[Cache. Canonical document at http://clover.slavic.pitt.edu/~djb/sgml/pvl/article.html.]
David J. Birnbaum
Department of Slavic Languages and LiteraturesCopyright (C) 1999 by David J. Birnbaum. All rights reserved.
To appear in: Medieval Slavic Manuscripts and SGML: Problems and Perspectives. Anisava Miltenova and David J. Birnbaum, ed. Sofia: Institute of Literature, Bulgarian Academy of Sciences, Marin Drinov Publishing House. 2000. In press.
Keywords: Standard Generalized Markup Language (SGML), Text Encoding Initiative (TEI), Povest' vremennykh let (PVL), Rus' Primary Chronicle, troff
Note: Most external links in this article are not yet active.
This report describes the development of a TEI-conformant SGML edition of the Rus' Primary Chronicle (Povest' vremennykh let) on the basis of an electronic transcription of the text that originally had been prepared for paper publication using troff. The present report also discusses strategies for browsing, indexing and querying the resulting SGML edition. Selected electronic files developed for this project are available at a web site maintained by the author.
The Rus' Primary Chronicle (henceforth PVL)[1] tells the history of Rus' from the creation of the world through the beginning of the twelfth century. It was based on both Byzantine chronicles and local sources and underwent a series of redactions before emerging in the early twelfth century in the form that scholars currently identify as the PVL. This text was then adopted as the foundation of later East Slavic chronicle compilations.[2]
In the 1970s, Donald Ostrowski reviewed the existing critical editions of the PVL, determined that none was satisfactory, and concluded that it was appropriate to prepare a new edition based on two principles: 1) the full presentation of all significant manuscript evidence and 2) the development of a paradosis (closest possible reconstruction of the common ancestor of the extant witnesses) according to stemmatic principles.[3]
Ostrowski's new print edition of the PVL renders the complete evidence from all major manuscript witnesses in an interlinear format, as follows:
Witness A: full text of first line from Witness A
Witness B: full text of first line from Witness B
Witness C: full text of first line from Witness C
Paradosis: full text of first line from Paradosis
Witness A: full text of second line from Witness A
Witness B: full text of second line from Witness B
Witness C: full text of second line from Witness C
Paradosis: full text of second line from Paradosis
etc. The unabridged transcription of all significant manuscript evidence in this format overcomes two weaknesses of traditional critical editions. First, traditional critical editions usually include only selected variant readings (the problem of incomplete presentation of the evidence). Second, traditional critical editions usually relegate variants to a set of cryptic marginal notes, which frustrates easy reading (the problem of compromised legibility).
Concerning completeness of presentation, whereas traditional critical editions provide variant readings only where the editor believes that these are significant, the new edition transcribes the full text of all witnesses, which will enable the reader to see at a glance the exact textual evidence that guided every step of the editor's preparation of the paradosis. These complete transcriptions free readers from having to accept without verification the editor's decisions about what constitutes significant variation. The editor still fulfills his responsibility to evaluate variant readings (when he decides what to include in the paradosis), but the reader is no longer unable to distinguish situations where there is no variation from those where the editor has decided that variation, although present, is not significant.[4]
Concerning legibility, even when the apparatus of a traditional critical edition does include all significant variation, reconstructing a reading other than the main one requires that the reader mentally insert pieces of the apparatus into the text where appropriate, a much slower and much less accurate process than simply reading continuously from left to right along a single line. While it is certainly true that an interlinear layout occupies more space than a traditional critical apparatus, since it foregoes the economy of presenting repeated information only once, the amount of paper, while significant (the print version of Ostrowski's edition of the PVL comes to slightly more than 2100 pages), is not prohibitive. Furthermore, the length of the published text is far less imporant where electronic editions are concerned than is the case with paper, and convenient and legible access to all manuscript evidence makes an interlinear format a very attractive choice for electronic publication.
The new print edition was originally prepared for processing by troff, a unix-based typesetting system popular in the 1980s and capable of supporting the formatting requirements of a complex multilingual text.[5] Because accessible optical character recognition software at that time was unable to deal effectively and affordably with handwritten manuscripts, early Cyrillic imprints, or even modern Cyrillic imprints, the editor engaged a typist to transcribe the full text of D. S. Likhachev's critical edition of the PVL. Each line of the transcription was then reproduced several times, so as to provide separate copies that would eventually represent each manuscript witness, each published critical edition, and the new paradosis. The individual copies were then edited against the sources they were intended to represent, that is, the text from each line of the Likhachev edition was compared to a particular source and altered to reflect the corresponding text that actually appeared in that source.[6]
SGML Editiontroff was designed to support the publication of documents on laser printers and typesetters, and has been used in a unix environment as part of a multipurposing publication strategy that relies on troff for printing that requires a high typographic standard and nroff, a similar program, for printing to a line printer or monospaced screen display. This flexibility in the choice of output device is possible because troff files are structured formally in a way that provides for easy access to the markup information by any formatter that is capable of parsing the structure. Although the markup of troff documents is presentational (rather than descriptive) in nature, the fact that it is formal greatly simplifies the process of translating between troff and SGML.[7]
I decided to translate the troff source documents to SGML for several reasons: SGML is more portable than troff;[8] SGML is descriptive, rather than presentational, in nature;[9] SGML supports structural validation in a way that troff does not; SGML can be indexed and queried using existing tools;[10] and SGML is more easily converted to HTML for delivery on the World Wide Web than troff. After outlining the method I adopted to prepare the SGML edition of the PVL, below, I describe browsing, indexing, and querying this edition, emphasizing the differences between these procedures in an SGML environment and comparable procedures with troff or plain text.
DTD for the Electronic EditionI decided to use the Text Encoding Initiative (TEI) document type description (DTD) for the SGML edition of the PVL for two reasons. First, the TEI DTD is widely used, which means that a TEI-conformant edition of the PVL can be processed using existing tools and can easily be incorporated into existing TEI-oriented digital libraries.[11] Second, the support for critical editions in the TEI DTD was developed with input from an international committee of experienced philologists from different disciplines, and it was clearly sensible to take advantage of their careful analysis of issues confronting the preparation of critical editions, particularly in an electronic format. In fact, the TEI DTD supports three different encoding strategies for critical editions (the location-referenced method, the double-end-point-attached method, and the parallel segmentation method), and my decision to adopt a TEI approach required me to evaluate and choose among those strategies.[12]
The interlinear structure of the existing electronic PVL files, as well as the desire to preserve an interlinear presentation for rendering the SGML edition, made the parallel-segmentation method an obvious choice. In the parallel-segmentation method, alternate readings of a passage are given in parallel in the text, with no notion of a privileged base text and no separate critical apparatus, an approach that is well suited to the interlinear design of the PVL edition. Furthermore, because the troff files had already aligned the parallel selections from the witnesses, both the parallel and the segmentation parts of parallel-segmentation analysis had already been implemented.
