source within
the same containing element. We speak of the elements and character-data
strings contained by the same parent element as siblings
; those which precede a given element or string in the document
are its elder siblings ; those which follow it
are its younger siblings .
The instance number in the location value of a previous
term designates the nth elder sibling of the location source,
counting from most recent to less recent. The location ladder
|
thus designates the element immediately preceding the element with an id of
a23 . Negative instance numbers also
designate elder siblings, counting from the eldest sibling to
the youngest. The location source must have at least as many elder
siblings as the absolute value of the instance number. If the
location source has at least one elder sibling, then the location
term
|
designates its eldest sibling and is thus synonymous with the ladder
|
The value
ALL may be used to select the entire
range of elder siblings of an element: the location ladder
|
thus designates the set of elements which precede the element with an id of
a23 and are contained by the same parent.
The keyword next behaves like previous
, but selects from the younger siblings of the location source,
not the elder siblings. The location ladder
ID (a23) NEXT (1)
|
thus designates the element or string immediately following the element which has an id of
a23 . Negative instance
numbers also designate younger siblings, counting from the youngest
sibling to the location source. The location source must have
at least as many younger siblings as the absolute value of the
instance number. If the location source has at least one younger
sibling, then the location term
|
designates its youngest sibling and is thus synonymous with the ladder
|
The preceding keyword selects an element or character-data
string from among those which precede the location source, without
being limited to the same containing element. The set of elements
and strings which may be selected is the set of all elements and
strings in the entire document which occur or begin before the
location source. (For purposes of the keywords PRECEDING
and FOLLOWING , elements are interpreted as occurring
where their start-tag occurs.) The PRECEDING keyword
thus resembles PREVIOUS but differs in searching
a larger set of strings and elements; its result is not guaranteed
to be a subset of its location source.
The instance number in the location value of a preceding
term designates the nth element or character-data string preceding
the location source, counting from most recent to less recent.
The location ladder
|
thus designates the fifth element or string before the element with an id of
a23 . Negative instance numbers also
designate preceding elements or strings, counting from the eldest
to the youngest; the ladder The location source must have at least
as many elder siblings as the absolute value of the instance number;
otherwise, the preceding term fails. The value ALL
may be used to select the entire portion of the document preceding
the beginning of the location source.
The keyword following behaves like preceding
, but selects from the portion of the document following the location
source, not that preceding it.
The token keyword selects a sequence of one or more
tokens chosen from within the character content
of the location source, where tokens are counted exactly as for
the corresponding HyTime dataloc form with quantum=word.
The location value must be either a single positive integer, or
a pair of positive integers separated by white space, representing
the first and the last token numbers to be included in the resulting
location. If two integers are specified, the second must not be
less than the first. The location source must contain at least
as many tokens as are specified in the location value.
This location type must not be used to count across element boundaries.
For example, the location specification
|
chooses the 3rd, 4th, and 5th tokens from the content of the element whose identifier is
a27 . If this element
contained the string This is _not_ a very good idea , the target
selected would be not_ a very .
In formal terms the location value of the token and
str keywords is defined as a range:
|
The space location term applies to entities which
represent graphical or spatio-temporal data; typically such entities
are not encoded in SGML, but in one of many specialized graphical
formats. SGML provides standard mechanisms (the NOTATION declaration
and related constructs) for specifying what format such an entity
uses.
The location value for space consists of two or three
parenthesized parameter lists. The first contains the name of
the co-ordinate space in use. The second and third each consist
of any number of signed integers. The numbers in a parameter list
represent locations along each dimension of a Cartesian co-ordinate
space with all axes orthogonal; the length of the list equals
the number of dimensions/axes of the space (usually, but not inevitably,
2, 3, or 4).
If the third parameter list is not specified, the location is the single point in the co-ordinate space specified by the second parameter list. If all three parameter lists are specified, the location is the rectangular prism defined by treating corresponding items of the second and third lists as inclusive bounds along each dimension in turn.
The mapping from co-ordinates to physical or display space, and the meaning and ordering of the axes, are not defined by these guidelines. They should be specified in the TEI header unless they can be determined by definition from the format in which the referenced entity is known to be encoded (for example, many graphics formats can only encode locations in units of pixels, counted in a 3 dimensional left-handed co-ordinate space).
Time may be construed as an axis in addition to any others; when it is, it is TEI recommended practice that it be positioned last. The units used must be defined in the TEI header; it is acceptable in certain media (such as videodiscs) to use frame numbers as a surrogate axis for time.
For example,
|
specifies the location of the unit square tangent to the origin in quadrant 1 of a common graph.
The location value for a space location term is a
NAME enclosed in parentheses, followed by a point pair:
|
The foreign keyword takes any number of parenthesized
parameter lists, and is terminated by the end of the attribute
value, or by the next non-parenthesized token, whichever comes
first.
The meaning of the foreign location term is not defined
by these Guidelines. It is intended for use in pointing to special
kinds of non-SGML, non-coordinate space data. That is, it should
be used for making links to data which cannot be specified using
the other mechanisms. The meaning of any foreign
location types must be specified in the TEI header, as a series
of paragraphs at the end of the encodingDesc element defined in
section * . If more than one such type is used,
it is TEI recommended practice that the first parameter list to
foreign be a name associated with the particular
type by documentation in the TEI header.
For example, assume that some program uses a proprietary data
format called XFORM, and that the program has supplied an identifier
06286208998 for some piece of data it owns. Then
the location specification
FOREIGN (XFORM) (06286208998)
|
would be one way of expressing a link to that piece of data.
The HTML copy of this draft specification was generated automatically from an XML source file using a custom formatter written in perl.