The segmentation in this case was performed according to the lineation of E. F. Karskii's 1926 edition of the Laurentian text of the PVL.[13] The principal advantage of this segmentation strategy is that the lineation of Karskii's edition has become a standard reference system, and is thus the closest thing PVL scholars have to a reference method that is suitable for collating texts that may vary substantially (cf. biblical chapters and verses). An additional practical advantage of segmentating the SGML edition according to Karskii lines, noted above, was that the troff files had already been segmented in precisely this way, which meant that I could obtain automatic parallel segmentation in the SGML edition by preserving the segmentation that had been implemented in the troff source files.
One disadvantage of this segmentation strategy is that querying text that spans apparatus blocks (that is, that crosses Karskii lines) is not supported directly, since text that crosses Karskii lines is not contiguous in the electronic files.[14] A second disadvantage is that segmentation that is dictated by the content of the text (such as by linguistic units) may be more appropriate in some cases than segmentation that is dictated by the typographic accidents of a single edition. An additional consideration that may or may not be a disadvantage is that the TEI parallel-segmentation method assumes that variant readings will be given only where there is variation, while the PVL edition presents the full text from all witnesses, regardless of the extent of agreement or variation among the witnesses. This complicates searching for specific patterns of agreement, since in the present edition there is no information in the markup that indicates which witnesses agree with which other witnesses at a given place.[15]
The TEI parallel-segmentation method groups variants within an app element, which may contain, among other things, rdg elements (which contain individual readings) and rdggrp elements (reading groups, which contain rdg elements). For the present edition, the readings have been assigned to two reading groups, one for manuscript witnesses (<rdggrp n="manuscripts">)and one for published editions (<rdggrp n="editions">). The witnesses within each rdggrp are identified by the value of the wit attribute on the rdg element (e.g., <rdg wit="lav">).
The following is the first block of text from the SGML edition:
<p id="k0-1">
<app>
<rdggrp n="manuscripts">
<rdg wit="Lav">se pov\(qesti vrem\(qan~ny\*(Sx l\(qe\*(St \fR[1\u\s-2v\d\s+2]</rdg>
<rdg wit="Tro">se pov\(qesti vremen~nyx& l\(qet& \fR[51]</rdg>
<rdg wit="Rad">pov\(qest~ vremenny\*(Sx l\(qet& \(qcernorizca feodos~eva \fR[1\u\s-2v\d\s+2]</rdg>
<rdg wit="Aka">pov\(qest~ vremenny\*(Sx l\(qet& \(qcernorizca feodos~eva \fR[1\u\s-2r\d\s+2]</rdg>
<rdg wit="Ipa">pov\(qest~ vremennyx& l\(qe\*(St \(qcernorizca fedos~eva \fR[3a]</rdg>
<rdg wit="Xle">pov\(qesti vr\(qemenny\*(Sx l\(qe\*(St nestera \(qcernorizca fe\*(Sdo\*(Sosieva \fR[2\u\s-2r\d\s+2]</rdg>
</rdggrp>
<rdggrp n="editions">
<rdg wit="Byc">Se pov\(qesti vrem\(jan~nyx l\(qet&,</rdg>
<rdg wit="Lix">Se pov\(qesti vrem\(jan~nyx l\(qet&,</rdg>
<rdg wit="Sax">Se pov\(qesti vremen~nyx& l\(qet&,</rdg>
<rdg wit="Ost">Pov\(qest~ vremen~nyx& l\(qet& \(qc~rnoriz~ca Fedosieva</rdg>
</rdggrp>
</app>
</p>
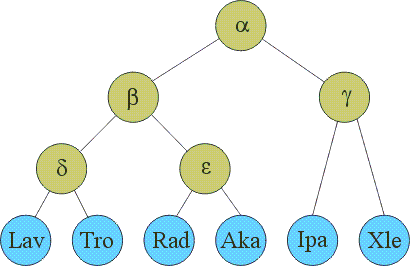
Because a TEI reading group (rdggrp) element may contain not only individual reading (rdg) elements, but also other reading groups, it is possible to subdivide the witnesses further. For example, the paradosis (Ost) might be separated from the other editions by grouping the latter in their own reading group. And the manuscript witnesses might be divided according to the evidence of stemmatic analysis, which reveals a southern tradition (Ipa and Xle) and a northern one, with the latter subdivided into one branch containing Lav and Tro and one containing Rad and Aka. In other words, the following stemmatic structure:
Figure 1: Stemma Codicum for the PVL (Simplified)
can be represented by the following element structure:
<app>
<rdggrp n="manuscripts">
<rdggrp n="beta">
<rdggrp n="delta">
<rdg wit="Lav">Text from lav</rdg>
<rdg wit="Tro">Text from tro</rdg>
</rdggrp>
<rdggrp n="epsilon">
<rdg wit="Rad">Text from rad</rdg>
<rdg wit="Aka">Text from aka</rdg>
</rdggrp>
</rdggrp>
<rdggrp n="gamma">
<rdg wit="Ipa">Text from ipa</rdg>
<rdg wit="Xle">Text from xle</rdg>
</rdggrp>
</rdggrp>
<rdggrp n="editions">
<rdggrp n="old">
<rdg wit="Byc">Text from byc</rdg>
<rdg wit="Lix">Text from lix</rdg>
<rdg wit="Sax">Text from sax</rdg>
</rdggrp>
<rdg wit="Ost">Text from ost (paradosis)</rdg>
</rdggrp>
</app>
This more elaborate nesting of reading groups is obviously an interpretive statement, but it is also a technological convenience, since it simplifies incorporating references to branches of the stemma into queries. That is, a search for a particular string in the northern tradition can be framed in terms of all rdg elements contained at some level by <rdggrp n=beta>, rather than by enumerating the individual witnesses. This grouping has not been attempted in the present edition, but the additional markup could be introduced in a simple automated SGML-to-SGML conversion.[16]
SGML TransformationThe input files for the SGML edition were already encoded for processing by troff, a legacy of a print edition that was conceived before SGML had been developed. As was mentioned above, this format dictated both the general decision to use a TEI parallel-segmentation structure for the SGML edition and the more specific decision to segment the text according to lines in Karskii's edition of the PVL.
The TEI DTD is far more complex than the structure of the PVL actually requires, and the text (non-header) portion of the ultimate TEI-conformant edition uses only four of the 174 elements allowed in the document.[17] To avoid dealing with the unneeded richness of the TEI DTD at the initial stage of the project, I decided to separate the task of parsing the troff source and converting it to SGML from the task of ensuring that the SGML output would be TEI-conformant. With this in mind, I began by developing a minimal DTD that described the structure of the PVL edition more precisely and specifically than the more general TEI DTD. The interim DTD had the following structure:
<!-- pvl-interim.dtd -->
<!ELEMENT pvl - - (block)+>
<!ELEMENT block - o (manuscripts, editions)>
<!ATTLIST block column number #required
line number #required>
<!ELEMENT manuscripts o o (lav?, tro?, rad?, aka?,
ipa?, xle?, kom?, nak?, tol?)>
<!ELEMENT editions o o (byc?, lix?, sax?, ost)>
<!ELEMENT (lav | tro | rad | aka | ipa | xle
| kom | nak | tol) - - (#PCDATA)>
<!ELEMENT (byc | lix | sax | ost) - - (#PCDATA)>
<!ENTITY amp SDATA "&">
<!ENTITY lt SDATA "<">
<!ENTITY gt SDATA ">">
Not only did use of the interim DTD enable me to postpone ensuring TEI compliance until I had fine-tuned my troff parser, but it also enabled me to verify that the witnesses always appeared in the edition in a consistent order. I used omittag to avoid having to determine from the troff source where the manuscript and edition groups began and ended, a task that was complicated by the fact that no witness, manuscript or edition (other than the paradosis) was obligatory for any block of text. In retrospect, I should have combined what I encoded as column and line attributes of the block element into a single attribute of type id, which would have enabled me to verify that all such references were unique.[18]
I tested the adequacy of the interim DTD by hand-coding one block of PVL text and ensuring that it passed validation, after which I wrote an OmniMark script that would parse the troff source and generate an SGML output file that conformed to the DTD. OmniMark is a free text-processing language that combines powerful pattern-matching facilities with a built-in SGML parser. It incorporates an up-translate mode that pipes its output through a validating SGML parser, and one possible strategy for my troff-to-SGML transformation would have been to use OmniMark's SGML parser to validate the SGML output during conversion. I opted instead to use OmniMark's cross-translate mode, which simply matches patterns and fires rules (most of which generate output) without validating the resulting SGML. I then parsed the OmniMark output externally using nsgmls (a free SGML parser) to ensure that the OmniMark output did, in fact, conform to my interim DTD. Separating the generation of SGML output from the validation of that output enabled me to isolate errors in my parsing of the troff input files from syntax errors in the SGML output I was generating.
The troff source files used ampersand (&), less-than (<), and greater-than (>) to represent text characters, and the OmniMark script converted these to SDATA entities, as declared in the interim DTD, above. The character coding was otherwise left intact. This decision is not wholly satisfactory, both because the character coding is nonstandard and because it mixes formatting commands (particularly those pertaining to superscription and the lineation of the manuscripts and editions) with text. The script should eventually be modified to recode superscription and lineation as SGML markup, at which point the transcription can also be adjusted, as needed.[19]
Once I had fine-tuned the OmniMark script to parse the troff input files and generate valid SGML output, I then modified the script to generate TEI-conformant SGML, which I verified by validating the SGML with nsgmls. Until this time I had been operating with individual parts of the troff source, which had been prepared not in a single large file, but in forty-eight separate small files, each containing six Karskii columns, but my eventual SGML edition was to be a single large document. Because the final print edition was to run continuously but the output of most of the forty-eight small parts would not end at the bottom of a page, the editor of the troff files had repeated a varying number of lines from the end of each section at the beginning of the following section. This would enable the publisher to print each section separately, discard the incomplete final pages of each section, and then combine the output of all sections.[20] Because I developed the tools to generate the SGML source at a time when the troff files were still undergoing editing, I could not simply combine them once and remove the duplicate lines manually, since I would continue to receive revisions of the smaller files, and I would need to incorporate these and remove the duplicates once again each time a revision arrived. I avoided this repetitive manual editing by writing a separate OmniMark cross-translate script whose only function was to delete the duplicate sections. I was then able to combine all the troff files into a single input file, generate SGML output, and remove the duplicate lines. The output of this operation passed validation with nsgmls.
SGML EditionThe ultimate value of electronic text in general as a research tool for medieval Slavic studies can be determined by evaluating whether electronic texts enable scholars to conduct meaningful philological research that would have been either impossible or considerably more cumbersome without the assistance of computers. The ultimate value of SGML in particular as a research tool for medieval Slavic studies can be determined by evaluating whether SGML enables scholars to conduct meaningful philological research that would have been either impossible or considerably more cumbersome without the use of SGML.
Regardless of how it ultimately is used, the mere preparation of an SGML edition of the PVL is a considerable accomplishment for at least two reasons. First, it serves the archival purpose of encoding the text using an open standard that has at least as strong a claim on longevity as any electronic format. Second, the SGML edition can be validated in an SGML validating parser, which is not true of the troff files. This means that the SGML edition is guaranteed to be free of certain types of errors, such as repeated sections.[21] But the more important advantages of an SGML-based electronic edition over a plain-text or troff-encoded electronic text involve browsing and querying. In both of these areas, the SGML markup enables the user to access not only the textual content of the document, but also structural information, and this, in turn, provides more sophisticated querying and browsing than would be possible with either paper editions or non-SGML electronic editions.
The troff source files can be browsed using any plain-text browsing utility (such as unix less), text editor (such as gnu emacs), or word processor (such as Microsoft Word). But what the user sees in such cases is not pretty, since the raw troff markup is intermixed with the text. Furthermore, even in cases where what might be considered markup information should be displayed (as is the case with the labels that associate each line of text with its source manuscript), the troff files provide no graphic distinction between markup and text.
It should be noted that the troff source files can be converted to plain text fairly easily by using global search and replace operations (such as with unix sed) to strip out all troff formatting commands. The result is less distracting than the raw troff source files, but it still lacks any graphic distinction between markup that should be displayed (such as the manuscript labels that precede each line of text) and data content.
An SGML edition will prove superior to a troff or plain-text edition for on-line browsing if it is able to suppress unwanted markup and to format desired markup in a way that highlights the difference between markup and data content. One process for browsing the SGML edition that accomplishes these goals--at least partially--is described below.
The troff source files can be searched in a linear fashion using any plain-text pattern-matching tool, such as unix grep, or a custom-designed program written in a language with strong pattern-matching facilities (such as OmniMark, perl, Snobol/Spitbol, gema, and many others). But because the troff source files do not distinguish manuscript labels from manuscript content, there is no easy way to retrieve, for example, all sequences of the letters "ro" without also retrieving the manuscript label Tro wherever it occurs. More importantly, because not every manuscript line is encoded as a single line of text (terminated by an end-of-line code) in the troff source files, it is not possible to retrieve all text in a particular manuscript merely by searching for all lines that begin with the manuscript label. The SGML edition avoids both of these problems, the first by moving the manuscript labels out of the data stream and into markup and the second by using element structure, rather than end-of-line codes, to organize the data. While either of these strategies could be duplicated in a non-SGML electronic edition, it is unclear why one would choose to construct complex patterns that duplicate a function already present in SGML.
The non-SGML tools mentioned in the preceding paragraph perform linear searching, which is of O(N) complexity, which is to say that the time required to complete an arbitrary search increases linearly with the size of the file. More efficient searches require indices that enable more rapid access to arbitrary locations in the data, a concern whose importance increases with the volume of data. It is possible to build such indices for either SGML or non-SGML data, and the SGML indexing tool described below uses Patricia trees, a particularly efficient structure of O(lgN) complexity.
The tool I selected for browsing the SGML edition of the PVL was Panorama Pro 1.5 (running on Microsoft Windows NT 4.0, SP 5), formerly distributed by SoftQuad and now part of the SoftQuad Panorama line of Interleaf products. Any SGML browser should provide roughly the same functionality.[22]
My main SGML file was developed using TEI formal public identifiers (FPIs), which I accessed through local SGML Open catalog files that mapped FPIs to system identifiers (local files). Because the Panorama edition of the PVL might at some point be distributed to users who do not have either the modular TEI DTD files or support for SGML Open catalogs, I used the TEI Pizza Chef to create a monolithic TEI DTD that incorporated all of my modifications in a single file. This makes it possible to distribute a browsable Panorama publication that contains instead of the more complex standard TEI file set a single DTD file that requires no system-dependent catalog configuration.
Panorama Pro includes an interactive menu-driven stylesheet editor. Developing a stylesheet that would render the present edition in a way that is conducive for reading involved simply creating the appropriate brief Panorama catalog and entityrc configuration files, opening the document, and applying style information to structural parts of the text. On a color display, text from manuscript witnesses is displayed in blue, text from editions in green, and the reading from the new paradosis in red. I also configured the stylesheet to prepend the value of the wit attribute of each reading (that is, a label identifying the witness), followed by a colon and space, to each line. The stylesheet also extracts the Karskii reference numbers from the id attribute of each block of text, renders those numbers in an enlarged typesize at the beginning of the block, and precedes the number with horizontal rule for all blocks except the first.[23]
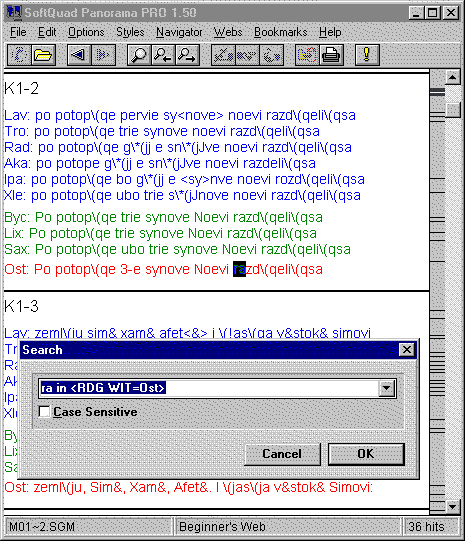
Figure 2: The PVL Displayed in Panorama Pro
Panorama is first of all an SGML browser, that is, a tool for applying rendering information to an SGML document and displaying the document in a way that enables users to read it easily. But Panorama also includes support for context-sensitive searching, which enables it to serve as a research aid in ways that transcend merely displaying a text for reading.
One traditional object of study for Slavic historical linguists has been the distribution of reflexes of Common Slavic liquid metathesis in East Slavic manuscripts. Identifying these examples is a laborious process using conventional, non-electronic methods, which require users to read through each manuscript individually, noting occurrences of the forms in question as they appear. This task is simplified considerably in an electronic edition, since the user can execute a string search within any witness or set of witnesses and find at a glance not only the readings in the witnesses that were queried directly, but also the parallel readings in all witnesses.
Of course an electronic string search cannot distinguish "ra" as a genuine reflex of liquid metathesis (e.g., razd\(qeli\(qsa 'divide [3pl aorist],' Karskii 1-2) from other sequences of the same characters that do not reflect liquid metathesis (e.g., D&n\(qepra 'Dnepr [river] [Gsg],' Karskii 3-18), and scholars must sift through the results of such queries manually in order to separate the two categories. But this sifting takes place as part of non-electronic searching as well, and the added value of electronic searching is that the scholar is not distracted by having to look at absolutely every word in a witness, including those that cannot possibly contain "ra" from liquid methathesis because they do not contain the string "ra" at all.
The preceding screen shot depicts the result of instructing Panorama to search in the paradosis (Ost) for all instances of the sequence "ra" in the first six columns of the Karskii edition of the PVL. The gray vertical bar between the textual display and the right vertical scroll bar is the Panorama "occurrence density indicator," which marks hits with small horizontal black lines. This allows the user to see the distribution of hits within the document,[24] and also to move immediately to any single hit by selecting the appropriate black line. The total number of hits (36) is displayed in the lower right corner and the query target in the text display window (in section K1-2 in this example) is highlighted. Note that Panorama's search engine is capable of implementing queries that refer not only to strings of text, but also to the structure of the document as encoded in SGML markup (in the present case, it can search for "ra" only when that sequence occurs in the paradosis). This gives Panorama considerably more power than plain-text search utilities such as unix grep.[25]
While Panorama's searching abilities greatly transcend those of plain-text tools, they are nonetheless limited in at least three ways. First, searching in Panorama is linear, which means that the time required to conduct a search increases at a constant rate with respect to the size of the file. This is insignificant as long as one is dealing with relatively small files, but it can be a severe inconvenience should a user wish to query hundreds of lengthy manuscript witnesses simultaneously. The limits imposed by Panorama's linear search algorithm can be overcome by employing a search engine that uses index files to implement efficient, non-linear searching, such as the Open Text 5 system, described below.
Second, Panorama can search for text strings only by specifying them exactly. It has no support for character classes, regular expressions, or any type of metacharacters that might let a user search not just for sequences of "ra", but, more narrowly, for such sequences only when they are preceded by either a consonant or the beginning of a word and followed by a consonant, a restriction that would greatly reduce the number of false hits during searching. Below I discuss a strategy for combining the indexed structural retrieval of the Open Text system (which does not support unix regular expressions) with an external regular-expression processor in order to specify extremely complex queries.[26]
Third, Panorama incorporates support for a navigator feature, which is rendered as a collapsible hierarchical table of contents to a document. Unfortunately, the navigator can include text only from the content of an element, and it cannot include text that is generated by Panorama itself or extracted from markup. Because the Karskii reference numbers are attributes of the paragraph elements, it is not possible to construct a navigator that can render a list of numbers, which would enable a user who is interested in the apparatus for a particular Karskii line to use the navigator to identify the location of that line in the document instance. The user can, of course, search for a particular Karskii line in the text, since Panorama does support queries that refer to attribute values, but it is nonetheless not possible to display attribute values directly in a Panorama navigator.
This problem could be circumvented by duplicating the Karskii numbers in the content of an extra element added to the content of the p element expressly for this purpose. One could even use the TEI div structure to divide the PVL into Karskii columns, which would be subdivided into Karskii lines using the TEI P element; if the text that should be rendered in the navigor is included somewhere in the content of each block, the navigator could be configured to display a list of column numbers, each of which can be expanded into a list of line numbers.[27]
Furthermore, because Panorama allows the user to attach multiple navigators to a single document, it would in theory also be possible to construct multiple navigators, each of which displays each line of text for each witness. This would enable the user to read continuous text from a single witness in the navigator, without being distracted by parallel readings, and then to move to the parallel readings for a specific passage whenever desired.[28] Because the names of witnesses in a TEI-based edition are stored only in attribute values and Panorama cannot use attribute information to control the content of a navigator, this approach would also require modifications to the structure of the SGML document.[29]
Although the enhancements required to support the use of Panorama navigators in the PVL edition have not been implemented for the present report, it would not be difficult to do so, and this would broaden the types of access to the edition that would be available to scholars through Panorama (albeit at the perhaps considerable expense of lessening TEI conformity). Meanwhile, the present version, despite its limitations, clearly illustrates the improvements in rendering and access that an SGML edition provides when compared to a non-SGML electronic or paper alternative.
Open Text is an indexing and retrieval tool designed for use with documents in a client-server environment. It uses Patricia trees to build indices that are able to locate text strings extremely quickly even in very large documents, and it provides an API than enables user-designed programs (such as CGI scripts) to query an indexed file and retrieve a report for subsequent formatting and delivery.
Although Open Text does incorporate a full SGML parser, it is ultimately a byte-indexing system, which means that it does not index fully information that may be part of the ESIS output of an SGML document but that is not specified explicitly in the document instance. In practice, this means that queries of SGML documents that have been indexed with Open Text cannot refer, for example, to default attribute values that have not been specified in the document itself.[30]
This limitation can be overcome by using spam (which stands for "sp add markup"), part of James Clark's sp suite of SGML and XML tools, to insert omissable markup that was not specified in the original SGML file. The output of spam may then be piped through sgmlnorm, another tool from the sp suite, which normalizes markup capitalization and spacing. This modified SGML file generates the same ESIS as the original (partially minimized and nonnormalized) version, but it differs from the original by making additional ESIS information available to Open Text.[31]
Although Open Text supports its own control file for associating FPIs with system files, the format of this file differs from the format of the SGML Open catalog used by most other SGML tools, and it proved simplest to forego FPIs and use the monolithic DTD that was generated for Panorama. With this in place, the Open Text indexing procedure was simple and quick, although it was necessary to make three sets of changes to one of the automatically-generated control files.
First, by default Open Text creates index points only at the beginnings of words, which makes it impossible to retrieve strings that start in the middle of a word. Since Slavic philologists may wish to search for strings within a word (e.g., to investigate the reflexes of liquid metathesis described above), it is necessary to instruct Open Text to create index points for every character in the document.
Second, by default Open Text converts all punctuation to space characters for indexing purposes, which enables users to search for a particular word by terminating the query string with a space character (e.g., " text " will retrieve not only the string "text" surrounded by spaces, but also the same string followed by a period or comma, in parentheses, etc.).[32] In the PVL edition, however, many punctuation marks represents alphabetic characters, which means that the lines in the configuration files that would normally map punctuation to space characters need to be deleted.[33]
Third, by default Open Text maps upper-case alphabetic characters to lower-case ones for indexing, which enables support for case-insensitive queries. This conflation is generally desirable, although it forecloses searches that target specifically upper-case or specifically lower-case letters, and different index files would have to be built if support for this type of searching were required. The PVL troff files employ upper- and lower-case letters in their usual alphabetic function (for editions) and to distinguish larger or decorative letters from regular ones (for manuscripts, where case in its modern sense is not part of the orthographic system). There is, however, one other place where the troff files exploit a case distinction: the troff string call \*(jj represents titlo over the preceding character, while \*(jJ represents titlo that straddles two characters. Because upper-case J is not otherwise used in the troff files (lower-case j is used widely as part of an escape sequence), the distinction between upper-case J and lower-case j in the Open Text indices has been retained even as all other alphabetic case differences have been neutralized.
Open Text supports queries either directly (by launching the Pat query and retrieval engine in its own terminal window) or through an API (where access may be mediated by an Open Text tool such as Lector or, as illustrated below, by an HTML query form and CGI script). In the present case, the direct method was used to fine-tune the query specifications, after which these specifications were built into a CGI script, for which an HTML query form was then developed.
For the purpose of this report, all queries involved searching for a particular string in the normalized paradosis and returning, among other things, the corresponding evidence from the manuscript witnesses. As far as Pat is concerned, searching the non-normalized manuscript transcriptions directly is no different from searching the normalized paradosis, since both queries simply look for the specified string. But the process of specifying the strings for searching non-normalized transcriptions is complicated by orthographic variation, which may license an unmanageable number of spellings of a particular word. The orthographic variation is preserved in the edition for archeographic reasons, to provide better documentation for the edition in general, and because orthography is often an object of study in its own right. But once these differences have been included in the source document, telling Pat to ignore them when they are not wanted is effectively impossible.
This limitation can be overcome by including in the document instance both normalized and non-normalized versions of each witness, both of which would then be available for querying and reporting. Although much of the conversion from the existing non-normalized transcriptions to normalized transcriptions can be automated, some manual editing will nonetheless be required, since orthographic variation includes not only variant letter forms, but also unpredicatable abbreviation and other idiosyncracies.
Pat queries may refer to SGML elements, attributes, and data content. For example, the following Pat query retrieves the Karskii column and line numbers for all lines where the paradosis contains the string "ra":
pr.region."A-ID" K within (region "A-ID" within (region P including (ra within (region RDG including (Ost within region "A-WIT")))))
The initial pr.region."A-ID" instructs Pat to print the value of the id attribute returned by the query defined by the rest of the line. Working from the left, this query, which is going to return the value of the id attribute, restricts itself to instances of that attribute that contain the string "K".[34] The text in question must then occur within a p element (a block of text including the readings of all witnesses that correspond to a specific Karskii line) that must include the string "ra" within the paradosis (a rdg element whose wit attribute has the value "Ost"). Pat is flexible enough to be able to return whatever the user requires; in the present instance this was just the value of the id attribute, but it could just as easily have been the corresponding text from any witness or set of witnesses.
Pat is capable of generating reports in two different modes, one designed for legibility and the other designed for machine processing. Pat also reads from stdin and writes to stdout, which means that the output generated by Pat can be piped to other processes and vice versa. This feature makes it possible to graft support for regular-expression processing onto Pat, which can be used to eliminate many false positives, such as those generated by an unrestricted string search for "ra" when what is really desired is only the instances of "ra" that may reflect liquid metathesis. This strategy is described below within the context of an HTML query-form interface to a CGI script written in perl.
The HTML query form asks for two pieces of input: the type of query (string with case folding or perl regular expression) and the query string itself. The following screen shot illustrates an abbreviated query form; a more complete one includes a brief description of the project, instructions about how case folding and regular expressions are implemented, and a pointer to the official documentation for perl regular expressions:
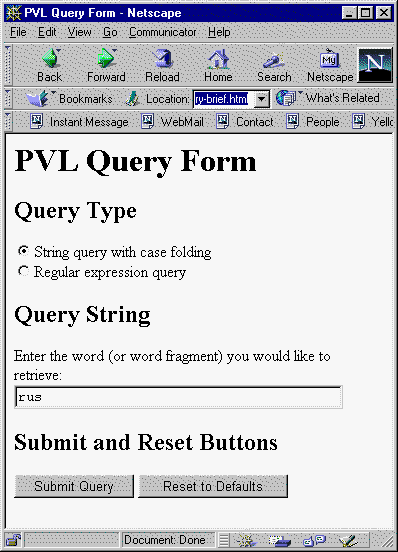
Figure 3: Abbreviated HTML Query Form
A user who fires off this string query might see the following result:
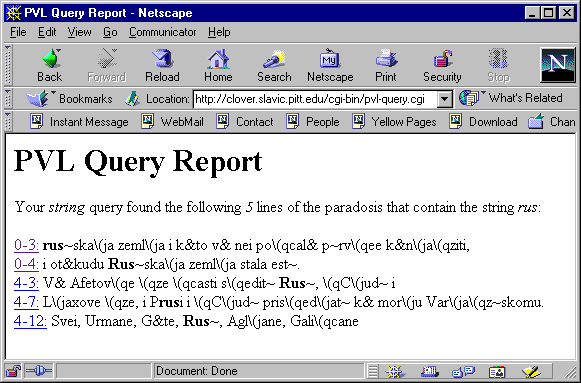
Figure 4: Results of Search for "rus" in the Paradosis
In the preceding screen shot, each line of text from the paradosis that includes the query string ("rus" in the present example) is displayed in full with the search string in bold and is preceded by the Karskii line number. The line numbers are links to a second CGI script, which will retrieve the corresponding readings from all witnesses. The following screen shot shows the results of selecting Karskii line 0-4 from the initial report above:
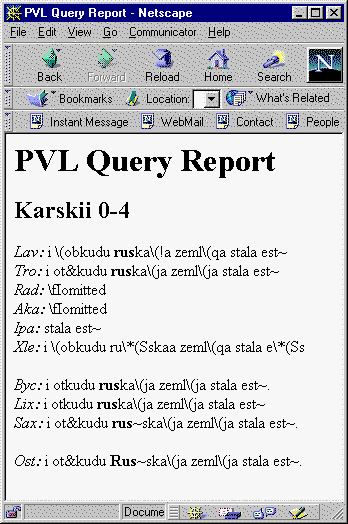
Figure 5: Text of Karskii 0-4 from All Witnesses
The preceding screen shot identifies the Karskii line and then presents the manuscript evidence, with a block of manuscripts first, followed by a block of previous editions, followed by the paradosis. The query target is in bold.
The query system illustrated by the screen shots above is driven by three CGI scripts. The first two conduct the initial (string and regular-expression) queries, returning a list of Karskii lines where the paradosis contains the query target. The third script is called by the other two to retrieve all witnesses corresponding to a particular Karskii line. Alternatively, one could develop more flexible scripts that would let the user specify the witness(es) to be used for the initial search (instead of only the paradosis, as is the case at present) and the evidence to be returned (perhaps a user-selected set of witnesses, rather than all witnesses).
The algorithm for string searches uses Pat to find all lines of the paradosis that match the target string and return both those lines and their associated Karskii line numbers. Because Pat does not support regular expressions, the algorithm for regular-expression searches retrieves all lines of the paradosis and their associated Karskii numbers, uses perl regular expressions to identify the lines of the paradosis that include a match for the query target, and then passes only those along to the user. In both string and regular-expression reports the Karskii line number that precedes each lines of the paradosis is an HTML a element that includes the Karskii line number and the original search target in the href attribute (e.g., <A HREF="http://clover.slavic.pitt.edu/cgi-bin/pvl-query1.cgi?string=rus&karskii=0-4">). Selecting a line number will return the entire app element (text from all manuscripts and editions) for that Karskii line number.
In general, any electronic edition will provide faster searching and retrieval than a paper edition.[35] If one wishes to take the structure of a document into consideration, an SGML document will support more sophisticated structural queries than plain text or text with procedural markup (such as troff).
The present report has documented the generation of a TEI-conformant SGML edition of the PVL from troff source using free tools. It has also illustrated the convenience of browsing and searching the text in Panorama, which includes support for queries that refer to the SGML element structure. This report has also described the use of Pat in a web-based environment to retrieve and render only selected portions of the document. Although Pat does not support regular expressions directly, this report has outlined a method for overcoming this limitation.[36]
[1] The acronym PVL is based on the traditional Russian name of this work: Povest' vremennykh let.
[2] The literature on the PVL from both historical and philological perspectives is vast. The best-known and most important sources (both editions and criticism) are cited in Ostrowski 1981.
[3] See Ostrowski 1981 for an introduction to stemmatic source criticism, with bibliography, and Ostrowski 1999 "Principles" for additional discussion of the application of stemmatic source criticism to editing the PVL
Ostrowski's edition of the PVL is scheduled for publication in 1999 as The Povest' vremennykh let: An Interlinear Collation and Paradosis, Donald Ostrowski (ed), Cambridge, MA: Distributed by the Harvard University Press for the Ukrainian Research Institute of Harvard University, 1999 (Harvard Library of Early Ukrainian Literature. Texts. Vol. 10. 3 volumes.)
[4] The new PVL edition thus incorporates certain features of diplomatic editions into a critical edition.
[5] These files are currently being processed with gnu groff, a gnu (see <http://www.gnu.org/>) counterpart to troff written by James Clark, the author of the sp suite of SGML tools.
[6] This data-entry strategy was determined primarily by economic concerns; the project did not have the funding needed to support the traditional data-entry method of having each source entered twice, so that the two copies could then serve as controls of each other's accuracy.
The original transcription from the Likhachev edition was performed by Volodymyra Stefura. The text from the manuscript witnesses was edited initially by Donald Ostrowski (using the critical apparatus in Ludolf Müller's Handbuch zur Nestorchronik) and then by David J. Birnbaum (using microfilm copies and published facsimiles). It was then proofread by Aleksei Gippius (using the actual manuscripts), after which Donald Ostrowski evaluated and input the suggested corrections. The text from published critical editions was edited initially by Donald Ostrowski and then proofread by Thomas Rosen, after which Donald Ostrowski evaluated and input the suggested corrections. Donald Ostrowski also prepared the paradosis and served as general editor of the project.
[7] Procedural markup tells a processor what to do, e.g., to italicize a segment of text. Descriptive markup records the structural role of a segment of text, e.g., that it is a book title. Because procedural statements tend to neutralize descriptive differences (e.g., book titles, emphasis, and foreign words are all descriptively different, but all may be italicized identically for presentation), conversion from descriptive to procedural markup is almost always simpler than conversion in the opposite direction.
[8] This has three implications, two synchronic and one diachronic. First, although troff is still part of most standard unix distributions, since it continues to underlie the unix man(ual) system, very little unix-based document processing other than man pages is currently performed using troff. There are very few troff books in print and it can be very difficult to find a knowledgeable troff specialist. Second, although troff has been ported to many non-unix operating systems (either directly or as gnu groff), its unix pedigree and its diminishing use means that it may be difficult to find and configure troff-compatible software on non-unix systems. Third, because SGML is a document-description system, rather than a piece of software, documents marked up with SGML are likely to have a longer lifespan than those that are marked up in a way that supports a single use with a single piece of software. Software tools tend to change, often rapidly, and documents encoded in formats that rely on a single piece of software may become inaccessible should that software become obsolete.
[9] This commonplace requires qualification, since there is nothing about SGML itself that requires that documents be marked up descriptively, rather than presentationally. It is nonetheless the case that SGML does not privilege presentation in the way that systems such as troff do, and SGML markup that is based on description, rather than presentation, is more flexible than the necessarily presentational troff markup (for reasons described above).
[10] While the textual content of troff and other electronic text formats can also be queried (using unix grep, for example), queries of SGML documents that have been marked up descriptively can take both textual content and structure into consideration.
[11] For a partial list of existing TEI-based projects see <http://www-tei.uic.edu/orgs/tei/app/index.html> .
[12] See TEI P3, Section 9.2 for detailed descriptions of all three methods.
[13] Lavrent'evskaia letopis'. Vyp. 1, Povest' vremennykh let. 2. izd. Leningrad: Akademiia nauk SSSR, 1926. Polnoe sobranie russkikh letopisei; t. 1. Prepared by the Arkheograficheskaia komissiia, Akademiia nauk SSSR.
[14] Queries that cross Karskii lines could be supported by encoding the individual witnesses separately, without segmentation, and linking these versions to the parallel-segmentation edition. If the link endpoints in the unsegmented transcription are encoded with standoff markup that uses location ladders, users will be able to query a single, continuous text stream and generate a report that returns the corresponding portion of the segmented edition. This strategy has not yet been implemented.
[15] The new edition of the PVL reproduces many orthographic (and sometimes even paleographic) peculiarities of the manuscript witnesses. These variants are often important to Slavic philologists who are interested in orthographic issues, while they are simultaneously distracting to historians who may not require this level of detail. That an edition may serve multiple audiences complicates determining when variation should be considered significant, and this, in turn, makes it impractical to conflate readings in the way that is commonly encountered in editions based on heavily normalized transcriptions. For a description of considerations involved in transcribing manuscripts for electronic editions, see Birnbaum 1996, especially Section 3.
[16] Although this grouping would simplify processing, it is not strictly necessary, since it is inferable from the existing markup.
[17] The PVL SGML files use the TEI base tag set for prose and the TEI auxiliary tag set for critical editions.
[18] When I switched over to the TEI DTD, I did, in fact, encode these references as a single id attribute of the p element enclosing each Karskii line, preceded by a "k" (e.g. "K11-20") both to represent "Karskii" and because attributes of type id may not begin with numerals (unless one modifies the SGML declaration).
The use of number as the declared-value keyword (type) of the column and line attributes in the interim DTD proved problematic when I encountered significant portions of text that Karskii had excluded from his edition but that nonetheless needed to be recorded because they were part of the evidence. The troff edition used Arabic letters to indicate these, e.g., block 11,20 (Karskii column 11, line 20) is followed by block 11,20a (omitted from Karskii's edition but occurring after the text of block 11,20 in some witnesses and some other editions), and my use of the number keyword excluded alphabetic characters from the attribute value. I could have modified the interim DTD to deal with this situation, but instead I fine-tuned the troff parser using the interim DTD only on portions of the troff source that did not contain such inclusions, and then switched to a TEI-conformant DTD (see below) to parse the entire source.
[19] Because early Cyrillic is not currently supported in standardized tools, some form of transcription is desirable, especially for web delivery. The most widely-used system for rendering early Cyrillic writing with ascii characters (Geurts 1987) is suitable only for texts that have been normalized more thoroughly than the PVL transcriptions. See Birnbaum 1996 and Lazov 1999 for a discussion of transcriptions of early Cyrillic materials for electronic publication.
[20] This problem could have been avoided by combining the current forty-eight small sections into a single comprehensive file at any stage, but processing files of this size was sufficiently impractical when the project was begun to make the current treatment of incomplete pages more convenient.
[21] In fact, except for the deliberate repetition of sections across the boundaries of the forty-eight small files, the troff source was also free of duplication. The difference is that there was no way to verify this on the basis of the troff files except by visual examination, while the syntactic integrity of the SGML files can be guaranteed by a validating parser.
It should also be noted that the TEI DTD does not support all types of validation that scholars might want. For example, my interim DTD could verify that all manuscript transcriptions occurred in the same order in all sections, while the TEI DTD cannot. The difference is that my interim DTD treated each manuscript line as a separate SGML element, specifying that those elements, although optional, could occur only in a particular order. The TEI DTD treats each manuscript line as a rdg element, with the identity of the manuscript encoded in the wit attribute, and SGML is unable to restrict the order of identical elements that differ only in attribute value. For that matter, the TEI DTD cannot even ensure that a particular app element does not contain two rdg elements that have the same value of their wit attributes.
Because the TEI DTD is intended for general use, it is not able to use generic identifiers (element names) to represent the names of witnesses, and is forced instead to rely on the wit attribute (whose content type is defined as CDATA). Careful preparation of an edition might, therefore, involve validating the files using an ad hoc DTD comparable to my interim DTD, above, before producing a final TEI-conformant document. Alternatively, one could modify the TEI DTD to include additional elements representing individual witnesses, although such extensive modification would complicate access to the benefits derived from using the TEI standard in the first place.
[22] The SGML edition could also be converted to an XML edition, which would enable users to browse the texts using a much larger number of tools, including Microsoft's free Internet Explorer 5. An XML version of the TEI DTD is under active preparation by the TEI Consortium. The PVL edition does not use any feature of SGML that cannot also be supported in XML.
[23] Ideally I would have set off the prepended manuscript labels from the manuscript text typographically, as well, but Panorama does not support different typographic features (color, typeface, weight, etc.) for the content of an element and for prepended generated text (such as text extracted from attribute values) for the same element. This is a limitation of Panorama, rather than of SGML in general.
[24] This may be of limited use when one is examining such low-level orthographic details as reflexes of liquid metathesis, but it could be very helpful if, for example, one wishes to find the portions of the PVL where a particular person or place is discussed. In this case, the density of hits for the name of the person or place would almost certainly be correlated, at least in some general but nonetheless meaningful way, with the extent to which a given portion of the text is concerned with that person or place.
[25] It might seem as if one could mimic the Panorama search by using a regular expression like ^\fBOst\f[cC]:.*ra, but there is no guarantee that a Karskii line will appear on a single troff line, and Karskii lines that are broken over multiple troff lines do not contain the manuscript label on each troff line. It would be very awkward (although not impossible) to construct a regular expression that would cross end-of-line codes until doing so encountered a string that indicated the end of the current witness.
[26] Pat, the Open Text query engine, allows queries to specify ranges of contiguous byte values, but it does not support other features of regular expressions.
[27] In general, the design of an SGML document should be determined by the inherent structure of the source document and by the interests of those who will use the electronic text. To let the limitations of a particular application determine the design of the edition compromises the application-independent multipurposing nature of SGML. More practically, however, the editor needs to decide whether introducing a superfluous element that will enable Panorama to support a navigator that uses Karskii reference numbers is sufficiently important to compensate for having to ignore that element when the same SGML document is processed by other applications. (One could, of course, perform SGML-to-SGML transformations to create variant custom SGML documents for each application, but this is an additional step that may be more of an inconvenience that the use of application-driven SGML structure.)
[28] One minor inconvenience is that Panorama does not support searching directly in a navigator, which means that a user who wanted to search for a string within a particular witness displayed in a navigator would have to search for that string within the entire document, constructing the search so as to restrict the domain to the witness in question. The effect is the same as that of searching the navigator text directly, but the syntax of the query is more complex.
[29] In this case, the modifications, which would involve enclosing the entire witness text in an element other than rdg, would be so great as to impinge significantly on the TEI-conformity of the document. And because Panorama cannot render text in a navigator that is not rendered in the main document window, it is not possible to include a parallel copy of the text that would be used only to facilitate navigation and would not be displayed in the main text window.
[30] Open Text indexes minimized default attributes, but the index points to a zero-length string, that is, it retrieves the attribute value specified in the document instance (in this case nothing), rather than a default value specified in the DTD (which is part of the ESIS).
[31] The Open Text sgmlrgn tool supports a normalize mode that can produce the same result.
[32] This remapping occurs only in the index files. The document file remains unchanged, which enables the punctuation to be ignored during indexing but rendered during reporting.
[33] The only mapping of punctuation retained in the Open Text document definition (dd) file involved the double quotation mark ("), which cannot be searched explicitly even if it is not remapped because the Pat query engine uses this character as a delimiter and does not provide an escape mechanism.
[34] Because id is an implied attribute for all TEI elements, all elements in the document contain an id attribute, even where this is not specified. Requiring that the attribute value contain a value that is known to occur in all Karskii references (and nowhere else, although in the present case no other id attribute value has been provided anywhere) weeds the implied values out of the query.
[35] Of course an electronic edition cannot perform philological or linguistic analysis by itself. For example, a user could search an English-language electronic text for all forms of the verb "to go" only if someone had included the information that "go" and "went" are both forms of "go". On the other hand, the same user could construct a set of careful string searches to locate all forms of "go" fairly quickly, even though this process might retrieve some false hits that might then need to be weeded out manually.
[36] As impressive as these achievements may be, there is also considerable room for improvement before the edition is ready for general use. Possible improvements include the following:
SGML edition.HTML that embeds graphics to represent the Cyrillic, the user would still need to be able to input Cyrillic query strings. Because the paradosis is heavily normalized, it would not be difficult to use Geurts's (1987) familiar transliteration system for this purpose, but users may also wish to query the manuscript transcriptions in a way that employs distinctions that are not supported by this transliteration. See Lazov 1999 for a proposal to overcome this limitation.SGML publishing environment from Inso. Available at: <http://www.inso.com/dynatext/> . SGML parser. Part of James Clark's free sp suite of SGML tools. Available at: <http://www.jclark.com/sp/> .SGML parser. Available at: <http://www.omnimark.com/> .SGML browser formerly manufactured by SoftQuad and now available from Interleaf. See: <http://www.interleaf.com/> .SGML normalizer. Part of James Clark's free sp suite of SGML tools. Available at: <http://www.jclark.com/sp/> .SGML processing tool, part of the discontinued commercial Open Text 5 indexing and retrieval product from Opentext, now replaced by Livelink. See <http://www.opentext.com/> .SGML tools. Available at: <http://www.jclark.com/sp/> .DTDs and documentation. Available at: <http://www.uic.edu/orgs/tei/> .DTD file from the TEI modular structure. Available at: <http://www.uic.edu/orgs/tei/pizza.html> and <http://www.oucs.ox.ac.uk/humanities/TEI/pizza.htm> .pvl-interim.dtdDTD used to develop troff parsing code. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/pvl-interim.dtd> .pvl-tei.dtdDTD (encoded as a single file). Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/pvl-tei.dtd> .pvl-interim.xomm01.n to m01-interim.sgml. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/pvl-interim.xom> .pvl.xomm01.n to m01.sgml. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/pvl.xom> .pvl.sshm01.sgml. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/pvl.ssh> .catalogcatalog file for browsing m01.sgml. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/catalog> .entityrcentityrc file for browsing m01.sgml. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/entityrc> .m01.nm01-interim.sgmlSGML version of m01.n (uses pvl-interim.dtd). Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/m01-interim.sgml> .m01.sgmlSGML version of m01.n (uses pvl-tei.dtd). Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/m01.sgml> .m01-spam.sgmlSGML version of m01.n (uses pvl-tei.dtd) that has had omissable markup (such as default attribute values) inserted by spam. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/m01-spam.sgml> .m01-sgmlnorm.sgmlSGML version of m01.n (uses pvl-tei.dtd) that has had markup formatting normalized by sgmlnorm. Used with Pat. Available at <http://clover.slavic.pitt.edu/~djb/sgml/pvl/m01-sgmlnorm.sgml> .